Agent研究学习【Coze、LangChain4j与LangGraph4j】
Agent研究学习【Coze、LangChain4j与LangGraph4j】
前言
在AI应用开发领域,LangChain4j和LangGraph4j是两个强大的Java框架,它们为开发者提供了构建复杂AI应用的能力。LangChain4j专注于与大语言模型的交互,而LangGraph4j则提供了工作流编排能力。
coze
扣子是新一代 AI 应用开发平台,借助扣子提供的可视化设计与编排工具,可以通过零代码或低代码的方式,快速搭建出基于大模型的各类 AI 项目,满足个性化需求。
基于Coze打造一个“自动笑话生成并存入文档”的小助手:
- 调用大模型:让AI创作一个原创的、简短的笑话
- 自动存文档:把这个笑话自动保存到一个新的在线文档里
- 返回链接:把这个保存了笑话的文档链接返回给用户
工作流搭建如下图: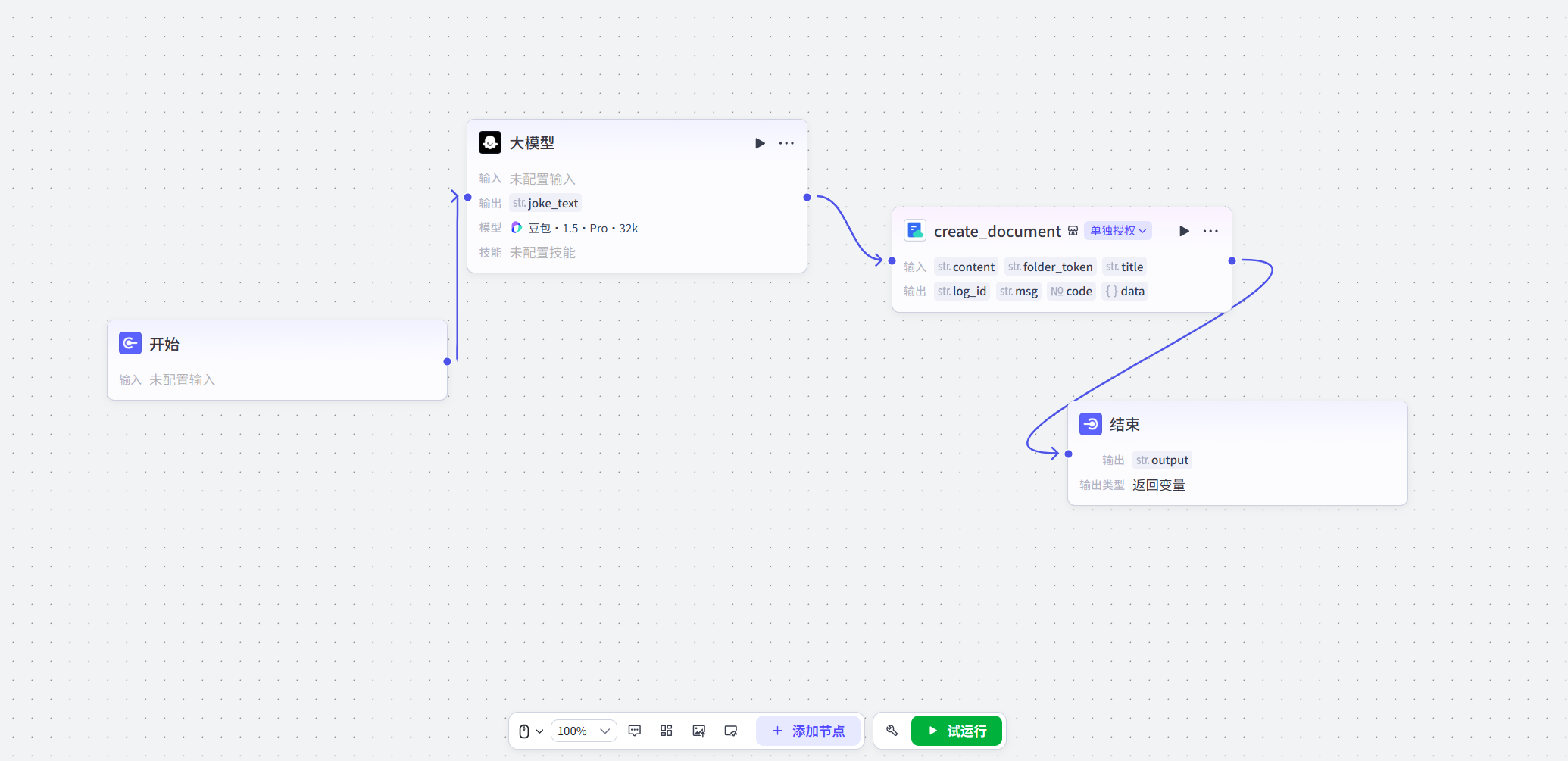
运行结果如下图:

RAG流程
检索增强生成(RAG)是一项结合了信息检索与自然语言生成的前沿技术,旨在显著提升大语言模型(LLM)的输出质量,使其回答不仅更准确,也更具关联性。
核心工作机制:
- 数据增强:RAG通过为模型引入外部知识源(如私有数据库、实时信息或模型训练截止日期之后的新数据),有效扩展了大语言模型的固有知识边界,弥补了其依赖静态训练数据的局限性。
- 检索阶段:从指定的外部知识库中精准检索与用户查询最相关的信息片段。
- 生成阶段:大语言模型基于检索到的补充信息,结合原有知识,生成最终的自然语言回答。
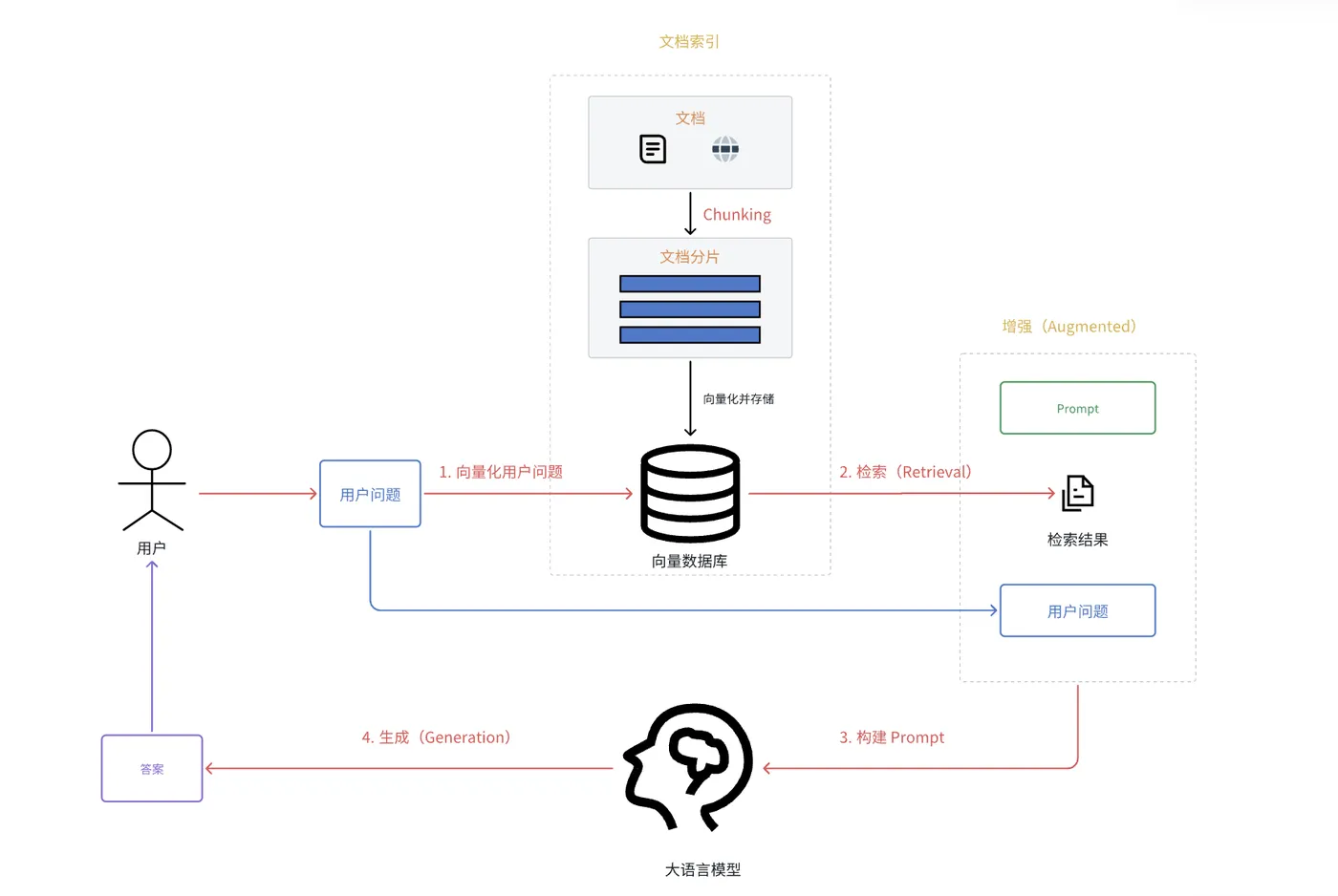
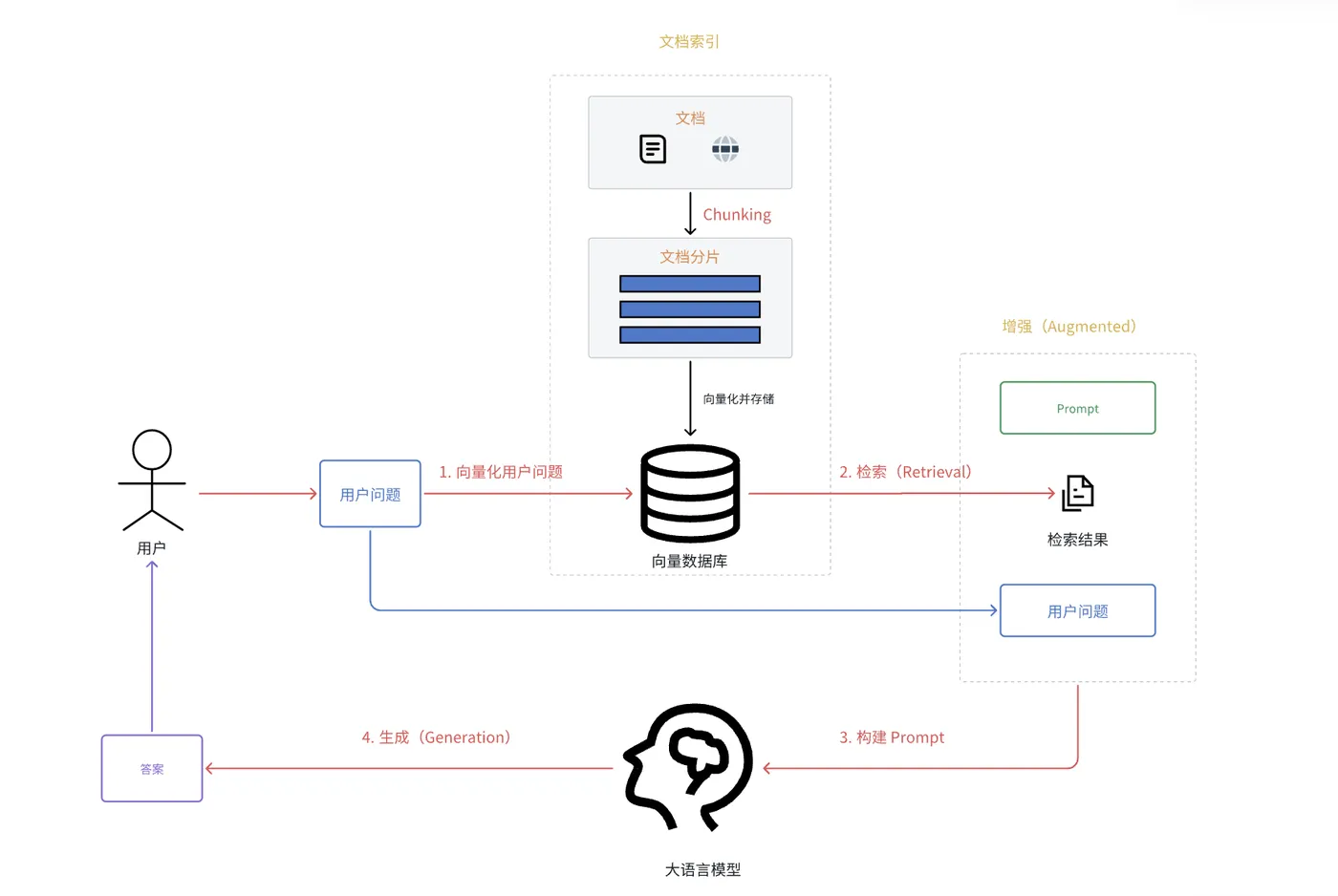
其核心工作流程如下:
-
索引 (Indexing) - 离线准备阶段
这是一个从原始数据构建可搜索知识库的管道(pipeline),通常预先离线完成。
它包含三个关键步骤:
加载(Load):使用文档加载器(Document Loaders) 从各类数据源(如文档、数据库)中加载原始数据。
分割(Split):使用文本分割器(Text Splitters) 将大型文档拆分成更小的语义块(chunks)。
存储(Store):将分割后的文本块转化为向量(使用嵌入模型 / Embeddings model),并存入向量数据库(VectorStore) 中建立索引,以便后续进行高效的相似性检索。 -
检索和生成 (Retrieval and Generation) - 在线运行阶段
这是在用户提问时实时运行的RAG链,主要步骤如下:
检索(Retrieval):当接收到用户查询时,系统将其转化为向量,并从已构建的向量数据库中检索出最相关的若干文本块。
生成(Generation):将原始的用户查询和检索到的相关文本一同作为上下文,提交给大语言模型(LLM),模型基于这些补充信息,生成更准确、更具上下文的最终答案。
LangChain4j
LangChain4j 的目标是简化在 Java 应用中集成大语言模型(LLM)的过程。
参考链接:LangChain4j官方文档
- 统一 API:
各类 LLM 提供商(如 OpenAI、Google Vertex AI)以及向量数据库(如 Pinecone、Milvus)通常采用各自的专有 API。LangChain4j 提供了统一的 API,使您无需为每个服务单独学习和实现其 API。在尝试不同的 LLM 或向量数据库时,您可以轻松切换,无需重写代码。LangChain4j 目前已支持 15+ 主流 LLM 提供商 和 20+ 向量数据库。 - 全面工具箱:
自 2023 年初以来,社区开发了大量基于 LLM 的应用,逐渐沉淀出常见的抽象、模式和方法。LangChain4j 将这些内容整合成一个开箱即用的工具包。工具箱涵盖从底层的提示模板、聊天记忆管理、函数调用,到高层的 Agents 和 RAG 等模式。每个抽象都配备接口和多种常用实现,便于直接使用。无论是开发聊天机器人,还是构建涵盖数据导入到检索的完整 RAG 流程,LangChain4j 都能提供丰富选择。
LangGraph4j
LangGraph4J是一个专门为Java生态设计的智能体工作流框架。它借鉴了Python中LangGraph的成功经验,但与LangChain4J和Spring AI等主流Java LLM框架深度集成,让Java开发者能够轻松构建复杂的多智能体系统。不再需要手动管理各个智能体之间的状态传递和协作逻辑,而是通过可视化的方式定义整个工作流程。这正是LangGraph4J的核心价值所在——降低AI应用开发门槛,提升开发效率。
参考链接:LangGraph4j简介
一、技术栈概览
1.1 核心依赖
使用以下核心依赖:
<!-- LangChain4j 核心库 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.1.0</version>
</dependency>
<!-- LangChain4j Spring Boot Starter -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.1.0-beta7</version>
</dependency>
<!-- LangChain4j 响应式支持 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.1.0-beta7</version>
</dependency>
<!-- 阿里云通义千问集成 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
<version>1.1.0-beta7</version>
</dependency>
<!-- LangGraph4j 核心库 -->
<dependency>
<groupId>org.bsc.langgraph4j</groupId>
<artifactId>langgraph4j-core</artifactId>
<version>1.6.0-beta6</version>
</dependency>
<!-- LangGraph4j 与 LangChain4j 集成 -->
<dependency>
<groupId>org.bsc.langgraph4j</groupId>
<artifactId>langgraph4j-langchain4j</artifactId>
<version>1.6.0-beta6</version>
</dependency>
1.2 配置文件
在 application.yml 中配置通义千问模型:
langchain4j:
community:
dashscope:
chat-model:
model-name: qwen-max
api-key: your-api-key-here
streaming-chat-model:
model-name: qwen-max
api-key: your-api-key-here
embedding-model:
model-name: text-embedding-v4
api-key: your-api-key-here
二、LangChain4j 核心功能实现
LangChain4j 的目标是简化将 LLM 集成到 Java 应用程序中的过程,官方文档:
LangChain4j官方文档
2.1 定义AI服务接口
LangChain4j 的核心思想是通过接口定义AI服务,使用注解来配置系统提示词和用户消息。
package com.example.service;
import dev.langchain4j.service.MemoryId;
import dev.langchain4j.service.Result;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import reactor.core.publisher.Flux;
public interface AiCodeHelperService {
/**
* 中文造句服务
* 使用同步方式返回结果
*/
@SystemMessage("你是一位专业的中文语言教师,专注于用给定词汇创作自然、地道的例句。\n" +
"- 用户会提供一个中文单词,你需要根据该词语的常用含义和语境,生成一个典型的中文例句。\n" +
"- 句子长度适中,结构完整,符合日常交流或书面表达习惯。\n" +
"- 若词语有多义项,选择最常用的义项进行造句。\n" +
"- 只需输出句子本身,无需额外解释。")
Result<String> chatPrompt(@MemoryId int memoryId, @UserMessage String userMessage);
/**
* 代码助手服务
* 使用流式响应,支持实时输出
*/
@SystemMessage("你是资深的一名后端开发工程师,帮助用户编写需求代码")
Flux<String> chat(@MemoryId int memoryId, @UserMessage String userMessage);
/**
* 中英翻译服务
* 将中文句子翻译成英文
*/
@SystemMessage("你是一位专业的中英翻译官,擅长将中文句子准确、流畅地翻译成英文。\n" +
"- 用户会提供一句中文句子,你需要将其翻译成英文。\n" +
"- 翻译需符合英文表达习惯,用词自然、语法正确,同时尽量保留原句的语境和情感色彩。\n" +
"- 只需输出英文翻译,无需额外说明或注释。")
Result<String> chat1(@MemoryId int memoryId, @UserMessage String userMessage);
}
关键注解说明:
@SystemMessage:定义系统提示词,用于设定AI的角色和行为规范@UserMessage:标记用户输入的消息参数@MemoryId:用于区分不同的会话,实现多会话管理Result<String>:同步返回结果,包含完整的响应内容Flux<String>:响应式流式返回,支持实时输出(SSE)
2.2 配置AI服务工厂
通过配置类创建AI服务实例,集成记忆管理、RAG检索等功能。
package com.example.config;
import com.example.service.AiCodeHelperService;
import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.chat.StreamingChatModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.service.AiServices;
import jakarta.annotation.Resource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class AiCodeHelperServiceFactory {
@Resource
private ContentRetriever contentRetriever;
@Resource
private ChatModel qwenChatModel;
@Resource
private StreamingChatModel qwenStreamingChatModel;
@Bean
public AiCodeHelperService aiCodeHelperService() {
return AiServices.builder(AiCodeHelperService.class)
// 同步聊天模型
.chatModel(qwenChatModel)
// 流式聊天模型
.streamingChatModel(qwenStreamingChatModel)
// 会话记忆提供者:每个会话独立存储最近10条消息
.chatMemoryProvider(memoryId ->
MessageWindowChatMemory.withMaxMessages(10))
// RAG 检索增强生成
.contentRetriever(contentRetriever)
.build();
}
}
核心配置说明:
-
ChatModel vs StreamingChatModel:
ChatModel:同步模型,等待完整响应后返回StreamingChatModel:流式模型,支持实时输出,适合长文本生成
-
ChatMemoryProvider:
- 为每个会话(memoryId)创建独立的记忆存储
MessageWindowChatMemory.withMaxMessages(10):保留最近10条对话记录- 实现上下文感知对话
-
ContentRetriever:
- RAG(检索增强生成)的核心组件
- 从知识库中检索相关内容,增强AI回答的准确性
2.3 RAG检索增强生成配置
RAG是提升AI回答质量的关键技术,通过检索相关文档来增强生成效果。
package com.example.config;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.document.splitter.DocumentByParagraphSplitter;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import jakarta.annotation.Resource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
@Configuration
public class RagConfig {
@Resource
private EmbeddingModel qwenEmbeddingModel;
@Resource
private EmbeddingStore<TextSegment> embeddingStore;
@Bean
public ContentRetriever contentRetriever() {
// 1. 加载文档:从指定目录加载所有文档
List<Document> documents = FileSystemDocumentLoader
.loadDocuments("src/main/resources/docs");
// 2. 文档切割:将文档按段落分割
// 参数1:每个片段最大1000字符
// 参数2:片段之间重叠200字符(避免语义断裂)
DocumentByParagraphSplitter paragraphSplitter =
new DocumentByParagraphSplitter(1000, 200);
// 3. 文档摄取器:将文档转换为向量并存储
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(paragraphSplitter)
// 为每个文本片段添加文件名元数据,提高检索质量
.textSegmentTransformer(textSegment -> TextSegment.from(
textSegment.metadata().getString("file_name") + "\n"
+ textSegment.text(),
textSegment.metadata()
))
// 使用通义千问的向量模型
.embeddingModel(qwenEmbeddingModel)
// 向量存储(可以是内存、Redis、Elasticsearch等)
.embeddingStore(embeddingStore)
.build();
// 执行文档摄取
ingestor.ingest(documents);
// 4. 创建内容检索器
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(qwenEmbeddingModel)
.maxResults(5) // 最多返回5个相关片段
.minScore(0.80) // 相似度阈值:过滤低相关性结果
.build();
}
}
RAG工作流程:
- 文档加载:从文件系统加载Markdown、TXT等文档
- 文档切割:将长文档切分为小片段,便于检索
- 向量化:使用Embedding模型将文本转换为向量
- 存储:将向量存储到向量数据库
- 检索:用户提问时,将问题向量化,检索最相关的文档片段
- 增强:将检索到的内容作为上下文,与用户问题一起发送给LLM
2.4 Controller层实现
提供RESTful API接口,支持流式和非流式两种响应方式。
package com.example.controller;
import com.example.service.AiCodeHelperService;
import jakarta.annotation.Resource;
import org.springframework.http.codec.ServerSentEvent;
import org.springframework.web.bind.annotation.*;
import reactor.core.publisher.Flux;
@RestController
@RequestMapping("/api/ai")
public class AiController {
@Resource
private AiCodeHelperService aiCodeHelperService;
/**
* 流式聊天接口
* 使用SSE(Server-Sent Events)实现实时响应
*
* @param memoryId 会话ID,用于区分不同用户或会话
* @param message 用户输入的消息
* @return 流式响应,前端可以实时显示生成内容
*/
@GetMapping("/chat")
public Flux<ServerSentEvent<String>> chat(int memoryId, String message) {
return aiCodeHelperService.chat(memoryId, message)
.map(chunk -> ServerSentEvent.<String>builder()
.data(chunk)
.build());
}
}
流式响应的优势:
- 用户体验好:内容逐字显示,类似ChatGPT的效果
- 降低等待时间:用户无需等待完整响应
- 适合长文本:生成长文本时不会超时
前端调用示例(JavaScript):
const eventSource = new EventSource('/api/ai/chat?memoryId=1&message=你好');
eventSource.onmessage = (event) => {
// 实时接收并显示每个文本片段
console.log(event.data);
document.getElementById('response').innerHTML += event.data;
};
eventSource.onerror = () => {
eventSource.close();
};
三、LangGraph4j 工作流编排
LangGraph4j 提供了强大的工作流编排能力,可以将多个AI任务串联成复杂的处理流程。
LangGraph4J是一个专门为Java生态设计的智能体工作流框架。它借鉴了Python中LangGraph的成功经验,但与LangChain4J和Spring AI等主流Java LLM框架深度集成,让Java开发者能够轻松构建复杂的多智能体系统。
核心概念理解
StateGraph:这是你定义应用结构的主要类,通过添加节点和边来创建图结构。
AgentState:代表图的共享状态,是一个可传递的状态容器,每个节点都可以读取和更新它。
节点与边:节点执行具体操作,边定义控制流在节点间的传递路径。
3.1 定义工作流状态
工作流状态用于在不同节点之间传递数据。
package com.example.entity;
import lombok.Data;
import org.bsc.langgraph4j.state.AgentState;
import java.util.HashMap;
import java.util.Map;
/**
* 提示词优化工作流状态
* 继承自AgentState,用于在工作流节点间传递数据
*/
@Data
public class PromptWorkflowState extends AgentState {
public PromptWorkflowState(Map<String, Object> initData) {
super(initData);
}
public PromptWorkflowState() {
super(new HashMap<>());
}
// 用户原始输入(例如:一个中文单词)
public String getUserInput() {
return (String) data().get("userInput");
}
public void setUserInput(String userInput) {
data().put("userInput", userInput);
}
// 优化后的提示词(例如:用该单词造的句子)
public String getOptimizedPrompt() {
return (String) data().get("optimizedPrompt");
}
public void setOptimizedPrompt(String optimizedPrompt) {
data().put("optimizedPrompt", optimizedPrompt);
}
// AI 生成的最终回答(例如:句子的英文翻译)
public String getAnswer() {
return (String) data().get("answer");
}
public void setAnswer(String answer) {
data().put("answer", answer);
}
}
3.2 实现工作流服务
构建一个完整的工作流,实现"单词造句→翻译成英文"的流程。
package com.example.service;
import com.example.entity.PromptWorkflowState;
import dev.langchain4j.service.Result;
import lombok.extern.slf4j.Slf4j;
import org.bsc.langgraph4j.CompiledGraph;
import org.bsc.langgraph4j.GraphStateException;
import org.bsc.langgraph4j.StateGraph;
import org.springframework.stereotype.Service;
import jakarta.annotation.Resource;
import java.util.Map;
import java.util.Optional;
import static org.bsc.langgraph4j.StateGraph.END;
import static org.bsc.langgraph4j.StateGraph.START;
import static org.bsc.langgraph4j.action.AsyncNodeAction.node_async;
/**
* 提示词优化工作流服务
* 演示如何使用LangGraph4j构建多步骤AI工作流
*/
@Slf4j
@Service
public class PromptWorkflowService {
@Resource
private AiCodeHelperService aiCodeHelperService;
/**
* 执行提示词优化工作流
*
* 工作流程:
* 1. 接收用户输入(一个中文单词)
* 2. 使用AI生成包含该单词的例句
* 3. 将例句翻译成英文
*
* @param memoryId 会话ID
* @param userInput 用户输入的单词
* @return 包含完整处理结果的状态对象
*/
public PromptWorkflowState executeWorkflow(int memoryId, String userInput)
throws GraphStateException {
// 构建工作流图
StateGraph<PromptWorkflowState> workflow =
new StateGraph<>(PromptWorkflowState::new)
// ========== 节点1: 开始节点 ==========
// 接收并保存用户输入
.addNode("start", node_async(state -> {
log.info("工作流开始,用户输入: {}", state.getUserInput());
state.setUserInput(userInput);
return Map.of("userInput", userInput);
}))
// ========== 节点2: 提示词优化节点 ==========
// 使用AI将单词转换为完整句子
.addNode("optimizePrompt", node_async(state -> {
log.info("开始优化提示词...");
String word = state.getUserInput();
// 调用AI服务生成例句
Result<String> result = aiCodeHelperService.chatPrompt(
memoryId, word);
String sentence = result.content();
state.setOptimizedPrompt(sentence);
log.info("优化后的提示词: {}", sentence);
return Map.of("optimizedPrompt", sentence);
}))
// ========== 节点3: 生成答案节点 ==========
// 将中文句子翻译成英文
.addNode("generateAnswer", node_async(state -> {
log.info("开始生成最终答案...");
String sentence = state.getOptimizedPrompt();
// 调用翻译服务
Result<String> result = aiCodeHelperService.chat1(
memoryId, sentence);
String translation = result.content();
state.setAnswer(translation);
log.info("最终答案: {}", translation);
return Map.of("answer", translation);
}))
// ========== 定义边(节点之间的连接) ==========
.addEdge(START, "start") // 开始 -> start节点
.addEdge("start", "optimizePrompt") // start -> 优化提示词
.addEdge("optimizePrompt", "generateAnswer") // 优化提示词 -> 生成答案
.addEdge("generateAnswer", END); // 生成答案 -> 结束
// 编译工作流
CompiledGraph<PromptWorkflowState> compiledWorkflow = workflow.compile();
// 初始化状态
PromptWorkflowState initialState = new PromptWorkflowState();
initialState.setUserInput(userInput);
// 执行工作流
Optional<PromptWorkflowState> result = compiledWorkflow.invoke(initialState);
return result.orElseThrow(() ->
new RuntimeException("工作流执行失败"));
}
}
工作流执行流程图:
用户输入(单词)
↓
[start节点] - 保存输入
↓
[optimizePrompt节点] - AI生成例句
↓
[generateAnswer节点] - AI翻译成英文
↓
返回结果
关键概念说明:
- StateGraph:工作流图的核心类,用于定义节点和边
- addNode:添加工作流节点,每个节点执行特定任务
- node_async:异步节点动作,支持异步操作
- addEdge:定义节点之间的连接关系
- compile:编译工作流图,生成可执行的工作流
- invoke:执行工作流,传入初始状态

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)