MeNTi: Bridging Medical Calculator and LLM Agent with Nested Tool Calling
将大语言模型(Large Language Models, LLMs)与外部工具相结合,为复杂任务提供了一种极具潜力的解决范式。然而,在某些特定下游任务中,仅依赖工具调用仍难以应对真实世界的复杂性。本文聚焦于医疗计算这一典型下游任务——医疗计算器(medical calculators),该任务通常通过标准化测试对患者健康风险进行量化评估。我们提出 MeNTi,一种面向医疗计算场景的智能体框架,通
NAACL 2025(NLP 四大会议之一:ACL / EMNLP / COLING / NAACL)
📅 Call for Papers:预计 10 月左右

文章目录
Abstract
将大语言模型(Large Language Models, LLMs)与外部工具相结合,为复杂任务提供了一种极具潜力的解决范式。然而,在某些特定下游任务中,仅依赖工具调用仍难以应对真实世界的复杂性。
本文聚焦于医疗计算这一典型下游任务——医疗计算器(medical calculators),该任务通常通过标准化测试对患者健康风险进行量化评估。我们提出 MeNTi,一种面向医疗计算场景的智能体框架,通过引入:
元工具机制(Meta-Tool)
嵌套调用机制(Nested Calling Mechanism)
系统性增强 LLM 对复杂医疗工具的理解与使用能力。
具体而言,MeNTi 能够实现 复杂工具选择、参数槽位填充以及内嵌工具调用,有效应对计算器选择、单位换算和多字段输入等真实临床挑战。
为系统评估 LLM 在该类任务中的能力,我们构建了 CalcQA 基准数据集。该数据集由专业医生设计,包含 100 个病例–计算器配对,并配套 281 个医疗计算器工具。实验结果表明,MeNTi 在多个指标上显著提升了模型性能,为 LLM 在高要求医疗场景中的落地应用提供了新方向。
1. 方法动机与关键机制
1.1 Meta-Tool 机制:解决“工具数量爆炸”问题
近期研究表明,将 LLM 与大规模工具集相结合,能够显著提升推理与求解能力。同时,针对具体场景设计专用工具 已成为提升模型性能的重要路径。
然而,在真实医疗实践中,医疗计算器仍面临以下挑战:
数量庞大:目前临床中已有超过 700 种 医疗计算器,工具选择成本极高
专业性强:每个计算器均针对特定疾病或临床情境,涉及复杂医学知识与内嵌规则
持续更新:新计算器不断发布,带来持续的工具维护与学习成本
为此,我们引入 Meta-Tool 机制,其目标是在庞大的工具库中实现 标准化、可扩展且可解释的工具选择流程。该机制明确了医疗计算器场景中工具调用的触发条件,并显著优化了工具筛选与决策过程。

示例说明:
患者:确诊冠心病
任务:评估其发生心肌梗死的风险
计算器选择:硬性冠心病 Framingham 风险评分
结果:10 年内心肌梗死或死亡风险为 83.6%
该结果表明患者心血管风险极高,可为后续治疗方案提供量化依据。
1.2 Nested Calling 机制:让工具“会调用工具”
即使正确选择了计算器,其在实际应用中仍面临诸多挑战,主要包括:
从冗长病历中定位关键字段
多参数槽位的准确填充
医疗单位之间的自动换算
例如,LLM 可能会混淆 风湿性心脏病 与 充血性心力衰竭,或需要将 8.3 mmol/L 的总胆固醇转换为 320.92 mg/dL。
为此,我们引入 嵌套调用机制(Nested Calling Mechanism),允许模型在执行某一计算器时,动态调用其他辅助工具(如单位换算器、信息抽取工具等),从而完成复杂的链式推理与执行。
1.3 CalcQA 基准数据集
我们构建了 CalcQA,以系统评估 LLM 在医疗计算器场景中的能力:
覆盖 44 种 临床常用医疗计算器
系统整理 237 种 常见医疗单位的换算规则
基于真实临床场景设计,强调端到端执行能力
1.4 主要贡献总结
本文的主要贡献如下:
提出 CalcQA 基准测试:
一个用于评估 LLM 在医疗计算器场景中能力的新基准,包含 100 个真实病例–计算器配对 与 281 个医疗计算器工具。
提出 MeNTi 智能体框架:
通过 Meta-Tool + Nested Calling 机制,显著扩展了 LLM 在真实医疗计算任务中的能力。
首次实现端到端医疗计算流程:
MeNTi 是首个在真实医疗场景中实现 计算器选择 → 参数填充 → 单位换算 → 计算执行 全流程的 LLM 框架,并取得了显著性能提升。
2. 相关工作
2.1 医疗领域 LLM 应用
近期研究主要集中于利用真实或合成医疗数据提升 LLM 在医疗场景中的表现,例如:
PMC-LLaMA(Wu et al., 2024):基于 490 万篇医学文献进行预训练
ChatDoctor(Yunxiang et al., 2023):融合真实医患对话数据
LMAMT(Wang et al., 2023):结合 RAG 架构与权威医学教材
Self-BioRAG(Jeong et al., 2024):引入领域检索器与指令集
2.2 智能体与工具使用
LATM(Cai et al., 2023):通过代码生成方式构建工具
CRAFT(Yuan et al., 2023):从数据中学习工具创建策略
AnyTool(Du et al., 2024):引入自我反思机制指导工具使用流程
3. 方法概述
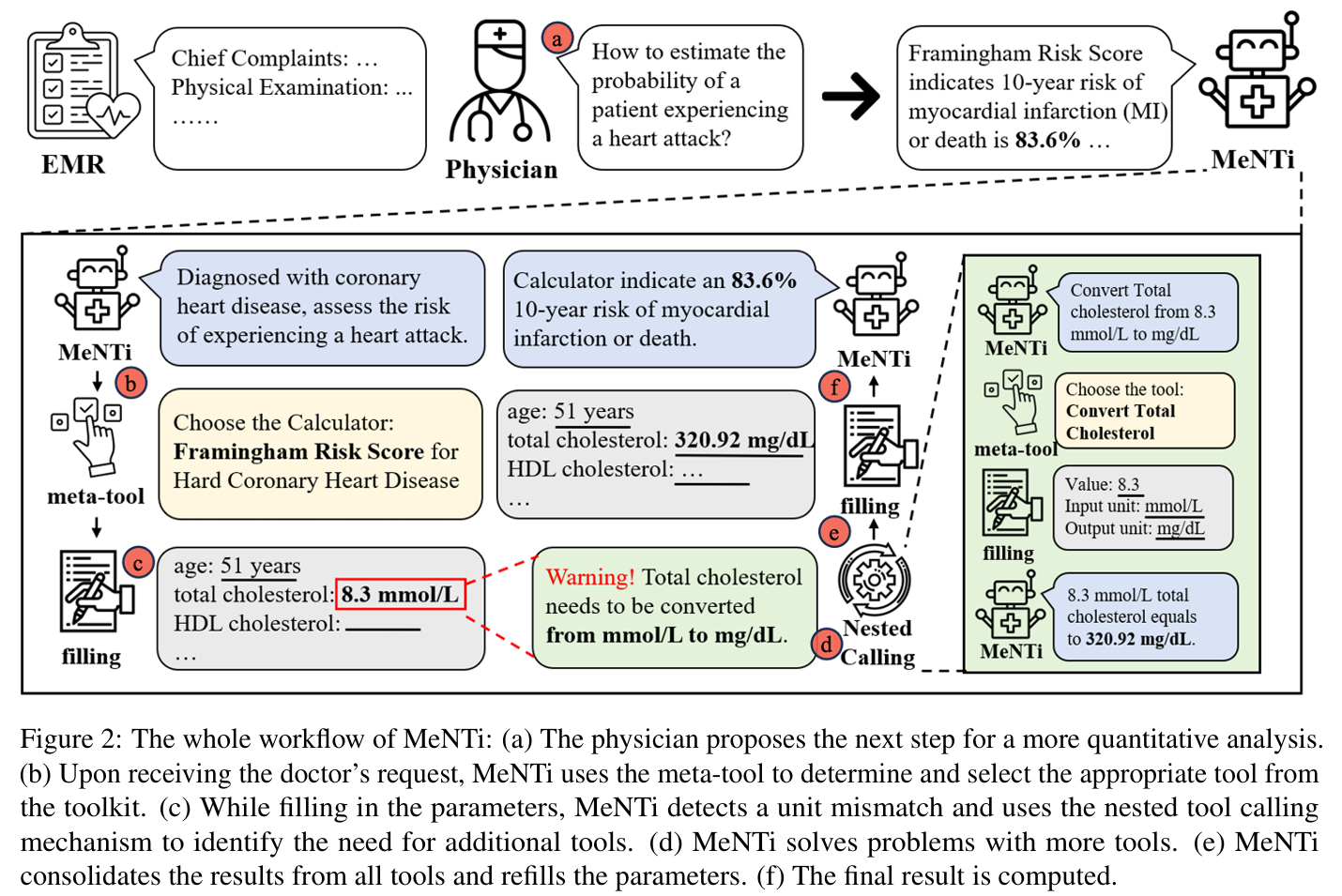
图 2:MeNTi 的整体工作流程
(a) 医生提出量化分析需求
(b) Meta-Tool 从工具库中筛选合适计算器
© 检测到单位不匹配,触发嵌套调用
(d) 调用辅助工具完成中间处理
(e) 汇总工具输出并填充参数
(f) 生成最终计算结果
4. 实验设置
我们从以下四个维度评估模型性能:
计算器选择准确率(CSA):衡量模型是否正确选择计算器
槽位填充准确率(SFA):衡量参数填充的准确性
单位转换准确率(UCA):衡量模型处理单位换算的能力
计算器计算准确率(CCA):衡量端到端执行的正确性
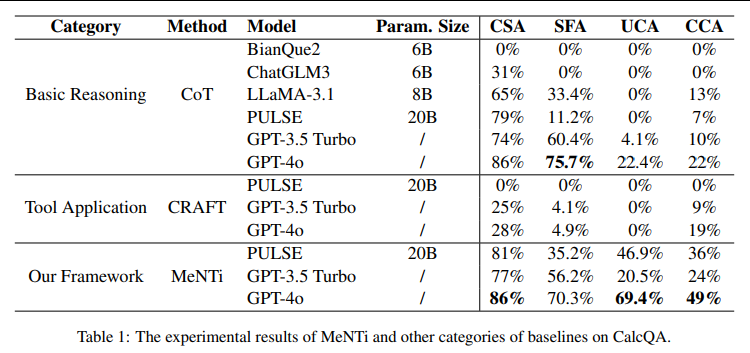
尽管 MeNTi 在医疗计算器场景中取得了显著性能提升,仍存在以下局限:
冗长医疗文本对轻量级骨干模型仍具有挑战
CalcQA 当前仅包含 100 个实例,规模仍有待扩展
工具构建成本较高,限制了跨任务泛化能力的系统评估

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)