2025 AI年度复盘:从100篇顶会论文看中美巨头的AGI路线之争
2025年AI领域迎来重大范式转变,从"暴力堆参数"转向精细化智能提升。基于100+篇顶会论文分析,四大技术突破尤为突出:流体推理通过Test-Time Compute让AI学会思考推演;长期记忆技术治愈模型"健忘症";空间智能补足视觉处理短板;元学习实现持续自我进化。其中,MoE架构、强化学习革新(如GRPO算法)和记忆系统升级成为关键驱动力。研究显示,AI在推理、长期记忆和视觉处理等原"零分项
2025 AI年度复盘:从100篇顶会论文看中美巨头的AGI路线之争
导读:2025年,AI领域经历了从"暴力美学"到"精细工程"的范式转变。本文基于对DeepMind、Meta、DeepSeek等顶尖机构100+篇论文的系统梳理,深度解析四大核心技术突破——流体推理、长期记忆、空间智能与元学习,揭示通往AGI的真实技术路径。
核心观点速览
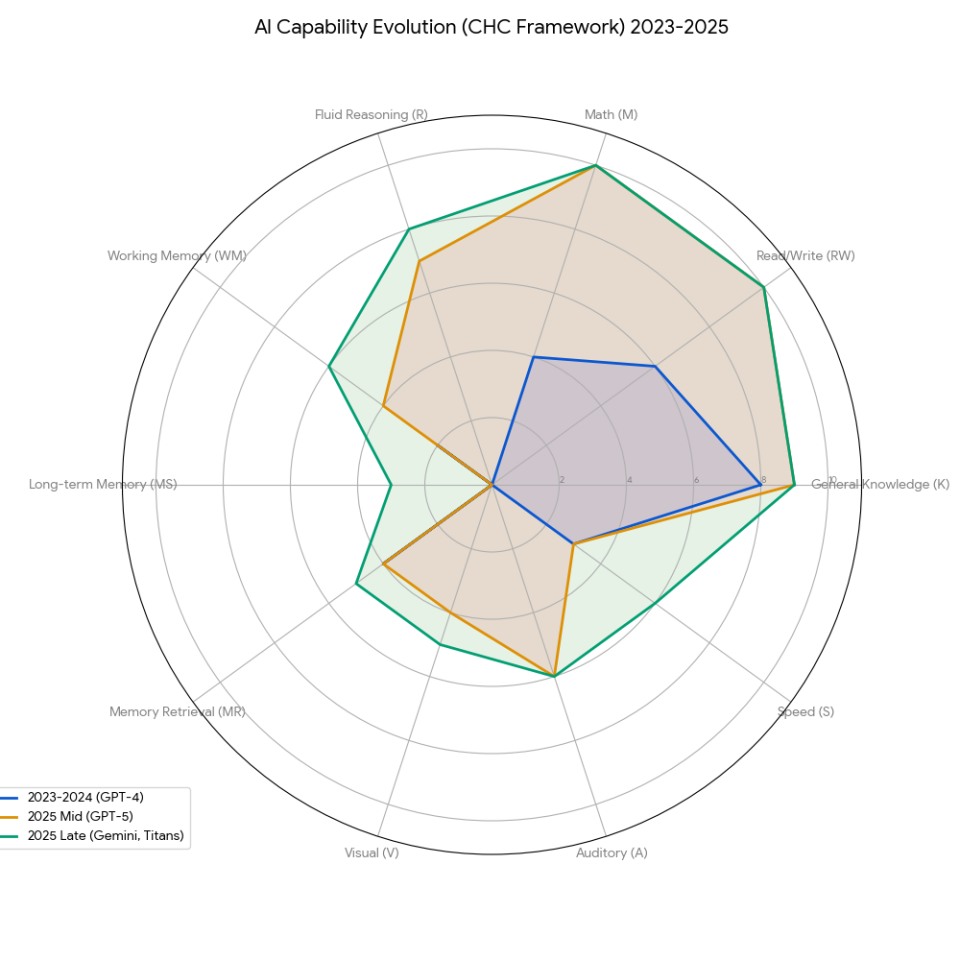
图:2025年AI技术发展全景概览。这一年的技术进步主要集中在流体推理(Fluid Reasoning)、长期记忆(Long-term Memory)、空间智能(Spatial Intelligence)以及元学习(Meta-learning)四个领域,标志着从"把模型做大"到"把模型做聪明"的范式转变。
2025年的核心命题
模型不仅要博学,更要懂思考、能记住、会学习。
通过Yoshua Bengio提出的AGI框架(基于CHC认知理论),我们发现之前的AI存在严重的"能力偏科":它在一般知识上得分极高,但在即时推理(R)、**长期记忆(MS)和视觉处理(V)**上几乎是空白。这种不平衡构成了通往AGI的最大阻碍。
| CHC能力维度 | 2023-2024 | 2025中期 | 2025晚期 | 关键技术驱动力 |
|---|---|---|---|---|
| 一般知识 (K) | 8% | 9% | 持平 | 事实性微调(FACTS benchmark) |
| 读写能力 (RW) | 6% | 10% | 持平 | 注意力机制变革 |
| 数学能力 (M) | 4% | 10% | 持平 | OpenAI o3在AIME达96.7% |
| 即时推理 ® | 0% | 7% | 8% | Test-Time Compute + RL |
| 工作记忆 (WM) | 2% | 4% | 6% | 上下文窗口扩展至2M-10M tokens |
| 长期记忆 (MS) | 0% | 0% | 3% | Titans/MIRAS架构 |
| 记忆检索 (MR) | 4% | 4% | 5% | 幻觉率降低但未根除 |
| 视觉处理 (V) | 0% | 4% | 5% | 世界模型发展 |
| 听觉处理 (A) | 0% | 6% | 持平 | 原生多模态音频处理 |
| 处理速度 (S) | 3% | 3% | 6% | 小模型蒸馏(Gemini 3 Flash) |
核心洞察:推理®、长期记忆(MS)、视觉(V)三个维度从0起步,是2025年补短板最成功的领域。这三个"零分项"的突破,构成了本文的核心叙事。
一、暴力美学的终结:2025年的范式转变
1.1 Scaling Law遇到天花板
2025年最重要的认知转变是:单纯堆参数的时代结束了。
GPT-4.5已经遇到了互联网数据枯竭的问题,训练超大型稠密模型的工程难度也在几何级增加。正如英伟达所言,Test-Time Compute已成为大模型的第三个Scaling Law——继模型参数和训练数据之后的新增长维度。
突破路径 = MoE稀疏化 + 合成数据 + 强化学习
MoE(混合专家)架构的崛起尤为显著。DeepSeek V3采用的MoE架构,通过稀疏激活机制,实现了"一次只训部分专家"的高效训练模式。相比传统稠密模型,MoE在保持性能的同时大幅降低了训练成本。
这标志着AI研究从"把模型做大"转向"把模型做聪明"。
二、流体推理革命:Test-Time Compute的崛起
2.1 从"背书鹦鹉"到"思考机器"
2025年最重要的范式革新是Test-Time Compute(推理时计算,TTC)。
核心理念:智能不仅是参数的函数,也是时间的函数。
以OpenAI o1和DeepSeek R1为代表,AI学会了在输出答案前进行数秒甚至数分钟的内部推演:
传统模型:输入 → 直接输出(毫秒级)
TTC模型:输入 → 内部推演 → 自我验证 → 输出(秒/分钟级)
技术本质:TTC将推理过程外化为可观察的思维链(Chain of Thought),模型通过长达数千token的内部对话,进行假设验证、错误回溯和方案比较。
2.2 强化学习的三大工程突破
强化学习(RL)成为提升推理能力的核心手段,因为模型的思维过程无法在预训练期间直接引导。RL系统可以拆解为三个核心组件:
RL系统 = 探索策略(采样) + 评分系统(奖励) + 参数更新(优化)
2.2.1 评分系统的革新:RLVR + Rubric Rewards
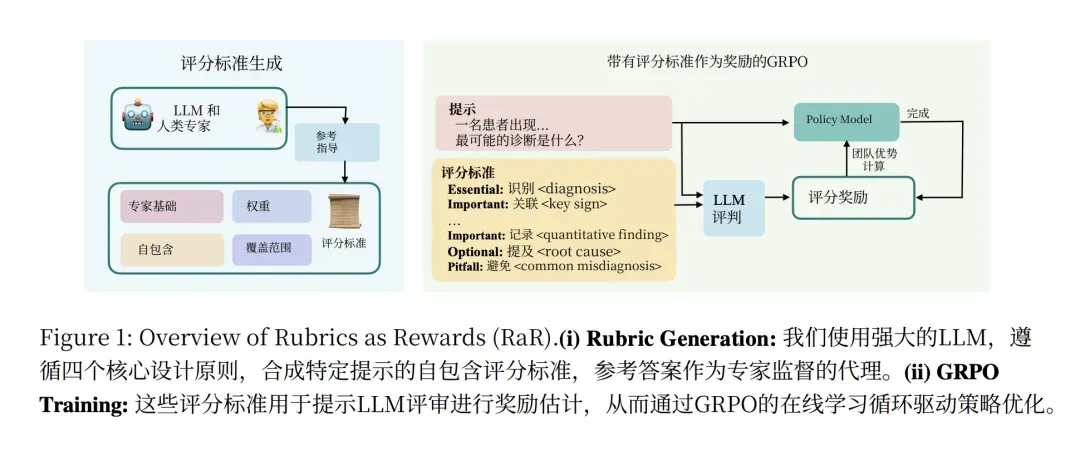
图:Rubrics as Rewards (RaR) 框架的完整工作流程。这是解决RLVR在开放领域缺乏客观验证标准问题的关键创新。
图解说明:
- 左侧 - Rubric生成过程:LLM根据任务自动生成评分细则,包含四类评分维度:
- Essential(必要项):如医疗诊断中的
<diagnosis>标签 - Important(重要项):如
<key sign>关键体征、<quantitative finding>定量发现 - Optional(可选项):如
<root cause>根因分析 - Pitfall(陷阱项):如
<common misdiagnosis>常见误诊
- Essential(必要项):如医疗诊断中的
- 右侧 - GRPO训练过程:模型根据Rubric进行自我评分,实现无需人工标注的强化学习训练
DeepSeek R1的成功证明了一个惊人的事实:只需给模型一个对错结论作为奖励信号,模型就能自发探索推理过程。这就是ORM(Outcome Reward Model)的威力。
| 评分方法 | 适用场景 | 优势 | 局限 |
|---|---|---|---|
| ORM(结果奖励) | 数学、代码、逻辑 | 简单高效,无需过程标注 | 长推理链易崩溃 |
| PRM(过程奖励) | 复杂多步推理 | 精细反馈,识别错误步骤 | 标注成本极高 |
| Rubric评分 | 开放领域(文学、医疗) | 灵活可控,适应主观任务 | 需人工设计评分细则 |
| Self-Critique | 通用场景 | 利用模型自身置信度 | 依赖模型校准质量 |
RLVR的局限与突破:
在数学、代码等可验证领域,RLVR效果显著。但对于文学、医疗等缺乏客观真假的领域,业界正在探索两条路径:
- 外求法:人工或模型制定复杂评分细则(Rubric),让模型按规则打分
- 内求法:利用模型自身的确信度(Self-Critique)作为奖励信号
Kimi K2的joint RL stage策略就是将RLVR和Self-Critique Rubric Reward结合的典型案例。
2.2.2 RL的Scaling Law:Sigmoid而非幂律
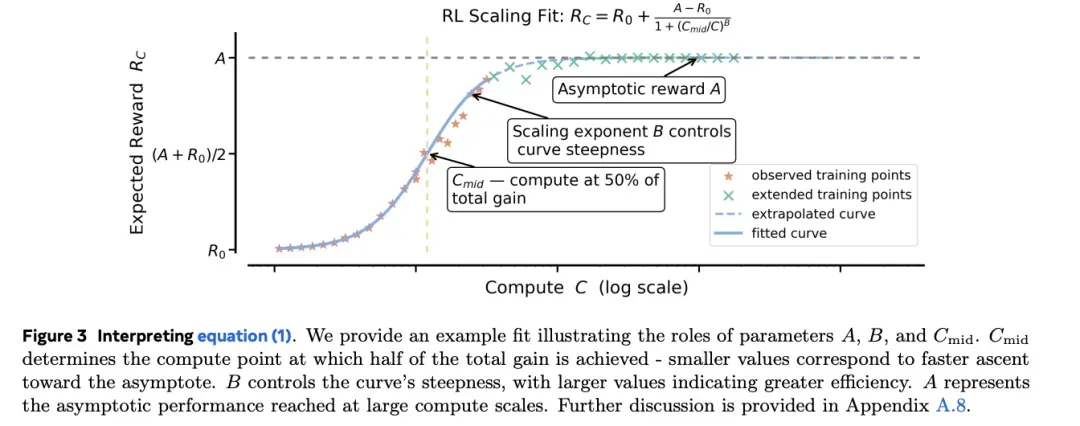
图:Meta ScaleRL研究的核心发现——RL性能与计算量呈Sigmoid曲线关系,而非传统的幂律关系。
图解说明:
- 拟合公式: R c = R 0 + A 1 + exp ( − B ( log C − log C m i d ) ) R_c = R_0 + \frac{A}{1+\exp(-B(\log C - \log C_{mid}))} Rc=R0+1+exp(−B(logC−logCmid))A
- A(Asymptotic reward):渐近奖励上限,表示RL能达到的最高性能天花板
- B(Scaling exponent):控制曲线陡峭程度,值越大表示效率越高
- C m i d C_{mid} Cmid:达到50%总增益时的计算量点
- 曲线特征:起步难(初期增长缓慢)→ 中间猛(快速增长期)→ 最后饱和(接近天花板)
- 关键发现:图中展示了fitted curve(拟合曲线)和extrapolated curve(外推曲线),证明该规律可用于预测大规模训练效果
这意味着什么?
- RL有天花板:不能无限提升智力上限,只能把模型已有的潜能"逼"出来
- 一旦逼到100%,RL就失效:想要突破,必须革新底座模型或算法架构
- 好消息:我们离天花板还远,还有大量工程优化空间
ScaleRL的最佳实践:
- 使用**长思维链(Long CoT)**作为关键驱动力
- 使用大Batch Size(如2048 prompts)触达更高性能天花板
- 这将RL从"炼金术"转变为可预测的工程科学
2.2.3 参数更新的革新:GRPO算法
DeepSeek R1带来的第二个RL震荡是GRPO(Group Relative Policy Optimization)算法的流行。
传统PPO的问题:
- 需要同时训练Actor Model(写答案)和Critic Model(打分)
- Critic Model需要在线训练,显存占用巨大
- 特别适合PRM(过程奖励),但成本高昂
GRPO的创新:
# 传统PPO:需要Actor + Critic两个模型
loss_ppo = actor_loss + critic_loss # 显存占用高
# GRPO:砍掉Critic,用组内平均分替代
def grpo_loss(responses, rewards):
# 1. 对每个问题采样一组输出 {o1, o2, ..., oG}
# 2. 用奖励模型对这些输出评分
# 3. 通过减去组平均值并除以组标准差进行标准化
normalized_rewards = (rewards - rewards.mean()) / rewards.std()
# 4. 使用标准化奖励作为优势函数
return policy_gradient_loss(responses, normalized_rewards)
核心优势:
- 节省50%显存(去掉Critic Model)
- 搭配ORM,形成极简训练流程
- 效果不逊于PPO,工程实现更简单
GRPO的变体演进:
| 变体 | 提出者 | 核心改进 |
|---|---|---|
| GSPO | Qwen | 引入分值加权,不只看是否高于平均分,还看绝对得分 |
| CISPO | MiniMax | 重要性采样,保留长COT中更重要的部分 |
三、记忆革命:治愈模型的"健忘症"
3.1 为什么记忆如此重要?
如果说TTC是2025年前半年最重要的模型变革,那记忆能力的提升就是后半年最重要的突破。这是唯一一个在GPT-5时代AGI得分还是0的分支能力——短板中的短板。
没有记忆能力的模型存在两个致命问题:
| 问题 | 具体表现 | 影响 |
|---|---|---|
| 无法自我学习 | 必须在算力工厂通过再训练学习 | 成本高昂,与日常使用脱节 |
| 无法个性化 | 无法记住用户偏好 | 每次对话都是"初次见面" |
3.2 三种记忆路径的进化
| 记忆方式 | 2024年状态 | 2025年突破 | 代表技术 |
|---|---|---|---|
| 上下文记忆 | 有限窗口(128K) | 2M-10M tokens | 注意力优化、Kimi Linear |
| RAG外挂记忆 | 简单检索 | 反思+进化 | ReMem、Evo-Memory |
| 参数内化记忆 | 不存在 | 架构级突破 | Titans、Nested Learning |
3.3 Titans:让模型拥有"活着的记忆"
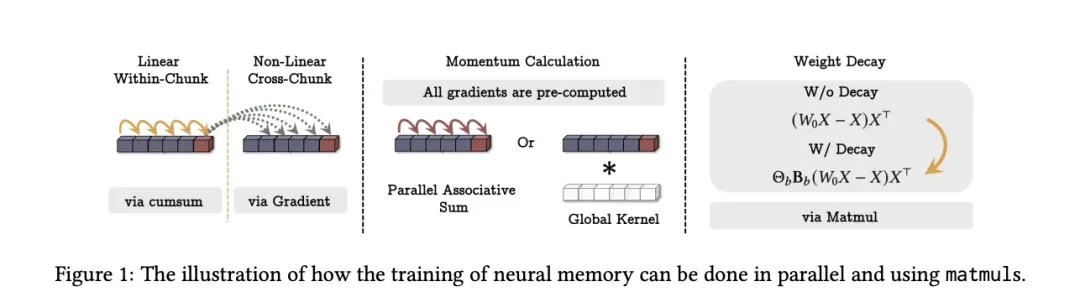
图:Google Titans架构的核心创新——神经记忆的并行训练机制。这是2025年记忆领域最重要的架构级突破。
图解说明:
图中展示了记忆更新的四个关键步骤,以及如何实现高效的并行计算:
| 步骤 | 机制 | 技术实现 | 作用 |
|---|---|---|---|
| Linear Within-Chunk | 线性层的块内处理 | 通过cumsum(累积求和)实现并行 | 处理局部信息 |
| Non-Linear Cross-Chunk | 非线性层的跨块处理 | 通过梯度计算实现关联记忆 | 建立长程依赖 |
| Momentum Calculation | 动量计算 | 通过矩阵乘法(Matmul)加速 | 稳定更新过程 |
| Weight Decay | 权重衰减 | 自动遗忘机制 | 清理不重要信息 |
关键创新:所有梯度都可以预计算(All gradients are pre-computed),使得测试时的参数更新变得高效可行。
Titans是Google Research 2025年的突破性工作,由姚班校友钟沛林参与完成。其核心创新是测试时参数更新:
传统Transformer:训练完成 → 参数冻结 → 推理(无状态)
Titans:训练完成 → 推理时持续更新参数 → 动态学习(有状态)
Titans的设计哲学:
英伟达将Test-Time Compute称为大模型的第三个Scaling Law。OpenAI把它用在推理(Reasoning),Google这次把它用在了记忆(Memory)。
核心机制详解:
| 机制 | 作用 | 技术实现 | 类比 |
|---|---|---|---|
| 惊奇度(Surprise Metric) | 决定是否存入记忆 | 基于输入数据与模型已有知识的差异(梯度大小) | 越新鲜越记得住 |
| 遗忘机制(Weight Decay) | 清理不重要信息 | 自动衰减旧记忆权重 | 避免记忆过载 |
| 门控融合 | 整合短期+长期记忆 | 记忆作为额外上下文输入给注意力机制 | 海马体+皮层协作 |
3.4 Nested Learning:分层更新的革命

图:Nested Learning的核心设计理念——模仿人脑的多频率神经振荡,实现真正的持续学习能力。
图解说明:
左侧 - 人脑的神经振荡:
展示了人脑的五种脑电波频率,各司其职:
| 脑电波类型 | 频率范围 | 主要功能 |
|---|---|---|
| Gamma波 | 30-150 Hz | 感知信息处理(最快) |
| Beta波 | 13-30 Hz | 主动思考、决策 |
| Alpha波 | 8-13 Hz | 放松、注意力调节(图中重点标注) |
| Theta波 | 4-8 Hz | 记忆编码、学习 |
| Delta波 | 0.5-4 Hz | 记忆巩固(最慢) |
右侧 - Nested Learning的架构设计:
- Uniform and Reusable Structure(统一可复用结构):架构分解为一组神经元(线性或局部深度MLP),每个神经元拥有自己的上下文流和目标函数
- Multi Time Scale Update(多时间尺度更新):
- Highest Frequency Neurons:每token更新,快速反应
- High Frequency Neurons:高频更新,短期记忆
- Mid Frequency Neurons:中频更新,中期记忆整合
- 低频层:约16M token更新一次,保证知识延续性
如果说Titans是在Transformer上加了记忆模块补丁,那Nested Learning就是更宏大的架构改变——它将整个模型的参数冻结都解放了。
核心思想:模仿人脑的多频率工作机制
Nested Learning的分层设计:
低频层(~16M tokens更新一次)→ 保证知识延续性,避免灾难性遗忘
↓
中频层 → 中期记忆整合
↓
高频层(每token更新)→ 快速反应,短期记忆
核心优势:
- 整个模型都是"活的",可以持续学习
- 成本比传统SFT/RL达成同等效果更低
- 真正的Personal AI成为可能
3.5 RAG的模型化升级:ReMem框架
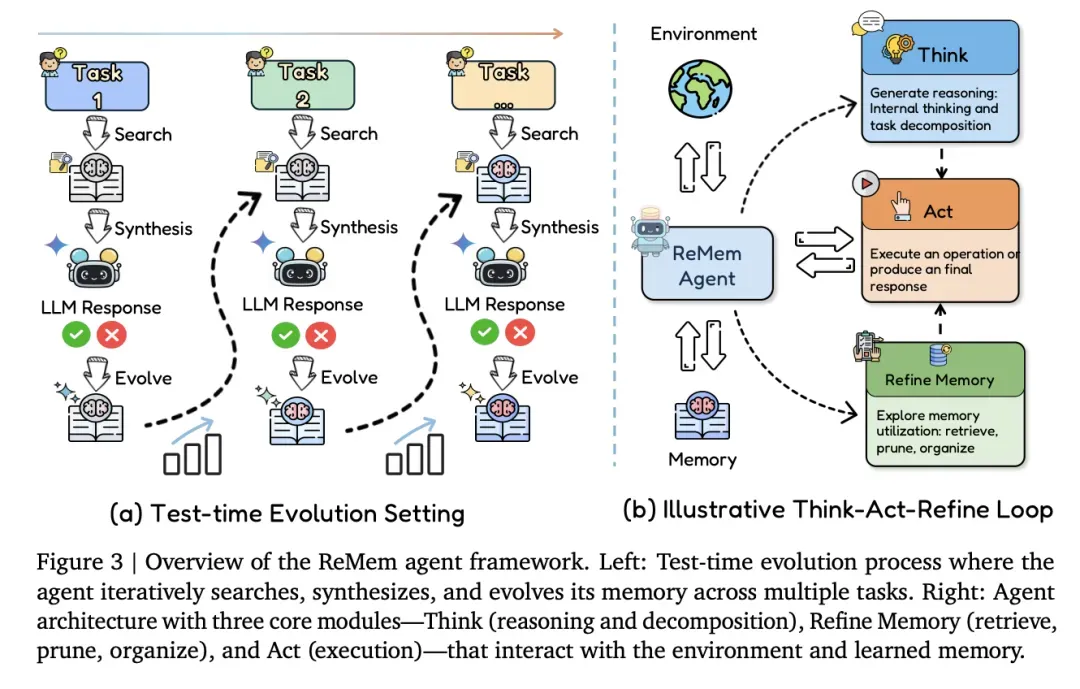
图:DeepMind提出的ReMem Agent框架——将RAG从"图书管理员"升级为具备反思与进化能力的智能系统。
图解说明:
左侧(a) - Test-time Evolution Setting(测试时进化设置):
Agent通过迭代搜索、综合和进化其记忆。每次与环境交互后,记忆都会得到更新和优化。
右侧(b) - Illustrative Think-Act-Refine Loop(思考-行动-精炼循环):
展示了Agent架构的三个核心模块:
| 模块 | 功能 | 具体操作 |
|---|---|---|
| Think(思考) | 推理和分解 | 对新上下文进行"内省",标记无效步骤和关键策略 |
| Act(行动) | 执行操作 | 在环境中执行具体动作,产生结果 |
| Refine Memory(精炼记忆) | 检索、修剪、组织 | 对记忆进行压缩和提纯,存储策略而非原始数据 |
之前,RAG被讥讽为"图书管理员"——只增不减,照单全收。但2025年,它发生了质的飞跃。
ReMem:Action-Think-Memory Refine全链路处理
DeepMind提出的ReMem引入了Agent式的记忆管理:
新上下文 → Think(内省标记:标记无效步骤和关键策略)
↓
Act(执行操作)
↓
Refine(记忆精炼:修剪冗余、重组便于检索)
↓
存储(定期清理 + 失败尝试作为负面教材)
效果:记忆不再是静止的录像,而是经过压缩和提纯的智慧。它存储的更多是策略,使模型能够调用过往成功经验,实现真正的经验复用。
3.6 灾难性遗忘的解决方案
在2025年之前,灾难性遗忘是参数记忆更新的最大敌人。模型用微调的方式做更新,很容易学了新的忘了旧的。但在2025年,学术界提出了多种解决方案:
| 方法 | 提出者 | 核心思想 | 效果 |
|---|---|---|---|
| Sparse Memory Finetuning | Meta | 在Transformer里加百万个独立槽位的空白内存层,筛选不重要槽位更新 | 仅11%旧知识遗忘(vs全量微调89%) |
| On-Policy Distillation (OPD) | Thinking Machines | 结合RL采样方式和SFT监督信号,学生在自己的"犯错分布"中学习 | 既不遗忘,又压缩成本 |
这两条路径,最终都导向了通过微调更新模型参数更稳定的路径。梦想中的"白天模型陪你说话,晚上你睡觉它微调更新参数",也许会变成可能。
四、空间智能:走出"柏拉图洞穴"
4.1 三大技术流派
另一个在Bengio AGI定义中2024年得分还是0的能力是视觉处理。2025年,这一能力在Sora 2、Veo 3等视频生成模型的爆发下得到了有效提升。
| 流派 | 代表 | 核心理念 | 优势 | 代表人物 |
|---|---|---|---|---|
| 自监督生成 | Sora 2/Veo 3/Genie 3 | 从视频学习物理规律 | 效果惊艳,涌现物理直觉 | OpenAI/Google |
| 符号主义 | World Labs/Marble | 3D几何+神经渲染 | 稳定可控,工业落地快 | 李飞飞 |
| 预测表征 | V-JEPA 2 | 预测即理解 | 提取因果本质 | Yann LeCun |
4.2 视频生成的Scaling Law突破
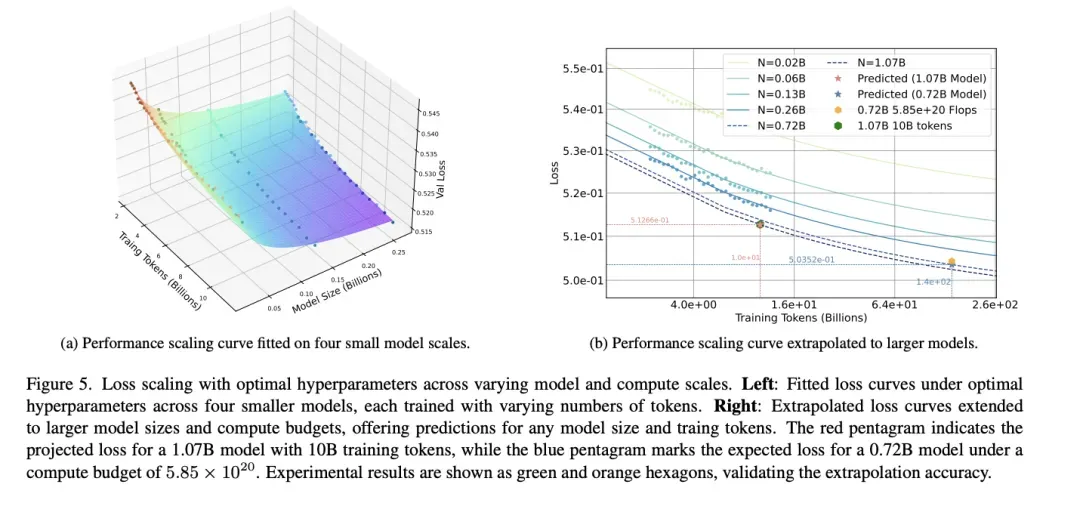
图:论文《Towards Precise Scaling Laws for Video Diffusion Transformers》的核心发现——DiT的Scaling Law与LLM存在显著差异。
图解说明:
左图(a) - 小规模模型拟合:
展示了四个不同规模模型(0.02B到0.72B参数)在不同训练token数下的损失曲线:
- 横轴:Training Tokens (Billions)
- 纵轴:Loss
- 不同颜色曲线代表不同模型规模(N=0.02B, 0.06B, 0.13B, 0.72B)
右图(b) - 外推预测验证:
- 红色五角星:预测的1.07B模型在10B tokens下的损失
- 蓝色五角星:预测的0.72B模型在5.85×10²⁰ FLOPs下的损失
- 绿色/橙色六边形:实验结果,验证了外推预测的准确性
关键发现:
DiT的Scaling Law ≠ LLM的Scaling Law
| 特性 | LLM | 视频扩散模型(DiT) |
|---|---|---|
| 超参数敏感度 | 相对稳定 | 对Batch Size和Learning Rate极度敏感 |
| 缩放定律 | 可直接套用 | 需要专门拟合,直接套用会失效 |
| 预测难度 | 较易 | 需要考虑更多因素 |
Veo 3成功的秘密:在对Veo 3团队的采访中,DeepMind员工表示,训练效果好主要是因为"打通了视频生成的Scaling Law"。
4.3 原生多模态的Scaling Law
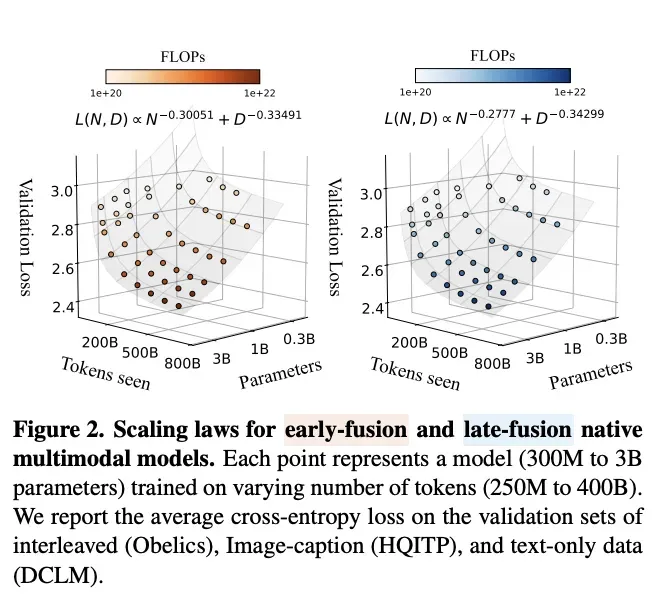
图:Apple论文《Scaling Laws for Native Multimodal Models》的核心发现——早期融合vs晚期融合的性能对比。
图解说明:
两张图展示了在不同FLOPs(10²⁰到10²²)下的损失曲线:
左图 - Early Fusion(早期融合/原生多模态):
- 拟合公式: L ( N , D ) ∝ N − 0.30051 ⋅ D − 0.33491 L(N,D) \propto N^{-0.30051} \cdot D^{-0.33491} L(N,D)∝N−0.30051⋅D−0.33491
- 参数利用率更高
右图 - Late Fusion(晚期融合/后台多模态):
- 拟合公式: L ( N , D ) ∝ N − 0.27777 ⋅ D − 0.34299 L(N,D) \propto N^{-0.27777} \cdot D^{-0.34299} L(N,D)∝N−0.27777⋅D−0.34299
- 样本效率高,但存在上限瓶颈
关键结论:
| 架构类型 | 样本效率 | 参数利用率 | 性能上限 |
|---|---|---|---|
| 晚期融合 | 高(加个视觉编码器就能变成视觉模型) | 低 | 存在瓶颈 |
| 早期融合 | 低(需要从头训练) | 高 | 上限更高 |
晚期融合架构相对于早期融合架构可能存在上限劣势。这意味着费力去训原生多模态是值得的。
4.4 V-JEPA 2:预测即理解
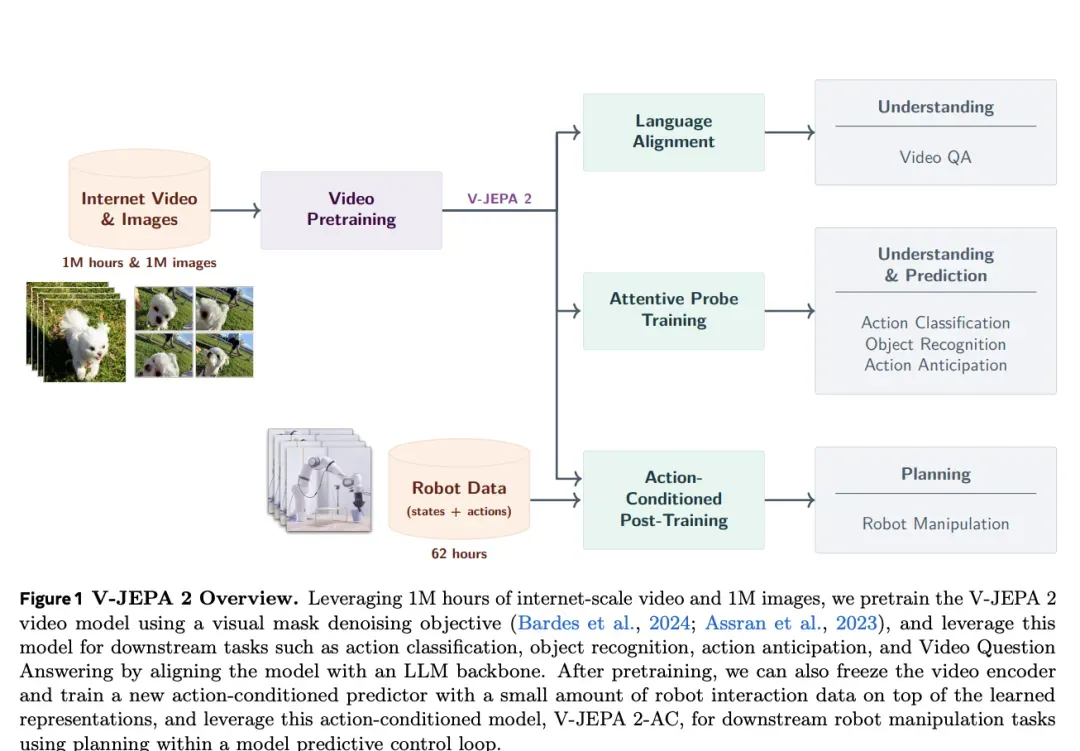
图:Meta V-JEPA 2的完整训练流程——首个基于视频训练的世界模型。
图解说明:
上半部分 - 预训练阶段:
- 输入:100万小时互联网视频 + 100万张图片
- 方法:视觉掩码去噪目标(Visual Mask Denoising Objective)
- 产出:具备Understanding(理解)和Prediction(预测)能力的V-JEPA 2模型
下半部分 - 后训练阶段:
| 训练方式 | 数据需求 | 输出能力 |
|---|---|---|
| Attentive Probe Training | 少量标注数据 | Action Classification(动作分类)、Object Recognition(物体识别)、Action Anticipation(动作预期) |
| Action-Conditioned Post-Training | 仅62小时机器人数据 | Robot Manipulation(机器人操控)、零样本控制 |
Yann LeCun的核心观点一直是:自回归生成只是鹦鹉,预测才能学习物理规则。
训练机制:
随机遮挡视频部分 → 要求模型预测被遮挡内容 → 提取因果本质
↓
教师编码器看到完整视频,生成目标特征向量
↓
模型被迫学习"可预测"的规律(重力、碰撞)
自动忽略"不可预测"的噪声(光斑、纹理)
V-JEPA 2-AC(动作条件化)变体:
已经能够预测"如果我执行这个动作,世界会变成什么样"——这是真正的因果推理能力。
性能对比:
- 运行速度比Nvidia Cosmos模型快30倍
- 仅用62小时机器人数据即可实现零样本控制
- 使用超过100万小时视频进行预训练
五、元学习:学会如何学习
5.1 Richard Sutton的批评
强化学习之父Richard Sutton在2025年批评当前LLM:
“只是被冻结的过去知识,缺乏在与环境交互中实时学习的能力。”
元学习的定义:不是把知识写死,而是把"获取知识的能力"写进代码里。
只有具备元学习能力的模型,才能:
- 遇到新问题时,通过很少几个样本调动"通用解题逻辑"
- 迅速归纳出规则,达成完整的动态泛化
- 应对无法预知的未来任务
5.2 Meta-RL:上下文中的策略适应
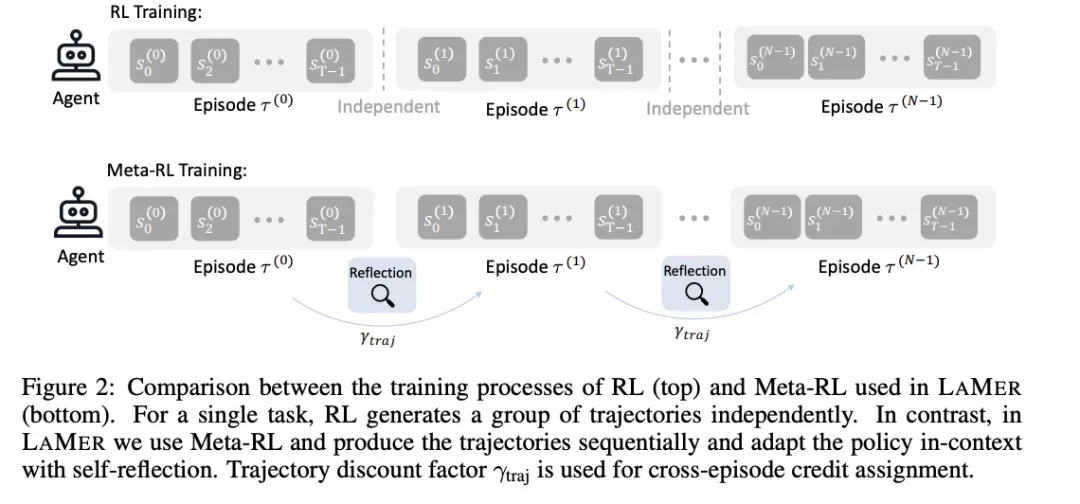
图:RL与Meta-RL训练过程的对比(LAMER框架)——从独立学习到上下文适应的范式转变。
图解说明:
上半部分 - 传统RL训练:
- 对单个任务独立生成一组轨迹(Trajectory)
- 各Episode之间没有关联
- Agent在每个Episode中独立行动,无法利用历史经验
下半部分 - Meta-RL训练(LAMER框架):
- 轨迹按顺序生成
- 每个Episode后都有Reflection(反思)阶段
- 通过上下文适应策略
- 关键创新:轨迹折扣因子 γ i , j \gamma_{i,j} γi,j 用于跨Episode的信用分配,使模型能够学习"如何学习"
关于模型是否具有隐式元学习能力,学术界存在长期争论:
| 观点 | 支持证据 | 代表研究 |
|---|---|---|
| ICL是隐式梯度下降 | 注意力机制数学形式类似GD | Anthropic、DeepMind |
| ICL只是模板匹配 | 只激活预训练知识,非真正学习 | 多项实证研究 |
LAMER框架的创新:通过Meta-RL让模型在上下文中进行策略适应,每个Episode后进行自我反思,形成新策略。这不是简单的模板匹配,而是真正的策略更新。
5.3 TTC与元学习:密集奖励的MRT方法
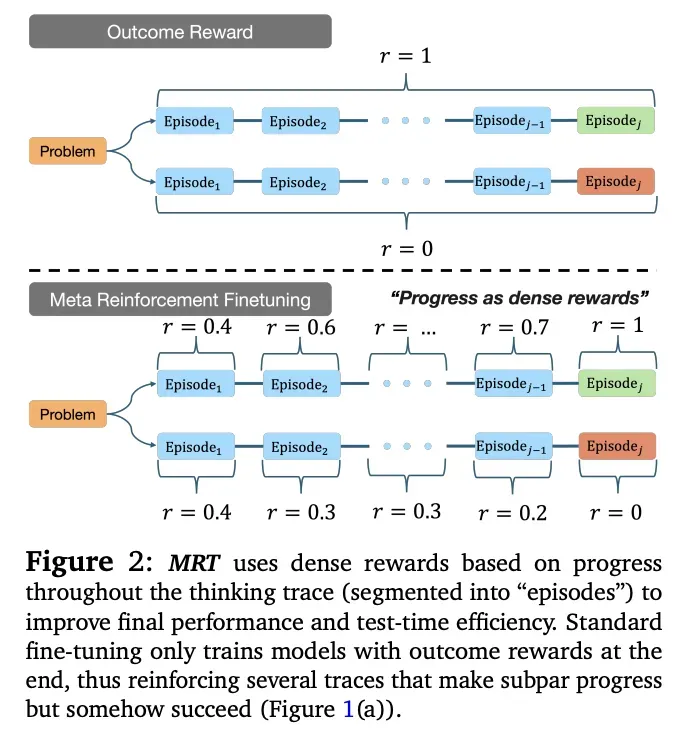
图:Meta Reinforcement Fine-Tuning (MRT) 的密集奖励机制——让模型学会"如何思考"。
图解说明:
上半部分 - Outcome Reward(结果奖励):
- 传统方法只在推理结束时给出结果奖励(r=1或r=0)
- 问题:很多"走了弯路但碰巧成功"的轨迹被强化
下半部分 - MRT的密集奖励:
- 将思维链分割为多个"Episode"
- 在每个节点计算进度奖励:r=0.4 → r=0.6 → r=… → r=0.7 → r=1
- 同时也能识别错误路径:r=0.4 → r=0.3 → r=0.3 → r=0.2 → r=0
- 实现累积遗憾最小化
TTC的到来为隐式元学习提供了新可能。卡耐基梅隆的研究《Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning》提出:
模型在推理时生成的长CoT,本质上是一个Agent在思维空间里探索最优路径。
累积遗憾最小化(Cumulative Regret)策略:
- 如果模型多思考了很多步,但答案置信度没有提升,这就是"遗憾"
- 通过RL引导模型减小遗憾发生的可能
- 让模型知道"遇到这种难度的题,应该调用多少算力、尝试几条路径"
这就是学习如何思考的元学习。
5.4 DiscoRL:AI自主发现学习算法
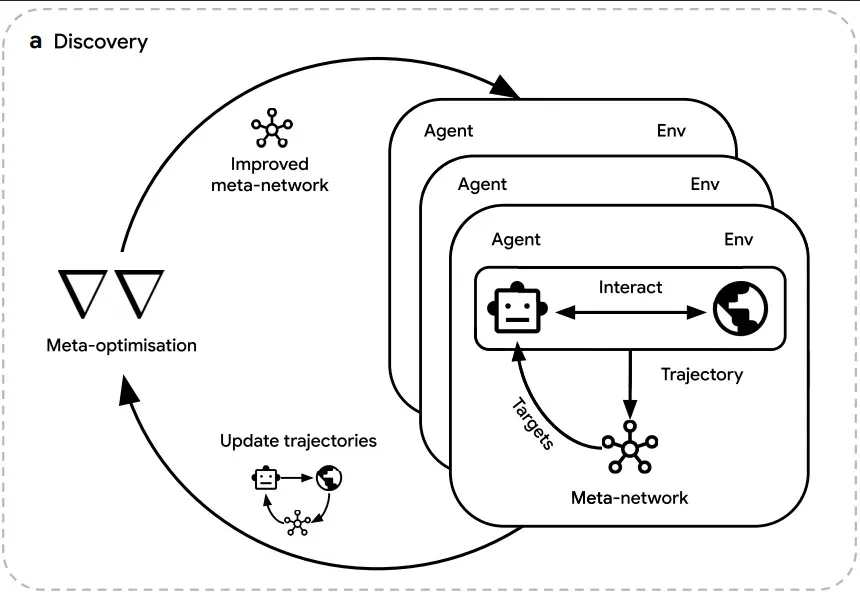
图:DeepMind发表在Nature上的DiscoRL的元优化循环——AI自主发现学习算法的里程碑。
图解说明:
双闭环架构:
| 循环 | 执行者 | 功能 | 输出 |
|---|---|---|---|
| 内部循环(Trajectory) | Agent | 在游戏环境中试错,生成轨迹 | Update trajectories |
| 外部循环(Meta-optimisation) | Meta-network | 观察轨迹表现,通过反向传播更新自身参数 | Improved meta-network |
Discovery(发现)过程:
- Meta-network不断优化自己的教学策略
- 产出改进的元网络,用于指导下一轮Agent训练
- 形成持续进化的闭环
DeepMind的DiscoRL是2025年元学习领域最惊人的突破,发表在Nature上。
双闭环架构:
内部循环:Agent在Atari等游戏环境中试错
↓
外部循环:Meta-network通过反向传播观察学生表现
↓
不断修正教学策略(更新学习算法的参数)
惊人发现:
- AI自主发现了策略转变:从"奖励最大化"转向"未来预测"
- 预测集中在关键时刻:重大事件(Aha moment)和改变方向之前
- 重新发现自举法:教师独立"重新发现"了RL中的Bootstrap方法
- Disco57算法击败人类设计:超越包括MuZero在内的顶级算法
- 惊人的泛化能力:在未见过的ProcGen和NetHack中依然表现出色
这证明了:AI可以通过递归抽象从纯粹经验中真正学习到"应该如何去探索"。
5.5 中训练:探索+反思
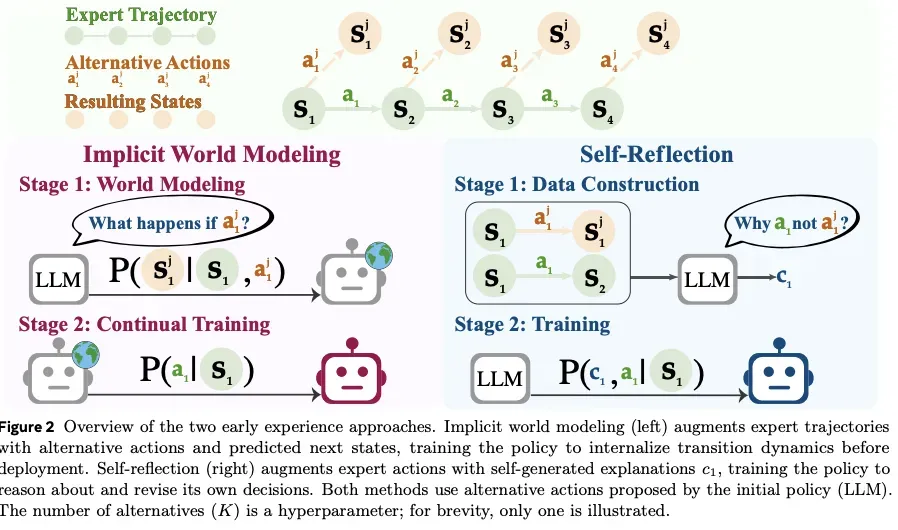
图:Meta论文《Agent Learning via Early Experience》提出的两种"中训练"方法——在预训练和RL之间增加主动探索阶段。
图解说明:
图中展示了Expert Trajectory(专家轨迹)的处理流程,包含状态序列 s 1 → s 2 → . . . → s n s_1 \to s_2 \to ... \to s_n s1→s2→...→sn 和对应的动作 u 1 , u 2 , . . . , u n u_1, u_2, ..., u_n u1,u2,...,un。
左侧 - Implicit World Modeling(隐式世界建模):
- Stage 1: World Modeling:在专家轨迹的每一步尝试备选动作 a 1 , a 2 , . . . a_1, a_2, ... a1,a2,...
- 预测下一状态: P ( s ′ ∣ s , a ) P(s'|s, a) P(s′∣s,a)
- Stage 2: Continual Training:训练策略内化转移动态 P ( a ∣ s ) P(a|s) P(a∣s)
右侧 - Self-Reflection(自反思):
- Stage 1: Data Construction:生成自己的经验,与专家动作对比
- 添加解释 e i e_i ei:反思"为什么专家做得好,我做的不好"
- 训练策略学会推理和修正自己的决策
Meta的《Agent Learning via Early Experience》提出在预训练和RL之间增加**"中训练"阶段**:
预训练:死记硬背专家操作(被动学习)
↓
中训练:自己瞎折腾 + 反思(主动探索)
↓
RL:稀缺奖励下的摸爬滚打(目标导向)
具体操作:
- 在专家演示的每一步,强制AI尝试几种不同的"备选动作"
- 记录这些动作会让环境变成什么样
- 对"为什么专家做得好,我做的不好"进行反思
效果:WebShop、ALFWorld成功率平均提升9.6%,泛化能力大幅增强。
核心洞察:这些方法都掌握了一个共性——“想有效探索,必须建立起一个对世界的预测”。这与Google《General Agents Need World Models》的结论不谋而合。
5.6 神经科学的启示:大脑的组合任务机制
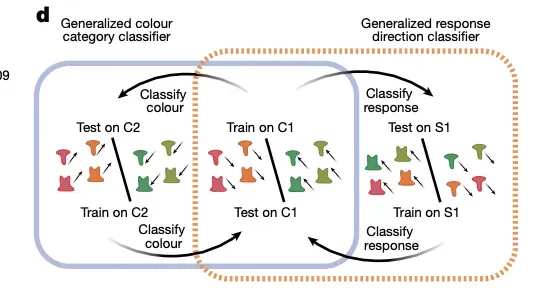
图:Nature论文《Building compositional tasks with shared neural subspaces》的核心发现——大脑如何通过"动态路由"执行新任务。
图解说明:
图中展示了大脑如何通过结构化、正交化的神经子空间来处理组合任务:
实验设计:
- Train on C1:训练颜色分类器(Classify colour)
- Train on St:训练响应方向分类器(Classify response direction)
- Test on C2:测试在新组合任务上的泛化能力
关键发现:
- Generalized colour category classifier:颜色类别分类器可以泛化
- Generalized response direction classifier:响应方向分类器可以泛化
- 大脑执行新任务不是靠修改神经元连接,而是靠"动态路由"机制重新连线不同神经子空间
2025年的神经科学研究让我们更理解人类是如何进行学习的:
- 大脑内部存在着结构化、正交化的神经子空间
- 这些子空间将"颜色"、“形状”、"动作"等概念从混沌的电信号中剥离出来,形成独立的、可复用的模块
- 执行新任务不是靠修改神经元连接(长出新脑细胞),而是靠"动态路由"机制重新连线
这启发了2025年涌现的很多对模型进行分区的尝试,包括记忆分区、快慢反应分区等。
六、工程优化:让智能更快更便宜
6.1 合成数据的突破:质量胜于数量
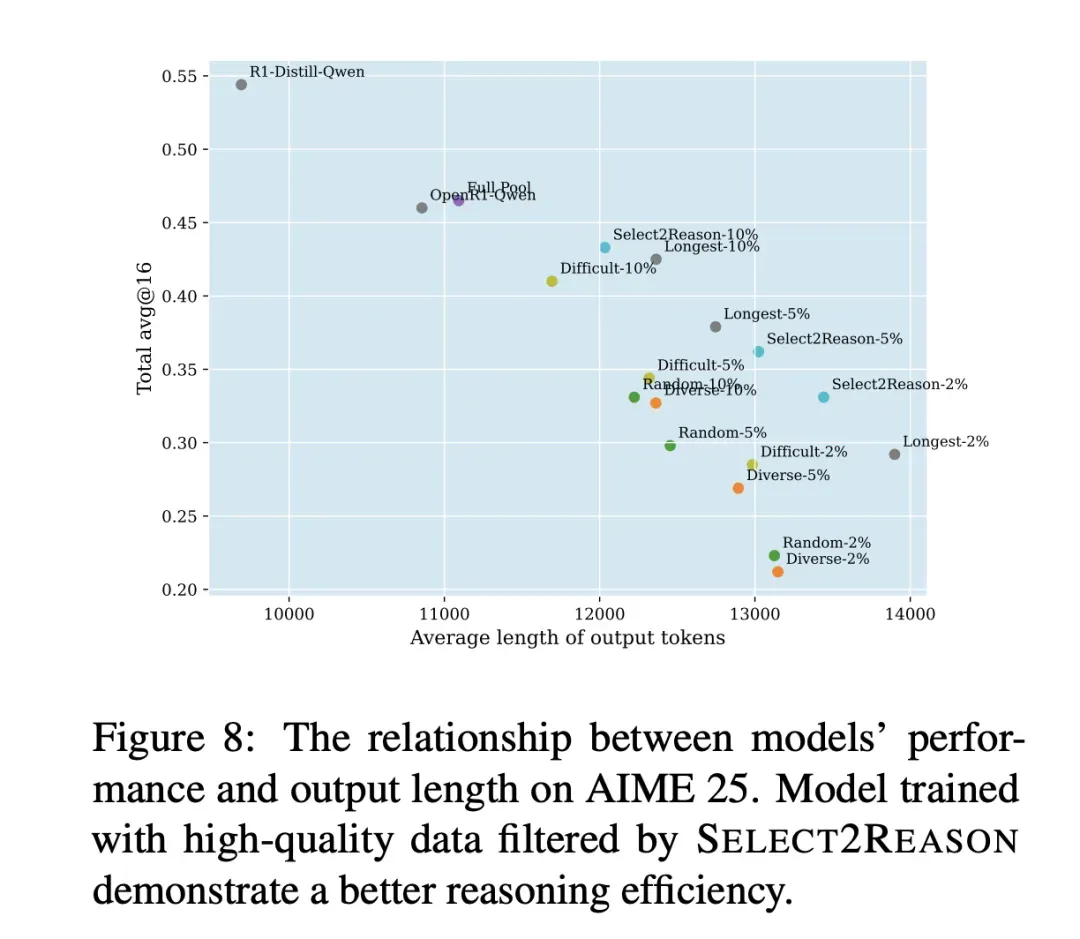
图:芝加哥大学Select2Reason实验的核心发现——“数据在精不在多”。
图解说明:
- 横轴:模型输出的平均token长度(Average length of output tokens)
- 纵轴:AIME 25测试的准确率(Accuracy)
- 数据点:不同数据筛选策略训练的模型
关键发现:
| 数据策略 | 数据量 | 准确率 | 输出长度 |
|---|---|---|---|
| Random-2% | 2% | ~0.25 | ~10000 |
| Diverse-2% | 2% | ~0.25 | ~10000 |
| Select2Reason-10% | 10% | ~0.50 | ~13000 |
| R1-DistillQwen | 100% | ~0.55 | ~14000 |
结论:仅筛选前10%推理路径最长、最复杂的样本(Select2Reason-10%)进行训练,效果就匹配甚至超越全量数据集。这证明了长COT合成数据是翻越数据墙的最有希望方式。
| 问题 | 解决方案 | 关键论文 |
|---|---|---|
| 数据枯竭 | 长COT合成数据 | DeepSeek R1 |
| Model Collapse | 自我验证过滤 | NeurIPS 2025 |
| 多样性丧失 | 生产知识空白区 | LLM-as-a-Judge |
Model Collapse的解决:南洋科技大学在NeurIPS 2025的论文中建立了自我验证机制:
- 生成合成数据后,模型计算内部置信度分数
- 低于阈值的数据被丢弃
- 只要模型校准误差在一定界限内,可以在完全合成数据体制下持续训练
6.2 蒸馏技术的进化
MoE蒸馏:让每个专家都发挥作用
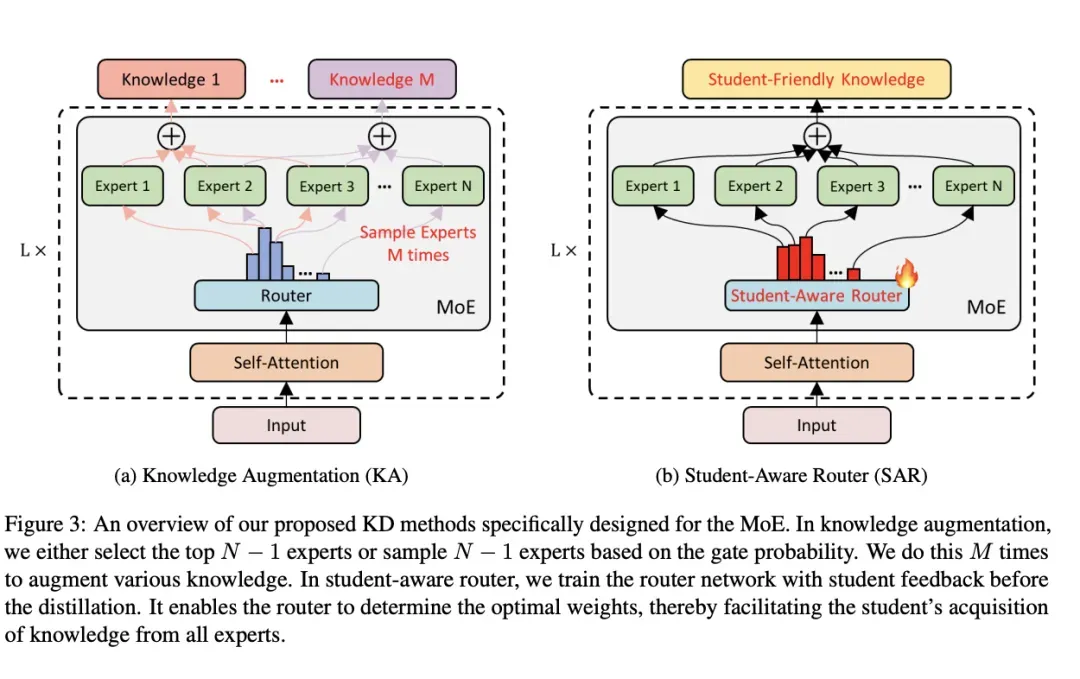
图:《Every Expert Matters》提出的MoE特化蒸馏方案——让学生接触"暗知识"。
图解说明:
左侧(a) - Knowledge Augmentation(知识增强):
- 传统方法:只选择Top-K专家,忽略其他专家的知识
- 新方法:通过两种策略增强知识多样性
- 选择Top N-1专家:保留次优专家的知识
- 基于门控概率采样N-1专家:随机探索不同专家组合
- 重复M次:增强多样化知识覆盖
右侧(b) - Student-Aware Router(学生感知路由):
- 在蒸馏前用学生反馈训练路由网络
- 让路由决策考虑学生模型的接受能力
传统蒸馏忽略了Non-activated Experts所蕴含的知识。新方法通过多次采样或强制激活策略,让学生模型学习到不同专家对同一问题的不同视角。
长COT蒸馏:Merge-of-Thought
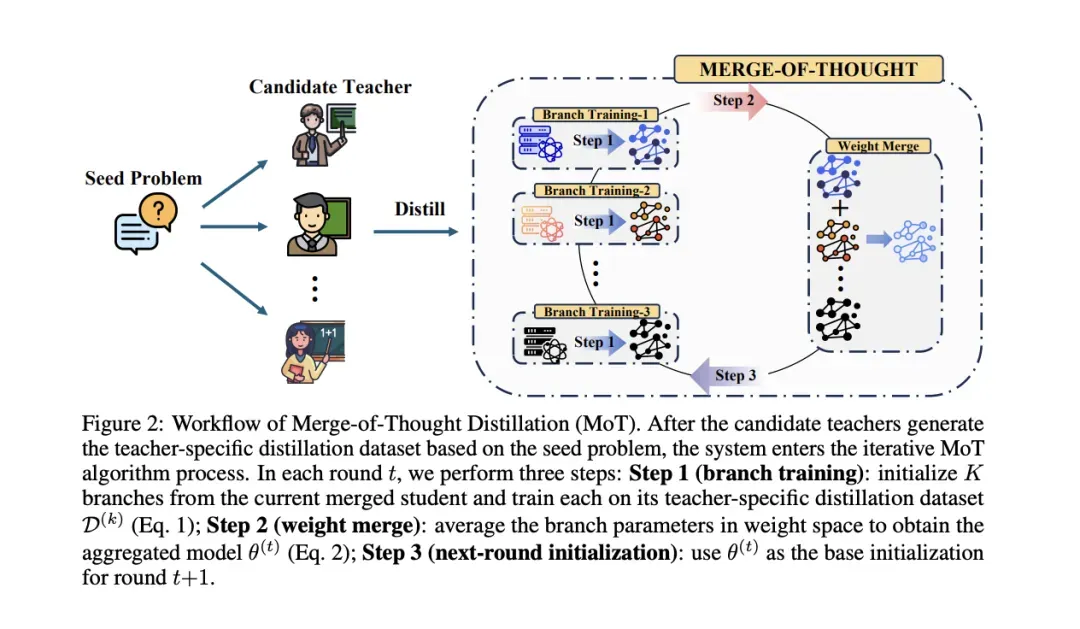
图:Merge-of-Thought (MoT) 蒸馏框架的工作流程——通过共识去噪提取多教师的"公约数"。
图解说明:
整体流程:
- Candidate Teachers:多个候选教师模型
- Seed Problem:种子问题作为输入
- Distill:各教师基于种子问题生成蒸馏数据集
迭代MoT算法:
| 步骤 | 操作 | 目的 |
|---|---|---|
| Step 1: Branch Training | 从当前合并学生初始化K个分支,各自在教师数据上训练 | 学习不同教师的推理风格 |
| Step 2: Weight Merge | 平均分支参数得到聚合模型 θ ( t ) \theta^{(t)} θ(t) | 提取共识推理逻辑 |
| Step 3: Next-round Initialization | 用 θ ( t ) \theta^{(t)} θ(t) 作为下一轮基础 | 迭代优化 |
**Merge-of-Thought(MoT)**通过共识去噪,提取多个教师的"公约数"推理逻辑:
- 不同教师的表达各异,但核心推理逻辑相似
- 在高维参数空间中提取所有教师的"公约数"
- 避免长序列推理的误差累积
6.3 注意力机制的变革
Kimi Linear的突破
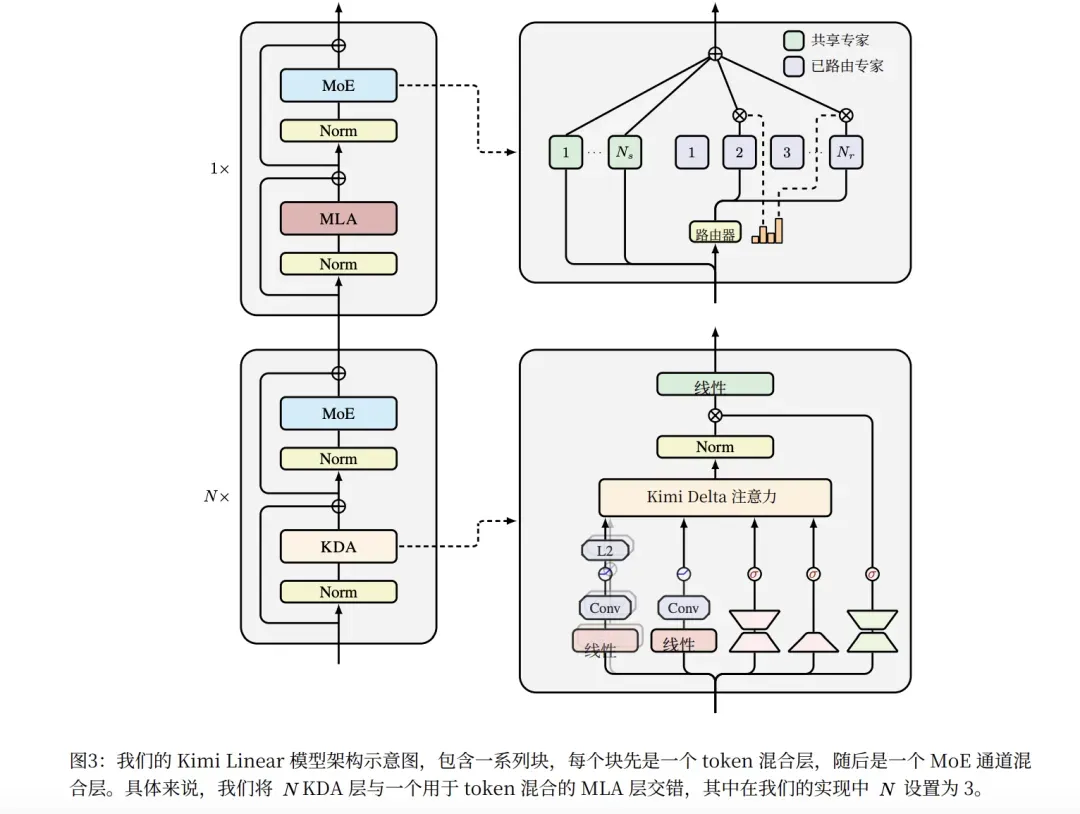
图:Kimi Linear的混合架构设计——线性注意力从备胎转为主力。
图解说明:
图中展示了Kimi Linear的核心设计理念:
- 3:1混合架构:3层线性注意力穿插1层MLA
- token处理流程:每个token经过线性注意力层处理,定期通过MLA层进行全局信息整合
- MoE集成:结合混合专家架构进一步提升效率
MLA(Multi-Head Latent Attention)的普及:
DeepSeek V3采用的MLA架构,通过低秩联合压缩技术:
| 模型 | 每token KV Cache |
|---|---|
| DeepSeek-V3 (MLA) | 70.272KB |
| Qwen-2.5 72B (GQA) | 327.680KB |
| LLaMA-3.1 405B | 516.096KB |
Kimi Linear的关键突破:
| 指标 | 性能 |
|---|---|
| 架构 | 3:1混合(3层线性 + 1层MLA) |
| KV缓存节省 | 75% |
| RULER测试(1M上下文) | 94.8分 |
| 吞吐量提升 | 全注意力的6.3倍 |
| 位置编码 | 无需RoPE,内在学习位置信息 |
连续概念空间:CALM
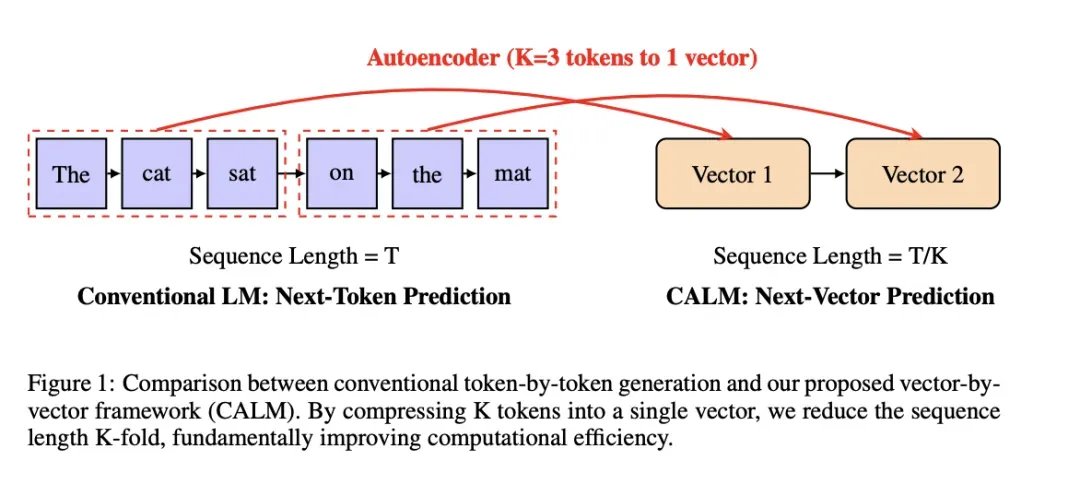
图:腾讯CALM(Continuous Autoregressive Language Models)的核心创新——从token预测到向量预测。
图解说明:
左侧 - Conventional LM(传统语言模型):
- 序列长度 = T
- 逐token预测:每次生成一个离散token
右侧 - CALM(连续自回归语言模型):
- 序列长度 = T/K(压缩K倍)
- 逐向量预测:每次生成一个连续向量
Autoencoder(自编码器):
- 将K个token(如K=3)压缩为1个连续向量
- 从根本上提升计算效率
Meta的LCM(Large Concept Models)和腾讯的CALM将多个Token压缩为连续向量:
- 从"预测下一个词"转变为"预测下一个概念向量"
- 一次推理步骤生成相当于原来4倍的信息量
七、2026展望:三大确定性方向
7.1 记忆的工程化落地
从理论到产品的周期约2年。以TTC革命为例,2024年末的GPT o1实际上在2022年左右已在Ilya脑海中成型。
2025年,三条记忆路径(RAG、微调、架构)都已小规模验证。2026年有望:
- 成为主流模型的标配
- 在一个成功架构(如DeepSeek R1)的推动下完成范式转换
- 让Mem0、Second Me等记忆系统有更好的落地体验
7.2 混合架构的成熟
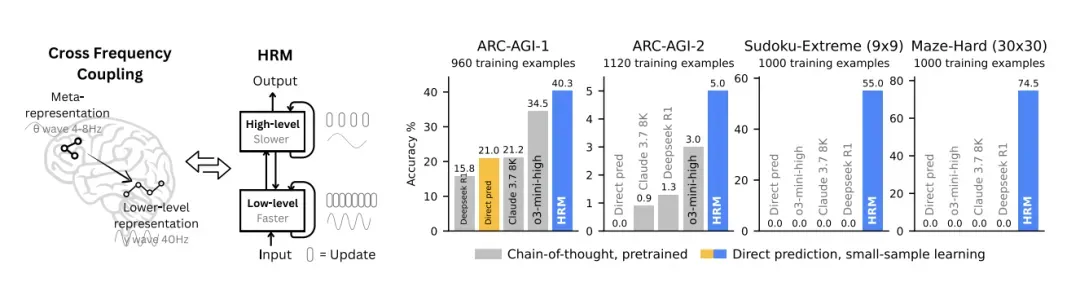
图:分层推理架构的实验验证——小样本学习超越长思维链预训练模型。
图解说明:
图中展示了在四个任务上的对比实验:
| 任务 | 训练样本数 | 对比方法 |
|---|---|---|
| ARC-AGI-1 | 960 | Chain-of-thought vs Direct prediction |
| ARC-AGI-2 | 1120 | 预训练LM vs 小样本学习 |
| Sudoku-Extreme (9x9) | 1000 | - |
| Maze-Hard (30x30) | 1000 | - |
架构设计:
- Meta representation(元表征):高层抽象表示
- Lower-level representation(底层表征):具体特征表示
- Gross Frequency Coupling Output(频率耦合输出):不同层级的信息整合
关键发现:通过分层设计,小样本学习可以超越长思维链预训练模型的效果。
分区、分层、多功能层的趋势将加速:
未来架构 = 记忆层(Titans) + 推理层 + 快速反应层
这种混合架构更符合人脑运作模式,可能随着神经科学和符号主义的回潮产生更多尝试。
7.3 自进化的早期探索
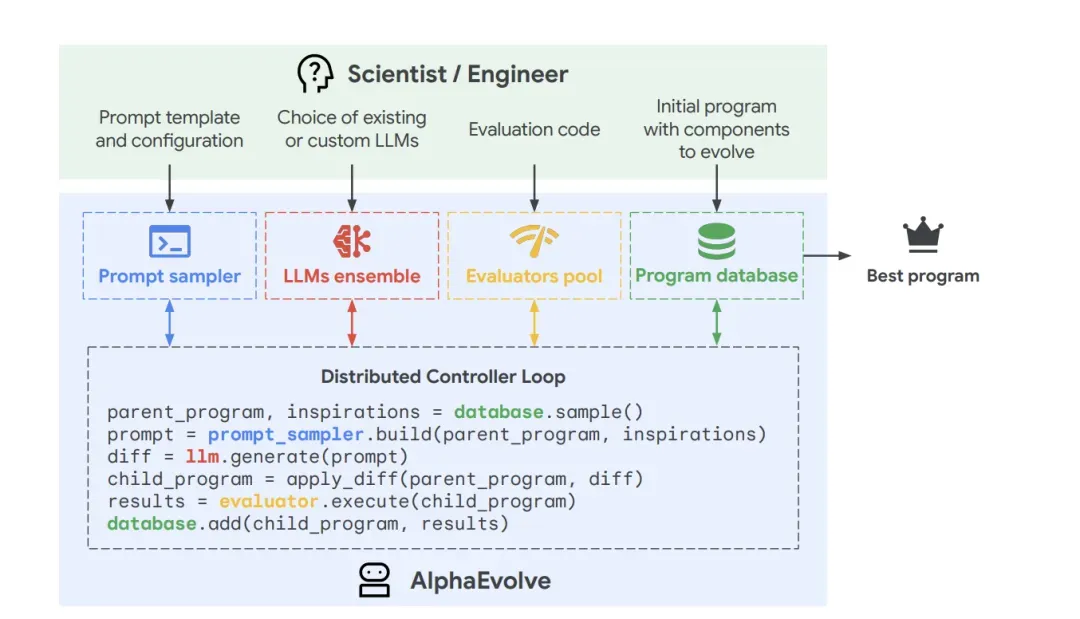
图:Google DeepMind的AlphaEvolve程序进化框架——AI发现优于人类设计的算法。
图解说明:
输入(科学家/工程师提供):
- Initial program(初始程序)
- Prompt template(提示模板)
- Evaluation code(评估代码)
- Components to evolve(待进化组件)
分布式控制器循环:
parent_program, inspirations = database.sample() # 从程序数据库采样
prompt = prompt_sampler.build(parent_program, inspirations) # 构建提示
diff = llm.generate(prompt) # LLM集成生成差异
child_program = apply_diff(parent_program, diff) # 应用差异产生子程序
results = evaluator.execute(child_program) # 评估器验证正确性和效率
database.add(child_program, results) # 优秀程序入库
LLM集成:
- Gemini Flash:追求速度
- Gemini Pro:追求深度
AlphaEvolve已经证明AI可以发现优于人类设计的算法:
- 解决了300年历史的"亲吻数问题"
- 改进了1969年的经典Strassen矩阵乘法算法
- 仅用48次标量乘法完成4x4复杂矩阵乘法
但真正的自进化还需要记忆、合成数据、元学习三者的深度融合。2026年,这个方向必然会产生更多可能性。
总结:从"暴力美学"到"精细工程"
2025年的AI发展可以用一句话概括:
模型不仅要博学,更要懂思考、能记住、会学习。
| 能力 | 关键突破 | 技术路径 | 核心论文 |
|---|---|---|---|
| 思考 | Test-Time Compute | RLVR + GRPO | ScaleRL, DeepSeek R1 |
| 记住 | 参数内化记忆 | Titans + Nested Learning | Titans, MIRAS |
| 学习 | 元学习 | DiscoRL + 中训练 | DiscoRL (Nature) |
| 理解世界 | 空间智能 | World Models + V-JEPA | Genie 3, V-JEPA 2 |
2026年,这些技术将从实验室走向产品,真正改变我们与AI交互的方式。
最后的思考:
正如论文中引用的爱因斯坦名言:
“我们无法用创造问题时的思维来解决问题。”
2025年的技术突破正是这种思维转变的体现——不再是简单地堆砌参数,而是从根本上重新思考机器学习模型应该如何设计。
参考论文
TTC革命
- ScaleRL - RL的Sigmoid Scaling Law
- GSPO - Qwen的分值加权优化
- MiniMax-M1 - CISPO算法
记忆能力
- Titans - 测试时记忆学习
- Nested Learning - 多频率分层更新
- MIRAS - 统一记忆框架
- Evo-Memory - RAG进化
- Sparse Memory Finetuning - 稀疏记忆微调
空间智能
- Video DiT Scaling Laws - 视频扩散Scaling Law
- VAR - 视觉自回归
- V-JEPA 2 - 预测式世界表征
- Native Multimodal Scaling - 原生多模态
- SVG-T2I - 无VAE潜在扩散
元学习
- DiscoRL - 自主发现RL算法
- Meta-RL for Language Agents - 语言Agent元学习
- Meta Reinforcement Fine-Tuning - TTC优化
- Agent Learning via Early Experience - 中训练
工程优化
- Every Expert Matters - MoE蒸馏
- Merge-of-Thought - 思维融合蒸馏
- Kimi Linear - 线性注意力
- LCM - 大型概念模型
- CALM - 连续自回归
本文基于对2025年100+篇顶会论文的系统梳理,力求以专业视角呈现AI技术的真实进展。如有疏漏,欢迎指正。
如果觉得有帮助,欢迎点赞、转发、在看三连!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)