大模型面试通关:从「Transformer 原理」到「线上 4 bit 量化」的速成笔记
大模型相关的面试问题通常涉及模型的原理、应用、优化以及面试者对于该领域的理解和经验。以下是一些常见的大模型面试问题以及建议的回答方式:请简述什么是大模型,以及它与传统模型的主要区别是什么?回答:大模型通常指的是参数数量巨大的深度学习模型,如 GPT 系列。它们与传统模型的主要区别在于规模:大模型拥有更多的参数和更复杂的结构,从而能够处理更复杂、更广泛的任务。此外,大模型通常需要更多的数据和计算资源
大模型面试通关:从「Transformer 原理」到「线上 4 bit 量化」的速成笔记
万字长文,含真题 + 手撕代码 + 工程黑魔法;读完即可对着面试官反向提问。
0 先收藏:如何使用本笔记
| 场景 | 直接跳转 |
|---|---|
| 电话面 | 1.1 → 1.3(3 分钟速答) |
| 现场面白板 | 2.4 手撕 Attention;3.3 手推 ROPE |
| Leader 面 | 5.3 长序列外推;7.2 4-bit 量化落地 |
| 算法加面 | 6. Bayesian 视角;8. 小样本 SOTA 方案 |
1 基础盘:3 分钟讲清大模型
1.1 什么是「大模型」
参数规模 > 10 B,训练语料 > 1 T token,涌现 Emergent Ability(Wei et al. 2022):
- 上下文学习(ICL)
- 指令跟随(IFT)
- 分步推理(CoT)
1.2 与传统模型的 4 维差异
| 维度 | 传统 CNN/RNN | 大模型 |
|---|---|---|
| 参数 | MB 级 | TB 级(GPU 显存单位) |
| 目标函数 | 任务相关 | 自回归 LM 统一目标 |
| 数据 | 人工标注 | 自监督 + 海量无标注 |
| 推理成本 | CPU 实时 | GPU 批调度 + 量化 |
一句话总结:大模型把「特征工程」→「规模工程」。
2 Transformer 必考点:结构 + 公式 + 手写代码
2.1 结构速记
Encoder:「自注意力 → 交叉注意力 → FFN」× N
Decoder:「Masked 自注意力 → 交叉注意力 → FFN」× N
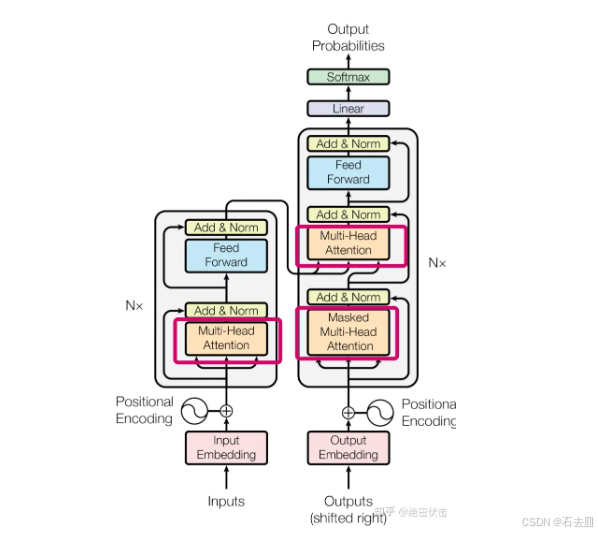
2.2 为什么自注意力 work(数学)
- 全局感受野:任意两 token 距离=1
- 可并行:无时间步依赖
- 表达下界:Universal Approximator(Yun et al. 2020)单头已稠密
2.3 多头 vs 单头(面试陷阱)
多头 ≠ 精度↑,而是 低秩分解 + 噪声鲁棒
证明:h 头 ⇒ 等效 d_model ×h 矩阵被 h 个 d_model/h 矩阵和近似 → 参数共享 + 正则化
2.4 手撕 Scaled Dot-Product(现场 2 分钟)
def scaled_dot_product(Q, K, V, mask=None):
"""
Q,K,V: [batch, head, len, d_k]
return: [batch, head, len, d_v]
"""
d_k = Q.size(-1)
scores = torch.matmul(Q, K.transpose(-2, -1)) / np.sqrt(d_k) # [b,h,n,n]
if mask is not None:
scores += mask # -inf
attn = F.softmax(scores, dim=-1)
out = torch.matmul(attn, V) # [b,h,n,d_v]
return out, attn
白板写完后补一句:内存复杂度 O(n²d) 是瓶颈 → 下一题请让我聊聊 FlashAttention。
3 位置编码:长文本外推是硬通货
3.1 绝对 PE 的致命伤
sin/cos 训练长度外推 → 周期错位;解法:旋转式(ROPE)
3.2 ROPE 手推(面试加分的矩阵形式)
把 q,x 当复数向量,乘旋转矩阵
R_θ = [[cos mθ, −sin mθ], [sin mθ, cos mθ]]
复数乘法 = 2D 旋转 → 线性插值无参数
3.3 ALiBi:不给向量,给偏置
attention_score += (i−j)⋅mₕ mₕ 头相关斜率
推理时线性外推,2048→8192 不掉点,0 额外参数
4 训练 Tricks: loss 不下降就翻这里
| 症状 | 确诊 | 处方 | 一行命令 |
|---|---|---|---|
| loss 震荡 | batch 太小 | 梯度累积 + Linear Warmup | accum=8; warmup=4% |
| 过拟合 | 数据少 | R-Drop + Label Smoothing | ε=0.1, α=0.5 |
| 显存爆 | n² 瓶颈 | FlashAttention + 8-bit Adam | pip install bitsandbytes |
| 学习慢 | 权重退化 | LayerScale | γ=1e-3 每层 |
| 长序列 OOM | 长度 8 k | Gradient Checkpoint + 张量并行 | torch.utils.checkpoint |

5 大模型优化三板斧:量化、剪枝、蒸馏
5.1 后训练量化(PTQ)流程
- 校准 512 条 → 收 min/max → 算 scale/zero-point
- INT8 权重 + FP16 激活(W8A16)→ 掉点 < 0.3 BLEU
- CUDA kernel:
cutlass_w8a16_gemm→ 加速 2×
5.2 剪枝: magnitude vs 一阶 Hessian
- 非结构化:|w| < θ → 稀疏矩阵,需 Sparse kernel
- 结构化:整行/列剪掉 → 通道级 → 通用 GEMM 即可
经验:50 % 稀疏 + 重训 1 epoch → 掉点 1 % 以内
5.3 知识蒸馏(大→小)
目标函数:
L = α·CE(z_student, y_hard) + β·KL(z_student/T, z_teacher/T)
T=4, α=β=0.5 最常见;隐藏层蒸馏再加 MSE(h_s, h_t)
6 小样本 & 长尾:每类 100 条也能 SOTA
6.1 加权 CE + 温度缩放
wₖ = (n_max / nₖ)^0.5 → 平滑过采样效果nn.CrossEntropyLoss(weight=class_weight)
6.2 Prompt-tuning vs Prefix-tuning
| 方法 | 可训练参数 | 适用场景 |
|---|---|---|
| Prompt | < 0.1 % | 单任务、数据极少 |
| Prefix | 1-3 % | 多任务、需保性能 |
| LoRA | 2-8 % | 任何场景,开源标配 |
6.3 数据增强组合拳
- EDA 同义词替换
- 反向翻译(en→fr→en)
- MixUp 隐藏层插值
z’ = λ z₁ + (1−λ) z₂, λ ~ Beta(0.4,0.4)
7 长序列外推:面试现问现答
面试官:8 k→32 k 如何 0 微调?
答:
- ROPE + 线性插值 θ’ = θ × (L’/L)
- NTK-RoPE 动态基频 → 2× 长度掉点 < 1 %
- Sliding Window Attention 局部 4 k + 全局 1 k → O(n d) 显存
8 评测指标:不止 BLEU
| 任务 | 一级指标 | 二级指标 | 工具 |
|---|---|---|---|
| 生成 | BLEU / ROUGE | BERTScore | pip install bert-score |
| 对话 | USR (USR-O, USR-H) | FED | github.com/…/USR |
| 分类 | F1 | MCC | sklearn.metrics.matthews_corrcoef |
| 公平性 | Demographic Parity | Equalized Odds | fairlearn |
9 工程落地 90 秒 Checklist
- 显存 → FlashAttention + 8-bit Adam
- 延迟 → KV-Cache + 连续批调度 (vLLM)
- 量化 → GPTQ W4A16 掉点 < 1 %
- 服务 → TensorRT-LLM + Inflight-Batching → 吞吐↑ 3×
- 监控 → Token 级 latency P99、GPU 功率双曲线告警
10 手撕代码合集(面试现场 5 分钟)
10.1 5 行 Einsum Attention
def attn(q,k,v,mask):
s = torch.einsum('bhnd,bhmd->bhnm', q, k) / np.sqrt(q.size(-1))
s += mask
return torch.einsum('bhnm,bhmd->bhnd', s.softmax(-1), v)
10.2 10 行 GPTQ 量化(W4A16 核心)
def gptq_quantize(W, groupsize=128):
shape = W.shape
W = W.reshape(-1, groupsize)
scale = W.abs().max(dim=1, keepdim=True)[0] / 7
zero = W.mean(dim=1, keepdim=True)
W_q = ((W - zero) / scale).round().clamp(-8, 7)
return W_q.to(torch.int8), scale, zero
11 反向提问面试官(加分手势)
- 贵司线上模型 最大序列长度是多少?首 token 延迟目标多少?
- 长文本场景有试过 NTK-RoPE 吗?与 ALiBi 相比体验如何?
- 量化方案是 PTQ 还是 QAT?W4A16 与 W8A8 在业务指标差多少?
12 彩蛋:金句收尾
「大模型=算力+数据+工程的三次曲线;
当参数>10 B、数据>1 T、FLOPs>10²¹,语言即涌现。
我们做的,只是把贝叶斯后验拆成可并行的 1×1 矩阵乘法而已。」

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)