RAG企业实战:从原理到落地,构建企业智能知识库
RAG(检索增强生成)技术正成为企业AI应用的核心,通过结合检索和生成能力,让大模型基于企业知识库提供准确、可追溯的答案。其核心流程包括检索、增强和生成三步,语义检索是关键创新点。企业实施RAG需具备深度文档理解、智能切片、检索优化等能力,并关注文档质量、模型选择、安全合规等要点。RAG可应用于智能客服、知识管理、数据分析等场景,未来将向更智能的检索、更强的文档理解方向发展。建议企业从小场景试点,
一、引言:为什么RAG成为企业AI的核心技术?
企业数据分散在文档、数据库、知识库中,传统LLM难以直接利用这些信息。RAG(Retrieval-Augmented Generation)通过检索增强生成,让大模型基于企业知识库生成答案,减少幻觉,提升准确性。
RAG的核心价值
- 解决知识更新问题:无需重新训练模型,更新知识库即可
- 降低幻觉风险:答案基于检索到的文档,可追溯来源
- 保护数据隐私:知识库可本地部署,数据不出企业
- 成本可控:无需微调大模型,降低训练成本
二、RAG基本原理:检索-增强-生成的三步走
RAG的核心流程可概括为三个步骤:
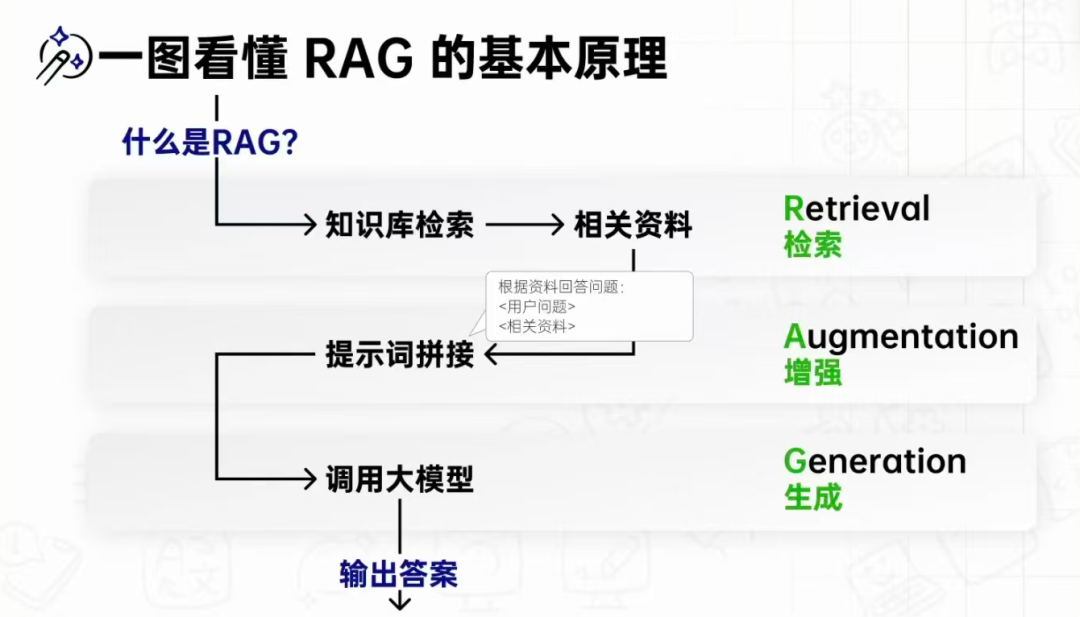
1. Retrieval(检索)
- 将用户问题转换为向量
- 在向量数据库中检索相似文档片段
- 返回Top-K相关片段
2. Augmentation(增强)
- 将检索到的文档片段与用户问题拼接
- 形成增强后的提示词(Prompt)
- 为模型提供上下文
3. Generation(生成)
- 大模型基于增强后的提示词生成答案
- 答案有据可查,可追溯来源
三、语义检索:RAG的"新"技术核心
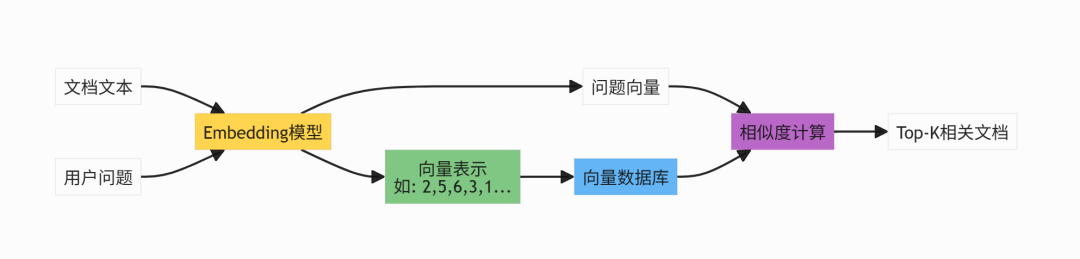
语义检索是RAG的核心。传统关键词检索依赖字面匹配,语义检索理解意图,提升检索质量。
语义检索的关键:Embedding
文档处理的关键能力
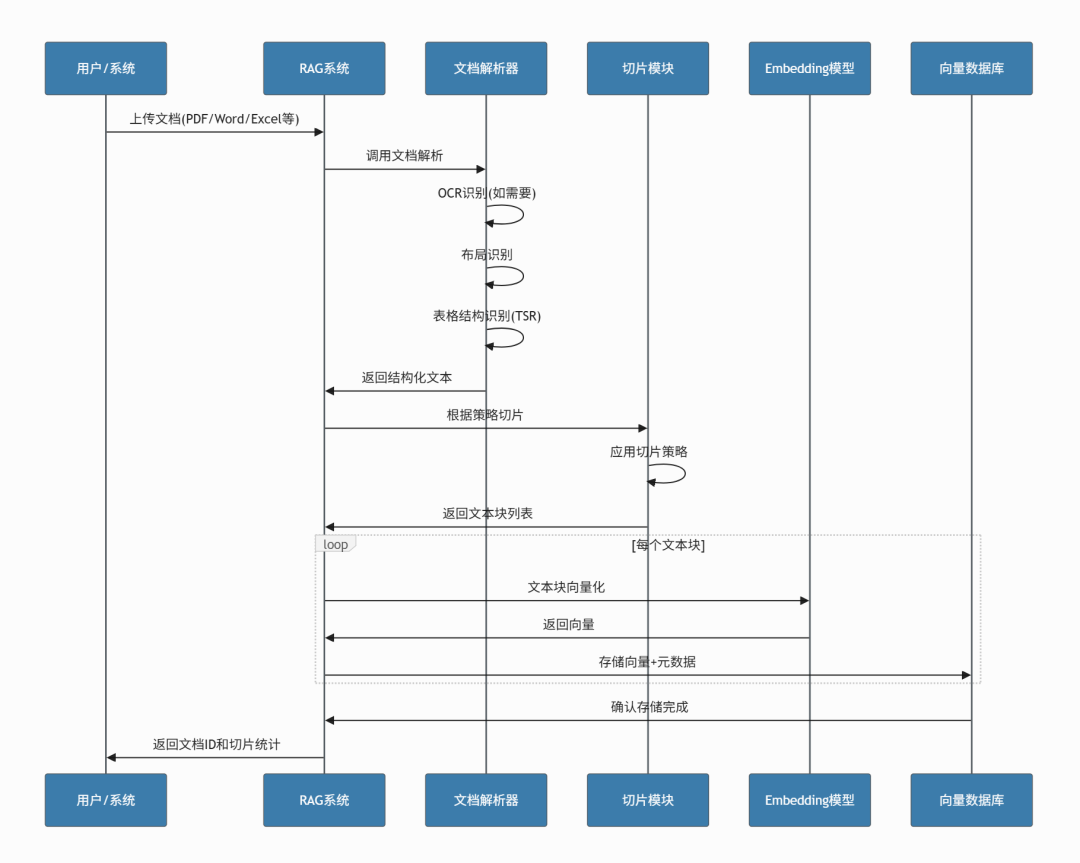
企业RAG系统需要具备的文档处理能力:
- OCR识别:图片、扫描件文字提取
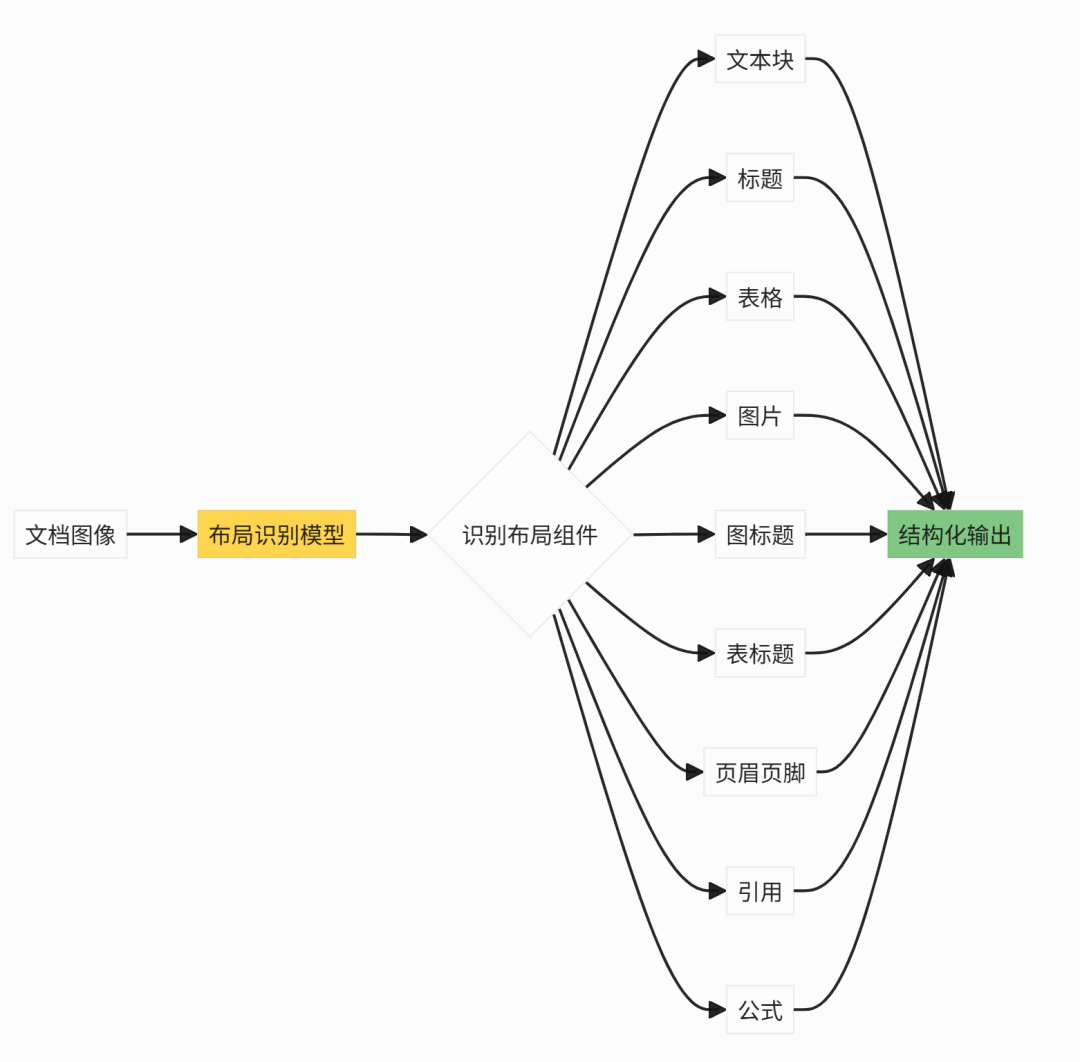
- 布局识别:识别标题、正文、表格、图片等布局组件
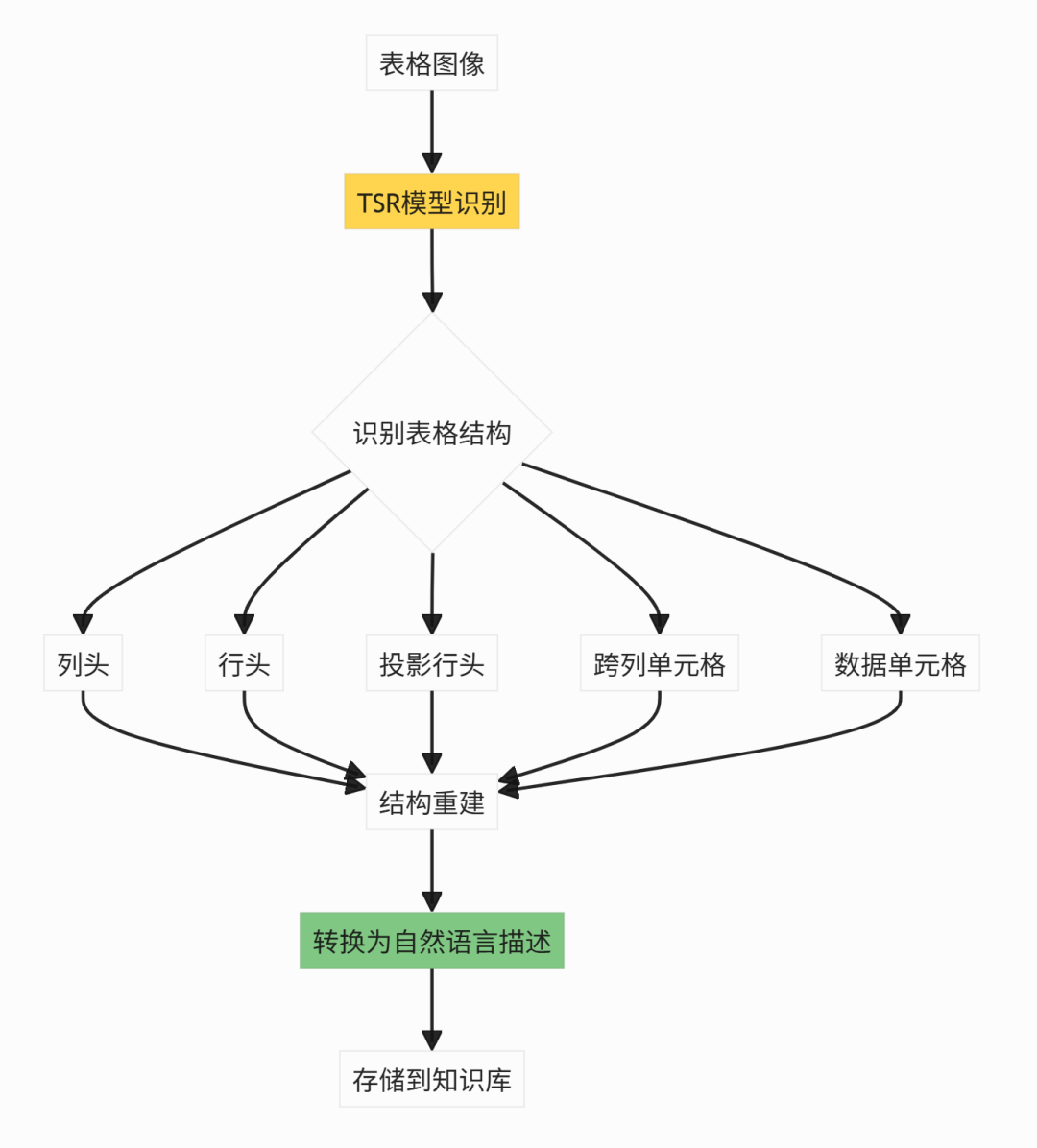
- 表格结构识别(TSR):处理复杂表格,转换为自然语言
- 多模态理解:PDF/DOCX中的图片可用多模态模型解析
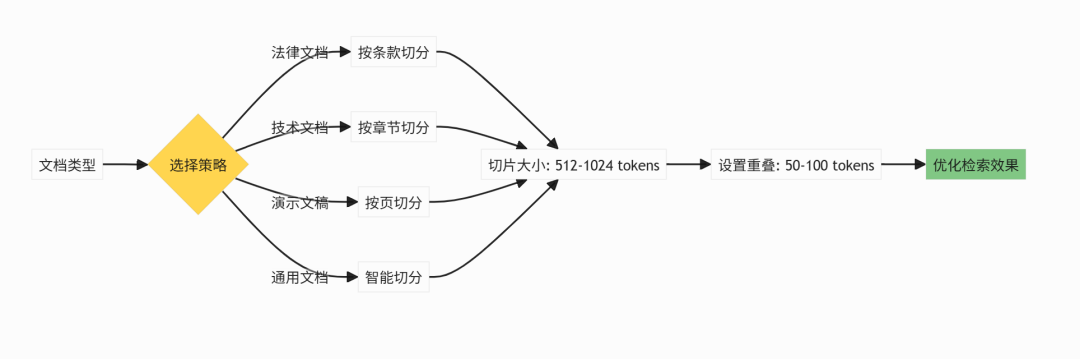
文档切片策略:质量决定效果
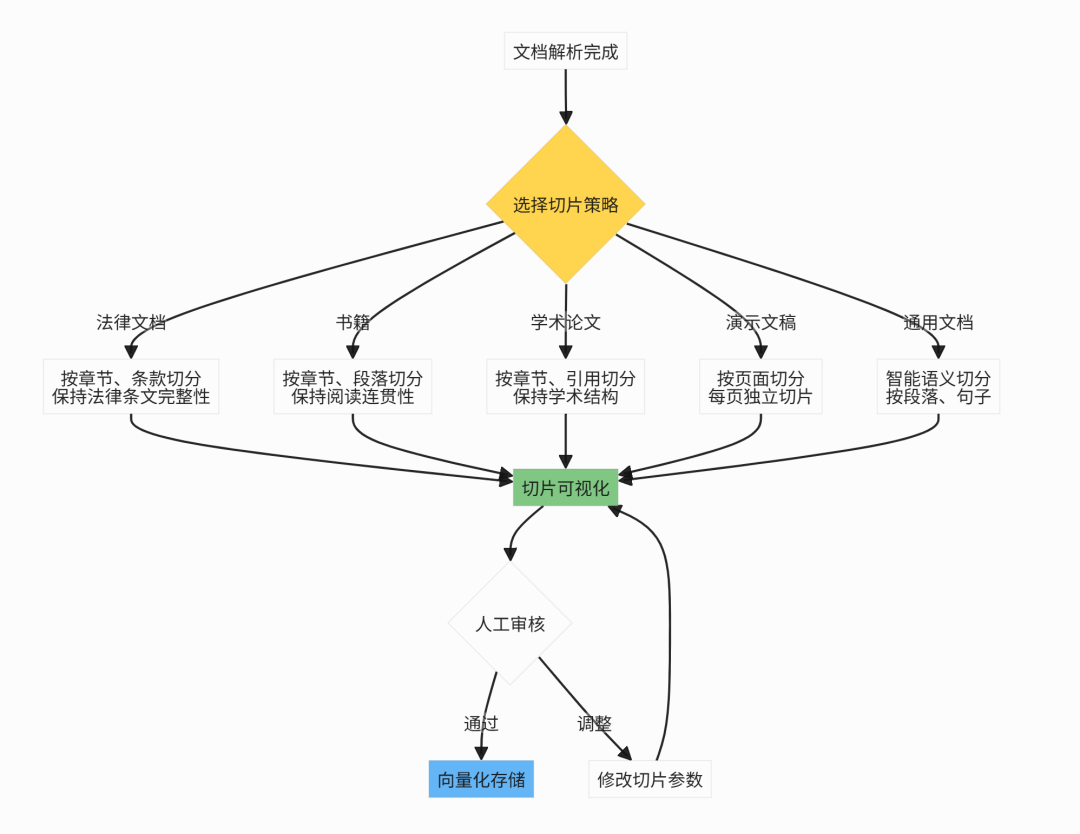
文档切片是RAG的关键环节,需要根据文档类型选择策略:
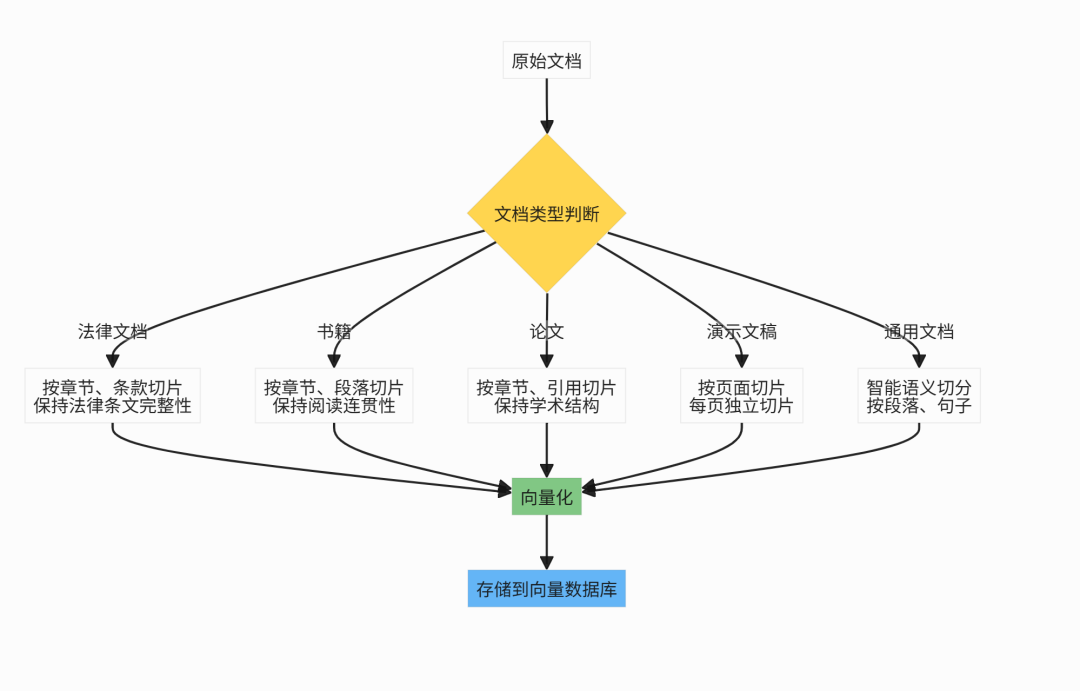
关键原则:
- 切片大小适中:过小丢失上下文,过大影响检索精度
- 保持语义完整性:按章节、段落等语义边界切分
- 可视化可调:支持可视化切片,便于人工干预和优化
四、技术架构:从文档到知识库的完整流程
4.1 文档向量化存储流程
4.2 RAG查询生成流程
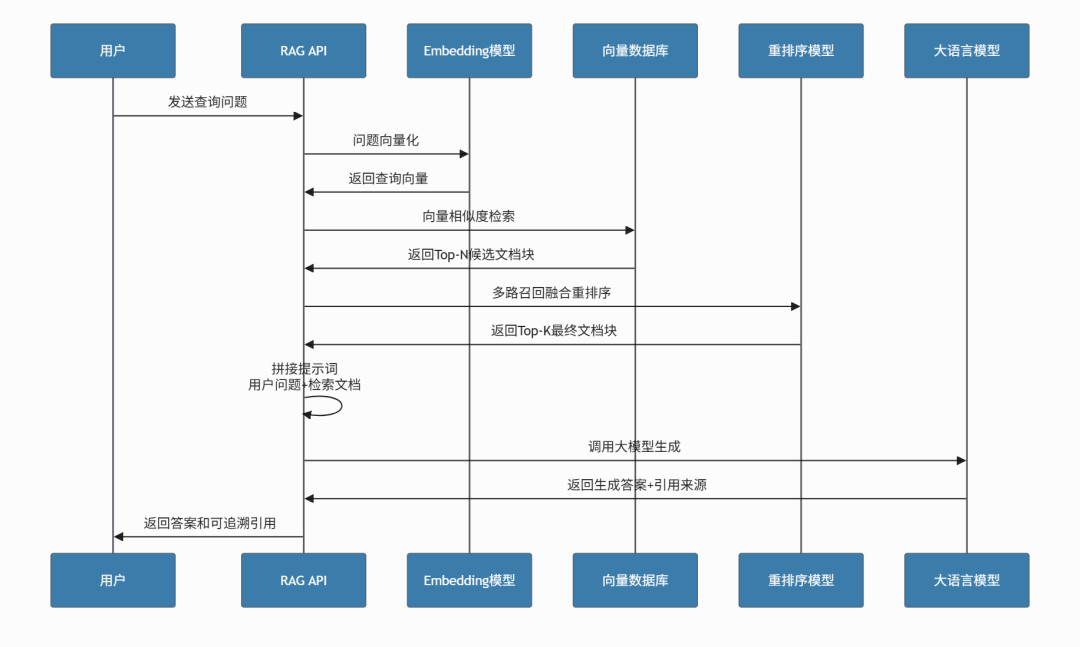
4.3 完整系统架构图
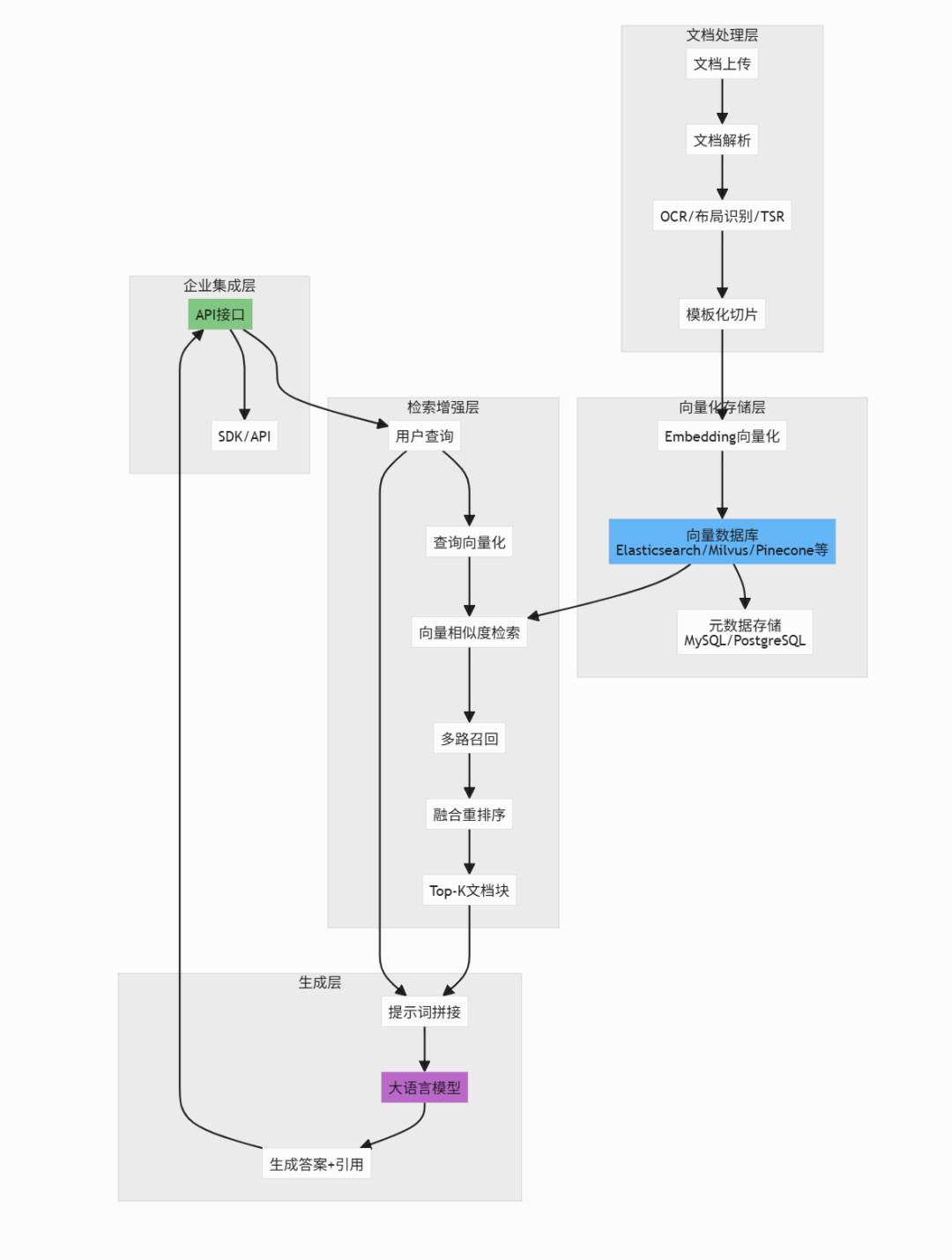
五、企业RAG系统核心能力要求
5.1 深度文档理解能力
企业RAG系统需要处理各种复杂格式的文档:
支持的文档格式
- PDF(含扫描件)
- Word(.docx, .doc)
- Excel(.xlsx, .xls)
- PowerPoint(.pptx)
- 图片(PNG, JPG等)
- 网页(HTML)
- 文本(TXT, Markdown)
- 邮件(Email)
布局识别能力
表格结构识别(TSR)
复杂表格处理流程:
5.2 智能切片策略
企业RAG系统应支持多种切片策略:
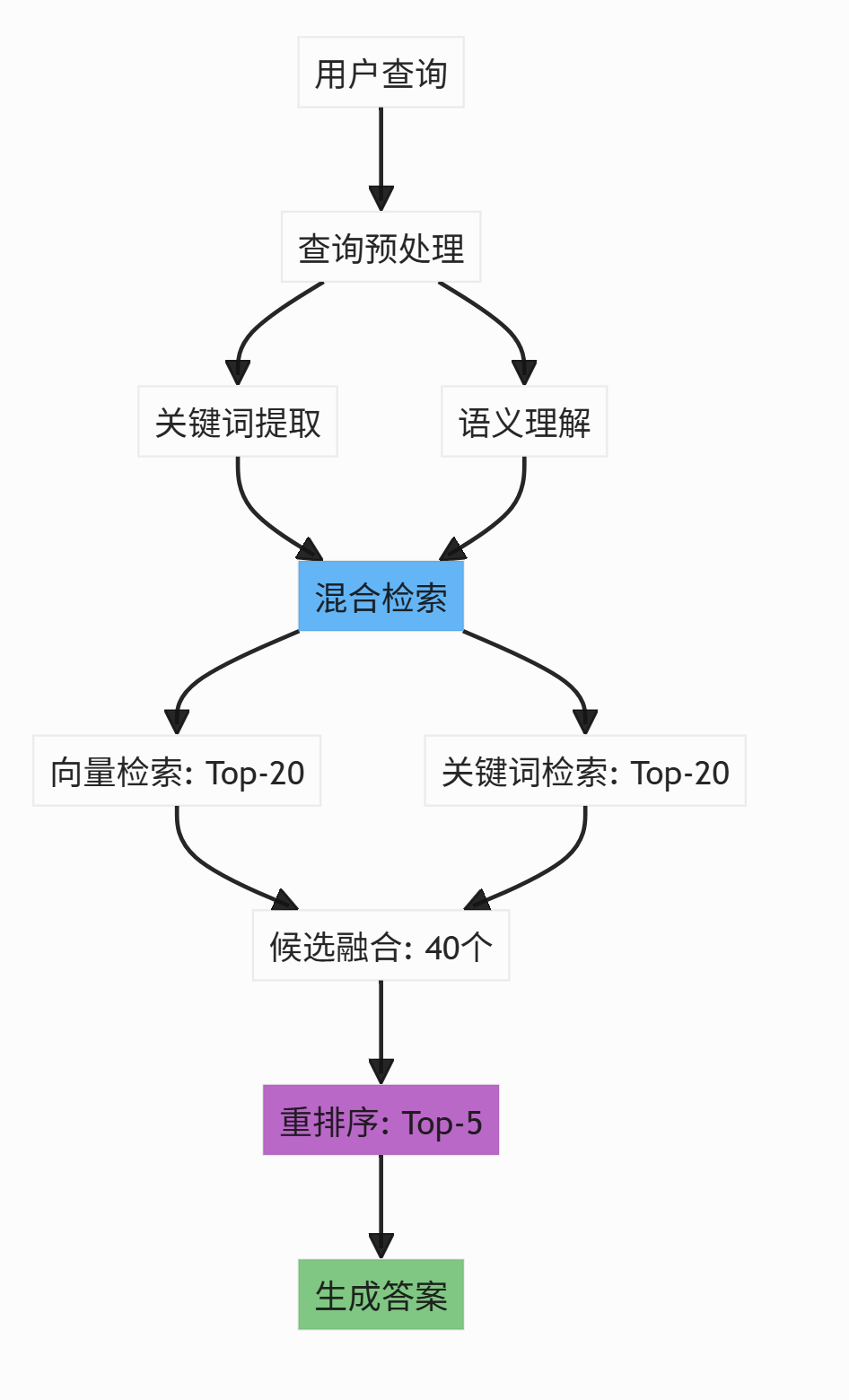
5.3 检索优化能力
企业RAG系统应具备检索优化能力,包括:
- 多路召回:结合向量检索、关键词检索等多种方式
- 融合重排序:使用重排序模型对候选结果进行精排
- 查询优化:对用户查询进行预处理和优化
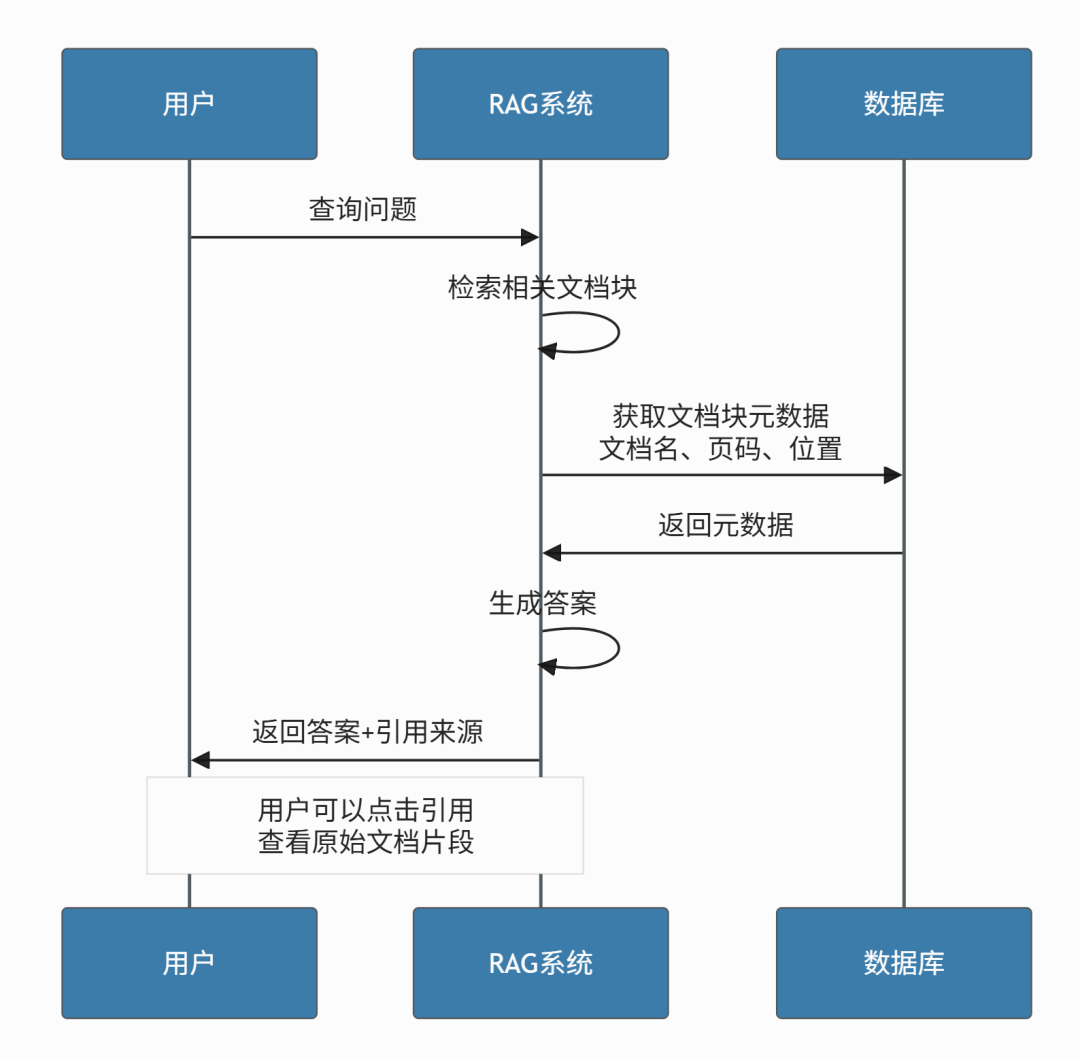
5.4 可追溯的引用机制
5.5 企业集成能力
- 企业RAG系统应提供完整的API接口,支持:
- RESTful API:标准HTTP接口,易于集成
- SDK支持:提供Python、Java等常用语言的SDK
- 认证安全:支持API Token、OAuth2、OIDC等多种认证方式
- 多租户支持:支持企业级多租户隔离
- 流式输出:支持流式响应,提升用户体验
💡 技术选型参考:如果您想深入了解开源RAG系统的工程实现,可以参考RAGFlow等开源项目。RAGFlow是一个基于深度文档理解的开源RAG引擎,在文档解析、切片策略、检索优化等方面有很好的工程实践,可以作为技术选型和系统设计的参考。如需了解RAGFlow的具体实现细节,可以参考相关的技术拆解文章。
六、企业应用场景实战
6.1 智能客服系统
场景:企业内部知识库问答
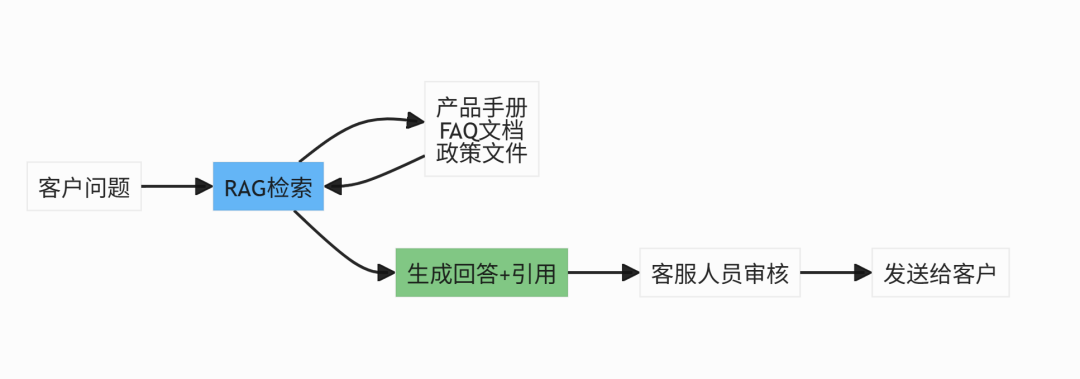
价值:
- 快速响应:秒级检索企业知识
- 准确性:基于官方文档,减少错误
- 可追溯:答案来源可查
实施要点:
- 通过API将RAG能力集成到企业客服系统
- 建立完善的知识库,包含产品手册、FAQ、政策文档等
- 设置审核机制,确保答案质量
6.2 知识管理系统
场景:合同、政策文档智能检索
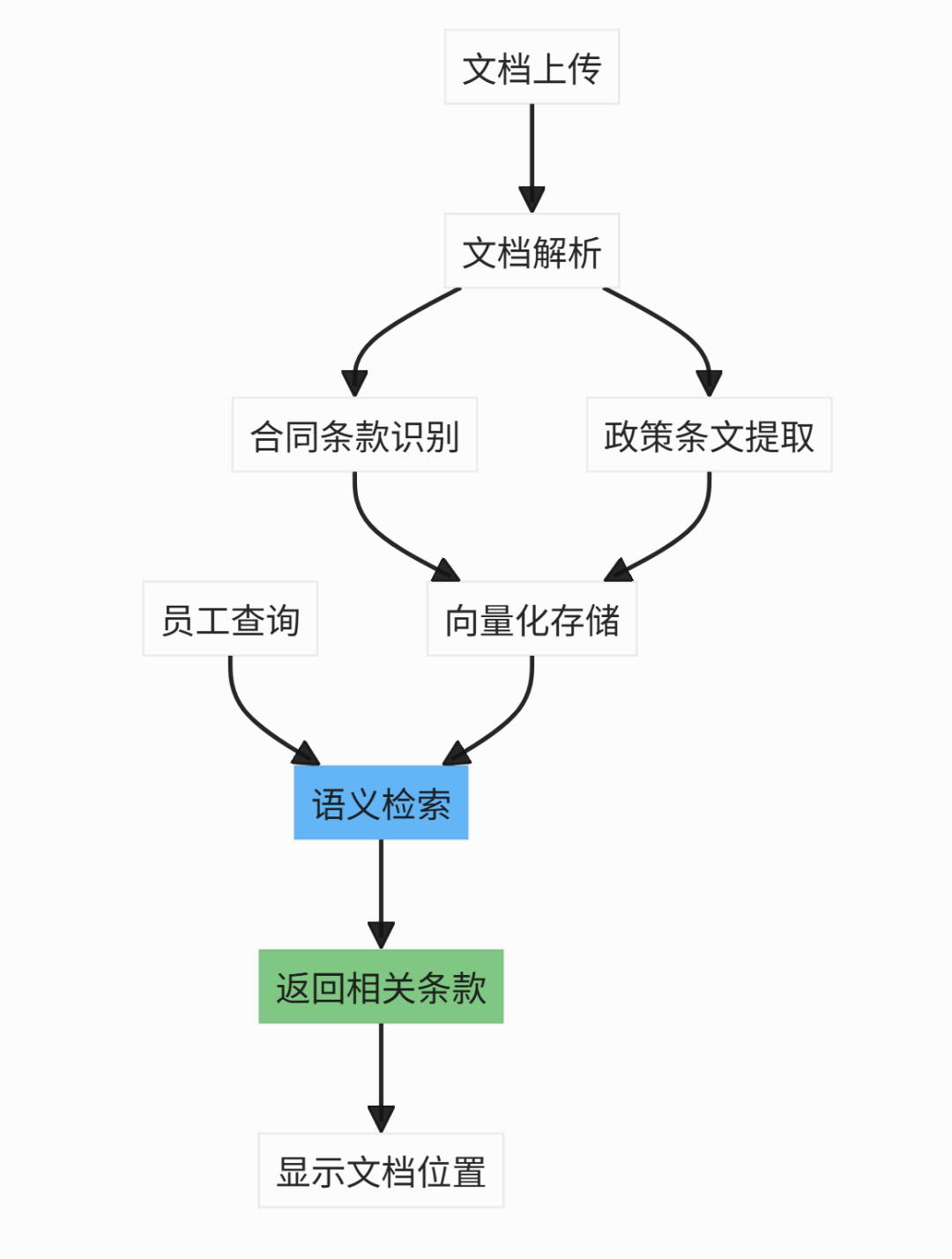
应用:
- 合同管理:快速查找合同条款
- 合规检查:检索相关政策要求
- 知识沉淀:将专家经验文档化
实施要点:
- 将RAG能力嵌入企业OA系统或知识管理平台
- 建立文档分类体系,便于管理和检索
- 设置权限控制,确保文档安全
6.3 数据分析助手
场景:Text2SQL + 报表解读
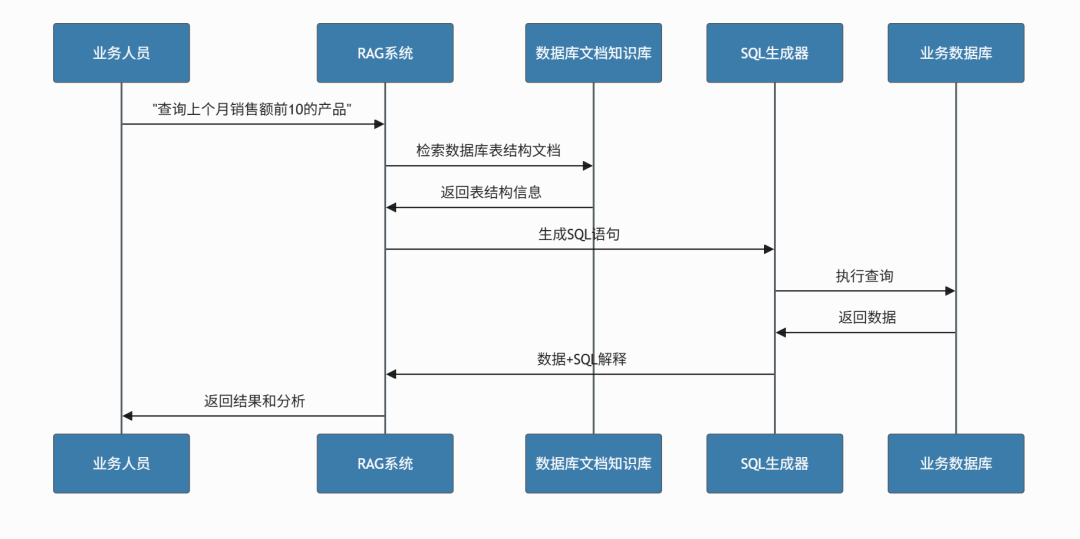
实施要点:
- 建立数据库文档知识库,包含表结构、字段说明等
- 通过API将RAG能力集成到BI系统
- 支持自然语言到SQL的转换,降低SQL使用门槛
6.4 内容生成与审核
场景:基于企业文档生成报告
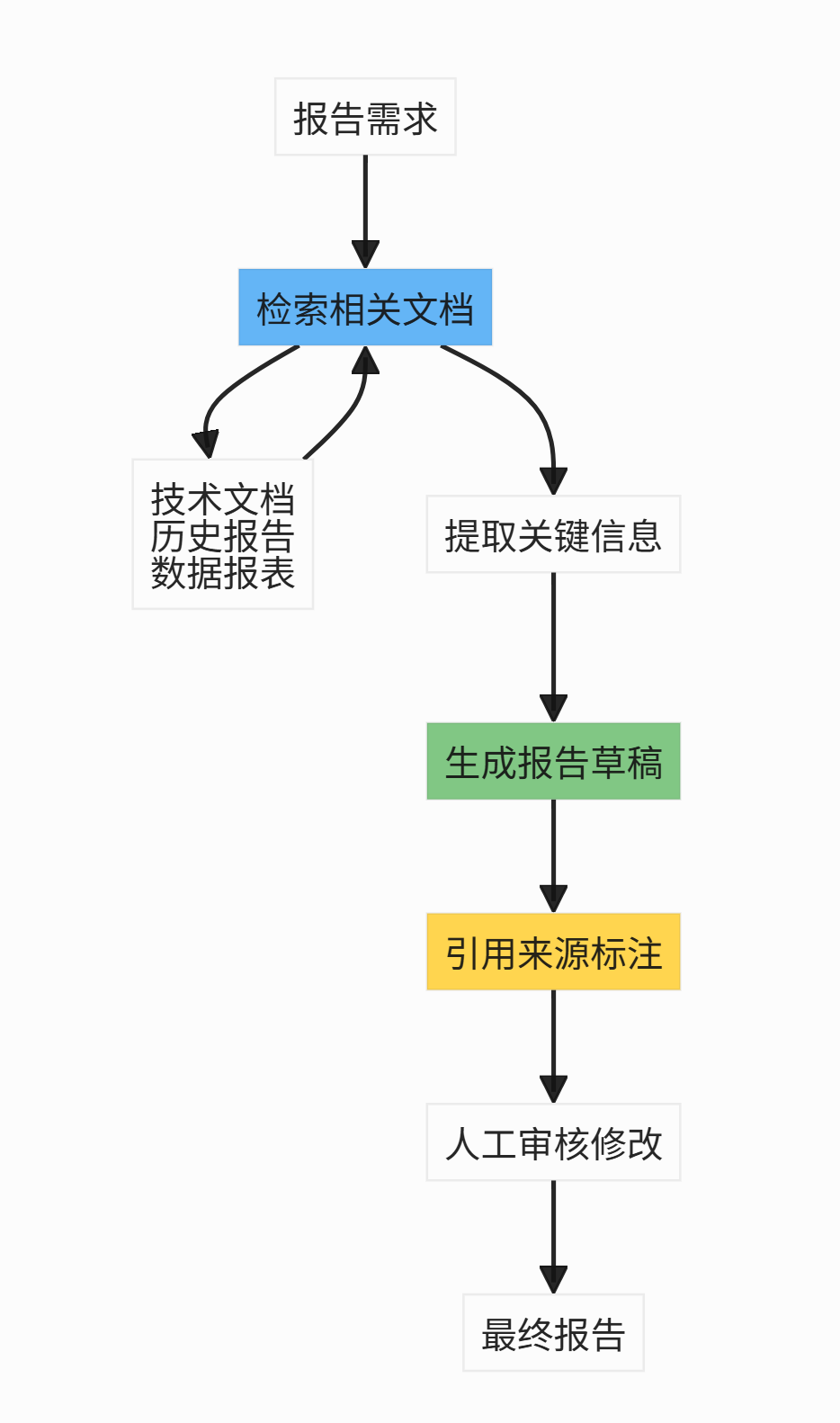
实施要点:
- 将RAG能力集成到企业内容管理系统
- 建立报告模板库,提高生成质量
- 设置审核流程,确保内容准确性
七、最佳实践与注意事项
7.1 文档质量:Quality in, Quality out
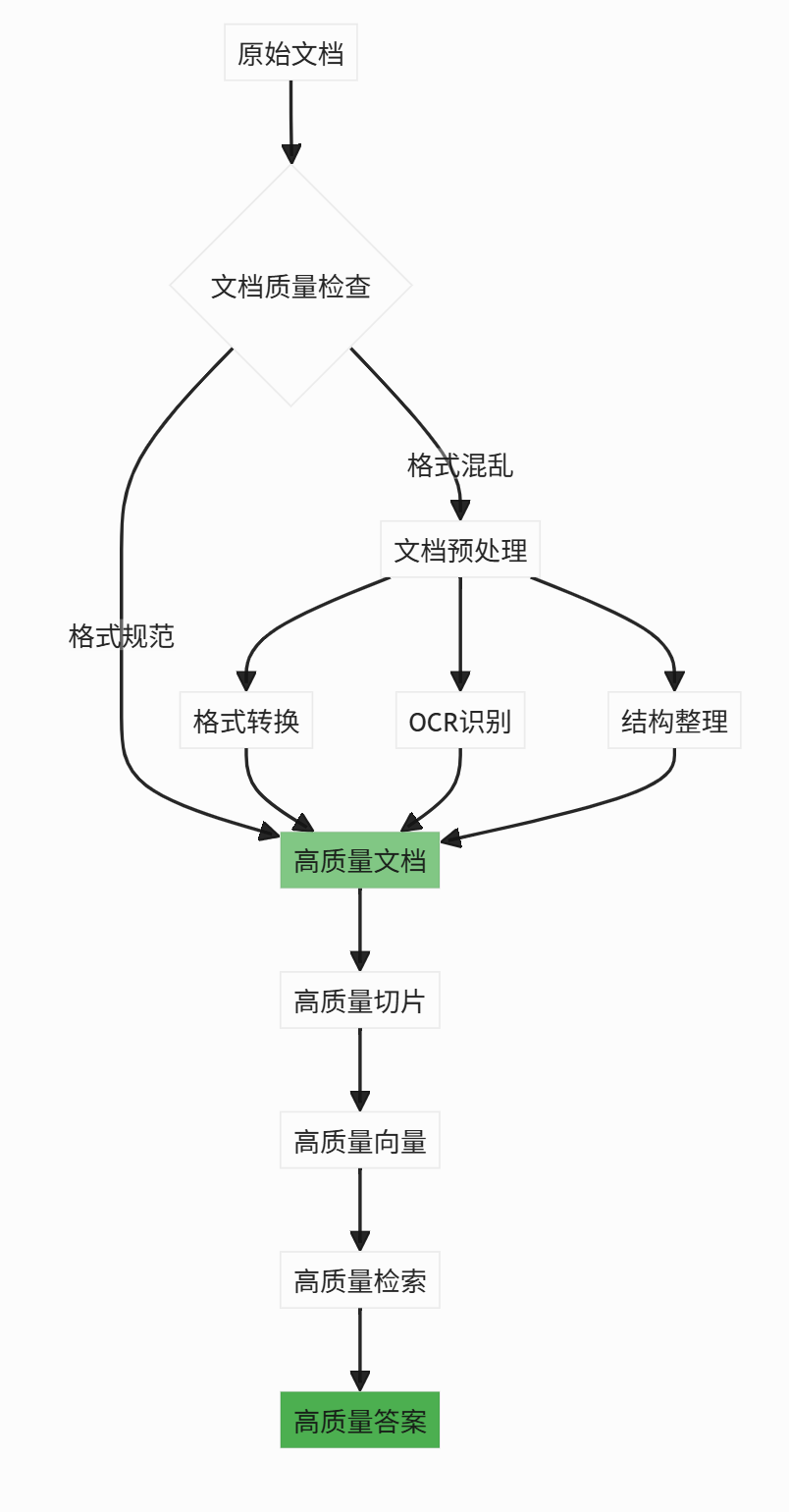
建议:
- 使用标准格式文档(PDF、Markdown等)
- 保持文档结构清晰(标题、段落分明)
- 扫描件需OCR处理
- 定期更新知识库
7.2 切片策略选择
7.3 检索优化策略
7.4 嵌入模型选择策略
- 嵌入模型是RAG系统的关键组件,直接影响检索质量。选择时需注意:模型能力差异:
- 低参/低维模型:能区分明显语义差异(如"跑步"vs"吃饭"),但难以区分细微差别(如"慢跑"vs"快跑")
- 高参/高维模型:能识别细微语义差别,但无法识别未纳入预训练语料的专业词汇
企业应用建议:
- 根据业务场景选择:通用场景可用中等参数模型,专业领域需高参数模型
- 专业词汇处理:对于企业特有术语,考虑领域微调或使用专业模型
- 平衡成本与效果:高参模型效果好但成本高,需根据实际需求权衡
💡 深入探讨:嵌入模型的选择和优化是RAG系统的核心技术难点,我们将在后续文章中详细探讨不同场景下的模型选择策略、专业词汇处理方案以及成本优化方法。
7.5 知识源选择与模型理解边界
RAG系统并非万能,需要明确知识源的适用边界:适用场景(模型可理解的知识):
- 通用概念和特殊约束(如员工手册中的通用规则)
- 实时更新的新闻、数据(不包含新梗、网络用语)
- 客观无偏见的信息
- 模型训练语料范围内的知识内容
禁用场景(模型难以理解的知识):
- 专有名词、新技术、新概念(未在预训练中出现)
- 提供的资料本身不是答案(需要推理、计算)
- 不具备语义的数学、符号(纯公式、代码)
- 模型无法理解、关联的内容
企业应用建议:
- 知识库构建时,优先选择模型能理解的内容
- 对于专业术语,在文档中提供上下文解释
- 避免将纯公式、代码片段作为知识源
- 定期评估知识库内容,确保符合模型理解范围
💡 深入探讨:知识源的选择和模型理解边界是RAG系统设计的重要考量,我们将在后续文章中详细分析不同行业的知识源特点、模型理解能力评估方法以及知识库优化策略。
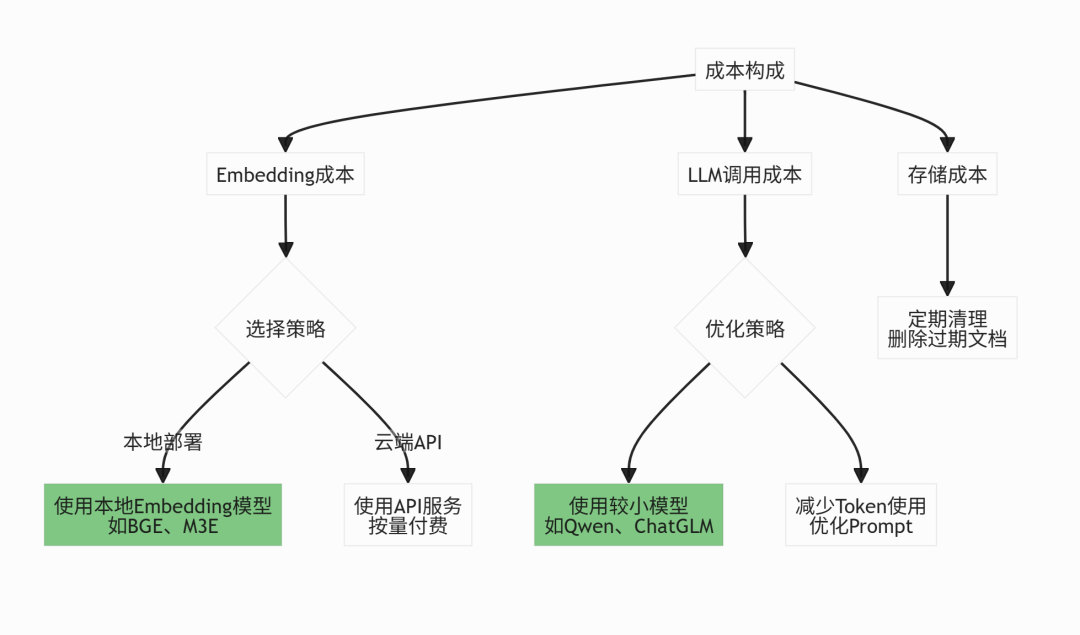
7.6 成本控制
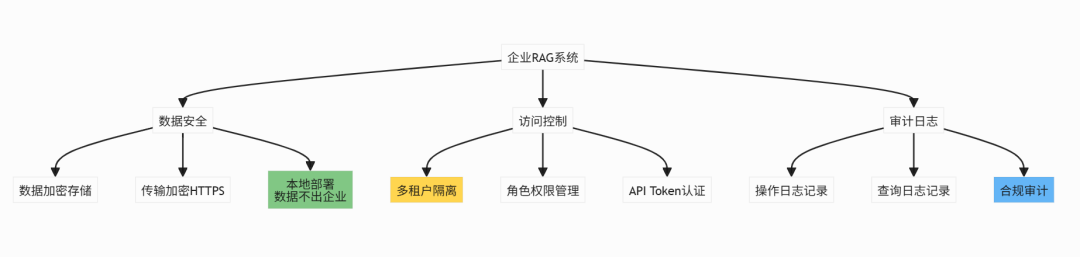
7.7 安全与合规
八、技术选型建议
8.1 自建 vs 使用开源方案
企业可以选择自建RAG系统或使用开源方案:
自建方案:
- 优点:完全可控,可根据业务定制
- 缺点:开发成本高,需要专业团队
- 适用:有充足技术团队,对系统有特殊要求
开源方案:
- 优点:快速上线,社区支持,工程实践成熟
- 缺点:需要评估是否符合企业需求
- 适用:希望快速上线,降低开发成本
8.2 核心技术组件选型
向量数据库:
- Elasticsearch:功能全面,适合已有ES基础设施的企业
- Milvus:专为向量检索设计,性能优秀
- Pinecone:云端服务,易于使用
- Qdrant:轻量级,易于部署
Embedding模型:
中文场景:BGE、M3E、text2vec等
多语言场景:multilingual-e5、BGE-M3等
选择建议:根据文档语言、领域特点选择
大语言模型:
- 云端API:OpenAI、Claude、文心一言等
- 本地部署:Qwen、ChatGLM、Llama等
- 选择建议:根据成本、数据安全要求选择
九、未来展望
RAG技术发展趋势
- 更智能的检索:结合图数据库、知识图谱,提升检索准确性
- 更强的文档理解:多模态、复杂表格处理能力持续增强
- 更低的成本:模型压缩、量化技术,降低部署成本
- 更好的可解释性:检索过程可视化、答案溯源更清晰
企业AI应用展望
随着RAG技术的成熟,企业AI应用将呈现以下趋势:
- 从单点应用到全场景覆盖:从智能客服扩展到知识管理、数据分析、内容生成等全场景
- 从工具到平台:从单一工具发展为集成多种AI能力的平台
- 从被动响应到主动服务:从问答系统发展为主动推荐和智能助手
💡 进阶学习:本文聚焦RAG的核心能力和基础应用。对于Agent工作流、跨语言查询、多模态理解、Deep Research等进阶能力,以及更深入的技术实现细节,我们将在后续文章中深入探讨。
结语
RAG为企业AI应用提供了可行路径。通过检索增强生成,企业可以让大模型基于自身知识库提供准确、可追溯的答案。
核心要点回顾:
- 语义检索是RAG的核心技术:理解用户意图,而非简单关键词匹配
- 文档质量决定RAG效果:"Quality in, Quality out"原则
- 切片策略需要根据文档类型选择:不同文档类型需要不同的切片策略
- 企业集成要考虑安全与合规:数据安全、访问控制、审计日志缺一不可
给企业的建议:
- 从小场景开始:选择一个具体场景(如智能客服)先试点
- 重视文档质量:投入时间整理和规范文档格式
- 持续优化:根据使用反馈不断优化切片策略和检索参数
- 关注成本:合理选择模型和部署方式,控制成本
- 重视安全:确保数据安全和访问控制,满足合规要求
希望本文能帮助企业在RAG应用中少走弯路,快速构建智能知识库系统,让AI真正为企业创造价值。
RAGFlow参考资源:
- RAGFlow官方文档:https://ragflow.io/docs/dev/
- GitHub仓库:https://github.com/infiniflow/ragflow
- Demo体验:https://demo.ragflow.io

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)