一文带你无痛看懂AI大模型 !
本文系统介绍了大模型的基础原理与应用技术。首先梳理了人工智能知识体系,阐明大模型的训练三阶段(预训练、监督微调、RLHF)及其基于概率预测的核心机制。重点讲解了推理增强技术,包括提示工程(COT、TOT等方法)和推理框架(如Plan and Execute)。详细解析了RAG技术的工作流程、常见问题及评估指标。最后引入Agent概念,指出其作为大模型与记忆、工具、规划能力的结合体。全文以通俗语言阐
本文适合入门,想对大模型有初步了解的,涵盖了其原理和核心机制,还有最近很火的Agent。自学然后整合的,纯手搓。
一、大模型原理
1. 关系图谱
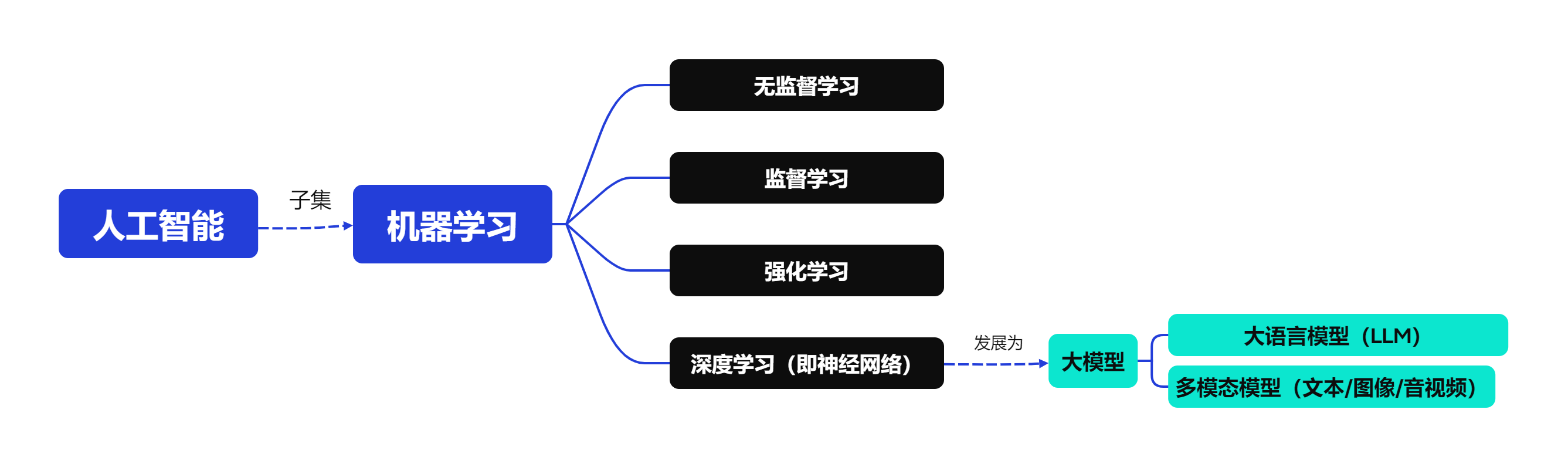
初学者可能人工智能、机器学习、深度学习傻傻分不清楚,一张图带你看懂:
2. 大模型训练过程
![]()
预训练:用海量无标注数据来训练大模型;
监督微调:用标注好的数据来微调;
RLHF:基于人类反馈的强化学习。通过人类对大模型的回答打分,让大模型的生成往人类偏好方向靠近。
3. 大模型特点
- 参数量大,规模大
- 预训练需要广泛数据集
- 适应性、灵活性强,可跨领域迁移
- 计算资源需求大
4. 大模型核心原理
基于概率的预测推理,根据给定文本预测下一个token(即“分词”)。
核心架构是Transformer的解码器,具体介绍详见合集的上一篇:小白友好 | 挑战主流神经网络最快入门
二、推理增强
推理增强是为了增强大模型推理能力的方法,包括推理提示和推理框架。
1. 推理提示
基于用户输入的提示方法,也可理解为提示词工程。
1.1 Prompt
- 零样本提示(Zero-Shot):提示词中不含回答示例。
- 少样本提示(Few-Shot):提示词中含少量回答示例,让模型学习示例进行输出。
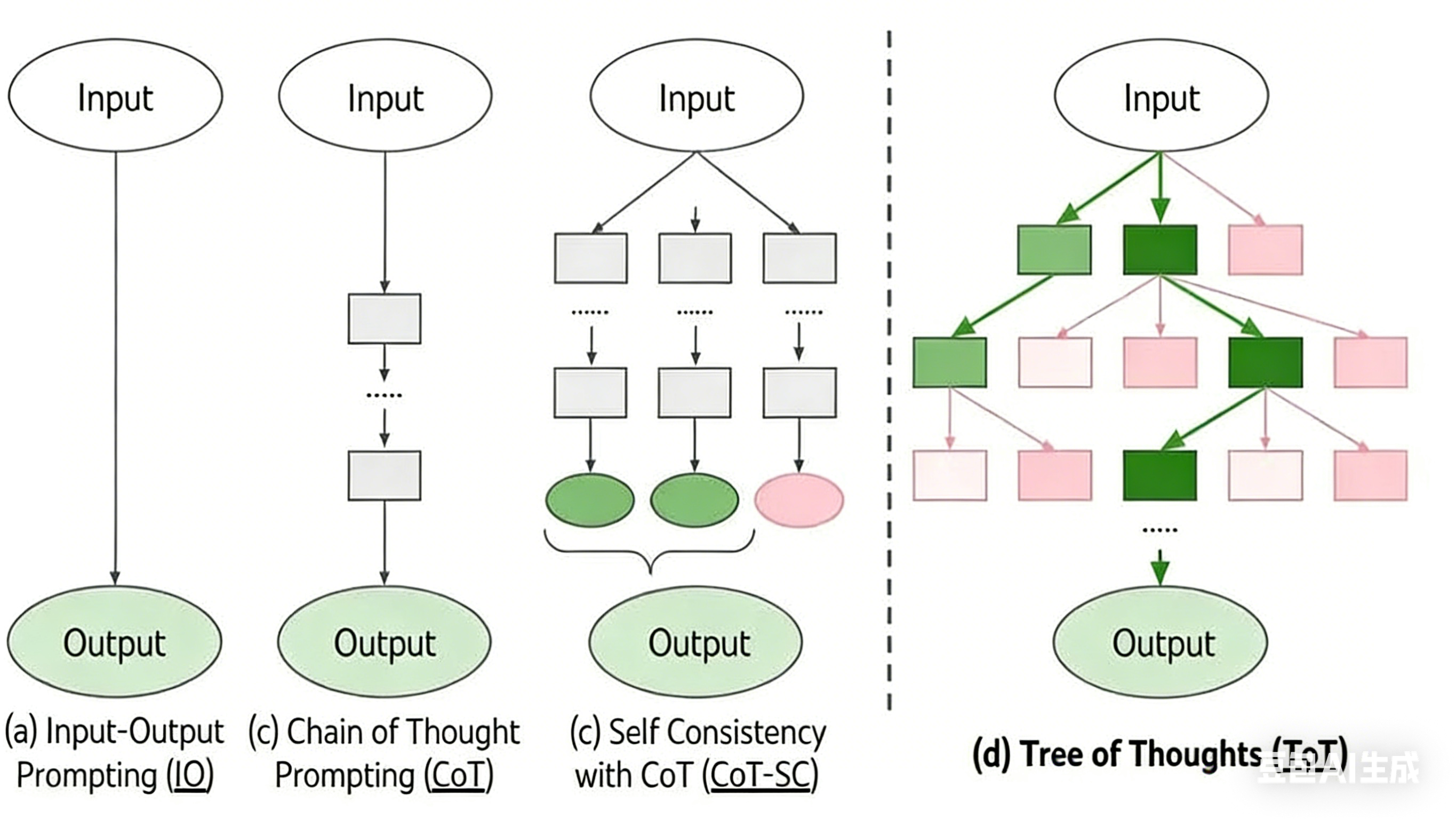
1.2 思维链(COT,Chain of Thought)
分步推理。将问题拆解成一步一步的中间小步骤,教AI一步步地思考。
1.3 自洽思维链(COT-SC,Chain of Thought with Self-Consistency)
同一个问题用思维链的方式问多次,最终选取占多数的答案。
1.4 思维树(TOT,Tree of Thought)
针对问题生成多个可能的推理路径(树状结构),大模型可平行探索不同分支并评估,选取最优。
下图展示了COT/COT-SC/TOT的结构:
1.5 LTM(Least to Most)
从简单到复杂、从易到难拆解问题,引导大模型先解决问题的 “子问题”,再基于子问题的答案,逐步推导最终的复杂问题答案。
2. 推理框架
基于工具或系统的推理方法,是一套完整的架构或工具集合。
| 推理框架 | 内容 |
| Reasoning and Acting | 推理,再调用工具执行 |
| Plan and Execute | 生成多步计划,再分步执行 |
| Self-Ask | 连续提问拆解问题 |
| Thinking and Self-Refection | 回答后主动检查(幻觉风险最低) |
三、RAG(Retrieval-Augmented Generation,检索增强生成)
1. 核心原理
通过检索外部数据,增强大模型的生成效果。
查询和检索到的“上下文”都会注入到大模型的Prompt中。
注意区分“微调”:微调是用一定量数据集对大模型进行局部参数的调整。
2. RAG工作流程

- 检索知识库:将文本分割并编码成向量,形成向量数据库;再将输入问题转换为向量,检索向量相似性;
- 文本分割:按句子/字符数/转义符号/滑动窗口+固定字符数/递归(基于分隔符反复拆分直至token数符合要求)等方式对文本分割;
- 向量相似性:由欧式距离、余弦距离计算
- 向量检索:按关键字、语义等对向量进行检索
- 向量持久化:将向量数据保存到磁盘或云存储中,断网也能用。
3. RAG痛点问题及解决方法
3.1 文本向量化过程
| 问题 | 解决方法 | 补充说明 |
|
内容缺失 (找不到答案) |
增加相应知识库; 数据清洗与增强; 优化Prompt |
数据增强:不加新数据,对现有数据加工,以提升模型泛化能力和鲁棒性 |
| 文档加载准确性和效率低 |
优化文档读取器; 数据清洗与增强 |
针对不同文档设计专门的读取器 |
| 文档切分粒度不当 |
固定长度分块; 滑动窗口分块; 基于文档结构分块; 基于递归分块 |
不同的嵌入模型有最优分块大小; 处理长篇和复杂信息,较大分块; 处理社交媒体信息,较小分块 |
3.2 检索增强回答过程
| 问题 | 解决方法 |
|
错过排名靠后的文档 |
增加召回数量(不推荐); 重排(先检索top N个,对这几个重排,选取其中k个) |
| 提取的上下文与答案无关 | 同“内容缺失”、“错过排名靠后”的文档 |
|
格式错误/ 答案不完整/ 未提取到答案 |
优化Prompt |
4. RAG评估指标
| 评估方面 | 评估指标 | 补充说明 |
| 检索质量 |
上下文相关性 召回率 |
召回率:衡量是否找全相关内容 (注意区分“精确率”,精确率衡量有无找错) |
| 生成质量 |
忠实性 答案相关性 |
忠实性:生成的是否遵循检索出来的内容 |
四、Agent 智能体
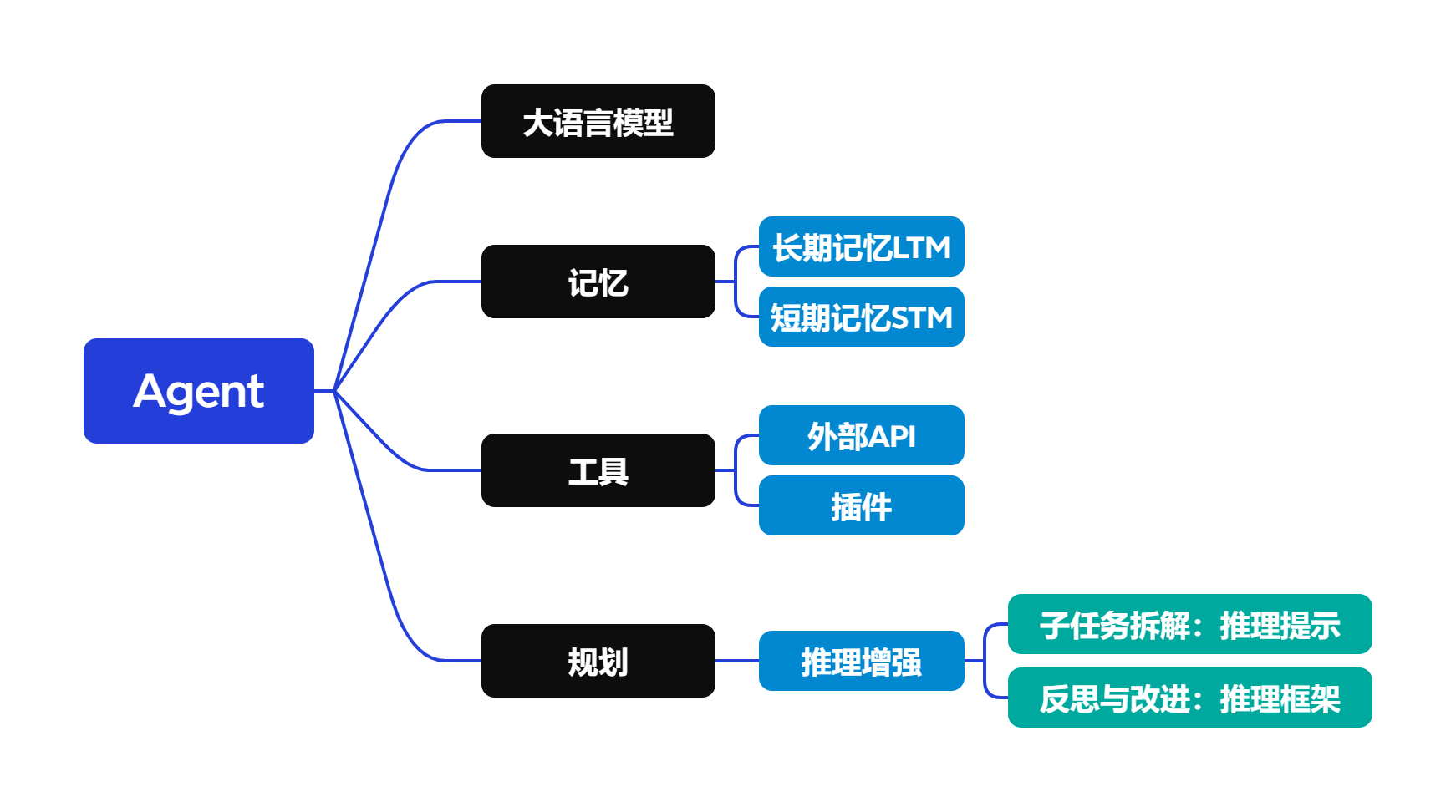
Agent=大语言模型+记忆+工具使用+推理规划

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)