结合代码读3DGS论文(7)——ICCV 2025 3DGS加速&压缩新工作Faster and Better 3D Splatting via Group Training论文及代码解读
ICCV 2025这篇文章提出了一种新颖的3D高斯溅射(3DGS)分组训练方法,通过将高斯基元划分为训练组和缓存组来优化训练效率。该方法采用基于不透明度的优先采样策略,有效减少冗余基元生成,在保持渲染质量的同时提升30%训练速度。实验证明该方法与现有3DGS框架兼容,显著改善场景重建效率和视图合成质量。关键创新包括循环缓存机制和数学验证的不透明度采样策略,为3DGS训练提供了高效解决方案。
ICCV 2025 3DGS加速&压缩新工作 Group Training论文及代码解读
写在前面:如果想了解更多关于3DGS的加速压缩新工作,可以关注笔者的Github仓库:Awesome-3DGS-Compress-Accelerate。
一、论文简介 🌟
1.1 基本信息
- 📖 题目:Faster and Better 3D Splatting via Group Training
- 🏫 单位:Hunan University(湖南大学);Nanyang Technological University(南洋理工大学);
- 🌍 主页:https://chengbo-wang.github.io/3DGS-with-Group-Training
- 🀄️ 论文摘要:3D Gaussian Splatting (3DGS) 已作为一种强大的新视图合成技术出现,展示了通过其高斯基元表示进行高保真场景重建的卓越能力,然而,海量基元带来的计算开销构成了训练效率的显著瓶颈。为了克服这一挑战,论文提出了分组训练(Group Training),这是一种简单而有效的策略,将高斯基元组织成可管理的组,从而优化训练效率并提高渲染质量。这种方法显示出与现有 3DGS 框架(包括原生 3DGS 和 Mip-Splatting)的普遍兼容性,始终在保持卓越合成质量的同时实现加速训练,广泛的实验表明,论文直观的分组训练策略在不同场景下实现了高达 30% 的收敛速度提升和渲染质量改善。
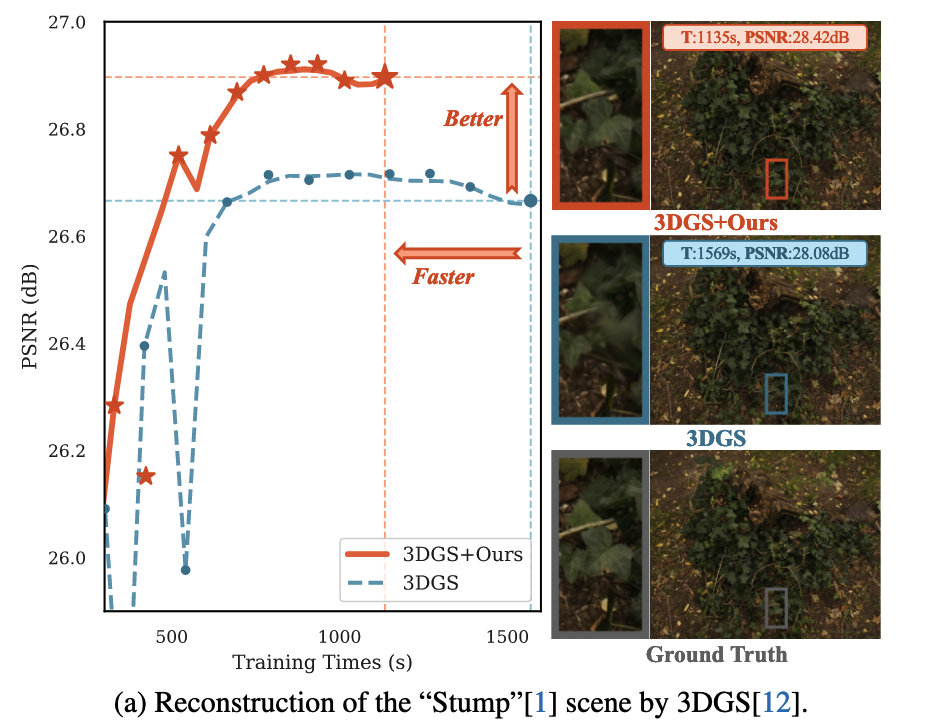
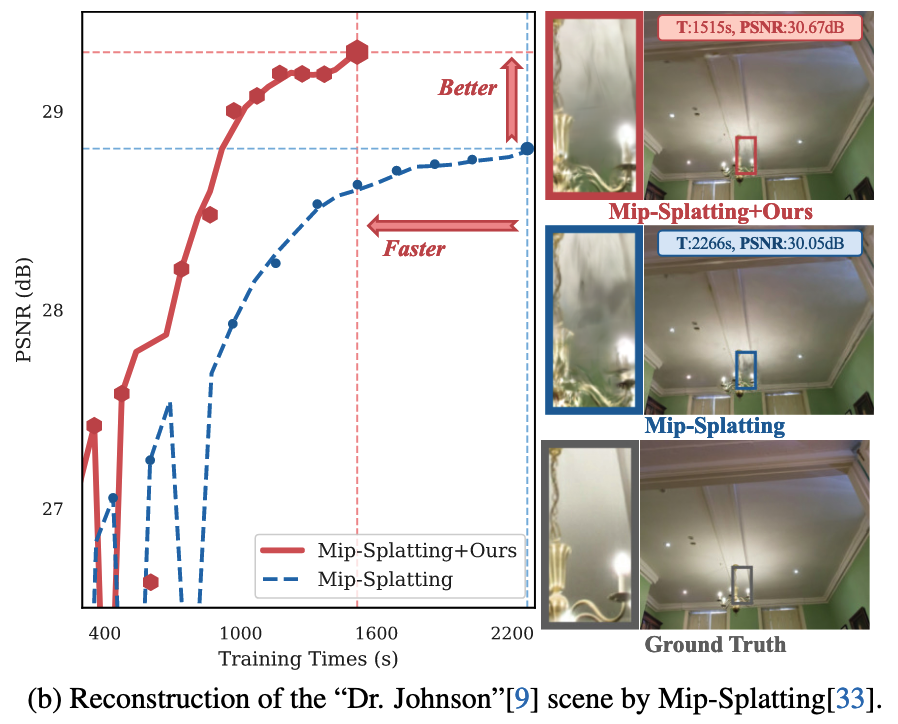
1.2 论文主要贡献
受循环修剪策略局限性的启发,论文建议缓存一部分高斯基元而不是直接修剪它们,这种“缓存”概念可以保留“重要”的高斯基元,同时减少其总数,因此论文提出了一种新颖的分组训练策略来加速 3DGS 的训练,具体而言:
- (1)一部分高斯基元在训练期间被循环缓存,这些缓存的高斯基元暂时被排除在场景渲染和模型训练之外,这大大减少了“正在训练的高斯基元”(Under-training Gaussians)的数量并缩短了训练时间;
- (2)此外,通过循环重采样,缓存的高斯基元被重新整合到 3DGS 模型中,减少了直接修剪的影响;
- (3)分组训练的一个关键要素是确定如何采样高斯基元以区分正在训练的和缓存的高斯基元,简单的采样方法是随机采样,有趣的是论文发现高斯不透明度值的分布会影响致密化期间生成的高斯基元数量和场景的渲染速度,因此论文引入了一种基于不透明度的优先采样(Opacity-based Prioritized Sampling)方法,有效地减少了冗余高斯基元的生成并提高了 3DGS 的训练速度。
论文的主要技术贡献如下:
- 1、论文提出了一种简单但高效的训练框架,称为用于 3D Gaussian Splatting 的分组训练,该框架无缝集成到现有的 3DGS 框架中,包括 3DGS 和 Mip-Splatting;
- 2、论文的框架显著提高了场景重建的效率和 NVS 的质量。
二、方法论 🍀
在 2.1 节中将全面介绍分组训练方法及其在 3D Gaussian Splatting (3DGS) 中的多功能优势,2.2 节介绍了两种采样范式:随机采样和优先采样(结合重要性评分、基于不透明度和基于体积的标准),并比较分析了它们的计算效率和性能权衡,论文在数学上证明了基于不透明度的优先采样实现了有效的 3DGS 致密化和高效渲染,最后在 2.3 节中总结了带有分组训练的 3DGS 的训练特征并确定了采样策略。
2.1 分组训练( Group Training)
在致密化阶段,高斯集中的高斯基元数量迅速增加以实现丰富的表示能力,这意味着从特定视点渲染场景的计算时间也会增加,并且这种影响将延伸到全局优化阶段,为此论文在训练期间采用分组训练方法。
对于任何给定的高斯集合 G G G,通过采样获得正在训练组 G U n d e r − t r a i n i n g G_{Under-training} GUnder−training,而剩余的基元构成缓存组 G C a c h e d G_{Cached} GCached,即:
G U n d e r − t r a i n i n g = { g i ∣ g i ∈ G , i ∈ I , I ⊆ { 1 , 2 , 3 , . . . , ∣ G ∣ } } ( 1 ) G_{Under-training}=\{g_{i}|g_{i}\in G,i\in I,I\subseteq\{1,2,3,...,|G|\}\}\quad (1) GUnder−training={gi∣gi∈G,i∈I,I⊆{1,2,3,...,∣G∣}}(1)
G C a c h e d = G ∖ G U n d e r − t r a i n i n g ( 2 ) G_{Cached}=G \setminus G_{Under-training}\quad (2) GCached=G∖GUnder−training(2)
在下一次分组之前,缓存组与正在训练组“合并”,之后重新采样新的 G U n d e r − t r a i n i n g G_{Under-training} GUnder−training 和 G C a c h e d G_{Cached} GCached 组,图3提供了组训练过程的可视化表示。此过程确保每个高斯基元都有机会参与训练过程,并有效地减少正在训练的高斯基元数量,同时保留那些被认为“重要”的基元。
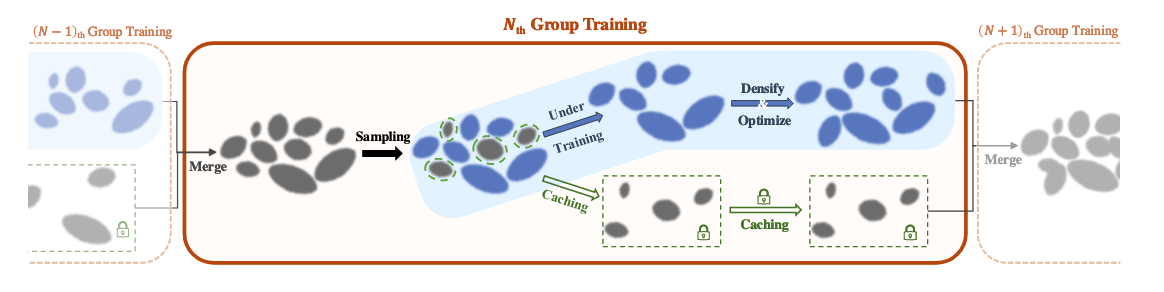
图3. Group Training的总体框架。Group Training涉及周期性地划分所有高斯基元。具体而言,在规则的迭代间隔中,在渲染训练视图之前,合并所有组中的高斯。随后,根据指定的采样策略,将所有高斯基元分类为Under-training Group和Caching Group。在下一次分组之前,训练不足组用于高斯致密化(迭代0 ~ 15 K)或优化(迭代15 ~ 30 K),而高速缓存组保持不活动并且不参与任何计算。
如第2节所述,3DGS训练过程包括两个不同的阶段:“密集化”和“优化”。分组训练在两个阶段中均有进行,并在每个阶段结束时进行组合并,如图4所示。
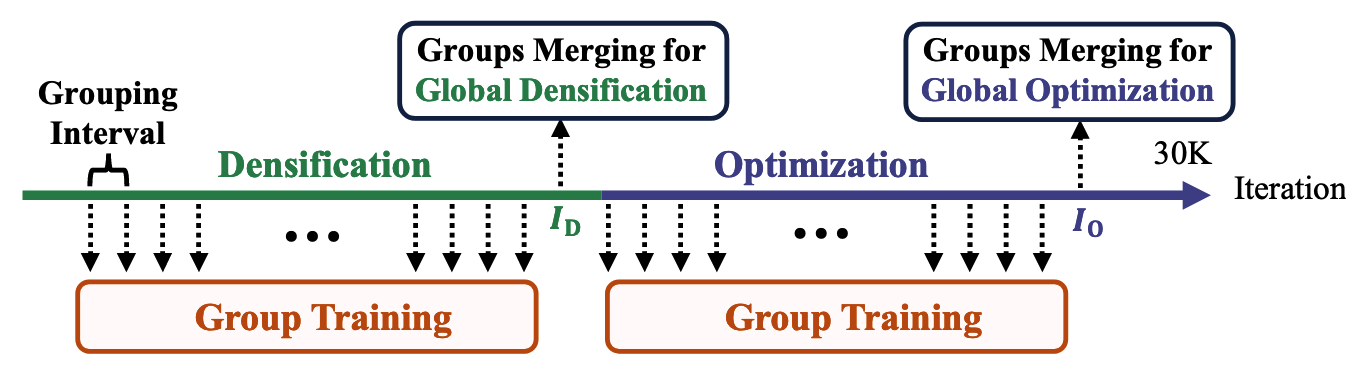
图4. 重建期间激活群组训练的时间表。群组训练会定期启用。在全局致密化和优化的致密化及优化过程完成之前,在迭代 I D I_{D} ID 和 I 0 I_{0} I0 时会发生群组合并(不重新采样的分组)。
2.2 有效和高效的抽样策略(Effective and Efficient Sampling Strategies)
在每个分组中,会从合并后的高斯分布中采样出一个高斯分布子集。最简单的采样策略是随机采样(RS)。论文提出了属性驱动的优先采样,以进一步优化3DGS。
论文评估了多种属性,包括基于不透明度和体积的方法以及重要性分数(详见附录中的详细比较)。其中,基于不透明度的优先采样在训练速度和渲染质量方面均表现出更优的性能。正如在3.2.1节和3.2.2节中通过数学证明的那样,不透明度本质上控制着3D高斯溅射(3DGS)的两个关键属性,这一点已通过实验得到验证。
2.2.1 用于更好致密化的采样策略(Sampling Strategy for Better Densification)
对于投影到成像平面上的任何高斯基元 G m G_{m} Gm,其 2D 中心坐标为 [ x m , y m ] [x_{m},y_{m}] [xm,ym],损失 L L L 对投影坐标的偏导数为 [ ∂ L ∂ x m , ∂ L ∂ y m ] [\frac{\partial L}{\partial x_{m}},\frac{\partial L}{\partial y_{m}}] [∂xm∂L,∂ym∂L],其通过公式控制致密化标准:
( ∂ L ∂ x m ) 2 + ( ∂ L ∂ y m ) 2 > τ g r a d ( 3 ) \sqrt{(\frac{\partial L}{\partial x_{m}})^{2}+(\frac{\partial L}{\partial y_{m}})^{2}}>\tau_{grad} \quad{(3)} (∂xm∂L)2+(∂ym∂L)2>τgrad(3)
其中 τ g r a d \tau_{grad} τgrad 表示预定义的梯度阈值。
论文制定了 3DGS 的第一个基本属性:
命题 1. 基于不透明度的有效高斯致密化: 具有较高不透明度的高斯基元是 3DGS 致密化的主要贡献者。
证明。在关于高斯属性之间相互独立以及图元内参数独立的假设下,偏导数计算如下:
∂ L ∂ x m = o m ∑ p i x e l ∂ L ∂ C ^ ∂ C ^ ∂ α m ∂ G m 2 D ∂ Δ x ∂ Δ x ∂ x m , ( 4 ) \frac{\partial L}{\partial x_{m}}=o_{m} \sum_{pixel } \frac{\partial L}{\partial \hat{C}} \frac{\partial \hat{C}}{\partial \alpha_{m}} \frac{\partial G_{m}^{2 D}}{\partial \Delta x} \frac{\partial \Delta x}{\partial x_{m}},\quad{(4)} ∂xm∂L=ompixel∑∂C^∂L∂αm∂C^∂Δx∂Gm2D∂xm∂Δx,(4)
∂ L ∂ y m = o m ∑ p i x e l ∂ L ∂ C ^ ∂ C ^ ∂ α m ∂ G m 2 D ∂ Δ y ∂ Δ y ∂ y m , ( 5 ) \frac{\partial L}{\partial y_{m}}=o_{m} \sum_{pixel } \frac{\partial L}{\partial \hat{C}} \frac{\partial \hat{C}}{\partial \alpha_{m}} \frac{\partial G_{m}^{2 D}}{\partial \Delta y} \frac{\partial \Delta y}{\partial y_{m}},\quad{(5)} ∂ym∂L=ompixel∑∂C^∂L∂αm∂C^∂Δy∂Gm2D∂ym∂Δy,(5)
其中 o m o_{m} om 表示 G m G_{m} Gm 的不透明度, h a t C hat{C} hatC 表示渲染的像素值, Δ x \Delta x Δx、 Δ y \Delta y Δy 表示像素与 [ x m , y m ] [x_{m}, y_{m}] [xm,ym] 之间的坐标偏移。在参数相互独立性假设下, [ ∂ Δ x ∂ x m , ∂ Δ y ∂ y m ] [\frac{\partial \Delta x}{\partial x_{m}}, \frac{\partial \Delta y}{\partial y_{m}}] [∂xm∂Δx,∂ym∂Δy]、 [ ∂ G m 2 D ∂ Δ x , ∂ G m 2 D ∂ Δ y ] [\frac{\partial G_{m}^{2 D}}{\partial \Delta x}, \frac{\partial G_{m}^{2 D}}{\partial \Delta y}] [∂Δx∂Gm2D,∂Δy∂Gm2D] 和 ∂ L ∂ C ^ \frac{\partial L}{\partial \hat{C}} ∂C^∂L 仍然独立于 o m o_{m} om。论文证明了 ∂ C ˙ ∂ α m \frac{\partial \dot{C}}{\partial \alpha_{m}} ∂αm∂C˙在随着附录中 o m o_{m} om 的期望值升高而增加:
E [ ∂ C ^ ∂ α m ] = ( c 0 − c b g ) T s a t u r a t i o n 1 − E [ o m ] ⋅ E [ G m 2 D ] , ( 6 ) \mathbb {E}\left[ \frac {\partial \hat {C}}{\partial \alpha _{m}}\right] =\frac {(c_{0}-c_{bg})T_{saturation}}{1-\mathbb {E}\left[ o_{m}\right] \cdot \mathbb {E}\left[ G_{m}^{2D}\right] },\quad(6) E[∂αm∂C^]=1−E[om]⋅E[Gm2D](c0−cbg)Tsaturation,(6)
其中, c 0 c_{0} c0和 α 0 \alpha_{0} α0 分别表示预期颜色和不透明度, T s a t u r a t i o n T_{saturation } Tsaturation 控制 α 饱和度。
在 L L L 固定的情况下,式(4)至式(6)表明,较高的不透明度分布会产生更大的梯度幅度。 [ ∂ L ∂ x m , ∂ L ∂ y m ] [\frac{\partial L}{\partial x_{m}}, \frac{\partial L}{\partial y_{m}}] [∂xm∂L,∂ym∂L],从而使这些高斯分布在统计上优先进行致密化。
实验验证:论文实验追踪了有助于致密化的高斯基元,重点关注不透明度和体积值。对致密化步骤中属性分布的统计分析(图5)表明,具有高不透明度和小体积的高斯基元是实现高斯致密化的主要来源。
值得注意的是,高不透明度高斯分布的不足会增加光度损失,加剧重建不足和过度重建的问题,从而迫使进行冗余的密集化处理。虽然在3D高斯溅射的模型压缩中,小体积可以作为一种压缩指标,但它们同时也会推动合理的密集化。综合考虑所有因素,建议缓存低不透明度的高斯分布,以实现更好的高斯密集化。
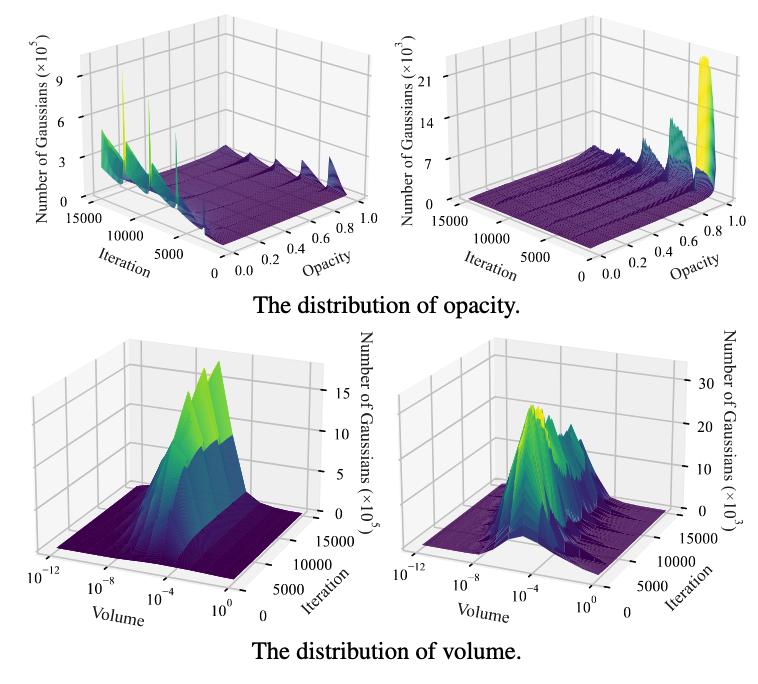
图5. 高斯属性的分布。在使用3DGS 的“自行车”场景中,所有高斯属性的分布(左)和那些专门有助于致密化的高斯属性的分布(右)。上行:虽然不透明度主要集中在0和1附近,但有助于致密化的高斯主要位于1附近。下行:体积分布。随着致密化的进行,体积较小的高斯越来越多地参与到致密化过程中。
2.2.2 用于更快渲染的采样策略(Sampling Strategy for Faster Rendering)
在3DGS的特定视角图像合成过程中,该框架通过在每个像素上递归应用合成方程来实现 α \alpha α-blending。
C p = ∑ i = 1 N c i α i T i , T i = ∏ j = 1 i − 1 ( 1 − α j ) , ( 7 ) C_{p}=\sum_{i=1}^{N} c_{i} \alpha_{i} T_{i}, T_{i}=\prod_{j=1}^{i-1}\left(1-\alpha_{j}\right), \quad (7) Cp=i=1∑NciαiTi,Ti=j=1∏i−1(1−αj),(7)
N = m i n { i ∈ N + , ∣ ∏ j = 1 i − 1 ( 1 − α j ) ≤ T s a t u r a t i o n } ( 8 ) N=min \left\{i \in \mathbb{N}^{+}, | \prod_{j=1}^{i-1}\left(1-\alpha_{j}\right) \leq T_{saturation }\right\} \quad(8) N=min{i∈N+,∣j=1∏i−1(1−αj)≤Tsaturation}(8)
正如在3DGS中所确立的,N的确定取决于在像素累积的α值(Transmittance T i < T s a t u r a t i o n T_{i}<T_{saturation } Ti<Tsaturation)内实现不透明度饱和。这一关键阈值的实现对渲染效率带来了一个基本限制:在正向渲染操作期间,高斯基元的顺序遍历本质上阻碍了 T i T_{i} Ti 值的并行计算。因此, N N N 成为渲染速度的主要决定因素, N N N 的任何减少都会直接转化为渲染速度的提升。
基于上述分析,论文提出3DGS框架的第二个基本性质:
命题2.基于不透明度的高效渲染加速:具有更高不透明度的高斯原语通过更快地实现 α \alpha α 饱和度来实现更快的渲染。
证明:基于高斯分布之间 α i \alpha_{i} αi 值相互独立的前提,我们假设数学期望 E [ T N ] ≈ T i E[T_{N}] ≈T_{i} E[TN]≈Ti 饱和,
E [ T N ] = ( 1 − E [ α i ] ) N = ( 1 − E [ o i ] ⋅ E [ G i 2 D ] ) N , ( 9 ) \mathbb {E}[T_{N}]=(1-\mathbb {E}\left[ \alpha _{i}\right] )^{N}=\left( 1-\mathbb {E}[o_{i}]\cdot \mathbb {E}[G_{i}^{2D}]\right) ^{N}, \quad (9) E[TN]=(1−E[αi])N=(1−E[oi]⋅E[Gi2D])N,(9)
其中 α i \alpha_{i} αi 结合了其内在不透明度 O i O_{i} Oi 和 G i 2 D G_{i}^{2 D} Gi2D(取决于视图投影和协方差,与 o i o_{i} oi 无关)。我们对 α i \alpha_{i} αi 的期望值进行解耦。
实验验证:论文使用从 N ( μ o , 0.1 ) \mathcal{N}(\mu_{o}, 0.1) N(μo,0.1) 中采样的Gaussian O i O_{i} Oi值生成了一个3DGS模型,同时固定了其他参数。图6展示了渲染时间作为 μ o \mu_{o} μo 的函数关系。结果表明,具有更高不透明度的高斯基元会导致更快的透射率饱和,从而减少混合步骤 N N N 和渲染计算量。
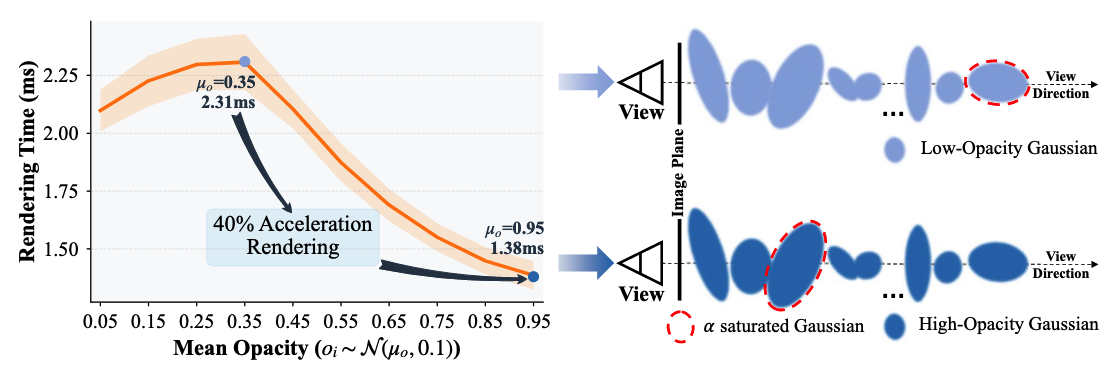
图6. 高不透明度高斯加速3DGS渲染。左图:随着 μ 0 \mu_{0} μ0 的增加,渲染时间减少40%。右图:高不透明度高斯通过更少数量的高斯实现更快的 α \alpha α 饱和的机制。
2.3 分析和设计见解(Analysis and Design Insights)
通过全面的测试程序以及对3DGS中致密化和渲染公式的详细研究,论文发现了不透明度属性在3DGS训练过程中的加速作用。基于这些见解,论文提出了一种基于不透明度的优先采样(OPS)策略。
基于不透明度的采样概率 p i p_{i} pi 用于选择训练中的高斯分布 G i G_{i} Gi,其定义如下:
p i = α i ∑ i = 1 N α i , ( 10 ) p_{i}=\frac{\alpha_{i}}{\sum_{i=1}^{N} \alpha_{i}}, \quad(10) pi=∑i=1Nαiαi,(10)
其中, α i \alpha_{i} αi 表示高斯基元 G i G_{i} Gi 的不透明度, N N N 是高斯基元的总数。
三、论文实验部分 🧪
3.1 实验设置(Experimental Settings)
实现细节。为便于与3DGS结合使用,分组训练方法被集成为一个插件。论文在3DGS 和 Mip-Splatting 中都实现了分组训练的方法。
在整个训练过程中,分组训练的默认分组间隔为500次迭代。论文采用了随机抽样(RS)和基于不透明度的优先抽样(OPS)两种策略,训练不足率(UTR)为0.6。考虑到初始高斯函数的重要性,为确保计算稳定性,分组训练在致密化开始后的第500次迭代时启动。全局致密化化( I D I_{D} ID)和优化( I O I_{O} IO)分别安排在 14.5K 和 29K 次迭代时进行。为了管理分组合并过程中增加的GPU内存消耗,论文在 I D I_{D} ID 和 I O I_{O} IO 次迭代时固定了SH系数。论文还进行了仅在致密化阶段应用分组训练的实验。
数据集与指标。论文方法的有效性在Mip-NeRF360、Tanks & Temples、Deep Blending 和NeRF-Synthetic 上使用单块RTX 3090进行评估。随后,使用PSNR、SSIM和 LPIPS 评估模型的重建性能。此外,还记录了每个场景的训练时间、峰值内存使用量和模型大小。
3.2 实验结果(Experiments Results)
本节展示了将分组训练方法整合到3DGS和Mip-Splatting的实验结果。测试结果表明,在所有场景中,结合OPS的分组训练相比 Baseline 能显著减少训练时间,同时如图7所示,还能提升新视角的渲染质量。
图7. 分组训练与基线方法在3DGS 和Mip-Splatting 上的视觉对比。分组训练方法将重建速度提升了约30%,同时实现了更细致、更准确的场景渲染。在“约翰逊博士”场景的相框和“花园”场景的桶柄处可以观察到显著改进,这些地方捕捉到了更精细的细节。此外,分组训练显著减少了Mip-Splatting中的漂浮物,提高了整体重建保真度。
3D高斯泼溅 论文首先基于3DGS测试了分组训练的有效性。所有场景的重建效率总结于表1,表2展示了所有场景的新视角合成(NVS)渲染质量。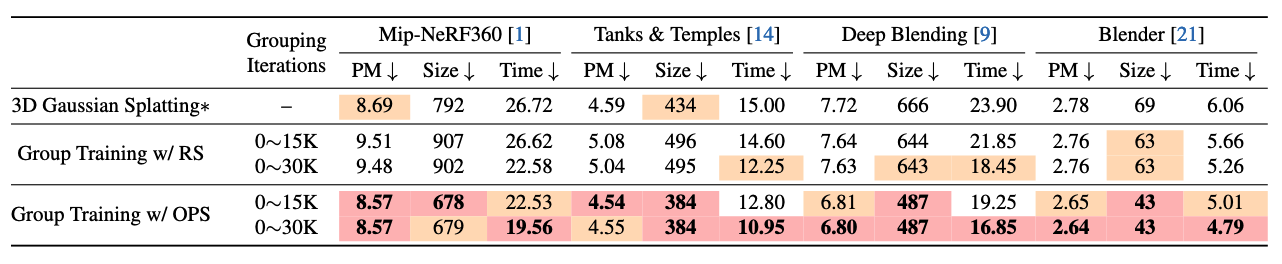
表1. 3DGS的重建效率对比。分组训练显著提高了所有四个数据集的重建速度,其中OPS策略实现了最高的加速。这种效果在复杂场景中尤为显著。虽然采用RS的分组训练会产生更冗余的模型,但OPS策略能生成更紧凑的模型,并减少GPU峰值内存使用量。∗表示模型经过了重新训练。PM代表GPU峰值内存分配,其中Size的单位为MB,Time的单位为分钟。

表2. 3DGS的重建质量比较。分组训练同时加快了3DGS场景重建过程,并提高了3D重建的准确性。值得注意的是,结合OPS的分组训练在保持最高重建速度的同时,实现了重建质量的显著提升。
在这些场景中,分组训练始终能实现更快的重建,而且在复杂场景中,这种速度提升更为显著。然而,带有RS的分组训练在某些重建任务中可能会导致过多冗余的高斯基元,这会使后续操作(如模型压缩)变得复杂。此外,如表1所示,由于这种冗余,GPU内存占用显著增加。与带有RS的分组训练相比,带有OPS的分组训练在重建速度上的提升更为明显。在对所有三个复杂场景的重建中,平均速度提升约为30%。此外,OPS大幅减少了冗余高斯基元的生成,使得在所有任务中重建模型的大小都小于原始的3DGS重建模型。在所有重建任务中,模型大小减少了10%到40%,总体上形成了更紧凑的模型。
Mip-Splatting 论文对结合了分组训练的Mip-Splatting进行了测试,它是Gaussian Splatting的另一个重要变体。实验结果如表3和表4所示。总体而言,结合Mip-Splatting的分组训练性能与3DGS相近。结合RS的分组训练在Mip-Splatting中持续提升了重建质量和速度,但在致密化阶段产生了最多数量的高斯基元。结合OPS的组训练实现了最快的重建速度,其重建质量也接近最优。OPS降低了致密化的比例,使得模型尺寸更小,要么是测试方法中最小的,要么与基线相当。

表3. Mip-Splatting的重建质量对比。分组训练在所有任务中均同时提升了Mip-Splatting的速度和重建质量。具体而言,结合OPS的组训练在所有三个数据集上都实现了最快的重建速度,并且在Tanks & Temples和Deep Blending数据集上达到了最高的重建质量。

表4. 基于Mip-Splatting 重建的Mip-NeRF360 的定量评估。对于户外场景重建,采用RS的分组训练会产生更大的模型尺寸,从而获得最佳的重建质量。采用OPS的分组训练实现了最快的重建速度,但重建质量次优。对于室内场景,采用OPS的分组训练仍然能同时提供最快的重建速度和最高的重建质量。
反直觉发现 论文实验揭示了两个值得注意的发现,这些发现对传统理解提出了挑战:
1. 尽管生成了更大的模型尺寸,但结合RS的分组训练持续提高了重建速度,这表明训练动态而非模型尺寸主导着重建效率。
2. 采用OPS的分组训练在减小模型规模的同时,还能实现更优的重建质量。这表明,卓越的性能源于其对优化过程的根本性影响,而非模型规模。
3.3 方法适用性(Methodological Applicability)
分组训练框架通过其与数据集无关的改进,从根本上解决了3DGS中的加速训练和渲染问题。该方法被设计为一个可插拔的训练组件,在两个方面都展现出双重功效,即3DGS模型加速和压缩,详细内容见附录。
3.4 消融实验(Ablation Studies)
论文在Tanks & Temples数据集上进行了消融研究,以评估分组训练方法的三个关键组件的影响。详细的对比结果见表5。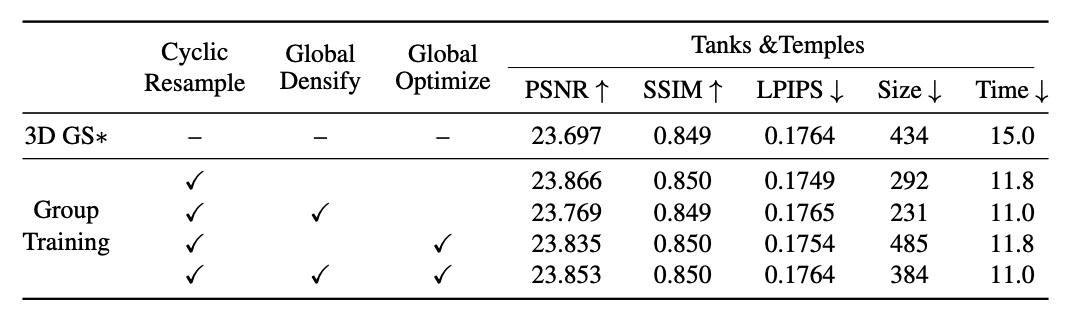
表5. 在Tanks & Temples数据集上使用OPS进行分组训练的消融研究。循环重采样为场景重建提供了最显著的加速,而全局致密化通过减小模型大小进一步提高了效率。在启用全局致密化的情况下,全局优化提升了模型的重建质量。
结果表明,循环重采样对提高训练速度的贡献最大。具体而言,在迭代 I D I_{D} ID ~ 15K 期间,全局致密化过程会自适应地对3DGS内的低不透明度高斯体进行循环剪枝,减少冗余高斯体,减小模型大小,从而提高训练效率。当启用全局致密化时,3DGS模型会在全局致密化过程中移除大部分冗余高斯体,导致缓存中的冗余高斯体少于优化阶段的组。在这种情况下,全局优化可以充分利用所有高斯函数,进一步提高重建性能。
3.5 讨论(Discussion)
论文实验结果表明,启用分组训练并利用OPS能够同时提高重建速度和质量。为了更好地阐明这些改进,从这些发现中引出了两个关键问题:
为何更快? 分组训练通过显著减少训练中高斯基元的数量,从而减轻模型的渲染负担,大幅加速了重建过程。即便最终模型规模大于基线模型,这种加速效果依然明显。与论文在2.2节中的早期分析一致,OPS对这种加速效果也有显著贡献。在致密化阶段,结合OPS的分组训练会保留训练组内的高透明度高斯基元,否则可能会导致重建不足和重建过度的情况。这些问题会引发冗余的致密化。因此,通过分组训练和OPS重建的模型包含更少的冗余高斯基元,从而减小了模型规模,并整体加快了重建速度。此外,OPS会优先对高透明度高斯基元进行采样,这会快速推动α饱和,这一点在2.2节中也有提及。专注于这些影响最大的高斯基元,减少了绘制所需的高斯基元数量,进一步提高了训练和渲染效率。
为什么更好? 使用OPS的分组训练优先考虑高不透明度高斯基元的保留与优化。这实现了与RS相当或更优的保真度,同时显著减小了模型尺寸。不透明度更高的高斯基元本质上对最终渲染图像有更大的影响,因此着重对其进行优化能显著提升整体渲染质量。此外,循环重采样会暂时排除随机选择的一部分高斯基元,每个剩余的基元都被迫学习如何独立表示关键的场景特征,从而形成更稳健的表示。
总之,通过整合这些策略,结合OPS的分组训练能够同时提升重建速度和渲染质量。通过聚焦于最具影响力的基元并鼓励独立的特征表示,分组训练实现了高效、高质量的场景重建。
3.6 结论(Conclusion)
论文提出了分组训练方法,这是一种通过动态管理有组织分组中的高斯基元来解决3D高斯溅射计算挑战的有效策略。通过理论分析和大量实验,论文证明该方法不仅能将训练速度提升高达30%,还能在各种场景中提高渲染质量。论文基于不透明度的采样策略与现有的3DGS框架具有普遍兼容性,在不增加模型复杂度的情况下实现了稳定的性能提升。分组训练的成功表明,在3DGS优化中动态基元管理至关重要,这为未来的研究指明了富有前景的方向,例如针对更复杂场景的自适应分组策略和动态采样机制。论文的研究为高效新视角合成的未来发展提供了宝贵见解。
四、论文代码解读 💻
这里主要围绕着和论文分组策略有关的部分进行总结。
4.1 Group Training代码实现
1️⃣ Group Training超参数设置代码
代码定义了一个名为 GroupingParams 的参数类,用于配置训练过程中的分组(Grouping / Group-Training)机制。它在初始化时设置了一系列与分组策略相关的超参数,包括是否启用分组训练、分组方法(如基于不透明度加权)、欠训练比例(UTR)、分组开始与结束的迭代区间、分组执行的时间间隔,并据此生成需要执行分组操作的迭代步列表,最后将这些参数注册到参数解析器中供整体训练流程使用。
class GroupingParams(ParamGroup):
def __init__(self, parser):
self.Grouping = True # False for Not Plugging in `Group-Training`
self.grouping_method = 'Opacity-weighted' # 'Opacity-weighted', 'Random', ...
self.UTR = 0.6 # Under Training Ratio
self.grouping_from_iter = 1000
self.grouping_until_iter = 29000
self.grouping_interval = 500 # Control Grouping Frequency
self.grouping_iteration = [ind_i for ind_i in range(self.grouping_from_iter, self.grouping_until_iter+1, self.grouping_interval)]
super().__init__(parser, "Grouping Parameters")
2️⃣ Group Training分组实现代码
代码实现了 Gaussian Splatting 训练中的分组与缓存机制:在指定迭代阶段,根据欠训练比例(UTR)和分组策略,将 Gaussian 划分为“继续训练的欠训练组”和“暂时冻结的缓存组”,缓存组的参数会被保存并从当前模型中裁剪,从而降低优化规模、提升训练效率;在后续分组迭代中,这些缓存的 Gaussian 会被重新合并回模型,在特定全局阶段则完全关闭分组并冻结部分参数以保证训练稳定性。
def gaussians_grouping_and_caching(_iteration: int,
_gaussian_model: GaussianModel,
_group_training,
_points_caching=None):
"""
在训练过程中执行 Gaussian 的分组(Grouping)与参数缓存(Caching)逻辑。
核心思想:
- 将 Gaussian 划分为「欠训练组」和「缓存组」
- 仅对欠训练组继续优化
- 将缓存组暂存并从当前模型中裁剪,减少优化负担
"""
# ============================= 合并缓存结果 =============================
# Fig 3:在非第一次 Grouping 时,将上一次缓存的 Gaussian 重新合并回模型
# 第一次 Grouping / 全局训练阶段时,_points_caching 为 None
if _points_caching is not None:
_gaussian_model.densification_postfix(**_points_caching)
# ============================= Grouping =============================
# Fig 4:在特定迭代点(全局 densify / optimize 阶段)禁用 Grouping
# 此时将 UTR 强制设为 1.0,表示不做分组
_UTR = 1.0 if _iteration in [14500, _group_training.grouping_until_iter] else _group_training.UTR
# ============================= 不进行 Grouping 的情况 =============================
# 当 UTR ≈ 1.0 时,表示所有 Gaussian 都参与训练
if _UTR >= 0.999:
# 清空缓存
del _points_caching
# 冻结 f_rest(通常是高阶 SH 特征),避免在全局阶段被更新
assert _gaussian_model.optimizer.param_groups[2]["name"] == "f_rest"
for param in _gaussian_model.optimizer.param_groups[2]["params"]:
param.requires_grad = False
# 不返回缓存
return None
# ============================= 执行 Grouping 的情况 =============================
elif _UTR > 0:
with torch.no_grad():
# Fig 3:根据欠训练比例和分组策略,生成欠训练 Gaussian 的 mask
_mask_under_training = get_under_training_mask(
_gaussian_model,
_UTR,
_group_training.grouping_method
)
# 缓存组为欠训练组的补集
_mask_caching = ~_mask_under_training
# ============================= 参数缓存 =============================
# 将缓存组 Gaussian 的所有参数保存下来
# 这些参数在之后的迭代中会重新合并回模型
# 注:部分 GS 框架(如 Sort-free GS / HoGS)需要额外缓存参数
_points_caching = {
"new_xyz": _gaussian_model._xyz[_mask_caching],
"new_features_dc": _gaussian_model._features_dc[_mask_caching],
"new_features_rest": _gaussian_model._features_rest[_mask_caching],
"new_opacities": _gaussian_model._opacity[_mask_caching],
"new_scaling": _gaussian_model._scaling[_mask_caching],
"new_rotation": _gaussian_model._rotation[_mask_caching],
}
# ============================= 模型裁剪 =============================
# 从当前 Gaussian Model 中移除缓存组,仅保留欠训练组用于后续优化
_gaussian_model.prune_points(_mask_caching)
# 返回缓存的 Gaussian 参数
return _points_caching
# ============================= 异常情况 =============================
else:
raise ValueError(f"Under-training-ratio {_UTR} is invalid: Must be in (0, 1]")
3️⃣ Group Training生成Mask代码
该函数用于在 Gaussian Splatting 训练过程中,根据指定的欠训练比例和分组策略(随机、体积加权、不透明度加权或二者结合),从所有 Gaussian 中选择一部分作为“欠训练组”,并生成对应的布尔掩码;该掩码用于后续训练阶段中区分需要继续优化的 Gaussian 与被缓存或冻结的 Gaussian,从而实现高效的分组训练与计算资源分配。
def get_under_training_mask(_gaussian_model: GaussianModel, under_training_ratio, grouping_method='Random'):
"""
根据指定的分组策略(grouping_method)和欠训练比例(under_training_ratio),
从所有 Gaussian 中选择一部分作为「欠训练组」,并返回对应的布尔 mask。
True 表示该 Gaussian 属于欠训练组(继续参与训练)
False 表示该 Gaussian 属于非欠训练组(将被缓存 / 冻结)
"""
# Gaussian 总数
_num_gaussian = _gaussian_model._xyz.shape[0]
# ============================= 随机分组 =============================
# 每个 Gaussian 以 under_training_ratio 的概率被选为欠训练
if grouping_method == 'Random':
_ind_UT = torch.rand([_num_gaussian, ]) < under_training_ratio
# ============================= 体积加权分组 =============================
# 根据 Gaussian 的体积(scaling 的乘积)进行加权采样
elif grouping_method == 'Volume-weighted':
# 每个 Gaussian 的体积(sx * sy * sz)
_theta_all = torch.prod(
_gaussian_model.get_scaling, dim=-1
).squeeze(-1) # [num_gaussians]
# 归一化为采样概率
_prob_UT = _theta_all / torch.sum(_theta_all)
# 按概率无放回采样指定数量的 Gaussian
_ind_UT = torch.multinomial(
_prob_UT,
int(_num_gaussian * under_training_ratio),
replacement=False
)
# ============================= 不透明度加权分组 =============================
# 根据 Gaussian 的 opacity 进行加权采样
elif grouping_method == 'Opacity-weighted':
# 获取每个 Gaussian 的不透明度
_theta_all = _gaussian_model.get_opacity.squeeze(-1)
# 归一化为采样概率
_prob_UT = _theta_all / torch.sum(_theta_all)
# 按概率无放回采样
_ind_UT = torch.multinomial(
_prob_UT,
int(_num_gaussian * under_training_ratio),
replacement=False
)
# ============================= 不透明度 + 体积加权分组 =============================
# 同时考虑 opacity 和体积大小进行采样
elif grouping_method == 'Opacity-Volume-weighted':
# 先取 opacity
_theta_all = _gaussian_model.get_opacity.squeeze(-1)
# 再乘以体积(scaling 的乘积)
_theta_all *= torch.prod(
_gaussian_model.get_scaling, dim=-1
).squeeze(-1)
# 归一化为采样概率
_prob_UT = _theta_all / torch.sum(_theta_all)
# 按概率无放回采样
_ind_UT = torch.multinomial(
_prob_UT,
int(_num_gaussian * under_training_ratio),
replacement=False
)
# ============================= 未实现的分组方式 =============================
else:
raise NotImplementedError
# ============================= 构造欠训练 mask =============================
# 初始化为全 False
_mask_under_training = torch.zeros(_num_gaussian, dtype=torch.bool)
# 被选中的 Gaussian 标记为 True(欠训练)
_mask_under_training[_ind_UT] = True # True 表示 under-training
return _mask_under_training
4.2 Group Training代码调用
这段代码展示了 Gaussian Splatting 训练流程中分组(Grouping)模块的调用方式:首先导入分组与缓存相关的函数和参数类;在训练循环中,当启用分组训练且当前迭代步位于预设的分组迭代列表时,在 render() 之前执行 gaussians_grouping_and_caching,将上一阶段缓存的 Gaussian 合并回模型并重新进行分组,从而动态控制哪些 Gaussian 继续参与训练、哪些被暂时缓存,以提升训练效率与稳定性。
# 1st: Import submodule
from gaussians_grouping import gaussians_grouping_and_caching, GroupingParams
# 3rd: Grouping before `render()`
if group_training.Grouping and iteration in group_training.grouping_iteration:
# Merge and Grouping
point_caching = gaussians_grouping_and_caching(iteration, gaussians, group_training,
_points_caching=point_caching)
写在最后
由于笔者🖊️精力有限且本文更多的目的是通过📒博客记录学习过程并分享更多知识,因此文中部分描述不太具体,如有不太理解💫的地方可在评论区👀留言。非特殊赶deadline⏰或假期⛱️期间,笔者会经常上线回复💬。如有不便之处,请海涵~
如果想了解更多关于3DGS的加速⏰压缩⚡️新工作,可以关注笔者的Github仓库:Awesome-3DGS-Compress-Accelerate。
另外,创造不易,转载请注明出处💗💗💗~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)