【AI大模型前沿】HunyuanOCR:腾讯混元推出的高效端到端OCR视觉语言模型
HunyuanOCR 是腾讯混元团队推出的一款开源端到端OCR视觉语言模型,专为高效处理复杂文档和多语言文本设计。它依托混元原生多模态架构,仅用1B参数量就实现了多项OCR任务的SOTA性能。HunyuanOCR 支持文本检测与识别、复杂文档解析、开放字段信息抽取、视频字幕抽取以及图像文本翻译等功能,覆盖了经典OCR任务的全场景应用。其轻量化设计和强大的多语言支持能力,使其在实际应用中表现出色,广
系列篇章💥
前言
随着数字化转型的加速,文本识别与处理需求日益增长。腾讯混元团队推出的 HunyuanOCR,凭借其轻量化架构和强大的多模态处理能力,为复杂文档解析、信息提取等任务提供了高效解决方案,推动了OCR技术的发展。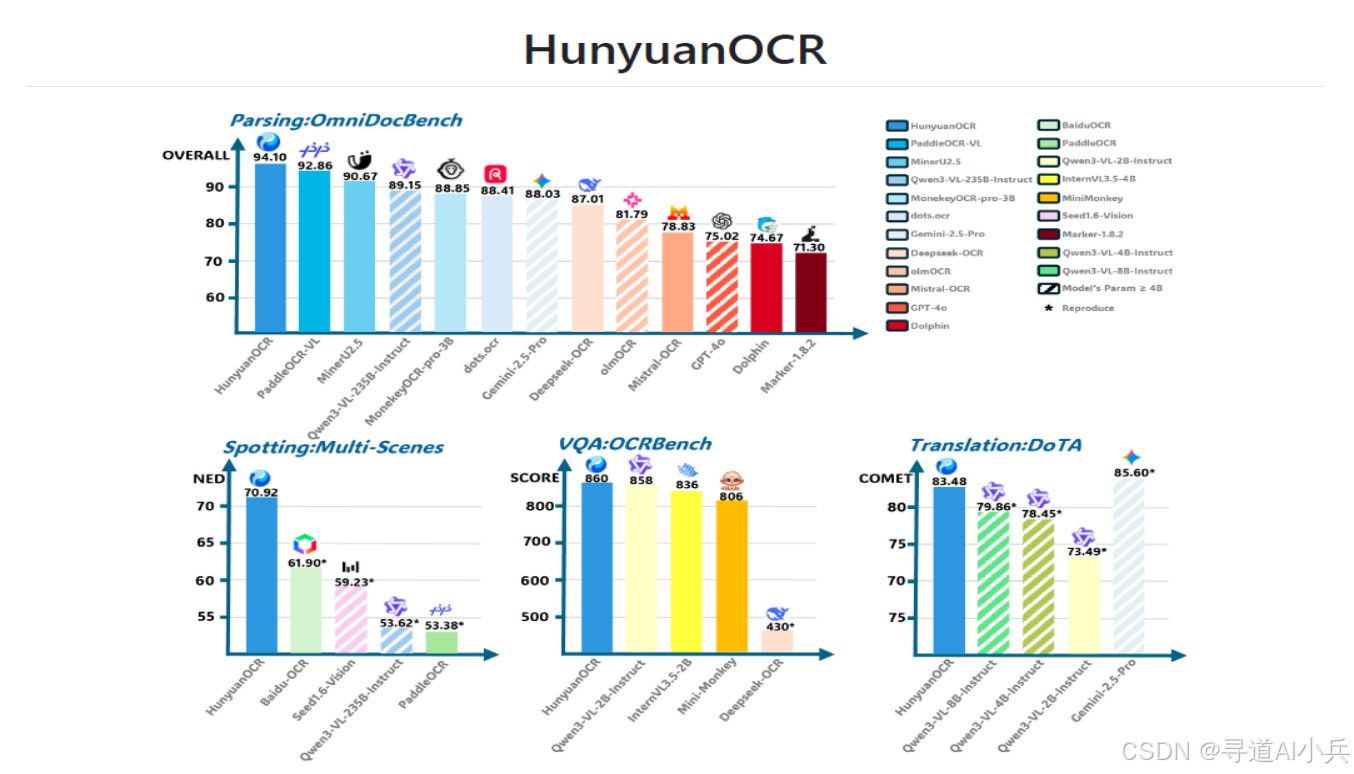
一、项目概述
HunyuanOCR 是腾讯混元团队推出的一款开源端到端OCR视觉语言模型,专为高效处理复杂文档和多语言文本设计。它依托混元原生多模态架构,仅用1B参数量就实现了多项OCR任务的SOTA性能。HunyuanOCR 支持文本检测与识别、复杂文档解析、开放字段信息抽取、视频字幕抽取以及图像文本翻译等功能,覆盖了经典OCR任务的全场景应用。其轻量化设计和强大的多语言支持能力,使其在实际应用中表现出色,广泛适用于文档处理、票据解析、视频内容创作等多个领域。
二、核心功能
(一)文本检测与识别
HunyuanOCR能够精准检测并识别图片中的文字,输出文本内容及其坐标信息。它适用于多种场景,包括文档、艺术字、街景、手写等。通过先进的视觉识别技术,模型可以快速定位并提取文字,为后续处理提供基础支持。
(二)复杂文档解析
HunyuanOCR支持多语种文档的电子化处理,能够将文档中的文本内容按阅读顺序组织,公式以LaTeX格式表示,表格以HTML格式表达。这一功能特别适合处理复杂的学术文档、报告等,帮助用户高效提取和利用文档信息。
(三)开放字段信息抽取
HunyuanOCR可以对常见卡证和票据中的感兴趣字段(如姓名、地址、金额等)进行标准JSON格式解析。这一功能极大地方便了信息提取和后续处理,广泛应用于财务、行政等领域,提高了工作效率。
(四)视频字幕抽取
HunyuanOCR能够自动化抽取视频中的字幕,支持单语和双语字幕。这一功能适用于视频内容制作和翻译场景,帮助视频创作者快速提取字幕,提升视频内容的可访问性和多语言支持。
(五)图像文本翻译
HunyuanOCR支持14种小语种(如德语、西班牙语、日语等)翻译成中文或英文,以及中英互译。这一功能特别适用于跨语言文档处理和交流,帮助用户突破语言障碍,实现信息的快速传递。
三、技术揭秘
(一)端到端架构
HunyuanOCR采用全端到端的训练和推理范式,模型直接从输入图像到输出结果,无需复杂的级联处理。这种架构设计显著提高了效率和准确性,避免了传统级联方案中常见的误差累积问题,使模型在多种OCR任务中表现出色。
(二)多模态融合
基于混元原生多模态架构,HunyuanOCR将视觉信息和语言信息深度融合。模型能够更好地理解和解析图像中的文本内容,支持复杂文档的多语言处理和信息提取,展现出强大的多模态交互能力。
(三)高质量数据训练
HunyuanOCR使用大规模高质量的应用导向数据进行训练,并结合在线强化学习。这种训练策略使模型在多种实际应用场景中表现出色,具有很强的泛化能力,能够适应不同的文档类型和语言环境。
(四)轻量化设计
HunyuanOCR仅使用1B参数量,通过高效的模型结构设计,在保持高性能的同时大幅降低了计算成本和部署难度。这种轻量化设计使其适合多种硬件环境,易于在实际应用中快速部署。
(五)多语言支持
HunyuanOCR支持100多种语言,能够处理单语言和多语言混合的复杂文档。通过优化语言理解和生成能力,模型在全球化应用场景中表现出色,适应不同语言环境下的文档处理需求。
四、基准评测/性能评估表现
(一)复杂文档解析基准
在业界普遍使用的 OmniDocBench 基准测试中,HunyuanOCR取得了94.1分的优异成绩,显著超越了DeepSeek-OCR、Gemini-3.0-Pro等竞品。此外,在多语言文档解析的内部基准测试中,HunyuanOCR也表现出了极低的编辑距离,证明了其在处理复杂多语言文档方面的强大能力。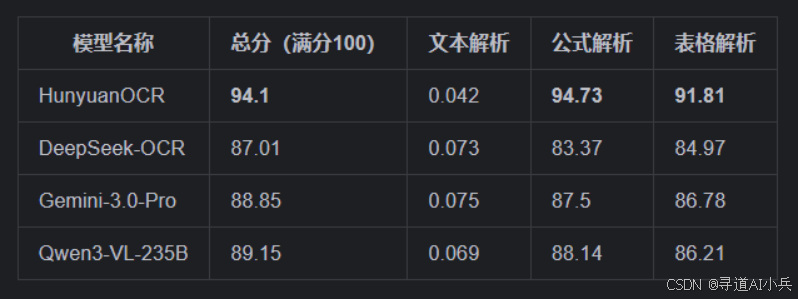
(二)文字检测和识别能力
HunyuanOCR在自建的覆盖9大应用场景(文档、艺术字、街景、手写、广告、票据、截屏、游戏、视频)的基准测试中,大幅度领先开源方案和商用OCR接口。这表明HunyuanOCR在多种复杂场景下都能高效准确地检测和识别文本。
(三)OCRBench榜单
在OCRBench榜单上,HunyuanOCR总得分为860分。尽管其参数量仅为1B,但该模型在总参数3B以下的模型中取得了SOTA成绩。这证明了HunyuanOCR在保持轻量化的同时,依然能够提供顶级的性能。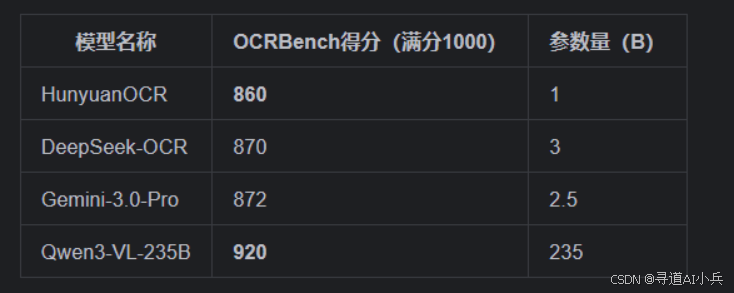
(四)小语种翻译能力
HunyuanOCR支持14种高频小语种翻译成中文或英文,并在ICDAR2025端到端文档图像翻译比赛的小模型赛道中获得冠军。这表明HunyuanOCR在跨语言文档处理方面具有显著优势。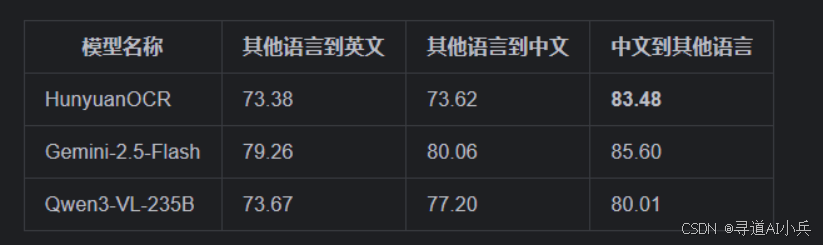
(五)信息抽取性能
在信息抽取任务的内部基准测试中,HunyuanOCR在卡片、票据和视频字幕提取等任务上均取得了优异成绩。例如,在处理卡片和票据时,HunyuanOCR的准确率分别达到了92.29%和92.53%,在视频字幕提取任务中,准确率达到了92.87%。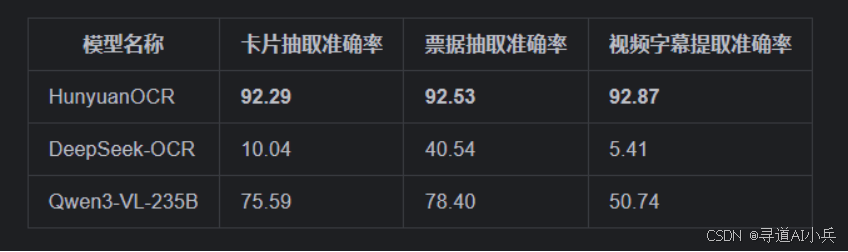
五、应用场景
(一)文档处理
HunyuanOCR能够高效处理多语种文档的电子化需求。它支持复杂文档解析,可将文档中的文本、公式(LaTeX格式)和表格(HTML格式)按阅读顺序提取和组织。这一功能广泛应用于学术研究、企业文档管理等领域,帮助用户快速将纸质文档转化为可编辑的电子格式。
(二)票据字段抽取
在财务和行政领域,HunyuanOCR可以快速准确地提取票据中的关键字段,如金额、日期、编号等。通过标准JSON格式输出,这些信息可直接用于数据录入和后续处理,极大提高了工作效率,减少了人工操作的错误率。
(三)视频字幕提取
HunyuanOCR能够自动化提取视频中的字幕,支持单语和双语字幕。这一功能适用于视频内容制作、翻译和字幕生成,帮助视频创作者快速提取字幕内容,提升视频的多语言支持能力,拓展视频内容的受众范围。
(四)拍照翻译
HunyuanOCR支持多种小语种的拍照翻译功能,可将图片中的文字翻译成中文或英文。这一功能特别适用于旅行、学习和跨语言交流场景,帮助用户快速获取和理解不同语言的文本信息。
(五)信息抽取
HunyuanOCR可以从图像中提取特定字段或信息,如从身份证、名片中提取姓名、地址等,并支持多种格式输出。这一功能广泛应用于信息录入、数据采集等领域,帮助用户快速提取关键信息。
(六)视频内容创作
对于视频创作者,HunyuanOCR能够快速提取视频中的文字内容,用于字幕制作和内容分析。这一功能帮助创作者高效处理视频中的文本信息,提升创作效率和内容质量。
(七)教育与学习
在教育领域,HunyuanOCR辅助学生和研究人员快速提取文献、教材中的关键信息,支持多语言学习和研究。它能够帮助用户快速获取和理解学术资料中的重要信息,提升学习和研究效率。
六、快速使用
(一)环境准备
HunyuanOCR的部署需要满足以下系统环境要求:
- 操作系统:Linux
- Python版本:3.12+(推荐并经过测试)
- CUDA版本:12.9
- PyTorch版本:2.7.1
- GPU:NVIDIA GPU,支持CUDA
- GPU显存:至少20GB(用于vLLM)
- 磁盘空间:至少6GB
(二)安装步骤
- 创建虚拟环境并激活:
uv venv hunyuanocr
source hunyuanocr/bin/activate
- 安装依赖库:
uv pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
uv pip install -r requirements.txt
- 安装CUDA兼容包(推荐):
sudo dpkg -i cuda-compat-12-9_575.57.08-0ubuntu1_amd64.deb
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.9/compat:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
# 验证cuda-compat-12-9安装
ls /usr/local/cuda-12.9/compat
(三)模型部署与推理
- 模型部署:
使用vLLM框架部署HunyuanOCR模型:
vllm serve tencent/HunyuanOCR \
--no-enable-prefix-caching \
--mm-processor-cache-gb 0 \
--gpu-memory-utilization 0.2
- 模型推理:
使用Python脚本进行推理,示例代码如下:
from vllm import LLM, SamplingParams
from PIL import Image
from transformers import AutoProcessor
def clean_repeated_substrings(text):
"""清理文本中的重复子字符串"""
n = len(text)
if n < 8000:
return text
for length in range(2, n // 10 + 1):
candidate = text[-length:]
count = 0
i = n - length
while i >= 0 and text[i:i + length] == candidate:
count += 1
i -= length
if count >= 10:
return text[:n - length * (count - 1)]
return text
model_path = "tencent/HunyuanOCR"
llm = LLM(model=model_path, trust_remote_code=True)
processor = AutoProcessor.from_pretrained(model_path)
sampling_params = SamplingParams(temperature=0, max_tokens=16384)
img_path = "/path/to/image.jpg"
img = Image.open(img_path)
messages = [
{"role": "system", "content": ""},
{"role": "user", "content": [
{"type": "image", "image": img_path},
{"type": "text", "text": "检测并识别图片中的文字,将文本坐标格式化输出。"}
]}
]
prompt = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = {"prompt": prompt, "multi_modal_data": {"image": [img]}}
output = llm.generate([inputs], sampling_params)[0]
print(clean_repeated_substrings(output.outputs[0].text))
- 使用提供的示例脚本:
如果需要快速测试,可以直接使用项目提供的示例脚本:
cd Hunyuan-OCR-master/Hunyuan-OCR-vllm && python run_hy_ocr.py
七、结语
HunyuanOCR凭借其轻量化架构和强大的多模态处理能力,在OCR领域展现了卓越性能和广泛的应用前景。它为开发者和企业提供了高效、便捷的文本识别与处理解决方案,推动了OCR技术的发展和应用。
八、项目地址
- 项目官网:https://hunyuan.tencent.com/vision/zh?tabIndex=0
- Github仓库:https://github.com/Tencent-Hunyuan/HunyuanOCR
- Huggingface模型库:https://huggingface.co/tencent/HunyuanOCR
- 技术报告:https://github.com/Tencent-Hunyuan/HunyuanOCR/blob/main/HunyuanOCR_Technical_Report.pdf
- 在线体验:https://huggingface.co/spaces/tencent/HunyuanOCR

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 29
29 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)