关于spring ai以及RAG的一些比较突出的亮点,可以写在简历上的那种(2)
这段代码的作用和它的作用类似只不过是更全面更自定义化,里面最关键的也就是只有一个变量也就是LoveAppContextualQueryAugmenterFactory.createInstance()这个,来咱们看一下这个的代码。分片重叠数相邻两个分片之间重叠的令牌数(比如 100 表示前一个分片的最后 100 个 Token 会和后一个分片的开头重叠),目的是避免语义割裂(比如一句话被切成两半)
1.之前咱们不是提到过可以设置相似阈值(达到这个相似度阈值才配被选为上下阿文)、返回文档数量(匹配到的上下文的个数)、 过滤条件吗。下面是给本地的vocostrore加的这些的条件。
先来回顾一下本地的那个vocostrore上一章有提到。
代码如下:
package com.yupi.yuaiagent.rag;
import jakarta.annotation.Resource;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
/**
* 恋爱大师向量数据库配置(初始化基于内存的向量数据库 Bean)
*/
@Configuration
public class LoveAppVectorStoreConfig {
@Resource
private LoveAppDocumentLoader loveAppDocumentLoader;
@Resource
private MyTokenTextSplitter myTokenTextSplitter;
@Resource
private MyKeywordEnricher myKeywordEnricher;
@Bean
VectorStore loveAppVectorStore(EmbeddingModel dashscopeEmbeddingModel) {
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashscopeEmbeddingModel).build();
// 加载文档
List<Document> documentList = loveAppDocumentLoader.loadMarkdowns();
// 自主切分文档
List<Document> splitDocuments = myTokenTextSplitter.splitCustomized(documentList);
// 自动补充关键词元信息
List<Document> enrichedDocuments = myKeywordEnricher.enrichDocuments(splitDocuments );
simpleVectorStore.add(enrichedDocuments);
return simpleVectorStore;
}
}
然后咱们来看加条件的代码,这段代码也就是自定义的advisors,默认的advisors是
QuestionAnswerAdvisor(loveAppVectorStore)这个根本没有咱们上述说的那些内容。
来看咱们所说的那个内容的代码;
package com.yupi.yuaiagent.rag;
import org.springframework.ai.chat.client.advisor.api.Advisor;
import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;
import org.springframework.ai.rag.retrieval.search.DocumentRetriever;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.filter.Filter;
import org.springframework.ai.vectorstore.filter.FilterExpressionBuilder;
/**
* 创建自定义的 RAG 检索增强顾问的工厂
*/
public class LoveAppRagCustomAdvisorFactory {
/**
* 创建自定义的 RAG 检索增强顾问
*
* @param vectorStore 向量存储
* @param status 状态
* @return 自定义的 RAG 检索增强顾问
*/
public static Advisor createLoveAppRagCustomAdvisor(VectorStore vectorStore, String status) {
// 过滤特定状态的文档
Filter.Expression expression = new FilterExpressionBuilder()
.eq("status", status)//标签
.build();
// 创建文档检索器
DocumentRetriever documentRetriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.filterExpression(expression) // 过滤条件
.similarityThreshold(0.5) // 相似度阈值
.topK(3) // 返回文档数量
.build();
return RetrievalAugmentationAdvisor.builder()
.documentRetriever(documentRetriever)
.queryAugmenter(LoveAppContextualQueryAugmenterFactory.createInstance())
.build();
}
}
这段代码相信大部分都可以看懂,但是
.queryAugmenter(LoveAppContextualQueryAugmenterFactory.createInstance())
这一行可能会有人有疑问,这是什么代码干什么用的。在说它的作用之前我们回顾一下那个QuestionAnswerAdvisor的作用是不是还有一个就是当在向量库找不到上下文的时候,就返回给大模型说回答你不知道。我的上一篇有讲为什么,底层源码也有。
这段代码的作用和它的作用类似只不过是更全面更自定义化,里面最关键的也就是只有一个变量也就是LoveAppContextualQueryAugmenterFactory.createInstance()这个,来咱们看一下这个的代码
代码示例:
package com.yupi.yuaiagent.rag;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.rag.generation.augmentation.ContextualQueryAugmenter;
/**
* 创建上下文查询增强器的工厂
*/
public class LoveAppContextualQueryAugmenterFactory {
public static ContextualQueryAugmenter createInstance() {
PromptTemplate emptyContextPromptTemplate = new PromptTemplate("""
你应该输出下面的内容:
抱歉,我只能回复**相关的问题,别的没办法帮到您哦,
""");
return ContextualQueryAugmenter.builder()
.allowEmptyContext(false)
.emptyContextPromptTemplate(emptyContextPromptTemplate)
.build();
}
}
这个绿色的字就是你自定义的当在向量库中找不到上下文的时候把这个绿色的话和问题给大模型。
接下来我还要补充之前的一些知识。
来看这个代码:
package com.yupi.yuaiagent.rag;
import jakarta.annotation.Resource;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
/**
* 恋爱大师向量数据库配置(初始化基于内存的向量数据库 Bean)
*/
@Configuration
public class LoveAppVectorStoreConfig {
@Resource
private LoveAppDocumentLoader loveAppDocumentLoader;
@Resource
private MyTokenTextSplitter myTokenTextSplitter;
@Resource
private MyKeywordEnricher myKeywordEnricher;
@Bean
VectorStore loveAppVectorStore(EmbeddingModel dashscopeEmbeddingModel) {
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashscopeEmbeddingModel).build();
// 加载文档
List<Document> documentList = loveAppDocumentLoader.loadMarkdowns();
// 自主切分文档
List<Document> splitDocuments = myTokenTextSplitter.splitCustomized(documentList);
// 自动补充关键词元信息
List<Document> enrichedDocuments = myKeywordEnricher.enrichDocuments(splitDocuments );
simpleVectorStore.add(enrichedDocuments);
return simpleVectorStore;
}
}
List<Document> documentList = loveAppDocumentLoader.loadMarkdowns(); 这个就是从文件中读取文档数据存入documentlist,这个不用多说 // 自主切分文档 List<Document> splitDocuments = myTokenTextSplitter.splitCustomized(documentList); 这段代码就myTokenTextSplitter.splitCustomized这个我上一篇没有来讲解,这一篇来讲解一下。 来看这个方法的代码:
package com.yupi.yuaiagent.rag;
import org.springframework.ai.document.Document;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.stereotype.Component;
import java.util.List;
/**
* 自定义基于 Token 的切词器
*/
@Component
class MyTokenTextSplitter {
public List<Document> splitDocuments(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter();
return splitter.apply(documents);
}
public List<Document> splitCustomized(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter(200, 100, 10, 5000, true);
return splitter.apply(documents);
}
}
new TokenTextSplitter(200, 100, 10, 5000, true);这几个参数的作用分别是chunkSize分片大小每个文本分片的最大令牌数(比如 200 表示每个分片最多包含 200 个 Token),是分片的核心控制参数。第 2 个100chunkOverlap分片重叠数相邻两个分片之间重叠的令牌数(比如 100 表示前一个分片的最后 100 个 Token 会和后一个分片的开头重叠),目的是避免语义割裂(比如一句话被切成两半)。第 3 个10tokenizerEncoding(或 encodingNamegpt2相关) 编码相关参数通常代表令牌化的编码方式 / 版本(比如 10 对应特定的 Tokenizer 编码配置,不同数值对应不同的分词规则,常见于 OpenAI/GPT 系列的 Token 计算)。第 4 个5000maxTokenLength最大令牌长度单个原始文本的最大令牌上限(超过 5000 个 Token 的文本会被优先过滤 / 特殊处理,避免 Token 数超限导致处理失败)。第 5 个truestripWhitespace去除空白符布尔值,true表示分割文本前会自动去除文本中的多余空白符(比如换行、连续空格),false则保留原始空白格式。 这就是按这个规则来进行切片,上一篇光说了切片没说为什么。 // 自动补充关键词元信息 List<Document> enrichedDocuments = myKeywordEnricher.enrichDocuments(splitDocuments );
当然这里也是用了这个myKeywordEnricher.enrichDocuments方法。
首先我来解释一下什么是词元(元数据),然后在看代码。
元数据就是描述「核心数据」的辅助数据,简单说:
- 核心数据:你处理的文档正文内容(比如 RAG 教程、业务文档的文字),是你最终要检索、让模型分析的主体;
- 元数据:给这份正文贴的 **“标签 / 属性 / 说明”**,用来描述正文的特征、属性、关联信息,本身不承载核心业务语义,但能让程序 / 检索系统更高效地管理、筛选、匹配核心数据。
类比:核心数据是一本书的正文,元数据就是这本书的封面 / 目录信息(书名、作者、分类、出版社、关键词、页码)—— 正文是核心,封面信息能让你快速找到这本书,而不用读完整本。
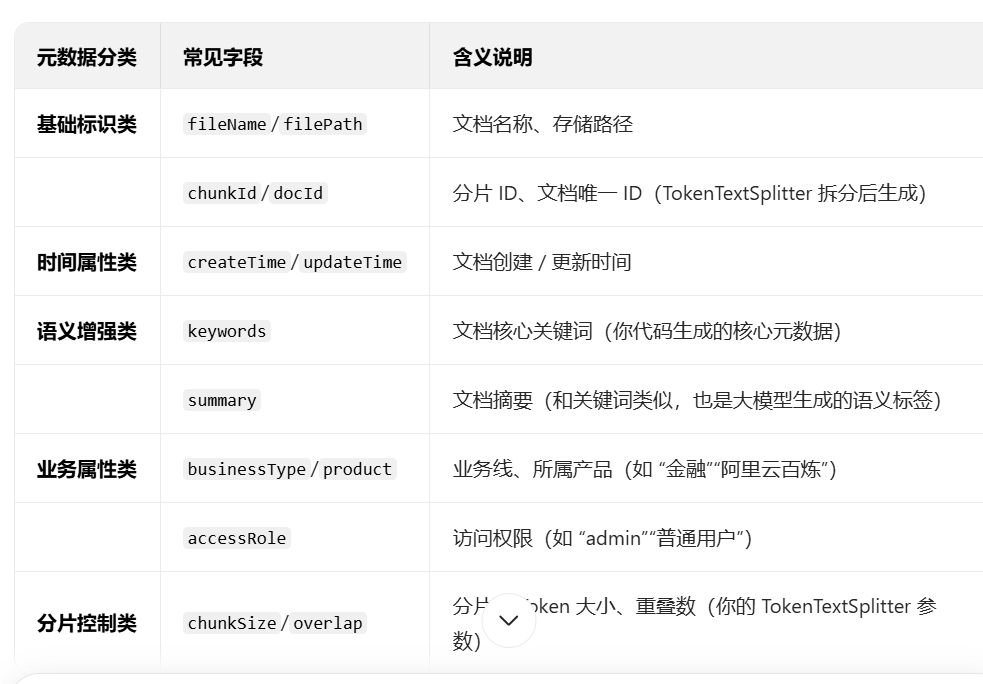
来看示例代码:
package com.yupi.yuaiagent.rag;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.document.Document;
import org.springframework.ai.model.transformer.KeywordMetadataEnricher;
import org.springframework.stereotype.Component;
import java.util.List;
/**
* 基于 AI 的文档元信息增强器(为文档补充元信息)
*/
@Component
public class MyKeywordEnricher {
@Resource
private ChatModel dashscopeChatModel;
public List<Document> enrichDocuments(List<Document> documents) {
KeywordMetadataEnricher keywordMetadataEnricher = new KeywordMetadataEnricher(dashscopeChatModel, 5);
return keywordMetadataEnricher.apply(documents);
}
}
new KeywordMetadataEnricher(dashscopeChatModel, 5);这里面就需要俩参数dashscopeChatModel和 5,第一个明显是大模型的类型,第二个就是要用这个大模型分几个元数据
下面咱们来讲语义拓展:
代码示例如下:
package com.yupi.yuaiagent.demo.rag;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.rag.Query;
import org.springframework.ai.rag.preretrieval.query.expansion.MultiQueryExpander;
import org.springframework.stereotype.Component;
import java.util.List;
/**
* 查询扩展器 Demo
*/
@Component
public class MultiQueryExpanderDemo {
private final ChatClient.Builder chatClientBuilder;
public MultiQueryExpanderDemo(ChatModel dashscopeChatModel) {
this.chatClientBuilder = ChatClient.builder(dashscopeChatModel);
}
public List<Query> expand(String query) {
MultiQueryExpander queryExpander = MultiQueryExpander.builder()
.chatClientBuilder(chatClientBuilder)
.numberOfQueries(3)
.build();
List<Query> queries = queryExpander.expand(new Query(query));
return queries;
}
}
this.chatClientBuilder = ChatClient.builder(dashscopeChatModel);
.chatClientBuilder(chatClientBuilder)
.numberOfQueries(3)
可变的也就这三行里面的参数,ChatClient.builder(dashscopeChatModel);里面是大模型,
numberOfQueries(3)里面的3就是把用户的 问题细分成三个,看下面这个例子
输入原始查询:
彭于晏是谁
↓ MultiQueryExpander调用DashScope大模型,按numberOfQueries(3)生成扩展查询
↓ 生成3个扩展查询: ① 彭于晏的职业和身份是什么? ② 彭于晏的代表作品有哪些? ③ 彭于晏的个人基本信息介绍?
↓ 每个扩展查询分别向量化,去向量库检索相关文档
↓ 合并3次检索的结果(去重、排序)
↓ 把合并后的文档+原始查询传给大模型,生成最终回答
这就是语义拓展
来看上一篇没讲的过滤就是在存入vocstore的时候进行的一些设置
package com.yupi.yuaiagent.rag;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.markdown.MarkdownDocumentReader;
import org.springframework.ai.reader.markdown.config.MarkdownDocumentReaderConfig;
import org.springframework.core.io.Resource;
import org.springframework.core.io.support.ResourcePatternResolver;
import org.springframework.stereotype.Component;
import org.springframework.transaction.ConfigurableTransactionManager;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* 恋爱大师应用文档加载器
*/
@Component
@Slf4j
public class LoveAppDocumentLoader {
private final ResourcePatternResolver resourcePatternResolver;
public LoveAppDocumentLoader(ResourcePatternResolver resourcePatternResolver) {
this.resourcePatternResolver = resourcePatternResolver;
}
/**
* 加载多篇 Markdown 文档
* @return
*/
public List<Document> loadMarkdowns() {
List<Document> documents = new ArrayList<>();
try {
Resource[] resources= resourcePatternResolver.getResources("classpath:documents/*.md");
for (Resource resource : resources) {
String filename = resource.getFilename();
MarkdownDocumentReaderConfig markdownDocumentReaderConfig=MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeBlockquote(false)
.withIncludeCodeBlock(false)
.withAdditionalMetadata("filename",filename)
.withAdditionalMetadata("status",filename)
.build();
MarkdownDocumentReader markdownDocumentReader=new MarkdownDocumentReader(resource,markdownDocumentReaderConfig);
documents.addAll(markdownDocumentReader.get());
}
} catch (IOException e) {
log.error("loadMarkdowns加载异常", e);
}
return documents;
}
}
.withAdditionalMetadata("status",filename)这一行就是加元数据。跟上面那个过滤
Filter.Expression expression = new FilterExpressionBuilder()
.eq("status", status)//标签
.build();
相对应,就是只找status为filename的切片,如果找不到就是之前说的返回
.queryAugmenter(LoveAppContextualQueryAugmenterFactory.createInstance())。
怎么弄标签的代码如下:
public String tag(String userQuery) {
String prompt = """
请根据用户问题判断它属于哪一类,并只返回标签。
可选标签:单身、恋爱、工作、学习、情绪、其他
只返回标签,不要返回其他内容。
用户问题:%s
""".formatted(userQuery);
// 调用大模型获取标签
String answer = chatClient.prompt()
.user(prompt)
.call()
.content();
return answer.trim();
}
/**
* 和 RAG 知识库进行对话
*
* @param message
* @param chatId
* @return
*/
public String doChatWithRag(String message, String chatId) {
// 自动给用户问题贴标签
String answer=tag(message);
// 查询重写
String rewrittenMessage = queryRewriter.doQueryRewrite(message);
ChatResponse chatResponse = chatClient
.prompt()
// 使用改写后的查询
.user(rewrittenMessage)
.advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId))
// 开启日志,便于观察效果
.advisors(new MyLoggerAdvisor())
// 应用 RAG 知识库问答
// .advisors(new QuestionAnswerAdvisor(loveAppVectorStore))
// 应用 RAG 检索增强服务(基于云知识库服务)
// .advisors(loveAppRagCloudAdvisor)
// 应用 RAG 检索增强服务(基于 PgVector 向量存储)
// .advisors(new QuestionAnswerAdvisor(pgVectorVectorStore))
// 应用自定义的 RAG 检索增强服务(文档查询器 + 上下文增强器)
.advisors(
LoveAppRagCustomAdvisorFactory.createLoveAppRagCustomAdvisor(
loveAppVectorStore, answer
)
)
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
log.info("content: {}", content);
return content;
}这是业务代码
其实这里消耗的token也不少因为tag那一步就调用了ai进行了一次对话。
这里就俩参数
loveAppVectorStore, answer
一个是向量库,一个是status,但是如果在云平台设置更方便。
下面是查询重写转换器,核心是调用大模型优化用户原始查询;
package com.yupi.yuaiagent.rag;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.rag.Query;
import org.springframework.ai.rag.preretrieval.query.transformation.QueryTransformer;
import org.springframework.ai.rag.preretrieval.query.transformation.RewriteQueryTransformer;
import org.springframework.stereotype.Component;
/**
* 查询重写器
*/
@Component
public class QueryRewriter {
private final QueryTransformer queryTransformer;
public QueryRewriter(ChatModel dashscopeChatModel)
{
ChatClient.Builder builder = ChatClient.builder(dashscopeChatModel);
queryTransformer= RewriteQueryTransformer.builder()
.chatClientBuilder(builder).build();
}
/**
* 执行查询重写
*
* @param prompt
* @return
*/
public String doQueryRewrite(String prompt) {
Query query = new Query(prompt);
// 执行查询重写
Query transformedQuery = queryTransformer.transform(query);
// 输出重写后的查询
return transformedQuery.text();
}
}
上面 String rewrittenMessage = queryRewriter.doQueryRewrite(message);这一行有使用。
举例:
假设:
targetSearchSystem = "向量数据库"- 提示词模板 =
将{query}改写为适配{target}检索的精准查询,仅返回查询语句,不要额外内容 - 用户原始查询 =
我是单身,怎么办?
执行流程:
- 大模型收到的完整提示词:
将我是单身,怎么办?改写为适配向量数据库检索的精准查询,仅返回查询语句,不要额外内容; - 大模型返回:
单身人群的脱单方法和建议; - 方法返回新的
Query对象,文本为单身人群的脱单方法和建议; - 后续检索时,用这个优化后的查询去向量库找文档,精准度更高。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)