论文阅读:IJACI 2025 Hallucination Reduction in Video-Language Models via Hierarchical Multimodal Consist
该文档是一篇发表于IJCAI-25的研究论文,核心聚焦于视频-语言模型(VLMs)中的幻觉问题,提出了多层多模态对齐(MMA)框架及两阶段训练策略,以提升模型语义一致性并减少幻觉。该研究通过语义对齐与两阶段训练,从根源缓解了VLMs的幻觉问题,同时提升了长视频理解与视频问答的准确性,为视频分析、多模态学习等领域的实际应用提供了更可靠的技术支撑。通过文本语义监督与多层对齐,强化视觉与文本模态的语义一
总目录 大模型相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
Hallucination Reduction in Video-Language Models via Hierarchical Multimodal Consistency
https://www.ijcai.org/proceedings/2025/1019.pdf
https://www.doubao.com/chat/35768888149032194
速览
该文档是一篇发表于IJCAI-25的研究论文,核心聚焦于视频-语言模型(VLMs)中的幻觉问题,提出了多层多模态对齐(MMA)框架及两阶段训练策略,以提升模型语义一致性并减少幻觉。
一、研究背景与问题
- VLMs的应用与挑战:视频-语言模型(VLMs)融合视觉编码器与大型语言模型(LLMs),可处理视频描述、视觉问答等多模态任务,但存在严重的“幻觉问题”——生成内容与视频实际信息不符,源于两方面核心缺陷:
- 语义辨别能力不足,无法准确理解视觉概念间的语义关系;
- 训练数据集规模小、多样性有限且样本分布不均衡,导致模型偏向预测常见物体及其共现组合。
- 现有方法局限:现有解决方案包括清洁数据集微调、跨模态模块设计、输出后处理等,但多忽视模态间的语义对齐,且存在资源消耗大、可扩展性差等问题。
二、核心方法:多层多模态对齐(MMA)框架
1. 核心设计思路
通过文本语义监督与多层对齐,强化视觉与文本模态的语义一致性,结合两阶段训练拓展语义多样性,从根源减少幻觉。
2. 关键组件
- 视觉特征提取:采用预训练视觉编码器(如ViT-G/14)提取视频帧特征,通过Q-Former与长期记忆库存储帧级特征和查询特征,捕捉视频时序动态与历史信息。
- 文本语义注入:引入BERT作为文本编码器,将文本提示与标签拼接后提取语义特征,通过语义辨别损失(InfoNCE形式),使视觉与文本特征在公共语义空间对齐,提升视觉编码的语义辨别力。
- 多层对齐策略:在视觉与文本模态的多个层级(如Q-Former输出特征、交叉注意力输入特征)进行语义对齐,既捕捉低层级(物体颜色、形状)又捕捉高层级(事件流、人物关系)语义关系,建立视频内容与生成语言的精准对应。
3. 两阶段训练策略
- 辅助预训练阶段:使用大规模多样化数据集(如WebVid-5K),仅通过语义辨别损失训练Q-Former与文本编码器,学习视觉-语言的通用语义关系,奠定泛化基础。
- 任务特定训练阶段:在下游任务数据集(如LVU、MSVD)上,结合语义辨别损失与文本解码损失(交叉熵)微调,冻结LLM参数,实现从通用语义到任务特定语义的渐进式学习。
三、实验结果
1. 数据集与配置
- 数据集:采用LVU(3万+长视频片段)和MSVD(2000+视频片段+12万句描述),覆盖长视频理解、视频问答任务。
- 模型配置:视觉编码器为EVA-CLIP的ViT-G/14,LLM采用Vicuna-7B,训练于4台V100 GPU。
2. 核心性能
- 长视频理解(LVU数据集):平均Top-1准确率达65.0%,较当前最优模型MA-LMM提升2.0%,在内容关系、场景识别、导演/类型预测等子任务中均表现最优。
- 视频问答(MSVD数据集):准确率达60.9%,超越MA-LMM(60.6%)及Video-LLaMA等模型,验证了多层对齐对任务理解与物体描述的提升。
- 消融实验:多层对齐策略使性能提升3.3%,结合两阶段训练后进一步提升4.4%,证明两者协同有效性;多层对齐优于单层级对齐,且无需增加帧采样数量即可获得性能增益。
3. 定性结果
模型能准确识别视频类型(喜剧)、人物关系(朋友)、场景(办公室),有效捕捉复杂语义,显著减少幻觉生成。
四、研究贡献
- 提出多层多模态对齐策略,在视觉编码阶段融入文本语义监督,解决VLMs的语义对齐不足问题。
- 设计两阶段训练,利用大规模数据集拓展语义多样性,实现通用到特定任务的渐进式学习。
- 在多个视频-语言任务中实现SOTA性能,为高可靠多模态系统提供新基准。
五、结论
该研究通过语义对齐与两阶段训练,从根源缓解了VLMs的幻觉问题,同时提升了长视频理解与视频问答的准确性,为视频分析、多模态学习等领域的实际应用提供了更可靠的技术支撑。
通过分层多模态一致性降低视频-语言模型的幻觉
Jisheng Dang(1;2;3),Shengjun Deng(4),Haochen Chang(2),Teng Wang(5),Bimei Wang(6;3,*),Shude Wang(7),Nannan Zhu(2),Guo Niu(4),Jingwen Zhao(2),Jizhao Liu(1)
1 Lanzhou University, Gansu, China
2 Sun Yat-sen University, Guangdong, China
3 National University of Singapore, Singapore
4 Foshan University, Guangdong, China
5 The University of Hong Kong, China
6 Jinan University, Guangdong, China
7 Lanzhou Institute of Technology, Gansu, China
dangjsh@mail2.sysu.edu.cn, wangbm@stu2021.jnu.edu.cn
* 通讯作者
摘要
大型语言模型(LLMs)的快速发展推动了视频-语言模型(VLMs)在诸多领域的广泛应用。然而,VLMs 往往受限于语义判别能力不足,而这一问题又因多数视频-语言数据集的多样性不足及样本分布偏置而进一步加剧。该限制会导致模型对视觉概念间语义关系的理解出现偏差,从而产生“幻觉”(hallucination)。为应对这一挑战,我们提出多层次多模态对齐(Multi-level Multimodal Alignment, MMA)框架:利用文本编码器与语义判别损失(semantic discriminative loss)实现多层次对齐,使模型同时捕获低层与高层语义关系,以降低幻觉。通过在训练过程中引入语言层面的对齐,我们的方法在视频与文本模态之间建立更强的语义一致性。此外,我们提出两阶段渐进训练策略,借助规模更大且更丰富的数据集增强语义对齐能力,更好地捕获视觉与文本模态之间的一般语义关系。大量实验表明,所提出的 MMA 方法能够显著缓解幻觉,并在多项视频-语言任务上达到最先进性能,为该领域树立新的基准。
1 引言
近年来,大型语言模型(LLMs)的迅猛发展显著推动了视频-语言模型(VLMs)的进步。通过将视觉编码器与 LLMs 结合,VLMs 能够处理多种复杂的多模态任务,例如视频描述(video captioning)[Li et al., 2023a]、视觉问答(visual question answering)[Yang et al., 2022]、视频编辑(video editing)[Dang et al., 2024c; Dang et al., 2023a; Dang et al., 2024a; Dang et al., 2024b]、图像/视频分类(image or video classification)[Li et al., 2024; Ma et al., 2024b; Meng et al., 2024; Wang et al., 2024; Meng et al., 2025]。这些模型融合了先进的视觉与语言技术,能够更准确、更具上下文感知地理解视频内容。
然而,视频-语言模型的发展面临一个关键挑战:幻觉。所谓幻觉,是指模型生成的内容无法反映视频中的真实信息,导致编造或错误的描述。
当前研究从多个角度尝试缓解视觉-语言模型的幻觉问题。有些工作通过清洗数据集并进行指令微调来提升推理表现[Ma et al., 2024a],但这种方法代价高昂。也有方法设计跨模态模块来弥合模态差距,例如可学习接口(learnable interfaces)[Liu et al., 2024]以及 Q-Former[Li et al., 2023a]。此外,一些模型通过后处理[Yin et al., 2024]或改进解码策略[Leng et al., 2024]直接纠正输出中的幻觉。
但上述许多方法忽视了模态间语义对齐的重要性。多数视觉编码器主要依赖语言生成损失进行训练,学习生成对显著物体、动作与场景的描述性字幕。这种训练方式限制了视觉表征的判别性,因为模型缺少对“概念的负样本”进行学习的机会。我们认为幻觉主要来自两类核心问题:(a) 语义判别能力不足,难以准确理解视觉概念之间的语义关系;(b) 下游数据集通常规模较小、样本多样性有限且分布不均,导致模型倾向于预测常见物体及其高频共现关系。
为解决上述问题,我们提出一种多层次多模态对齐(MMA)策略:在视觉编码阶段引入文本语义监督以增强中间视觉特征,并结合最终的语言监督,引导模型生成更准确且与上下文一致的输出。具体而言,我们使用文本编码器将文本输入转换为语义特征,并通过语义判别损失实现视觉与文本模态对齐。不同于仅使用全局表征的对齐方式,我们在多个层次执行对齐,使模型能够同时捕获高层与低层语义关系,从而通过建立视频内容与生成语言之间更精确的对应关系来降低幻觉。
为进一步增强语义对齐,我们引入两阶段渐进训练策略:利用更大且更多样的数据集扩展语义特征的覆盖范围,更好地捕获视觉与文本模态之间的一般语义关系。通过将更丰富的语义信息注入模型并持续细化对齐过程,我们显著降低了歧义,并在多种视频-语言任务上提升性能。
大量实验表明,我们的方法在降低幻觉、提升多模态对齐以及总体性能方面均优于现有模型。结果表明,所提出方法能够有效缓解大规模视频-语言模型的幻觉,为更可靠、更准确的多模态系统奠定基础。
我们总结本文的主要贡献如下:
- 提出一种新的多层次多模态对齐策略,在视觉编码过程中引入文本语义监督,并在多层次上对齐文本与视觉语义特征,以解决大规模视频-语言模型的幻觉问题。
- 提出两阶段训练策略,促进从通用视觉-文本语义到任务特定语义的渐进式协同学习,并利用更大且更多样的数据集。
- 在 LVU 与 MSVD 数据集上进行了大量实验,与多种 VLM 进行对比,证明我们的方法在多项下游视频任务上达到最先进性能,显著提升视频-语言模型的输出质量与可靠性,同时有效降低幻觉。
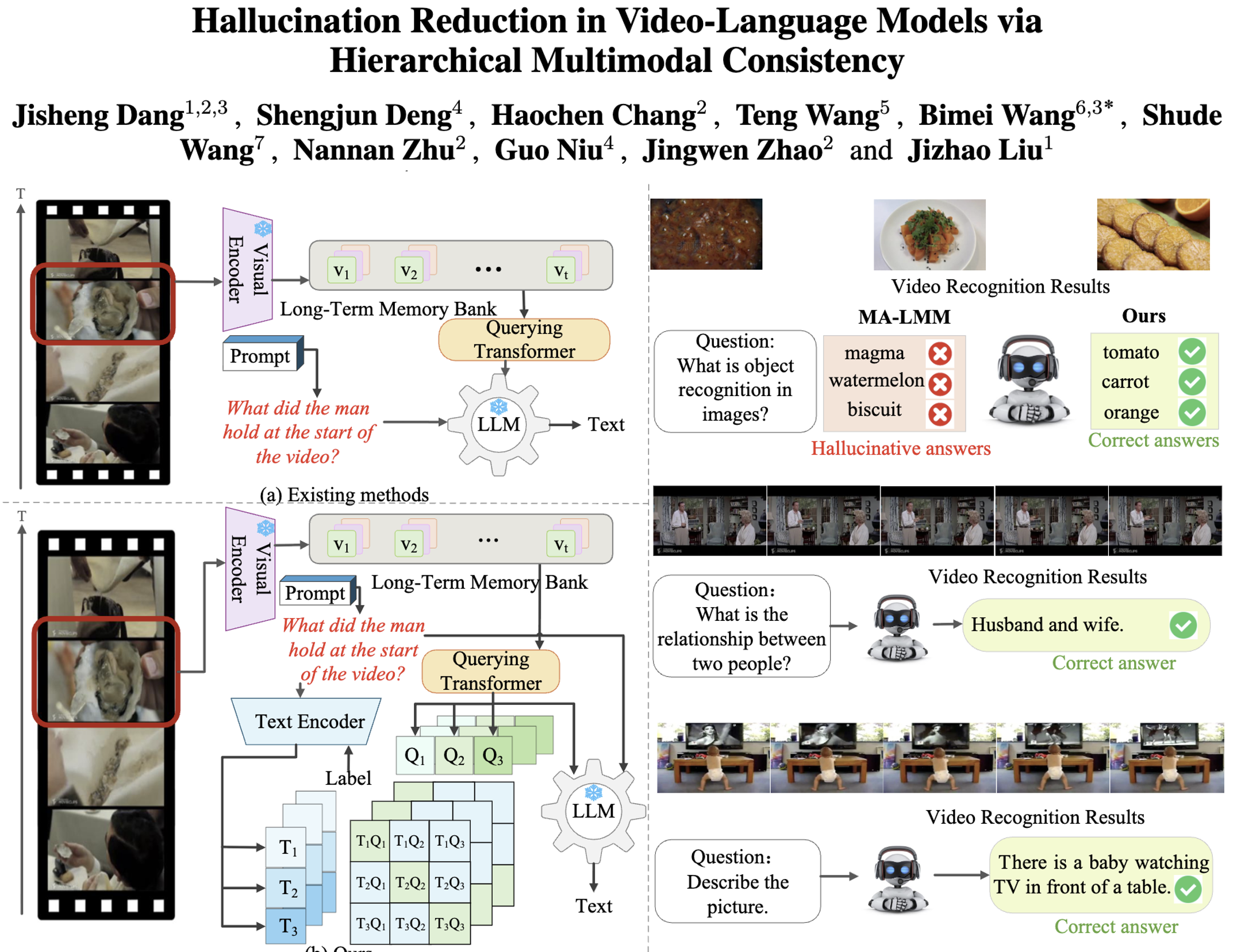
图 1:(左上)现有方法往往使用与文本解码语义不对齐的视觉特征。(左下)我们的 MMA 采用多层次多模态语义对齐策略以缓解幻觉。(右)我们的方法能够有效区分易混淆对象,展示了对复杂语义的把握能力;在降低幻觉与提升回答准确性方面显著优于 MA-LMM。
2 相关工作
图 2:(左)框架概览:使用 Long-Term Memory Bank 与 Q-Former 编码视觉特征;文本编码器从提示词与文本标签中提取联合语义特征,并通过对比学习在多个层次与视觉特征实现语义对齐;随后 LLM 生成多种下游视频理解任务的文本输出。(右)两阶段训练:辅助预训练阶段在更大且更丰富的视频-语言数据集上使用语义判别损失;任务特定训练阶段在下游任务数据集上同时使用语义判别损失与文本解码损失。
2.1 长视频理解的进展
长视频理解的近期进展主要受多模态 LLM(MLLMs)、记忆增强架构以及任务特定方法推动。然而,由于计算效率低、时间依赖复杂以及冗余信息多,处理长时长视频仍然具有挑战。
视觉与语言模型的融合在该领域发挥了关键作用。早期模型如 BLIP-2[Li et al., 2023a]结合了预训练的视觉与语言编码器,使得模型能够在视频描述与视觉问答等任务上进行丰富的跨模态推理。在此基础上,Video-ChatGPT[Maaz et al., 2023]与 Video-LLaMA[Zhang et al., 2023]引入视频 Transformer 以更好建模时序动态。但由于固定大小 token 压缩,它们在处理更长视频序列时仍会丢失关键语义。TimeChat[Ren et al., 2024]通过动态 token 压缩(依据视频长度调整压缩率)缓解该问题,提升了时间事件定位能力并增强了复杂时间关系建模能力,从而推动了多模态视频模型的发展。
2.2 记忆增强架构与可扩展性挑战
记忆增强架构通过保留并引用过去帧来维持时间一致性,已成为长视频理解的重要策略。例如 LongVLM[Weng et al., 2025]在短期与长期记忆之间取得平衡,以减少长视频中的冗余,但在有限计算预算下往往难以保留细粒度视觉细节。分层模型如 MeMViT[Wu et al., 2022]改进了长序列任务的注意力机制,但常常未充分利用 token 级表征,而 token 级表征对有效编码仍至关重要。
与此同时,任务特定方法在多种视频理解任务上提升了计算效率[Dang et al., 2023b; Dang and Yang, 2022; Dang and Yang, 2021]。检索增强生成(RAG)将外部知识与生成模型结合以降低成本;而 STTS[Bertasius et al., 2021]等方法通过早期选择与合并信息量更大的 token 来提升效率。尽管取得了进展,同时捕获局部与全局的时间依赖仍是长时长视频理解的核心挑战。
2.3 缓解视频-语言模型幻觉的策略
幻觉是 VLMs 的突出问题,显著限制其在真实场景中的可用性。研究者提出了多类纠错策略,通常可分为:数据集去幻觉、弥合模态差距、以及输出纠错。但在需要复杂多模态推理的任务中,幻觉缓解仍然是难点。
数据层面的方法(例如 Text Shearing 与 CIT[Hu et al., 2023])通过提高数据质量、降低过度自信、打破训练数据中的虚假共现来缓解幻觉。模态层面方法(例如视觉融合与感知增强)提升跨模态对齐并降低语义错位。输出纠错策略(例如生成后精修 Woodpecker[Yin et al., 2024])侧重于检测并修正输出中的幻觉。尽管这些方法有效,但往往计算开销较高或依赖大量精心构建的数据集,从而限制可扩展性。本文提出一种显式集成语言层面对齐并配合增强训练方案的新框架,以获得更强的语义一致性与更稳健的跨任务表现。
3 方法
3.1 总体概述
我们提出一种用于长视频理解的新型视频-语言模型,通过多层次多模态对齐来缓解幻觉。整体架构如图 2 所示。在视觉特征提取阶段,多层次语义判别损失通过对比学习将视频嵌入空间与语言嵌入空间对齐,从而在视觉编码过程中注入语义信息。对齐后的视觉特征被输入到 LLM 进行文本解码。在训练方面,我们采用两阶段训练策略:辅助预训练阶段使用语义更丰富的数据集对 Q-Former 进行预训练,以学习跨模态的一般语义;任务特定训练阶段在冻结 LLM 的前提下,在任务数据集上进行更精细的语义学习,从而缓解幻觉现象。
3.2 多层次多模态对齐
视觉特征提取。 为有效捕获长视频的时序动态并聚合历史信息,类似于 MA-LMM[He et al., 2024],我们以自回归方式按时间顺序采样视频帧,并将视频特征存入长期记忆库(long-term memory bank)。此外,我们使用 Querying Transformer(Q-Former)[Li et al., 2023a; He et al., 2024]对视觉与文本特征进行初步对齐。
具体而言,给定包含 T T T 帧的视频序列,我们先将每一帧输入到预训练视觉编码器,得到对应的视觉特征
V = [ v 1 , v 2 , … , v T ] , v t ∈ R P t i m e s C , V = [v_1, v_2, \dots, v_T], \quad v_t \in \mathbb{R}^{P\\times C}, V=[v1,v2,…,vT],vt∈RPtimesC,
其中 P P P 表示每帧的 patch 数, C C C 为通道维度。随后通过位置嵌入层注入时间顺序信息,并将帧级特征存入长期记忆库,得到视觉记忆特征
F t = m a t h r m C o n c a t [ f 1 , f 2 , … , f t ] , F t ∈ R t P t i m e s C , F_t = \\mathrm{Concat}[f_1, f_2, \dots, f_t], \quad F_t \in \mathbb{R}^{tP\\times C}, Ft=mathrmConcat[f1,f2,…,ft],Ft∈RtPtimesC,
以及查询记忆特征
Z t = m a t h r m C o n c a t [ z 1 , z 2 , … , z t ] , Z t ∈ R t N t i m e s C , Z_t = \\mathrm{Concat}[z_1, z_2, \dots, z_t], \quad Z_t \in \mathbb{R}^{tN\\times C}, Zt=mathrmConcat[z1,z2,…,zt],Zt∈RtNtimesC,
其中 f t f_t ft 表示帧级特征, t t t 为当前时间步, N N N 为可学习 token 数。我们使用 Q-Former 让可学习 Query 与视频记忆特征交互,从而学习视觉特征对应的“文本化表征”。
在多数现有视频-语言模型中,模态间语义对齐主要依赖冻结的大语言模型,而视觉编码阶段缺少自然语言的语义引导与监督,导致视觉编码出现偏移:模型难以将视频中的丰富内容映射为与文本语义高度匹配的特征表征。面对复杂场景或细微动作时,模型可能将视频中的某个视觉概念误解为其先前见过的另一个概念,继而在下游任务中生成不准确或不相关的描述,产生幻觉。因此,我们希望在视觉编码过程中引入文本语义监督,以增强视觉编码的语义判别能力。
受 CLIP[Radford et al., 2021]启发,我们引入 BERT embedding layer[Devlin, 2018]作为文本编码器 E t E_t Et 来提取文本语义特征。我们将文本提示(prompt)与文本标签(label)拼接后输入文本编码器,得到语义嵌入特征 f t f_t ft:
f t = E t ( [ l a n g l e t e x t p r o m p t r a n g l e + l a n g l e t e x t l a b e l r a n g l e ] ) . t a g 1 f_t = E_t([\\langle \\text{prompt} \\rangle + \\langle \\text{label} \\rangle]). \\tag{1} ft=Et([langletextpromptrangle+langletextlabelrangle]).tag1
为实现视觉与文本模态特征的语义对齐,我们使用语义判别损失(semantic discriminative loss)在视觉 Q-Former 的训练过程中注入文本语义。具体地,在一个包含 N N N 个(video, text)对的 batch 中,正样本为匹配的 N N N 个视频-文本对,负样本为 batch 内其余不匹配的视频-文本组合。该损失最大化正样本对的余弦相似度、最小化负样本对的余弦相似度。它本质上遵循 InfoNCE 损失形式,学习视觉与文本共享的语义嵌入空间:
m a t h c a l L t e x t s e m a n t i c = − f r a c 1 N s u m i = 1 N l o g f r a c e x p l e f t ( l a n g l e f v i , f t i r a n g l e / t a u r i g h t ) s u m j = 1 N e x p l e f t ( l a n g l e f v i , f t j r a n g l e / t a u r i g h t ) . t a g 2 \\mathcal{L}_{\\text{semantic}} = -\\frac{1}{N}\\sum_{i=1}^{N} \\log \\frac{ \\exp\\left( \\langle f_v^i, f_t^i\\rangle / \\tau \\right) }{ \\sum_{j=1}^{N} \\exp\\left( \\langle f_v^i, f_t^j\\rangle / \\tau \\right) }. \\tag{2} mathcalLtextsemantic=−frac1Nsumi=1Nlogfracexpleft(langlefvi,ftirangle/tauright)sumj=1Nexpleft(langlefvi,ftjrangle/tauright).tag2
其中 f v i f_v^i fvi 为 Q-Former 输出的视频语义特征, f t i f_t^i fti 为文本编码器输出的文本语义特征; t a u \\tau tau 为温度系数。训练时我们更新 Q-Former 与文本编码器参数,同时冻结视觉编码器与 LLM。
引入文本语义监督的潜在优势包括:(1)改进 Q-Former 的视觉编码学习过程,提高语义判别性;(2)文本语义特征作为更规范的表征,与视觉特征具有更强一致性,有助于促进跨模态信息交互。
多层次对齐。 不同层次的语义对齐能够在不同抽象程度上捕获文本与视觉信息。在长视频理解任务中,较低层次的对齐可以将角色服饰颜色、物体几何形状等基础视觉特征与文本中的颜色/形状词汇对应起来;较高层次对齐则可以将事件流程、人物关系等复杂视觉语义与文本中关于剧情发展、人物互动的抽象概念匹配。
为进一步增强视觉编码的语义判别性,我们将语义判别损失扩展为多层次框架,从而提升语义对齐效果。多层次语义损失可写为:
其中 L L L 为对齐层数。实验中我们采用两层对齐方案:对齐 Q-Former 的输出特征,以及对齐交叉注意力机制的输入特征。通过多层次语义判别损失,我们在视觉与文本模态的各层次上实现语义对齐,从而同时捕获高层与低层语义关系,并通过建立视频内容与生成语言之间更精确的对应关系来有效降低幻觉。
3.3 两阶段训练
训练数据是导致视频-语言模型产生幻觉的重要因素。一方面,某些数据集缺乏多样性会使模型对部分视觉概念理解不足,从而加大视频与文本模态对齐难度;另一方面,训练集中的物体分布不均会使模型偏向预测常见物体或高频共现的物体组合。因此,我们提出两阶段训练方案,利用扩展数据集改善多层次语义判别损失的优化:辅助预训练阶段与任务特定训练阶段。
辅助预训练阶段。 该阶段使用更大量的数据向模型注入更丰富的语义。我们首先在 WebVid 数据集上进行预训练,使模型学习视觉与语言模态之间的一般语义关系,为特定任务训练提供辅助。WebVid-5K 数据集包含大量且多样的视频片段与对应文本描述。通过接触这一广泛多样的数据源,模型可以捕获现实世界中丰富的语义关系,从而更好泛化,并为后续任务特定训练打下更稳固基础。
任务特定训练阶段。 完成辅助预训练后,我们在其他数据集上进一步训练以实现特定任务的语义对齐。该两步流程旨在利用预训练阶段获得的知识,并根据任务需求对模型进行微调。从大规模通用语义到任务特定语义的渐进学习,使模型持续细化语义理解,逐步将注意力从广泛语义空间聚焦到目标任务的语义域;通过迭代学习与适配,模型能够捕获更准确的跨模态语义关系,从而在特定任务上生成更高质量的输出。
3.4 训练目标
我们将 Q-Former 在最终时间步输出的特征(包含顺序历史信息)输入 LLM 进行文本解码。训练时,给定由视频与文本对组成的标注数据集,使用标准交叉熵损失:
其中 l a m b d a t e x t m u l t i \\lambda_{\\text{multi}} lambdatextmulti 与 l a m b d a t e x t t e x t \\lambda_{\\text{text}} lambdatexttext 为权衡两部分的超参数。
4 实验
4.1 数据集
实验在两个常用的长视频数据集上进行:
- LVU 数据集[Wu and Krahenbuhl, 2021]:包含超过 30,000 个视频片段,每段时长 1–3 分钟,来源于约 3,000 部电影,覆盖多种真实世界场景。
- MSVD 数据集[Chen and Dolan, 2011]:包含约 120K 句子,对 2,000+ 个视频片段进行摘要描述;这些句子由 Mechanical Turk 于 2010 年夏季收集。
4.2 实现细节
视觉编码器方面,我们采用 EVA-CLIP[Fang et al., 2023]中预训练的图像编码器 ViT-G/14[Alexey, 2020],也可替换为其他基于 CLIP 的视频编码器。Q-Former 采用 InstructBLIP[Dai et al., 2023]提供的预训练权重,并使用收集到的 WebVid-5K[Bain et al., 2021]数据集完成第一阶段训练。LLM 采用 Vicuna-7B[Chiang et al., 2023]。我们方法中的损失权重设置为 l a m b d a t e x t m u l t i = 0.5 \\lambda_{\\text{multi}}=0.5 lambdatextmulti=0.5、 l a m b d a t e x t t e x t = 1 \\lambda_{\\text{text}}=1 lambdatexttext=1。所有实验在 4 张 V100 GPU 上进行。
4.3 定量结果
长视频理解。 我们在 LVU 基准上与先前的最先进方法进行对比,结果见表 1。值得注意的是,我们的方法在内容理解与元数据预测两类任务上均优于现有长视频模型(MA-LMM[He et al., 2024]、ViS4mer[Islam and Bertasius, 2022]、VideoBERT[Sun et al., 2019]、Object Transformer[Wu and Krahenbuhl, 2021]),在多数任务上带来显著提升,相比 MA-LMM 的平均 top-1 准确率提升 2.0%。这表明我们的方法具有更强的长视频理解能力。与以往方法不同,我们在多层次对视频内容进行语义对齐,使模型能够更精确理解视频中的问题与线索。
视频问答。 为与现有多模态视频理解方法比较,我们在 MSVD[Chen and Dolan, 2011] 视频问答(VQA)数据集上进行实验(表 2)。结果表明,基于提示词进行多层次对齐能够帮助模型更好理解任务并更准确描述视频中的对象;多层次对齐带来的性能提升验证了其增强语义对齐能力的作用。在此基础上,结合两阶段训练可进一步学习更具体的语义信息,降低模型幻觉。值得注意的是,我们的结果也超过了近期的 MA-LMM,体现出在视频问答任务上的显著改进。
消融实验。 为评估多层次多模态对齐策略与两阶段训练策略的有效性,我们在 LVU relation 数据集上进行全面消融,结果见图 3。
图 3: 多层次多模态对齐与两阶段训练在 LVU Relation 上的消融结果。
图 4: 多层次对齐模块的消融实验结果。
图 4 的结果表明:在基线之上使用多层次对齐策略可带来 3.3% 的提升,说明该策略能够有效将文本语义融入视频语言模型训练,增强 Q-Former 的训练过程并显著提高长视频理解任务的识别精度。图 3 还表明:在基线之上同时采用多层次对齐与两阶段训练可带来 4.4% 的提升,并且该组合的准确率高于仅使用多层次对齐,证明两阶段训练能够帮助 VLM 学到更丰富的语义。
此外,我们比较了不同对齐策略与采样帧设置的影响:仅对前三帧进行单层对齐即可优于基线;采用多层次对齐可达到 61.5%,进一步验证对齐策略的有效性。我们尝试修改采样方法(例如前两帧、首帧与末帧),top-1 表现无明显变化;在多层次对齐中使用更多帧也未带来额外收益。总体上,多层次对齐优于单层对齐;引入两阶段训练后性能再次提升,表明额外数据的对齐有助于更好缓解幻觉。
表 1: 在 LVU 数据集上的长视频理解任务,与最先进方法的对比(Top-1 Accuracy,%)。
| 模型 | Relation | Speak | Scene | Director | Genre | Writer | Year | Avg |
|---|---|---|---|---|---|---|---|---|
| Obj_T4mer [Wu and Krahenbuhl, 2021] | 54.8 | 33.2 | 52.9 | 47.7 | 52.7 | 36.3 | 37.8 | 45.0 |
| Performer [Choromanski et al., 2020] | 50.0 | 38.8 | 60.5 | 58.9 | 49.5 | 48.2 | 41.3 | 49.6 |
| Orthoformer [Patrick et al., 2021] | 50.0 | 38.3 | 66.3 | 55.1 | 55.8 | 47.0 | 43.4 | 50.8 |
| VideoBERT [Sun et al., 2019] | 52.8 | 37.9 | 54.9 | 47.3 | 51.9 | 38.5 | 36.1 | 45.6 |
| LST [Islam and Bertasius, 2022] | 52.5 | 37.3 | 62.8 | 56.1 | 52.7 | 42.3 | 39.2 | 49.0 |
| VIS4mer [Islam and Bertasius, 2022] | 57.1 | 40.8 | 67.4 | 62.6 | 54.7 | 48.8 | 44.8 | 53.7 |
| MA-LMM [He et al., 2024] | 58.2 | 44.8 | 80.3 | 74.6 | 61.0 | 70.4 | 51.9 | 63.0 |
| MMA(本文方法) | 62.6 | 41.9 | 83.0 | 79.9 | 62.1 | 70.6 | 54.9 | 65.0 |
表 2: 在 MSVD 数据集上的视频问答任务,与最先进方法的对比(Accuracy,%)。
| 模型 | MSVD |
|---|---|
| FrozenBiLM [Yang et al., 2022] | 54.8 |
| GiT [Wang et al., 2022] | 56.8 |
| mPLUG-2 [Xu et al., 2023] | 58.1 |
| UMT-L [Li et al., 2023b] | 55.2 |
| VideoCoCa [Yan et al., 2022] | 56.9 |
| Video-LLaMA [Zhang et al., 2023] | 58.3 |
| MA-LMM [He et al., 2024] | 60.6 |
| MMA(本文方法) | 60.9 |
4.4 可视化分析
图 1(右)展示了我们的方法与基线 MA-LMM 在长视频理解任务上的对比示例。
图 5: LVU 数据集长视频识别任务的可视化结果。
图 5 展示了我们方法在 LVU 长视频理解任务上的定性结果。在“喜剧类型判定”(上)中,模型能依据视频内容准确判断电影类型,体现其对剧情等视觉要素的理解以及与语义概念对齐的能力。在“朋友关系识别”(中)中,模型成功推断角色间关系,展示其捕获并分析人物互动等视觉信息的能力。在“办公室场景识别”(下)中,模型正确识别场景,表明其能够分析并分类视频背景等视觉要素,并输出准确的语义信息。以上示例共同表明,我们的模型在捕获复杂语义信息的同时显著降低了幻觉发生。
5 结论
本文提出了一种直接应对大规模视频-语言模型幻觉问题的新框架。通过在训练过程中引入语言层面的监督与对齐,我们增强了视频与文本模态之间的语义一致性,从而有效降低噪声或错位数据带来的影响。扩展数据集与改进的语义判别损失进一步增强了跨模态对齐能力,并引入更丰富且语义更强的表征。跨多项视频-语言任务的实验结果表明,我们的方法不仅显著降低幻觉,还达到最先进性能,为后续研究设定了新的基准。该工作为更准确、更鲁棒的视频-语言理解铺平道路,具有广泛应用前景,包括视频分析、多模态学习等。
参考文献
以下为原文参考文献条目(保持英文原样):
[Alexey, 2020] Dosovitskiy Alexey. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv: 2010.11929, 2020.
[Bain et al., 2021] Max Bain, Arsha Nagrani, Gl Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 17281738, 2021.
[Bertasius et al., 2021] Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? In ICML, volume 2, page 4, 2021.
[Chen and Dolan, 2011] David L. Chen and William B. Dolan. Collecting highly parallel data for paraphrase evaluation. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies - Volume 1, page 190200, 2011.
[Chiang et al., 2023] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023.
[Choromanski et al., 2020] Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers. arXiv preprint arXiv:2009.14794, 2020.
[Dai et al., 2023] Wenliang Dai, Junnan Li, D Li, AMH Tiong, J Zhao, W Wang, B Li, P Fung, and S Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. arxiv 2023. arXiv preprint arXiv:2305.06500, 2, 2023.
[Dang and Yang, 2021] Jisheng Dang and Jun Yang. Higcnn: Hierarchical interleaved group convolutional neural networks for point clouds analysis. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 28252829. IEEE, 2021.
[Dang and Yang, 2022] Jisheng Dang and Jun Yang. Lh-phgcnn: Lightweight hierarchical parallel heterogeneous group convolutional neural networks for point cloud scene prediction. IEEE Transactions on Intelligent Transportation Systems, 23(10):1890318915, 2022.
[Dang et al., 2023a] Jisheng Dang, Huicheng Zheng, Jinming Lai, Xu Yan, and Yulan Guo. Efficient and robust video object segmentation through isogenous memory sampling and frame relation mining. IEEE Transactions on Image Processing, 32:39243938, 2023.
[Dang et al., 2023b] Jisheng Dang, Huicheng Zheng, Xiaohao Xu, and Yulan Guo. Unified spatio-temporal dynamic routing for efficient video object segmentation. IEEE Transactions on Intelligent Transportation Systems, 25(5):45124526, 2023.
[Dang et al., 2024a] Jisheng Dang, Huicheng Zheng, Bimei Wang, Longguang Wang, and Yulan Guo. Temporo-spatial parallel sparse memory networks for efficient video object segmentation. IEEE Transactions on Intelligent Transportation Systems, 2024.
[Dang et al., 2024b] Jisheng Dang, Huicheng Zheng, Xiaohao Xu, Longguang Wang, and Yulan Guo. Beyond appearance: Multi-frame spatio-temporal context memory networks for efficient and robust video object segmentation. IEEE Transactions on Image Processing, 2024.
[Dang et al., 2024c] Jisheng Dang, Huicheng Zheng, Xiaohao Xu, Longguang Wang, Qingyong Hu, and Yulan Guo. Adaptive sparse memory networks for efficient and robust video object segmentation. IEEE Transactions on Neural Networks and Learning Systems, 2024.
[Devlin, 2018] Jacob Devlin. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
[Fang et al., 2023] Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. Eva: Exploring the limits of masked visual representation learning at scale. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1935819369, 2023.
[He et al., 2024] Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, and Ser-Nam Lim. Ma-lmm: Memory-augmented large multimodal model for long-term video understanding. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1350413514, 2024.
[Hu et al., 2023] Hongyu Hu, Jiyuan Zhang, Minyi Zhao, and Zhenbang Sun. Ciem: Contrastive instruction evaluation method for better instruction tuning. arXiv preprint arXiv:2309.02301, 2023.
[Islam and Bertasius, 2022] Md Mohaiminul Islam and Gedas Bertasius. Long movie clip classification with state-space video models. In European Conference on Computer Vision, pages 87104. Springer, 2022.
[Leng et al., 2024] Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1387213882, 2024.
[Li et al., 2023a] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the 40th International Conference on Machine Learning, pages 1973019742. PMLR, 2023.
[Li et al., 2023b] Kunchang Li, Yali Wang, Yizhuo Li, Yi Wang, Yinan He, Limin Wang, and Yu Qiao. Unmasked teacher: Towards training-efficient video foundation models. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 1994819960, 2023.
[Li et al., 2024] Xiangxian Li, Yuze Zheng, Haokai Ma, Zhuang Qi, Xiangxu Meng, and Lei Meng. Cross-modal learning using privileged information for long-tailed image classification. Computational Visual Media, 10(5):981992, 2024.
[Liu et al., 2024] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2629626306, 2024.
[Ma et al., 2024a] Fan Ma, Xiaojie Jin, Heng Wang, Yuchen Xian, Jiashi Feng, and Yi Yang. Vista-llama: Reducing hallucination in video language models via equal distance to visual tokens. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1315113160, 2024.
[Ma et al., 2024b] Haokai Ma, Ruobing Xie, Lei Meng, Xin Chen, Xu Zhang, Leyu Lin, and Jie Zhou. Triple sequence learning for cross-domain recommendation. ACM Transactions on Information Systems, 42(4):129, 2024.
[Maaz et al., 2023] Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. arXiv preprint arXiv:2306.05424, 2023.
[Meng et al., 2024] Lei Meng, Zhuang Qi, Lei Wu, Xiaoyu Du, Zhaochuan Li, Lizhen Cui, and Xiangxu Meng. Improving global generalization and local personalization for federated learning. IEEE Transactions on Neural Networks and Learning Systems, 2024.
[Meng et al., 2025] Lei Meng, Xiangxian Li, Xiaoshuo Yan, Haokai Ma, Zhuang Qi, Wei Wu, and Xiangxu Meng. Causal inference over visual-semantic-aligned graph for image classification. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 1944919457, 2025.
[Patrick et al., 2021] Mandela Patrick, Dylan Campbell, Yuki Asano, Ishan Misra, Florian Metze, Christoph Feichtenhofer, Andrea Vedaldi, and Joao F Henriques. Keeping your eye on the ball: Trajectory attention in video transformers. Advances in Neural Information Processing Systems, 34:1249312506, 2021.
[Radford et al., 2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, pages 87488763. PMLR, 2021.
[Ren et al., 2024] Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. Timechat: A time-sensitive multimodal large language model for long video understanding. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1431314323, 2024.
[Sun et al., 2019] Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmid. Videobert: A joint model for video and language representation learning. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 74647473, 2019.
[Wang et al., 2022] Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, and Lijuan Wang. Git: A generative image-to-text transformer for vision and language. arXiv preprint arXiv:2205.14100, 2022.
[Wang et al., 2024] Yuqing Wang, Lei Meng, Haokai Ma, Yuqing Wang, Haibei Huang, and Xiangxu Meng. Modeling event-level causal representation for video classification. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 39363944, 2024.
[Weng et al., 2025] Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, and Bohan Zhuang. Longvlm: Efficient long video understanding via large language models. In European Conference on Computer Vision, pages 453470. Springer, 2025.
[Wu and Krahenbuhl, 2021] Chao-Yuan Wu and Philipp Krahenbuhl. Towards long-form video understanding. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18841894, 2021.
[Wu et al., 2022] Chao-Yuan Wu, Yanghao Li, Karttikeya Mangalam, Haoqi Fan, Bo Xiong, Jitendra Malik, and Christoph Feichtenhofer. Memvit: Memory-augmented multiscale vision transformer for efficient long-term video recognition. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1358713597, 2022.
[Xu et al., 2023] Haiyang Xu, Qinghao Ye, Ming Yan, Yaya Shi, Jiabo Ye, Yuanhong Xu, Chenliang Li, Bin Bi, Qi Qian, Wei Wang, et al. mplug-2: a modularized multi-modal foundation model across text, image and video. In Proceedings of the 40th International Conference on Machine Learning, pages 3872838748. PMLR, 2023.
[Yan et al., 2022] Shen Yan, Tao Zhu, Zirui Wang, Yuan Cao, Mi Zhang, Soham Ghosh, Yonghui Wu, and Jiahui Yu. Videococa: Video-text modeling with zero-shot transfer from contrastive captioners. arXiv preprint arXiv:2212.04979, 2022.
[Yang et al., 2022] Antoine Yang, Antoine Miech, Josef Sivic, Ivan Laptev, and Cordelia Schmid. Zero-shot video question answering via frozen bidirectional language models. Advances in Neural Information Processing Systems, 35:124141, 2022.
[Yin et al., 2024] Shukang Yin, Chaoyou Fu, Sirui Zhao, Tong Xu, Hao Wang, Dianbo Sui, Yunhang Shen, Ke Li, Xing Sun, and Enhong Chen. Woodpecker: Hallucination correction for multimodal large language models. Science China Information Sciences, 67(12):220105, 2024.
[Zhang et al., 2023] Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献78条内容
已为社区贡献78条内容

所有评论(0)