Spring AI框架下RAG模式的基本实现方式,包括文档存储、相似性
摘要 该代码展示了如何使用ChatClient进行检索增强生成(RAG)实现问答功能。主要特点包括: 初始化阶段存储了两类文档向量:航班预订和取消预订的相关政策信息 测试方法testRag演示了通过QuestionAnswerAdvisor进行相似性检索,设置topK=5和相似度阈值0.6 testRag2展示了更宽松的相似度阈值(0.1)配置 使用DashScopeChatModel作为基础模型
通过ChatClient进行相似性检索增强
package com.xushu.springai.rag;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import com.alibaba.cloud.ai.dashscope.embedding.DashScopeEmbeddingModel;
import org.apache.el.lang.ExpressionBuilder;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.client.advisor.api.Advisor;
import org.springframework.ai.chat.client.advisor.vectorstore.QuestionAnswerAdvisor;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.model.transformer.KeywordMetadataEnricher;
import org.springframework.ai.rag.Query;
import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;
import org.springframework.ai.rag.generation.augmentation.ContextualQueryAugmenter;
import org.springframework.ai.rag.preretrieval.query.transformation.QueryTransformer;
import org.springframework.ai.rag.preretrieval.query.transformation.RewriteQueryTransformer;
import org.springframework.ai.rag.preretrieval.query.transformation.TranslationQueryTransformer;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.filter.FilterExpressionBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.boot.test.context.TestConfiguration;
import org.springframework.context.annotation.Bean;
import java.util.List;
@SpringBootTest
public class ChatClientRagTest {
ChatClient chatClient;
@BeforeEach
public void init(
@Autowired DashScopeChatModel chatModel,
@Autowired VectorStore vectorStore) {
Document doc = Document.builder()
.text("""
预订航班:
- 通过我们的网站或移动应用程序预订。
- 预订时需要全额付款。
- 确保个人信息(姓名、ID 等)的准确性,因为更正可能会产生 25 的费用。
""")
.build();
Document doc2 = Document.builder()
.text("""
取消预订:
- 最晚在航班起飞前 48 小时取消。
- 取消费用:经济舱 75 美元,豪华经济舱 50 美元,商务舱 25 美元。
- 退款将在 7 个工作日内处理。
""")
.build();
List<Document> documents = List.of(doc, doc2);
// 存储向量(内部会自动向量化)
vectorStore.add(documents);
}
@Test
public void testRag(
@Autowired DashScopeChatModel dashScopeChatModel,
@Autowired VectorStore vectorStore) {
chatClient = ChatClient.builder(dashScopeChatModel)
.defaultAdvisors(SimpleLoggerAdvisor.builder().build())
.build();
String content = chatClient.prompt()
.user("退票需要多少费用?")
.advisors(
SimpleLoggerAdvisor.builder().build(),
QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(
SearchRequest.builder()
.topK(5)
.similarityThreshold(0.6)
.build()
).build()
)
.call()
.content();
System.out.println(content);
}
@Test
public void testRag2(
@Autowired DashScopeChatModel dashScopeChatModel,
@Autowired VectorStore vectorStore) {
chatClient = ChatClient.builder(dashScopeChatModel)
.defaultAdvisors(SimpleLoggerAdvisor.builder().build())
.build();
//FilterExpression基于元数据过滤搜索结果的参数
String content = chatClient.prompt()
.user("退票需要多少费用?")
.advisors(
SimpleLoggerAdvisor.builder().build(),
QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(
SearchRequest.builder()
.topK(5)
.similarityThreshold(0.1)
//.filterExpression()
.build()
).build()
)
.call()
.content();
System.out.println(content);
}
@Test
public void testRag3(@Autowired VectorStore vectorStore,
@Autowired DashScopeChatModel dashScopeChatModel) {
chatClient = ChatClient.builder(dashScopeChatModel)
.defaultAdvisors(SimpleLoggerAdvisor.builder().build())
.build();
// 增强多
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
// 查 = QuestionAnswerAdvisor
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.0)
// .topK()
// .filterExpression()
.vectorStore(vectorStore)
.build())
// 检索为空时,allowEmptyContext=false返回提示 allowEmptyContext=true 正常回答
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(false)
.emptyContextPromptTemplate(PromptTemplate.builder().template("用户查询位于知识库之外。礼貌地告知用户您无法回答").build())
.build())
// 检索查询转换器
// 重写检索查询转换器
.queryTransformers(RewriteQueryTransformer.builder()
.chatClientBuilder(ChatClient.builder(dashScopeChatModel))
.targetSearchSystem("航空票务助手")
.build())
// 翻译转换器
.queryTransformers(TranslationQueryTransformer.builder()
.chatClientBuilder(ChatClient.builder(dashScopeChatModel))
.targetLanguage("english")
.build())
// 检索后文档监控、操作
.documentPostProcessors((query, documents) -> {
System.out.println("Original query: " + query.text());
System.out.println("Retrieved documents: " + documents.size());
return documents;
})
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user("我今天心情不好,不想去玩了,你能不能告诉我退票需要多少钱?")
.call()
.content();
System.out.println(answer);
}
@TestConfiguration
static class TestConfig {
@Bean
public VectorStore vectorStore(DashScopeEmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}
}
}
ChatClientRagTest 知识点与原理分析
文件路径:
09rag/src/test/java/com/xushu/springai/rag/ChatClientRagTest.java
Spring AI 版本: 1.0.0
分析日期: 2025年1月
📋 目录
概述
ChatClientRagTest 是 Spring AI RAG 的核心测试类,演示了从简单到高级的 RAG 使用方式。它展示了如何将向量检索与 LLM 生成结合,实现基于知识库的智能问答系统。
测试方法概览
| 方法 | 功能 | 核心组件 | 特点 |
|---|---|---|---|
testRag() |
简单 RAG | QuestionAnswerAdvisor |
基础检索增强 |
testRag2() |
元数据过滤 RAG | QuestionAnswerAdvisor + filterExpression |
支持元数据过滤 |
testRag3() |
高级 RAG | RetrievalAugmentationAdvisor |
查询转换、后处理等 |
RAG 在 Spring AI 中的位置
用户查询
↓
ChatClient.prompt()
↓
Advisor 链(RAG Advisor)
↓
向量检索 → 上下文增强
↓
LLM 生成回答
↓
返回答案
核心知识点
1. ChatClient 架构
1.1 ChatClient 是什么?
ChatClient 是 Spring AI 提供的高级 API,用于简化与 LLM 的交互。
核心特性:
- ✅ 流式 API:支持流式对话
- ✅ Advisor 机制:支持插件式增强
- ✅ 工具集成:支持 Function-Call
- ✅ 内存管理:支持对话历史
1.2 Advisor 机制
Advisor 是什么?
- Advisor 是 Spring AI 中的拦截器模式实现
- 可以在请求前后进行拦截和处理
- 支持责任链模式,可以组合多个 Advisor
RAG Advisor 的作用:
用户查询 → Advisor.before() → 向量检索 → 上下文增强 → LLM 调用
2. RAG 核心概念
2.1 什么是 RAG?
RAG(Retrieval-Augmented Generation):
- 检索(Retrieval):从知识库中检索相关文档
- 增强(Augmentation):将检索到的文档作为上下文注入
- 生成(Generation):基于增强后的上下文生成回答
2.2 RAG 的优势
| 优势 | 说明 |
|---|---|
| 知识更新 | 可以随时更新知识库,无需重新训练模型 |
| 准确性提升 | 基于真实文档回答,减少幻觉 |
| 可追溯性 | 可以追溯到答案的来源文档 |
| 领域适应 | 可以快速适配特定领域 |
3. 向量检索原理
3.1 相似度检索
工作流程:
1. 用户查询:"退票需要多少费用?"
2. 向量化查询:embeddingModel.embed(query) → [0.1, 0.2, ...]
3. 向量检索:vectorStore.similaritySearch(queryVector)
4. 相似度计算:cosine_similarity(queryVector, docVector)
5. 排序返回:按相似度从高到低排序
3.2 相似度阈值
similarityThreshold:
- 作用:过滤低相似度的文档
- 范围:通常 0.0 - 1.0
- 建议:
- 严格过滤:0.6 - 0.8
- 宽松过滤:0.3 - 0.5
- 不过滤:0.0
使用特性详解
特性 1: 简单 RAG(QuestionAnswerAdvisor)
代码示例
@Test
public void testRag(
@Autowired DashScopeChatModel dashScopeChatModel,
@Autowired VectorStore vectorStore) {
chatClient = ChatClient.builder(dashScopeChatModel)
.defaultAdvisors(SimpleLoggerAdvisor.builder().build())
.build();
String content = chatClient.prompt()
.user("退票需要多少费用?")
.advisors(
SimpleLoggerAdvisor.builder().build(),
QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(
SearchRequest.builder()
.topK(5) // 返回前 5 个最相似的文档
.similarityThreshold(0.6) // 相似度阈值,低于此值的文档会被过滤
.build()
).build()
)
.call()
.content();
System.out.println(content);
}
配置选项
| 配置项 | 类型 | 说明 | 默认值 |
|---|---|---|---|
topK |
int |
返回最相似的文档数量 | 4 |
similarityThreshold |
double |
相似度阈值,低于此值的文档会被过滤 | 0.0 |
filterExpression |
String |
基于元数据的过滤表达式 | null |
工作流程
1. 用户查询:"退票需要多少费用?"
↓
2. 向量化查询
↓
3. 相似度检索(topK=5, threshold=0.6)
↓
4. 过滤低相似度文档
↓
5. 构建增强 Prompt:
"""
基于以下文档回答问题:
文档1: 取消预订: 最晚在航班起飞前 48 小时取消。取消费用:经济舱 75 美元...
问题:退票需要多少费用?
"""
↓
6. 调用 LLM 生成回答
↓
7. 返回答案
特性说明
优点:
- ✅ 简单易用:配置简单,开箱即用
- ✅ 性能好:直接检索,无额外处理
- ✅ 适合简单场景:满足大多数基础需求
限制:
- ❌ 功能有限:不支持查询转换、后处理等
- ❌ 配置简单:无法进行复杂定制
适用场景:
- 简单的问答系统
- 快速原型开发
- 基础知识库查询
特性 2: 元数据过滤 RAG
代码示例
@Test
public void testRag2(
@Autowired DashScopeChatModel dashScopeChatModel,
@Autowired VectorStore vectorStore) {
chatClient = ChatClient.builder(dashScopeChatModel)
.defaultAdvisors(SimpleLoggerAdvisor.builder().build())
.build();
String content = chatClient.prompt()
.user("退票需要多少费用?")
.advisors(
SimpleLoggerAdvisor.builder().build(),
QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(
SearchRequest.builder()
.topK(5)
.similarityThreshold(0.1)
// .filterExpression() // 基于元数据过滤
.build()
).build()
)
.call()
.content();
System.out.println(content);
}
元数据过滤语法
FilterExpression 语法:
// 方式 1:精确匹配
.filterExpression("category == '退票'")
// 方式 2:包含匹配
.filterExpression("excerpt_keywords in ('退票', '费用')")
// 方式 3:组合条件
.filterExpression("category == '退票' AND filename == 'terms.txt'")
// 方式 4:范围匹配
.filterExpression("score >= 0.6 AND score <= 1.0")
使用示例:
SearchRequest.builder()
.topK(5)
.similarityThreshold(0.6)
.filterExpression("excerpt_keywords in ('退票')") // 只检索包含"退票"关键词的文档
.build()
特性说明
优点:
- ✅ 精确过滤:可以基于元数据精确过滤文档
- ✅ 提高精度:减少无关文档的干扰
- ✅ 灵活组合:支持复杂的过滤条件
适用场景:
- 需要按类别过滤的场景
- 需要按关键词过滤的场景
- 多知识库场景
特性 3: 高级 RAG(RetrievalAugmentationAdvisor)
代码示例
@Test
public void testRag3(@Autowired VectorStore vectorStore,
@Autowired DashScopeChatModel dashScopeChatModel) {
chatClient = ChatClient.builder(dashScopeChatModel)
.defaultAdvisors(SimpleLoggerAdvisor.builder().build())
.build();
// 构建高级 RAG Advisor
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
// 1. 文档检索器
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.0)
.topK(5)
// .filterExpression() // 基于元数据过滤
.vectorStore(vectorStore)
.build())
// 2. 查询增强器:处理检索为空的情况
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(false) // 检索为空时,false 返回提示,true 正常回答
.emptyContextPromptTemplate(
PromptTemplate.builder()
.template("用户查询位于知识库之外。礼貌地告知用户您无法回答")
.build()
)
.build())
// 3. 查询转换器:重写查询
.queryTransformers(RewriteQueryTransformer.builder()
.chatClientBuilder(ChatClient.builder(dashScopeChatModel))
.targetSearchSystem("航空票务助手")
.build())
// 4. 查询转换器:翻译查询
.queryTransformers(TranslationQueryTransformer.builder()
.chatClientBuilder(ChatClient.builder(dashScopeChatModel))
.targetLanguage("english")
.build())
// 5. 文档后处理器:检索后对文档进行处理
.documentPostProcessors((query, documents) -> {
System.out.println("Original query: " + query.text());
System.out.println("Retrieved documents: " + documents.size());
// 可以在这里对文档进行过滤、排序、去重等操作
return documents;
})
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user("我今天心情不好,不想去玩了,你能不能告诉我退票需要多少钱?")
.call()
.content();
System.out.println(answer);
}
组件详解
3.1 文档检索器(Document Retriever)
VectorStoreDocumentRetriever:
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.0) // 相似度阈值
.topK(5) // 返回文档数量
.filterExpression("...") // 元数据过滤
.vectorStore(vectorStore) // 向量存储
.build())
功能:
- 向量化查询
- 相似度检索
- 元数据过滤
- 返回相关文档列表
3.2 查询增强器(Query Augmenter)
ContextualQueryAugmenter:
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(false) // 检索为空时的处理策略
.emptyContextPromptTemplate(...) // 空上下文时的提示模板
.build())
allowEmptyContext 选项:
| 值 | 行为 | 适用场景 |
|---|---|---|
false |
检索为空时返回提示信息 | 严格的知识库场景 |
true |
检索为空时正常回答(可能产生幻觉) | 宽松的场景 |
使用场景:
- false(推荐):企业知识库、客服系统
- true:通用问答、需要兜底的场景
3.3 查询转换器(Query Transformers)
RewriteQueryTransformer(查询重写):
.queryTransformers(RewriteQueryTransformer.builder()
.chatClientBuilder(ChatClient.builder(dashScopeChatModel))
.targetSearchSystem("航空票务助手") // 目标搜索系统
.build())
作用:
- 将用户自然语言查询重写为更适合检索的查询
- 提取关键信息,去除无关内容
示例:
原始查询:"我今天心情不好,不想去玩了,你能不能告诉我退票需要多少钱?"
重写后:"退票费用"
TranslationQueryTransformer(查询翻译):
.queryTransformers(TranslationQueryTransformer.builder()
.chatClientBuilder(ChatClient.builder(dashScopeChatModel))
.targetLanguage("english") // 目标语言
.build())
作用:
- 将查询翻译为其他语言
- 适用于多语言知识库
使用场景:
- 多语言知识库
- 跨语言检索
3.4 文档后处理器(Document Post Processors)
功能:
.documentPostProcessors((query, documents) -> {
// 1. 监控检索结果
System.out.println("Original query: " + query.text());
System.out.println("Retrieved documents: " + documents.size());
// 2. 过滤文档
// documents = documents.stream()
// .filter(doc -> doc.getScore() > 0.7)
// .collect(Collectors.toList());
// 3. 排序文档
// documents.sort((a, b) -> Double.compare(b.getScore(), a.getScore()));
// 4. 去重文档
// documents = removeDuplicates(documents);
return documents;
})
常见操作:
- 过滤:基于相似度分数过滤
- 排序:重新排序文档
- 去重:去除重复文档
- 监控:记录检索日志
特性说明
优点:
- ✅ 功能强大:支持查询转换、后处理等
- ✅ 灵活定制:可以自定义各个环节
- ✅ 适合复杂场景:满足企业级需求
限制:
- ❌ 配置复杂:需要理解各个组件
- ❌ 性能开销:查询转换需要额外 LLM 调用
适用场景:
- 企业级知识库系统
- 复杂的问答场景
- 需要精细控制的场景
RAG 工作流程
简单 RAG 流程
用户查询
↓
QuestionAnswerAdvisor.before()
↓
向量化查询
↓
向量检索(topK=5, threshold=0.6)
↓
过滤低相似度文档
↓
构建增强 Prompt
↓
调用 LLM
↓
返回答案
高级 RAG 流程
用户查询
↓
RetrievalAugmentationAdvisor.before()
↓
查询转换器(RewriteQueryTransformer)
↓
查询转换器(TranslationQueryTransformer)
↓
文档检索器(VectorStoreDocumentRetriever)
↓
向量检索
↓
文档后处理器(Document Post Processors)
↓
查询增强器(ContextualQueryAugmenter)
├─ 检索为空?
│ ├─ allowEmptyContext=false → 返回提示
│ └─ allowEmptyContext=true → 继续
↓
构建增强 Prompt
↓
调用 LLM
↓
返回答案
上下文注入机制
Prompt 模板:
基于以下文档回答问题:
文档1: [检索到的文档内容1]
文档2: [检索到的文档内容2]
...
问题:{用户查询}
实际示例:
基于以下文档回答问题:
文档1: 取消预订: 最晚在航班起飞前 48 小时取消。取消费用:经济舱 75 美元,豪华经济舱 50 美元,商务舱 25 美元。退款将在 7 个工作日内处理。
问题:退票需要多少费用?
代码分析
整体架构
ChatClientRagTest
├── @BeforeEach init() → 初始化向量库
├── testRag() → 简单 RAG
├── testRag2() → 元数据过滤 RAG
└── testRag3() → 高级 RAG
初始化流程
@BeforeEach
public void init(
@Autowired DashScopeChatModel chatModel,
@Autowired VectorStore vectorStore) {
// 1. 创建测试文档
Document doc = Document.builder()
.text("预订航班: ...")
.build();
Document doc2 = Document.builder()
.text("取消预订: ...")
.build();
// 2. 存储到向量库(内部自动向量化)
vectorStore.add(List.of(doc, doc2));
}
说明:
@BeforeEach:每个测试方法执行前都会运行vectorStore.add():内部会自动向量化文档- 为后续测试准备数据
设计模式
1. Builder 模式
QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder()
.topK(5)
.similarityThreshold(0.6)
.build())
.build()
优势:
- 链式调用,代码清晰
- 可选参数灵活
- 配置对象不可变
2. 责任链模式
chatClient.prompt()
.advisors(
SimpleLoggerAdvisor.builder().build(), // Advisor 1
QuestionAnswerAdvisor.builder(...).build() // Advisor 2
)
优势:
- 可以组合多个 Advisor
- 每个 Advisor 独立处理
- 支持动态添加/移除
3. 策略模式
不同的 Advisor 实现不同的策略:
QuestionAnswerAdvisor:简单检索策略RetrievalAugmentationAdvisor:高级检索策略
数据流
用户查询
↓
ChatClient.prompt().user("...")
↓
Advisor 链处理
↓
向量检索 → 文档列表
↓
上下文增强 → 增强 Prompt
↓
LLM 调用 → ChatResponse
↓
提取内容 → String
最佳实践
1. Advisor 选择
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 简单问答 | QuestionAnswerAdvisor |
简单高效 |
| 需要元数据过滤 | QuestionAnswerAdvisor + filterExpression |
支持过滤 |
| 复杂场景 | RetrievalAugmentationAdvisor |
功能强大 |
| 需要查询转换 | RetrievalAugmentationAdvisor |
支持转换 |
2. 参数配置建议
topK 选择:
// 场景 1:简单问答(推荐)
.topK(3-5) // 返回 3-5 个文档
// 场景 2:复杂问答
.topK(5-10) // 返回 5-10 个文档
// 场景 3:需要更多上下文
.topK(10-20) // 返回 10-20 个文档
similarityThreshold 选择:
// 场景 1:严格过滤(推荐)
.similarityThreshold(0.6-0.8) // 只返回高相似度文档
// 场景 2:宽松过滤
.similarityThreshold(0.3-0.5) // 返回中等相似度文档
// 场景 3:不过滤
.similarityThreshold(0.0) // 返回所有文档
3. 查询转换器使用
何时使用 RewriteQueryTransformer:
- ✅ 用户查询包含大量无关信息
- ✅ 需要提取关键信息
- ✅ 查询语言不规范
何时使用 TranslationQueryTransformer:
- ✅ 多语言知识库
- ✅ 跨语言检索需求
性能考虑:
- ⚠️ 查询转换需要额外的 LLM 调用
- ⚠️ 会增加延迟和成本
- ⚠️ 只在必要时使用
4. 空上下文处理
推荐配置:
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(false) // 严格模式
.emptyContextPromptTemplate(
PromptTemplate.builder()
.template("抱歉,我无法在知识库中找到相关信息。请尝试换一种方式提问。")
.build()
)
.build())
原因:
- 避免产生幻觉
- 提供明确的反馈
- 提高用户体验
5. 文档后处理
常见操作:
.documentPostProcessors((query, documents) -> {
// 1. 过滤低分文档
documents = documents.stream()
.filter(doc -> doc.getScore() > 0.7)
.collect(Collectors.toList());
// 2. 限制文档数量
if (documents.size() > 5) {
documents = documents.subList(0, 5);
}
// 3. 记录日志
log.info("Query: {}, Retrieved: {} documents", query.text(), documents.size());
return documents;
})
6. 错误处理
try {
String answer = chatClient.prompt()
.user("退票需要多少费用?")
.advisors(questionAnswerAdvisor)
.call()
.content();
System.out.println(answer);
} catch (Exception e) {
log.error("RAG 处理失败", e);
// 返回默认回答或错误提示
}
常见问题
Q1: topK 应该设置多大?
建议:
- 简单问答:3-5 个文档
- 复杂问答:5-10 个文档
- 需要详细上下文:10-20 个文档
考虑因素:
- LLM 上下文窗口限制
- 文档平均长度
- 回答质量要求
Q2: similarityThreshold 如何设置?
建议:
- 严格场景:0.6-0.8(只返回高相似度文档)
- 一般场景:0.3-0.5(返回中等相似度文档)
- 宽松场景:0.0(返回所有文档)
调试方法:
// 先设置为 0.0,查看所有文档的相似度分数
.similarityThreshold(0.0)
// 然后根据实际分数调整阈值
Q3: 何时使用查询转换器?
使用场景:
- ✅ 用户查询包含大量无关信息
- ✅ 需要提取关键信息
- ✅ 查询语言不规范
不使用场景:
- ❌ 查询已经很简洁
- ❌ 对延迟敏感
- ❌ 成本敏感
Q4: allowEmptyContext 如何选择?
推荐:
- 企业知识库:
false(严格模式) - 通用问答:
true(宽松模式)
原因:
false:避免产生幻觉,提供明确反馈true:提供兜底回答,但可能不准确
Q5: 如何提高检索精度?
优化策略:
- 调整 topK:增加检索文档数量
- 调整 threshold:提高相似度阈值
- 使用元数据过滤:精确过滤文档
- 使用查询转换:优化查询语句
- 使用文档后处理:过滤、排序文档
Q6: 如何调试 RAG?
调试方法:
// 1. 使用 SimpleLoggerAdvisor 查看日志
.defaultAdvisors(SimpleLoggerAdvisor.builder().build())
// 2. 在文档后处理器中打印信息
.documentPostProcessors((query, documents) -> {
System.out.println("Query: " + query.text());
System.out.println("Retrieved: " + documents.size());
documents.forEach(doc -> {
System.out.println("Score: " + doc.getScore());
System.out.println("Text: " + doc.getText().substring(0, 100));
});
return documents;
})
// 3. 查看增强后的 Prompt
// 在 SimpleLoggerAdvisor 的日志中可以看到完整的 Prompt
总结
核心要点
- 选择合适的 Advisor:根据场景选择简单或高级 Advisor
- 合理配置参数:topK、similarityThreshold 等
- 使用查询转换:在必要时优化查询
- 处理空上下文:避免产生幻觉
- 文档后处理:过滤、排序、去重等
学习路径
- ✅ 掌握简单 RAG(QuestionAnswerAdvisor)
- ✅ 理解元数据过滤
- ✅ 学习高级 RAG(RetrievalAugmentationAdvisor)
- ✅ 实践查询转换和后处理
- ✅ 优化检索精度
下一步
- 📖 学习重排序(Rerank)
- 📖 学习 RAG 评估(Evaluation)
- 📖 学习流式 RAG
- 📖 学习多轮对话 RAG
相关文件:
ReaderTest.java- 文档读取测试SplitterTest.java- 文档分割测试VectorStoreTest.java- 向量存储测试RerankTest.java- 重排序测试
文本读取器
package com.xushu.springai.rag.ELT;
import org.junit.jupiter.api.Test;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.ExtractedTextFormatter;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.reader.markdown.MarkdownDocumentReader;
import org.springframework.ai.reader.markdown.config.MarkdownDocumentReaderConfig;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.reader.pdf.ParagraphPdfDocumentReader;
import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.core.io.Resource;
import java.io.IOException;
import java.util.List;
@SpringBootTest
public class ReaderTest {
@Test
public void testReaderText(@Value("classpath:rag/terms-of-service.txt") Resource resource) {
TextReader textReader = new TextReader(resource);
List<Document> documents = textReader.read();
for (Document document : documents) {
System.out.println(document.getText());
}
}
@Test
public void testReaderMD(@Value("classpath:rag/9_横店影视股份有限公司_0.md") Resource resource) {
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(false) // 分割线创建新document false:不会 true:会
.withIncludeCodeBlock(false) // 代码创建新document false:会
.withIncludeBlockquote(false) // 引用创建新document false:会
.withAdditionalMetadata("filename", resource.getFilename()) // 每个document添加的元数据
.build();
MarkdownDocumentReader markdownDocumentReader = new MarkdownDocumentReader(resource, config);
List<Document> documents = markdownDocumentReader.read();
for (Document document : documents) {
System.out.println(document.getText());
}
}
@Test
public void testReaderPdf(@Value("classpath:rag/平安银行2023年半年度报告摘要.pdf") Resource resource) {
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(resource,
PdfDocumentReaderConfig.builder().build());
List<Document> documents = pdfReader.read();
for (Document document : documents) {
System.out.println(document.getText());
}
}
// 必需要带目录, 按pdf的目录分document
@Test
public void testReaderParagraphPdf(@Value("classpath:rag/平安银行2023年半年度报告.pdf") Resource resource) {
ParagraphPdfDocumentReader pdfReader = new ParagraphPdfDocumentReader(resource,
PdfDocumentReaderConfig.builder()
// 不同的PDF生成工具可能使用不同的坐标系 , 如果内容识别有问题, 可以设置该属性为true
.withReversedParagraphPosition(true)
.withPageTopMargin(0) // 上边距
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
// 从页面文本中删除前 N 行
.withNumberOfTopTextLinesToDelete(0)
.build())
.build());
List<Document> documents = pdfReader.read();
for (Document document : documents) {
System.out.println(document.getText());
}
}
}
ELT
在之前,我们主要完成了数据检索阶段,但是完整的RAG流程还需要有emedding阶段,即:
提取(读取)、转换(分隔)和加载(写入)
- Document Loaders 文档读取器
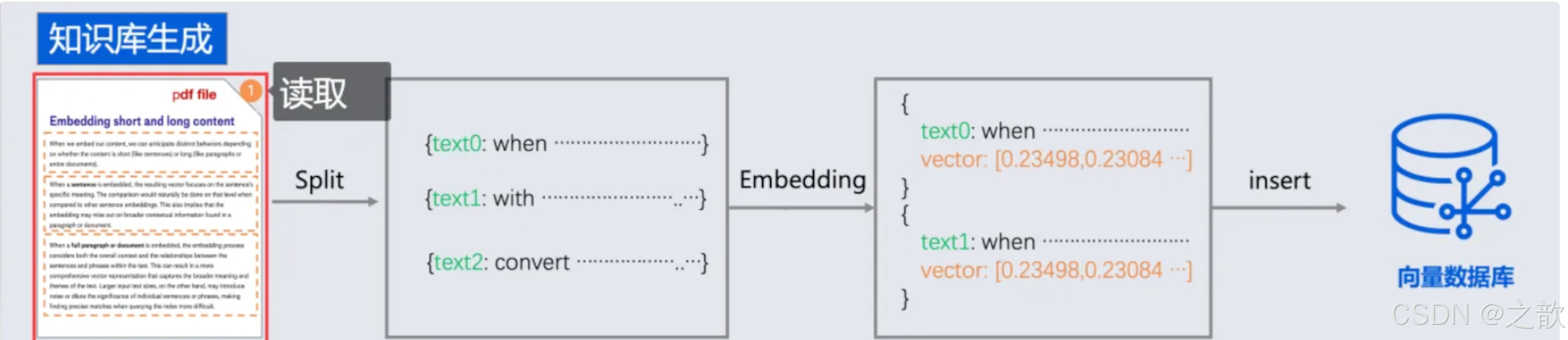
springai提供了以下文档阅读器
读取markdown .
ReaderTest 知识点与使用特性分析
📋 目录
概述
ReaderTest 是 Spring AI RAG 中 文档读取(Extract) 阶段的测试类,演示了如何从不同格式的文件中提取文本并转换为 Document 对象。这是 RAG 流程的第一步,为后续的向量化和检索奠定基础。
测试方法概览
| 方法 | 功能 | 文件格式 | 特点 |
|---|---|---|---|
testReaderText() |
文本文件读取 | .txt |
最简单,无配置 |
testReaderMD() |
Markdown 文件读取 | .md |
支持结构化配置 |
testReaderPdf() |
PDF 按页读取 | .pdf |
每页一个 Document |
testReaderParagraphPdf() |
PDF 按段落读取 | .pdf |
需要目录结构,更精细 |
核心知识点
1. Spring Boot 测试框架
1.1 @SpringBootTest
@SpringBootTest
public class ReaderTest {
// ...
}
知识点:
- 集成测试注解:启动完整的 Spring 应用上下文
- 自动配置:自动加载所有 Spring Boot 自动配置
- 测试环境:提供完整的 Spring 容器环境
使用场景:
- 需要测试 Spring Bean 的集成
- 需要完整的应用上下文
- 需要测试与外部资源的交互(如文件读取)
1.2 @Test (JUnit 5)
@Test
public void testReaderText(@Value("classpath:rag/terms-of-service.txt") Resource resource) {
// ...
}
知识点:
- JUnit 5 测试方法:标记为测试方法
- 方法参数注入:Spring 会自动注入方法参数
- 测试隔离:每个测试方法独立运行
2. Spring 资源注入
2.1 @Value 注解
@Value("classpath:rag/terms-of-service.txt")
Resource resource
知识点:
- 资源路径注入:从 classpath 加载资源文件
- Resource 接口:Spring 的资源抽象接口
- 路径前缀:
classpath:- 从类路径加载file:- 从文件系统加载http:- 从 URL 加载
优势:
- ✅ 统一资源访问接口
- ✅ 支持多种资源来源
- ✅ 自动处理资源不存在的情况
3. Spring AI Document 模型
3.1 Document 对象
List<Document> documents = textReader.read();
for (Document document : documents) {
System.out.println(document.getText());
}
知识点:
- Document 结构:
Document { String text; // 文档文本内容 Map<String, Object> metadata; // 元数据(文件名、来源等) String id; // 文档唯一标识 } - 不可变性:Document 对象通常是不可变的
- 元数据支持:可以添加自定义元数据用于后续过滤
使用场景:
- 存储提取的文本内容
- 保存文档来源信息
- 为向量化做准备
使用特性详解
特性 1: 文本文件读取(TextReader)
代码示例
@Test
public void testReaderText(@Value("classpath:rag/terms-of-service.txt") Resource resource) {
TextReader textReader = new TextReader(resource);
List<Document> documents = textReader.read();
for (Document document : documents) {
System.out.println(document.getText());
}
}
特性说明
优点:
- ✅ 简单直接:无需配置,开箱即用
- ✅ 性能好:纯文本读取,速度快
- ✅ 内存友好:适合大文件
限制:
- ❌ 无结构化:无法识别文档结构
- ❌ 无格式信息:丢失所有格式信息
适用场景:
- 简单的文本文档
- 日志文件
- 配置文件
- 纯文本内容
元数据扩展:
TextReader textReader = new TextReader(resource);
textReader.getCustomMetadata().put("filename", resource.getFilename());
textReader.getCustomMetadata().put("source", "terms-of-service");
List<Document> documents = textReader.read();
特性 2: Markdown 文件读取(MarkdownDocumentReader)
代码示例
@Test
public void testReaderMD(@Value("classpath:rag/9_横店影视股份有限公司_0.md") Resource resource) {
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(false) // 分割线不创建新文档
.withIncludeCodeBlock(false) // 代码块不创建新文档
.withIncludeBlockquote(false) // 引用不创建新文档
.withAdditionalMetadata("filename", resource.getFilename())
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);
List<Document> documents = reader.read();
}
配置选项详解
| 配置项 | 类型 | 默认值 | 说明 |
|---|---|---|---|
withHorizontalRuleCreateDocument() |
boolean |
false |
分割线(---)是否创建新 Document |
withIncludeCodeBlock() |
boolean |
false |
代码块是否创建独立的 Document |
withIncludeBlockquote() |
boolean |
false |
引用块是否创建独立的 Document |
withAdditionalMetadata() |
Map<String, Object> |
{} |
为每个 Document 添加元数据 |
特性说明
优点:
- ✅ 结构化处理:识别 Markdown 语法结构
- ✅ 灵活配置:可以控制哪些元素创建新文档
- ✅ 元数据支持:可以添加自定义元数据
配置策略:
策略 1:合并所有内容(推荐用于 RAG)
MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(false) // 不分割
.withIncludeCodeBlock(false) // 代码块合并
.withIncludeBlockquote(false) // 引用合并
.build();
- 适用:需要完整上下文进行检索
- 结果:整个 Markdown 文件作为一个或少量 Document
策略 2:按结构分割
MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true) // 分割线创建新文档
.withIncludeCodeBlock(true) // 代码块独立
.withIncludeBlockquote(true) // 引用独立
.build();
- 适用:需要精确匹配特定内容块
- 结果:每个结构元素创建独立的 Document
适用场景:
- 技术文档(README、API 文档)
- 博客文章
- 结构化内容
- 需要保留格式信息的文档
特性 3: PDF 按页读取(PagePdfDocumentReader)
代码示例
@Test
public void testReaderPdf(@Value("classpath:rag/平安银行2023年半年度报告摘要.pdf") Resource resource) {
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(
resource,
PdfDocumentReaderConfig.builder().build()
);
List<Document> documents = pdfReader.read();
}
特性说明
工作原理:
- 逐页读取 PDF 文件
- 每页提取文本内容
- 每页创建一个 Document 对象
优点:
- ✅ 简单直接:无需 PDF 目录结构
- ✅ 通用性强:适用于所有 PDF 文件
- ✅ 配置简单:默认配置即可使用
限制:
- ❌ 粒度粗:按页分割,可能将相关内容分开
- ❌ 无语义理解:不识别段落、章节等结构
适用场景:
- 简单的 PDF 文档
- 不需要精细分割的场景
- PDF 没有目录结构的情况
元数据示例:
// 每个 Document 自动包含页面信息
document.getMetadata().get("page"); // 页码
document.getMetadata().get("source"); // 文件来源
特性 4: PDF 按段落读取(ParagraphPdfDocumentReader)
代码示例
@Test
public void testReaderParagraphPdf(@Value("classpath:rag/平安银行2023年半年度报告.pdf") Resource resource) {
ParagraphPdfDocumentReader pdfReader = new ParagraphPdfDocumentReader(
resource,
PdfDocumentReaderConfig.builder()
.withReversedParagraphPosition(true) // 坐标系反转
.withPageTopMargin(0) // 上边距
.withPageExtractedTextFormatter(
ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0) // 删除前 N 行
.build()
)
.build()
);
List<Document> documents = pdfReader.read();
}
配置选项详解
4.1 withReversedParagraphPosition(boolean)
作用:控制 PDF 坐标系的处理方式
问题背景:
- 不同的 PDF 生成工具可能使用不同的坐标系
- 有些工具使用左上角为原点(Y 轴向下)
- 有些工具使用左下角为原点(Y 轴向上)
解决方案:
.withReversedParagraphPosition(true) // 反转坐标系
何时使用:
- ✅ PDF 内容识别位置不正确
- ✅ 段落顺序混乱
- ✅ 不同工具生成的 PDF 表现不一致
4.2 withPageTopMargin(int)
作用:设置页面上边距
使用场景:
- 过滤页眉内容
- 调整内容提取区域
- 处理有固定页眉的 PDF
示例:
.withPageTopMargin(50) // 忽略页面上方 50 像素的内容
4.3 withPageExtractedTextFormatter()
作用:格式化提取的文本
配置项:
withNumberOfTopTextLinesToDelete(int):删除前 N 行文本
使用场景:
- 删除页眉
- 删除固定格式的前缀
- 清理不需要的文本
示例:
ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(2) // 删除前 2 行
.build()
特性说明
优点:
- ✅ 精细分割:按段落分割,保持语义完整性
- ✅ 结构识别:识别 PDF 目录结构
- ✅ 灵活配置:支持多种配置选项
限制:
- ❌ 需要目录:PDF 必须有目录结构
- ❌ 配置复杂:需要根据 PDF 特性调整配置
- ❌ 性能较低:比按页读取慢
适用场景:
- 有目录结构的 PDF(如报告、书籍)
- 需要精确段落分割的场景
- 长文档的精细处理
注意事项:
// ⚠️ 重要:PDF 必须有目录结构
// 如果 PDF 没有目录,使用 PagePdfDocumentReader
代码分析
整体架构
ReaderTest
├── testReaderText() → TextReader
├── testReaderMD() → MarkdownDocumentReader
├── testReaderPdf() → PagePdfDocumentReader
└── testReaderParagraphPdf() → ParagraphPdfDocumentReader
设计模式
1. Builder 模式
MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(false)
.withIncludeCodeBlock(false)
.build();
优势:
- ✅ 链式调用,代码清晰
- ✅ 可选参数灵活
- ✅ 配置对象不可变
2. 策略模式
不同的 Reader 实现不同的读取策略:
TextReader:简单文本读取MarkdownDocumentReader:结构化 Markdown 读取PagePdfDocumentReader:按页 PDF 读取ParagraphPdfDocumentReader:按段落 PDF 读取
数据流
Resource (文件资源)
↓
Reader (读取器)
↓
List<Document> (文档列表)
↓
后续处理 (分割、向量化、存储)
最佳实践
1. 选择合适的读取器
| 文件类型 | 推荐读取器 | 原因 |
|---|---|---|
| 纯文本 | TextReader |
简单高效 |
| Markdown | MarkdownDocumentReader |
保留结构信息 |
| PDF(无目录) | PagePdfDocumentReader |
通用性强 |
| PDF(有目录) | ParagraphPdfDocumentReader |
精细分割 |
2. Markdown 配置建议
RAG 场景(推荐):
MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(false) // 不分割,保持上下文
.withIncludeCodeBlock(false) // 代码块合并到文档中
.withIncludeBlockquote(false) // 引用合并
.withAdditionalMetadata("source", "markdown") // 添加来源标识
.build();
原因:
- 保持文档上下文完整性
- 提高检索准确性
- 减少文档碎片化
3. PDF 配置建议
按页读取(简单场景):
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(
resource,
PdfDocumentReaderConfig.builder().build() // 默认配置即可
);
按段落读取(复杂场景):
ParagraphPdfDocumentReader pdfReader = new ParagraphPdfDocumentReader(
resource,
PdfDocumentReaderConfig.builder()
.withReversedParagraphPosition(true) // 根据实际情况调整
.withPageTopMargin(0) // 根据页眉高度调整
.build()
);
4. 元数据管理
添加元数据:
// 方式 1:通过配置添加(Markdown)
.withAdditionalMetadata("filename", resource.getFilename())
.withAdditionalMetadata("source", "markdown")
// 方式 2:读取后添加(通用)
for (Document doc : documents) {
doc.getMetadata().put("processed_date", LocalDateTime.now().toString());
}
元数据用途:
- 文档来源追踪
- 后续过滤和检索
- 调试和日志记录
5. 错误处理
@Test
public void testReaderWithErrorHandling(@Value("classpath:rag/file.txt") Resource resource) {
try {
TextReader reader = new TextReader(resource);
List<Document> documents = reader.read();
if (documents.isEmpty()) {
System.out.println("警告:未读取到任何文档");
}
// 处理文档...
} catch (IOException e) {
System.err.println("读取文件失败: " + e.getMessage());
}
}
常见问题
Q1: PDF 读取时内容顺序混乱?
原因:PDF 坐标系问题
解决方案:
.withReversedParagraphPosition(true) // 反转坐标系
Q2: Markdown 代码块是否需要单独创建 Document?
建议:
- RAG 场景:
false(合并到文档中,保持上下文) - 代码搜索场景:
true(代码块独立,便于精确匹配)
Q3: PDF 按段落读取失败?
检查清单:
- ✅ PDF 是否有目录结构?
- ✅ 坐标系配置是否正确?
- ✅ 边距设置是否合理?
解决方案:
- 如果没有目录,使用
PagePdfDocumentReader - 调整
withReversedParagraphPosition参数 - 调整
withPageTopMargin参数
Q4: 如何提高读取性能?
优化建议:
- 选择合适的读取器:简单场景用简单读取器
- 批量处理:一次读取多个文件
- 异步处理:大文件使用异步读取
- 缓存结果:相同文件避免重复读取
Q5: 元数据如何用于后续检索?
示例:
// 存储时添加元数据
Document doc = Document.builder()
.text("内容...")
.metadata(Map.of("category", "技术文档", "author", "张三"))
.build();
// 检索时过滤
SearchRequest.builder()
.query("查询内容")
.filterExpression("category == '技术文档'") // 元数据过滤
.build();
总结
核心要点
- 选择合适的读取器:根据文件类型和需求选择
- 合理配置:Markdown 和 PDF 都有丰富的配置选项
- 元数据管理:充分利用元数据提高检索精度
- 错误处理:添加适当的异常处理
学习路径
- ✅ 掌握基础读取器(TextReader)
- ✅ 理解配置模式(Builder Pattern)
- ✅ 学习 Markdown 结构化读取
- ✅ 掌握 PDF 两种读取方式
- ✅ 实践元数据管理
下一步
- 📖 学习文档分割(Splitter)
- 📖 学习向量化(Embedding)
- 📖 学习向量存储(VectorStore)
- 📖 学习检索增强(RAG)
相关文件:
SplitterTest.java- 文档分割测试VectorStoreTest.java- 向量存储测试ChatClientRagTest.java- RAG 完整流程测试
package com.xushu.springai.rag.ELT;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import com.alibaba.cloud.ai.dashscope.embedding.DashScopeEmbeddingModel;
import org.junit.jupiter.api.Test;
import org.springframework.ai.document.Document;
import org.springframework.ai.model.transformer.KeywordMetadataEnricher;
import org.springframework.ai.model.transformer.SummaryMetadataEnricher;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TextSplitter;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.boot.test.context.TestConfiguration;
import org.springframework.context.annotation.Bean;
import org.springframework.core.io.Resource;
import java.util.List;
@SpringBootTest
public class SplitterTest {
// 只要token数合理就行
// 不要想着严格按照主题来分 (企业级知识库 各式各样的文档资料)
@Test
public void testTokenTextSplitter(@Value("classpath:rag/terms-of-service.txt") Resource resource) {
TextReader textReader = new TextReader(resource);
List<Document> documents = textReader.read();
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> apply = splitter.apply(documents);
apply.forEach(System.out::println);
}
@Test
public void testChineseTokenTextSplitter(@Value("classpath:rag/terms-of-service.txt") Resource resource) {
TextReader textReader = new TextReader(resource);
List<Document> documents = textReader.read();
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter();
List<Document> apply = splitter.apply(documents);
apply.forEach(System.out::println);
}
@Test
public void testKeywordMetadataEnricher(
@Autowired VectorStore vectorStore,
@Autowired DashScopeChatModel chatModel,
@Value("classpath:rag/terms-of-service.txt") Resource resource) {
TextReader textReader = new TextReader(resource);
textReader.getCustomMetadata().put("filename", resource.getFilename());
List<Document> documents = textReader.read();
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter();
documents = splitter.apply(documents);
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(chatModel, 5);
documents= enricher.apply(documents);
/* KeywordMetadataEnricher.KEYWORDS_TEMPLATE= """
给我按照我提供的内容{context_str},生成%s个关键字;
允许的关键字有这些:
['退票','预定']
只允许在这个关键字范围进行选择。
""";*/
vectorStore.add(documents);
documents = vectorStore.similaritySearch(
SearchRequest.builder()
.filterExpression("filename in ('退票')")
// 过滤元数据
.filterExpression("excerpt_keywords in ('退票')")
.build());
for (Document document : documents) {
System.out.println(document.getText());
System.out.println(document.getText().length());
}
}
@TestConfiguration
static class TestConfig {
@Bean
public VectorStore vectorStore(DashScopeEmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}
}
@Test
public void testSummaryMetadataEnricher(
@Autowired DashScopeChatModel chatModel,
@Value("classpath:rag/terms-of-service.txt") Resource resource) {
// 读取
TextReader textReader = new TextReader(resource);
textReader.getCustomMetadata().put("filename", resource.getFilename());
List<Document> documents = textReader.read();
// 分隔
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(130,10,5,10000,true);
List<Document> apply = splitter.apply(documents);
// 摘要总结转换器 依赖大模型能力进行总结
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryMetadataEnricher.SummaryType.PREVIOUS,
SummaryMetadataEnricher.SummaryType.CURRENT,
SummaryMetadataEnricher.SummaryType.NEXT));
apply = enricher.apply(apply);
System.out.println(apply);
}
}
SplitterTest知识点分析
SplitterTest 知识点与使用特性分析
📋 目录
概述
SplitterTest 是 Spring AI RAG 中 文档分割(Transform)和元数据增强(Enrichment) 阶段的测试类,演示了如何将长文档切分成较小的片段,并为文档添加元数据以提高检索精度。这是 RAG 流程的关键步骤,直接影响检索效果。
测试方法概览
| 方法 | 功能 | 核心组件 | 特点 |
|---|---|---|---|
testTokenTextSplitter() |
标准 Token 分割 | TokenTextSplitter |
简单,适用于英文 |
testChineseTokenTextSplitter() |
中文 Token 分割 | ChineseTokenTextSplitter |
支持中文分词 |
testKeywordMetadataEnricher() |
关键词元数据增强 | KeywordMetadataEnricher |
提取关键词,支持过滤 |
testSummaryMetadataEnricher() |
摘要元数据增强 | SummaryMetadataEnricher |
生成摘要,提高检索精度 |
RAG 流程中的位置
文档读取 (Reader)
↓
文档分割 (Splitter) ← 本文件重点
↓
元数据增强 (Enricher) ← 本文件重点
↓
向量化 (Embedding)
↓
向量存储 (VectorStore)
↓
检索增强生成 (RAG)
核心知识点
1. 文档分割(Text Splitting)
1.1 为什么需要文档分割?
问题:
- 长文档无法直接向量化(超出模型上下文窗口)
- 检索精度低(大块文本难以精确匹配)
- 向量化质量差(大块文本语义混杂)
解决方案:
- 将长文档切分成较小的片段(chunks)
- 每个片段独立向量化
- 检索时匹配相关片段
1.2 分割策略
按 Token 数分割(推荐):
- ✅ 简单实用
- ✅ 适合企业级知识库
- ✅ 不依赖文档结构
按主题分割(不推荐):
- ❌ 复杂且不准确
- ❌ 企业文档多样,难以统一
- ❌ 实现成本高
重要提示:
💡 只要 token 数合理就行,不要想着严格按照主题来分(企业级知识库各式各样的文档资料)
2. Spring AI 分割器接口
2.1 TextSplitter 接口
public abstract class TextSplitter {
public List<Document> apply(List<Document> documents) {
// 将文档列表分割成更小的文档列表
}
protected abstract List<String> splitText(String text);
}
设计模式:模板方法模式
apply()方法定义算法骨架splitText()由子类实现具体分割逻辑
3. 元数据增强(Metadata Enrichment)
3.1 什么是元数据增强?
定义:为文档添加额外的结构化信息,用于:
- 提高检索精度
- 支持元数据过滤
- 提供上下文信息
示例:
Document {
text: "退票需要支付 75 美元的费用..."
metadata: {
"filename": "terms-of-service.txt",
"excerpt_keywords": ["退票", "费用", "取消"], // 关键词增强
"summary": "关于退票政策和费用的说明" // 摘要增强
}
}
3.2 增强器接口
public interface Transformer {
List<Document> apply(List<Document> documents);
}
设计模式:函数式接口
- 输入:文档列表
- 输出:增强后的文档列表
- 可链式调用:
splitter.apply(enricher.apply(documents))
使用特性详解
特性 1: 标准 Token 分割(TokenTextSplitter)
代码示例
@Test
public void testTokenTextSplitter(@Value("classpath:rag/terms-of-service.txt") Resource resource) {
TextReader textReader = new TextReader(resource);
List<Document> documents = textReader.read();
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> apply = splitter.apply(documents);
apply.forEach(System.out::println);
}
特性说明
工作原理:
- 使用 Token 编码器(如 CL100K_BASE)将文本编码为 Token
- 按指定的
chunkSize切分 Token - 将 Token 解码回文本,创建新的 Document
优点:
- ✅ 简单直接:无需配置,开箱即用
- ✅ 通用性强:适用于大多数场景
- ✅ 性能好:基于 Token 计数,速度快
限制:
- ❌ 中文支持弱:对中文 Token 计数不准确
- ❌ 默认配置:无法自定义分割参数
适用场景:
- 英文文档
- 简单的文档分割需求
- 快速原型开发
默认参数:
chunkSize: 默认值(通常 800-1000 tokens)chunkOverlap: 默认值(通常 10% 重叠)
特性 2: 中文 Token 分割(ChineseTokenTextSplitter)
代码示例
示例 1:使用默认配置
@Test
public void testChineseTokenTextSplitter(@Value("classpath:rag/terms-of-service.txt") Resource resource) {
TextReader textReader = new TextReader(resource);
List<Document> documents = textReader.read();
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter();
List<Document> apply = splitter.apply(documents);
apply.forEach(System.out::println);
}
示例 2:自定义配置
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(
130, // chunkSize: 每个分块的目标 token 数
10, // chunkOverlap: 分块之间的重叠 token 数(注意:此实现中通过句子边界实现)
5, // minChunkSize: 最小分块 token 数
10000, // maxChunkSize: 最大分块 token 数
true // keepSeparator: 是否保留分隔符
);
参数详解
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
chunkSize |
int |
800 |
每个分块的目标 token 数 |
minChunkSizeChars |
int |
350 |
最小分块字符数(用于句子边界判断) |
minChunkLengthToEmbed |
int |
5 |
最小嵌入长度,小于此值的分块会被丢弃 |
maxNumChunks |
int |
10000 |
最大分块数量,防止无限分割 |
keepSeparator |
boolean |
true |
是否保留换行符等分隔符 |
工作原理
分割算法:
1. 将文本编码为 Token 列表
2. 按 chunkSize 切分 Token
3. 查找最后一个标点符号(. ? ! \n 。 ? !)
4. 如果按句子截取后长度 > minChunkSizeChars,则按句子截取
5. 否则保留原块
6. 过滤掉长度 < minChunkLengthToEmbed 的分块
7. 重复直到所有 Token 处理完毕
中文支持:
- 使用
CL100K_BASE编码器(支持中文) - 识别中文标点符号(。?!)
- 更准确的中文 Token 计数
优点:
- ✅ 中文优化:针对中文文档优化
- ✅ 智能分割:按句子边界分割,保持语义完整
- ✅ 灵活配置:支持多种参数配置
- ✅ 防止碎片化:过滤过小的分块
适用场景:
- 中文文档
- 需要精确 Token 计数的场景
- 需要保持语义完整性的场景
配置建议:
场景 1:短文档(< 1000 tokens)
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(
200, // 较小的 chunkSize
10, // 较小的重叠
50, // 较大的最小长度
100, // 较小的最大分块数
true // 保留分隔符
);
场景 2:长文档(> 10000 tokens)
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(
500, // 较大的 chunkSize
50, // 较大的重叠(10%)
100, // 较大的最小长度
10000, // 较大的最大分块数
true // 保留分隔符
);
场景 3:代码文档
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(
300, // 中等 chunkSize
30, // 10% 重叠
50, // 最小长度
5000, // 最大分块数
false // 不保留分隔符(代码通常不需要)
);
特性 3: 关键词元数据增强(KeywordMetadataEnricher)
代码示例
@Test
public void testKeywordMetadataEnricher(
@Autowired VectorStore vectorStore,
@Autowired DashScopeChatModel chatModel,
@Value("classpath:rag/terms-of-service.txt") Resource resource) {
// 1. 读取文档
TextReader textReader = new TextReader(resource);
textReader.getCustomMetadata().put("filename", resource.getFilename());
List<Document> documents = textReader.read();
// 2. 分割文档
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter();
documents = splitter.apply(documents);
// 3. 关键词增强
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(chatModel, 5);
documents = enricher.apply(documents);
// 4. 存储到向量库
vectorStore.add(documents);
// 5. 使用关键词过滤检索
documents = vectorStore.similaritySearch(
SearchRequest.builder()
.filterExpression("excerpt_keywords in ('退票')")
.build()
);
}
配置选项
基本配置:
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(
chatModel, // ChatModel 实例(用于调用 LLM)
5 // 提取的关键词数量
);
自定义模板:
// 自定义关键词提取模板
KeywordMetadataEnricher.KEYWORDS_TEMPLATE = """
给我按照我提供的内容{context_str},生成%s个关键字;
允许的关键字有这些:
['退票','预定']
只允许在这个关键字范围进行选择。
""";
工作原理
增强流程:
1. 对每个 Document,提取文本内容
2. 调用 LLM,使用模板生成关键词
3. 将关键词添加到 Document 的 metadata 中
4. 关键词存储在 "excerpt_keywords" 字段
元数据结构:
Document {
text: "退票需要支付 75 美元的费用..."
metadata: {
"filename": "terms-of-service.txt",
"excerpt_keywords": ["退票", "费用", "取消", "政策", "退款"]
}
}
特性说明
优点:
- ✅ 提高检索精度:关键词可以用于精确过滤
- ✅ 语义理解:利用 LLM 理解文档语义
- ✅ 灵活配置:可以自定义关键词提取模板
- ✅ 支持约束:可以限制关键词范围
限制:
- ❌ 需要 LLM:依赖 ChatModel,有成本
- ❌ 处理速度慢:需要调用 LLM API
- ❌ 关键词质量依赖模型:不同模型效果不同
适用场景:
- 需要精确过滤的场景
- 文档分类场景
- 主题检索场景
元数据过滤
过滤语法:
SearchRequest.builder()
// 方式 1:精确匹配
.filterExpression("excerpt_keywords in ('退票')")
// 方式 2:多关键词
.filterExpression("excerpt_keywords in ('退票', '费用')")
// 方式 3:组合过滤
.filterExpression("excerpt_keywords in ('退票') AND filename == 'terms-of-service.txt'")
.build()
过滤示例:
// 检索包含"退票"关键词的文档
documents = vectorStore.similaritySearch(
SearchRequest.builder()
.query("退票费用")
.filterExpression("excerpt_keywords in ('退票')")
.topK(5)
.build()
);
特性 4: 摘要元数据增强(SummaryMetadataEnricher)
代码示例
@Test
public void testSummaryMetadataEnricher(
@Autowired DashScopeChatModel chatModel,
@Value("classpath:rag/terms-of-service.txt") Resource resource) {
// 1. 读取文档
TextReader textReader = new TextReader(resource);
textReader.getCustomMetadata().put("filename", resource.getFilename());
List<Document> documents = textReader.read();
// 2. 分割文档(使用自定义参数)
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(130, 10, 5, 10000, true);
List<Document> apply = splitter.apply(documents);
// 3. 摘要增强(依赖大模型能力进行总结)
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(
chatModel,
List.of(
SummaryMetadataEnricher.SummaryType.PREVIOUS, // 前一个分块的摘要
SummaryMetadataEnricher.SummaryType.CURRENT, // 当前分块的摘要
SummaryMetadataEnricher.SummaryType.NEXT // 下一个分块的摘要
)
);
apply = enricher.apply(apply);
System.out.println(apply);
}
摘要类型
| 类型 | 说明 | 用途 |
|---|---|---|
PREVIOUS |
前一个分块的摘要 | 提供前文上下文 |
CURRENT |
当前分块的摘要 | 概括当前内容 |
NEXT |
下一个分块的摘要 | 提供后文上下文 |
工作原理
增强流程:
1. 对每个 Document,获取前一个、当前、下一个分块
2. 调用 LLM,为每个分块生成摘要
3. 将摘要添加到 Document 的 metadata 中
4. 摘要存储在对应的字段中:
- "previous_summary": 前一个分块的摘要
- "current_summary": 当前分块的摘要
- "next_summary": 下一个分块的摘要
元数据结构:
Document {
text: "退票需要支付 75 美元的费用..."
metadata: {
"filename": "terms-of-service.txt",
"current_summary": "关于退票费用和政策的说明",
"previous_summary": "预订航班的相关规定",
"next_summary": "退款处理时间说明"
}
}
特性说明
优点:
- ✅ 提供上下文:通过前后文摘要提供上下文信息
- ✅ 提高检索精度:摘要可以用于更精确的匹配
- ✅ 语义理解:利用 LLM 理解文档语义
- ✅ 支持多类型:可以同时生成多种类型的摘要
限制:
- ❌ 需要 LLM:依赖 ChatModel,有成本
- ❌ 处理速度慢:需要调用 LLM API
- ❌ 内存占用:需要存储多个分块的摘要
适用场景:
- 需要上下文信息的场景
- 长文档的精细检索
- 需要理解文档关系的场景
配置建议:
场景 1:只需要当前摘要
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(
chatModel,
List.of(SummaryMetadataEnricher.SummaryType.CURRENT)
);
场景 2:需要完整上下文
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(
chatModel,
List.of(
SummaryMetadataEnricher.SummaryType.PREVIOUS,
SummaryMetadataEnricher.SummaryType.CURRENT,
SummaryMetadataEnricher.SummaryType.NEXT
)
);
代码分析
整体架构
SplitterTest
├── testTokenTextSplitter() → TokenTextSplitter
├── testChineseTokenTextSplitter() → ChineseTokenTextSplitter
├── testKeywordMetadataEnricher() → KeywordMetadataEnricher + VectorStore
└── testSummaryMetadataEnricher() → SummaryMetadataEnricher
设计模式
1. 策略模式
不同的 Splitter 实现不同的分割策略:
TokenTextSplitter:标准 Token 分割ChineseTokenTextSplitter:中文优化分割
2. 装饰器模式
Enricher 对 Document 进行增强,不改变原有结构:
Document → Enricher → Enhanced Document
3. 链式调用
可以链式调用多个 Transformer:
List<Document> result = enricher.apply(splitter.apply(reader.read()));
数据流
Resource (文件资源)
↓
TextReader.read() → List<Document>
↓
Splitter.apply() → List<Document> (分割后的文档)
↓
Enricher.apply() → List<Document> (增强后的文档)
↓
VectorStore.add() → 存储到向量库
↓
VectorStore.similaritySearch() → 检索文档
测试配置
@TestConfiguration
static class TestConfig {
@Bean
public VectorStore vectorStore(DashScopeEmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}
}
说明:
- 使用
@TestConfiguration创建测试专用的配置 - 配置
VectorStoreBean 用于测试 - 支持依赖注入(
@Autowired)
最佳实践
1. 分割策略选择
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 英文文档 | TokenTextSplitter |
简单高效 |
| 中文文档 | ChineseTokenTextSplitter |
中文优化 |
| 代码文档 | ChineseTokenTextSplitter (keepSeparator=false) |
不保留换行 |
| 长文档 | 较大的 chunkSize (500-800) |
保持上下文 |
| 短文档 | 较小的 chunkSize (200-300) |
避免过度分割 |
2. 参数配置建议
chunkSize 选择:
// 根据模型上下文窗口选择
// GPT-4: 128K tokens → chunkSize: 500-1000
// GPT-3.5: 16K tokens → chunkSize: 200-500
// Claude: 200K tokens → chunkSize: 1000-2000
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(
500, // chunkSize: 根据模型选择
50, // 10% 重叠
100, // 最小长度
10000, // 最大分块数
true // 保留分隔符
);
重叠设置:
- ✅ 推荐:10-20% 的重叠
- ❌ 不推荐:无重叠(可能丢失上下文)
- ❌ 不推荐:重叠过大(> 50%,浪费资源)
3. 元数据增强策略
关键词增强:
// 场景 1:需要精确过滤
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(chatModel, 5);
documents = enricher.apply(documents);
// 场景 2:自定义关键词范围
KeywordMetadataEnricher.KEYWORDS_TEMPLATE = """
给我按照我提供的内容{context_str},生成%s个关键字;
允许的关键字有这些:
['退票','预定','取消','退款']
只允许在这个关键字范围进行选择。
""";
摘要增强:
// 场景 1:只需要当前摘要(节省成本)
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(
chatModel,
List.of(SummaryMetadataEnricher.SummaryType.CURRENT)
);
// 场景 2:需要完整上下文(提高精度)
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(
chatModel,
List.of(
SummaryMetadataEnricher.SummaryType.PREVIOUS,
SummaryMetadataEnricher.SummaryType.CURRENT,
SummaryMetadataEnricher.SummaryType.NEXT
)
);
4. 性能优化
批量处理:
// 一次性处理多个文档
List<Document> allDocuments = new ArrayList<>();
for (Resource resource : resources) {
List<Document> docs = reader.read(resource);
allDocuments.addAll(docs);
}
List<Document> splitDocs = splitter.apply(allDocuments);
异步处理(大文件):
CompletableFuture<List<Document>> future = CompletableFuture.supplyAsync(() -> {
return enricher.apply(splitter.apply(reader.read()));
});
List<Document> documents = future.get();
缓存结果:
// 避免重复处理相同文档
Map<String, List<Document>> cache = new ConcurrentHashMap<>();
String key = resource.getFilename();
if (!cache.containsKey(key)) {
cache.put(key, enricher.apply(splitter.apply(reader.read())));
}
5. 错误处理
@Test
public void testSplitterWithErrorHandling(@Value("classpath:rag/file.txt") Resource resource) {
try {
TextReader reader = new TextReader(resource);
List<Document> documents = reader.read();
if (documents.isEmpty()) {
System.out.println("警告:未读取到任何文档");
return;
}
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter();
List<Document> splitDocs = splitter.apply(documents);
if (splitDocs.isEmpty()) {
System.out.println("警告:分割后未产生任何文档");
return;
}
// 处理文档...
} catch (Exception e) {
System.err.println("处理失败: " + e.getMessage());
e.printStackTrace();
}
}
常见问题
Q1: chunkSize 应该设置多大?
建议:
- 根据模型上下文窗口:chunkSize 应该小于模型上下文窗口的 1/4
- 根据文档类型:
- 技术文档:300-500 tokens
- 普通文档:200-400 tokens
- 长文档:500-800 tokens
示例:
// GPT-4 (128K tokens)
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(500, 50, 100, 10000, true);
// GPT-3.5 (16K tokens)
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(300, 30, 50, 10000, true);
Q2: 是否需要重叠?
强烈建议使用重叠:
- ✅ 保持上下文:重叠可以保持分块之间的上下文连贯性
- ✅ 提高检索精度:避免重要信息被分割
- ✅ 推荐比例:10-20% 的重叠
示例:
// chunkSize: 500, overlap: 50 (10%)
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(500, 50, 100, 10000, true);
Q3: 关键词增强的成本如何控制?
优化策略:
- 减少关键词数量:
new KeywordMetadataEnricher(chatModel, 3)而不是 10 - 批量处理:一次性处理多个文档
- 选择性增强:只对重要文档进行增强
- 缓存结果:避免重复处理
示例:
// 只提取 3 个关键词(而不是 5 个)
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(chatModel, 3);
Q4: 摘要增强应该使用哪些类型?
建议:
- 成本敏感:只使用
CURRENT - 精度优先:使用
PREVIOUS、CURRENT、NEXT - 平衡方案:使用
CURRENT+NEXT
示例:
// 平衡方案
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(
chatModel,
List.of(
SummaryMetadataEnricher.SummaryType.CURRENT,
SummaryMetadataEnricher.SummaryType.NEXT
)
);
Q5: 如何调试分割结果?
调试方法:
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(500, 50, 100, 10000, true);
List<Document> splitDocs = splitter.apply(documents);
// 打印分割结果
splitDocs.forEach(doc -> {
System.out.println("=== 分块 ===");
System.out.println("长度: " + doc.getText().length());
System.out.println("内容: " + doc.getText().substring(0, Math.min(100, doc.getText().length())));
System.out.println("元数据: " + doc.getMetadata());
System.out.println();
});
Q6: 分割后文档数量过多怎么办?
解决方案:
- 增加 chunkSize:减少分块数量
- 设置 maxNumChunks:限制最大分块数
- 提高 minChunkLengthToEmbed:过滤小分块
示例:
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(
800, // 增大 chunkSize
80, // 相应增大重叠
200, // 提高最小长度
5000, // 限制最大分块数
true
);
总结
核心要点
- 选择合适的分割器:根据文档类型选择 TokenTextSplitter 或 ChineseTokenTextSplitter
- 合理配置参数:chunkSize、重叠、最小长度等
- 元数据增强:使用关键词和摘要提高检索精度
- 性能优化:批量处理、异步处理、缓存结果
学习路径
- ✅ 掌握基础分割器(TokenTextSplitter)
- ✅ 理解中文分割器(ChineseTokenTextSplitter)
- ✅ 学习关键词增强(KeywordMetadataEnricher)
- ✅ 学习摘要增强(SummaryMetadataEnricher)
- ✅ 实践元数据过滤
下一步
- 📖 学习向量化(Embedding)
- 📖 学习向量存储(VectorStore)
- 📖 学习检索增强(RAG)
- 📖 学习重排序(Rerank)
相关文件:
ReaderTest.java- 文档读取测试VectorStoreTest.java- 向量存储测试ChatClientRagTest.java- RAG 完整流程测试ChineseTokenTextSplitter.java- 中文分割器实现
自定义支持中文符号分割器和分割器源码解读
package com.xushu.springai.rag.ELT;
import com.knuddels.jtokkit.Encodings;
import com.knuddels.jtokkit.api.Encoding;
import com.knuddels.jtokkit.api.EncodingRegistry;
import com.knuddels.jtokkit.api.EncodingType;
import com.knuddels.jtokkit.api.IntArrayList;
import org.springframework.ai.transformer.splitter.TextSplitter;
import org.springframework.util.Assert;
import java.util.ArrayList;
import java.util.List;
public class ChineseTokenTextSplitter extends TextSplitter {
private static final int DEFAULT_CHUNK_SIZE = 800;
private static final int MIN_CHUNK_SIZE_CHARS = 350;
private static final int MIN_CHUNK_LENGTH_TO_EMBED = 5;
private static final int MAX_NUM_CHUNKS = 10000;
private static final boolean KEEP_SEPARATOR = true;
private final EncodingRegistry registry = Encodings.newLazyEncodingRegistry();
private final Encoding encoding = this.registry.getEncoding(EncodingType.CL100K_BASE);
// The target size of each text chunk in tokens
private final int chunkSize;
// The minimum size of each text chunk in characters
private final int minChunkSizeChars;
// Discard chunks shorter than this
private final int minChunkLengthToEmbed;
// The maximum number of chunks to generate from a text
private final int maxNumChunks;
private final boolean keepSeparator;
public ChineseTokenTextSplitter() {
this(DEFAULT_CHUNK_SIZE, MIN_CHUNK_SIZE_CHARS, MIN_CHUNK_LENGTH_TO_EMBED, MAX_NUM_CHUNKS, KEEP_SEPARATOR);
}
public ChineseTokenTextSplitter(boolean keepSeparator) {
this(DEFAULT_CHUNK_SIZE, MIN_CHUNK_SIZE_CHARS, MIN_CHUNK_LENGTH_TO_EMBED, MAX_NUM_CHUNKS, keepSeparator);
}
public ChineseTokenTextSplitter(int chunkSize, int minChunkSizeChars, int minChunkLengthToEmbed, int maxNumChunks,
boolean keepSeparator) {
this.chunkSize = chunkSize;
this.minChunkSizeChars = minChunkSizeChars;
this.minChunkLengthToEmbed = minChunkLengthToEmbed;
this.maxNumChunks = maxNumChunks;
this.keepSeparator = keepSeparator;
}
public static Builder builder() {
return new Builder();
}
@Override
protected List<String> splitText(String text) {
return doSplit(text, this.chunkSize);
}
protected List<String> doSplit(String text, int chunkSize) {
if (text == null || text.trim().isEmpty()) {
return new ArrayList<>();
}
List<Integer> tokens = getEncodedTokens(text);
List<String> chunks = new ArrayList<>();
int num_chunks = 0;
// maxNumChunks多能分多少个块, 超过了就不管了
while (!tokens.isEmpty() && num_chunks < this.maxNumChunks) {
// 按照chunkSize进行分隔
List<Integer> chunk = tokens.subList(0, Math.min(chunkSize, tokens.size()));
String chunkText = decodeTokens(chunk);
// Skip the chunk if it is empty or whitespace
if (chunkText.trim().isEmpty()) {
tokens = tokens.subList(chunk.size(), tokens.size());
continue;
}
// Find the last period or punctuation mark in the chunk
int lastPunctuation =
Math.max(chunkText.lastIndexOf('.'),
Math.max(chunkText.lastIndexOf('?'),
Math.max(chunkText.lastIndexOf('!'),
Math.max(chunkText.lastIndexOf('\n'),
Math.max(chunkText.lastIndexOf('。'),
Math.max(chunkText.lastIndexOf('?'),
chunkText.lastIndexOf('!')
))))));
// 按照句子截取之后长度 > minChunkSizeChars
if (lastPunctuation != -1 && lastPunctuation > this.minChunkSizeChars) {
// 保留按照句子截取之后的内容
chunkText = chunkText.substring(0, lastPunctuation + 1);
}
// 按照句子截取之后长度 < minChunkSizeChars 保留原块
// keepSeparator=true 替换/r/n =false不管
String chunkTextToAppend = (this.keepSeparator) ? chunkText.trim()
: chunkText.replace(System.lineSeparator(), " ").trim();
// 替换/r/n之后的内容是不是<this.minChunkLengthToEmbed 忽略
if (chunkTextToAppend.length() > this.minChunkLengthToEmbed) {
chunks.add(chunkTextToAppend);
}
// Remove the tokens corresponding to the chunk text from the remaining tokens
tokens = tokens.subList(getEncodedTokens(chunkText).size(), tokens.size());
num_chunks++;
}
// Handle the remaining tokens
if (!tokens.isEmpty()) {
String remaining_text = decodeTokens(tokens).replace(System.lineSeparator(), " ").trim();
if (remaining_text.length() > this.minChunkLengthToEmbed) {
chunks.add(remaining_text);
}
}
return chunks;
}
private List<Integer> getEncodedTokens(String text) {
Assert.notNull(text, "Text must not be null");
return this.encoding.encode(text).boxed();
}
private String decodeTokens(List<Integer> tokens) {
Assert.notNull(tokens, "Tokens must not be null");
var tokensIntArray = new IntArrayList(tokens.size());
tokens.forEach(tokensIntArray::add);
return this.encoding.decode(tokensIntArray);
}
public static final class Builder {
private int chunkSize = DEFAULT_CHUNK_SIZE;
private int minChunkSizeChars = MIN_CHUNK_SIZE_CHARS;
private int minChunkLengthToEmbed = MIN_CHUNK_LENGTH_TO_EMBED;
private int maxNumChunks = MAX_NUM_CHUNKS;
private boolean keepSeparator = KEEP_SEPARATOR;
private Builder() {
}
public Builder withChunkSize(int chunkSize) {
this.chunkSize = chunkSize;
return this;
}
public Builder withMinChunkSizeChars(int minChunkSizeChars) {
this.minChunkSizeChars = minChunkSizeChars;
return this;
}
public Builder withMinChunkLengthToEmbed(int minChunkLengthToEmbed) {
this.minChunkLengthToEmbed = minChunkLengthToEmbed;
return this;
}
public Builder withMaxNumChunks(int maxNumChunks) {
this.maxNumChunks = maxNumChunks;
return this;
}
public Builder withKeepSeparator(boolean keepSeparator) {
this.keepSeparator = keepSeparator;
return this;
}
public ChineseTokenTextSplitter build() {
return new ChineseTokenTextSplitter(this.chunkSize, this.minChunkSizeChars, this.minChunkLengthToEmbed,
this.maxNumChunks, this.keepSeparator);
}
}
}
ChineseTokenTextSplitter 知识点与实现分析
文件路径:
09rag/src/test/java/com/xushu/springai/rag/ELT/ChineseTokenTextSplitter.java
Spring AI 版本: 1.0.0
分析日期: 2025年1月
📋 目录
概述
ChineseTokenTextSplitter 是一个自定义的中文 Token 分割器,专门针对中文文档进行了优化。它继承自 Spring AI 的 TextSplitter,使用 jtokkit 库进行 Token 编码,实现了智能的文档分割算法。
核心特性
| 特性 | 说明 |
|---|---|
| 中文优化 | 识别中文标点符号(。?!) |
| 智能分割 | 按句子边界分割,保持语义完整 |
| Token 精确 | 使用 CL100K_BASE 编码器,精确计算 Token 数 |
| 灵活配置 | 支持多种参数配置 |
| 防止碎片化 | 过滤过小的分块 |
在 RAG 流程中的位置
文档读取 (Reader)
↓
文档分割 (ChineseTokenTextSplitter) ← 本文件
↓
元数据增强 (Enricher)
↓
向量化 (Embedding)
↓
向量存储 (VectorStore)
核心知识点
1. 继承关系与模板方法模式
1.1 继承 TextSplitter
public class ChineseTokenTextSplitter extends TextSplitter {
@Override
protected List<String> splitText(String text) {
return doSplit(text, this.chunkSize);
}
}
设计模式:模板方法模式(Template Method Pattern)
父类 TextSplitter 的职责:
- 定义算法骨架:
apply(List<Document>)方法 - 调用子类实现:
splitText(String)方法 - 处理 Document 转换:将分割后的文本转换为 Document 列表
子类 ChineseTokenTextSplitter 的职责:
- 实现具体分割逻辑:
splitText(String)方法 - 处理 Token 编码/解码
- 实现智能分割算法
优势:
- ✅ 代码复用:公共逻辑在父类中
- ✅ 扩展性强:可以轻松创建新的分割器
- ✅ 统一接口:所有分割器使用相同的 API
2. Token 编码与解码
2.1 jtokkit 库
jtokkit 是一个 Java 实现的 Token 编码库,支持 OpenAI 的编码方式。
核心类:
EncodingRegistry:编码注册表Encoding:编码器接口EncodingType:编码类型枚举IntArrayList:整数数组列表
2.2 CL100K_BASE 编码器
private final EncodingRegistry registry = Encodings.newLazyEncodingRegistry();
private final Encoding encoding = this.registry.getEncoding(EncodingType.CL100K_BASE);
CL100K_BASE:
- OpenAI GPT-4 使用的编码方式
- 支持多语言,包括中文
- Token 计数准确
编码过程:
// 文本 → Token 列表
List<Integer> tokens = encoding.encode(text).boxed();
// Token 列表 → 文本
String text = encoding.decode(tokensIntArray);
2.3 Token 编码的重要性
为什么需要 Token 编码?
- LLM 模型基于 Token 工作,不是字符
- 不同语言的 Token 计数方式不同
- 中文 Token 计数比字符计数更准确
示例:
文本:"你好世界"
字符数:4
Token 数:可能是 2-3(取决于编码器)
3. 智能分割算法
3.1 句子边界识别
支持的标点符号:
- 英文:
. ? ! \n - 中文:
。 ? !
识别逻辑:
int lastPunctuation = Math.max(
chunkText.lastIndexOf('.'),
Math.max(chunkText.lastIndexOf('?'),
Math.max(chunkText.lastIndexOf('!'),
Math.max(chunkText.lastIndexOf('\n'),
Math.max(chunkText.lastIndexOf('。'),
Math.max(chunkText.lastIndexOf('?'),
chunkText.lastIndexOf('!')))))));
作用:
- 在 Token 边界附近查找句子边界
- 优先在句子边界处分割
- 保持语义完整性
3.2 最小分块长度控制
minChunkSizeChars:
- 作用:控制按句子分割的最小字符数
- 逻辑:如果按句子分割后长度 < minChunkSizeChars,则保留原块
minChunkLengthToEmbed:
- 作用:过滤过小的分块
- 逻辑:长度 < minChunkLengthToEmbed 的分块会被丢弃
4. Builder 模式
4.1 Builder 类实现
public static final class Builder {
private int chunkSize = DEFAULT_CHUNK_SIZE;
private int minChunkSizeChars = MIN_CHUNK_SIZE_CHARS;
// ...
public Builder withChunkSize(int chunkSize) {
this.chunkSize = chunkSize;
return this;
}
public ChineseTokenTextSplitter build() {
return new ChineseTokenTextSplitter(...);
}
}
设计模式:Builder 模式
优势:
- ✅ 链式调用,代码清晰
- ✅ 可选参数灵活
- ✅ 配置对象不可变
使用示例:
ChineseTokenTextSplitter splitter = ChineseTokenTextSplitter.builder()
.withChunkSize(500)
.withMinChunkSizeChars(200)
.withKeepSeparator(true)
.build();
实现原理
1. 类结构
ChineseTokenTextSplitter
├── 常量定义(默认值)
├── 字段(配置参数)
├── 构造函数(多种重载)
├── 核心方法
│ ├── splitText() → 模板方法实现
│ ├── doSplit() → 核心分割逻辑
│ ├── getEncodedTokens() → Token 编码
│ └── decodeTokens() → Token 解码
└── Builder 内部类
└── 配置方法
2. 默认参数
| 参数 | 默认值 | 说明 |
|---|---|---|
DEFAULT_CHUNK_SIZE |
800 |
默认分块大小(Token 数) |
MIN_CHUNK_SIZE_CHARS |
350 |
最小分块字符数 |
MIN_CHUNK_LENGTH_TO_EMBED |
5 |
最小嵌入长度 |
MAX_NUM_CHUNKS |
10000 |
最大分块数量 |
KEEP_SEPARATOR |
true |
是否保留分隔符 |
3. 构造函数
三种构造函数:
// 1. 无参构造函数(使用所有默认值)
public ChineseTokenTextSplitter()
// 2. 只指定 keepSeparator
public ChineseTokenTextSplitter(boolean keepSeparator)
// 3. 完整参数构造函数
public ChineseTokenTextSplitter(
int chunkSize,
int minChunkSizeChars,
int minChunkLengthToEmbed,
int maxNumChunks,
boolean keepSeparator
)
使用场景:
- 快速使用:无参构造函数
- 简单定制:只指定 keepSeparator
- 完全定制:使用完整参数或 Builder
算法详解
1. 分割算法流程
输入:文本 text
输出:文本块列表 chunks
1. 文本验证
├─ text == null 或为空?
│ └─ 返回空列表
└─ 继续
2. Token 编码
└─ tokens = encode(text)
3. 循环分割(直到 tokens 为空或达到 maxNumChunks)
├─ 提取 chunkSize 个 Token
├─ 解码为文本 chunkText
├─ 跳过空文本
├─ 查找最后一个标点符号
├─ 按句子边界调整(如果长度 > minChunkSizeChars)
├─ 处理分隔符(根据 keepSeparator)
├─ 过滤小分块(长度 > minChunkLengthToEmbed)
└─ 移除已处理的 Token
4. 处理剩余 Token
└─ 如果还有剩余,添加到 chunks
5. 返回 chunks
2. 核心算法代码分析
2.1 主循环
while (!tokens.isEmpty() && num_chunks < this.maxNumChunks) {
// 1. 提取 Token 块
List<Integer> chunk = tokens.subList(0, Math.min(chunkSize, tokens.size()));
String chunkText = decodeTokens(chunk);
// 2. 跳过空文本
if (chunkText.trim().isEmpty()) {
tokens = tokens.subList(chunk.size(), tokens.size());
continue;
}
// 3. 查找句子边界
int lastPunctuation = findLastPunctuation(chunkText);
// 4. 按句子调整
if (lastPunctuation != -1 && lastPunctuation > this.minChunkSizeChars) {
chunkText = chunkText.substring(0, lastPunctuation + 1);
}
// 5. 处理分隔符
String chunkTextToAppend = (this.keepSeparator)
? chunkText.trim()
: chunkText.replace(System.lineSeparator(), " ").trim();
// 6. 过滤小分块
if (chunkTextToAppend.length() > this.minChunkLengthToEmbed) {
chunks.add(chunkTextToAppend);
}
// 7. 移除已处理的 Token
tokens = tokens.subList(getEncodedTokens(chunkText).size(), tokens.size());
num_chunks++;
}
2.2 句子边界查找
int lastPunctuation = Math.max(
chunkText.lastIndexOf('.'), // 英文句号
Math.max(chunkText.lastIndexOf('?'), // 英文问号
Math.max(chunkText.lastIndexOf('!'), // 英文感叹号
Math.max(chunkText.lastIndexOf('\n'), // 换行符
Math.max(chunkText.lastIndexOf('。'), // 中文句号
Math.max(chunkText.lastIndexOf('?'), // 中文问号
chunkText.lastIndexOf('!'))))))); // 中文感叹号
逻辑说明:
- 从后往前查找最后一个标点符号
- 支持中英文标点符号
- 返回标点符号的位置(-1 表示未找到)
2.3 句子边界调整
// 按照句子截取之后长度 > minChunkSizeChars
if (lastPunctuation != -1 && lastPunctuation > this.minChunkSizeChars) {
// 保留按照句子截取之后的内容
chunkText = chunkText.substring(0, lastPunctuation + 1);
}
// 按照句子截取之后长度 < minChunkSizeChars 保留原块
逻辑说明:
- 如果找到标点符号且位置 > minChunkSizeChars
- 则在标点符号处截取(保留标点符号)
- 否则保留原块(避免分块过小)
2.4 分隔符处理
// keepSeparator=true 替换/r/n =false不管
String chunkTextToAppend = (this.keepSeparator)
? chunkText.trim()
: chunkText.replace(System.lineSeparator(), " ").trim();
逻辑说明:
keepSeparator=true:保留换行符,只去除首尾空白keepSeparator=false:将换行符替换为空格
2.5 小分块过滤
// 替换/r/n之后的内容是不是<this.minChunkLengthToEmbed 忽略
if (chunkTextToAppend.length() > this.minChunkLengthToEmbed) {
chunks.add(chunkTextToAppend);
}
逻辑说明:
- 过滤掉长度 < minChunkLengthToEmbed 的分块
- 防止产生过小的分块
- 提高向量化质量
2.6 Token 移除
// Remove the tokens corresponding to the chunk text from the remaining tokens
tokens = tokens.subList(getEncodedTokens(chunkText).size(), tokens.size());
逻辑说明:
- 重新编码已处理的分块文本
- 计算实际使用的 Token 数
- 从剩余 Token 中移除已使用的 Token
为什么需要重新编码?
- 因为可能按句子边界调整了分块
- 实际分块大小可能小于 chunkSize
- 需要准确计算已使用的 Token 数
3. 剩余 Token 处理
// Handle the remaining tokens
if (!tokens.isEmpty()) {
String remaining_text = decodeTokens(tokens).replace(System.lineSeparator(), " ").trim();
if (remaining_text.length() > this.minChunkLengthToEmbed) {
chunks.add(remaining_text);
}
}
逻辑说明:
- 处理循环结束后剩余的 Token
- 将剩余 Token 解码为文本
- 如果长度足够,添加到结果列表
使用特性
特性 1: 多种构造方式
方式 1:无参构造函数
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter();
适用场景:快速使用,使用所有默认值
方式 2:指定 keepSeparator
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(false);
适用场景:只需要控制分隔符处理
方式 3:完整参数
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(
500, // chunkSize
200, // minChunkSizeChars
10, // minChunkLengthToEmbed
5000, // maxNumChunks
true // keepSeparator
);
适用场景:需要完全自定义配置
方式 4:Builder 模式(推荐)
ChineseTokenTextSplitter splitter = ChineseTokenTextSplitter.builder()
.withChunkSize(500)
.withMinChunkSizeChars(200)
.withMinChunkLengthToEmbed(10)
.withMaxNumChunks(5000)
.withKeepSeparator(true)
.build();
适用场景:需要灵活配置,代码可读性好
特性 2: 中文标点符号支持
支持的标点符号:
- 英文:
. ? ! \n - 中文:
。 ? !
优势:
- ✅ 识别中文标点符号
- ✅ 在中文句子边界处分割
- ✅ 保持中文语义完整性
特性 3: 智能句子边界分割
工作原理:
- 按 Token 数切分文本
- 在分块内查找最后一个标点符号
- 如果标点位置 > minChunkSizeChars,则在标点处分割
- 否则保留原块
优势:
- ✅ 保持句子完整性
- ✅ 避免在句子中间分割
- ✅ 提高检索精度
特性 4: 防止碎片化
多层过滤:
- minChunkSizeChars:控制按句子分割的最小长度
- minChunkLengthToEmbed:过滤过小的分块
效果:
- ✅ 避免产生过小的分块
- ✅ 提高向量化质量
- ✅ 减少存储开销
特性 5: 最大分块数限制
maxNumChunks:
- 作用:限制最大分块数量
- 默认值:10000
- 目的:防止无限分割
使用场景:
- 超长文档处理
- 防止内存溢出
- 控制处理时间
代码分析
1. 类图结构
┌─────────────────────────────┐
│ TextSplitter │
│ (Spring AI 父类) │
└──────────────┬──────────────┘
│ extends
▼
┌─────────────────────────────┐
│ ChineseTokenTextSplitter │
│ │
│ - chunkSize │
│ - minChunkSizeChars │
│ - minChunkLengthToEmbed │
│ - maxNumChunks │
│ - keepSeparator │
│ - encoding │
│ │
│ + splitText() │
│ + doSplit() │
│ + getEncodedTokens() │
│ + decodeTokens() │
│ │
│ ┌─────────────────────┐ │
│ │ Builder │ │
│ │ (内部类) │ │
│ └─────────────────────┘ │
└─────────────────────────────┘
2. 方法调用链
apply(List<Document>)
↓
splitText(String) [模板方法]
↓
doSplit(String, int) [核心逻辑]
├─ getEncodedTokens() [Token 编码]
├─ decodeTokens() [Token 解码]
└─ 循环处理
├─ 查找句子边界
├─ 调整分块
├─ 处理分隔符
└─ 过滤小分块
3. 设计模式应用
3.1 模板方法模式
- 父类:定义算法骨架
- 子类:实现具体逻辑
3.2 Builder 模式
- Builder 类:提供链式配置
- build() 方法:创建不可变对象
3.3 策略模式(隐含)
- 不同的分割策略(按 Token、按句子等)
- 可扩展的分割算法
最佳实践
1. 参数配置建议
chunkSize 选择
根据模型上下文窗口:
// GPT-4 (128K tokens)
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(500, 200, 10, 10000, true);
// GPT-3.5 (16K tokens)
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(300, 150, 10, 10000, true);
// Claude (200K tokens)
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(1000, 400, 10, 10000, true);
根据文档类型:
// 技术文档(推荐)
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(400, 200, 10, 10000, true);
// 普通文档(推荐)
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(300, 150, 10, 10000, true);
// 长文档(推荐)
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(500, 250, 10, 10000, true);
minChunkSizeChars 选择
建议值:
- 短文档:100-200 字符
- 普通文档:200-300 字符
- 长文档:300-400 字符
原则:
- 太小:可能产生过小的分块
- 太大:可能无法按句子分割
minChunkLengthToEmbed 选择
建议值:5-20 字符
原则:
- 太小:可能包含无意义的分块
- 太大:可能过滤掉有用的短文本
2. keepSeparator 选择
keepSeparator=true(推荐用于大多数场景):
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(true);
适用场景:
- 需要保留格式的文档
- Markdown 文档
- 代码文档
keepSeparator=false:
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(false);
适用场景:
- 纯文本文档
- 不需要保留格式
- 需要压缩空白
3. 使用 Builder 模式
推荐方式:
ChineseTokenTextSplitter splitter = ChineseTokenTextSplitter.builder()
.withChunkSize(500)
.withMinChunkSizeChars(200)
.withMinChunkLengthToEmbed(10)
.withMaxNumChunks(5000)
.withKeepSeparator(true)
.build();
优势:
- 代码可读性好
- 参数清晰
- 易于维护
4. 性能优化
批量处理:
// 一次性处理多个文档
List<Document> allDocuments = new ArrayList<>();
for (Resource resource : resources) {
List<Document> docs = reader.read(resource);
allDocuments.addAll(docs);
}
List<Document> splitDocs = splitter.apply(allDocuments);
缓存结果:
// 避免重复分割相同文档
Map<String, List<Document>> cache = new ConcurrentHashMap<>();
String key = document.getId();
if (!cache.containsKey(key)) {
cache.put(key, splitter.apply(List.of(document)));
}
常见问题
Q1: chunkSize 应该设置多大?
建议:
- 根据模型上下文窗口:chunkSize 应该小于模型上下文窗口的 1/4
- 根据文档类型:
- 技术文档:300-500 tokens
- 普通文档:200-400 tokens
- 长文档:500-800 tokens
示例:
// GPT-4 (128K tokens) - 技术文档
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(500, 200, 10, 10000, true);
// GPT-3.5 (16K tokens) - 普通文档
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(300, 150, 10, 10000, true);
Q2: 为什么需要 minChunkSizeChars?
原因:
- 防止按句子分割后产生过小的分块
- 如果按句子分割后长度 < minChunkSizeChars,则保留原块
- 保持分块大小的合理性
示例:
// 如果 minChunkSizeChars = 200
// 分块文本:"这是一个很短的句子。"
// 按句子分割后长度 = 10 字符 < 200
// 结果:保留原块(不按句子分割)
Q3: minChunkLengthToEmbed 的作用是什么?
作用:
- 过滤掉过小的分块
- 防止产生无意义的分块
- 提高向量化质量
建议值:5-20 字符
示例:
// 如果 minChunkLengthToEmbed = 10
// 分块文本:"你好" (2 字符) → 被过滤
// 分块文本:"这是一个测试" (6 字符) → 被过滤
// 分块文本:"这是一个较长的测试文本" (12 字符) → 保留
Q4: 如何调试分割结果?
调试方法:
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(500, 200, 10, 10000, true);
List<Document> splitDocs = splitter.apply(documents);
// 打印分割结果
splitDocs.forEach((doc, index) -> {
System.out.println("=== 分块 " + (index + 1) + " ===");
System.out.println("长度: " + doc.getText().length() + " 字符");
System.out.println("内容: " + doc.getText().substring(0, Math.min(100, doc.getText().length())));
System.out.println();
});
Q5: 分割后文档数量过多怎么办?
解决方案:
- 增加 chunkSize:减少分块数量
- 提高 minChunkLengthToEmbed:过滤更多小分块
- 设置 maxNumChunks:限制最大分块数
示例:
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(
800, // 增大 chunkSize
400, // 相应增大 minChunkSizeChars
20, // 提高最小长度
5000, // 限制最大分块数
true
);
Q6: 为什么需要重新编码 Token?
原因:
- 分块可能按句子边界调整
- 实际分块大小可能小于 chunkSize
- 需要准确计算已使用的 Token 数
示例:
// 原始 Token 数:500
// 按句子调整后实际 Token 数:450
// 需要从剩余 Token 中移除 450 个,而不是 500 个
tokens = tokens.subList(getEncodedTokens(chunkText).size(), tokens.size());
总结
核心要点
- 继承 TextSplitter:使用模板方法模式
- Token 编码:使用 jtokkit 库,支持 CL100K_BASE
- 智能分割:按句子边界分割,保持语义完整
- 中文优化:识别中文标点符号
- 防止碎片化:多层过滤机制
设计模式
- 模板方法模式:继承 TextSplitter
- Builder 模式:提供灵活配置
- 策略模式(隐含):可扩展的分割算法
学习路径
- ✅ 理解 Token 编码原理
- ✅ 掌握分割算法流程
- ✅ 学习参数配置
- ✅ 实践最佳实践
- ✅ 优化性能
下一步
- 📖 学习其他分割器(TokenTextSplitter)
- 📖 学习元数据增强(Metadata Enricher)
- 📖 学习向量化(Embedding)
- 📖 学习向量存储(VectorStore)
相关文件:
SplitterTest.java- 分割器使用测试ReaderTest.java- 文档读取测试TextSplitter.java- Spring AI 父类
文档分割器使用经验总结
📋 目录
分割策略核心原则
核心观点
💡 只要 token 数合理就行,不要想着严格按照主题来分(企业级知识库各式各样的文档资料)
原因:
- 企业级知识库文档多样,格式不统一
- 无法保证每个 chunk 是一个完整的主题内容
- 即使人为干预也很难做到完美
- 实战中往往需要结合资料来决定分割器
推荐做法:
- ✅ 按 Token 数分割(简单实用)
- ✅ 结合实际情况调整参数
- ✅ 必要时加入人工干预
过细分块的问题
1. 语义割裂
问题描述:
- 破坏上下文连贯性
- 影响模型理解
- 丢失重要语义信息
示例:
原文:"Spring AI 是一个强大的框架,它提供了丰富的功能。"
过细分块:
- 块1: "Spring AI 是一个强大的框架"
- 块2: "它提供了丰富的功能。"
问题:块2 中的"它"失去了指代对象
影响:
- ❌ 检索精度下降
- ❌ 生成答案不连贯
- ❌ 上下文信息丢失
2. 计算成本增加
问题描述:
- 分块过细导致向量嵌入次数增多
- 检索次数增加
- 时间和算力开销增大
成本分析:
假设文档有 1000 tokens:
- 分块大小 100 tokens → 10 个分块 → 10 次向量化
- 分块大小 500 tokens → 2 个分块 → 2 次向量化
成本差异:5 倍
影响:
- ❌ API 调用成本增加
- ❌ 处理时间延长
- ❌ 存储空间占用增加
3. 信息冗余与干扰
问题描述:
- 碎片化的文本块可能引入无关内容
- 干扰检索结果的质量
- 降低生成答案的准确性
示例:
查询:"退票费用是多少?"
过细分块结果:
- 块1: "预订航班: 通过我们的网站或移动应用程序预订。"
- 块2: "预订时需要全额付款。"
- 块3: "取消预订: 最晚在航班起飞前 48 小时取消。"
- 块4: "取消费用:经济舱 75 美元..."
问题:检索可能返回块1、块2等无关内容
影响:
- ❌ 检索精度下降
- ❌ 答案准确性降低
- ❌ 用户体验变差
分块过大的弊端
1. 信息丢失风险
问题描述:
- 过大的文本块可能超出嵌入模型的输入限制
- 导致关键信息未被有效编码
- 超出上下文窗口限制
限制说明:
常见模型上下文窗口:
- GPT-3.5: 16K tokens
- GPT-4: 128K tokens
- Claude: 200K tokens
如果分块过大(如 20K tokens),可能:
- 超出模型限制
- 被截断
- 丢失关键信息
影响:
- ❌ 关键信息丢失
- ❌ 向量化不完整
- ❌ 检索效果差
2. 检索精度下降
问题描述:
- 大块内容可能包含多主题混合
- 与用户查询的相关性降低
- 影响模型反馈效果
示例:
查询:"退票费用是多少?"
过大分块(包含多个主题):
"预订航班: 通过我们的网站或移动应用程序预订。预订时需要全额付款。
取消预订: 最晚在航班起飞前 48 小时取消。取消费用:经济舱 75 美元。
更改预订: 允许在航班起飞前 24 小时更改。改签费:经济舱 50 美元。"
问题:包含预订、取消、更改多个主题,相关性降低
影响:
- ❌ 检索相关性下降
- ❌ 答案准确性降低
- ❌ 上下文噪音增加
不同场景的分块策略
场景 1: 微博/短文本
特点:
- 文本长度短(通常 < 500 字符)
- 语义完整
- 结构简单
分块策略:
- 策略:句子级分块,保留完整语义
- 方法:按句子分割,不进一步拆分
参数参考:
- 每块:100-200 字符
- chunkSize: 50-100 tokens
- 重叠:0-10%
代码示例:
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(
100, // chunkSize: 较小的分块
50, // minChunkSizeChars: 最小字符数
10, // minChunkLengthToEmbed: 最小嵌入长度
1000, // maxNumChunks: 最大分块数
true // keepSeparator: 保留分隔符
);
场景 2: 学术论文
特点:
- 文本长度长(通常 > 10000 字符)
- 结构清晰(章节、段落)
- 需要保持上下文
分块策略:
- 策略:段落级分块,叠加 10% 重叠
- 方法:按段落分割,保持 10% 重叠
参数参考:
- 每块:300-500 字符
- chunkSize: 200-400 tokens
- 重叠:10-20%
代码示例:
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(
300, // chunkSize: 中等分块
200, // minChunkSizeChars: 最小字符数
20, // minChunkLengthToEmbed: 最小嵌入长度
5000, // maxNumChunks: 最大分块数
true // keepSeparator: 保留分隔符
);
场景 3: 法律合同
特点:
- 文本结构严格(条款、章节)
- 需要精确分割
- 语义边界清晰
分块策略:
- 策略:条款级分块,严格按条款分隔
- 方法:识别条款标记,按条款分割
参数参考:
- 每块:200-400 字符
- chunkSize: 150-300 tokens
- 重叠:5-10%
代码示例:
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(
250, // chunkSize: 中等分块
150, // minChunkSizeChars: 最小字符数
15, // minChunkLengthToEmbed: 最小嵌入长度
3000, // maxNumChunks: 最大分块数
true // keepSeparator: 保留分隔符
);
注意:
- 可能需要自定义分割器识别条款标记
- 建议使用元数据标记条款编号
场景 4: 长篇小说
特点:
- 文本长度极长(通常 > 100000 字符)
- 结构复杂(章节、段落)
- 需要递归拆分
分块策略:
- 策略:章节级分块,长段落递归拆分
- 方法:先按章节分割,再按段落分割
参数参考:
- 每块:500-1000 字符
- chunkSize: 400-800 tokens
- 重叠:10-20%
代码示例:
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter(
600, // chunkSize: 较大分块
400, // minChunkSizeChars: 最小字符数
30, // minChunkLengthToEmbed: 最小嵌入长度
10000, // maxNumChunks: 最大分块数
true // keepSeparator: 保留分隔符
);
注意:
- 可能需要多级分割(章节 → 段落 → 句子)
- 建议使用元数据标记章节信息
参数配置参考
通用参数说明
| 参数 | 说明 | 推荐范围 |
|---|---|---|
chunkSize |
每个分块的目标 Token 数 | 200-800 tokens |
minChunkSizeChars |
最小分块字符数 | 100-400 字符 |
minChunkLengthToEmbed |
最小嵌入长度 | 10-30 字符 |
maxNumChunks |
最大分块数量 | 1000-10000 |
keepSeparator |
是否保留分隔符 | true/false |
场景参数对照表
| 场景 | chunkSize (tokens) | 字符数 | 重叠 | keepSeparator |
|---|---|---|---|---|
| 微博/短文本 | 50-100 | 100-200 | 0-10% | true |
| 学术论文 | 200-400 | 300-500 | 10-20% | true |
| 法律合同 | 150-300 | 200-400 | 5-10% | true |
| 长篇小说 | 400-800 | 500-1000 | 10-20% | true |
| 技术文档 | 300-500 | 400-600 | 10-15% | true |
| 普通文档 | 200-400 | 300-500 | 10-15% | true |
根据模型上下文窗口调整
| 模型 | 上下文窗口 | 推荐 chunkSize | 说明 |
|---|---|---|---|
| GPT-3.5 | 16K tokens | 200-400 tokens | 保守设置 |
| GPT-4 | 128K tokens | 500-1000 tokens | 可以设置较大 |
| Claude | 200K tokens | 800-1500 tokens | 可以设置很大 |
原则:chunkSize 应该小于模型上下文窗口的 1/4
实战建议
1. 选择合适的分割器
推荐方案:
| 文档类型 | 推荐分割器 | 原因 |
|---|---|---|
| 英文文档 | TokenTextSplitter |
简单高效 |
| 中文文档 | ChineseTokenTextSplitter |
中文优化 |
| 代码文档 | ChineseTokenTextSplitter (keepSeparator=false) |
不保留换行 |
| 混合文档 | ChineseTokenTextSplitter |
支持多语言 |
2. 参数调优流程
步骤 1:初始配置
// 使用默认配置开始
ChineseTokenTextSplitter splitter = new ChineseTokenTextSplitter();
步骤 2:测试分割结果
List<Document> splitDocs = splitter.apply(documents);
splitDocs.forEach(doc -> {
System.out.println("长度: " + doc.getText().length());
System.out.println("内容: " + doc.getText().substring(0, Math.min(100, doc.getText().length())));
});
步骤 3:根据结果调整
- 如果分块过多 → 增大 chunkSize
- 如果分块过少 → 减小 chunkSize
- 如果语义割裂 → 增大 minChunkSizeChars
- 如果碎片化严重 → 增大 minChunkLengthToEmbed
步骤 4:验证检索效果
// 测试检索精度
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder()
.query("测试查询")
.topK(5)
.build()
);
// 检查结果相关性
3. 不要过度追求主题分割
原因:
- ❌ 企业级知识库文档多样,格式不统一
- ❌ 无法保证每个 chunk 是一个完整的主题
- ❌ 即使人为干预也很难做到完美
- ❌ 实现成本高,效果不一定好
推荐做法:
- ✅ 按 Token 数分割(简单实用)
- ✅ 结合实际情况调整参数
- ✅ 必要时加入人工干预
- ✅ 使用元数据增强(关键词、摘要)提高检索精度
4. 结合资料决定分割器
决策流程:
1. 分析文档类型
├─ 短文本 → 句子级分割
├─ 长文档 → 段落级分割
└─ 结构化文档 → 按结构分割
2. 测试不同参数
├─ 测试 chunkSize
├─ 测试重叠比例
└─ 测试最小长度
3. 验证检索效果
├─ 测试检索精度
├─ 测试答案质量
└─ 测试响应时间
4. 优化调整
├─ 根据结果调整参数
└─ 必要时加入人工干预
5. 使用元数据增强
关键词增强:
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(chatModel, 5);
documents = enricher.apply(documents);
摘要增强:
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(
chatModel,
List.of(SummaryMetadataEnricher.SummaryType.CURRENT)
);
documents = enricher.apply(documents);
作用:
- 提高检索精度
- 支持元数据过滤
- 弥补分割不完美的缺陷
常见问题
Q1: 如何判断分块是否合适?
判断标准:
- 分块数量:不应该过多或过少
- 语义完整性:每个分块应该保持语义完整
- 检索精度:检索结果应该相关
- 答案质量:生成的答案应该准确
测试方法:
// 1. 检查分块数量
System.out.println("分块数量: " + splitDocs.size());
// 2. 检查分块长度分布
splitDocs.forEach(doc -> {
System.out.println("长度: " + doc.getText().length());
});
// 3. 测试检索效果
List<Document> results = vectorStore.similaritySearch(...);
// 检查结果相关性
Q2: 重叠应该设置多少?
建议:
- 一般场景:10-20% 重叠
- 短文档:0-10% 重叠
- 长文档:15-25% 重叠
原因:
- 保持上下文连贯性
- 避免重要信息被分割
- 提高检索精度
Q3: 如何处理特殊格式的文档?
解决方案:
- 自定义分割器:继承
TextSplitter,实现自定义逻辑 - 预处理文档:在分割前预处理文档格式
- 使用元数据:使用元数据标记特殊格式
示例:
// 自定义分割器识别条款
public class ClauseSplitter extends TextSplitter {
@Override
protected List<String> splitText(String text) {
// 识别条款标记(如"第一条"、"1."等)
// 按条款分割
}
}
Q4: 分块后如何验证效果?
验证方法:
- 检查分块数量:不应该过多或过少
- 检查分块质量:语义是否完整
- 测试检索精度:检索结果是否相关
- 测试答案质量:生成的答案是否准确
代码示例:
// 1. 检查分块
splitDocs.forEach(doc -> {
System.out.println("长度: " + doc.getText().length());
System.out.println("内容: " + doc.getText().substring(0, Math.min(100, doc.getText().length())));
});
// 2. 测试检索
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder()
.query("测试查询")
.topK(5)
.build()
);
// 3. 检查结果
results.forEach(doc -> {
System.out.println("相似度: " + doc.getScore());
System.out.println("内容: " + doc.getText());
});
总结
核心原则
- ✅ 按 Token 数分割:简单实用,适合大多数场景
- ✅ 不要过度追求主题分割:企业级知识库文档多样,难以统一
- ✅ 结合实际情况调整:根据文档类型和需求调整参数
- ✅ 必要时加入人工干预:特殊场景需要人工处理
最佳实践
- 选择合适的 chunkSize:根据模型上下文窗口和文档类型
- 设置适当的重叠:10-20% 重叠保持上下文
- 过滤小分块:使用 minChunkLengthToEmbed 过滤
- 使用元数据增强:提高检索精度
- 验证分割效果:测试检索精度和答案质量
学习路径
- ✅ 理解分割原理
- ✅ 掌握参数配置
- ✅ 实践不同场景
- ✅ 优化分割效果
- ✅ 验证检索精度

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)