RAG(检索增强生成)架构与原理:告别LLM“幻觉”的秘密武器
RAG(检索增强生成)是一种优化大语言模型输出的技术,通过从外部知识库检索相关信息作为上下文输入,显著提高回答的准确性、可靠性和时效性。其工作流程分为检索(数据准备、嵌入、向量存储)和生成(上下文整合、LLM生成)两个阶段,能有效缓解LLM的幻觉问题。RAG具有提高准确性、增强可靠性、降低成本等优势,但也面临检索质量、分块策略等挑战。目前主流开源实现方案包括LangChain、LlamaIndex
什么是RAG?
检索增强生成(Retrieval Augmented Generation,简称RAG)是一种优化大型语言模型(LLM)输出的技术。它通过在生成响应之前,从外部权威知识库中检索相关信息,并将其作为上下文提供给LLM,从而提高LLM回答的准确性、可靠性和时效性,同时有效缓解LLM可能出现的“幻觉”问题。
RAG的工作原理
RAG的工作流程通常分为两个主要阶段:检索阶段和生成阶段。
1. 检索阶段 (Retrieval Phase)
在检索阶段,RAG模型会根据用户的查询(Query)或问题,从预先构建的知识库中检索出最相关的文档或信息片段。这个阶段的关键步骤包括:
-
数据准备与索引 (Data Preparation & Indexing):
-
数据摄取 (Data Ingestion):从各种数据源(如文档、数据库、网页等)收集原始数据。
-
文本分块 (Text Chunking):将长文本分割成更小的、有意义的片段(chunks)。这有助于提高检索的粒度,并确保每个片段都能被有效地嵌入。
-
嵌入 (Embedding):使用嵌入模型(Embedding Model)将文本片段转换为高维向量(embeddings)。这些向量能够捕捉文本的语义信息,使得语义相似的文本在向量空间中距离更近。
-
向量存储 (Vector Storage):将生成的向量存储到向量数据库(Vector Database)中。向量数据库针对高效的相似性搜索进行了优化。
-
-
查询处理与相似性搜索 (Query Processing & Similarity Search):
-
当用户提出查询时,同样的嵌入模型会将查询转换为向量。
-
然后,这个查询向量会在向量数据库中进行相似性搜索,找出与查询向量最接近(即语义最相关)的文本片段。
-
检索到的文本片段将作为后续生成阶段的上下文信息。
-
2. 生成阶段 (Generation Phase)
在生成阶段,大型语言模型(LLM)会利用检索阶段获得的上下文信息,结合原始的用户查询,生成最终的回答。这个阶段包括:
-
上下文整合 (Context Integration):将检索到的相关文本片段与原始用户查询一起,构建成一个增强的提示(Prompt)。这个提示通常会明确指示LLM基于提供的上下文进行回答。
-
LLM生成 (LLM Generation):LLM接收增强后的提示,并根据其内部知识和提供的外部上下文信息生成回答。由于LLM现在有了额外的、相关且权威的信息作为参考,它能够生成更准确、更少“幻觉”的回答。
RAG如何解决LLM的“幻觉”问题?
大型语言模型在训练过程中可能会“编造”信息,即产生“幻觉”(Hallucination),给出听起来合理但实际上不准确或不真实的内容。RAG通过以下方式有效缓解这一问题:
-
引入外部知识源:RAG的核心在于将LLM的知识范围扩展到其训练数据之外的实时或特定领域的数据。这意味着LLM不再仅仅依赖其内部参数中固化的知识,而是可以访问和利用最新的、经过验证的信息。
-
提供事实依据:通过检索阶段,RAG为LLM提供了生成回答所需的事实依据。LLM被“锚定”在这些检索到的信息上,从而减少了其“自由发挥”和产生不准确信息的可能性。
-
可追溯性:RAG系统通常可以指出其回答所依据的原始文档或信息来源,这大大增加了回答的可信度和可追溯性。用户可以验证信息的真实性,这对于需要高准确性的应用场景(如医疗、法律、金融)至关重要。
-
实时性与更新:LLM的训练数据通常是静态的,无法及时反映最新信息。RAG通过连接到可实时更新的知识库,确保LLM能够访问到最新的数据,从而避免因信息过时而产生的错误。
RAG的优势
-
提高准确性:通过提供外部事实依据,显著减少LLM的幻觉,提高回答的准确性。
-
增强可靠性:答案基于可验证的外部知识,增加了系统的可靠性和可信度。
-
降低成本:无需对LLM进行昂贵的再训练或微调,即可使其适应新数据或特定领域知识。
-
实时性:能够利用最新信息,解决LLM知识滞后的问题。
-
可解释性:可以追溯答案的来源,提高系统的透明度。
RAG的挑战
-
检索质量:检索到的信息质量直接影响生成结果。不相关的或低质量的检索结果可能导致生成内容不佳。
-
分块策略:如何有效地将文档分块,既能保留上下文,又能适应LLM的输入限制,是一个挑战。
-
向量数据库选择与管理:选择合适的向量数据库,并进行有效的索引和管理,需要专业知识。
-
多模态RAG:处理图片、视频等非文本数据,并进行有效检索和生成,是未来的发展方向和挑战。
RAG整体架构图
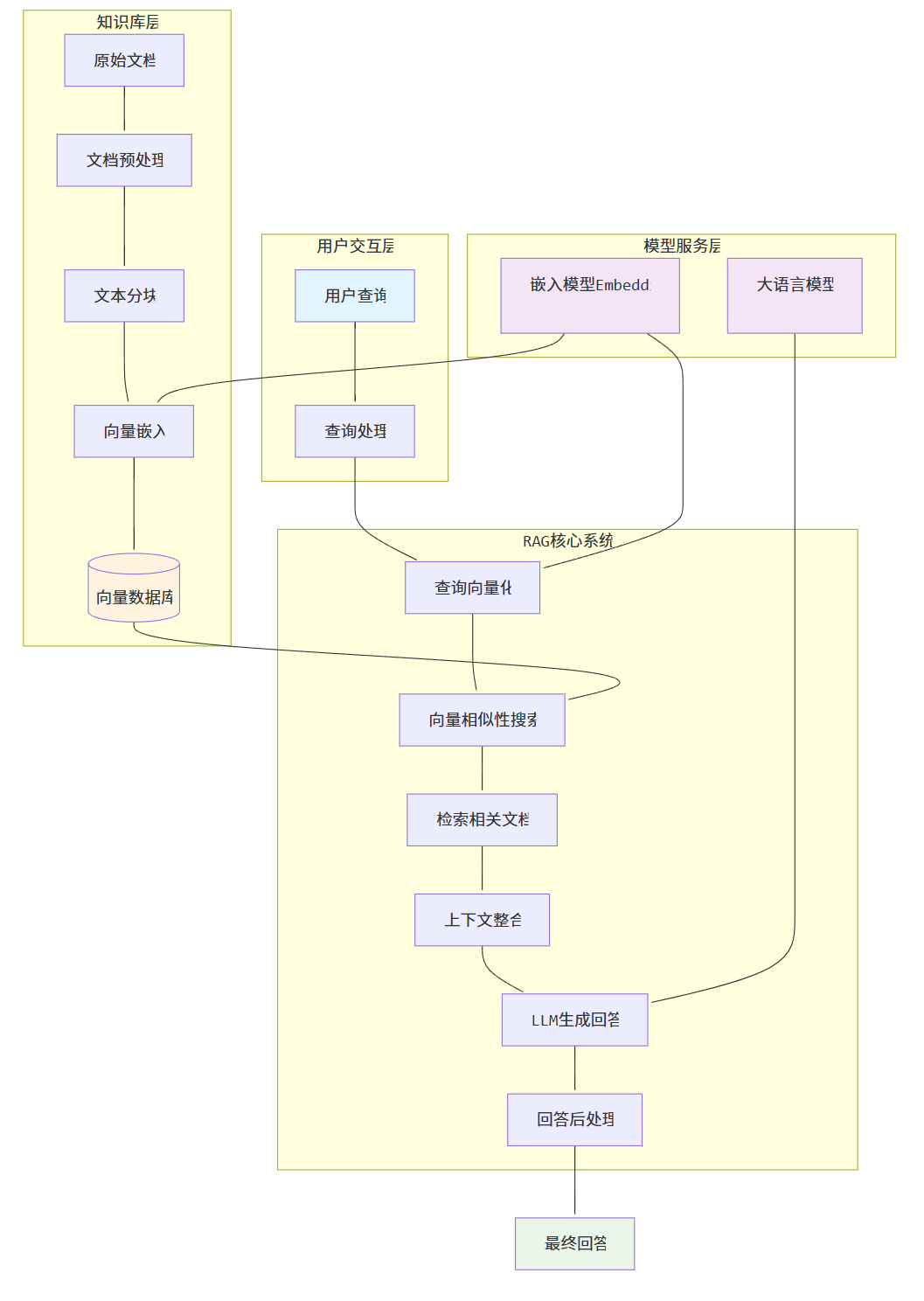
主流开源RAG实现方案
随着RAG技术的日益成熟,许多优秀的开源框架和库应运而生,极大地降低了RAG应用的开发门槛。这些框架通常提供了一系列模块化的组件,涵盖了RAG工作流的各个环节,从数据加载、文本处理、向量嵌入到检索和LLM集成。以下是目前最受欢迎的几个开源RAG框架:
1. LangChain
LangChain是一个功能强大的框架,旨在帮助开发者构建端到端的LLM应用。它提供了丰富的模块和工具,使得RAG的实现变得简单高效。LangChain的核心概念包括:
-
模型(Models):支持各种LLM和聊天模型。
-
提示(Prompts):用于构建和管理LLM的输入提示。
-
索引(Indexes):用于结构化文档,以便LLM可以与它们交互。这包括文档加载器、文本分割器、向量存储和检索器。
-
链(Chains):将多个组件组合在一起,形成一个完整的应用逻辑,例如检索问答链。
-
代理(Agents):允许LLM根据工具的描述自主决定采取哪些行动。
LangChain的优势在于其高度的模块化和灵活性,开发者可以根据自己的需求选择和组合不同的组件。它支持与多种向量数据库(如Chroma、FAISS、Pinecone等)和嵌入模型(如OpenAI Embeddings、Hugging Face Embeddings等)的集成。
2. LlamaIndex
LlamaIndex(原名GPT Index)是一个专注于将外部数据源连接到LLM的框架。它提供了一套全面的工具,用于数据摄取、索引构建、查询和检索。LlamaIndex的特点在于其对数据源的广泛支持和灵活的索引策略,能够帮助开发者轻松地为LLM构建定制化的知识库。
LlamaIndex的主要组件包括:
-
数据连接器(Data Connectors):用于从各种数据源(如文件、数据库、API等)加载数据。
-
文档(Documents):表示加载的数据。
-
节点(Nodes):文档的原子单位,通常是文本块或结构化数据。
-
索引(Indexes):将节点组织成可查询的结构,例如向量索引、树索引、列表索引等。
-
查询引擎(Query Engines):用于接收用户查询,通过索引检索相关信息,并将其传递给LLM生成回答。
LlamaIndex在处理非结构化数据和构建复杂知识图谱方面表现出色,是构建高级RAG应用的理想选择。
3. Dify
Dify是一个开源的LLM应用开发平台,它融合了Backend-as-a-Service和LLMOps的理念,旨在简化生成式AI应用的开发和运营。Dify提供了可视化的Prompt编排、RAG管道、Agent工作流、数据集管理等功能,使得开发者可以快速构建和部署生产级的RAG应用。其RAG功能特点包括:
-
可视化RAG管道:Dify将RAG管道的各个环节可视化,提供友好的用户界面,方便用户管理知识库、文档和数据源。
-
多种数据源支持:支持从多种数据源摄取数据,并进行文本分块、嵌入和向量存储。
-
Agentic AI工作流:支持构建Agentic AI应用,结合RAG能力,实现更复杂的任务和决策。
-
易于集成:提供丰富的API和SDK,方便将RAG能力集成到现有应用中。
Dify适用于希望通过低代码/无代码方式快速构建和管理RAG应用的团队和个人。
4. FastGPT
FastGPT是一个基于LLM的知识库问答系统,提供开箱即用的数据处理、模型调用、RAG检索和可视化AI工作流编排能力。它旨在帮助用户快速构建专属的AI知识库和智能问答系统。FastGPT的RAG功能特点包括:
-
开箱即用:提供数据处理、模型调用、RAG检索等一站式能力,简化RAG应用的开发流程。
-
可视化工作流:通过Flow可视化编排,用户可以自由组合各种功能节点,实现复杂的问答场景。
-
知识库管理:支持多种知识库创建方式,包括手动输入、QA拆分、直接分段和CSV导入等,方便用户管理和优化知识库内容。
-
API集成:提供OpenAPI功能,方便开发者将FastGPT的RAG能力集成到自己的应用中。
FastGPT适用于需要快速构建和部署基于知识库的智能问答系统,并希望通过可视化界面进行管理的场景。
5. Haystack
Haystack是Deepset公司开发的一个开源NLP框架,专注于构建生产级的搜索系统和问答系统。它提供了灵活的管道(Pipelines)机制,允许开发者组合不同的组件来构建RAG应用。Haystack的组件包括:
-
文档存储(Document Stores):用于存储文档,支持多种后端(如Elasticsearch、FAISS、Pinecone等)。
-
检索器(Retrievers):用于从文档存储中检索相关文档,支持BM25、DPR、Embedding Retriever等多种检索算法。
-
阅读器(Readers):用于从检索到的文档中提取精确的答案。
-
生成器(Generators):用于生成自然语言回答。
Haystack的优势在于其强大的搜索能力和对生产环境的优化,适合构建高性能的RAG系统。
6. RAGFlow
RAGFlow是一个端到端的开源RAG引擎,旨在提供一站式的RAG解决方案。它特别强调深度文档理解能力,能够有效地处理各种格式的文档,并从中提取高质量的信息。RAGFlow的特点包括:
-
智能文档解析:支持OCR、表格识别、图片理解等功能,能够从复杂文档中准确提取内容。
-
多种分块策略:提供多种文本分块模板,并支持可视化编辑,方便用户根据文档特性进行优化。
-
内置向量数据库:简化了部署和管理。
-
用户友好的界面:提供了Web界面,方便用户进行文档管理、知识库构建和问答测试。
RAGFlow适用于需要处理大量复杂文档,并希望快速构建RAG应用的场景。
这些开源框架为开发者提供了丰富的工具和灵活的选项,使得RAG技术的应用变得更加便捷和高效。在实际项目中,开发者可以根据具体需求和技术栈选择最适合的框架进行开发。
代码示例
为了更好地理解RAG的实际应用,我们将通过LangChain和LlamaIndex这两个主流框架,展示如何构建一个简单的RAG系统。请注意,以下代码示例需要您配置OpenAI API Key才能运行。
LangChain RAG示例
首先,确保您已安装LangChain和OpenAI库:
pip install langchain langchain-community langchain-openai然后,创建一个名为langchain_rag_example.py的文件,并将以下代码复制进去。请将YOUR_OPENAI_API_KEY替换为您的实际OpenAI API Key。
import os
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain_community.llms import OpenAI
# 设置OpenAI API Key
# os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# 1. 加载文档
# 为了演示方便,这里直接创建一个data.txt文件
withopen("data.txt", "w", encoding="utf-8") as f:
f.write("RAG(Retrieval Augmented Generation)是一种优化大型语言模型(LLM)输出的技术。它通过在生成响应之前,从外部权威知识库中检索相关信息,并将其作为上下文提供给LLM,从而提高LLM回答的准确性、可靠性和时效性,同时有效缓解LLM可能出现的“幻觉”问题。RAG的工作流程通常分为两个主要阶段:检索阶段和生成阶段。检索阶段包括数据准备与索引、查询处理与相似性搜索。生成阶段包括上下文整合和LLM生成。LangChain和LlamaIndex是流行的RAG开源框架。")
loader = TextLoader("data.txt", encoding="utf-8")
documents = loader.load()
# 2. 分割文本
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 3. 创建嵌入并存储到向量数据库
# 注意:这里需要有效的OpenAI API Key
embeddings = OpenAIEmbeddings()
db = Chroma.from_documents(texts, embeddings)
# 4. 创建检索器
retriever = db.as_retriever()
# 5. 创建RAG链
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
# 6. 提问
query = "RAG的工作流程是怎样的?"
print(qa.run(query))
query = "RAG解决了LLM的什么问题?"
print(qa.run(query))运行此脚本,您将看到RAG系统根据提供的文档内容回答问题。
LlamaIndex RAG示例
首先,确保您已安装LlamaIndex和OpenAI库:
pip install llama-index openai然后,创建一个名为llama_index_rag_example.py的文件,并将以下代码复制进去。请将YOUR_OPENAI_API_KEY替换为您的实际OpenAI API Key。
import os
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
# 设置OpenAI API Key
# os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# 1. 加载文档
# 确保data.txt文件存在,内容与LangChain示例相同
documents = SimpleDirectoryReader(input_files=["data.txt"]).load_data()
# 2. 创建嵌入模型和LLM
embed_model = OpenAIEmbedding()
llm = OpenAI()
# 3. 创建索引并存储到向量数据库 (默认使用内存中的SimpleVectorStore)
index = VectorStoreIndex.from_documents(documents, embed_model=embed_model)
# 4. 创建查询引擎
query_engine = index.as_query_engine(llm=llm)
# 5. 提问
query = "RAG的工作流程是怎样的?"
response = query_engine.query(query)
print(response)
query = "RAG解决了LLM的什么问题?"
response = query_engine.query(query)
print(response)运行此脚本,您将看到LlamaIndex系统根据提供的文档内容回答问题。
最后的总结
RAG技术通过将外部知识检索与大型语言模型相结合,为解决LLM的“幻觉”问题和知识滞后性提供了有效的途径。它不仅提高了LLM回答的准确性和可靠性,还降低了模型训练和维护的成本。随着RAG技术的不断发展和完善,以及更多开源框架的涌现,RAG将在未来的AI应用中扮演越来越重要的角色,为各行各业带来更智能、更可靠的解决方案。
零基础入门AI大模型必看
也陆陆续续也整理了不少资源,希望能帮大家少走一些弯路!
无论是学业还是事业,都希望你顺顺利利 !
1️⃣ 大模型入门学习路线图(附学习资源)
2️⃣ 大模型方向必读书籍PDF版
3️⃣ 大模型面试题库
4️⃣ 大模型项目源码
5️⃣ 超详细海量大模型LLM实战项目
6️⃣ Langchain/RAG标题一/Agent学习资源
7️⃣ LLM大模型系统0到1入门学习教程
8️⃣ 吴恩达最新大模型视频+课件


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)