真实人类活动视频进行机器人操作中可扩展的视觉-语言-动作模型预训练
25年10月来自清华和微软亚洲研究院的论文“Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos”。本文提出一种方法利用大量真实生活中人类手部活动的非脚本视频素材预训练机器人操作视觉-语言-动作(VLA)模型。其将人手视为灵巧的机
25年10月来自清华和微软亚洲研究院的论文“VITRA:Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos”。
本文提出一种方法利用大量真实生活中人类手部活动的非脚本视频素材预训练机器人操作视觉-语言-动作(VLA)模型。其将人手视为灵巧的机器人末端执行器,并证明无需任何标注的“真实场景”中以人为中心的视频可以转换为与现有机器人VLA训练数据在任务粒度和标签方面完全一致的数据格式。这个通过开发一种适用于任意人手视频全自动整体人类活动分析方法实现。该方法可以生成原子级的手部活动片段及其语言描述,每个片段都包含逐帧的3D手部运动和摄像机运动信息。其处理大量以人为中心的视频,并创建一个包含100万个片段和2600万帧的手部VLA训练数据集。该训练数据涵盖现实生活中广泛的物体和概念、灵巧操作任务以及环境变化,远远超过现有机器人数据的覆盖范围。其设计一种灵巧手部VLA模型架构,并使用该数据集对模型进行预训练。该模型在完全未见过的真实世界观测数据上展现出强大的零样本学习能力。此外,在少量真实机器人动作数据上进行微调,显著提高任务成功率和对真实机器人实验中新物体的泛化能力。文中还展示模型任务性能随预训练数据规模的良好扩展性。
近年来,利用人类视频训练机器人模型的研究日益活跃。一些研究[56, 61, 92, 96]利用以自我为中心的人类视频来学习视觉和语言表征。一些方法使用从动作捕捉视频[23, 24, 43, 69, 71, 84]或网络视频[65, 76]中提取的显式人类动作,通过模仿学习框架来指导机器人策略训练。另一些方法则不使用显式动作,而是从人类视频中学习affordance [4, 19, 42, 57]、点轨迹[6, 88, 98]或手-物体掩码[78]。最近,涌现出一系列方法,它们以无监督的方式从人类视频中学习潜动作,并使用潜动作标签预训练动作模型[8, 16, 21, 101, 107]。最近的一些研究尝试从以自我为中心的人类视频中提取3D手部动作标签,用于VLA预训练[7, 55, 100]。如前所述,这些研究主要涉及在受控环境下拍摄的、包含特定信息的视频。另一方面,一些方法利用人类视频来训练视频生成模型,用于人机视频迁移[93, 95]、视觉任务规划[5, 38]或世界模型构建[21, 41, 59]。
现有的机器人操作V-L-A数据[14, 28, 44, 63, 109]通常包含简单的、短时程任务(例如,“拿起桌上的海绵”、“用抹布擦拭炉灶”),这些任务可以通过高级规划器组合成长时程任务。每个数据片段包含一条语言指令、一个视频帧序列以及末端执行器在机器人或摄像机坐标系中帧对齐的3D动作块。本文方法分析一段非脚本化的人类视频,并生成这种格式的V-L-A数据,将人的双手视为末端执行器。整个框架包含三个阶段,其概览如图所示。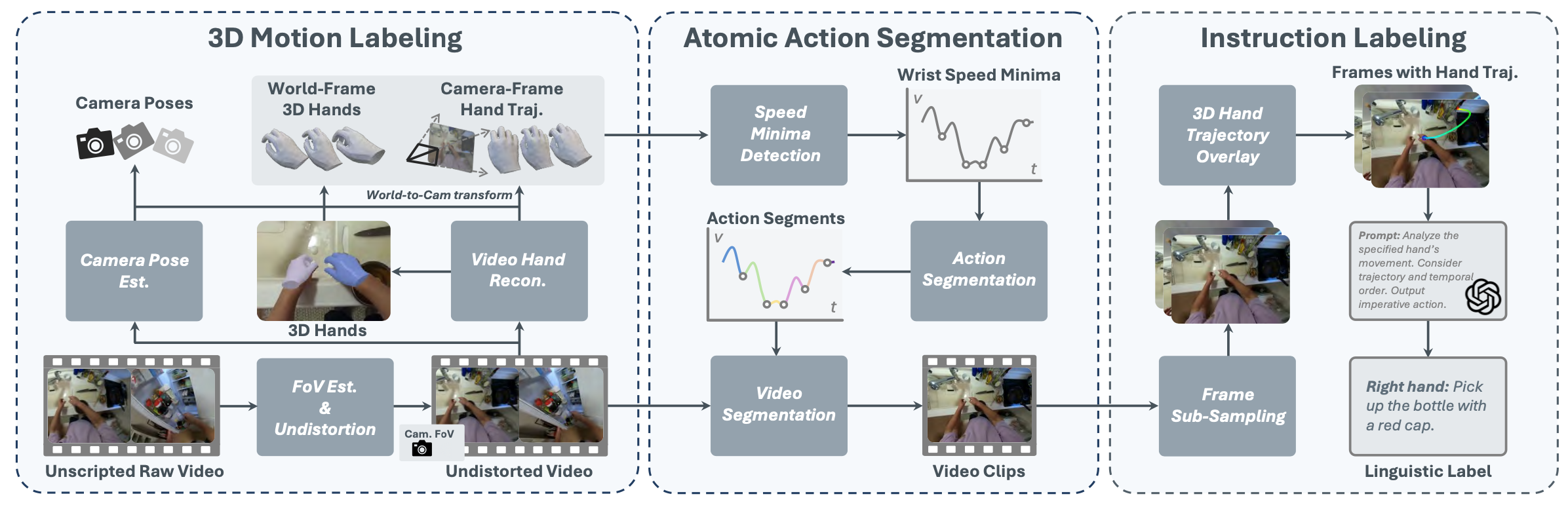
3D运动标注
方法的第一阶段是从视频中提取3D运动,包括双手和摄像机的运动。为此,首先应用一个简单的算法,基于背景光流来判断摄像机是静止的还是运动的。然后,通过应用DroidCalib [33](针对运动摄像机)和MoGe-2 [87] 和DeepCalib [11](针对静止摄像机)来估计视频的摄像机内参。对于畸变较大的视频,进行畸变校正,使其符合针孔相机模型。有了内参和校正后的视频,继续进行视频手部重建和摄像机姿态跟踪。对于前者,采用HaWoR [105] 来重建逐帧的摄像机空间3D手部模型。每个重建的手部模型都包含腕部6D姿态和关节角度,这些姿态和角度由MANO [75] 手部参数模型表示。为了跟踪移动摄像机的位姿,应用MegaSAM [50] 的改进版,其中将用于视觉SLAM的深度先验深度估计模型替换为MoGe-2 [87]。然后,通过结合摄像机空间的3D手部运动和度量尺度摄像机位姿,获得世界空间的3D手部运动序列。最后,对世界空间的手部运动进行样条平滑处理并去除异常值。
世界空间的3D手部运动序列可以轻松转换到任何视频帧的摄像机空间,有效地模拟大多数机器人数据中的静态摄像机。此外,它还有助于后续的原子动作分割和指令标注。为了提高效率,在此阶段将长视频切割成重叠的20秒片段,然后重新组合它们的结果。
原子动作分割
本阶段旨在从长视频中分割出简单的、原子级别的手部动作序列,以符合机器人V-L-A数据的粒度和时间窗口。这并非易事,目前也没有现成的模型能够可靠地应用于此问题。解决方案灵感来源于现实生活中人类手部动作的自然“节拍”。具体而言,在动作转换过程中,人手通常会表现出速度变化,速度最小值往往指示动作的切换。这一观察启发利用已恢复的3D手部运动,设计以下简单却出人意料地有效的算法:检测世界空间中3D手腕的速度最小值,并将其用作分割点。对运动轨迹进行平滑处理,并选择以每个分割点为中心的固定窗口内的局部速度最小值点。分割分别针对左手和右手进行,忽略另一只手的运动。这样,每个分割片段都捕捉到至少一只手的单个原子动作。
值得注意的是,这种方法效率极高,无需额外的模型推理或预标注的文本标签,因此特别适用于可扩展的手部活动视频分割。此外,分割原子级动作片段有助于降低后续指令标注的复杂度。这种策略可能会导致某些动作的过分割(例如,考虑手来回移动的擦拭动作),但这些动作可以在指令标注之后轻松合并。
指令标注
给定视频片段和 3D 手部动作序列,创建可视化图并使用 GPT-4.1 [1] 进行动作标注。从每个片段中,均匀地采样 8 帧,并通过将手掌在世界空间中的轨迹从当前帧投影到片段末尾来突出显示每一帧中的手部轨迹(参见示例)。这些帧随后被输入到GPT中,GPT被要求以祈使句的形式描述指定手部的动作,同时考虑帧的内容和叠加的手部轨迹。还指示GPT将缺乏语义上有意义动作的片段标记为“N/A”。
通过实验发现,为GPT提供原子级视频片段进行字幕标注能够有效提高标注准确率。相比之下,简单地将视频分割成固定长度的片段(例如1秒)会降低准确率,这可能是因为每个片段仍然可能包含多个原子动作,从而增加GPT理解内容的难度。此外,将手部轨迹叠加到图像上对于确保字幕标注的正确性也至关重要,此前的研究已证实,将视觉标记(marker)作为补充提示可以提高标注的准确性[97]。
手部 V-L-A 数据集构建
利用上述框架,通过处理来自 Ego4D [31]、Epic-Kitchen [25]、EgoExo4D [32] 和 Something-Something-V2 (SSV2) [30] 的自我为中心人类视频,构建一个大规模的人手 V-L-A 数据集。需要注意的是,本文并未使用这些数据集提供的动作标注;相反,直接使用框架处理原始视频。这些标注通常与所需的任务粒度不匹配,或者缺乏动作的精确起始和结束时间。在实验中证明,使用这些标注进行训练会导致性能明显下降。构建的数据集包含 100 万个片段,共 2600 万帧(77% 来自 Ego4D,12% 来自 Epic-Kitchen,6% 来自 EgoExo4D,5% 来自 SSV2)。它具有多样化的手部动作、物体、属性和环境,涵盖了烹饪、清洁、建造、修理、工艺制作和绘画等现实生活活动(如图所示)。
构建了一个用于灵巧操作的 VLA 模型 π:
π : (l, o_t, s_t) → (a_t, a_t+1, …, a_t+N)
该模型基于当前的视觉观察 o_t、机器人本体感觉状态 s_t 和语言指令 l 预测未来末端执行器动作序列 a。
VLA模型设计
模型架构
如图展示模型架构概览。模型由VLM骨干网络和扩散动作专家组成。用PaliGemma-2 [80] 作为VLM,它结合用于对齐的SigLIP [102]视觉编码器(采用线性投影)和用于多模态token处理的Gemma-2 [82]语言模型。使用3B参数模型,输入图像分辨率为224²作为默认设置。进一步将相机视场角(FoV)信息作为一个额外token添加到模型中,以帮助其更好地理解原始图像的宽高比和相机内参。参考[48],向VLM添加一个可学习的“认知” token 作为额外输入,其输出特征fc作为动作专家的条件。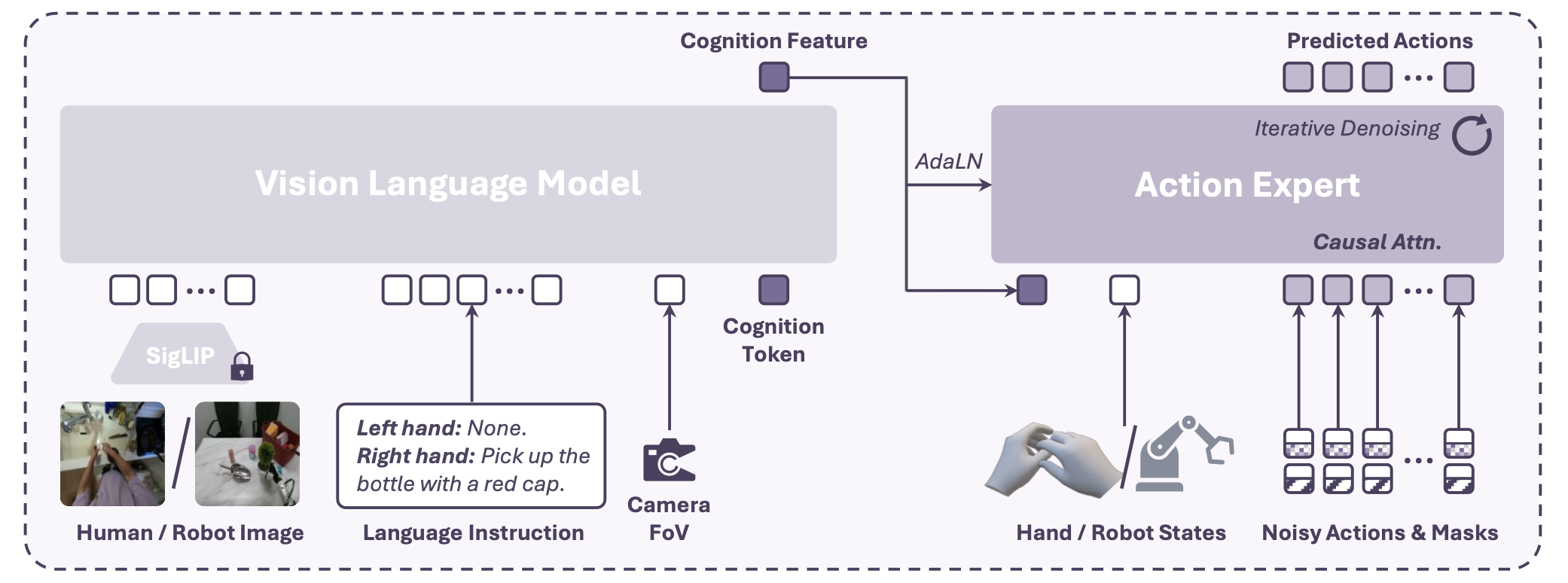
对于动作专家,应用扩散transformer(DiT)[67],默认使用DiT-Base模型。输入是认知特征 fc、手部状态 s_t 和一个带噪声的动作块 (ai_t , ai_t+1 , . . . , ai_t+N) 的拼接,其中 i 表示去噪步骤。手部状态包括当前图像观测中手腕在相机空间中的平移和旋转,以及手部关节角度。模型还提供一组动作掩码,用于指示每个动作是否有效。
此外,还使用 AdaLN [67] 将认知特征注入到 DiT 中,以增强条件。动作专家通过优化 MSE 损失进行训练,从而预测迭代去噪所需的额外噪声。动作专家、VLM 和认知 token进行端到端训练,而视觉编码器保持冻结状态。
手部动作空间
模型预测当前观测值 o_t 的相机坐标系中的手部动作。在时间步 t,定义手部动作 a_t,其中 ∆t 和 ∆r 分别表示相邻帧之间手腕的相对平移和旋转(由旋转矩阵转换而来的欧拉角),θ_h 表示 MANO 手部模型局部坐标系中 15 个关节的欧拉角。上标 l 和 r 分别表示左手和右手。
统一的单手和双手动作预测
VLA预训练数据基于单手原子动作,但部分场景包含重叠的双手动作。为了统一处理这些不同情况,引入以下设计。具体来说,VLM始终接收格式为“左手:<左手动作>”、“右手:<右手动作>”的语言指令。对于视频帧o_t,左手和右手的动作描述分别设置为“无”或o_t对应的原子动作块指令。同时,动作专家始终接收双手的噪声动作。为了处理仅有一只手动作标签的场景,将与动作维度相匹配的额外动作掩码(0或1)与噪声动作沿特征维度连接起来,作为动作专家的输入。当掩码值为0时,相应的噪声动作被设置为0,并从损失计算中排除。
因果动作去噪
在现实生活中,人手移动速度很快,预训练数据集中的许多动作片段只有短短 1 秒(约 30 帧)。因此,对于合理的片段长度(例如,在设置中 N = 16),VLA 模型的许多预测片段会超出episode结束的时间范围。简单地在末尾填充零动作可能会有问题,因为许多原子动作发生在任务过程中,不应该以零动作结束(例如,手来回移动的擦拭任务)。为了解决这个问题,采用因果注意机制进行动作去噪,确保每个动作步骤的token只关注之前的动作。这可以防止零填充的位置影响之前的预测,这与双向注意机制不同。此外,这些填充的位置也会被排除在损失计算之外,因为它们对应的动作掩码被设置为 0。
使用人手VLA数据进行预训练
首先使用构建的数据集训练用于人手动作预测的VLA模型。在训练过程中,对训练图像和动作应用轨迹-觉察增强,以提升模型的泛化能力。具体来说,对输入图像进行随机裁剪和透视变形,改变视场角(FoV)、宽高比和裁剪中心,同时保持主点位于图像中心。动作序列也相应地进行变换,以匹配增强后的相机参数。在随机裁剪过程中,确保从当前帧到episode结束的投影手部轨迹始终位于裁剪后的图像范围内。通过这种策略,交互对象也大多能够被很好地包含在内。还应用随机图像翻转,并对手部动作和语言指令进行相应的调整。当文本描述中没有明确的颜色线索时,会进一步应用随机颜色抖动。
微调以用于机器人灵巧操作
预训练完成后,可以使用机器人数据对模型进行微调,以便部署到机器人上。将人手动作空间视为机器人手动作空间的超集,并按照定义公式将机器人动作空间与人手动作空间对齐。具体而言,用相机坐标系中的机器人末端执行器 6D 位姿来计算 ∆t 和 ∆r。对于关节角度,采用一种简单的映射策略:将机器人手的每个关节映射到其拓扑结构中最接近的人类关节,并使用人类动作中对应的维度 θ_h 进行微调。动作掩码中未映射的维度用零填充。此外,用直接的未来执行指令来监督模型,而不是使用从记录的机器人状态中提取的动作标签。这种方法在手与物体交互过程中能够产生更合理的机械手运动。指令语言格式与预训练期间使用的格式保持一致。
备注:人手和灵巧机器人手之间的动作空间映射在过去已得到广泛研究 [34, 71, 85]。本文并未采用直接姿态迁移(如远程操作中那样),而是通过微调来缓解动作空间差异。其他策略也可采用。
训练详情。预训练阶段,首先对动作专家模型、认知token的映射层以及多层感知器(MLP)的投影视场(FoV)进行5000步的预热。然后,联合微调VLM骨干网络和动作专家模型,共80000步。动作专家模型和VLM的学习率分别为1e-4和1e-5,批大小为512。预训练阶段在8块NVIDIA H100 GPU上耗时2天。在真实机器人数据上进行微调时,用批大小为256、学习率为1e-5的算法对模型进行20000步的优化,这在8块NVIDIA H100 GPU上耗时8小时。
预训练数据分析
如图所示,用词云可视化语言指令中最常用的词汇,并展示随机抽样的任务环境。为了进一步探究数据的多样性,对数据集中的视觉观察和语言指令进行详细分析。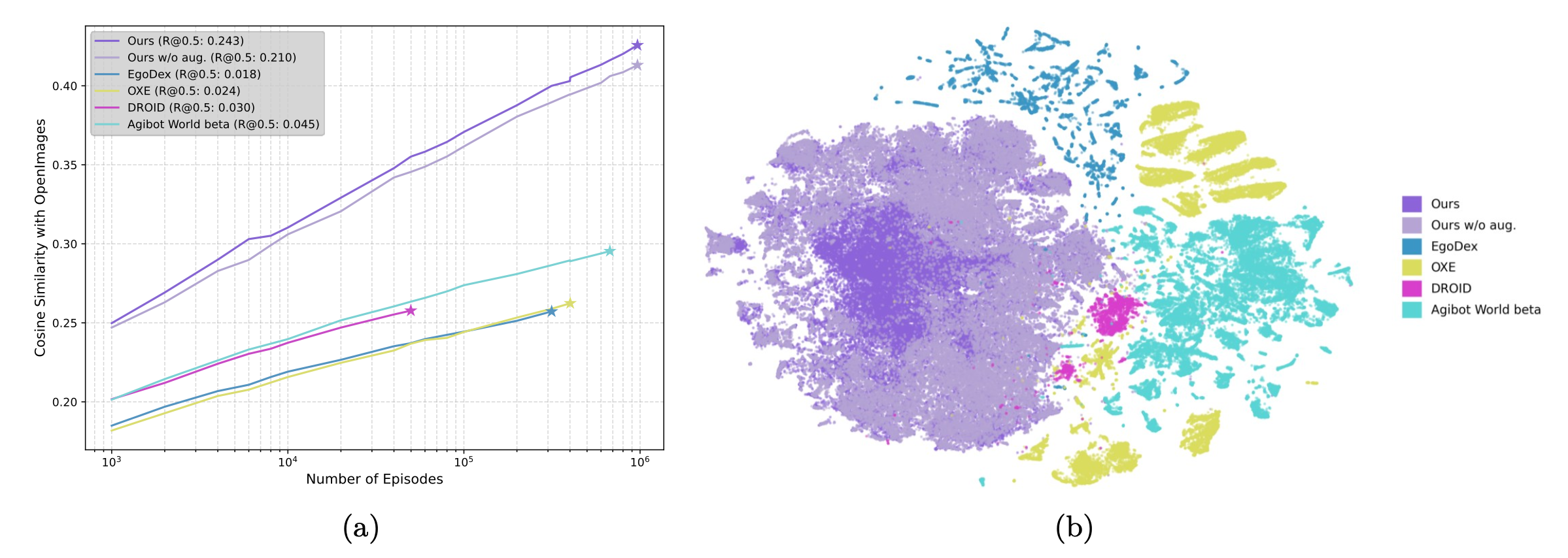
视觉多样性
视觉观测的多样性及其对自然场景的覆盖范围对于增强模型在真实场景中的泛化能力至关重要。为了量化数据集的多样性和覆盖范围,用 OpenImages [47] 数据集作为参考,并计算数据集与其之间的相似度,因为 OpenImages 涵盖了广泛的真实世界场景,并且已知具有高度多样性 [94]。具体来说,从 OpenImages 中随机抽取 8000 张图像作为查询,并使用 DINOv2 [62] 编码器提取它们的特征。对于每个查询特征,计算其与数据集的最大余弦相似度,其中目标特征提取自数据集中每个场景的第一帧。用所有查询特征最大余弦相似度的平均值作为数据集多样性的度量。更高的相似度值表明数据集覆盖 OpenImages 中更大比例的真实世界场景。
指令多样性
语言指令的多样性对于模型执行各种任务至关重要。为了公平地比较具有不同指令格式的数据集,用 GPT-4.1 从每条指令中提取名词、动词和形容词,并分别分析它们的分布情况。
人手动作预测
评估预训练的 VLA 模型在未见过的环境中进行人手动作预测的性能。考察数据集组成、模型架构、训练策略、数据构建策略和数据集规模等关键因素如何影响动作预测性能。首先,介绍用于评估手部动作预测的基准测试,然后系统地分析每个因素如何影响性能。
基准测试
构建一个在未见过的真实环境中进行的基准测试,该测试包含以下两种任务类型:
抓取:指示模型抓取场景中的物体。用 Azure Kinect 从 47 个未见过的环境中采集 RGB-D 图像,并为 396 个物体标注描述信息和分割后的 3D 点云。将合成人手渲染到图像上,距离适合使用单个动作块抓取物体。计算预测手指轨迹与目标物体点之间的最小距离(即 d_hand-obj),以评估动作的合理性。
一般动作:对于更一般的手部动作,定量指标可能无法充分反映预测动作的合理性或正确性。为了解决这个问题,设计一项用户研究,评估在 117 个未曾见过的真实场景中,使用手机拍摄的接触前后的手部动作。对于每个场景,向模型提供带注释的指令,并将预测的手部动作渲染到视频帧上。邀请 23 名参与者对从 117 个场景中随机选择的 30 个场景中预测的前 3 个动作进行排名。这些动作将被分别赋予 3 分、2 分和 1 分,而所有其他动作的得分均为 0 分。然后,报告所有参与者的平均得分,以评估预测动作的合理性。
真实世界机器人灵巧操作
评估针对灵巧操作任务,在少量真实机器人轨迹上微调的 VLA 模型的性能。
机器人设置
用一台配备 12 自由度 XHand 灵巧手和 RealSense 头戴式摄像头的 Realman 机器人,如图 a 所示。该机器人放置在桌面环境中。图 b 展示用于微调的 XHand 与人手之间的关节映射。为了采集真实机器人数据,采用如图 c 所示的远程操作系统。该系统由两个与 Realman 机器人手臂拓扑结构相匹配的远程操作臂组成,用于控制末端执行器的 6D 位姿;此外,在机械臂末端还配备一副 MANUS 远程操作手套,用于控制灵巧手的关节角度。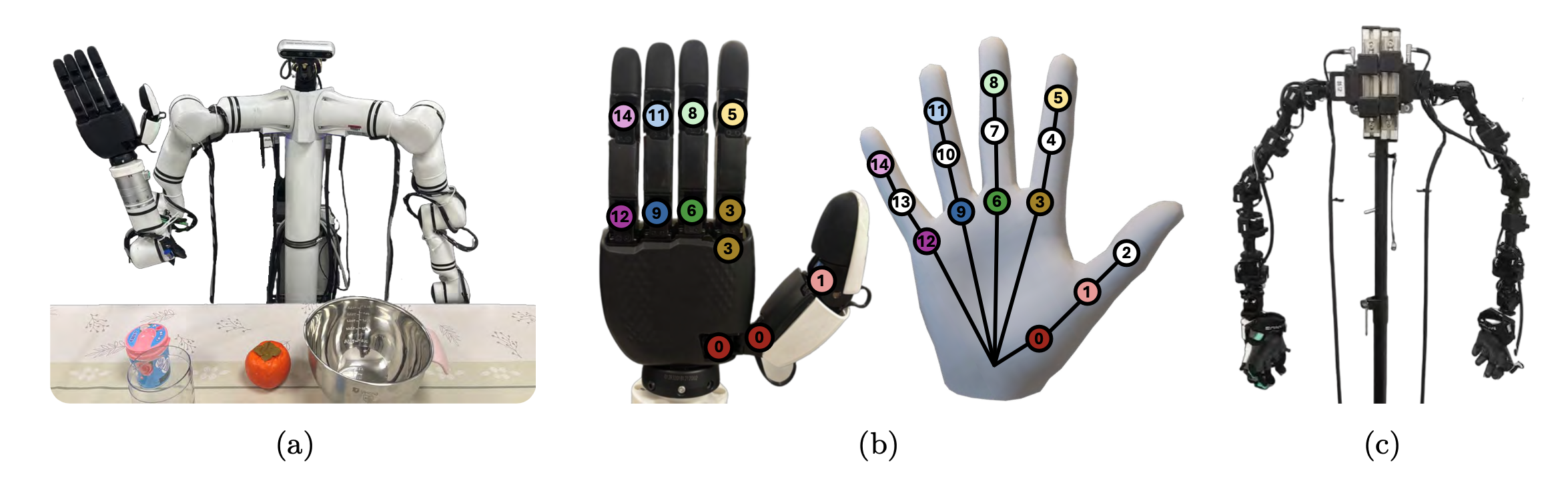
任务设计
收集 1200 条遥控轨迹,用于四项任务:i) 一般拾取和放置——将物体放入一个包含 3-4 个随机干扰物的盒子中;ii) 功能性抓取——抓取物体的功能位置(例如,把手);iii) 倾倒——拿起一个瓶子,将其内容物倒入另一个容器中,然后将其放回桌面上;iv) 清扫——从篮子中拿起扫帚,将垃圾扫入簸箕中,然后放回扫帚。为了进行评估,在见过和未见过两种设置下执行上述任务(物体和背景如图所示):
见过物体和背景在微调阶段被观察;在评估阶段添加随机位置和干扰物。
未见过物体和背景用于评估,并包含两种附加设置:未见过物体,其中物体是新的,但在微调阶段观察到相同类别的其他物体;以及未见过的类别,其中目标属于以前从未遇到的类别。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献172条内容
已为社区贡献172条内容

所有评论(0)