Qwen家族震撼发布!目前最强的开源多模态嵌入大模型,从这里开启你的AI新征程!
阿里通义千问团队发布最强开源多模态检索模型Qwen3-VL-Embedding和Reranker,支持文本、图像、视频等多模态输入及混合处理。8B版本在MMEB-V2评测中以77.8分获SOTA,Embedding模型负责初始召回生成向量,Reranker模型进行精排输出相关性评分。支持30+种语言、自定义指令和量化部署,适用于多模态RAG、视觉文档检索、视频内容检索等场景。
阿里通义千问团队又放大招了!这次是多模态检索领域的重磅更新——Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 正式发布。
一句话总结:这是目前最强的开源多模态嵌入模型,文本、图片、视频、截图,统统能搞定!
简介
Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 是 Qwen 家族的新成员,基于强大的 Qwen3-VL 视觉语言大模型构建。专门为多模态信息检索和跨模态理解设计,支持文本、图像、截图、视频输入,甚至可以处理这些模态的任意混合输入。
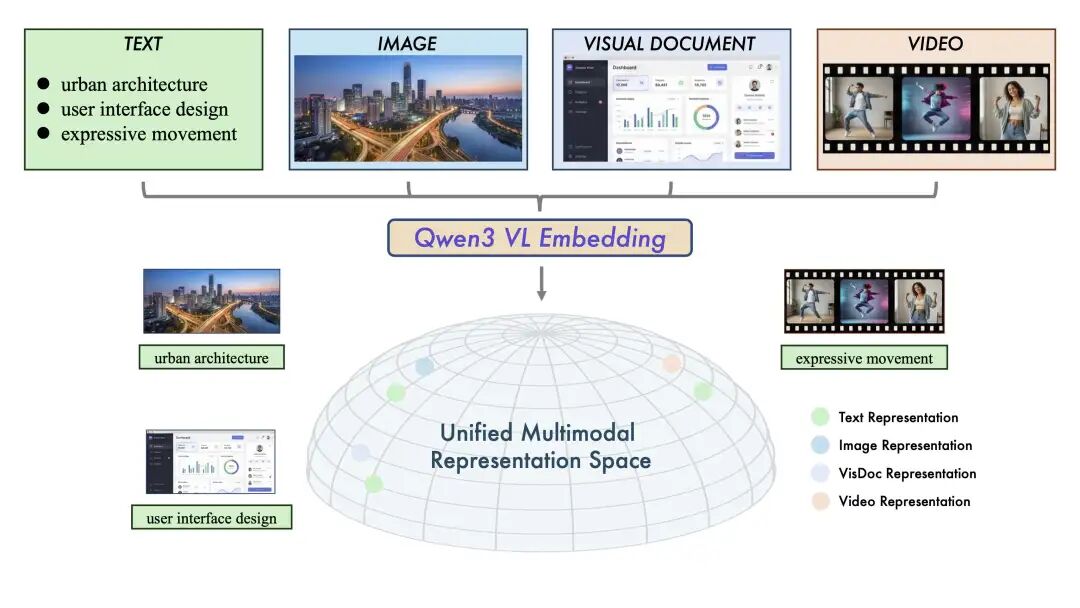
统一多模态表示空间示意图
这套模型延续了 Qwen3-Embedding 和 Qwen3-Reranker 的成功经验,把纯文本的高性能表现扩展到了视觉和视频理解任务。两个模型协同工作:
- Embedding 模型:负责初始召回阶段,生成语义丰富的向量
- Reranker 模型:负责精排阶段,输出精确的相关性评分
简单说就是:先用 Embedding 粗选,再用 Reranker 精排,最终大幅提升检索准确率。
核心亮点
🎨 多模态通用性
一个框架搞定所有模态输入!文本、图片、截图、视频,都能无缝处理。在图文检索、视频文本匹配、视觉问答(VQA)、多模态内容聚类等任务上都达到了 SOTA 级别。
🔄 统一表示空间
利用 Qwen3-VL 架构,把视觉和文本信息映射到同一个高维语义空间。这意味着你可以用文本去检索图片,也可以用图片去匹配文本,甚至可以用"文本+图片"的混合查询去检索视频。
🎯 高精度重排序
Reranker 模型接收 (Query, Document) 对作为输入,两者都可以是任意单一或混合模态,输出精确的相关性分数。比 Embedding 召回更准,适合对精度要求高的场景。
🌍 超强实用性
- 支持 30+ 种语言,全球化应用无压力
- 支持 自定义指令,可针对特定任务优化
- 支持 灵活向量维度(MRL,Matryoshka Representation Learning)
- 支持 量化嵌入,部署更高效
- 易于集成到现有 RAG 管道
模型规格
| 模型 | 参数量 | 层数 | 序列长度 | 嵌入维度 | 量化支持 | MRL支持 | 指令感知 |
|---|---|---|---|---|---|---|---|
| Qwen3-VL-Embedding-2B | 2B | 28 | 32K | 2048 | ✅ | ✅ | ✅ |
| Qwen3-VL-Embedding-8B | 8B | 36 | 32K | 4096 | ✅ | ✅ | ✅ |
| Qwen3-VL-Reranker-2B | 2B | 28 | 32K | - | - | - | ✅ |
| Qwen3-VL-Reranker-8B | 8B | 36 | 32K | - | - | - | ✅ |
2B 版本适合资源有限的场景,8B 版本追求极致性能。32K 的上下文长度意味着可以处理相当长的文档或视频。
架构设计
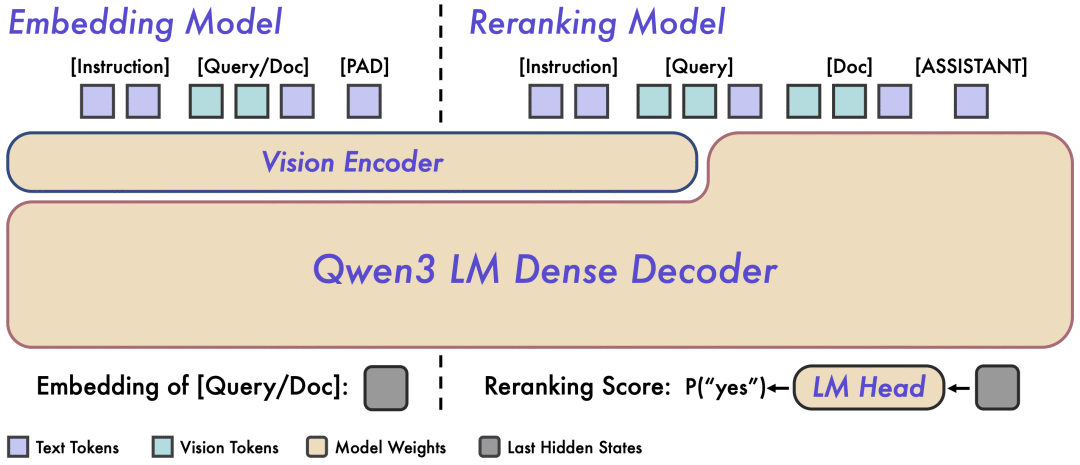
模型架构概览
Embedding 模型:双塔架构
采用经典的双塔设计,接收单模态或混合模态输入,映射到高维语义向量。具体是提取最后一层 [EOS] token 的隐藏状态作为最终语义表示。这种设计支持 Query 和 Document 独立编码,非常适合大规模检索场景的离线向量预计算。
Reranker 模型:单塔架构
接收 (Query, Document) 对,通过 Cross-Attention 机制实现更深层次的跨模态交互和信息融合。通过预测特殊 token(yes 和 no)的生成概率来输出相关性分数。这种设计牺牲了一些效率,换来更精准的语义匹配。
| Embedding 模型 | Reranker 模型 | |
|---|---|---|
| 核心功能 | 语义表示、向量生成 | 相关性打分、精确排序 |
| 输入 | 单模态或混合模态 | (Query, Document) 对 |
| 架构 | 双塔 | 单塔 |
| 机制 | 高效检索 | 深度跨模态交互 |
| 输出 | 语义向量 | 相关性分数 |
两个模型都采用多阶段训练范式,充分利用 Qwen3-VL 强大的多模态语义理解能力。
性能表现
这才是大家最关心的!直接看数据:
MMEB-V2 基准测试(多模态嵌入评测)
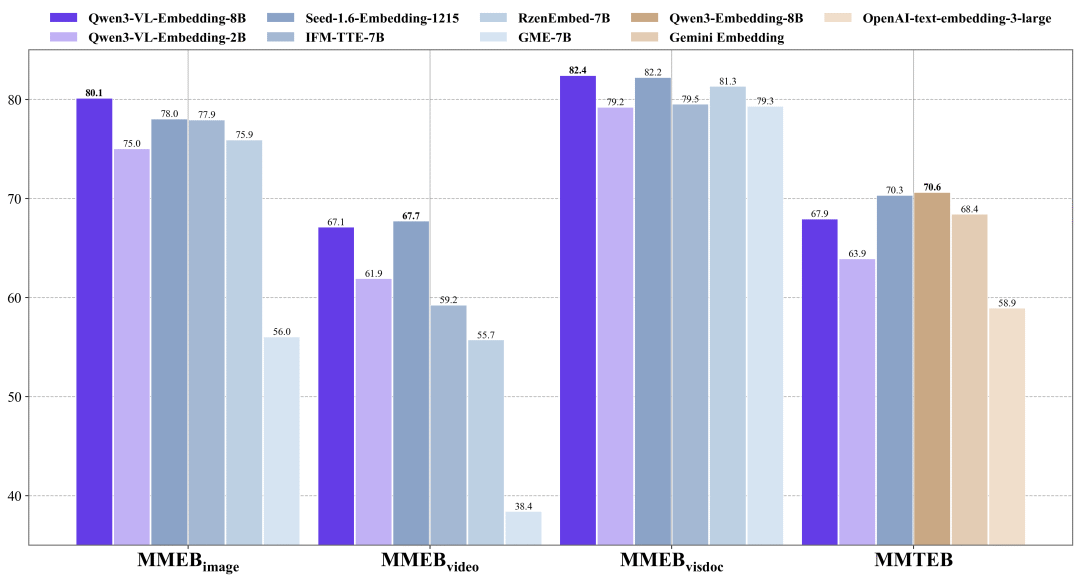
性能对比图
| 模型 | 参数量 | 图像整体 | 视频整体 | 视觉文档整体 | 总分 |
|---|---|---|---|---|---|
| VLM2Vec | 2B | 59.7 | 28.6 | 44.0 | 47.7 |
| GME-7B | 7B | 56.0 | 38.4 | 79.3 | 59.1 |
| IFM-TTE | 8B | 77.9 | 59.2 | 79.5 | 74.1 |
| Seed-1.6-embedding | unknown | 78.0 | 67.7 | 82.2 | 76.9 |
| Qwen3-VL-Embedding-2B | 2B | 75.0 | 61.9 | 79.2 | 73.2 |
| Qwen3-VL-Embedding-8B | 8B | 80.1 | 67.1 | 82.4 | 77.8 |
8B 版本以 77.8 分的总分拿下 SOTA!在图像、视频、视觉文档三个方向全面领先。2B 版本也相当能打,73.2 的分数超过了很多更大的模型。
MMTEB 基准测试(纯文本评测)
不仅多模态强,纯文本也不拉胯。8B 版本在纯文本检索上也有 67.88 的 Mean Task 分数,仅次于专门做文本嵌入的 Qwen3-Embedding 系列。
Reranker 性能
| 模型 | 参数量 | MMEB-v2 Avg | MMTEB | JinaVDR | ViDoRe(v3) |
|---|---|---|---|---|---|
| Qwen3-VL-Embedding-2B | 2B | 73.4 | 68.1 | 71.0 | 52.9 |
| jina-reranker-m0 | 2B | - | - | 82.2 | 57.8 |
| Qwen3-VL-Reranker-2B | 2B | 75.1 | 70.0 | 80.9 | 60.8 |
| Qwen3-VL-Reranker-8B | 8B | 79.2 | 74.9 | 83.6 | 66.7 |
Reranker 模型持续超越基础 Embedding 模型和其他重排序器,8B 版本在几乎所有任务上都是最佳表现。
安装与使用
安装非常简单:
# 克隆仓库git clone https://github.com/QwenLM/Qwen3-VL-Embedding.gitcd Qwen3-VL-Embedding# 一键环境配置bash scripts/setup_environment.sh# 激活环境source .venv/bin/activate
下载模型(从 Hugging Face):
uv pip install huggingface-hubhuggingface-cli download Qwen/Qwen3-VL-Embedding-2B --local-dir ./models/Qwen3-VL-Embedding-2B
或者从 ModelScope(国内用户更友好):
uv pip install modelscopemodelscope download --model qwen/Qwen3-VL-Embedding-2B --local_dir ./models/Qwen3-VL-Embedding-2B
Embedding 模型使用示例:
import torchfrom src.models.qwen3_vl_embedding import Qwen3VLEmbeddermodel = Qwen3VLEmbedder( model_name_or_path="./models/Qwen3-VL-Embedding-2B", # 开启 flash_attention_2 加速 # torch_dtype=torch.bfloat16, # attn_implementation="flash_attention_2")# 支持文本、图片、混合输入inputs = [{ "text": "A woman playing with her dog on a beach at sunset.", "instruction": "Retrieve images or text relevant to the user's query.",}, { "text": "一个女人和她的金毛犬在海边玩耍..."}, { "image": "https://example.com/demo.jpeg"}, { "text": "图文混合查询", "image": "https://example.com/demo.jpeg"}]embeddings = model.process(inputs)print(embeddings @ embeddings.T) # 计算相似度矩阵
Reranker 模型使用示例:
from src.models.qwen3_vl_reranker import Qwen3VLRerankermodel = Qwen3VLReranker( model_name_or_path="./models/Qwen3-VL-Reranker-2B",)inputs = { "instruction": "Retrieve images or text relevant to the user's query.", "query": {"text": "A woman playing with her dog on a beach at sunset."}, "documents": [ {"text": "文本文档..."}, {"image": "https://example.com/demo.jpeg"}, {"text": "图文混合文档", "image": "https://example.com/demo.jpeg"} ], "fps": 1.0, # 视频采样率 "max_frames": 64 # 最大帧数}scores = model.process(inputs)print(scores) # 输出各文档的相关性分数
vLLM 推理加速:
# 需要 vllm>=0.14.0from vllm import LLMmodel = LLM(model="Qwen/Qwen3-VL-Embedding-2B", runner="pooling")inputs = [ {"prompt": "文本查询"}, {"prompt": "<|vision_start|><|image_pad|><|vision_end|>", "multi_modal_data": {"image": image}},]outputs = model.embed(inputs)
适用场景
这套模型适合什么场景呢?
- 多模态 RAG:用文本检索图片、用图片检索视频、用图文混合查询检索文档
- 视觉文档检索:PDF、PPT、网页截图的语义检索
- 视频内容检索:根据文本描述找到相关视频片段
- 跨模态问答:VQA、图像问答等场景
- 电商/内容平台:以图搜图、以文搜图、智能推荐
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
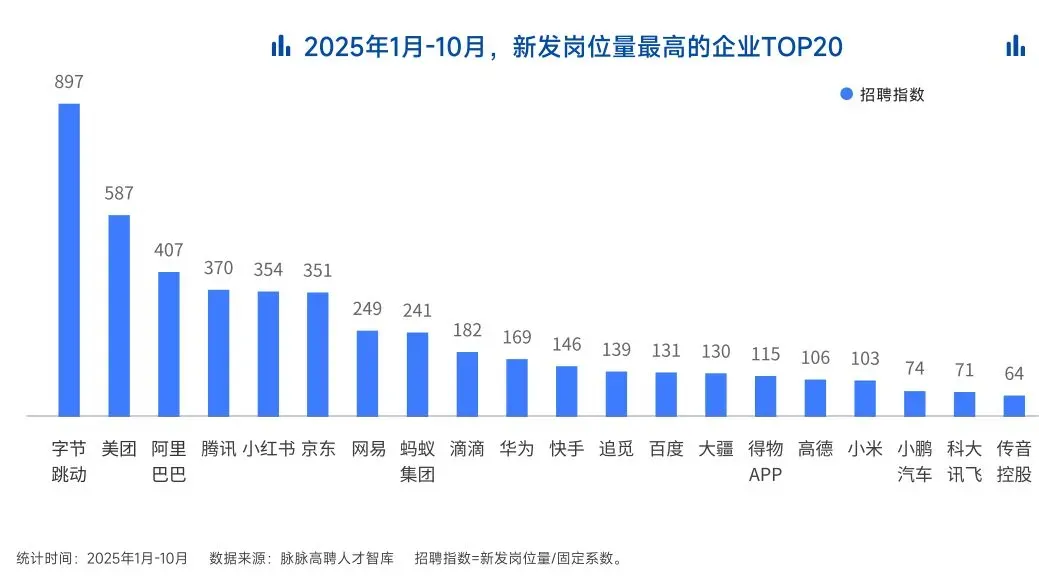
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献464条内容
已为社区贡献464条内容

所有评论(0)