课题进度总卡在实验上?你可能忽略了科研的“第二曲线”
先通过计算模拟批量生成“结构-性能”数据,再用机器学习模型学习其中隐藏的规律,快速预测海量候选材料的性能,将靶点缩小到几十个,最后用可解释AI分析模型决策逻辑,找到关键结构描述符。更酷的是,可以运用“主动学习”策略,让模型智能地建议“下一个最具信息量的实验或计算该做什么”,实现闭环优化。你可以从电子结构层面计算基础物性,模拟原子尺度的位错运动,预测微观组织的演化(如晶粒生长、裂纹扩展),最终直接计
不知道大家有没有过这种感觉:实验计划排得满满当当,结果不是设备排队,就是样品制备周期过长,好不容易拿到数据,又发现和预期不符,机理解释不清……整个研究节奏被拖得支离破碎。
在材料、化学、力学这些传统工科领域,我们往往被“第一曲线”——基于物理实验的科研范式——牢牢束缚。但今天,我想聊聊那条能让你研究效率倍增、甚至弯道超车的“第二曲线”:计算与数据驱动的科研新范式。
这条新曲线不是要替代实验,而是作为强大的“探照灯”和“加速器”,帮你照亮前路,减少在黑暗中的无效摸索。
下面我整理了最近在圈内讨论度很高的几个前沿方向及核心技术栈,或许正能解决你当下的研究瓶颈:
方向一:打通微观与宏观的“上帝视角”
核心问题: 材料的宏观性能(强度、韧性)到底由哪些微观机制(位错、相变)决定?传统方法只能看到两头,中间是黑箱。
核心技术栈: 第一性原理计算(DFT)→ 分子动力学(MD)→ 相场法 → 晶体塑性有限元(CPFEM)。
-
能做什么: 你可以从电子结构层面计算基础物性,模拟原子尺度的位错运动,预测微观组织的演化(如晶粒生长、裂纹扩展),最终直接计算出构件的宏观力学响应。
-
价值点: 这构建了一套从“埃米”到“毫米”的全链路解释框架。当审稿人追问“为什么是这个性能?”,你可以不从文献找猜想,而是用自己这套模拟工作流,给出一个自洽的、跨尺度的物理图像。这对于发顶刊、讲好一个深刻的故事至关重要。
方向二:从“大海捞针”到“按图索骥”的材料筛选
核心问题: 面对MOFs、催化剂等动辄数万的候选材料库,合成测试如同大海捞针,效率极低。
核心技术栈: 高通量计算(DFT/GCMC)→ 机器学习(ML)/图神经网络(GNN)→ 可解释AI(SHAP)。
-
能做什么: 先通过计算模拟批量生成“结构-性能”数据,再用机器学习模型学习其中隐藏的规律,快速预测海量候选材料的性能,将靶点缩小到几十个,最后用可解释AI分析模型决策逻辑,找到关键结构描述符。
-
价值点: 将研究范式从试错型转变为理性设计型。你不再是被动测试,而是主动预测和筛选。这尤其适合材料发现、性能优化类课题,能极大提升研究的前瞻性和产出速度。
方向三:让数据“开口说话”的合金设计术
核心问题: 手头有一堆成分、工艺、性能的离散数据,却感觉一片混沌,找不到优化方向。
核心技术栈: Python数据分析 → 特征工程(描述符)→ 机器学习模型(XGBoost等)→ 主动学习/贝叶斯优化。
-
能做什么: 系统性地挖掘数据中的“特征-性能”关联,建立预测模型。更酷的是,可以运用“主动学习”策略,让模型智能地建议“下一个最具信息量的实验或计算该做什么”,实现闭环优化。
-
价值点: 把随机的、依赖经验的“炼丹”,变成目标明确的、迭代的“智能实验设计”。特别适合成分复杂、工艺窗口窄的合金体系开发。
方向四:当有限元仿真“跑不动”时,请AI代劳
核心问题: 复合材料、多孔材料等细观结构复杂,进行高保真有限元仿真计算成本极高,想做参数优化或不确定性分析更是难上加难。
核心技术栈: ABAQUS二次开发(批量建模仿真)→ 深度学习(CNN/DNN/PINN)构建代理模型。
-
能做什么: 用有限元仿真生成一批高质量数据,训练一个神经网络作为“代理模型”。此后,输入新的结构参数,秒级获得性能预测,完全绕开昂贵的仿真计算。
-
价值点: 这是做优化设计、不确定性量化、参数反演的“核武器”。别人调一个参数等一天仿真结果,你已经用代理模型完成了上千次迭代,实现了真正的降维打击。
方向五:在最传统的领域,玩转最前沿的数据科学
核心问题: 水泥、混凝土等传统材料数据积累多但规律复杂,如何挖掘新知识、实现性能精准预测?
核心技术栈: 经典机器学习全流程(数据预处理/特征工程/模型训练/调参/可解释分析)。
-
能做什么: 这是一个绝佳的“练兵场”。你可以系统地实践从数据清洗到模型部署的完整流程,使用从线性回归到XGBoost再到神经网络的各种工具,并直接复现领域顶刊的工作。
-
价值点: 能让你快速获得将数据科学应用于具体工程问题的正反馈,建立扎实的方法论。这套技能具有极强的可迁移性,是你转向智能材料、数字孪生等前沿交叉领域的坚实基础。
专题一:金属材料多尺度计算模拟技术与应用:微观机理到宏观性能的集成工作流
|
目录 |
主要内容 |
|
|
第一部分 多尺度模拟基础与微观机理 |
1. 论内容: 1.1. 金属材料多尺度模拟范式:从电子结构到宏观性能的跨尺度关联 1.2. 第一性原理计算基础:密度泛函理论(DFT)的基本假设、泛函选择及标准计算流程 1.3. 分子动力学模拟核心:经典势函数的物理内涵、适用范围与验证原则;LAMMPS 的基本建模思想 1.4. 跨尺度参数传递的基本原则:从电子/原子尺度计算获取 2. 实践内容:(从参数计算到原子尺度变形模拟) 案例:金属物性计算—后续微观 / 跨尺度计算的基准前提 ○ 计算晶格常数:构建原子模型(纯金属、缺陷、合金)的几何基础 ○ 计算体积模量:反映材料抵抗体积压缩的能力 ○ 计算弹性常数矩阵:连续尺度本构模型的直接输入参数 ○ 计算空位形成能与迁移能垒:揭示材料的 “动态响应机制” ○ 计算简单合金体系的形成能:从纯金属到实际合金的体系扩展,判断合金的热力学稳定性,为介观组织模拟提供基础。 案例:纳米线拉伸变形的MD模拟 —跨尺度塑性机制的核心桥梁 ○ 构建金属纳米线模型并施加载荷,复现材料动态受力场景 ○ 可视化解析塑性微观机制:追踪原子轨迹,分析位错的形核位点等 ○ 量化多因素影响规律:对比不同温度与加载速率下位错运动特征,理解热激活过程与尺度效应 |
|
|
第二部分 相场方法:微观组织演化与断裂模拟 |
1. 理论内容: 1.1. 相场法核心思想 1.2. 相场热力学动力学耦合模型 1.3. 相场模型参数物理意义 1.4. 相场模型参数化分析:如何利用第一部分计算结果校准相场模型中的关键参数(如界面能、迁移率) 2. 实践内容:(从微观组织演化到裂纹扩展) 案例:微观组织演化模拟 —连接微观参数与宏观性能的关键纽带 ○ 模拟凝固枝晶生长行为 ○ 固态相变核心过程:模拟固态相变过程中新相的形核与生长 ○ 模拟多晶晶粒生长行为 ○ 探究 Zener 钉扎调控机制:在多晶模型中引入第二相粒子,研究钉扎效应对晶粒长大的抑制机制 案例:锯齿型晶界对裂纹扩展的抑制机制—抗裂材料微观结构设计的支撑 ○ 构建含不同曲率锯齿形晶界的双晶模型:引入初始微裂纹 ○ 解析裂纹扩展动态机制:采用相场 - 力学耦合方法施加外载,模拟并分析裂纹尖端塑性区演变及裂纹扩展路径 ○ 验证抗裂优化设计准则 ○ 关联疲劳损伤演化规律:研究循环载荷下裂纹的扩展行为 |
|
|
第三部分 晶体塑性有限元模拟与多尺度衔接 |
1. 理论内容: 1.1. 晶体塑性理论框架 1.2. 晶体塑性有限元在科学软件中实现 1.3. 多尺度数据传递策略与模型验证 2. 实践内容:(从单晶到多晶的塑性响应预测) 案例:晶体塑性本构模型的单晶验证 ○ 滑移系开动的数值模拟:基于弹性常数与滑移系参数,模拟典型滑移系的启动与演化过程,验证本构模型 ○ 分析单晶各向异性力学响应:模拟单晶在不同取向下的拉伸与压缩变形,分析各向异性响应 案例:基于真实微观结构的多晶宏观性能预测 ○ 微观组织 - 有限元网格映射:将相场法生成的微观组织图像通过脚本转换为有限元网格,实现微观结构与数值模型的对应。 ○ 多晶宏观力学响应计算:构建多晶代表性体积单元,施加周期性边界条件,计算宏观应力-应变响应。 ○ 组织 - 性能定量关联分析:讨论组织特征(晶粒尺寸、取向分布)对整体力学性能的影响 案例:循环载荷下的疲劳损伤与织构演化分析 ○ 模型构建与循环载荷模拟:基于相场微观组织特征建立三维多晶RVE模型,模拟循环加-卸载过程。 ○ 疲劳损伤与织构演化耦合分析 |
|
|
第四部分 金属液铸造成型过程模拟与应用实例 |
1. 理论内容 1.1 铸造成型过程模拟软件(EasyCast)概述 1.2 流场、温度场控制方程及求解 1.3 缺陷预测 1.4 与相场微观组织模拟耦合 2. 实践内容:(为企业界优化铸造工艺,带来经济效益) ○ 舱体、轮毂、隔板件等铸造成型过程建模仿真 |
|
|
第五部分 集成工作流与论文实例解读与复现 |
1. 理论内容: 1.1. 专题研讨:相场-扩散耦合模拟在金属氢致裂纹问题中的应用 1.2. 专题研讨:基于晶体塑性有限元CPFEM的高温蠕变损伤分析 1.3. 多尺度模拟结果在科研论文中的有效呈现与数据解读技巧 1.4. 集成工作流设计原则:针对特定科学问题,选择和组合多尺度方法 2. 实践内容:(前沿论文总结与复现) 案例:典型多尺度模拟论文精读与关键结果复现 ○ Serrated grain boundary modulation inhibits nano cracks propagation in pure magnesium: A phase field crystal and quasi in-situ EBSD study, Acta Materialia, 301(2025):121573 ○ Enhancing plasticity in BCC Mg-Li-Al alloys through controlled precipitation at grain boundaries, International Journal of Plasticity,181(2024):104105 |
|
专题二:计算化学与人工智能驱动的MOFs性能预测与筛选技术
|
目录 |
主要内容 |
|
|
第一部分 AI与MOF计算基础及环境搭建 |
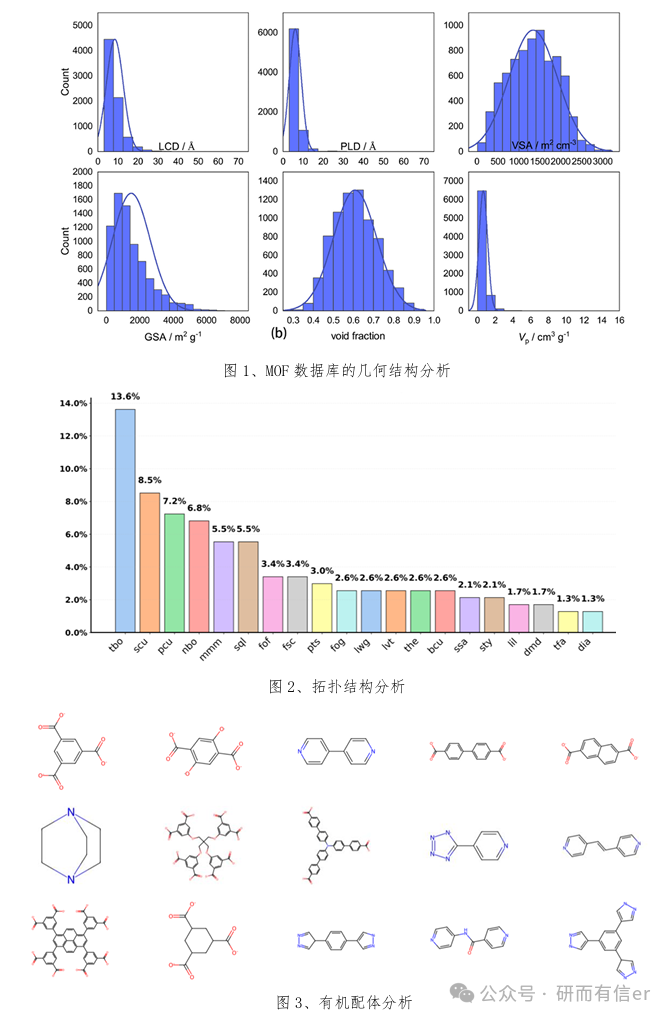
1. 关键理论: 1.1. AI 在计算化学中的范式革新:从计算化学到深度学习 1.2. MOF结构-功能关系解析:从金属节点、有机配体的化学特性到宏观吸附、分离性能 1.3. 科学计算与AI工作流整合:数据获取(DB)→结构清洗(Code)→特征计算(Tool)→模型训练(AI)的标准流程 1.4. 量子化学基础:DFT在MOF结构优化、电子结构与吸附位点分析中的应用 案例实践1: ◇ Case 1:使用MOSAEC算法处理CoRE-MOF、QMOF数据库,进行结构合理性校验与数据清洗,确保所有结构满足化学合理性 ◇ Case 2:使用Zeo++计算 MOF 孔结构特征(比表面积、孔隙率等) ◇ Case 3:拓扑分析与化学描述符(开放金属位点、有机配体结构式)批量提取 ◇ Case 4:使用CP2K完成MOF的晶体结构优化,并计算CH4的结合能,为机器学习筛选出来的潜在候选物进行机理解释。 |
|
|
第二部分 分子模拟和高通量计算在MOFs中的应用 |
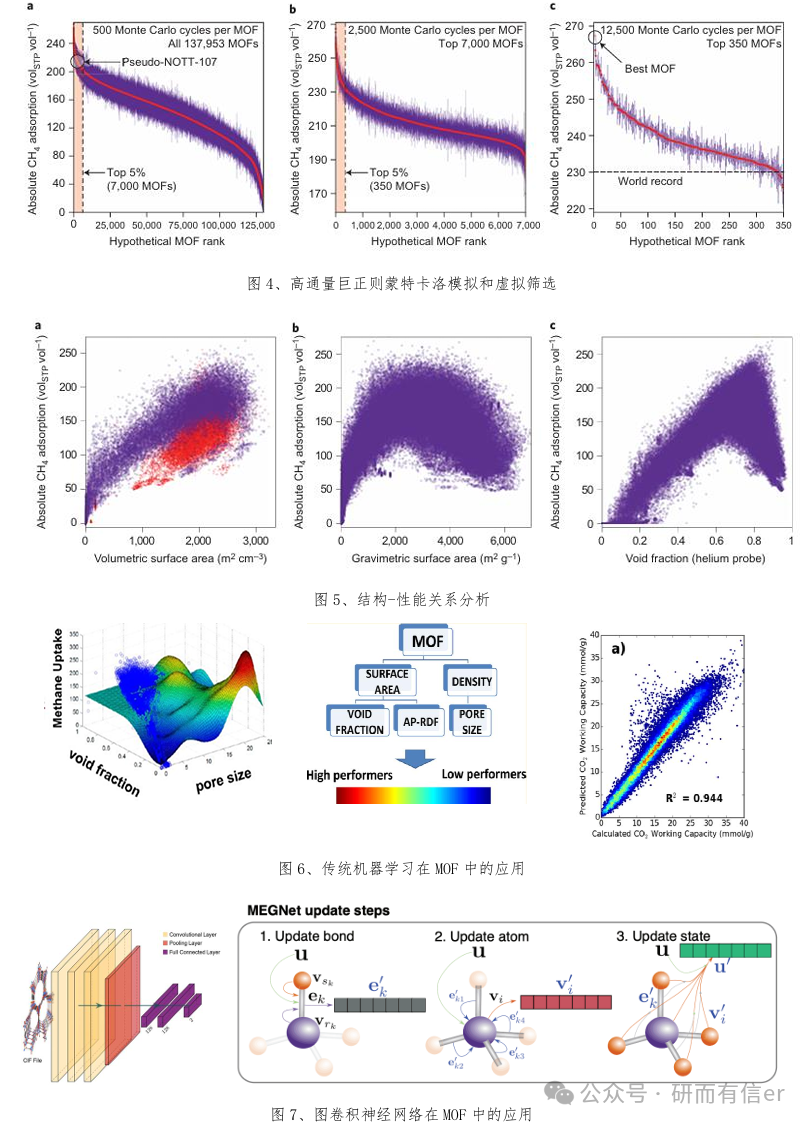
1. 关键理论: 1.1. 分子模拟核心:力场与电荷分配的物理意义与选择策略 1.2. 分子模拟在揭示MOF吸附与分离机制(吸附位点、扩散路径)中的作用 1.3. 高通量计算:作为AI模型“数据工厂” 的搭建流程与MOF 设计中的应用 案例实践2: ◇ Case 1:使用 RASPA2 计算气体吸附/分离性质 ◇ Case 2:使用 RASPA2计算等温吸附曲线和气体吸附概率密度图 ◇ Case 3: 使用GPU加速的gRASPA实现高通量GCMC模拟,体验“计算产生数据”的规模与效率,并构建后续所需数据集 ◇ Case4:高通量GCMC计算结果的分析与可视化,提取结构-性能对应关系。 文献复现:复现经典文献的高通量筛选流程,讨论如何将结果作为AI模型的输入Large-scale screening of hypothetical metal–organic frameworks. Nature Chem 2012, 4, 83–89 DOI: 10.1038/nchem.1192 |
|
|
第三部分 传统机器学习与可解释AI在MOF中的应用 |
1. 理论部分 1.1. 机器学习在MOF中的QSAR/QSPR模型:结构-性质定量关系 1.2. 特征工程核心:化学描述符(比表面积、孔径等)的物理意义 1.3. 算法深度解析:随机森林(RF)、XGBoost、SVM在吸附预测中的优劣 1.4. 可解释AI前沿:SHAP、SISSO 在挖掘物理机制与发现设计规则中的应用 案例实践3: ◇ Case 1:Python实现XGBoost、SVM、RF模型预测MOF气体吸附分离性质 ◇ Case 2:使用贝叶斯优化算法进行参数调优与特征选择 ◇ Case 3:基于独立筛选和稀疏算子 (SISSO) 算法从高维特征空间中学习简洁且可解释的物理公式 ◇ Case 4:可视化结果:AUC曲线、误差散点图、蜜蜂群图 ◇ Case 5:预测未知MOF的吸附性质,验证模型泛化能力 文献复现:Robust Machine Learning Models for Predicting High CO2 Working Capacity and CO2/H2 Selectivity of Gas Adsorption in Metal Organic Frameworks for Precombustion Carbon Capture J. Phys. Chem. C 2019, 123, 7, 4133–4139 DOI: 10.1021/acs.jpcc.8b10644 |
|
|
第四部分 图神经网络(GNN)与MOF结构-性能建模 |
1. 理论部分 1.1. GNN基础:如何将晶体结构表示为图—节点、边与全局状态的化学信息编码 1.2. 主流GNN模型:CGCNN、MEGNet消息传递机制及在MOF建模中的优势 1.3. 节点/边特征构建:化学键、配位环境、拓扑连通性的编码策略 1.4. GNN的可解释性:如何理解GNN“看到”的化学信息 案例实践4: ◇ Case 1:使用Pymatgen将MOF晶体结构转换为图神经网络所需的张量数据 ◇ Case 2:训练CGCNN或MEGNet模型,预测MOF的吸附性能,并与传统ML对比 ◇ Case 3:GNN可视化:使用t-SNE或主成分分析模型学习到的结构表征 ◇ Case 4:利用训练好的GNN模型,对虚拟MOF数据库(如hMOF)进行快速性能筛选与候选材料推荐 文献复现:Hydrogen storage metal-organic framework classification models based on crystal graph convolutional neural networks, Chemical Engineering Science 2022, 259, 117813. DOI: 10.1016/j.ces.2022.117813 |
|
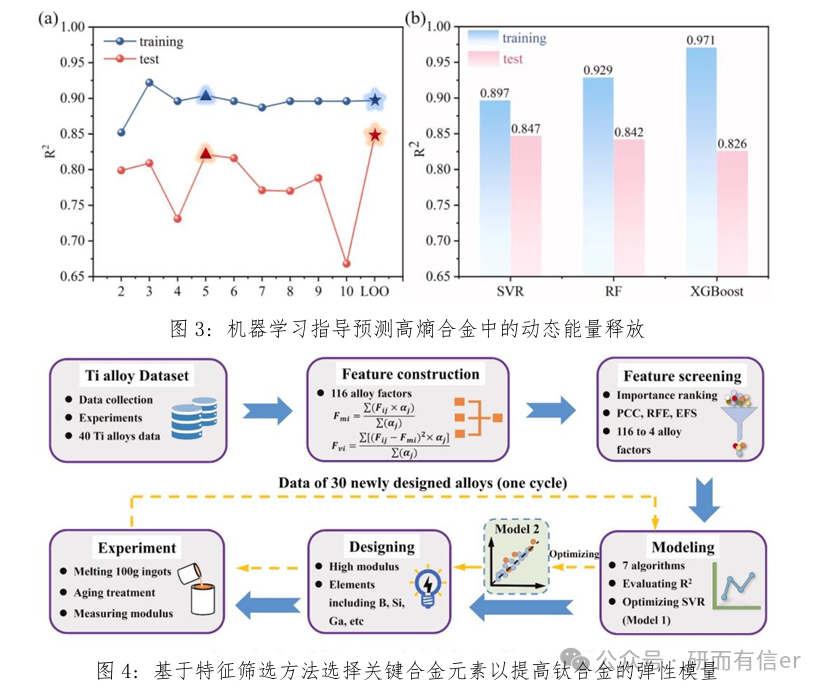
☆课程相关案例图示:
专题三:人工智能与数据驱动方法加速金属材料设计与应用
|
目录 |
主要内容 |
|
|
第一部分 Python与材料科学数据分析基础 |
1. 理论内容: 1.1. 数据驱动材料设计的范式革命与核心流程 1.2. Python材料数据科学生态系统 1.3. 材料数据库与数据标准化概述 2. 实践内容:从环境搭建到数据分析 ◇ Case 1:Python科学计算环境搭建与核心库(NumPy, Pandas等) ◇ Case 2:准备或数据库下载特定材料数据 □ 高温合金体系,获取其原子结构、成分、相溶解温度等基本信息 □ 钛合金体系,重点关注蠕变性能和拉伸力学性能 □ 下载/准备钛合金或高温合金的数据,并将结果保存为DataFrame ◇ Case 3:数据清洗、探索与可视化分析 |
|
|
第二部分 描述符工程与特征优化 |
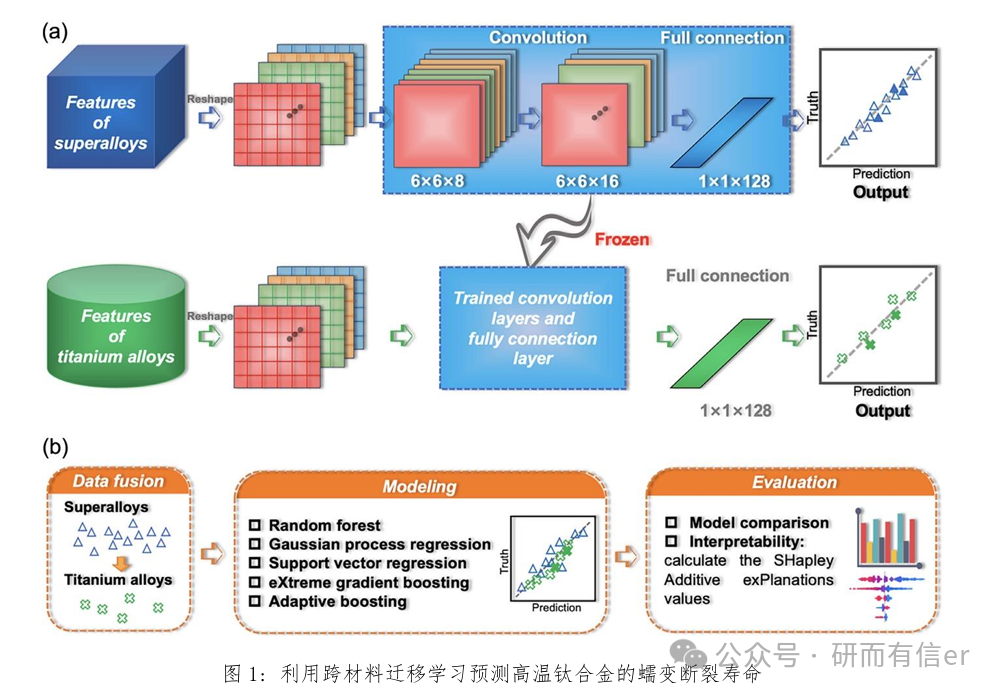
1. 理论内容: 1.1. 材料描述符的核心概念:如何数字化表征材料 1.2. 成分描述符、工艺描述符、晶体结构描述符与电子结构描述符详解 1.3. 特征选择、降维与特征重要性分析方法及原理 2. 实践内容:从生成描述符到优化特征空间 ◇ Case 1:使用Matminer批量生成多元化描述符 □ 为钛合金体系生成描述符 □ 为高温合金体系生成描述符 □ 获得包含原始材料信息和数十至上百个描述符列的DataFrame ◇ Case 2:无监督学习与数据可视化 □ 数据预处理: 对生成的大量描述符进行标准化,确保处于同一量纲 □ 主成分分析:对钛合金/高温合金体系描述符数据进行PCA分析 □ t-SNE可视化:使用t-SNE对钛合金体系/高温合金体系进行可视化 ◇ Case 3:特征选择与优化 □ 过滤法:计算描述符与目标性能的相关系数 □ 随机森林或其他回归模型进行训练。 以“预测钛合金的蠕变断裂寿命或其他性能”为例,分析模型哪些描述符最为重要。 □ 递归特征消除:使用RFECV工具,自动确定最佳特征数量。 |
|
|
第三部分 经典与集成机器学习算法 |
1. 理论内容: 1.1. 监督学习的基本框架与材料数据的建模流程 1.2. 经典机器学习算法的核心思想与比较 1.3. 集成学习方法及其在复杂材料体系中的优势 1.4. 模型评估、误差分析与模型选择策略 2. 实践内容——从基础建模到集成算法应用 ◇ Case 1:基于经典算法的材料性能预测入门实践 □ 使用给定合金属性数据集(如晶体结构/力学性能 - 元素特征数据)建立初始化线性回归、支持向量机回归、决策树回归/分类器等模型 □ 完成训练–测试流程,可视化预测误差 ◇ Case 2:超参数调优实战:使用交叉验证和自动化搜索工具来寻找模型的最佳超参数组合 ◇ Case 3:集成模型在复杂材料任务中的应用与解释 □ 针对合金力学性能等,分别训练基于随机森林、GBDT等性能预测模型,调整主要超参数,比较不同集成模型的预测精度与训练效率 □ 模型解释性:使用SHAP库,对合金力学性能预测模型进行分析 |
|
|
第四部分 主动学习与多目标优化 |
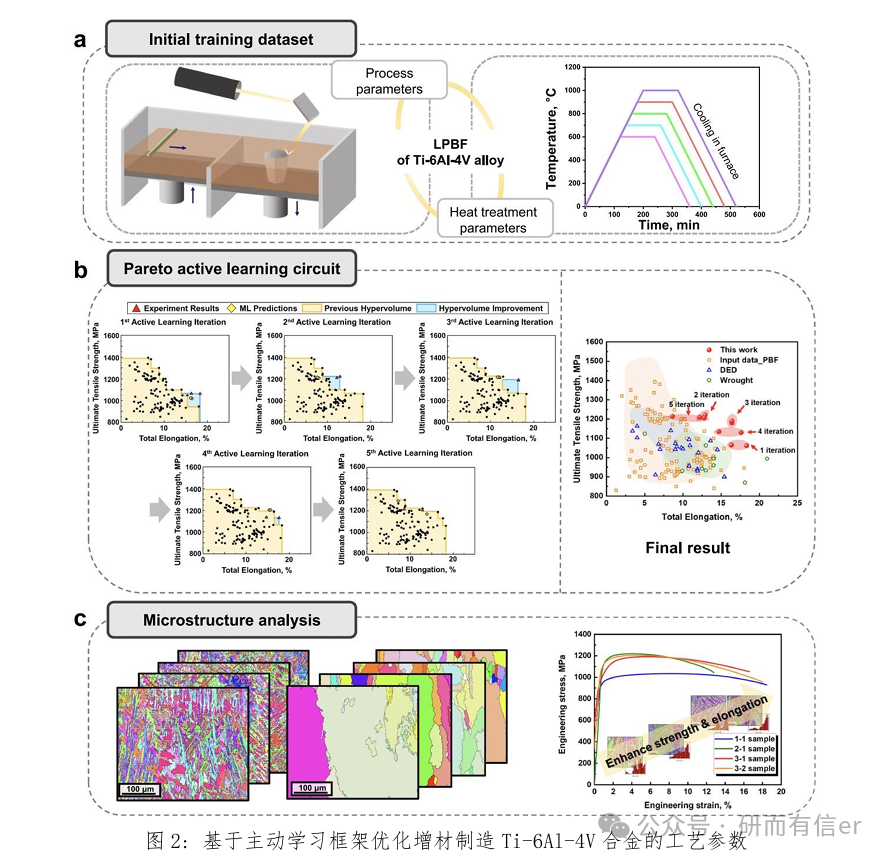
1. 理论内容: 1.1. 材料研发的瓶颈与主动学习的核心 1.2. 主动学习优化框架:建模与决策 1.3. 单目标优化与多目标优化介绍 2. 实践内容: ◇ Case 1:在一个简单一维函数上实现主动学习循环,理解其工作原理 ◇ Case 2:综合案例—钛合金增材制造工艺参数优化 □ 问题定义 □ 构建初始代理模型 □ 设计主动学习循环 □ 执行循环,绘制每一轮中发现的最佳性能的进化图 □ 循环结束后,分析最终推荐出的增材制造工艺参数 论文实例复现与解读: 1.Active learning framework to optimize process parameters for additive-manufactured Ti-6Al-4V with high strength and ductility. Nature Communication, 2025: 16: 931. |
|
|
第五部分 “灰箱”模型与可解释AI |
1. 理论内容: 1.1. “灰箱”模型的核心思想与优势 1.2. 物理信息神经网络核心原理与应用 1.3. 符号回归 1.4. 模型可解释性技术(全局与局部解释、SHAP 理论) 2. 实践内容——构建与解读下一代AI模型(结合相关论文) ◇ Case 1:物理约束神经网络实战 ◇ Case 2:符号回归发现新材料规律 □ 输入系统或材料相关的多维数据,运行符号回归寻找关键描述符 □ 对发现的公式进行合理性评估,判断其是否具有实际解释意义 □ 运用SHAP工具解读一个高性能集成学习模型,获得材料设计指南 □ 全局解释:计算并绘制SHAP特征重要性条形图,识别出影响合金性能的最关键描述符,绘制SHAP摘要图,观察每个描述符与目标性能的单调性或非线性关系 □ 局部解释:选择一个模型预测为超高力学性能的特定合金成分,生成该样本的SHAP力力图,直观展示描述符(特征) |
|
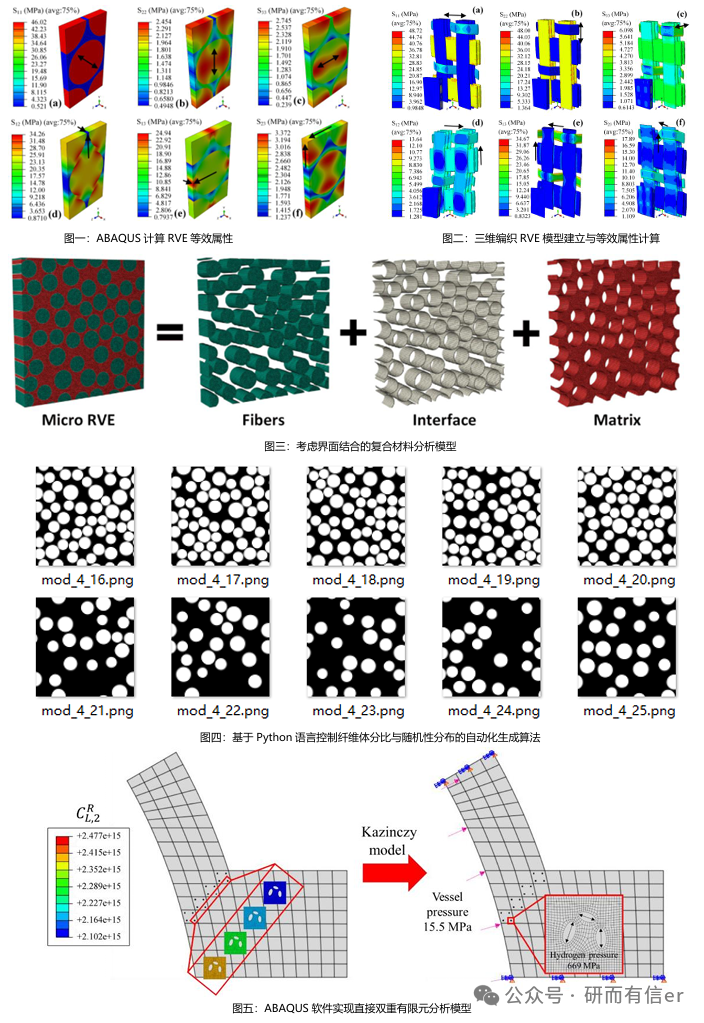
☆课程相关案例图示:
专题四:基于AI-有限元融合的复合材料多尺度建模与性能预测前沿技术
|
目录 |
主要内容 |
|
|
关键理论与软件 二次开发使用方法 |
1. 基础理论: 1.1.复合材料均质化理论(Eshelby方法、代表性体积单元RVE)论文详述 1.2.有限元在复合材料建模中的关键问题(网格划分、周期性边界条件) 1.3.神经网络基础与迁移学习原理(DNN、CNN、Domain Adaptation) 1.4.纤维复合材料的损伤理论(Tsai-Wu准则、Hashin准则) 实践1:软件环境配置与二次开发方法实践 ☆ ABAQUS/Python脚本交互(基于论文中RVE建模案例) ☆ ABAQUS GUI操作与Python脚本自动化建模 ☆ 输出应力-应变场数据的文件格式标准化 ☆ ABAQUS二次开发框架搭建 ☆ 基于ABAQUS二次开发程序的Hashin/Tsai-Wu失效分析有限元实践 ☆ TexGen软件安装及GUI界面操作介绍、Python脚本参数化方法 ☆ 三维编织/机织纤维复合材料几何模型及网格划分方法 |
|
|
多尺度建模与数据生成方法 |
1. 复合材料多尺度建模与仿真分析方法 1.1.多相复合材料界面(纤维/基质界面)理论机理(Cohesive模型) 1.2.连续纤维复合材料RVE建模(纤维分布算法、周期性边界条件实现) 1.3.参数化设计:纤维体积分数、纤维直径随机性等对性能的影响 1.4.双尺度有限元仿真方法原理及理论(FE2方法) 1.5.直接双尺度有限元仿真方法原理及理论方法(Direct FE2方法) 实践2:大批量仿真分析与数据处理方法 ☆ 考虑界面结合(Cohesive模型)的复合材料分析模型建立 ☆ 基于Python的ABAQUS批量仿真(PyCharm嵌入ABAQUS计算内核) ☆ 基于PowerShell调用Python FEA脚本解决动态内存爆炸问题 ☆ 控制纤维体分比的纤维丝束生成算法(RSE) ☆ 编写脚本生成不同纤维排布的RVE模型 ☆ 输出训练数据集(应变能密度、弹性等效属性等) ☆ ABAQUS实现Direct FE2方法仿真分析(复合材料) |
|
|
深度学习模型构建与训练 |
1. 深度学习模型设计: 1.1.基于多层感知机(DNN)的训练预测网络 1.2.基于卷积神经网络(CNN)的跨尺度特征提取网络(ResNet/DenseNet) 1.3.复合材料的多模态深度学习方法(结构特征提取+材料属性) 1.4.三维结构(多相复合材料/单相多孔材料)的特征处理及预测方法 1.5.物理信息神经网络(PINN):将物理信息融合到深度学习中 1.6.迁移学习策略:预训练模型在新型复合材料中的参数微调 实践3:代码实现与训练 ☆ 深度学习框架PyTorch/TensorFlow模型搭建 ☆ 构建多层感知机(DNN)的训练预测网络 ☆ 数据增强技巧:对有限元数据进行噪声注入与归一化 ☆ 构建二维结构的特征处理及预测网络(CNN—ResNet/DenseNet)+多模态学习预测 ☆ 构建三维结构的特征处理及预测网络(三维卷积神经网络) ☆ 建立物理信息神经网络(PINN)学习预测模型 |
|
|
迁移学习与跨领域应用 |
1. 迁移学习理论深化 1.1.归纳迁移学习与迁移式学习理论深入详解与应用 1.2.归纳迁移学习在跨领域学习预测中的应用 1.3.领域自适应(Domain Adaptation)在材料跨尺度预测中的应用 1.4.案例:碳纤维→玻璃纤维、树脂基质→金属基质的性能预测迁移 实践4:基于预训练模型的迁移学习 ☆ 迁移学习神经网络模型的搭建 ☆ 归纳学习方法:加载预训练模型权重,针对新材料类型进行微调 ☆ 领域自适应:使用领域自适应方法预测未知新材料相关属性 ☆ 使用TensorBoard可视化训练过程与性能对比 实践5:端到端复合材料性能预测系统开发 ☆ 参数化建模→有限元计算→神经网络预测→结果可视化全流程实现 |
|
☆课程相关案例图示:
专题五:机器学习在智能水泥基复合材料中的应用与实践
|
目录 |
主要内容 |
|
|
机器学习基础模型与复合材料研究融合 |
1.机器学习在复合材料中的应用概述 2.机器学习用于复合材料研究的流程 3.复合材料数据收集与数据预处理 实例:数据的收集和预处理 4.复合材料机器学习特征工程与选择 实例:以纳米材料增强复合材料为例,讨论特征选择、特征工程在提高模型性能中的作用。 5.线性回归用于复合材料研究 实例:线性回归在处理复合材料数据中的应用 6.多项式回归用于复合材料研究 实例:多项式回归在处理复合材料数据中的非线性关系时的应用 7.决策树用于复合材料研究 实例:决策树回归在预测水泥基复合材料强度中的应用 |
|
|
复合材料研究中应用集成学习与支持向量模型 |
1.随机森林用于复合材料研究 实例:随机森林在预测复合材料性能中的应用 2. Boosting算法用于复合材料研究 实例:Catboost在预测复合材料强度中的应用 3.XGBoost和LightGBM用于复合材料研究 (1) XGBoost (2) LightGBM (3) 模型解释性技术 实例:XGBoost和LightGBM在水泥基复合材料性能预测中的应用,模型比较 4.支持向量机 (SVM) 用于复合材料研究 (1) 核函数 (2) SVM用于回归(SVR) 实例:SVR在预测复合材料的力学性能中的应用 5.模型调参与优化工具包 (1) 网格搜索、随机搜索的原理与应用 (2) 工具包Optuna 实例:超参数调整方法,模型调参与优化工具包的应用 6.机器学习模型评估 (1) 回归模型中的评估指标(MSE, R2, MAE等) (2) 交叉验证技术 实例:比较不同模型的性能并选择最佳模型 |
|
|
复合材料研究中应用神经网络 |
1.神经网络基础 (1) 激活函数 (2) 前向传播过程 (3) 损失函数 实例:手动实现前向传播 2.神经网络反向传播与优化 (1) 梯度下降法原理 (2) 反向传播算法 (3) 随机梯度下降(SGD) 实例:实现梯度下降算法 3.复合材料研究中的多层感知机(MLP) (1) MLP架构设计 (2) MLP的训练过程 (3) MLP在回归和分类中的应用 实例:构建简单的MLP解决复合材料中的回归问题 4.PINNs (1)PINN基本原理 (2)弹簧振动正问题中的PINNs (3)弹簧振动逆问题中的PINNs 实例:使用PyTorch构建PINNs 5.GAN (1)GAN基本原理 (2)针对表格数据的GAN (3)增强数据的评估指标 实例:构建GAN生成水泥基复合材料数据 6.可解释性机器学习方法-SHAP (1) SHAP理论基础 (2) 计算和解释SHAP值 实例:复合材料中应用SHAP进行模型解释和特征理解 |
|
|
论文复现机器学习综合应用以及SCI文章写作 |
论文实例解读与复现:选择两篇应用机器学习研究水泥基复合材料的SCI论文 1. Comparison of traditional and automated machine learning approaches in predicting the compressive strength of graphene oxide/cement composites. Construction and Building Materials, 2023, 394: 132179. 2. Machine learning aided uncertainty analysis on nonlinear vibration of cracked FG-GNPRC dielectric beam. Structures, 2023, 58: 105456. Ø论文中使用的复合材料数据集介绍 Ø论文中的复合材料特征选择与数据预处理方法 Ø论文中使用的模型结构与构建 Ø机器学习研究复合材料的超参数调整 Ø复合材料研究中机器学习模型性能评估 复合材料机器学习研究结果可视化 |
|
|
课程总结与未来展望 Ø 课程重点回顾 Ø 机器学习在复合材料中的未来发展方向 Ø 如何继续学习和深入研究 Ø Q&A环节 |
||
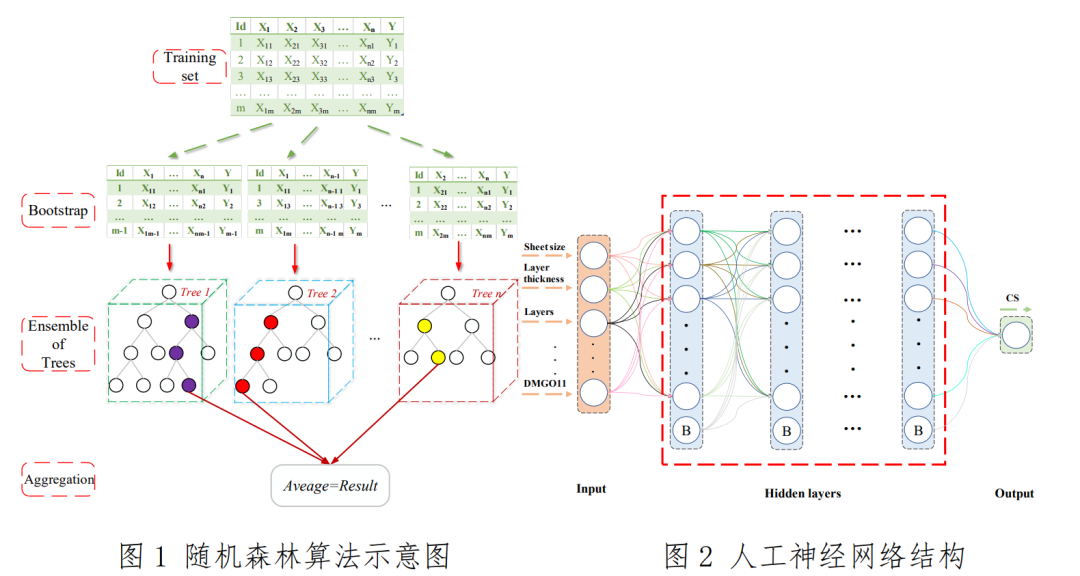
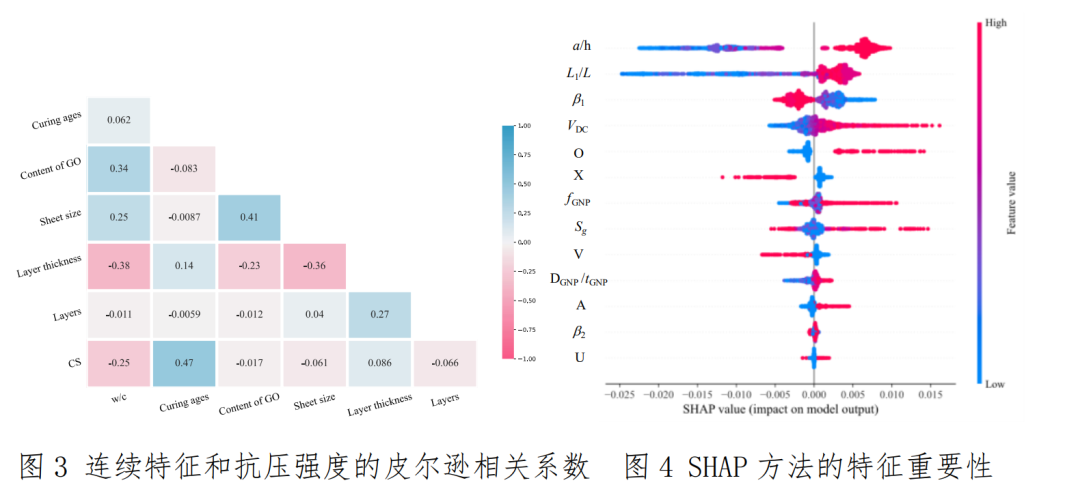
部分案例图示:
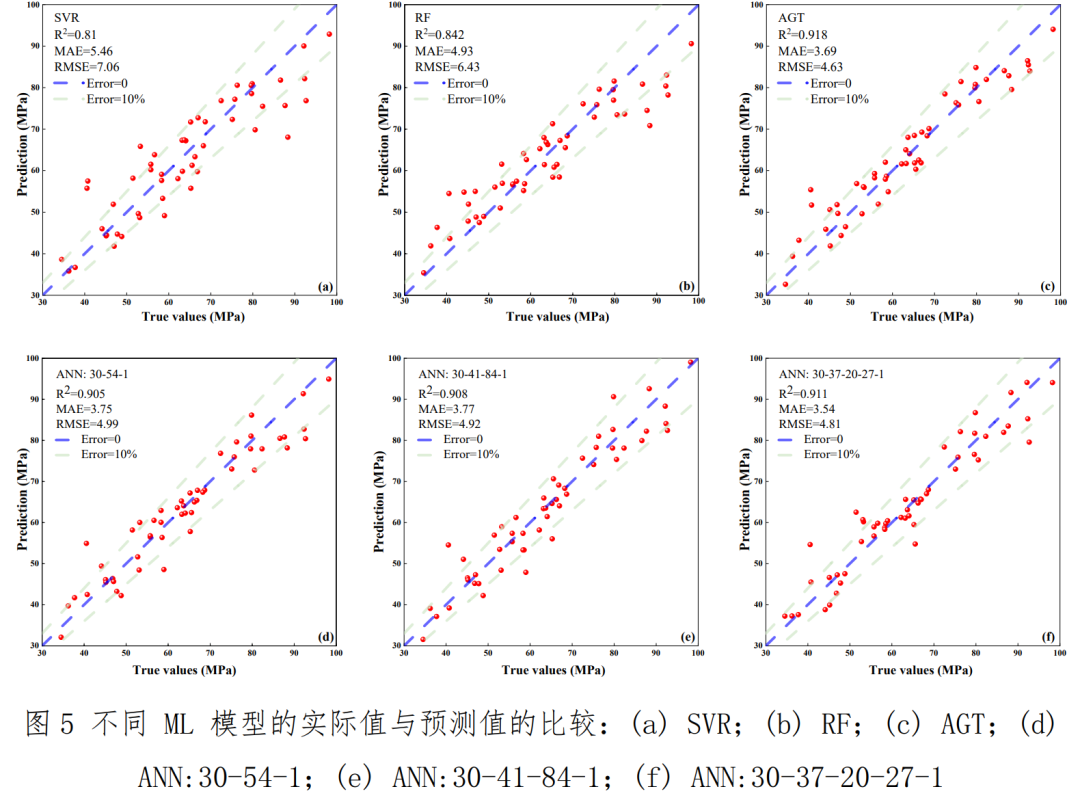
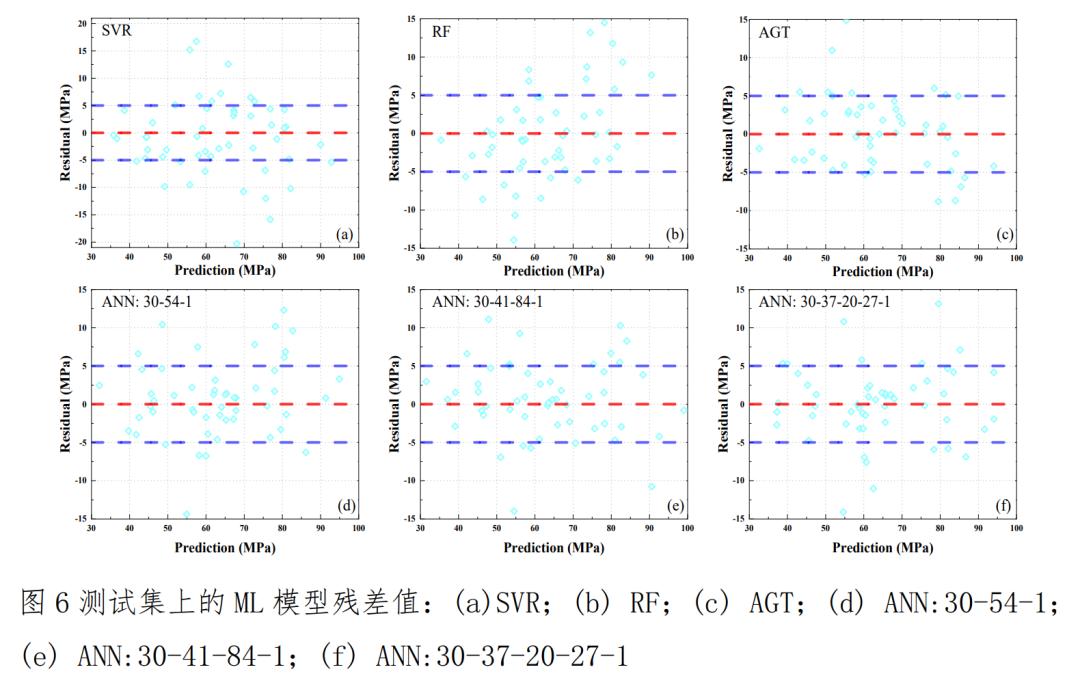
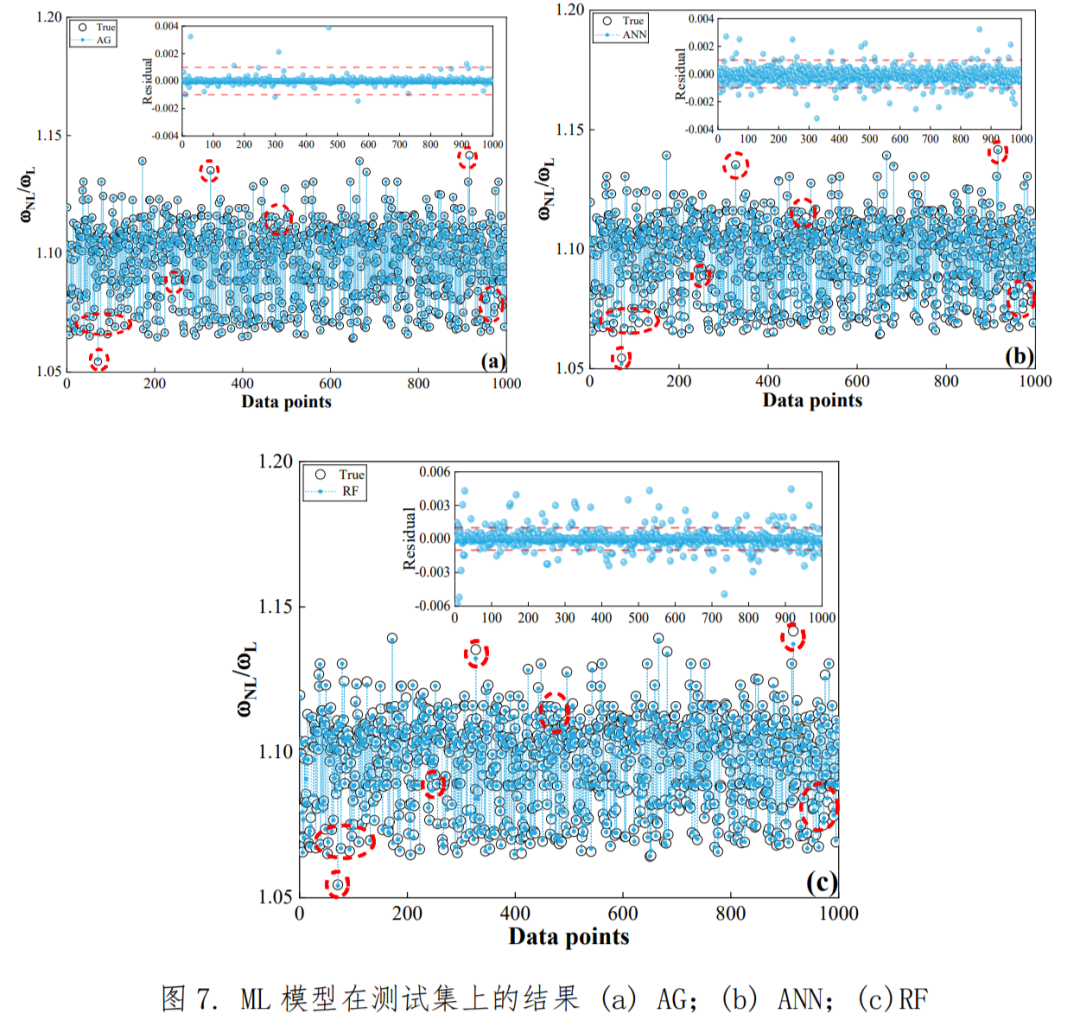
我知道,看到这些你可能既兴奋又焦虑。兴奋于新工具的潜力,焦虑于自己是否能学会、时间是否来得及。
我完全理解。 我们都经历过对着满屏报错的无助,经历过对复杂理论的畏难,更经历过在课题压力和毕业倒计时下的深深焦虑。
但请你相信一个事实:科研的核心竞争力,正在从“谁拥有更先进的实验设备”,转向“谁能更聪明地提出科学问题,并运用更强大的工具去解决问题”。 计算与数据科学,就是当今时代最普惠的“先进设备”。
学习它们,不是为了赶时髦,而是为了给你的科研生命安装一个“加速器”和一个“导航仪”。让你能把宝贵的时间和创造力,从重复、等待、试错中解放出来,投入到真正有创造性的思考中。
这条路开始会有点难,但每一步都算数。 从看懂一行代码、复现一个案例、解决手头一个小问题开始。你会发现,自己正从一个被实验进度推着走的“操作工”,逐渐成长为能驾驭多种工具、洞察问题本质的“战略科学家”。
别高估一年的变化,也别低估三年的积累。 选择一个最能解决你当前痛点的方向,行动起来。今天你投入时间学习的每一个新工具,都是在为你未来的学术生涯和职业道路,积累最硬的通货。
科研长路,愿你有实验的笃实,也有计算的锐利。共勉。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)