能源AI挑战赛(电池异常检测)霸榜第二名方案分享
·
在刚刚结束的“vLoong能源AI挑战赛——异常检测赛”的一轮提交中,我们团队取得了 0.7492 的成绩,暂列榜首。本文将复盘我们的比赛思路:如何从官方 Baseline 的 0.56 AUC 提升至 0.74+。与其使用复杂的 大模型+微调或深度学习模型,我们发现扎实的统计特征工程 + 模型融合才是处理此类工业时序数据的“大杀器”。感兴趣参与的朋友可以私信联系。
1. 赛题背景与数据分析
比赛目标:根据新能源车辆电池的充电数据(电压、电流、温度等),判断该数据片段是否存在异常(故障)。
数据格式:
- 输入:
.pkl文件,每个文件包含(256, 8)的时序数据。 - 维度:256个时间步,8个特征(电压、电流、SOC、最高/低单体电压、最高/低温度、时间戳)。
- 标签:0(正常)/ 1(异常)。
官方 Baseline 的痛点:
官方提供的 Paddle 示例代码使用的是 AutoEncoder(自编码器),但它有一个致命弱点:只取了滑窗的最后一个时间点数据。
这种做法完全丢失了电池充电过程中的变化趋势(如电压突降、温度急升),导致 AUC 只有 0.56 左右,基本等同于瞎猜。
2. 核心提分策略:时序特征统计化
既然数据是短周期的时序数据(256步),且物理含义明确。我们不需要动用 Transformer 这种重型武器,而是将时序信息压缩为统计特征。
我们为每一个物理量(如电压、温度)构建了以下特征组:
- 基础统计:均值 (
mean)、标准差 (std)、最大值 (max)、最小值 (min)。 - 极差:
max - min,反映波动范围。 - 趋势特征:
diff_mean(一阶差分的均值),这非常关键,它代表了变化率。例如,电池短路往往伴随着电压的剧烈变化率。 - 终值:保留最后一个点的值(保留 Baseline 的有效部分)。
通过这种方式,我们将 (256, 7) 的矩阵转换为了 (1, 7 * 7) = 49 维的表格数据,完美适配树模型。
3. 模型架构:XGBoost + KNN 的强强联手
我们没有使用深度学习,而是选择了传统的机器学习强分类器。
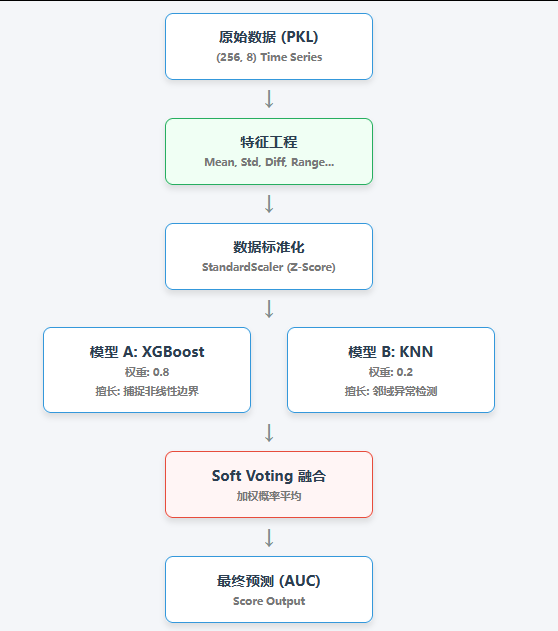
3.1 方案架构图
(这是为你生成的架构图,请截图使用)
3.2 为什么选这两个模型?
- XGBoost (权重 0.8):
- 表格数据竞赛的王者。
- 使用
scale_pos_weight参数处理了正负样本不平衡(正常数据远多于异常数据)。 - 树模型对特征的数值幅度不敏感,鲁棒性强。
- KNN (权重 0.2):
- 异常检测的直觉:异常点通常在空间中远离正常簇,或者形成了独立的小簇。KNN 基于距离度量,能提供与树模型完全不同的视角。
- 注意:使用 KNN 必须先对数据进行
StandardScaler归一化,否则大数值特征(如电压)会掩盖小数值特征(如变化率)。
5. 总结与思考
- 不要迷信深度学习:在数据量(几万条)和特征维度(7维)相对有限,且物理规律清晰的场景下,手动特征工程+梯度提升树往往比 RNN/LSTM 效果更好,且训练速度快几个数量级。
- 数据清洗的重要性:比赛中我们发现 KNN 对数据尺度极其敏感,加入
StandardScaler后,模型融合效果提升了显著的百分点。 - 融合的艺术:XGBoost 关注“切分”,KNN 关注“距离”。两者的错误模式不同,融合后能有效降低方差,提升 AUC。
下一步计划:
目前的方案仅使用了统计特征,未来可以尝试引入 TsFresh 提取更复杂的时序特征(如傅里叶变换系数),或者使用 CatBoost 处理潜在的类别信息,冲击更高的分数。
私信联系博主购买车票组队上车获取AI比赛前三名机会!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)