国产芯片上如何排查大模型精度问题?干货经验分享!
我们使用了逐算子、逐 module 层精度对比工具,以及 loss 曲线比对的方式,排查分析了大模型微调时下游评测精度在 A2 和 CUDA 对不齐的问题。经分析发现和rms_norm存在精度问题,在使用非和使用组合的rms_norm后,loss 曲线可以和 CUDA 对齐,且下游评测任务的平均得分和 CUDA 基本一样。如果你喜欢我们的内容,欢迎我们!也欢迎在评论区与我们互动!你的支持是我们持续
作者:YB from DeepLink Group
TL/DR
使用国产芯片训练、微调或推理大模型时,经常会遇到下游评测精度降低的问题。此问题一直困扰着使用国产算力的AI 算法研究员。因为精度问题分析涉及的链路较长,需定位是数据问题、大模型框架问题还是国产算力自身的问题。本文以 InterLM2-102B 模型在昇腾Atlas 200T A2 Box16上微调为例,展示了顺利排查精度问题的全过程,向大家分享国产芯片上的精度排查经验。
1. 前置工作
默认用户已在昇腾Atlas 200T A2 Box16(后续简称A2)上适配好了大模型训练、微调或推理框架,并在使用过程中存在评测精度下降的问题。
DeepLink 有一整套大模型框架接入国产芯片的适配方案,感兴趣的朋友可以点击链接了解和使用。
2. 微调精度问题描述
使用 EasyLLM 框架对 InterLM2-102B 模型进行 sft 全参微调,并在A100上使用 OpenCompass 评测。在 A2 上微调后的模型的下游评测结果和 Nvidia A100 使用相同框架微调后的评测结果对比,平均精度下降 1 %,其中部分评测集上下降超过 2 %。值得注意的是,在题目较少的评测集上评测时,评测得分可能出现较大抖动,对排查精度问题会带来一定的干扰,不过当前情况不存在此类问题。除此之外,通过多次重复实验验证,结论与上方描述情况一致。
3. 问题排查
3.1 设计 A100 和 NPU A2 的对比实验
设置对照试验,即除了 A100 和 A2 这两种硬件不一样之外,保持大模型微调框架和数据集一致,并且需满足以下情况:
-
微调时,随机数种子需保持一致、且均在CPU 上生成。因为不同硬件使用的随机数生成算法可能不一样,导致相同种子生成的随机数不一致。
-
确保微调模型没有使用设备上带随机性的算子。比如 dropout 等,本次场景中虽使用了 dropout 算子,但 dropout 的 p 值为 0,故不具有随机性。如有带随机性的算子在设备上计算,可将其 fallback 到 CPU 上。因随机数种子一致,所以在两台设备上产生的结果也会一致。
-
确保微调使用的数据集一样,且数据集的加载顺序一样。
在满足了以上 3 个条件的基础上,开始初步排查 loss 曲线的对齐情况。对于 102B 的模型,我们发现 loss 曲线的相对误差会在 0.2%左右,具体可见图 1、图 2、图 3。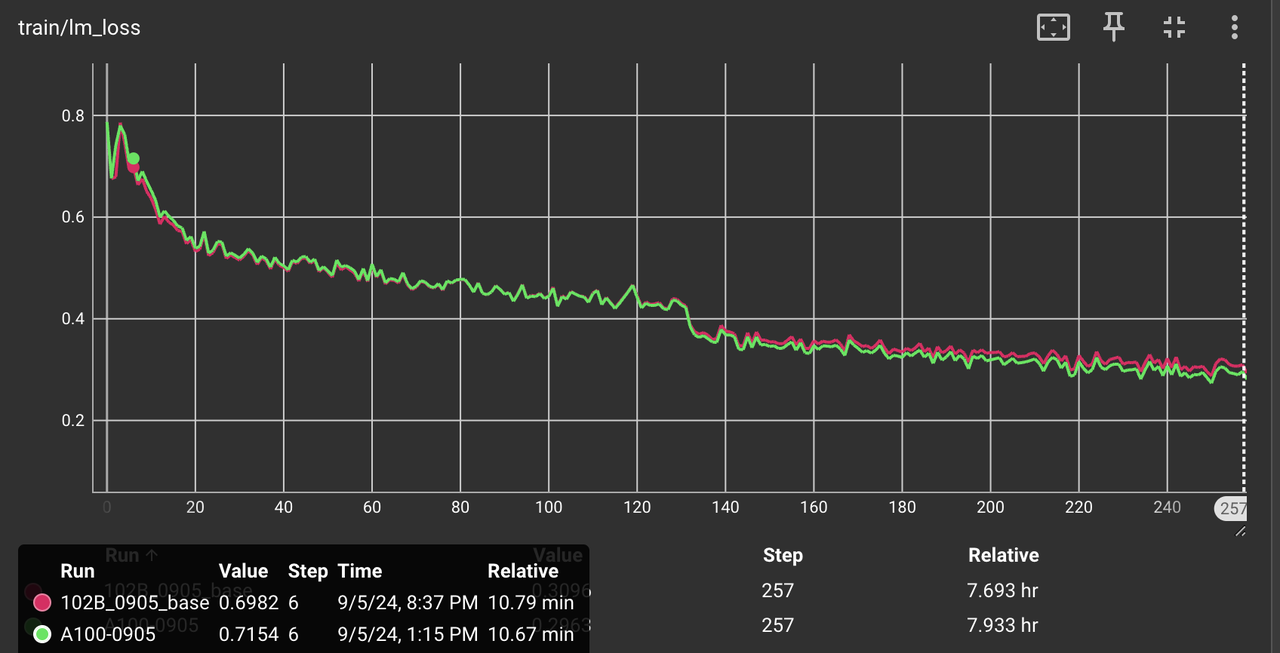
图 1:整体的 loss 曲线(微调了2个epoch)
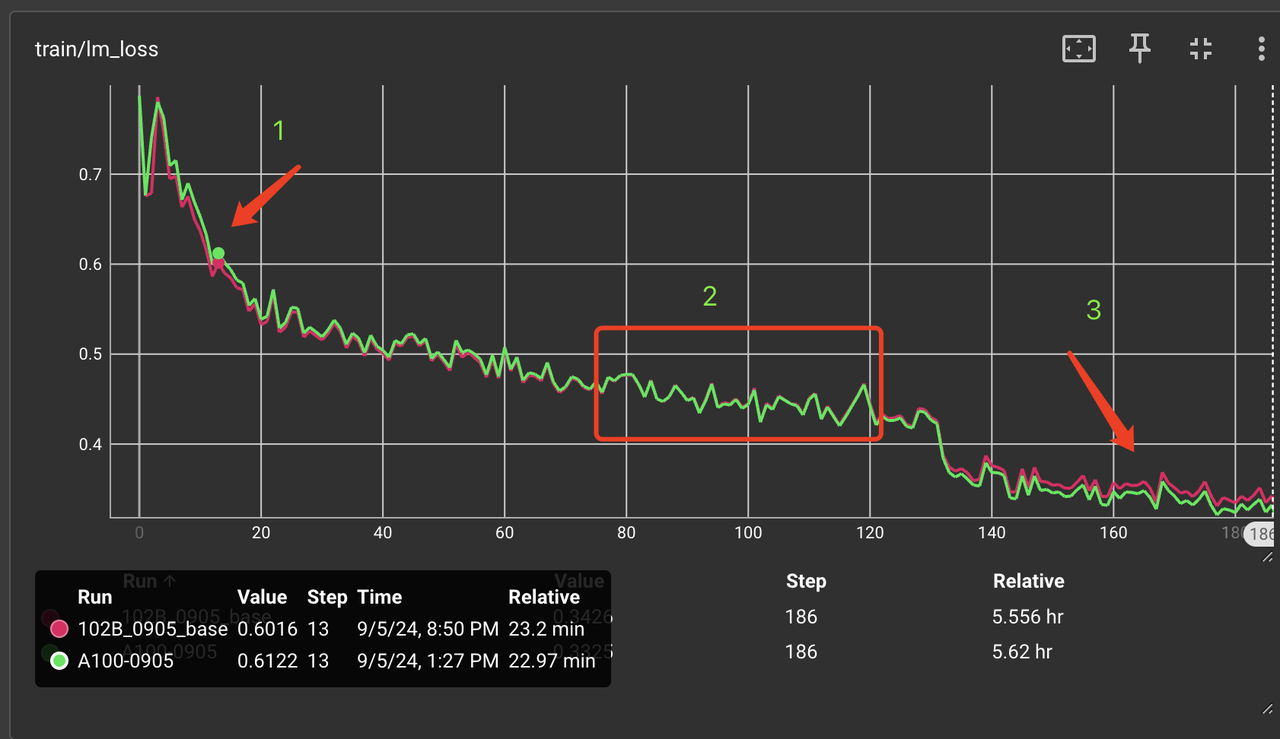
图 2:第 1 个 epoch loss 曲线对比图。
图 2 中可以看到,在“1” 处 loss 有的较大误差,A2 的 loss 值比 A100 上低了约 0.011,相对误差 1.8%;在“2”处 loss 基本一样;而在第 2 个 epoch 的中,“3”处 loss 明显变大,且 A2 loss 值比 A100 的 loss 值高约 0.01 。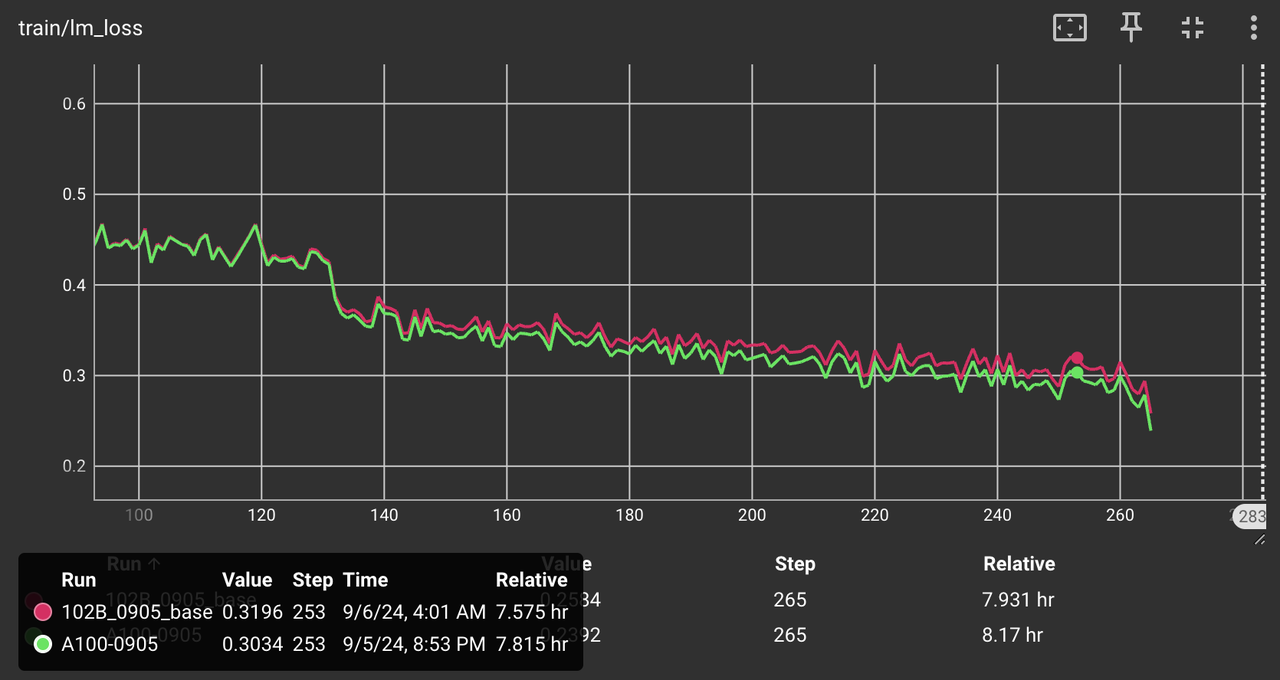
图 3:第 2 个 epoch 的 loss 曲线对比图。第2个 epoch 的后段, A2 的 loss 曲线比 A100 高了约 0.016,相对误差为 2.6%。
由于昇腾的通信库带 reduce 操作的算子计算顺序有不确定性,设置以下环境变量可保证确定性。比如 reduce sum 的浮点累加,由于累加顺序不一致导致计算结果不一样, 所以以上实验都已确保了通信的确定性。
export HCCL_DETERMINISTIC=true
export LCCL_DETERMINISTIC=1
针对这种精度下降的问题,通常是计算错误引起的。其中计算错误包含:
-
使用到的 PyTorch 算子计算错误。针对这种算子,可以使用 DeepLink 下 ditorch 自带的算子对比工具,进行计算结果的校验。此工具会将 CPU 的计算结果和设备上的计算结果进行比较;在 CPU 上运算时,对具有累加性质的算子会提升数据类型再进行计算,从而提升 CPU 计算精度,保证算子对比工具的可靠性。
-
使用到的 PyTorch 外的扩展算子计算错误。比如
rms_norm,flash-attention,rotary_embedding等。此情况下,需在模型中抓取真实输入的数据,在模型外写最小复现代码计算输出结果,再和 CUDA 的计算结果相比较。 -
通信库中,带 reduce 操作的通信算子在 reduce 时计算错误,比如
reduce、all_reduce、reduce_scatter等。当然很少会有通信算子在reduce时会计算错误,更多的是浮点数计算a+b+c != c+b+a。也就是浮点数求和计算会存在大数吞小数的问题,其累加的顺序对结果会有较大的影响。我们可以使用上面提到的开启通信确定性的环境变量,也可以把带 reduce 运算的所有算子的输入转为 fp32,再把运算得到的结果从 fp32 再转为 bf16。
有了上面的分析,下面只需做对应的实验排查问题即可。
3.2实验排查计算错误的类型
1. 确认是否为通信库中带 reduce 操作的通信算子引起误差?
首先,将通信带 reduce 的算子统一用了 fp32 来运算,得到 loss 曲线如图 4 所示。从图中可以看出 loss 曲线确实有所下降,但是幅度很小,和 A100 的 loss 曲线相比仍然有较大的差距。这里使用 fp32 后下降是符合预期的,因为 fp32 的 reduce sum 会比 bf16 的 reduce sum 精度更高,所以可以确定通信算子不是本次精度问题的主要原因。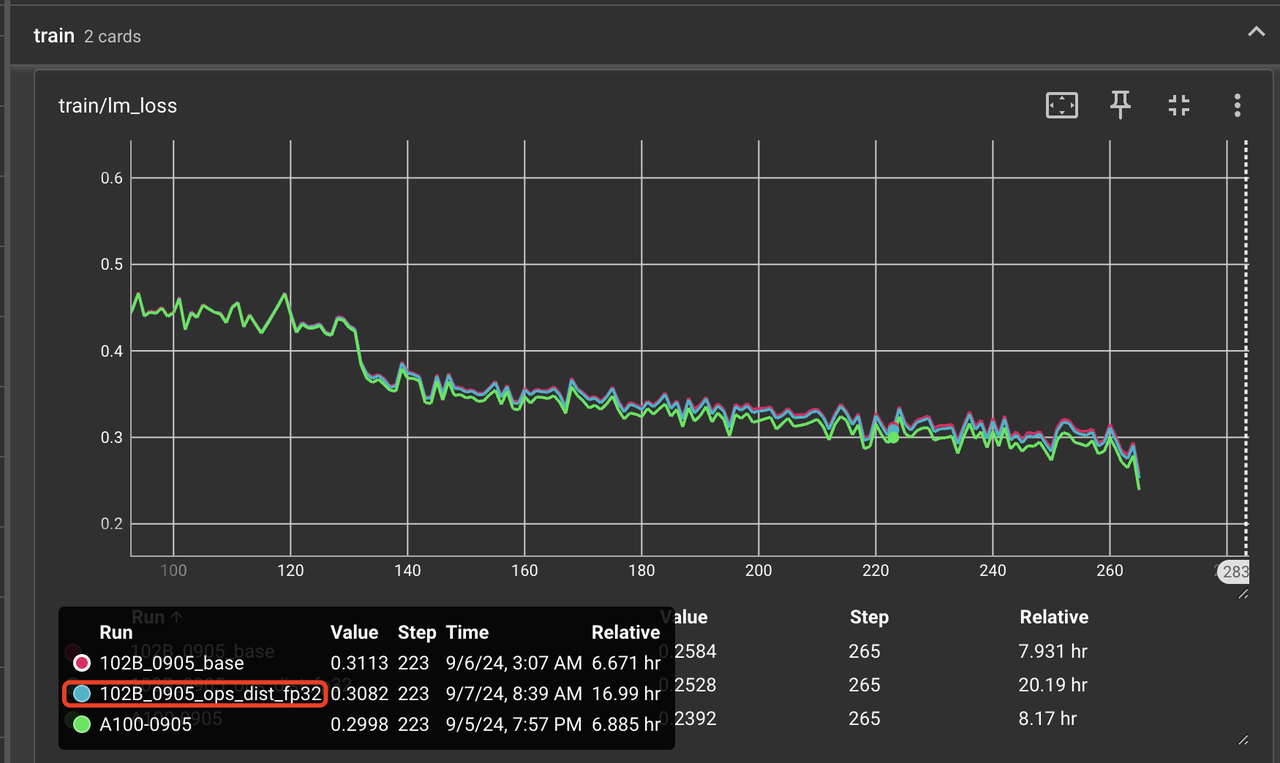
图 4: reduce 类的通信算子在使用 fp32 来计算后的 loss 曲线对比图。其中红色是 A2 原始曲线,蓝色是 reduce 类通信算子使用 fp32 后的曲线,绿色是 A100 的曲线。
2. 排查 PyTorch 的算子问题
我们将 adamw 算子使用非 fused 实现(因为工具暂无法支持 fused adamw 的精度自动对比),使用 ditorch 中算子对比工具排查一遍 PyTorch 算子,在设置 atol 和 rtol 为 1e-3 的情况下并未发现可疑算子。由于用户使用的是 fused adamw, 所以怀疑 fused adamw 可能存在问题,为此我们将微调时使用的 adamw 改为非 fused 实现,得到 loss 曲线如下如图 5。 从图 5 可以看出 loss 曲线在前几个 iter 已经和 A100 几乎完全一致。但是在 loss 曲线的后端依旧和 A100 对不齐,如图 6。 可见,adamw 的融合实现确实有问题,但是除此问题外应该还有其他算子问题。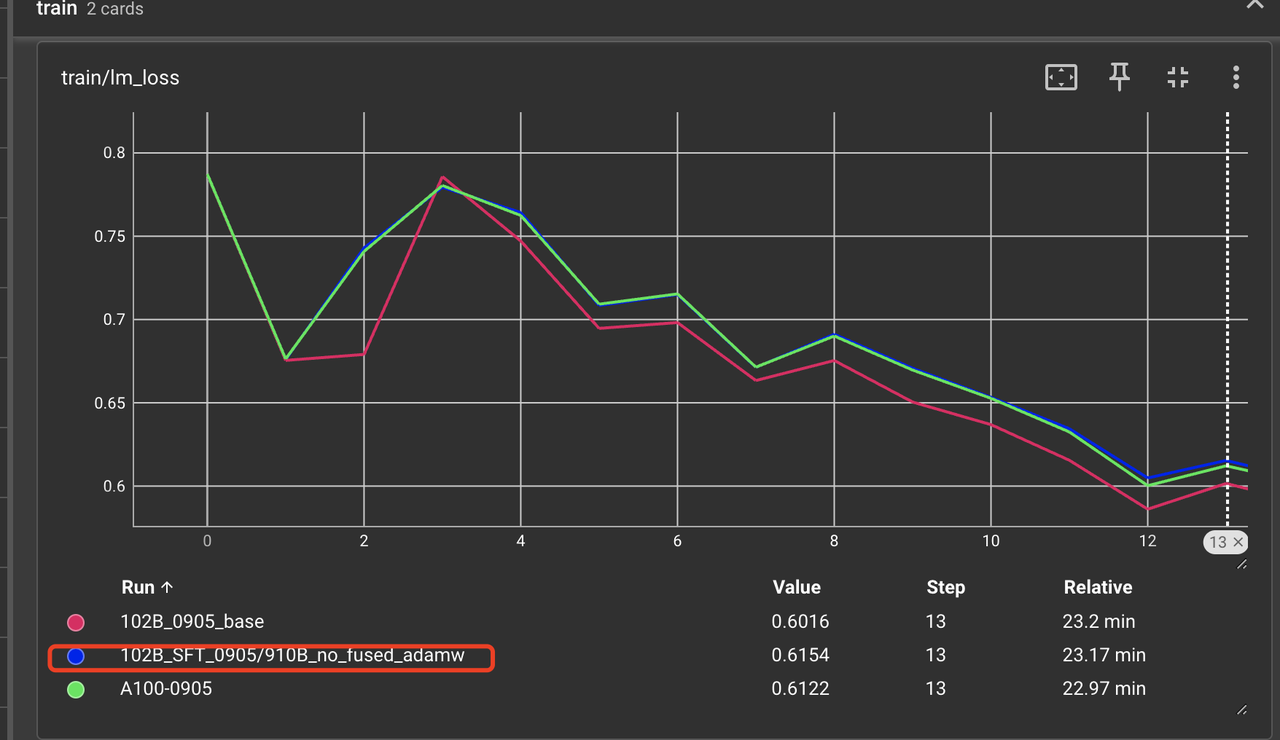
图 5:A2 上 adamw 不使用 fused 实现时,前 12 个 iter 下A2 和 A100 的 loss 曲线对比。
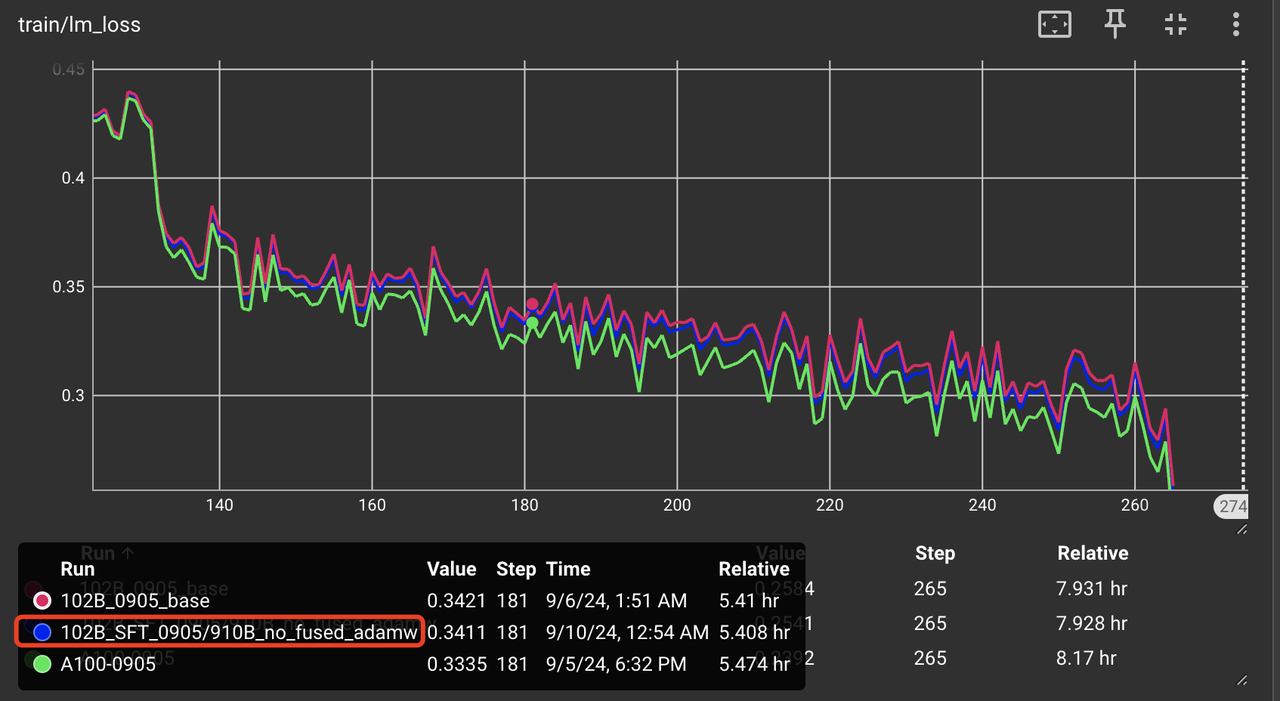
图 6:A2 上 adamw 不使用 fused 实现时,第 2 个 epoch 下 A2 和 A100 的 loss 曲线对比
3. 排查 PyTorch 外的扩展算子
考虑到 PyTorch 的算子都排查了一遍,怀疑剩下的问题可能是 PyTorch 外的扩展算子导致,比如 rms_norm、 rotary_embedding、flash attention。flash-attention 出问题的概率低,因为在昇腾上训练大模型时都会用到此算子。在当前场景中 rotary_embedding 使用的是组合实现,其用到的算子均为 PyTorch 自带算子,并且正确性已通过 ditorch 工具排查过。那么,自然还剩下一个 rms_norm 算子。难道是此算子出现了问题?
为此,我们将 rms_norm 换成了 apex 中的 PyTorch 组合实现,不使用昇腾提供的torch_npu.npu_rms_norm,得到如图 7 所示的微调 loss 曲线。从图中可以看出,A2 的 loss 曲线已经完全和 A100 对齐。并且后续对微调好的权重做了下游评测,发现平均得分已经基本和 CUDA 一致。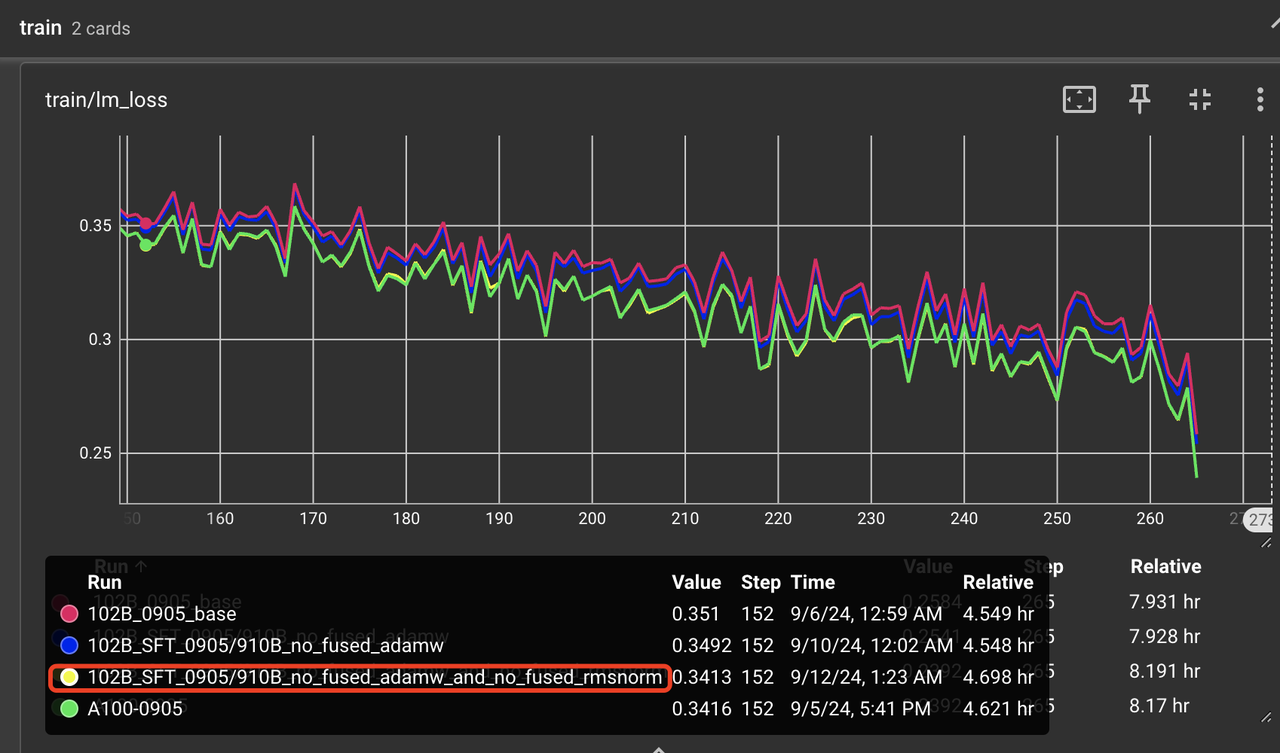
图 7:使用组合 rms_norm 后 loss 曲线在第 2 个 epoch 上的对比图。
我们将这两个问题提给了昇腾,并和昇腾算子专家研讨了解到:针对 adamw 算子,CANN 算子设计是需要兼容MindSpore、PyTorch、Paddle 等多种框架;昇腾的 CANN 底层的 adamw 融合算子实现,完全遵循 adamw 论文标准公式,算子并无精度问题;只是在适配 PyTorch时未和 PyTorch 对齐,PyTorch已在融合算子外部对 step 加了1,在适配torch._fused_adamw 时其内无需再加1(详见:adamw.py源代码)。此问题已经在 torch_npu 适配中修复。
而 rms_norm 问题在昇腾专家支持下,快速排查到是由于 kernel 在计算 pow、mean 和 sqrt 等时,虽依旧使用的是 fp32 计算,但为了和纯 GPU 的组合小算子在 bf16 上计算结果对齐,rms_norm 的实现在中间结果上转成了 bf16。此行为单看算子实现是无问题的,但在算法层面上 rms_norm 需要高精度计算,apex 以及 flash-attention仓库中的rms_norm 组合实现以及融合实现均为高精度实现。实验表明,在后续去除了中间结果转为 bf16 的逻辑后,此算子的计算精度已经对齐 CUDA。此问题也已经在 cann8.0.RC3 中修复。
3.3 其他尝试步骤
上面的排查过程是按照最顺利的方向进行,其实在排查过程中有很多其他的尝试,在此做下分享:
1. 将 layer_num 改为 1 层对比 loss 曲线。由于 102B 的微调需要的卡太多,且微调时间太长,导致实验的成本很高。所以曾尝试将模型的 layer_num 改为 1,即将模型砍为 1 层,然后对比A100和A2的 loss 曲线,看能否找出loss差距。但由于改成 1 层后模型的表示能力下降,且会减少误差的累计效应,对通过 loss 来排查算子精度问题虽有一定的帮助,但作用并不大。在 rms_norm 有精度问题的情况下,loss 曲线依旧是对齐的。
2. 将 layer_num 改为 1 层,使用 torch.nn.Module 级别的逐 module 层对比工具,跑 1 个 iter 然后逐 module 层对比和 CUDA 的计算结果。发现 module.3 层的输出结果在 atol 和 rtol 为 1e-3 的情况下,只有 0.026%的数据和 CUDA 的计算结果不 allclose。但下一层 module.5 却有 54.99%的数据和 CUDA 的计算结果不 allclose(module.4 为空,所以下一层是 moudle.5),因此怀疑是 module.5 内有计算错误。排查模型结构后,发现 module.5 正是 RMSNorm 层。这一结论和 3.2.3 部分中发现的“rms_norm 需要使用组合实现, loss 才能对齐”得出的结论是一致的,即 rms_norm 有精度问题。但这种方法对优化器算子的排查起不到作用,只能排查前向和反向所使用的算子。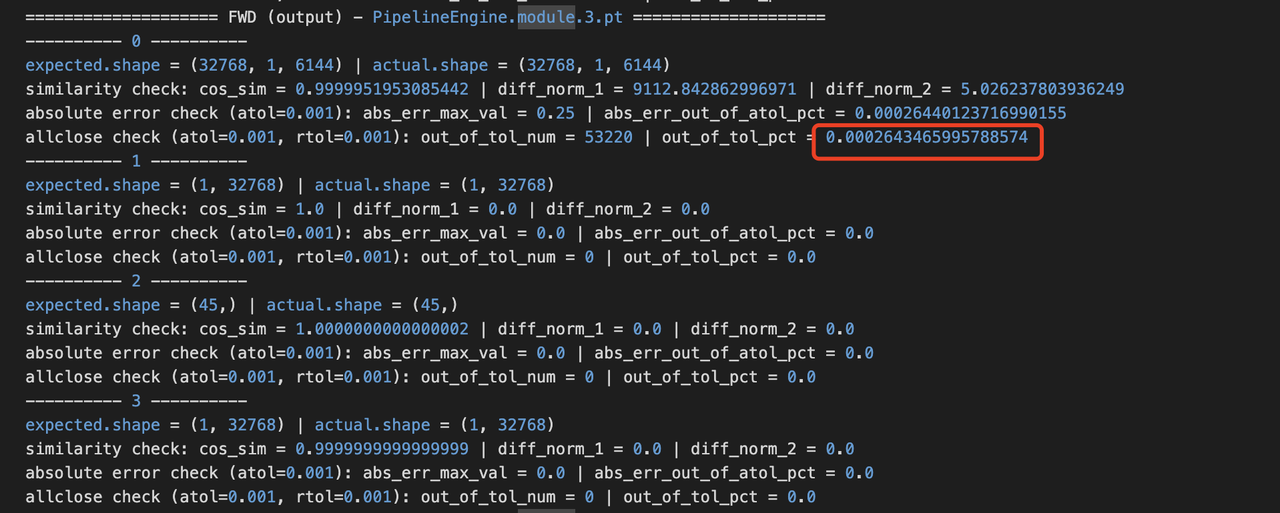

3. 在使用单算子精度自动对比工具( ditorch )检查 PyTorch 算子精度时,排查出 matmul、linear 等带有矩阵乘的算子,其计算误差会随矩阵大小的增大而增大。且自动对比工具的基准是 CPU 上的 fp32 的计算结果,所以几乎不可能和 CPU 的计算结果对齐,不过可以作为一个误差参考因素。为检验这类算子的正确性,我们在 Nvidia 设备上单独写测例对比 bf16 类型的矩阵乘误差。实验表明 bf16 的矩阵乘计算结果和 A100 的计算结果在 atol=1e-3,rtol=1e-3 下有 0.8%不 allclose。不过 NPU 和 CUDA 上结果对 fp32 的计算结果不 allclose 的比例均为21.51%,说明 CUDA 的 bf16 矩阵乘运算和 fp32 比也有较大的误差(虽然累加类型使用的是fp32)。值得注意的是,下游模型精度评测结果 NPU 和 CUDA 是对齐的。
总结
我们使用了逐算子、逐 module 层精度对比工具,以及 loss 曲线比对的方式,排查分析了大模型微调时下游评测精度在 A2 和 CUDA 对不齐的问题。经分析发现 fused adamw 和 rms_norm 存在精度问题,在使用非 fused adamw 和使用组合的 rms_norm 后,loss 曲线可以和 CUDA 对齐,且下游评测任务的平均得分和 CUDA 基本一样。
如果你喜欢我们的内容,欢迎赞同∆、收藏⭐️、关注➕我们!
也欢迎在评论区与我们互动!
你的支持是我们持续创作的动力!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)