ACL 2025杰出论文!用能力显著向量让大模型下游任务性能预测更精准
本文提到Capability Salience Vector(能力显著向量,CSV),这是一种将整体损失分解并为不同tokens分配重要性权重的方法,能实现将验证损失与模型下游任务能力对齐的功能。传统缩放定律虽建立了训练计算与验证损失的关系,但验证损失与下游任务能力间存在差距,因其默认tokens重要性相同,无法直接建模下游能力与计算或token损失的关系。
第63届国际计算语言学协会年会(ACL 2025)于7月27日至8月1日在奥地利维也纳盛大举行。作为自然语言处理领域最具影响力的顶级盛会,本届ACL汇聚了全球众多顶尖学者,投稿数量与质量再创新高。
在本届大会上,由上海人工智能实验室大模型中心与与复旦大学计算机科学与人工智能学院联合提出的研究成果《Capability Salience Vector: Fine-grained Alignment of Loss and Capabilities for Downstream Task Scaling Law》荣获“杰出论文奖”(Outstanding Papers)。
以下为该篇论文的详细介绍(转载自AI前沿速递)
1. 【导读】
上海人工智能实验室大模型中心与复旦大学计算机科学与人工智能学院联合提出了Capability Salience Vector(能力显著向量,CSV),旨在解决大语言模型中验证损失与下游任务能力之间的脱节问题。传统缩放定律虽能预测模型验证损失,但难以直接关联下游任务表现,因验证损失默认所有 tokens 重要性相同,而实际不同 tokens 对模型能力的贡献存在差异。该研究通过 CSV 为 tokens 损失分配不同权重,将整体损失分解为与特定元能力对齐的加权损失,结合 sigmoidal 函数建模能力分数与下游任务性能的关系。实验在 MMLU、BBH 等六大基准测试上验证,CSV 显著提升了模型下游任务表现的可预测性,为精准建模语言模型损失与下游任务性能的缩放关系提供了新思路。

论文基本信息
|
信息类型 |
详情 |
|---|---|
|
论文标题 |
Capability Salience Vector: Fine-grained Alignment of Loss and Capabilities for Downstream Task Scaling Law |
|
作者 |
Qiming Ge、Shuhao Xing、Songyang Gao、Yunhua Zhou、Yicheng Zou、Songyang Zhang、Zhi Chen、Hang Yan、Qi Zhang、Qipeng Guo、Kai Chen |
|
作者单位 |
上海人工智能实验室、复旦大学计算机科学与人工智能学院 |
|
论文链接 |
https://arxiv.org/abs/2506.13216v1 |
2. 【摘要】
本文提到 Capability Salience Vector(能力显著向量,CSV),这是一种将整体损失分解并为不同tokens分配重要性权重的方法,能实现将验证损失与模型下游任务能力对齐的功能。传统缩放定律虽建立了训练计算与验证损失的关系,但验证损失与下游任务能力间存在差距,因其默认tokens重要性相同,无法直接建模下游能力与计算或token损失的关系。这种技术突破了验证损失无法有效预测下游任务表现的局限,通过CSV量化下游任务所需能力,实验在六大流行基准上验证其显著提升了语言模型下游任务表现的可预测性。
3. 【研究背景及相关工作】
3.1 研究背景
-
缩放定律的局限性:大语言模型的缩放定律构建了训练计算量与验证损失之间的关系,使研究人员能有效预测不同计算水平下模型的损失趋势。但验证损失与模型的下游任务能力之间存在差距,将缩放定律直接应用于下游任务的性能预测并非易事。
-
验证损失的不足:验证损失通常代表对预测tokens的累积惩罚,隐含认为所有tokens具有同等重要性。然而,研究表明,考虑不同训练数据分布时,无法直接建模下游能力与计算量或token损失之间的关系。实际中,相似验证损失的模型在下游任务表现上可能差异显著,说明验证损失单独作为模型真实能力的指标并不总是可靠。
3.2 相关工作
目前部分研究绕过验证损失,专注于直接建立计算资源与任务性能的缩放关系。为最小化数据分布偏移的影响,他们在所有实验设置中固定预训练数据集,同时调整计算量和模型大小。但数据分布偏移的影响不可忽视,相同计算量下,不同数据分布训练的模型在下游任务上可能产生显著不同的结果。
另一种研究方向聚焦于开发与下游任务性能相关性更好的替代指标。例如,Ruan等人提出观察性缩放定律(OSL),利用开源基准结果并应用主成分分析(PCA)探索模型能力的各个维度。不过,这些方法严重依赖所用基准的多样性和范围,可能产生巨大的评估成本。
Owen研究了模型在BBH和MMLU任务上缩放的可预测性,提出下游任务性能遵循S形函数且可预测,且随着更多模型纳入拟合过程,预测误差会降低。Gadre等人研究了在特定预训练数据分布上过度训练模型的缩放定律,发现验证损失与下游任务性能之间存在幂律关系,表明在给定数据分布上预训练后具有可预测性。Isik等人探索了预训练数据分布对翻译任务下游性能的影响,发现不同的预训练分布显著影响下游任务的缩放行为,表明评估模型缩放定律时应考虑数据分布。
4. 【主要贡献】
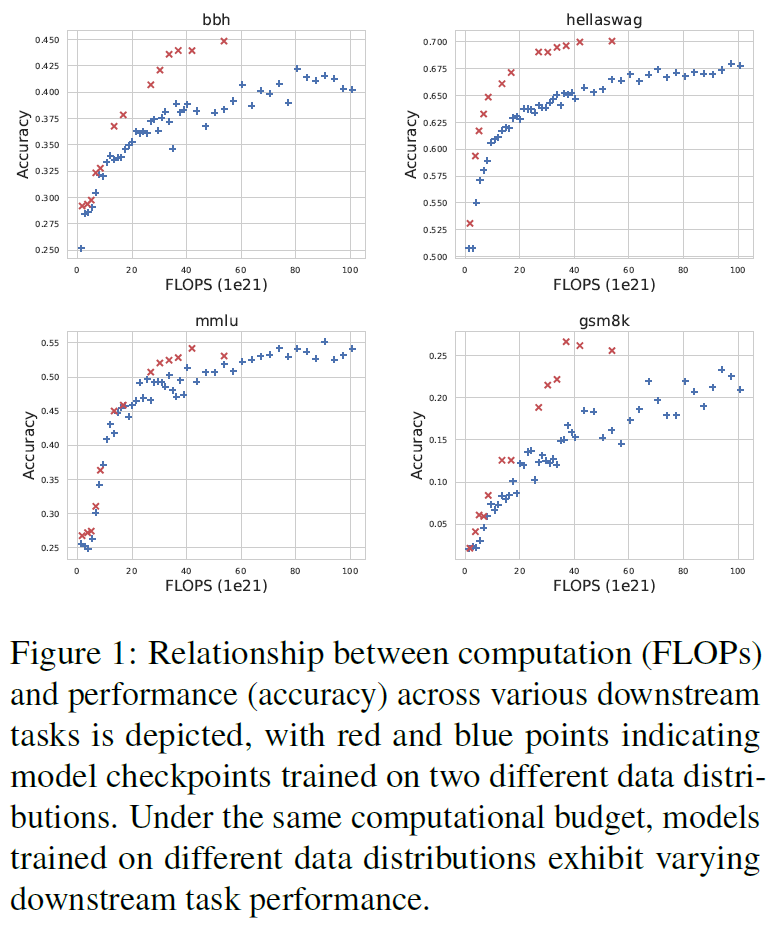
4.1 证明下游缩放定律无法直接通过计算量或平均 token 损失建模
相同计算量下,不同预训练数据分布的模型在下游任务表现差异显著(如数学任务 Gsm8k、推理任务 BBH 等),说明仅基于计算成本或验证集平均损失无法可靠预测下游性能。
4.2 提出能力显著向量(Capability Salience Vector, CSV)并建立损失与下游性能的对齐机制
CSV通过为不同token的损失分配重要性权重(如数学问题中的数字token、推理任务中的逻辑连接词token),将整体损失分解为与特定元能力相关的加权损失,解决了传统验证损失中所有token重要性均等的缺陷。
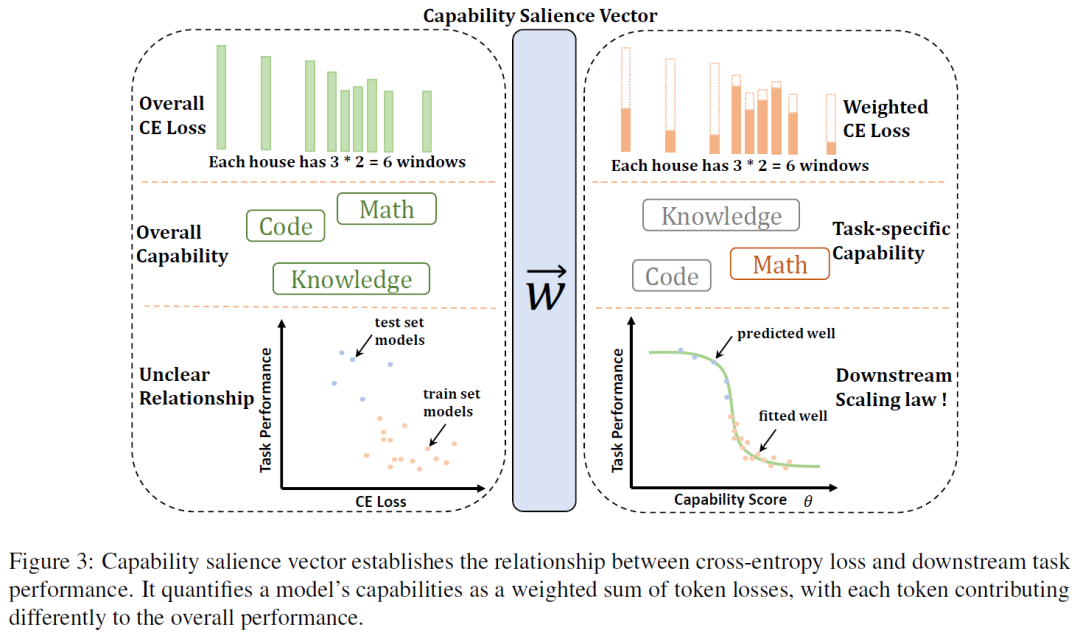
- **图示支撑**:图3直观展示CSV如何将原始交叉熵损失(CE Loss)转化为加权损失,通过权重分配使损失与下游任务能力(如数学、代码知识)对齐,建立可预测的映射关系。
4.3 通过六大基准实验验证CSV对下游性能预测的显著提升
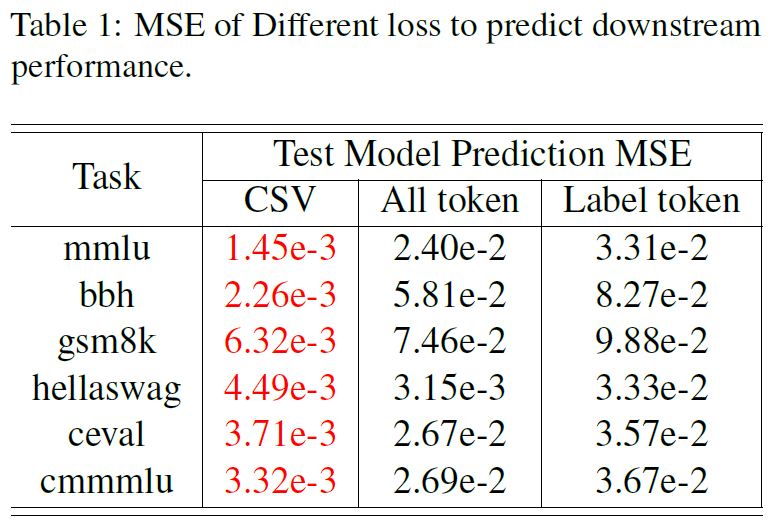
在知识(MMLU)、推理(BBH)、数学(Gsm8k)等六大任务上,CSV的预测均方误差(MSE)维持在1e-3范围内,远低于基线方法(如“All token loss”的MSE为2.40e-2~9.88e-2)。
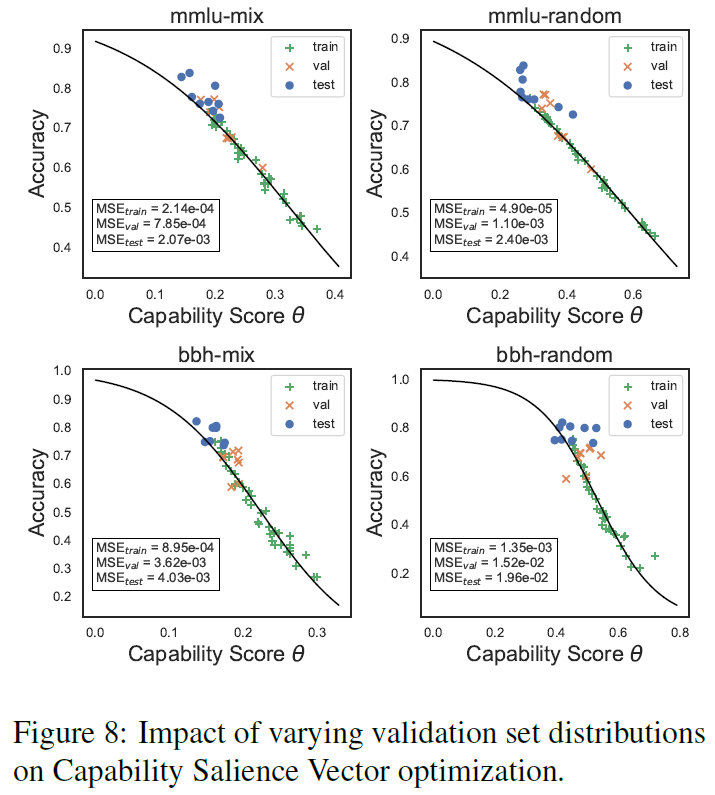
4.4 揭示验证集数据分布对能力建模的关键影响
验证集数据分布越多样(如混合知识、推理、数学等场景数据),CSV捕获的元能力组合越全面,下游预测越准确。
5. 【研究方法与基本原理】

5.1 核心思想
通过CSV为验证集token损失分配不同权重,使损失与下游任务所需特定元能力对齐。
5.2 能力分数计算

5.3 下游任务性能建模
其中,、为拟合参数,为随机猜测的预期性能。
5.4 CSV优化步骤
5.4.1 提取CSV权重
用语言模型评分头为每个token分配分数。
5.4.2 拟合下游缩放定律函数

5.4.3 优化CSV参数
用SGD最小化预测与实际下游性能的MSE。
6. 【实验结果】
6.1 数据集与模型
六大基准: MMLU(知识)、BBH(推理)、Hellaswag(常识)、Gsm8k(数学)、CMMLU和Ceval(中文)。评估模型: 超50个开源模型(LLAMA2、LLAMA3等)及自研不同数据分布训练的模型。
6.2 关键结果
6.2.1 CSV显著提升下游任务预测准确性,如MMLU预测MSE为1.45e-3,远低于基线方法(All token loss为2.40e-2)
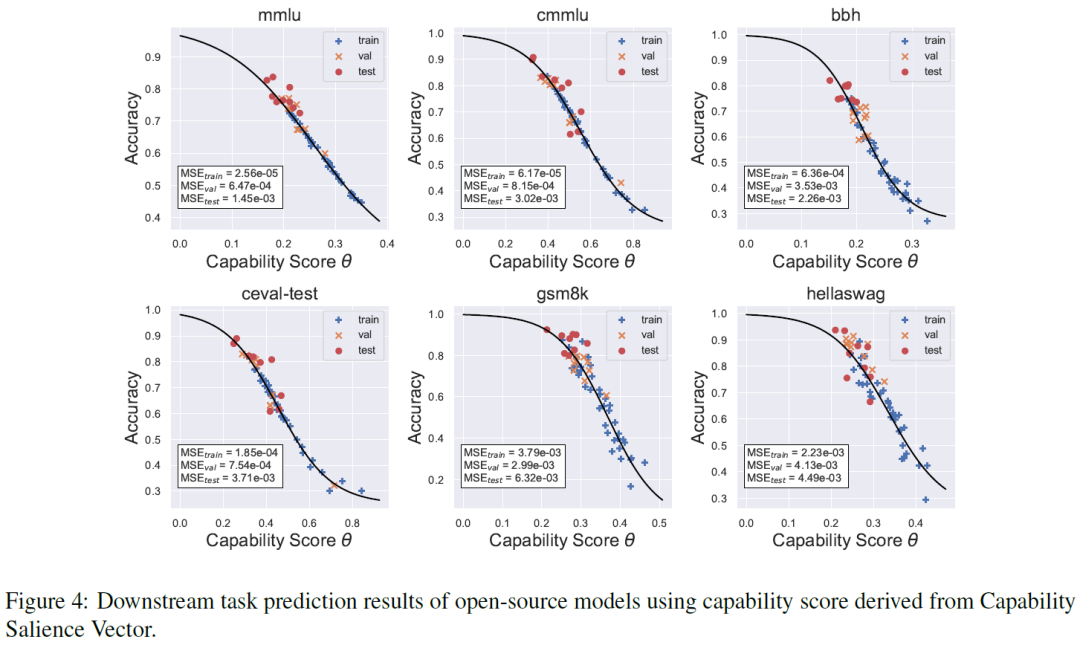
6.2.2 CSV推导的能力分数与开源/闭源模型的下游任务性能有强相关性,预测MSE多数在1e-3范围内。
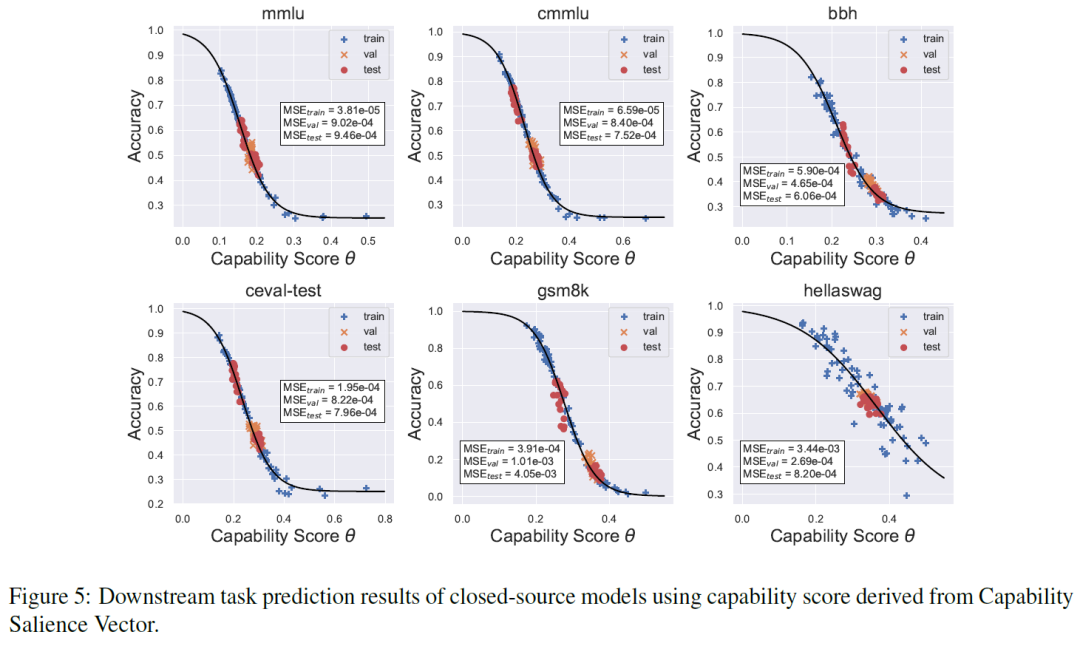
6.2.3 验证集数据分布多样性越高,CSV对下游缩放定律的能力预测越准确
7.【论文总结展望】
7.1 总结
本文首先证明了不同 tokens 对应不同的元能力,强调在探索语言模型交叉熵(CE)损失与下游任务性能的缩放关系时,需考虑 token 级差异。其次,提出了自动优化方法以识别文本片段的能力显著向量(Capability Salience Vector),通过为不同 tokens 的损失分配不同重要性权重,实现了对损失与下游任务缩放关系的建模。实验表明,该方法能有效提升下游任务性能的可预测性

7.2 展望
7.2.1 优化文本选择:探索如何更高效地选择适合优化能力显著向量的文本,提升不同场景下的建模效果。
7.2.2 算法效率提升:研究优化算法的轻量化改进,降低长文本优化的计算成本。
7.2.3 任务类型拓展:将方法应用于更复杂的主观评价任务或专业领域(如医疗、代码生成)。
7.2.4 跨模型迁移能力:探索能力显著向量在不同架构模型间的迁移适用性,增强泛化性。
非常高兴此次活动能汇聚近 70 位开发者面对面交流,期待未来有机会开展更多丰富有趣的活动,一起见证书生大模型社区的茁壮成长。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)