盘点|4年JEPA进化之路,12篇核心突破!LeCun(杨立昆)如何用它重构AI表征学习?
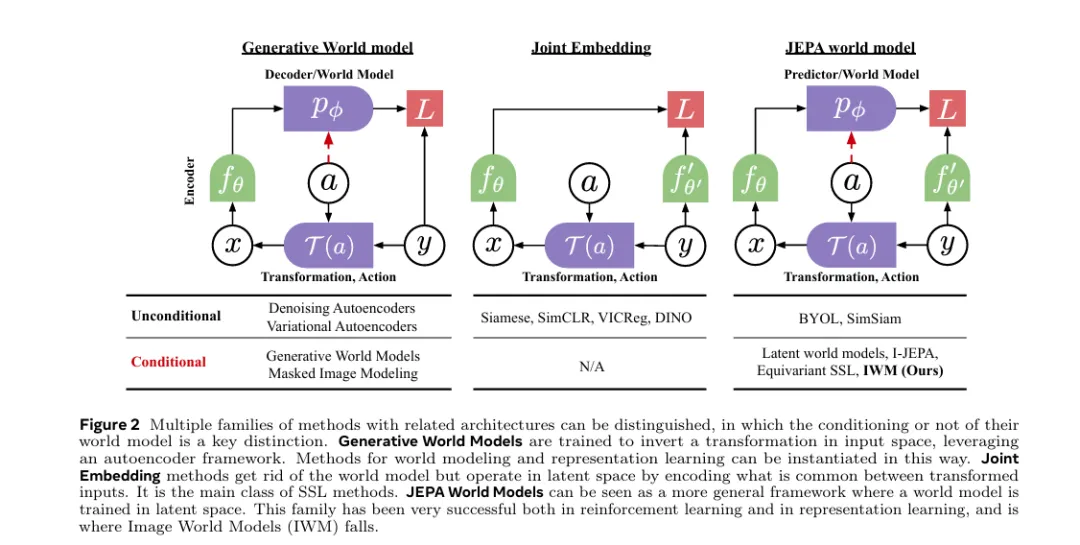
同年另一篇工作⁵(arXiv:2403.00504)进一步拓展JEPA的预测任务,提出“图像世界模型(IWM)”,将预测范围从“掩码块”扩展到“全局 photometric变换”,实现了表征抽象度的可控性——既可学习对比式的不变表征,也可学习掩码建模的等变表征,极大提升了JEPA的泛化能力。未来,随着JEPA在小样本学习、低资源模态、实时性优化上的持续突破,它有望成为连接大模型与真实世界的“通用表

「读懂LeCun的“世界模型”」
目录
2023:理论奠基与图像落地——I-JEPA与H-JEPA的双重突破
2024:视频拓展与泛化升级——V-JEPA开启动态表征学习
AI的“世界认知”能力,正在被JEPA改写?
时至今日,“自监督学习”仍是AI领域的核心赛道,而LeCun团队主推的JEPA(联合嵌入预测架构),无疑是近两年最具颠覆性的技术方向——它跳出生成式重建、对比式学习的传统框架,用“潜空间预测”为AI搭建起理解世界的全新路径。
从图像到视频,从语言到机器人,JEPA正在快速渗透多模态领域,成为通用AI的“表征引擎”。它的崛起并非偶然,而是LeCun团队对“AI如何高效学习世界模型”这一核心问题的持续探索。
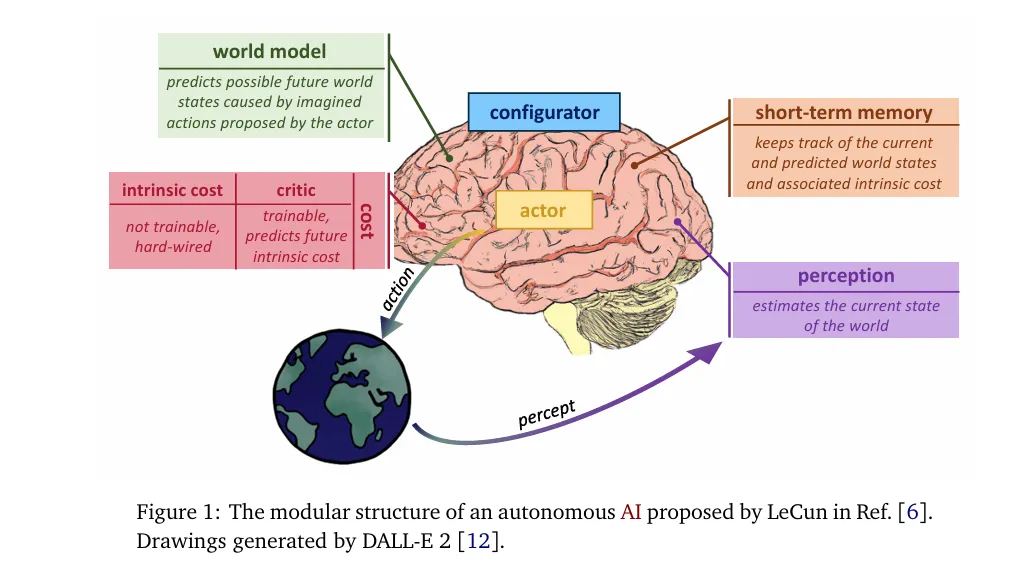
本文将梳理2022–2026年JEPA的关键突破与技术演进,看这套架构如何从实验室的理论草图,逐步成长为横跨多模态、赋能机器人规划的通用范式。
01 JEPA为什么能颠覆传统?
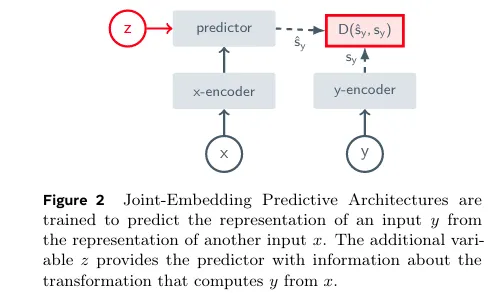
JEPA,全称Joint Embedding Predictive Architecture,即联合嵌入预测架构,其核心使命与传统自监督方法截然不同:放弃像素/Token级重建,专注于抽象表征空间的预测学习。
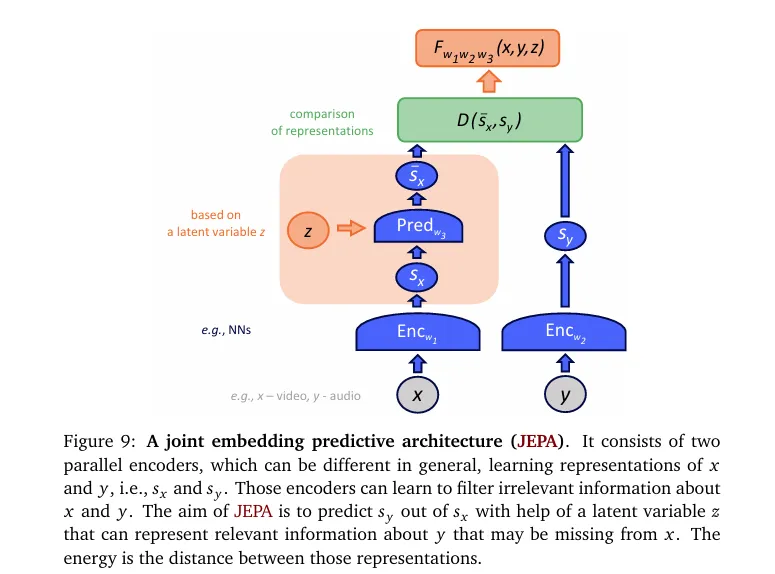
你可以把它理解为——传统AI学习“复刻细节”(比如生成相似图片、预测下一个词),而JEPA学习“把握本质”:给模型一段上下文信息,让它预测缺失部分的抽象特征,迫使模型理解数据的内在规律、动态逻辑与语义关联。
这种设计的优势显而易见:摆脱对数据增强的依赖、避免表征坍缩、高效学习可预测、可操控的世界模型,而这些正是通向通用AI的关键。从视觉理解到语言建模,从语音处理到机器人规划,只要涉及“从数据中提炼核心规律”,JEPA都能发挥核心作用。
接下来,我们将以年度为轴,拆解JEPA如何从早期探索,逐步覆盖多模态、落地真实场景。
02 JEPA的逐年进化路径
2022:JEPA初现——离线场景的首次验证
JEPA 的核心架构思路由杨立昆于 2022 年 6 月在《A Path Towards Autonomous Machine Intelligence》中正式提出,而 LeCun 团队于 NeurIPS 2022 发表的短篇研究 ¹(arXiv:2211.10831),是 JEPA 提出后首批实证验证工作。
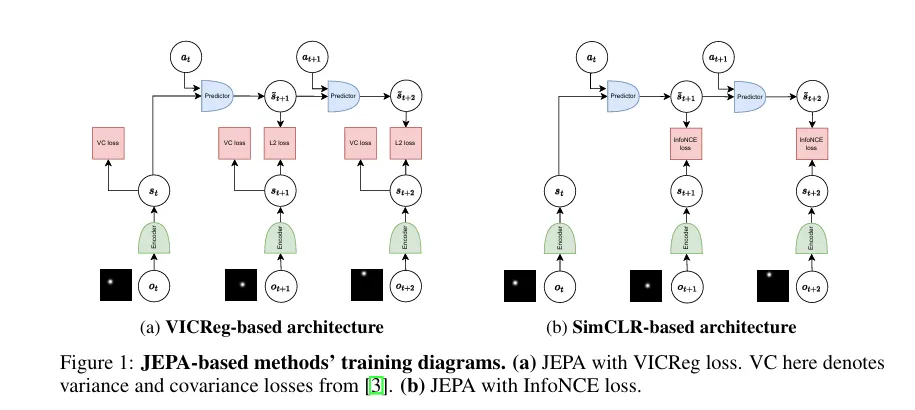
该研究在 “移动点 + 干扰背景” 的简单环境中,聚焦无奖励、全离线场景,对比了搭配 VICReg、SimCLR 目标的 JEPA 与重建式、逆动力学建模等方法的性能。结果显示:当干扰噪声逐帧变化时,JEPA 表现持平甚至优于重建式方法,但在固定噪声下会因聚焦 “慢特征”(静态干扰)而忽略目标 —— 这一发现既验证了 JEPA “重建无关” 设计的可行性,也明确了其早期短板,为后续 HJEPA(层次化 JEPA)等优化方向提供了关键依据。
这一阶段的工作虽偏向基础验证,但为 JEPA 从理论框架走向实际落地提供了重要的实证支撑。
2023:理论奠基与图像落地——I-JEPA与H-JEPA的双重突破
2023年是JEPA的“范式确立年”,两篇核心论文分别从理论与工程层面,为JEPA搭建起完整框架。
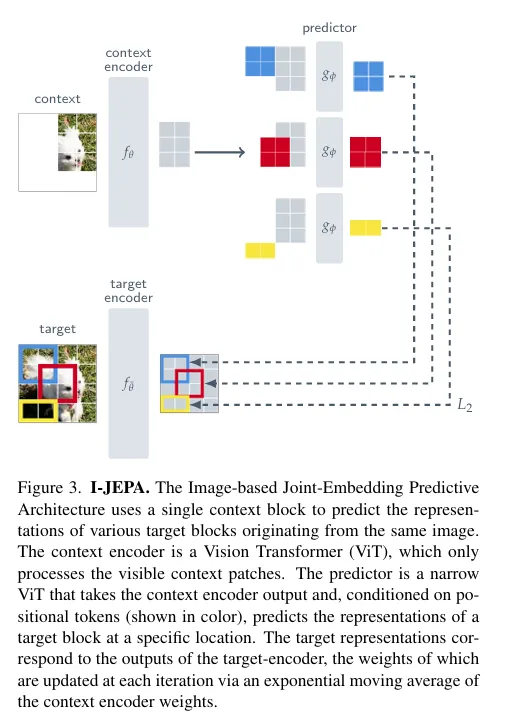
年初,ICCV论文I-JEPA²(arXiv:2301.08243)横空出世,成为图像JEPA的奠基之作。它提出了 JEPA 的经典设计范式:用 “大尺度语义目标块 + 空间分布式上下文块”,从单张图像中预测缺失块的表征,彻底摆脱对数据增强的依赖。基于 ViT-Huge/14 训练,I-JEPA 在 ImageNet 下游任务中表现优异,不仅线性探测、半监督学习等任务性能超越同期方法,还以更少训练 epochs 实现更高效率,充分证明了 JEPA 在视觉表征学习中的潜力。该项工作因此被CVPR2023接收。
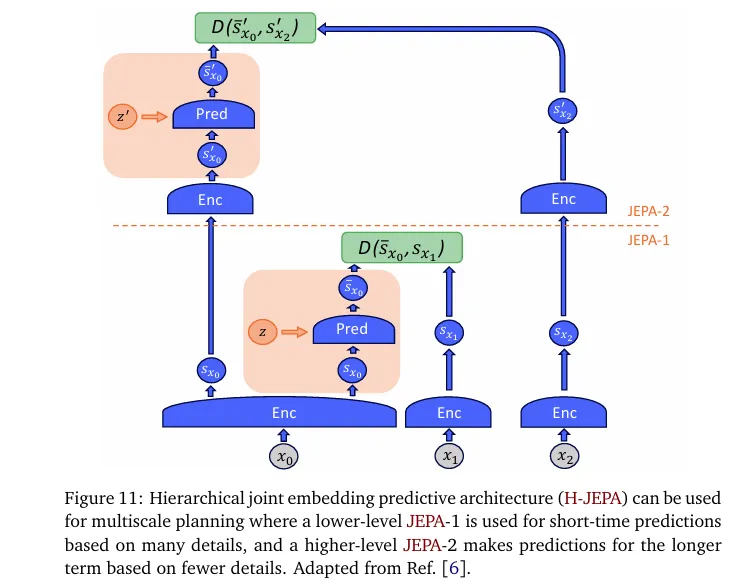
年中,LeCun团队发表H-JEPA综述³(arXiv:2306.02572),为JEPA构建了统一理论框架。论文将能量模型、潜变量模型与JEPA结合,提出“分层联合嵌入预测架构”,明确JEPA的核心目标是学习“抽象、可预测、可操控”的世界模型——这篇综述堪称JEPA的“理论纲领”,为后续所有变种(V-JEPA/LLM-JEPA)提供了底层逻辑支撑。
至此,JEPA完成了“理论+工程”的双重闭环,正式从学术概念走向可复用的技术框架。
2024:视频拓展与泛化升级——V-JEPA开启动态表征学习
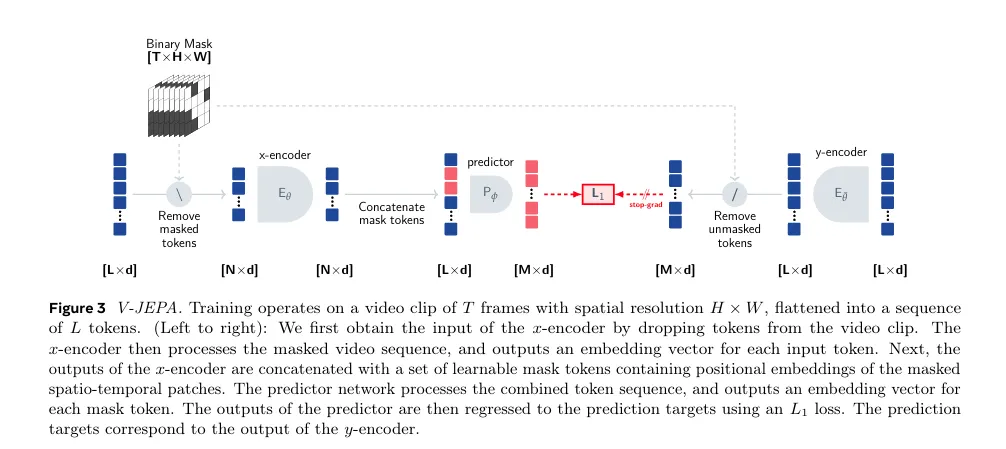
在图像领域验证可行性后,JEPA的探索重点转向动态场景——视频表征学习。2024年的V-JEPA⁴(arXiv:2404.08471)成为这一方向的里程碑。
V-JEPA首次实现“纯视频自监督学习”:不依赖图像预训练、文本辅助或负样本,仅用200万段视频训练,通过预测跨帧特征表征,同时掌握“外观内容”与“运动动态”。其最大模型ViT-H/16在Kinetics-400(81.9%)、ImageNet1K(77.9%)等图像/视频任务中同步达到SOTA,证明JEPA能高效捕捉时序与空间双重信息。
同年另一篇工作⁵(arXiv:2403.00504)进一步拓展JEPA的预测任务,提出“图像世界模型(IWM)”,将预测范围从“掩码块”扩展到“全局 photometric变换”,实现了表征抽象度的可控性——既可学习对比式的不变表征,也可学习掩码建模的等变表征,极大提升了JEPA的泛化能力。
2025:跨模态爆发与理论标准化——从语言到语音的全面渗透
2025年,JEPA进入“多模态爆发期”,同时完成理论层面的标准化优化,实现“质与量”的双重飞跃。
在理论优化上,LeJEPA⁶(arXiv:2511.08544)解决了早期JEPA依赖启发式设计的痛点。它提出“各向同性高斯嵌入”为最优分布,设计轻量的SIGReg正则化,实现“无启发式”JEPA:仅1个超参、线性复杂度、50行代码即可部署,在多种架构、数据集上验证了稳定性,推动JEPA工业化落地。
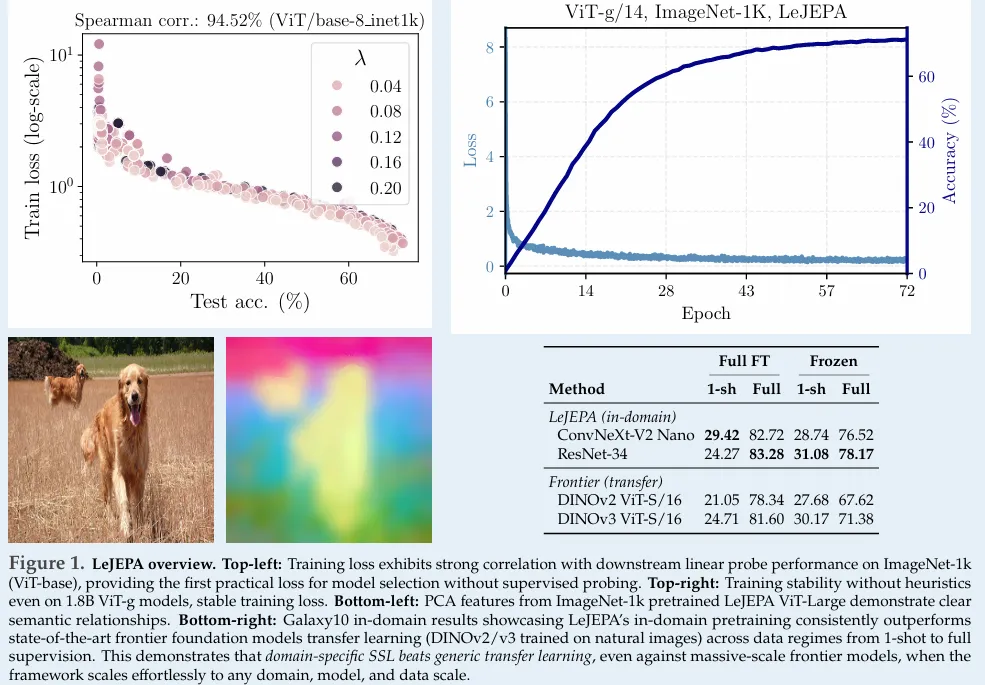
在跨模态拓展上,两大突破尤为亮眼:
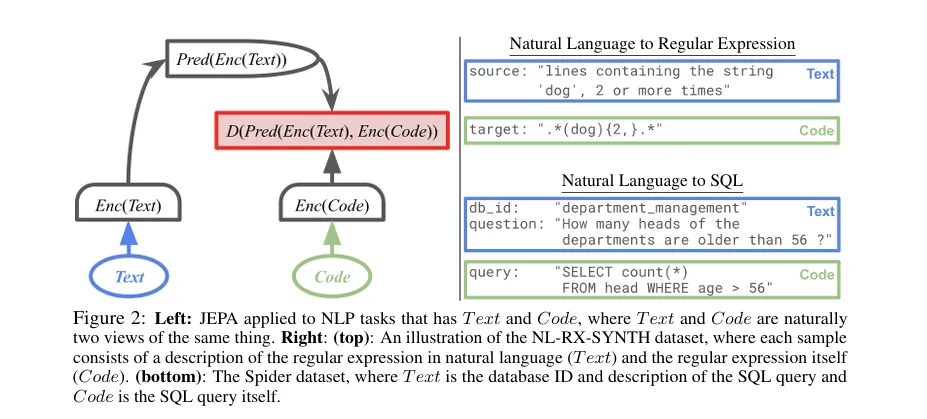
一是LLM-JEPA⁷(arXiv:2509.14252),首次将JEPA引入语言领域,通过预测文本片段的潜表征,打破LLM依赖Token生成的局限,在Llama3、Gemma2等模型上显著提升性能与抗过拟合能力;
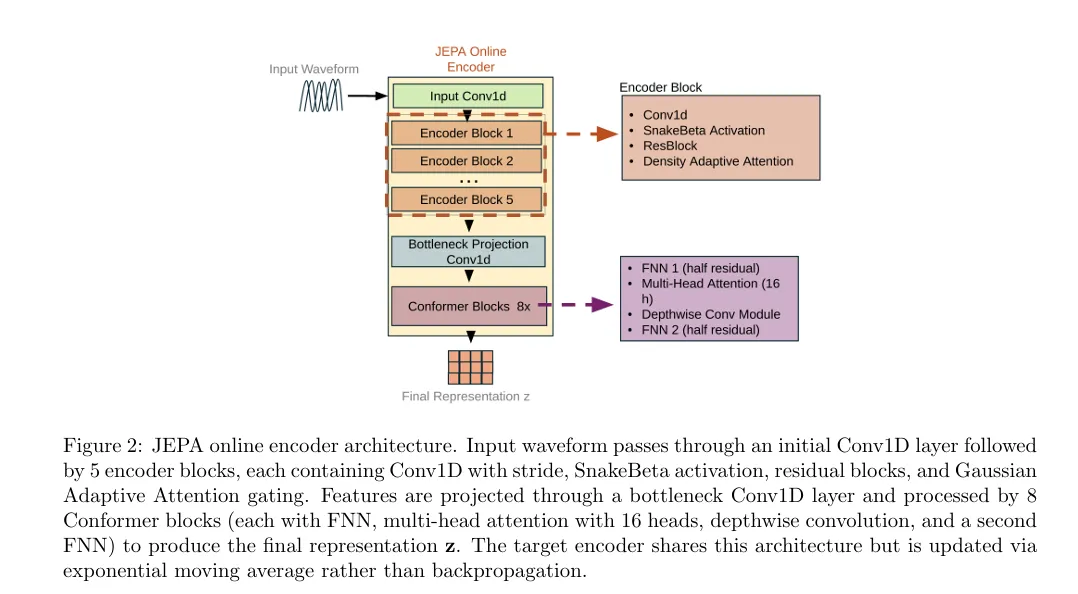
二是语音JEPA⁸(arXiv:2512.07168),采用“JEPA+密度自适应注意力”双阶段框架,将语音压缩至47.5 tokens/sec,兼顾语义理解与高效编码。
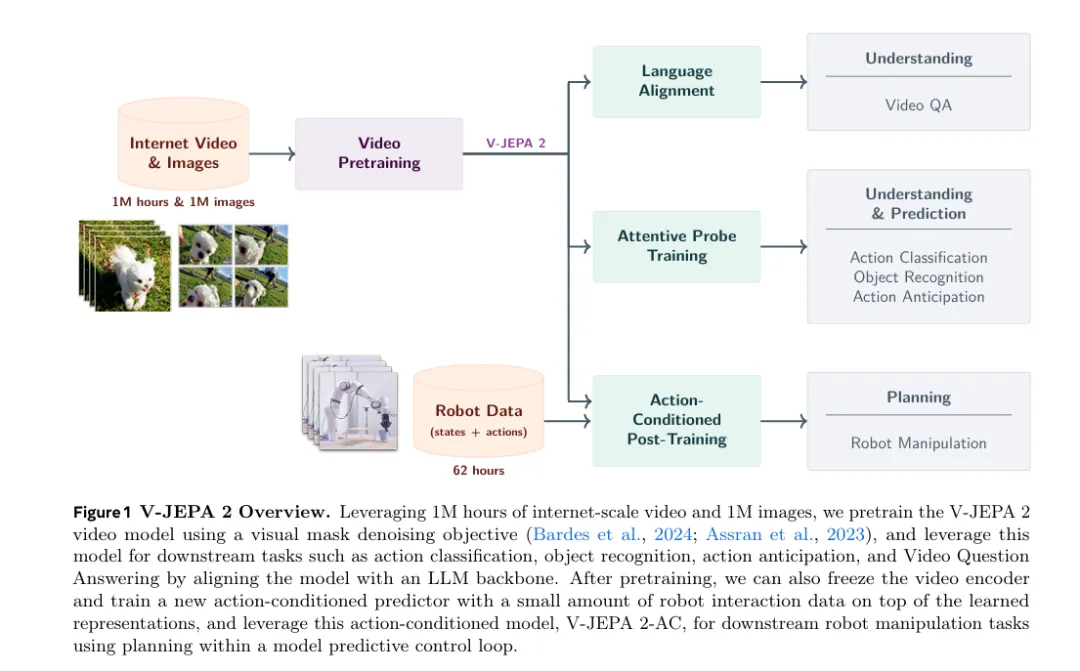
此外,V-JEPA 2⁹(arXiv:2506.09985)实现JEPA的落地突破:基于100万小时互联网视频预训练,在动作理解、预测任务中达到SOTA,更通过少量机器人数据微调,零样本部署到Franka机械臂完成抓取任务,打通“表征学习→机器人规划”的链路。
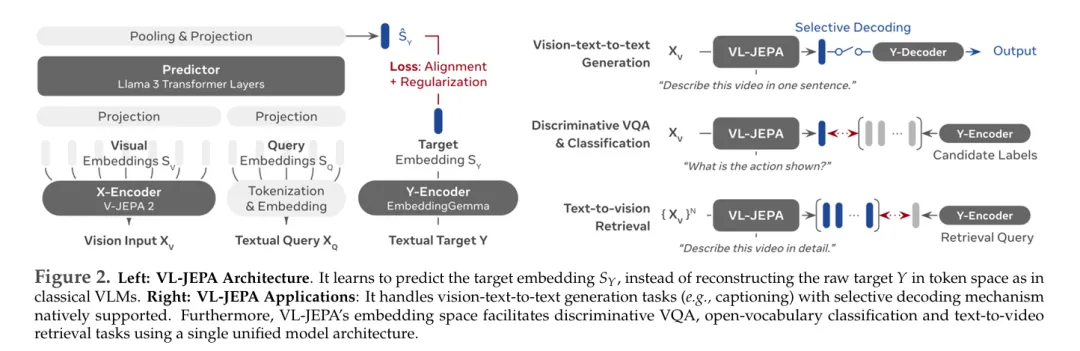
VL-JEPA¹⁰(arXiv:2512.10942)则深耕视觉-语言领域,以50%参数量超越传统VLM,支持选择性解码,兼顾效率与性能。
2026:规划闭环——JEPA赋能机器人的终极落地
2026年初,JEPA完成“表征学习→动作规划”的完整闭环,价值引导规划JEPA¹¹(arXiv:2601.00844)成为关键突破。并且该工作被World Modeling Workshop 2026所接收。
该工作通过塑造JEPA的表征空间,让目标条件下的价值函数可通过表征距离近似,显著提升JEPA世界模型的规划能力。在简单控制任务中,其规划性能远超标准JEPA模型,证明JEPA不仅能“理解世界”,更能“指导行动”,为通用机器人智能体提供了核心支撑。
03 一个范式的成型:JEPA的多元技术分支
如今,JEPA已不再是单一架构,而是发展为覆盖多模态、多场景的技术范式,其研究方向正快速分化为三大分支:
在模态拓展上,从图像、视频等单模态,走向语言、语音、视觉-语言等跨模态,甚至延伸到机器人交互场景,实现“感知-理解-规划”的全链路;在理论优化上,从早期启发式设计,走向LeJEPA的标准化、工程化,降低落地门槛;在落地场景上,从学术任务的性能比拼,走向机器人、语音编码、视频QA等实际应用,释放产业价值。
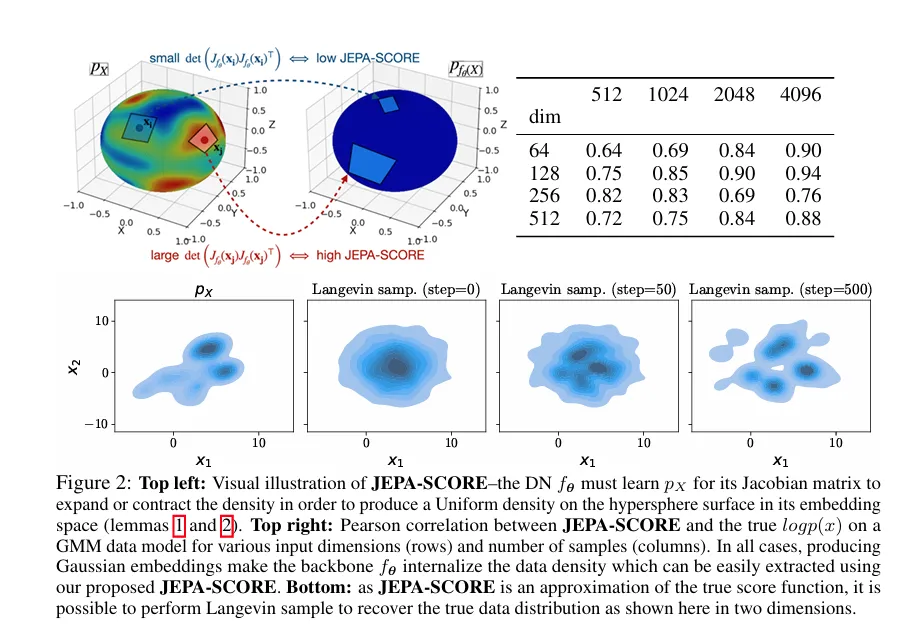
此外,JEPA的衍生思路也在不断创新,如JEPA-SCORE¹²(arXiv:2510.05949)解锁密度估计能力,可用于数据 curation、异常检测,进一步拓展了JEPA的应用边界
04 总结与展望
回顾2022–2026年,JEPA的发展轨迹清晰而迅猛:从简单环境的离线验证,到理论框架的成熟定型;从单模态的性能突破,到跨模态的全面渗透;从表征学习的技术创新,到机器人规划的落地闭环,JEPA正在重构AI理解世界的方式。
它的核心优势的在于——跳出“复刻细节”的局限,专注于“把握本质”,这种思路恰好契合了通用AI的发展需求。LeCun团队用四年时间,让JEPA从学术构想,成长为赋能多领域的核心范式,证明了无重建式自监督的巨大潜力。
未来,随着JEPA在小样本学习、低资源模态、实时性优化上的持续突破,它有望成为连接大模型与真实世界的“通用表征桥梁”,不仅推动AI在机器人、自动驾驶、智能交互等领域的落地,更可能开启下一代“类人认知”AI的新时代。
05 一点思考

杨立昆因与 Meta 在 LLM 路线上的理念分歧自立门户,坚持以 JEPA 为核心的世界模型探索,这让我们不禁思考:这套横跨多模态与机器人规划的架构,脱离 Meta 的算力与数据支持后,能否持续推进工业化落地?
新公司会将 JEPA 向更细分场景深耕还是维持多模态拓展节奏?Meta 对已落地的 V-JEPA 2 等变种又会延续怎样的研发投入?这一切依旧需要我们拭目以待。
参考资料:
1. Joint Embedding Predictive Architectures Focus on Slow Features
2. Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
3. Introduction to Latent Variable Energy-Based Models: A Path Towards Autonomous Machine Intelligence
4. Revisiting Feature Prediction for Learning Visual Representations from Video
5. Learning and Leveraging World Models in Visual Representation Learning
6. LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
7. LLM-JEPA: Large Language Models Meet Joint Embedding Predictive Architectures
8. JEPA as a Neural Tokenizer: Learning Robust Speech Representations
9. V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
10. VL-JEPA: Joint Embedding Predictive Architecture for Vision-language
11. Value-guided action planning with JEPA world models
12. Gaussian Embeddings: How JEPAs Secretly Learn Your Data Density

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献66条内容
已为社区贡献66条内容

所有评论(0)