显卡架构深度解析与AI时代选型指南:从深度学习到具身智能的全方位剖析
本文系统分析了GPU架构演进及其在AI领域的应用。从Pascal到Blackwell架构,NVIDIA GPU逐步从图形处理器发展为AI专用加速器,重点优化了深度学习训练和推理性能。文章详细对比了RTX 40系列和数据中心级GPU的关键参数,并探讨了具身智能等新兴领域对GPU的特殊需求,为不同应用场景提供了专业选型建议。随着AI模型规模扩大,NVLink多GPU互联技术成为大规模训练的关键支撑。
0. 引言
在人工智能技术飞速发展的今天,GPU已经从传统的图形渲染工具彻底转变为AI计算的核心驱动力。从ChatGPT等大语言模型的训练,到自动驾驶汽车的实时决策,再到具身智能机器人的多模态感知,GPU的计算能力直接决定了AI应用的性能上限。
随着AI模型规模的指数级增长和应用场景的不断拓展,GPU的选型已经成为一个复杂的技术决策问题。不同的AI工作负载对GPU的要求截然不同:深度学习训练需要大显存和高精度计算,具身智能要求低延迟和实时推理,而边缘部署则更关注功耗和成本效益。
本文将从技术架构的底层原理出发,深入分析当前主流GPU架构的设计理念和性能特点,并结合实际应用场景提供专业的选型指导。我们将特别关注NVIDIA Ada Lovelace和AMD RDNA3两大主流架构,深度剖析RTX 50系列的技术问题,并为不同预算和需求的用户提供详细的购买建议。

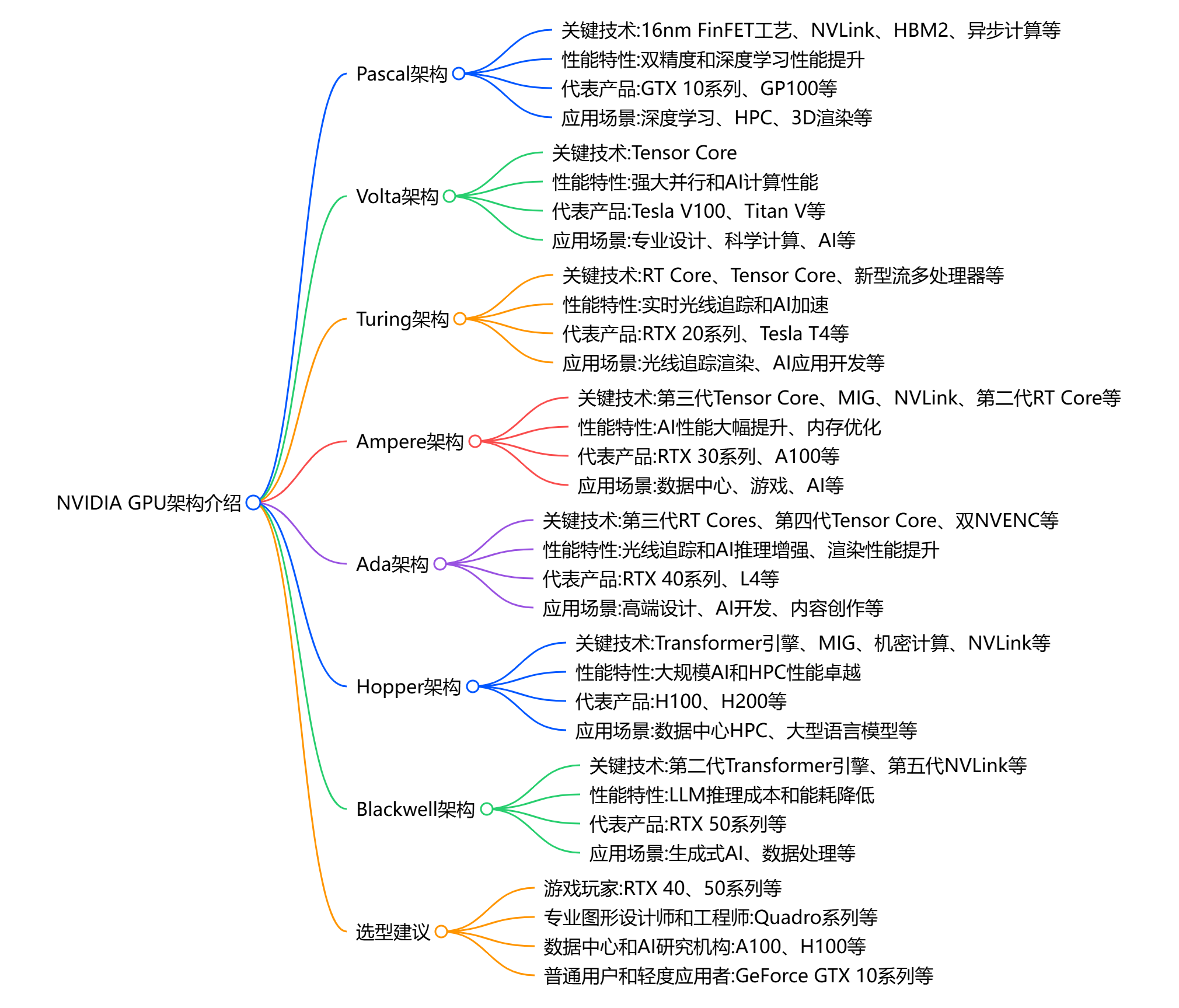
1. NVIDIA GPU架构演进详解
1.1 历代架构技术发展轨迹
NVIDIA GPU架构的发展史代表了整个GPU行业从图形专用处理器向AI通用加速器的演进过程。每一代架构都针对当时的技术挑战和应用需求进行了专门优化,形成了清晰的技术发展脉络。
Pascal架构(2016年):现代GPU架构奠基 Pascal架构采用台积电16nm FinFET工艺,标志着GPU进入现代高能效时代。该架构首次引入了NVIDIA NVLink技术,为多GPU系统提供了高带宽互联方案。Pascal架构在科学计算和深度学习领域表现卓越,成为GPU加速AI计算的重要里程碑。核心创新包括统一内存架构改进、更高的计算精度支持和显著提升的能效比。
Volta架构(2017年):AI专用计算元年 Volta架构的推出标志着GPU正式进入AI专用加速时代。该架构最重要的创新是引入了第一代Tensor Core,专门针对深度学习中的混合精度矩阵运算进行优化。Volta采用台积电12nm工艺,在能效比方面实现了显著提升。架构中的HBM2高带宽内存为大规模AI模型提供了充足的数据传输能力,奠定了现代AI训练平台的硬件基础。
Turing架构(2018年):实时光追与AI推理 Turing架构是GPU历史上的一个重要转折点,首次将实时光线追踪技术引入消费级产品。该架构包含第一代RT Core和改进的第二代Tensor Core,实现了图形渲染和AI计算的完美结合。Turing还引入了DLSS 1.0技术,利用AI技术提升游戏性能。在AI推理方面,Turing架构的INT8和INT4精度支持为边缘部署提供了强大的计算能力。
Ampere架构(2020年):大规模AI训练平台 Ampere架构专门针对大规模AI训练进行了优化,引入了第三代Tensor Core,支持更多精度格式包括BF16、TF32等。该架构最大的创新是多实例GPU(MIG)技术,允许单个GPU被分割为多个独立的GPU实例,显著提升了数据中心的资源利用率。Ampere还改进了NVLink技术,提供了更高的多GPU通信带宽,为超大规模模型训练提供了硬件支撑。
Ada Lovelace架构(2022年):AI推理优化 Ada Lovelace代表了NVIDIA在AI推理领域的最新突破,采用台积电4nm工艺实现了显著的能效提升。第四代Tensor Core支持FP8精度格式,为AI推理提供了前所未有的性能。该架构还引入了DLSS 3.0技术,展示了AI技术在实时图形渲染中的巨大潜力。第三代RT Core的性能提升为具身智能的视觉感知系统提供了强大的硬件加速能力。
Hopper架构(2022年):数据中心AI专用 Hopper架构专门为数据中心AI工作负载设计,引入了Transformer Engine专门优化大语言模型训练。该架构采用台积电4nm工艺,在计算密度和能效方面达到新的高度。Hopper的最大创新是支持FP8精度的混合精度训练,为大模型训练提供了更高的效率。架构中的NVLink 4.0技术实现了900GB/s的双向带宽,为分布式训练提供了强大的通信能力。
Blackwell架构(2024年):AI计算新纪元 Blackwell架构代表了NVIDIA GPU技术的最新巅峰,采用台积电3nm工艺制程,集成了超过2000亿个晶体管。该架构引入了第五代Tensor Core和第二代Transformer Engine,专门针对下一代AI工作负载进行优化。Blackwell架构还支持最新的NVLink 5.0技术,提供1.8TB/s的双向带宽,能够支持多达576个GPU的大规模互联系统,为AGI(通用人工智能)时代的超大规模模型训练奠定了硬件基础。
1.2 NVLink技术与多GPU互联
NVLink技术演进历程 NVLink作为NVIDIA的专有高速互联技术,从Pascal架构开始就成为高端GPU的标配功能。该技术专门解决传统PCIe总线带宽不足的问题,为多GPU系统提供了高带宽、低延迟的通信方案。NVLink技术的发展经历了从第一代的20GB/s到最新NVLink 5.0的1.8TB/s的巨大飞跃。
支持NVLink的GPU型号 数据中心级别的Tesla、A系列和H系列GPU均支持NVLink技术,包括V100、A100、A800、H100、H800等型号。这些GPU通过NVLink技术可以实现真正的多GPU内存共享和高效通信。值得注意的是,消费级RTX 40系列已经取消了NVLink支持,这主要是出于成本控制和市场定位的考虑。
多GPU训练优势 在大规模AI模型训练中,NVLink技术能够显著提升多GPU系统的训练效率。通过高带宽的GPU间通信,模型梯度同步时间大幅缩短,整体训练吞吐量可以实现接近线性的扩展。对于参数量超过百亿的大模型,NVLink技术已经成为必需的硬件配置。

2. 具体型号规格对比
| 型号 | CUDA核心 | Tensor核心 | RT核心 | 显存容量 | 内存带宽 | TDP |
|---|---|---|---|---|---|---|
| RTX 4090 | 16,384 | 512 | 128 | 24GB | 1008 GB/s | 450W |
| RTX 4080 | 9,728 | 304 | 76 | 16GB | 717 GB/s | 320W |
| RTX 4070 Ti | 7,680 | 240 | 60 | 12GB | 504 GB/s | 285W |
| RTX 4070 | 5,888 | 184 | 46 | 12GB | 504 GB/s | 200W |
| RTX 4060 Ti | 4,352 | 136 | 34 | 16GB/8GB | 288 GB/s | 165W |
| 型号 | 架构 | CUDA核心 | Tensor核心 | 显存容量 | 内存带宽 | 主要应用场景 |
|---|---|---|---|---|---|---|
| A100 | Ampere | 6912 | 432 | 80GB HBM2e | 1935 GB/s | 大规模训练、科学计算 |
| H100 | Hopper | 14592 | 456 | 80GB HBM3 | 3350 GB/s | 大语言模型训练、推理 |
| A800 | Ampere | 6912 | 432 | 80GB HBM2e | 1935 GB/s | 区域市场AI应用 |
| H800 | Hopper | 14592 | 456 | 80GB HBM3 | 2000 GB/s | 区域市场高端AI |
| H20 | 定制 | - | - | 96GB HBM3 | 4000 GB/s | AI推理、边缘计算 |
这些数据中心级GPU在大规模AI训练、推理部署、科学计算等领域各有优势,用户需要根据具体的应用需求、预算约束和技术要求来选择最适合的产品。
3. 具身智能领域的GPU需求分析

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)