从账单一万tokens到高效AI客服:MCP优化实战指南!
文章讲述AI客服MCP工具过多导致的性能成本问题,提出三项解决方案:工具组分类、精准选择工具、清理输出噪音。通过实际案例展示优化效果,解释原理:减少上下文噪音提升模型专注度,降低成本和错误率。强调"上下文工程"是新时代性能优化,精简胜于全面。
上周部署 了一个AI 客服,底层接了一个“豪华版” MCP 服务器:60 多个工具一把梭。上线第一天大家都挺兴奋,第二天看到惊人的账单“一轮就一万多 tokens?账单怎么跟开了加速器一样?”
更尴尬的是第三天:客服开始“胡言乱语”。用户明明问的是“帮我查亚马逊价格”,它却跑去调用 LinkedIn;有时候还会一本正经地编参数,像是工具文档读了一半就开始写作文。
那一刻我才意识到:工具越多≠能力越强。很多时候,工具多到一定程度,反而是灾难。
我后来把这个矛盾总结成一句话:你有 60 把锤子,但每次只需要一把螺丝刀。而 AI 却要先看一遍所有工具的说明书,才开始干活。
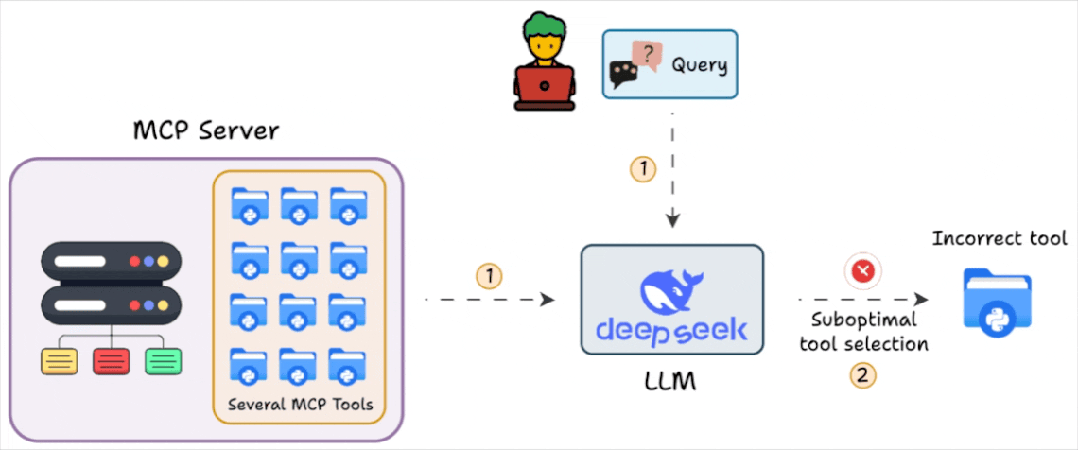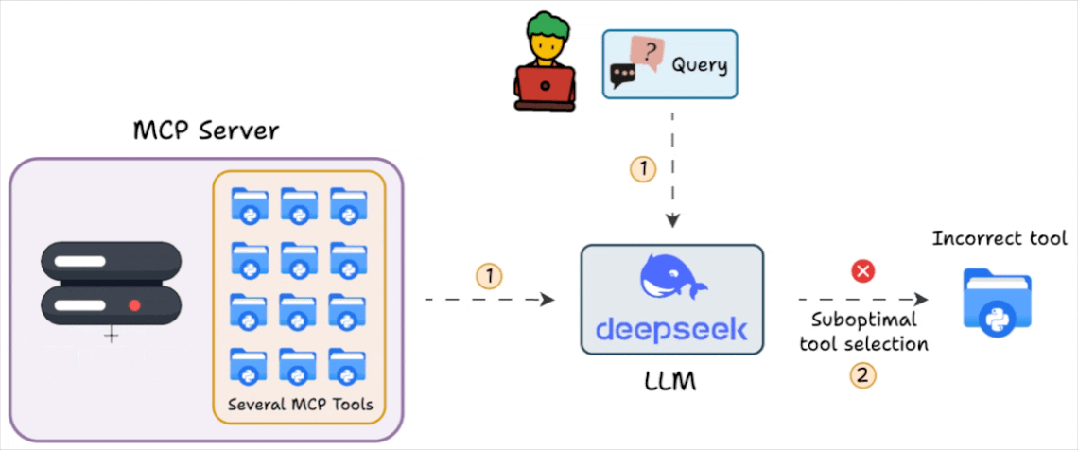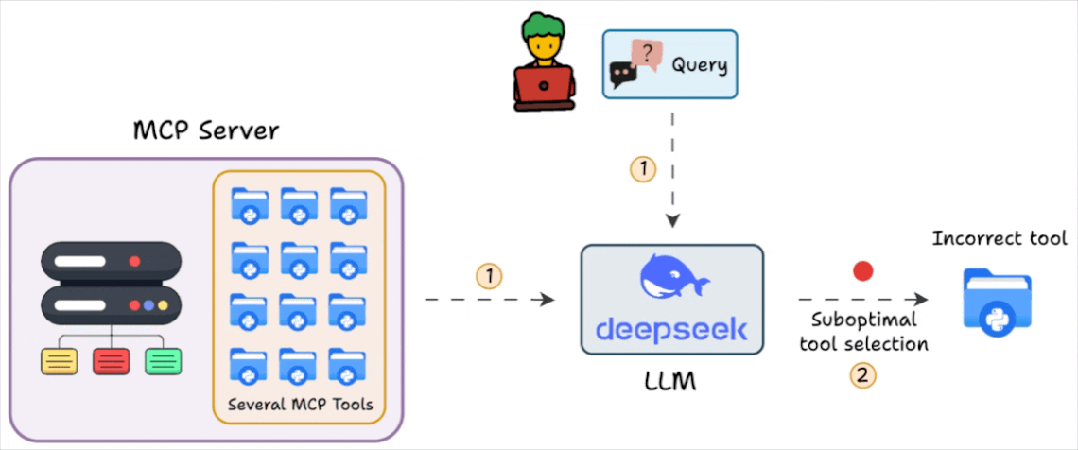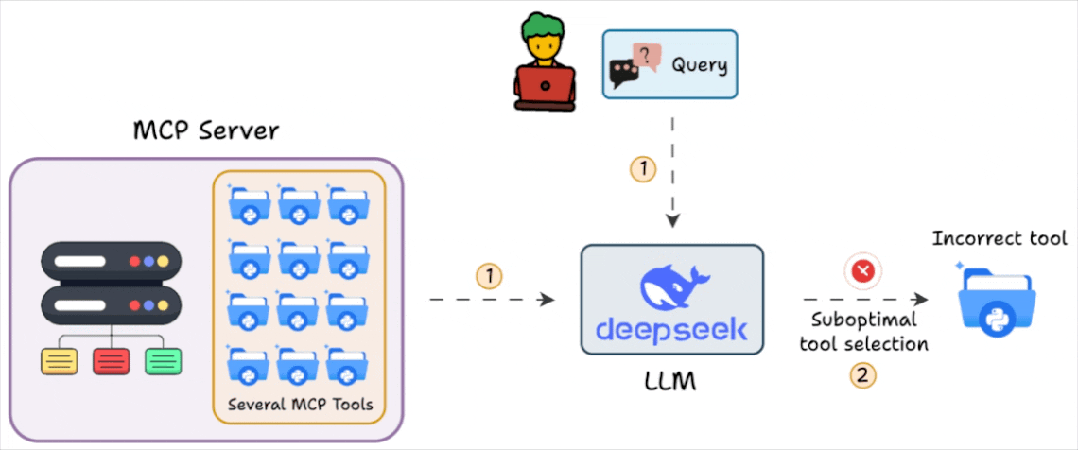
一、问题本质:MCP 的“全家桶诅咒”
1.1 什么是 MCP 服务器?
一句话说明白:让 AI 像人一样调用外部工具的协议。
你可以把它理解成“给模型接上手和脚”。比如 Claude Desktop 通过 MCP 能做到:读取数据库、爬网页、发邮件、查企业信息……你能想到的“外部动作”,它都可以通过工具去执行。
这也是为什么大家一接入 MCP 就容易上头:工具一多,感觉 AI 立刻变成“超级员工”。
但现实往往是:工具越多,坑越大。
1.2 传统 MCP 的两大痛点
痛点 1:Token 黑洞
技术上,很多 MCP 客户端在启动或连接时,会把所有工具的文档/Schema塞进上下文(context)。工具越多,开场白越长,token 消耗就越夸张。
粗略算一笔账:
60 个工具 × 平均 200 tokens/工具 = 12,000 tokens
GPT-4 API 价格:$0.03/1K tokens
→ 每次对话开头就烧掉 $0.36
注意:这还只是“刚开始聊天”,用户一句话没说完,你已经在付钱了。
痛点 2:注意力稀释
工具多不仅贵,还会“干扰思考”。Anthropic 自己也提过:工具太多会让模型分心。你给它一堆工具,它并不会像工程师一样先筛选后调用,更多时候是在做“语义匹配 + 猜”。
我见过最典型的翻车现场:
- 用户问:“帮我查亚马逊价格”
- AI 却调用了 LinkedIn 工具(因为上下文里还有几十个工具在抢注意力)
这不是模型“傻”,而是你把它放进了一个噪音巨大的工作台。
二、解决方案:三板斧砍掉 95% 的浪费
我后来用的方法很朴素:先做减法,再谈智能。落地时就是三招,从粗到细。
2.1 第一招:工具组分类(粗筛)
思路很简单:别让模型一上来就看 60 个工具。先按场景把工具分组,只加载当前业务需要的一组。
你可以把它想象成:
传统方式是把整个工具箱倒在桌上;优化后是只带“社交媒体小工具包”。
传统方式:加载 60 个工具(电商+社交+金融+…)
优化后:只加载"社交媒体"组(LinkedIn/YouTube/Facebook)
→ Token 减少 80%
配置示例(Bright Data MCP):
{
"mcpServers": {
"brightdata": {
"command": "npx",
"args": ["-y", "@brightdata/mcp-server"],
"env": {
"BRIGHT_DATA_TOOL_GROUPS": "SOCIAL_MEDIA"
}
}
}
}
常用工具组可以这么理解:
| 工具组 | 包含工具 | 适用场景 |
|---|---|---|
| ECOMMERCE | Amazon/eBay/Walmart | 价格监控、竞品分析 |
| SOCIAL_MEDIA | LinkedIn/TikTok/X | 舆情监测、KOL 挖掘 |
| BUSINESS | Google Maps/Crunchbase | 企业调研、选址分析 |
| RESEARCH | GitHub/Reuters | 技术调研、新闻追踪 |
这一招的价值是:你不需要“知道每个工具细节”,只要把场景卡住,token 立刻降一大截。
2.2 第二招:精准选择(细筛)
工具组能把“60”变成“10”,但很多业务其实连“10”都嫌多。
比如你做一个价格比价机器人,真的只需要 Amazon + Google Shopping。TikTok、LinkedIn 这些都不该出现。
配置可以直接指定工具:
{
"env": {
"BRIGHT_DATA_TOOLS": "amazon_product,google_shopping_search"
}
}
更实用的是“组合拳”:先加载一个大组,再补一两个特例工具(有时候业务就是这么拧巴)。
{
"env": {
"BRIGHT_DATA_TOOL_GROUPS": "ECOMMERCE",
"BRIGHT_DATA_TOOLS": "linkedin_profile"
}
}
这样做的效果很明显:上下文更干净,模型选工具更稳定,“乱调用”和“瞎编参数”会少很多。
2.3 第三招:输出瘦身(Strip-Markdown)
很多人只盯着“工具定义”这块 token,其实还有一块特别容易忽视:工具返回的内容。
尤其是爬网页、抓文档、拉公告这类工具,经常返回一大坨 Markdown:标题、加粗、图片、链接、列表……对人类好看,对模型来说就是噪音。
比如:
# **重要通知**

点击[这里](https://example.com)查看详情
模型真正需要的可能只有:
“重要通知 点击这里查看详情”。
你可以在服务端(或中间层)做一次 Markdown 清理:
import { remark } from "remark";
import stripMarkdown from "strip-markdown";
const cleaned = await remark()
.use(stripMarkdown)
.process(rawMarkdown);
我在一个项目里测过一轮:
- 处理前:1200 tokens
- 处理后:720 tokens(↓40%)
这招看起来“抠门”,但在高频对话场景里非常值钱。
三、实战案例:从理论到落地
讲方法很容易,落地才是最容易出坑的地方。我拿两个真实场景复盘一下。
案例 1:社交媒体监控机器人
需求:实时抓取 LinkedIn 职位发布 + YouTube 品牌视频。
Step 1:安装 & 找到配置文件
npx @brightdata/mcp-server
Claude Desktop 配置路径(别写错):
- macOS:
~/Library/Application Support/Claude/claude_desktop_config.json - Windows:
%APPDATA%\Claude\claude_desktop_config.json
Step 2:写入配置
{
"mcpServers": {
"brightdata": {
"command": "npx",
"args": ["-y", "@brightdata/mcp-server"],
"env": {
"BRIGHT_DATA_TOOL_GROUPS": "SOCIAL_MEDIA",
"BRIGHT_DATA_API_KEY": "你的API密钥"
}
}
}
}
Step 3:验证
- 重启 Claude Desktop(注意是完全退出再打开)
- 输入:“帮我抓取 LinkedIn 上最新的 AI 工程师职位”
- 看工具调用日志是否只在社交媒体工具里活动
对比效果很直观:
- 不用 MCP:经常被 LinkedIn 反爬拦截
- 用 MCP:成功获取数据(通常自带代理池/更稳定的采集能力)
案例 2:电商价格追踪
需求:监控 3 个平台的 iPhone 15 价格。
这类需求不需要“电商工具大全”,直接极简:
{
"env": {
"BRIGHT_DATA_TOOLS": "amazon_product,walmart_product,google_shopping_search"
}
}
Prompt 模板可以写得很业务化:
请每天 9 点帮我对比以下商品价格:
- Amazon: iPhone 15 Pro 256GB
- Walmart: 同款
- Google Shopping: 同款
如果价格低于 $999,立即通知我
工具少、目标清晰,模型会更像“认真干活的人”,而不是“翻工具说明书的实习生”。
四、深层原理:为什么这些优化有效?
如果你想彻底理解“为什么减法能提升效果”,核心在两点:加载机制 + 幻觉来源。
4.1 MCP 的工具加载机制(简化理解)
很多客户端连接时会“全量加载工具定义”,相当于把工具说明书塞进 prompt:
class MCPClient:
def connect(self, server):
self.tools = server.list_all_tools()
if "TOOL_GROUPS" in env:
self.tools = server.filter_by_group(env["TOOL_GROUPS"])
你做的所有优化,本质是在减少 self.tools 的规模与噪音。
4.2 Token 计算的真相
一个工具并不只是“一个名字”,它往往包含:
- 函数名
- 参数说明
- 字段类型
- 示例
- 注意事项
平均 150–300 tokens 很正常。60 个工具就是 12,000 tokens,差不多 9 页 A4 纸的信息量。让模型每轮都读一遍,既贵又不稳定。
4.3 为什么会“虚构参数”?
这不是玄学,是模式匹配的副作用。
当上下文里有很多相似工具时,模型会做模糊匹配,然后“补全它认为合理的结构”。比如:
amazon_product(asin="...")
walmart_product(item_id="...")
→ 模型可能创造出 ebay_product(asin="...")
你工具越多、越相似,越容易诱发这种“看起来对,其实错”的输出。
五、避坑指南:我踩过的 5 个坑
1)配置文件路径写错
很多人把配置丢到 home 目录就以为生效了:
# 错误
~/claude_desktop_config.json
# 正确
~/Library/Application Support/Claude/claude_desktop_config.json
2)环境变量不生效
原因通常只有一个:改了配置没重启客户端。记住:要完全退出再打开。
3)工具名称拼写错误
这种最隐蔽,尤其是上线前夜:
//错误
"BRIGHT_DATA_TOOLS": "amazo_product"
//正确
"BRIGHT_DATA_TOOLS": "amazon_product"
4)API 配额耗尽
TOOL_GROUPS 做验证,确认逻辑没问题再上生产。
5)Strip-Markdown 过度清理
如果你要提取代码块,反引号被删掉会导致结构丢失。做“输出瘦身”一定要按场景来,不要一刀切。
六、进阶玩法:组合拳(高级技巧)
如果你已经把基础三招跑通了,这里有三个我觉得特别实用的“工程化”玩法。
6.1 动态切换工具组
按时间或任务切换工具组,比“一个配置打天下”稳定得多:
export BRIGHT_DATA_TOOL_GROUPS="ECOMMERCE"export BRIGHT_DATA_TOOL_GROUPS="SOCIAL_MEDIA"
更进一步可以和任务调度结合,让不同 agent 在不同时间段只带自己需要的工具。
6.2 自定义工具过滤器
在 MCP 服务端加一层过滤逻辑,把“业务规则”写死,比让模型自己判断靠谱:
function filterTools(allTools, userPreference) {
if (userPreference.industry === "retail") {
return allTools.filter(t => t.category === "ECOMMERCE");
}
}
这一步做完,你会明显感觉:模型变“老实”了。
6.3 Token 监控仪表板
不要靠感觉做优化,直接把 usage 打出来:
print(f"输入 Tokens: {response.usage.input_tokens}")
print(f"输出 Tokens: {response.usage.output_tokens}")
我强烈建议你在灰度阶段就把这个打点接上,否则等账单来了再查,基本都是“亡羊补牢”。
七、总结
我现在越来越相信一句话:上下文工程,就是新时代的性能优化。
- 工具不是越多越好 → 精准胜过全面
- Token 就是真金白银 → 每一个都值得优化
- AI 也会“注意力不集中” → 你要帮它做减法
最后给你三个我自己常用的“公式”,方便复盘优化效果:
优化效果 = 工具组分类(80%) + 精准选择(15%) + 输出瘦身(5%)
成本节约 = 原始 Token × (1 - 优化比例) × API 单价
响应质量 ∝ 1 / 上下文噪音
在 AI Agent 的时代,上下文工程师的价值,不亚于 10 年前的性能优化工程师。省下的每一个 Token,都是给业务增长让路。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
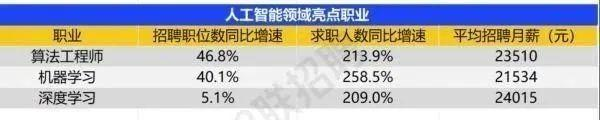
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献449条内容
已为社区贡献449条内容

所有评论(0)