传统数据治理 vs Data-centric AI 数据准备——从“管住数据”到“让数据为 AI 工作”
摘要:AI时代的数据治理范式转变 传统数据治理体系正面临挑战,因为AI成为数据的第一消费者。本文指出当前企业面临的核心矛盾:沿用为人设计的数据治理方式服务AI系统导致效果不佳。通过对比分析传统数据治理与AI数据准备的差异,提出数据工作应从治理转向为模型准备数据的新范式。 关键转变包括:目标从数据是否合规转向能否被模型理解使用;数据形态从结构化表格转向向量化语义表示;文章介绍了DataFlow系统的
这两年,大模型能力突飞猛进,能写代码、能规划任务、还能调用工具。但在企业真实场景中,很多团队却遇到了一个反直觉的问题:数据明明已经治理过了,AI 却依然不好用。
RAG 经常答非所问,Agent 会误用数据,回答看起来“有道理”,却经不起业务推敲。于是,常见的结论是:数据质量还不够好、治理还不够完善。更多规则、更多文档、更多流程随之而来,但效果却并没有明显改善。
问题真的出在“治理不够”吗?
或许恰恰相反——问题出在我们还在用一套“为人设计的数据治理方式”,去服务一个“以模型为核心的 AI 系统”。
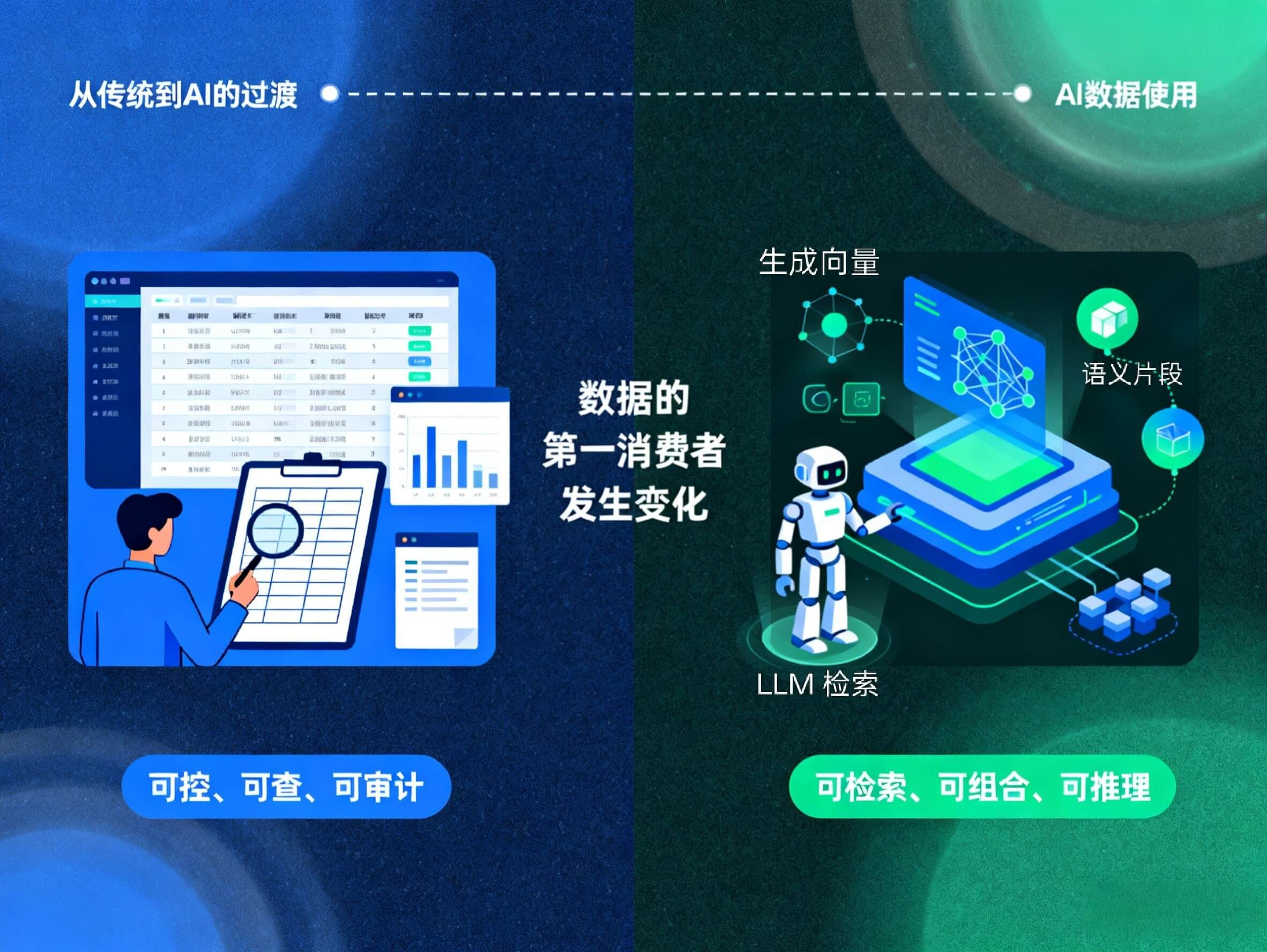
从数据治理到数据准备
传统数据治理,是“先管住数据,再谈使用数据”的治理范式。而进入 AI 时代后,数据治理不再是“把数据整理好给人用”,而是“把数据持续转化为模型可以直接理解、调用、推理的上下文能力”,我们称之为“数据准备”。它不是传统数据治理的升级版,而是一种面向模型的全新数据生产方式。从传统数据治理到 AI 数据准备,其实就是“数据的第一消费者”发生了变化,下面我们深入解析一下。
传统数据治理:数据是给人用的
在很长一段时间里,企业谈“数据治理”,其实背景非常明确——数据是给人用的。
业务看报表,管理层做决策,分析师拉数、算指标。只要数据口径不统一、质量不稳定,讨论就会迅速失焦,甚至直接影响经营判断。传统数据治理,正是在这样的场景下逐步建立起来的。
它要解决的核心问题并不复杂:
-
同一个指标能不能算得一致?
-
同一份数据可不可信?
-
出了问题,谁来负责?
围绕这些问题,企业逐渐形成了一套成熟的方法:定义数据标准、统一指标口径、建设主数据和元数据系统、配置质量规则、加强权限与合规控制。治理的目标很明确——让数据可控、可查、可审计。
在 BI 和数据仓库时代,这套体系是有效的。业务使用方式相对稳定,数据形态以结构化表为主,只要规则清晰、流程到位,大多数问题都能被提前消化在治理阶段。
但需要注意的是,这套体系背后隐含着一个重要前提:数据最终是被人阅读、理解和解释的。指标定义写给人看,口径评审给人讨论,数据目录也是给人查的。只要“人能理解”,数据治理的目标就算达成了。
这个前提,在很长时间里没有问题。直到 AI 开始成为数据的主要使用者。
AI 数据准备:大模型成为“第一消费者”
当大模型进入企业系统后,数据的使用方式发生了一个不易察觉、却非常关键的变化:数据第一次不再主要是给人用的,而是给模型用的,这也是为什么需要数据准备。
在传统场景里,数据的价值通过“人”来实现。人会阅读报表、理解指标含义、结合业务背景做判断。即使数据存在一些模糊之处,也可以通过经验和上下文自行补全。但模型没有这种能力,它既不会翻数据口径文档,也不会参与指标评审会议。
模型使用数据的方式非常直接:在某个任务中,是否能被检索到,是否语义清晰,是否能与其他信息组合推理。一旦上下文选择出现偏差,后续推理就会整体失效,而且这种失效往往很难通过传统的数据质量规则提前发现。
在这个视角下,传统数据治理的几个核心能力开始显得力不从心。统一的指标口径,并不能保证模型理解了业务语义;完善的数据目录,也不等于模型可以高效检索到合适的上下文;严格的质量规则,更无法判断一段信息是否“足以支撑一次推理”。
当数据的第一消费者发生变化,问题的本质也随之改变。AI 关心的,不再是“这张表是否合规”,而是“在这个问题下,我是否拿到了正确且足够的信息”。继续沿用以人为中心的数据治理思路,去支撑以模型为中心的 AI 系统,错位几乎是必然的。
传统数据治理 vs Data-centric AI 数据准备
到这里,我们已经看到两种数据工作的思路:一种是为人服务,一种是为模型服务。把它们放在一起对比,就更容易理解差异所在。
首先,第一消费者不同。传统数据治理的目标是人:管理者、分析师、业务人员。AI 数据准备的目标是模型:RAG 检索、Agent 推理、LLM 调用。消费者变了,工作重心自然也变了。
其次,关注点不同。传统治理关注“对不对、统一口径、谁负责”,强调可控、可查、可审计。而 AI 数据准备关注“能不能被找到、能不能被理解、能不能组合推理”,强调可用、可检索、可推理。
再者,数据形态不同。传统数据治理以结构化表为主,指标、字段、口径是核心;AI 数据准备以表示为核心,向量、语义片段、跨模态统一表示成为新单位。表格只是原料,模型能理解的表示才是产出。
变化节奏和流水线也不同。传统治理多依赖周期性流程(季度、月度),问题由人工发现和修复。AI 数据准备是持续运行的流水线,数据变化 → 表示更新 → 检索更新 → 转为 AI-ready 数据 → 模型消费,任何环节都可能触发迭代。
| 维度 | 传统数据治理 | AI-ready 数据准备 |
|---|---|---|
| 第一消费者 | 人 | 模型 / Agent |
| 核心目标 | 统一口径、保证质量、控制风险 | 可检索、可理解、可组合推理 |
| 数据形态 | 表格、字段、指标 | 向量、语义片段、跨模态表示 |
| 关注点 | 对不对、可审计 | 能不能用、能不能被组合 |
| 流程节奏 | 周期性、人工驱动 | 持续、自动化流水线 |
| 成功指标 | 数据一致性、合规性 | 模型效果、检索命中率、推理准确性 |
一句话总结:
传统数据治理关注“数据是否被管好”,
Data-centric AI 数据准备关注“数据是否能让模型变聪明”。
在这样的背景下,一个新的问题开始浮现:如果不再从“治理”的角度出发,而是从“模型如何使用数据”出发,数据工作应该被重新组织成什么样?
这,正是以 Data-centric AI 为理念打造的 DataFlow 数据准备系统要回答的核心问题。
Data-centric AI 的数据准备:为模型而生
AI 时代,数据不再是给人看的报表或表格,而是模型进行推理和决策的原料。这意味着,数据工作的目标从“治理数据”转向了“为模型准备数据”,核心关注点也完全不同。
模型训练需要怎样的数据
在传统数据治理语境里,“高质量数据”通常意味着:字段齐全、口径统一、格式规范、没有脏值。但在 AI 时代,这样的数据依然可能是“低质量”的。原因很简单:它并不一定能被模型真正使用。当数据的使用者从「人」变成「模型」,高质量数据的标准,发生了根本变化。主要包含以下方面:
-
可供模型直接处理:数据需经过规范的清洗、标注与格式化处理,形成标准统一的结构,这是模型能够顺利处理的基础。比如将大量格式各异的发票,通过OCR和解析,统一抽取并结构化存储为“发票号、日期、金额、卖方”等固定字段,是训练自动化报销模型的基础。
-
可保证输出准确:数据必须准确、真实、一致,减少错误和噪声,比如去除掉 PDF 文档中没有太大意义的页眉页脚、页码等等,这是模型产出可靠结果的重要前提。
-
可适配具体场景:数据应具备强烈的场景适配性,与行业Know-how深度融合,满足垂直领域的专业术语、流程逻辑和合规要求。比如在智能客服场景,利用历史对话日志,通过自动聚类和意图识别技术,快速归纳出高频问题与标准答案对,作为训练数据
-
可闭环迭代:数据质量能通过“模型表现 → 诊断缺陷 → 优化数据管线 → 重新训练”的流程持续改进,形成以模型反馈驱动数据演进的自优化系统。
-
可支持推理泛化:数据的组织应体现逻辑关系或思维链条,助力模型学会推演与分析,而非简单记忆。比如在数学教育领域,生成海量、符合教学大纲的“题目-分步解答-最终答案”数据,为模型提供丰富的推理链学习素材,无需教师手动编写海量题目。
如何产生这样的 AI-ready 数据
理解了模型训练所需高质量数据的特点之后,一个问题自然出现:这些数据,并不是原始就存在的,那它们到底是如何被稳定、规模化地产生出来的?
答案是:它们不是“整理”出来的,而是“被处理、被构建出来的”。这就是 DataFlow 数据准备系统的核心目标。
1. 从“原始数据”开始,而不是理想数据
现实世界中的数据,大多并不“干净”:
-
PDF 文档结构混乱
-
爬虫文本重复、噪声多
-
内容不完整、表达不统一
如果只依赖人工规则或一次性清洗,这些数据很难直接变成高质量数据。DataFlow 的出发点不是假设数据是干净的,而是承认:低质量、嘈杂数据,才是常态。
2. 通过“算子”,把数据一步步变好
DataFlow 的核心不是一条固定流程,而是一组可复用、可组合的算子。这些算子可以完成不同类型的工作:
-
修正:纠错、重写、标准化表达
-
扩增:补全信息、生成新样本
-
评估:判断数据是否准确、有价值
-
过滤:剔除噪声、重复或低质量内容
每一个算子都很“原子”,但组合起来,就能逐步把原始数据推向高质量数据。
3. 用流水线,把“一次处理”变成“系统能力”
高质量数据不是靠一次加工得到的,而是靠可重复、可演化的流程产生的。DataFlow 通过将算子有序连接,构建数据处理流水线:
-
每一步都有明确目标
-
每一步都可以调整或替换
-
整条流程可以被复用到不同场景
这使得数据准备从“临时工程”变成了长期能力。
4. 用 DataFlow-Agent,让数据工程变得更灵活
当数据准备的需求变得多样,或是已有的算子或流水线无法满足需求时,你就可以使用 DataFlow-Agent 用自然语言:
-
构建新的算子
-
从其他数据源采集、清洗更多的数据
-
动态组合已有算子,生成新的流水线
在 Data-centric AI 的视角下,数据准备本身,已经成为一项核心基础设施能力。而 DataFlow 是一个面向模型的、可执行的数据工程体系,是 AI 系统背后的隐形能力。通过系统化的数据处理能力,持续产出可用于训练、检索和推理的高质量数据。
从传统治理到 AI 原生数据准备的演进路径
传统数据治理的目标很清晰:统一口径、保证质量、控制风险,让数据“对人可读、可解释、可审计”。但当 AI 成为数据的主要使用者时,这套逻辑开始失效。模型不会阅读指标定义,也不会理解业务评审结论,它只关心一件事:在需要的时候,能不能拿到正确、足够、可推理的上下文。
这意味着,AI 时代真正缺的,可能并不是“更严格的数据治理”,而是一种全新的问题视角——数据是否被准备成了 AI 可以直接使用的形态。从这一刻起,数据工作的重心,正在从“治理数据”,转向“为 AI 准备数据(AI-ready 数据)”。
既然传统数据治理和 AI 数据准备关注点不同,企业该如何平滑过渡,让数据既安全合规,又能真正支撑 AI 系统呢?关键在于重心迁移,而不是推倒重来。
首先,要保留传统治理中必要的部分。安全、权限、合规、基础质量仍然不可忽视,它们是数据使用的底层保障。没有这些基础,AI 系统的可持续性和风险控制都会受到影响。
其次,重心需要向模型可用性迁移。具体来说,就是让数据能被模型理解和调用,包括:
-
表示化:将文本、表格、图像等转化为向量或语义片段
-
可检索:建立索引和检索策略,保证模型在需要时能快速找到相关信息
-
流水线化:让数据更新、表示更新、索引更新和模型调用形成闭环,持续支持 AI 推理
在这个过程中,新的基础设施发挥了关键作用。AI 数据库、DataFlow 数据准备系统、RAG 检索系统,都不是简单的工具,而是让数据从原始状态变成模型能力的承载体。企业在搭建这套体系时,不仅是在“整理数据”,更是在“构建模型可用的知识底盘”。
最终,数据工作的评价标准也随之改变:不再只看数据是否干净、一致,而是看模型能否高效、准确地利用数据完成任务。换句话说,数据真正变成了 AI 系统的能力,而不是仅仅被治理起来的资产。
一句话来说:
未来的数据竞争,不是谁拥有最多数据,而是谁能最快、最可靠地把数据准备成 AI 可直接使用的能力。
这也意味着,传统数据治理虽然重要,但在 AI 时代,它只是基础;而 Data-centric AI 数据准备,将成为企业 AI 成功的核心底盘。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 44
44 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)