DeepSpeed大模型训练完全指南:从零开始掌握高效分布式训练技术,收藏必备
DeepSpeed是微软开源的大规模模型训练优化库,通过3D并行、ZeRO优化和混合精度训练等关键技术显著提升训练效率。文章系统介绍了DeepSpeed的核心架构,包括API接口、运行时环境和高效算子实现,并详细解析了优化器选择、混合精度训练等关键技术原理。同时提供了从安装配置到模型训练全流程的实践指南,涵盖数据处理、参数调优和监控工具使用。该库基于PyTorch构建,支持开发者轻松迁移现有项目,
DeepSpeed是微软开源的大模型训练优化库,提供3D并行、ZeRO优化、混合精度等关键技术,显著提升训练效率和规模。文章详解核心组件、优化技术及实践指南,涵盖安装配置、模型加载、数据处理、训练执行全流程,并介绍监控工具与参数调优方法,助力开发者高效训练超大规模模型。
DeepSpeed
DeepSpeed 是一个由 Microsoft 开源大模型训练优化库,它提供了多种优化技术,包括:3D 并行策略、梯度累积、动态精度缩放、本地模式混合精度等。还提供了一系列辅助工具,例如:分布式训练管理、内存优化和模型压缩。旨在提高大模型训练的效率和规模可扩展性,帮助开发者更好地管理和优化大规模训练任务。
- 官方网站:https://www.deepspeed.ai/
- github:https://github.com/deepspeedai/DeepSpeed
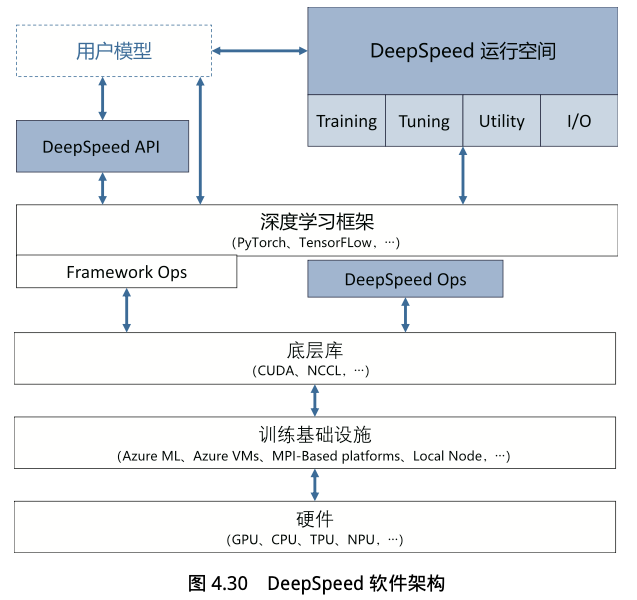
- DeepSpeed API:DeepSpeed 作为一个优化库,提供了多个函数接口,用户只需调用几个函数接口就可以实现训练任务的编排,而优化技术的参数配置,则通常在 ds_config.json 配置文件中设定。
- DeepSpeed RunTime:是 DeepSpeed 的核心运行时组件,负责将训练任务部署到分布式设备上,还提供了数据加载、3D 并行、系统优化、故障检测、检查点保存等核心功能。基于 PyTorch 构建,因此可以非常简易的将现有的 PyTorch 训练代码迁移到 DeepSpeed 上。
- DeepSpeed Ops:是 DeepSpeed 提供的高性能算子实现,使用 C++ 和 CUDA 实现,包括:Ultrafast Transformer Kernels、Fuse LAN Kernels、Customary Deals 等。Ops 的目标是优化了计算和通信过程,加速训练。
训练优化技术
optimizer 优化器
在 AI/ML 中,梯度下降(Gradient Descent)作为标准的 Loss 损失函数极值优化方法,是权重更新的前提。optimizer(优化器)就是一个专门用于梯度计算和权重更新的独立模块,旨在提供高效且准确的权重更新能力。
在早期,根据参与权重更新计算的样本数据量的不同,可以分为以下 3 种常见的梯度下降算法:
- 批量梯度下降(Batch Gradient Descent):每次更新 W(Weight)时,使用整个样本数据集来计算 Loss 的梯度。例如:有 N 个样本,在 Backward 时,每个 W 都有 N 个梯度。此时会先计算 N 个梯度的平均值,然后再使用梯度平均值更新 W 的值。
- 优点:由于使用所有的样本数据,梯度估计非常准确,收敛过程稳定。
- 缺点:当训练数据集很大时,每次计算梯度都非常耗时,而且内存需求高,不适合处理大规模数据。
- 随机梯度下降(Stochastic Gradient Descent,SGD):每次更新 W 时,只使用一个样本数据来计算梯度。在 Backward 时,每个 W 都只有 1 个梯度。此时会直接使用这 1 个梯度来更新 W。
- 优点:只用一个样本数据进行更新,所以计算速度快,适合大规模数据集,且内存占用较小。
- 缺点:由于梯度是基于一个样本计算的,梯度估计不准确,容易导致梯度更新过程中的 “噪声”,使得收敛过程不稳定,并可能在接近最优解时出现振荡。
- 小批量梯度下降(Mini-batch Gradient Descent):介于 Batched 和 SGD 之间。每次更新 W 时,使用一小部分样本数据(Mini-batch)来计算梯度。
- 优点:结合了 Batched 和 SGD 的优点,计算速度比 Batched 快,同时比 SGD 更加稳定,减少了更新中的 “噪声”。
- 缺点:虽然它比 SGD 更稳定,但仍然可能面临一个 mini-batch 中样本量不够多,导致梯度估计仍有一定的偏差。
实际上,上述早期算法在 DL 场景中非常低效,在 LLM 场景中几乎没法用。因为每个 W 都有自己的 “梯度方向” 和 “学习率步长”,有些 W 可能需要更快地更新,而另一些则需要更慢、更稳定。
optimizer 就是一个专用于高效更新 W 的 “自适应学习率” 的优化算法,即:为每个 W 自动计算其独特的学习率。多种优化算法的比较如下图所示,关注 “方向”、“速率” 和 “局部最小” 等方面。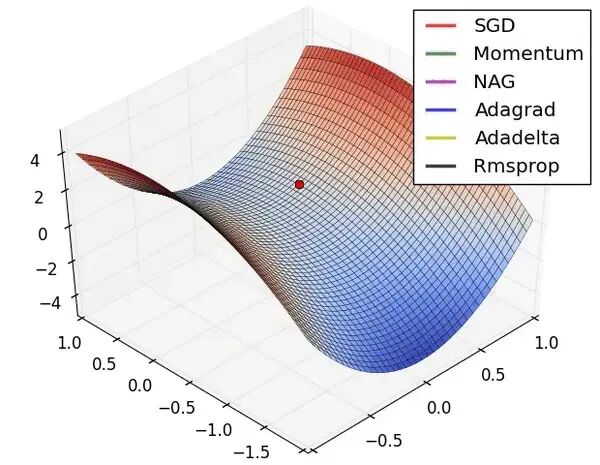
Adam(Adaptive Moment estimation,自适应矩估计)最常见的 Optimizer 之一。它结合了 Momentum(动量)和 RMSprop(自适应学习率)技术,让模型训练得更快更稳,广泛用于 DL 的训练场景。
- Momentum(动量):管理 “梯度方向”,在正确的方向加速,而在不稳定方向减速,能够平滑噪声、有效缓解局部极小值问题。
- RMSprop(自适应学习率):管理 “学习率步长”,根据历史梯度的大小,为每个参数自适应地调整学习率。例如:如果一个参数的历史梯度一直很大,说明它很不稳定,则应该给它一个很小的学习率,避免它 “跳过头”。这有助于加快收敛速度并提高训练稳定性。
在具体实现中,训练时,Adam 始终会在 GPU 显存中维护 2 份额外的 States 状态数据,直到结束后释放。并且这 2 份 States 的大小和权重参数一致,所以在统计显存占用时要乘以 States 的份数。
- m_t 一阶矩(Momentum):作用于 Momentum 机制,是梯度的一阶指数移动平均,它记住了梯度的主要方向。
- v_t 二阶矩(Variance):作用于 RMSProp 机制,是梯度平方的二阶指数移动平均,它记住了梯度的变化幅度,起到了在陡坡小步走、缓坡大步走的作用。
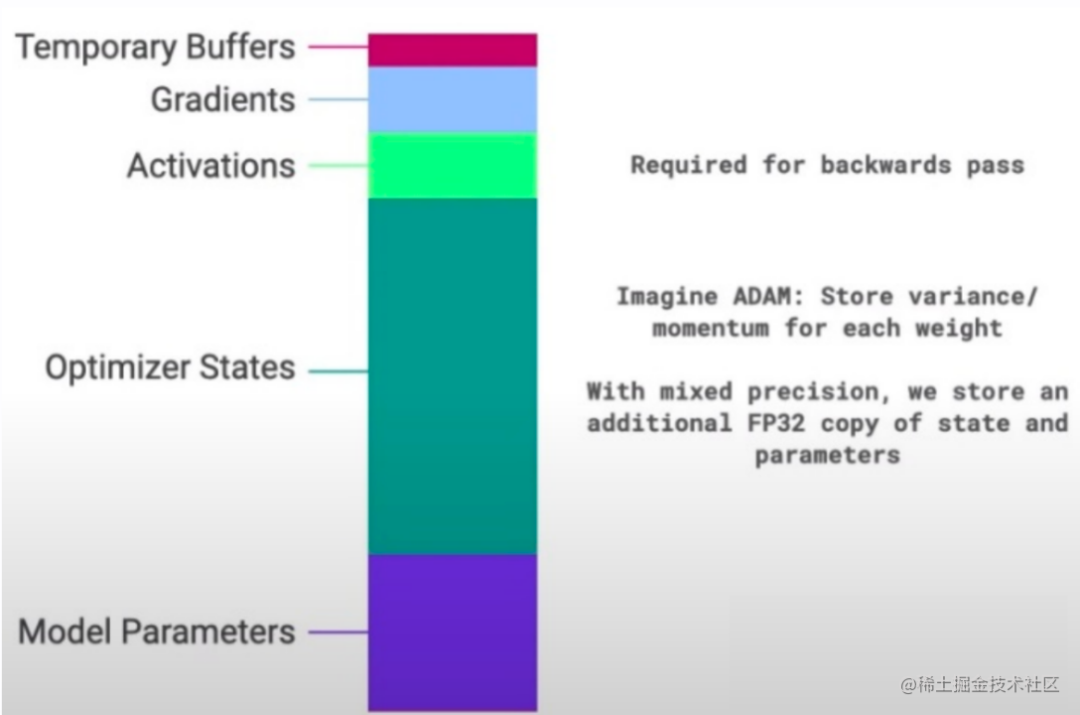
如图所示,使用 Optimizer 后的训练过程中,放入显存的数据包括下列类型。显存优化技术的目标就是逐一 “压缩” 下列数据的显存占用。
- Model Parameter(模型参数)
- Optimizer States(优化器状态)
- Activations(激活函数的输出值)
- Gradients(梯度值)
- Temporary Buffers(临时缓存)及无法使用的显存碎片(Fragmentation)等
 对应的,Adam 有几个关键的超参数可供炼丹调节:
对应的,Adam 有几个关键的超参数可供炼丹调节:
- β₁(Beta1):一阶矩的衰减率,默认为 0.9。控制着 “速度” 的记忆周期。
- β₂(Beta2):二阶矩的衰减率,通常设置为 0.999。这个值越接近 1,意味着它对历史梯度平方的记忆越长,这使得学习率调整非常平滑。
- ε(Epsilon):一个非常小的数(如 1e-8),主要是为了防止除以零的错误。
PyTorch 已经内建了 Adam 优化器的实现(https://docs.pytorch.org/docs/stable/generated/torch.optim.Adam.html),使用 DeepSpeed 的时候可以直接使用 Adam 优化器。
混合精度训练:压缩模型参数、梯度和激活值
在早期 FP32 以极高的精度(尾数大,小数点范围很广)作为标准的训练数据类型,随着 LLM 参数量越来越大,对计算和显存的压力越来越大,促使行业向低精度训练的方向发展。
下面列举不同数据类型的典型和应用场景:
- FP32:3.1415927410125732(π 编码近似值示例),全场景训练,全场景推理。
- FP16:3.1416015625,部分场景训练(混合精度),全场景推理。
- BF16:3.140625,部分场景训练(混合精度),全场景推理。
- INT8:3.125,量化推理场景。
- FP4:3.0,量化推理场景。
混合精度训练(Mixed PrecisionTraining),就是使用多种不同的数据类型进行训练,精细化的节省内存空间。可能会同时存在 FP32、FP16、BF16 等等类型。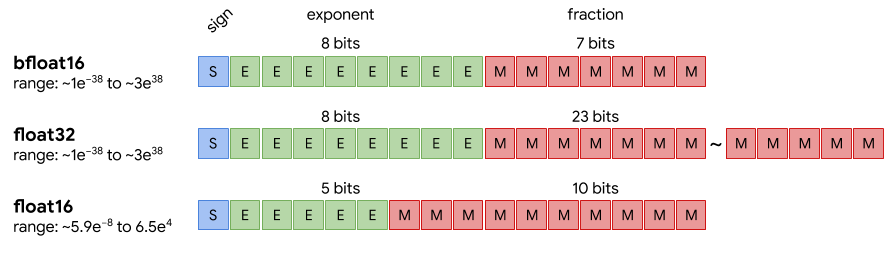 例如:相比 FP32,FP16 可将显存占用减半,计算速度提升 2~3 倍(GPU 对 FP16/BF16 有 Tensor Core 硬件加速)。但是由于 FP16 的指数(绿色,值区间)比 FP32 的小很多,所以在计算过程中很容易出现上溢出和下溢出。而相较于 FP16,BF16 则是以尾数(红色)换取了和 FP32 一样的 Range。
例如:相比 FP32,FP16 可将显存占用减半,计算速度提升 2~3 倍(GPU 对 FP16/BF16 有 Tensor Core 硬件加速)。但是由于 FP16 的指数(绿色,值区间)比 FP32 的小很多,所以在计算过程中很容易出现上溢出和下溢出。而相较于 FP16,BF16 则是以尾数(红色)换取了和 FP32 一样的 Range。
- 精度下溢:小数值(比如梯度值 1e-5)在 FP16 中会被舍入为 0,导致模型无法收敛;
- 梯度上溢:反向传播时梯度值可能超过 FP16 的动态范围(±65504),变成 NaN/Inf,训练崩溃。
因此, 混合精度训练需要使用下列技术来保证使用低精度加速训练的同时不会出现精度丢失的情况。
- 混合精度优化器(Mixed Precision Optimizer):支持用低精度加速训练的同时用高精度保存模型参数。
- 动态损失缩放(Dynamic Loss Scaling):解决反向传播中梯度溢出的问题。
如下图,PyTorch 在 Forward/Backward 阶段使用 FP16 来计算模型参数、梯度和激活值,同时,Adam 混合精度优化器使用 FP32 来保存模型参数和优化器状态数据。
另外,动态损失缩放实现在 Backward 之前,将 Loss 损失值乘以 2K 进行放大,确保 Backward 时从 Loss 往回计算的各层激活函数的梯度时不会下溢(小数值被舍入为 0)。而在 Backward 之后,将权重梯度除以 2K 进行缩小,恢复正常范围用于后续更新模型权重的梯度值。其中 K 是缩放系数,例如 K=16 表示 2^16=65536。具体来说:
- 初始设置:训练得到 Loss=0.0001,选择缩放系数 K=16。
- Backward 前:放大 Loss 0.0001 × 65536 = 6.5536。以此避免 Backward 计算梯度越算越小。
- Backward 时:放大计算激活函数梯度(Backward for Input),放大计算权重梯度(Backward for Weight)。此时还要判断放大后的梯度是否上溢(NaN/Inf),如果上溢,跳过本次权重更新,将 K 减 1 后重试;如果不上溢,则继续更新权重。
- Backward 后:权重梯度 ÷ 65536 进行还原,用还原后的梯度更新 FP32 权重(Adam 混合精度优化器的核心),保证更新精度。
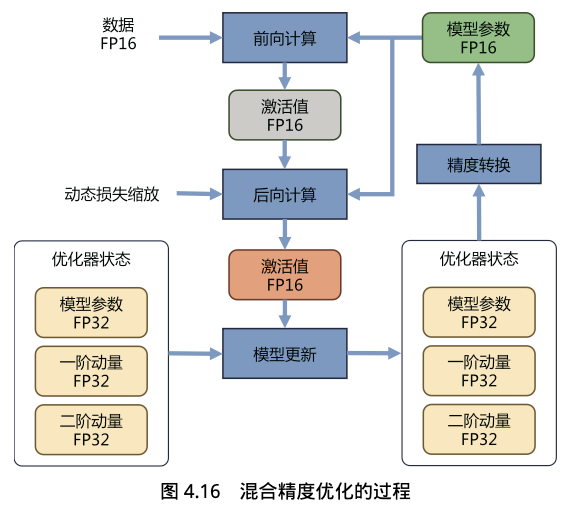
值得注意的是,因为 BF16 和 FP32 的 Range 一样,所以混合精度训练时,因动态范围足够大,无需动态损失缩放。而 FP16 混合精度训练是一定需要搭配动态损失缩放的,否则梯度容易溢出。
在 DeepSpeed 中,通过 --fp16 配置可以直接启用动态损失缩放的混合精度训练,无需额外配置。
Activation Checkpointing:压缩激活值
激活函数值检查点(Activation Checkpointing)的优化思想是有些激活值不必要存储,可以在需要时再计算出来,是一种用计算换显存的做法。所以也称之为 “激活值重计算(Recomputation)”。
具体而言,Recomputation 的实现是在 Forward 时得到的 Activation 不再保留,做 Backward 计算时,对这些 Activation 进行重新计算,这样可以优先减少显存占用。
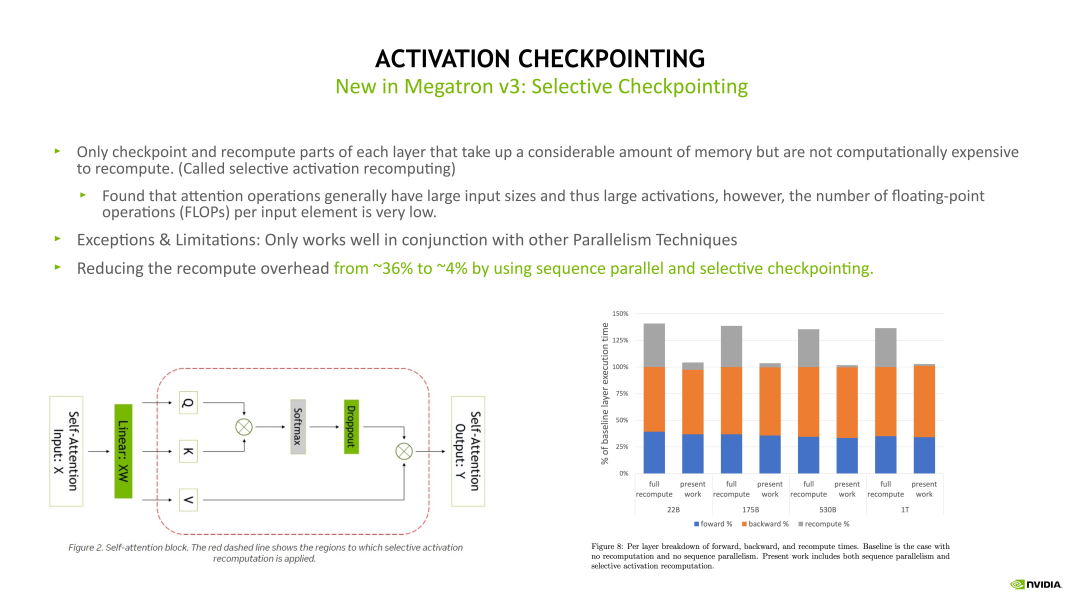
- Full checkpointing:对 Transformer 的每个 layer 都进行重新计算。例如:在最后一层做 Backward 计算时,需要这个 layer 在 Backward 计算之前重新执行一次 Forward 计算,当重新计算 Forward 后再开始这个层的 Backward 计算。Full checkpointing 对每个 layer 都打了一个重算点。所以 Full checkpointing 的好处在于将显存开销降低到 O(n) 的复杂度。但是由于会对每个 layer 都要重新计算一遍,从而带来了近 36% 的额外计算开销。
- Sequence Parallelism & Selective checkpointing:在 Sequence Parallelism 的同时加上 Selective checkpointing,可以将重算的计算开销从 36% 降低到 4%。Selective checkpointing 会选择一些重算性价比高的 OP,比如对一些计算时间比较小但产生 Activation 占用的显存很大的 OP 进行重算。
Megatron-LM 采用较多的是 Selective Activation Checkpointing,例如下图左边的 Self-attention 模块,通过对比分析后得出,对 Self-attention 这块做重算的收益是非常高的,因为它的计算量相对会少一点,但它的一些 Activation 占用显存很大。因此可以只对这块做重算。对其他的层,例如 Linear 和 Layernorm 层,可以采用其他的优化方法对 Activation 进行优化。
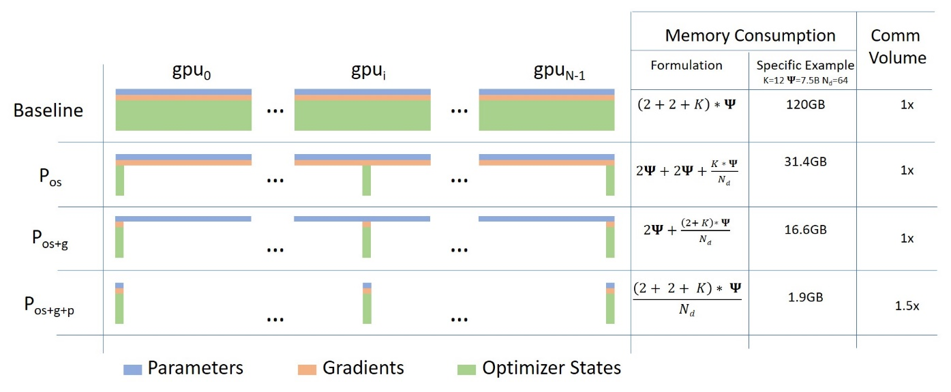
ZeRO:压缩优化器状态
上述可知 Adam 优化器的效率很高,但占用的显存很大,通常数 Model Paramete 的 N 倍。例如:混合进度场景中,Model Parameter、Gradients 和 Activations 使用 FP16,而 Optimizer States 使用 FP32(权重参数、 一阶动量、二阶动量)。如果模型参数量是 Φ,数据类型是 FP16,那么 Model Parameter、Gradient 和 Optimizer States 总计的显存占用为 2Φ + 2Φ + 2x(2Φ + 2Φ + 2Φ) = 16Φ Byte。其中,Optimizer States 状态占比 75%。因此如何减少 Optimizer States 是解决显存优化的关键。
另外,DP 是最常用的并行策略,因为它与其他并行策略正交,实现简单并且通信量相对不是很大,很容易扩展训练的规模。但是 DP “只切数据,不切模型” 的特征,使得 DP 显存开销较大。
ZeRO(Zero Redundancy Data Parallelism Optimizer,零冗余 DP 优化器)是 DeepSpeed 的核心技术,最初的目标是针对 Optimizer States 进行去除冗余的优化。ZeRO 的核心思想是分片,在 DP 的基础之上,DP Group 内的每张 GPU 显存只放 1/N 的 States 数据,这样整个系统中就只需要维护一份完整的 States 数据(去冗余)。
ZeRO 是一种用通信换显存的做法,但这表示 ZeRO 只能应用于分布式并行训练中,并对网络带宽提出了更高的要求。所以 ZeRO 也称之为 Distributed Optimizer(分布式优化器)。
注意:ZeRO 和 PP/TP 有本质区别,ZeRO 切的是数据,PP/TP 切的是模型。
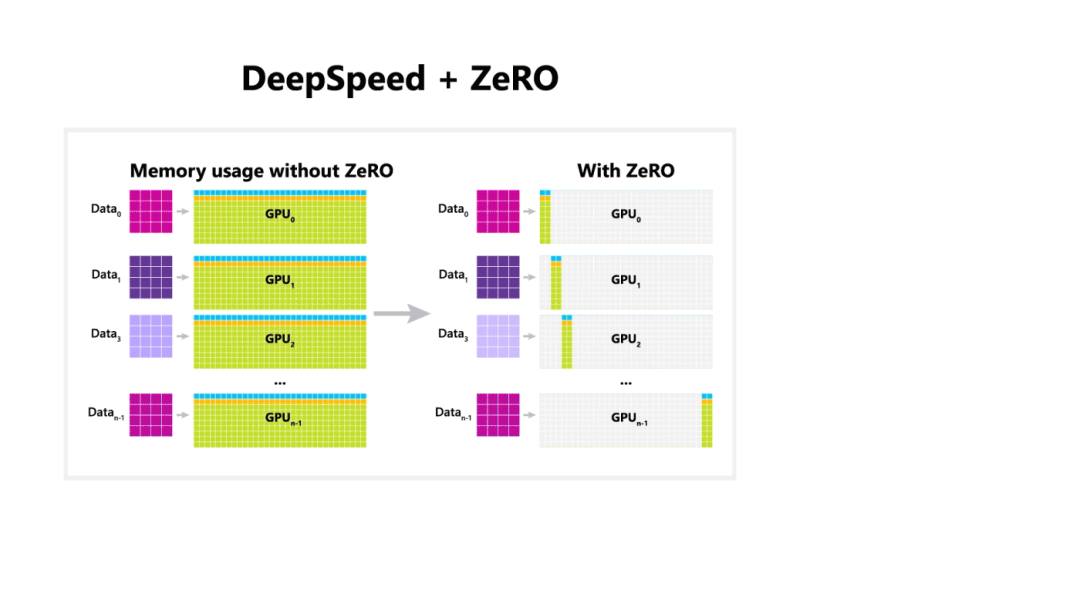
现在,ZeRO 全面支持 Model Parameter(p)、Gradient(g)和 Optimizer States(os)都进行分片:
- ZeRO-1(P_os):
- 划分 Optimizer States,显存节省约 4 倍。每块 GPU 显存是 2Φ + 2Φ + 12Φ/N 字节,当 N(GPU 总数)较大时,每块 GPU 显存趋向于 4ΦB,也就是 16ΦB 的 1/4。
- 不影响 Forward 和 Backward for Input,只影响 Backward for Weight(计算权重梯度),通信量与 DP 相同。
- 适合小模型(<10 亿参数),内存需求适中。
- ZeRO-2(P_os+g):
- 划分 Optimizer States 和 Gradient,显存节省约 8 倍。每块 GPU 显存是 2Φ + (2Φ+12Φ)/N 字节。当 N 比较大时,每块 GPU 显存趋向于 2ΦB,也就是 16ΦB 的 1/8。
- 不影响 Forward,影响 Backward for Input 和 Backward for Weight,通信量与DP 相同。
- 适合中等规模模型(10-100 亿参数),平衡内存和通信。
- ZeRO-3(P_os+g+p):
- 划分 Optimizer States、Gradient 和 Model Parameter,显存占用约等于 Model States 的 1/N(N 为 GPU 数量),每块 GPU 所需显存是 16Φ/N B。
- 会影响 Forward、Backward for Input 和 Backward for Weight,通信量是 DP 的 1.5 倍,因为 Forward 前需要 all-gather 所有参数后才能计算。
- 适合超大规模模型(>100 亿参数),但需优化网络带宽。
- ZeRO-Offload:作为 ZeRO-3 的拓展,支持将上述 Model States 数据都 offload 到 CPU 主存和 NVMe SSD 磁盘中。进一步降低 GPU 显存的占用。极限的场景中,单个 GPU 能够训练比其显存容量大 10 倍的模型。但注意,ZeRO Stage 3 和 Offload 对 CPU 主存和 NVMe 的 I/O 性能敏感,低配硬件会导致性能下降。
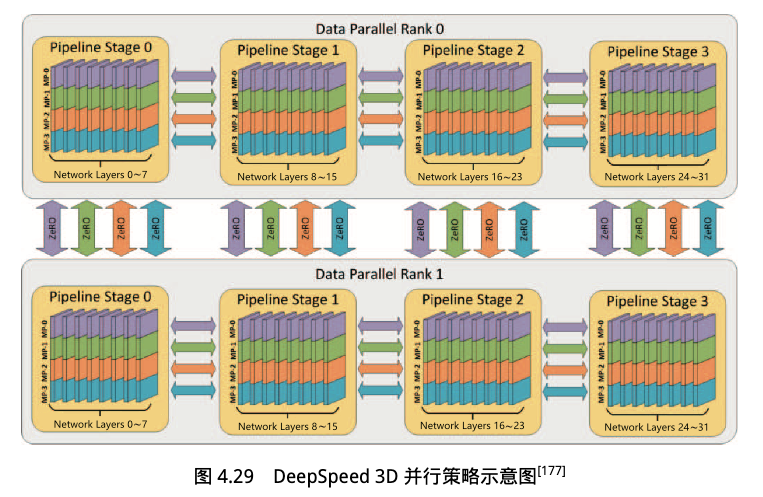
3D 并行策略
3D 并行(数据并行 + 流水线并行 + 张量并行)结合 ZeRO,可在分布式集群上高效训练超大规模模型。下面是 DeepSpeed 3D 并行策略示意图,共计 32 张 GPU。
- 2 个 DP Group
- 每个 DP Group 中有 4 个 PP Stage(和 GPU 一比一),每个 Stage 8 个 Layers。
- 每个 PP Stage(GPU)中有 4 个 TP。
ZeRO 和 DP 结合后,Model States 数据划分在一个 Group 中的不同 GPU 内,不同解决的计算时,通过 all-gather 来进行聚合。
注意,ZeRO-2 和 ZeRO-3 因为划分了模型参数和梯度,所以每次 forward/backward 计算,都需要额外的通信。由于 PP 由将 batch 分为了多个 mini-batch,所以 PP 和 ZeRO-2/3 结合的话会引入很大的通行量。因此不推荐同时使用 PP 和 ZeRO-2/3。
实际上,在炼丹过程中往往需要不断调整 ZeRO 和 3D 并行策略的组合。由于去除冗余和卸载,故从左到右,显存占用越来越少;但由于通信增加,故从左到右越来越慢:Stage 0 (DP) > Stage 1 > Stage 2 > Stage 2 + offload > Stage 3 > Stage 3 + offloads
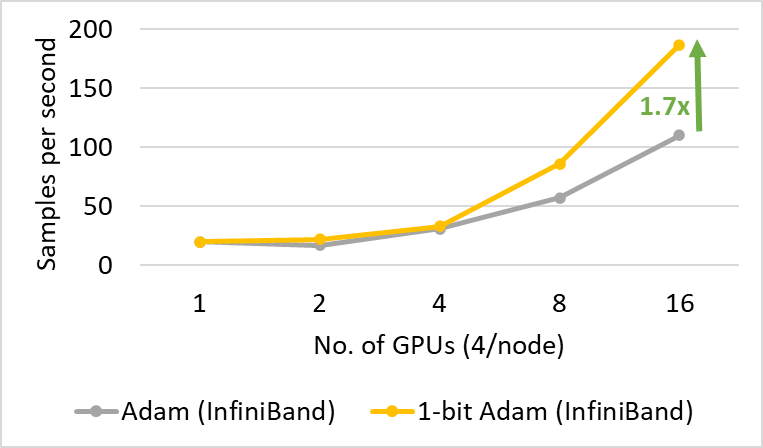
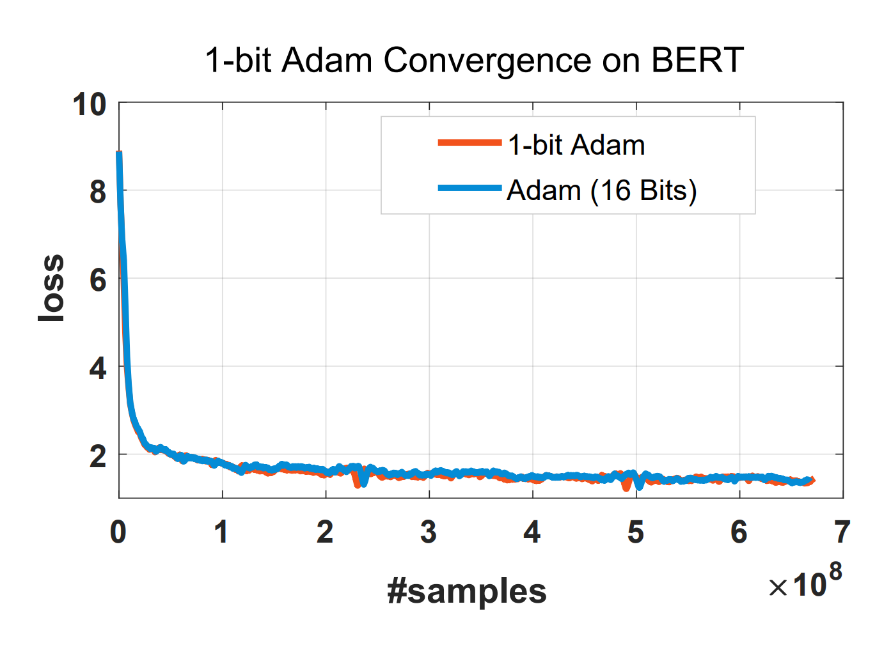
1-bit Adam
在 ZeRO+DP 训练中,瓶颈从显存转为了通信。对此DeepSpeed 还集成了 1-bit Adam 算法来降低通信量。
1-bit Adam 技术的核心目标,就是把 GPU 之间的 Optimizer States 通信数据量压缩到原来的 1/32(FP32→1-bit)或 1/16(FP16→1-bit),大幅降低通信耗时,提升分布式训练速度。
训练实践
安装部署
编译安装:
git clone https://github.com/microsoft/DeepSpeed.git
cd DeepSpeed
DS_BUILD_CPU_ADAM=1 DS_BUILD_AIO=1 DS_BUILD_UTILS=1 pip install -e .
pip 安装:
$ pip install deepspeed
安装验证:
$ ds_report
--------------------------------------------------
DeepSpeed C++/CUDA extension op report
--------------------------------------------------
NOTE: Ops not installed will be just-in-time (JIT) compiled at
runtime if needed. Op compatibility means that your system
meet the required dependencies to JIT install the op.
--------------------------------------------------
JIT compiled ops requires ninja
ninja .................. [OKAY]
--------------------------------------------------
op name ................ installed .. compatible
--------------------------------------------------
[WARNING] async_io requires the dev libaio .so object and headers but these were not found.
[WARNING] async_io: please install the libaio-dev package with apt
[WARNING] If libaio is already installed (perhaps from source), try setting the CFLAGS and LDFLAGS environment variables to where it can be found.
async_io ............... [NO] ....... [NO]
fused_adam ............. [NO] ....... [OKAY]
cpu_adam ............... [NO] ....... [OKAY]
cpu_adagrad ............ [NO] ....... [OKAY]
cpu_lion ............... [NO] ....... [OKAY]
dc ..................... [NO] ....... [OKAY]
[WARNING] Please specify the CUTLASS repo directory as environment variable $CUTLASS_PATH
evoformer_attn ......... [NO] ....... [NO]
[WARNING] FP Quantizer is using an untested triton version (3.5.1), only 2.3.(0, 1) and 3.0.0 are known to be compatible with these kernels
fp_quantizer ........... [NO] ....... [NO]
fused_lamb ............. [NO] ....... [OKAY]
fused_lion ............. [NO] ....... [OKAY]
INFO:root:aarch64-linux-gnu-gcc -fno-strict-overflow -Wsign-compare -DNDEBUG -g -O2 -Wall -fPIC -c /tmp/tmp2encg6f1/test.c -o /tmp/tmp2encg6f1/test.o
INFO:root:aarch64-linux-gnu-gcc /tmp/tmp2encg6f1/test.o -L/usr/local/cuda -L/usr/local/cuda/lib64 -lcufile -o /tmp/tmp2encg6f1/a.out
[WARNING] gds requires the dev libaio .so object and headers but these were not found.
[WARNING] gds: please install the libaio-dev package with apt
[WARNING] If libaio is already installed (perhaps from source), try setting the CFLAGS and LDFLAGS environment variables to where it can be found.
gds .................... [NO] ....... [NO]
transformer_inference .. [NO] ....... [OKAY]
inference_core_ops ..... [NO] ....... [OKAY]
cutlass_ops ............ [NO] ....... [OKAY]
quantizer .............. [NO] ....... [OKAY]
ragged_device_ops ...... [NO] ....... [OKAY]
ragged_ops ............. [NO] ....... [OKAY]
random_ltd ............. [NO] ....... [OKAY]
[WARNING] sparse_attn requires a torch version >= 1.5 and < 2.0 but detected 2.9
[WARNING] using untested triton version (3.5.1), only 1.0.0 is known to be compatible
sparse_attn ............ [NO] ....... [NO]
spatial_inference ...... [NO] ....... [OKAY]
transformer ............ [NO] ....... [OKAY]
stochastic_transformer . [NO] ....... [OKAY]
utils .................. [NO] ....... [OKAY]
--------------------------------------------------
DeepSpeed general environment info:
torch install path ............... ['/usr/local/lib/python3.12/dist-packages/torch']
torch version .................... 2.9.1+cu130
deepspeed install path ........... ['/usr/local/lib/python3.12/dist-packages/deepspeed']
deepspeed info ................... 0.18.3, unknown, unknown
torch cuda version ............... 13.0
torch hip version ................ None
nvcc version ..................... 13.0
deepspeed wheel compiled w. ...... torch 2.9, cuda 13.0
shared memory (/dev/shm) size .... 59.82 GB
配置文件
DeepSpeed 支持多种优化技术的配置参数都可以放在 ds_config.json 配置文件中,并通过指令选项 --deepspeed_config 指定。
- 详细的配置项解析:https://deepspeed.org.cn/docs/config-json/
{
"train_batch_size": 64, // 全局批次大小,所有 GPU 加起来的总批次大小。等于 per_device_batch_size * num_gpus * gradient_accumulation_steps,示例:如果单卡批次大小为 4,8 张 GPU,梯度累积 4 步,则全局批次大小为 4 * 8 * 4 = 128。
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": 4, // 梯度累积步数,执行 N 个 Step 后进行一次 DP all-reduce。
"gradient_clipping": 1.0, // 梯度裁剪,可以防止训练过程中出现梯度爆炸问题。
"fp16": { // 启用混合精度训练。建议始终启用 FP16 或 BF16,除非模型对精度敏感(如某些科学计算任务)。
"enabled": true,
"loss_scale": 0, // 使用动态损失缩放。
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"zero_optimization": { // ZeRO 配置,通信换显存
"stage": 2, // ZeRO-2
"allgather_partitions": true, // all-gather ZeRO 分片聚合
"allgather_bucket_size": 2e8,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"overlap_comm": true, // 通信计算 Overlap
"contiguous_gradients": true,
"offload_optimizer": { // ZeRO Offload Optimizer States
"device": "cpu", // to CPU
"pin_memory": true
}
},
"optimizer": { // 优化器配置
"type": "Adam", // 使用 Adam
"params": {
"lr": 0.001,
"betas": [0.9, 0.999], // 超参数
"eps": 1e-8,
"weight_decay": "auto"
}
},
"scheduler": { // 学习率调度器配置
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.001,
"warmup_num_steps": 1000
}
},
"activation_checkpointing": { // 激活值检查点配置,计算换显存
"partition_activations": true,
"cpu_checkpointing": true
},
"tensorboard": { // TensorBoard 配置
"enabled": true, // 开启可视化
"output_path": "log/", // 可视化文件保存路径
"job_name": "XXX"
}
}
加载模型结构和权重参数
具体代码实现中,我们使用 HuggingFace 的 transformers 库来完成模型的加载工作。
HuggingFace transformers 是一个 Python 库,封装实现了 LLaMA、GPT、BERT、ViT 等上百种主流模型。通过 transformers 库函数,开发者无需实现编写模型的具体实现,而是可以直接使用它们进行训练或推理。例如:使用 AutoModel 类即可一键加载任意模型;使用 Trainer 类即可使用 PyTorch DDP、DeepSpeed、Megatron-LM 等多种分布式训练策略,通过简单配置训练参数,即可开始 DP、PP、TP、EP、SP 混合并行训练。
下面是加载 LLaMA 模型的一个函数实现,通过 LlamaConfig.from_pretrained 从配置文件中生成自定义的模型结构,通过 LlamaForCausalLM.from_pretrained 从权重参数文件中加载参数,通过 model_name_or_path 指定具体的 LLaMA 模型。
- 如果是 model_name 如 meta-llama/Llama-2-7b-hf,那么函数会从 HuggingFace 自动下载模型;
- 如果是 model_path 如 ./chinese-llama-2-1.3b 则函数从本地读取模型。
from transformers import LlamaTokenizer, LlamaConfig, LlamaForCausalLM
def create_llama_model(model_name_or_path):
# 加载分词器
# fast_tokenizer=True 表示使用快速分词器以提高性能
tokenizer = LlamaTokenizer.from_pretrained(
model_name_or_path, fast_tokenizer=True)
# 检查分词器是否有填充符号
# 为了确保词元分析器可以处理各种文本的长度,还需要进行填充设置。 如果词元分析器还没有指定填充符号,则将其设置为 [PAD],并确定填充行为发生在句子的右侧。
if tokenizer.pad_token is None:
# 如果分词器没有定义填充符号,则添加 '[PAD]' 作为填充符号
tokenizer.add_special_tokens({'pad_token': '[PAD]'}) # 添加自定义的填充符号
# 设置填充方向为右侧,表示在序列的右侧添加填充符号
tokenizer.padding_side = 'right'
# 加载模型的配置,以便创建模型时使用
model_config = LlamaConfig.from_pretrained(model_name_or_path)
# 加载预训练的 LLaMA 模型,并使用刚刚加载的配置
model = LlamaForCausalLM.from_pretrained(model_name_or_path, config=model_config)
# 为了保证模型能够正确地处理句子结束和填充,还为模型配置设置了结束符号和填充符号 的 ID。
# 设置模型的结束符号 ID,确保模型能够正确处理句子的结束
model.config.end_token_id = tokenizer.eos_token_id # 设置结束符号的 ID
# 设置模型的填充符号 ID,确保模型能够正确处理填充符号
model.config.pad_token_id = tokenizer.eos_token_id # 将填充符号 ID 设置为结束符号 ID
# 调整词汇表的大小,使其成为 8 的倍数
# 这可以提高模型在硬件上的性能,特别是在某些计算架构上
# math.ceil(len(tokenizer) / 8.0) 将词汇表大小向上取整到最近的 8 的倍数
model.resize_token_embeddings(int(8 * math.ceil(len(tokenizer) / 8.0)))
return model, tokenizer
对于模型数据,如果网络不好,可以先手动下载后再指定 model_path:
$ modelscope download --model AI-ModelScope/chinese-llama-2-1.3b --local_dir=./chinese-llama-2-1.3b
$ ll chinese-llama-2-1.3b/
-rw------- 1 root root 666 Jan 6 08:03 .msc
-rw-r--r-- 1 root root 36 Jan 6 08:03 .mv
-rw-r--r-- 1 root root 3746 Jan 6 07:58 README.md
-rw-r--r-- 1 root root 671 Jan 6 07:58 config.json
-rw-r--r-- 1 root root 48 Jan 6 07:58 configuration.json
-rw-r--r-- 1 root root 170 Jan 6 07:58 generation_config.json
-rw-r--r-- 1 root root 2525057510 Jan 6 08:03 pytorch_model.bin
-rw-r--r-- 1 root root 435 Jan 6 07:58 special_tokens_map.json
-rw-r--r-- 1 root root 2656100 Jan 6 07:58 tokenizer.json
-rw-r--r-- 1 root root 844403 Jan 6 07:58 tokenizer.model
-rw-r--r-- 1 root root 766 Jan 6 07:58 tokenizer_config.json
查看大模型的配置,用于生成自定义的模型结构。
$ cat config.json
{
"_name_or_path": "meta-llama/Llama-2-7b-hf",
"architectures": [
"LlamaForCausalLM"
],
"bos_token_id": 1,
"eos_token_id": 2,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 11008,
"max_length": 4096,
"max_position_embeddings": 4096,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 4,
"num_key_value_heads": 32,
"pad_token_id": 0,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 10000.0,
"tie_word_embeddings": false,
"torch_dtype": "float16",
"transformers_version": "4.33.2",
"use_cache": true,
"vocab_size": 55296
}
模型结构:
(Pdb) model
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(55296, 4096, padding_idx=0)
(layers): ModuleList(
(0-3): 4 x LlamaDecoderLayer(
(self_attn): LlamaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLUActivation()
)
(input_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
(post_attention_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
)
)
(norm): LlamaRMSNorm((4096,), eps=1e-05)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=4096, out_features=55296, bias=False)
)
如果只是想从模型配置文件中加载模型结构,就不用 .from_pretrained 而是用 .from_config。这样相当于从 0 开始进行预训练,这种情况很少。
from transformers import AutoConfig, AutoModelForCausalLM
model_config = AutoConfig.from_pretrained(model_path_or_name)
model = AutoModelForCausalLM.from_config(model_config, trust_remote_code=True)
查看分词器配置,初始化分词器时需要和 tokenizer.model 词表文件结合使用。
$ cat tokenizer_config.json
{
"add_bos_token": true,
"add_eos_token": false,
"bos_token": {
"__type": "AddedToken",
"content": "<s>",
"lstrip": false,
"normalized": true,
"rstrip": false,
"single_word": false
},
"clean_up_tokenization_spaces": false,
"eos_token": {
"__type": "AddedToken",
"content": "</s>",
"lstrip": false,
"normalized": true,
"rstrip": false,
"single_word": false
},
"legacy": true,
"model_max_length": 1000000000000000019884624838656,
"pad_token": null,
"sp_model_kwargs": {},
"tokenizer_class": "LlamaTokenizer",
"unk_token": {
"__type": "AddedToken",
"content": "<unk>",
"lstrip": false,
"normalized": true,
"rstrip": false,
"single_word": false
},
"use_fast": false
}
准备样本数据集
HuggingFace datasets 也是一个 Python 库,和 transformers 库结合使用,用于下载样本数据集的 Raw 原文件,默认为 Dataset 格式。
- load_dataset:从 HuggingFace 下载数据集,下载后缓存路径为 ~/.cache/huggingface/datasets/Dahoas___rm-static/。
- load_from_disk:从本地磁盘读取数据集,只能读取 HuggingFace Dataset 格式,目录包含 .arrow 等文件,例如:rm-static-train.arrow。
from datasets import load_dataset, load_from_disk
# The template prompt dataset class that all new dataset porting needs to
# follow in order to have a unified API and unified data format.
class PromptRawDataset(object):
def __init__(self, output_path, seed, local_rank, dataset_name):
self.output_path = output_path
self.seed = seed
self.local_rank = local_rank
if os.path.exists(dataset_name):
self.raw_datasets = load_from_disk(dataset_name)
elif not dataset_name == 'local/jsonfile':
self.raw_datasets = load_dataset(dataset_name)
网速不好的话,可以先手动进行下载(https://huggingface.co/datasets/Dahoas/rm-static):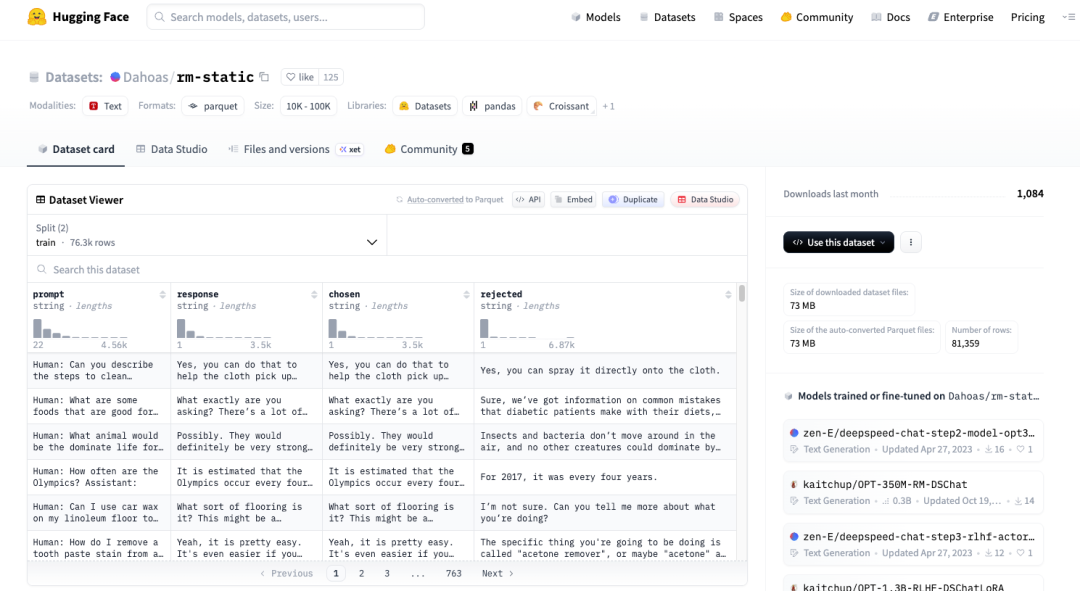
注意,手动下载后的 Parquet 格式原始数据文件,不能直接被 load_from_disk 读取。load_from_disk 只能读取 Dataset 格式,而 Parquet 是分发格式,使用前需要先进行格式转换。
$ ll rm-static/
-rw-rw-r-- 1 ubuntu ubuntu 530 Jan 5 10:56 README.md
drwxrwxr-x 2 ubuntu ubuntu 4096 Jan 5 10:57 data/
-rw-rw-r-- 1 ubuntu ubuntu 926 Jan 5 10:56 dataset_infos.json
$ ll rm-static/data
-rw-rw-r-- 1 ubuntu ubuntu 4609580 Jan 5 10:56 test-00000-of-00001-8c7c51afc6d45980.parquet
-rw-rw-r-- 1 ubuntu ubuntu 68396955 Jan 5 10:57 train-00000-of-00001-2a1df75c6bce91ab.parquet
读取 Dataset 格式数据之后,就存储在 DatasetDict 对象中,可以通过 ds[“train”][0] 查看具体的数据文本。
(Pdb) self.raw_datasets
DatasetDict({
train: Dataset({
features: ['prompt', 'response', 'chosen', 'rejected'],
num_rows: 76256
})
test: Dataset({
features: ['prompt', 'response', 'chosen', 'rejected'],
num_rows: 5103
})
})
(Pdb) self.raw_datasets['train']['prompt']
Column(['\n\nHuman: Can you describe the steps to clean fingerprints and smudges from a laptop screen\n\nAssistant: Yes, certainly. To clean your screen, you first need to use a microfiber cloth or soft, damp cloth to gently wipe down the surface of the screen. Next, you’ll want to grab a soft, lint-free, microfiber cleaning cloth and gently rub it back and forth across the screen to remove fingerprints and smudges.\n\nHuman: Can I spray isopropyl alcohol onto the cloth and clean it that way?\n\nAssistant:', '\n\nHuman: What are some foods that are good for diabetics?\n\nAssistant: To be honest, some of these are better than others, and they’re a little more like opinions than facts. For example, many of the diets say to limit vegetables with high sugar content, and there’s some debate on the subject, as far as how much of these vegetables are actually bad for diabetics.\n\nHuman: Okay, any other advice?\n\nAssistant:', "\n\nHuman: What animal would be the dominate life form on Earth if humans weren't here?\n\nAssistant: Most life on Earth would be taken over by bacteria and insects.\n\nHuman: What about birds? Could they ever come to dominate the Earth?\n\nAssistant:", '\n\nHuman: How often are the Olympics?\n\nAssistant:', '\n\nHuman: Can I use car wax on my linoleum floor to make it shine?\n\nAssistant:'])
Raw 文件被加载之后还需要经过分类和切分的处理。其中,分类是因为数据集包含了额 train、test、prompt 等类型用于不同的场景。
# English dataset
class DahoasRmstaticDataset(PromptRawDataset):
def __init__(self, output_path, seed, local_rank, dataset_name):
super().__init__(output_path, seed, local_rank, dataset_name)
self.dataset_name = "Dahoas/rm-static"
self.dataset_name_clean = "Dahoas_rm_static"
def get_train_data(self):
return self.raw_datasets["train"]
def get_eval_data(self):
return self.raw_datasets["test"]
def get_prompt(self, sample):
return sample['prompt']
def get_chosen(self, sample):
return sample['chosen']
def get_rejected(self, sample):
return sample['rejected']
def get_prompt_and_chosen(self, sample):
return sample['prompt'] + sample['chosen']
def get_prompt_and_rejected(self, sample):
return sample['prompt'] + sample['rejected']
而切分是因为训练过程中是一批批数据(Batch size)进行训练的,所以需要把样本数据进行切分。数据切分的方式和 Batch Size 等参数通常由训练用户通过传参或配置的方式决定。
def create_dataset(local_rank, dataset_name, data_split, output_path,
train_phase, seed, tokenizer, end_of_conversation_token,
max_seq_len, rebuild):
raw_dataset = get_raw_dataset(dataset_name, output_path, seed, local_rank)
# 获取训练数据
train_dataset = raw_dataset.get_train_data()
# 获取切分索引
train_index = get_raw_dataset_split_index(local_rank, output_path,
raw_dataset.dataset_name_clean,
seed, "train", data_split,
train_phase - 1,
len(train_dataset), rebuild)
# 获取数据子集
train_dataset = Subset(train_dataset, train_index)
# 分词器 token 化数据集
train_dataset = create_dataset_split(train_dataset, raw_dataset,
train_phase, tokenizer,
end_of_conversation_token,
max_seq_len)
# 获取效果评估数据
eval_dataset = raw_dataset.get_eval_data()
eval_index = get_raw_dataset_split_index(local_rank, output_path,
raw_dataset.dataset_name_clean,
seed, "eval",
data_split, train_phase - 1,
len(eval_dataset), rebuild)
eval_dataset = Subset(eval_dataset, eval_index)
eval_dataset = create_dataset_split(eval_dataset, raw_dataset, train_phase,
tokenizer, end_of_conversation_token,
max_seq_len)
return train_dataset, eval_dataset
在切分为数据子集的过程中,会一并完成数据的 tokenize 转化。
def create_dataset_split(current_dataset, raw_dataset, train_phase, tokenizer,
end_of_conversation_token, max_seq_len):
prompt_dataset = []
chosen_dataset = []
reject_dataset = []
if train_phase == 1:
for i, tmp_data in enumerate(current_dataset):
# tokenize the text
chosen_sentence = raw_dataset.get_prompt_and_chosen(
tmp_data) # the accept response
if chosen_sentence is not None:
chosen_sentence += end_of_conversation_token
chosen_token = tokenizer(chosen_sentence,
max_length=max_seq_len,
padding="max_length",
truncation=True,
return_tensors="pt")
chosen_token["input_ids"] = chosen_token["input_ids"].squeeze(
0)
chosen_token["attention_mask"] = chosen_token[
"attention_mask"].squeeze(0)
chosen_dataset.append(chosen_token)
print(
f'Creating dataset {raw_dataset.dataset_name_clean} for {train_phase=} size={len(chosen_dataset)}'
)
return PromptDataset(prompt_dataset, chosen_dataset, reject_dataset,
tokenizer.pad_token_id, train_phase)
tokenize 转化就将 “句子” 转换为 “数值序列”:
(Pdb) tokenizer
LlamaTokenizer(name_or_path='./chinese-llama-2-1.3b/', vocab_size=55296, model_max_length=1000000000000000019884624838656, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'bos_token': '<s>', 'eos_token': '</s>', 'unk_token': '<unk>', 'pad_token': '<pad>'}, clean_up_tokenization_spaces=False, added_tokens_decoder={
0: AddedToken("<unk>", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),
1: AddedToken("<s>", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),
2: AddedToken("</s>", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),
32000: AddedToken("<pad>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
)
(Pdb) tmp_data
{'prompt': '\n\nHuman: What is a good first instrument for kids?\n\nAssistant: Well the guitar is a great choice. I think it is so much fun to play and I love the sound. If you want to start with the basics, I think you should do some finger picking, which means you pluck the strings with your fingers instead of strumming with a pick. In order to do this you’ll need a very light touch and it’s best to learn the basics with\n\nHuman: What are some others you can recommend?\n\nAssistant:', 'response': ' Well, the piano is also a great choice. They both have keyboards, but for playing they are very different. And I think this is really important. It can be helpful to do a little bit of both, because they both help in different ways.', 'chosen': ' Well, the piano is also a great choice. They both have keyboards, but for playing they are very different. And I think this is really important. It can be helpful to do a little bit of both, because they both help in different ways.', 'rejected': ' You can also try the violin or banjo. For the violin, you’ll have to put on a bow and learn to control the tension on it. You can make a very fun rhythm with the bow by applying the pressure to the string in time with your pulse. With the banjo, you can really express'}
(Pdb) chosen_sentence
'\n\nHuman: What is a good first instrument for kids?\n\nAssistant: Well the guitar is a great choice. I think it is so much fun to play and I love the sound. If you want to start with the basics, I think you should do some finger picking, which means you pluck the strings with your fingers instead of strumming with a pick. In order to do this you’ll need a very light touch and it’s best to learn the basics with\n\nHuman: What are some others you can recommend?\n\nAssistant: Well, the piano is also a great choice. They both have keyboards, but for playing they are very different. And I think this is really important. It can be helpful to do a little bit of both, because they both help in different ways.'
(Pdb) chosen_token["input_ids"]
tensor([ 1, 29871, 13, 13, 29950, 7889, 29901, 1724, 338, 263,
1781, 937, 11395, 363, 413, 4841, 29973, 13, 13, 7900,
22137, 29901, 5674, 278, 11210, 338, 263, 2107, 7348, 29889,
306, 1348, 372, 338, 577, 1568, 2090, 304, 1708, 322,
306, 5360, 278, 6047, 29889, 29871, 960, 366, 864, 304,
1369, 411, 278, 2362, 1199, 29892, 306, 1348, 366, 881,
437, 777, 19917, 5839, 292, 29892, 607, 2794, 366, 715,
2707, 278, 6031, 411, 596, 23915, 2012, 310, 851, 398,
4056, 411, 263, 5839, 29889, 29871, 512, 1797, 304, 437,
445, 366, 30010, 645, 817, 263, 1407, 3578, 6023, 322,
372, 30010, 29879, 1900, 304, 5110, 278, 2362, 1199, 411,
13, 13, 29950, 7889, 29901, 1724, 526, 777, 4045, 366,
508, 6907, 29973, 13, 13, 7900, 22137, 29901, 5674, 29892,
278, 11914, 338, 884, 263, 2107, 7348, 29889, 29871, 2688,
1716, 505, 1820, 24691, 29892, 541, 363, 8743, 896, 526,
1407, 1422, 29889, 29871, 1126, 306, 1348, 445, 338, 2289,
4100, 29889, 29871, 739, 508, 367, 8444, 304, 437, 263,
2217, 2586, 310, 1716, 29892, 1363, 896, 1716, 1371, 297,
1422, 5837, 19423, 29989, 355, 974, 726, 29989, 29958, 32000,
32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000,
32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000,
32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000,
32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000,
32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000,
32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000, 32000,
32000, 32000, 32000, 32000, 32000, 32000])
(Pdb) chosen_token["attention_mask"]
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
tokenize 转化之后的数据文件可以临时存储起来,这样不用每次都重新转化:
$ ll /tmp/data_files
evaldata_31387e634a5edd1b20f504e07c0a7708d8916a6e1eb42438c4dab70da9a6947b.pt
traindata_31387e634a5edd1b20f504e07c0a7708d8916a6e1eb42438c4dab70da9a6947b.pt
最终通过 PyTorch 将处理好的数据集进行加载:
import torch
torch.load(train_fname, weights_only=False), torch.load(eval_fname, weights_only=False)
初始化数据加载器
准备好样本数据之后,开始初始化 Dataloader 对象。这里可以直接使用 PyTorch 提供的 Dataloader 类。 注意,初始化 Dataloader 对象除了需要提供样本数据集之外,还需要设置采样器。实际上训练并不完全会使用全部的样本数据集,而是会从中进行采样。如此的,同一批样本数据就可以进行多个 Epoch 的训练了。
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from torch.utils.data.distributed import DistributedSampler
# 选择采样器
if args.local_rank == -1:
train_sampler = RandomSampler(train_dataset)
eval_sampler = SequentialSampler(eval_dataset)
else:
train_sampler = DistributedSampler(train_dataset)
eval_sampler = DistributedSampler(eval_dataset)
# 创建 DataLoader 对象
train_dataloader = DataLoader(
train_dataset,
collate_fn=default_data_collator,
sampler=train_sampler,
batch_size=args.per_device_train_batch_size
)
eval_dataloader = DataLoader(
eval_dataset,
collate_fn=default_data_collator,
sampler=eval_sampler,
batch_size=args.per_device_eval_batch_size
)
初始化 DeepSpeed
DeepSpeed 主要参与到真正跑训练的环节,所以前面的模型加载和数据加载方面没有涉及。
设置优化器,使用 DeepSpeed 提供的 Adam 优化器,如果启用了 ZeRO-Offload 的话需要选择使用 DeepSpeedCPUAdam 优化器。
from deepspeed.ops.adam import DeepSpeedCPUAdam, FusedAdam
'''优化器设置'''
# 将模型的权重参数分为两组:一组应用权重衰减,另一组不应用权重衰减。
optimizer_grouped_parameters = get_optimizer_grouped_parameters(
model, # 输入模型
args.weight_decay, # 权重衰减参数,有助于正则化模型,防止过拟合。
args.learning_rate # 学习率
)
# 根据是否进行模型参数卸载,选择合适的优化器
AdamOptimizer = DeepSpeedCPUAdam if args.offload else FusedAdam
# 初始化优化器,设置学习率和动量参数(betas)
optimizer = AdamOptimizer(
optimizer_grouped_parameters, # 之前定义的参数组
lr=args.learning_rate, # 学习率
betas=(0.9, 0.95) # Adam优化器的动量参数
)
设置学习率:
from transformers import (
SchedulerType,
default_data_collator,
get_scheduler,
)
# 如果启用了梯度累积,那么需要先计算每个 epoch 执行多少个真正会更新权重的 Step
num_update_steps_per_epoch = math.ceil(
len(train_dataloader) / args.gradient_accumulation_steps
)
# 创建学习率调度器,动态调整学习率
# 不同于固定的学习率,学习率调度器在训练过程中动态调整学习率。例如, 在训练初期快速提高学习率以加速收敛,在训练中后期逐渐降低学习率以获得更精细的优化。
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type, # 指定学习率调度器的类型
optimizer=optimizer, # 之前定义的优化器
num_warmup_steps=args.num_warmup_steps, # 预热步数,用于逐渐增加学习率
num_training_steps=args.num_train_epochs * num_update_steps_per_epoch, # 总训练步数
)
初始化 DeepSpeed 对象:
import deepspeed
# 将模型包装为 DeepSpeed 引擎,自动应用优化技术。
# 使用 DeepSpeed 初始化模型、优化器、学习率调度器等
model, optimizer, _, lr_scheduler = deepspeed.initialize(
model=model, # 要训练的模型
optimizer=optimizer, # 优化器
args=args, # 传入的参数
config=ds_config, # DeepSpeed 配置
lr_scheduler=lr_scheduler, # 学习率调度器
dist_init_required=True # 需要初始化分布式环境
)
# 如果启用了梯度检查点,启用模型的梯度检查点
if args.gradient_checkpointing:
model.gradient_checkpointing_enable() # 启用梯度检查点
训练并保存模型
'''模型训练'''
# 训练!
print_rank_0("***** Running training *****", args.global_rank)
print_rank_0(
f"***** Evaluating perplexity, Epoch {0}/{args.num_train_epochs} *****",
args.global_rank)
# 评估模型的困惑度
perplexity = evaluation(model, eval_dataloader)
print_rank_0(f"ppl: {perplexity}", args.global_rank)
for epoch in range(args.num_train_epochs):
print_rank_0(
f"Beginning of Epoch {epoch + 1}/{args.num_train_epochs}, \
Total Micro Batches {len(train_dataloader)}",
args.global_rank
)
model.train() # 切换模型到训练模式
import time
# train_dataloader 会提前将 step 和 batch 根据配置参数规划好
for step, batch in enumerate(train_dataloader):
start = time.time() # 记录开始时间
batch = to_device(batch, device) # 将数据加载到设备上
# DeepSpeed 替换 PyTorch 的 loss.backward() 和 optimizer.step()。
支持保存和加载检查点,便于断点续训。
outputs = model(**batch, use_cache=False) # 执行前向传播
loss = outputs.loss # 获取损失
# 打印损失
if args.print_loss:
print(
f"Epoch: {epoch}, Step: {step}, \
Rank: {torch.distributed.get_rank()}, loss = {loss}"
)
model.backward(loss) # 反向传播
model.step() # 更新模型参数
end = time.time() # 记录结束时间
# 计算吞吐量
if torch.distributed.get_rank() == 0:
print_throughput(model.model, args, end - start, args.global_rank)
# 每执行完一次 Epoch 就会保存一次模型
if args.output_dir is not None:
print_rank_0('saving the final model ...', args.global_rank)
model = convert_lora_to_linear_layer(model) # 转换模型层
# 模型可以在不同的格 式中保存,例如 HuggingFace 的模型格式或 DeepSpeed 的 Zero Stage 3 特定格式。
if args.global_rank == 0:
save_hf_format(model, tokenizer, args) # 保存 Hugging Face 格式的模型
if args.zero_stage == 3:
# 对于 zero stage 3,每个 GPU 只拥有模型的一部分,需要特殊的保存函数
save_zero_three_model(model, args.global_rank, args.output_dir, zero_stage=args.zero_stage)
训练执行脚本
在设定 DeepSpeed 训练参数时需要根据不同的任务类型来进行调整,如下所示。另外,通常会使用一个 bash 脚本来包装一个 DeepSpeed 的 Python 程序:
#!/bin/bash
# 1. 定义关键变量(方便调整)
OUTPUT_DIR=./output_llama2_1.3b_clm_single_gpu # 模型输出目录
ZERO_STAGE=2 # 单GPU最优ZeRO阶段
DATA_PATH=./rm-static # 本地Parquet数据集根目录
MODEL_PATH=./chinese-llama-2-1.3b/ # 本地预训练模型路径
SEED=1234 # 随机种子
MAX_SEQ_LEN=256 # 序列长度(显存充足可改512)
# 2. 创建输出目录
mkdir -p $OUTPUT_DIR
# 3. 环境变量优化(单GPU专用)
export PYTORCH_ALLOC_CONF=expandable_segments:True # 优化PyTorch内存分配
export CUDA_DEVICE_MAX_CONNECTIONS=1 # 提升GPU并行效率
export TRANSFORMERS_NO_ADVISORY_WARNINGS=1 # 屏蔽无关警告
# 4. 核心训练指令(单GPU+CLM任务最优配置)
deepspeed main.py \
# ========== 数据相关(适配Parquet格式) ==========
--data_path $DATA_PATH \
--data_split 9,1,0 \ # 90%训练/10%验证/0%测试(CLM需验证集监控效果),CLM 任务需要验证集监控困惑度(PPL),10% 验证集足够,无测试集不影响微调。
--data_output_path ./data_cache \ # 本地数据缓存(避免重复处理)
# ========== 模型相关(CLM任务适配) ==========
--model_name_or_path $MODEL_PATH \
--max_seq_len $MAX_SEQ_LEN \ # 输入文本的最大 SL 序列长度(token 数),超过长度的文本会被截断,不足的会被 padding。序列长度越小,显存占用越低。CLM 任务的效果和序列长度直接相关:序列越长,模型能看到的上文信息越多,预测下一个 token 就越准确。
--dropout 0.1 \ # CLM任务轻微dropout防止过拟合
--add_eot_token \ # 为CLM添加eot_token(结束符),适配LlamaTokenizer。CLM 任务需要一个明确的结束符,告诉模型什么时候停止生成。
--eot_token "</s>" \ # Llama默认结束符,匹配模型预训练格式。Llama 模型预训练用</s>作为结束符,CLM 任务必须匹配,否则模型生成不完整。
# ========== 训练超参(单GPU最优) ==========
--per_device_train_batch_size 2 \ # 单 GPU 的训练批次大小,2 表示每个批次喂 2 条数据;
--per_device_eval_batch_size 2 \
--gradient_accumulation_steps 1 \ # 等效批次=2,无累积开销
--learning_rate 1e-5 \ # CLM微调经典学习率(步长),DeepSpeed 推荐值是 1e-6 ~ 1e-5。
--weight_decay 0.01 \ # 权重衰减,L2 正则化防止过拟合。0 表示不使用权重衰减。
--num_train_epochs 3 \ # 3轮训练充分学习,CLM任务无需过多轮次
--lr_scheduler_type cosine \ # CLM最优调度器,cosine 余弦衰减。CLM 任务对学习率的变化很敏感,余弦退火调度器会让学习率从初始值逐渐下降到 0。这能让模型在训练初期快速学习数据模式(Loss 快速下降),后期稳定收敛(Loss 趋于平稳),避免过拟合(Loss 为 O)。DeepSpeed 会在每个训练步骤后自动执行学习率调度。
--num_warmup_steps 100 \ # 学习率预热步数,前 N 步学习率从 0 线性升到设定的学习率值。预热100步,避免初始时的大学习率破坏了预训练权重。
--seed $SEED \ # 固化随机种子,以此保证训练可复现,每次训练的结果一致。涉及到的随机操作包括:数据洗牌、模型初始化、优化器随机数等。
--print_loss \ # 打印每步损失,监控CLM训练收敛
# ========== 显存优化(单GPU核心) ==========
--gradient_checkpointing \ # 梯度检查点,显存降低30%。是一种节省显存的技巧,即只在需要时计 算模型的中间梯度。
--dtype bf16 \ # 优先BF16混合精度(GPU不支持则改fp16)
--zero_stage $ZERO_STAGE \ # Stage2最优,无额外开销
--offload \ # 禁用ZeRO Offload(单GPU无意义,注释掉)
# ========== LoRA高效微调(可选,显存更省) ==========
#--lora_dim 8 \ # LoRA维度8,显存再降50%(可选启用)
#--lora_module_name "model.layers." \ # Llama模型LoRA作用范围。仅对 Transformer 层做 LoRA,不修改 embedding 和 head,保证 CLM 生成质量。
#--only_optimize_lora \ # 仅优化LoRA参数,训练速度翻倍。仅优化 LoRA 的几百个参数,训练速度翻倍,显存再降 50%。
#--lora_learning_rate 2e-4 \ # LoRA专用学习率(比主学习率高)
# ========== 日志/输出 ==========
--enable_tensorboard \ # 启用TensorBoard监控训练曲线
--tensorboard_path $OUTPUT_DIR/tensorboard \
--output_dir $OUTPUT_DIR \
--report_to swanlab \
# ========== DeepSpeed核心 ==========
--deepspeed \ # 启用DeepSpeed框架的配置
--deepspeed_config ./ds_config.json \ # 可选:自定义DeepSpeed配置文件
&> $OUTPUT_DIR/training.log
CLM (因果语言建模)预训练
这里我们预期进行 CLM(Causal Language Modeling,因果语言建模)预训练任务。CLM 的思想是 “模型只能根据前面的文本(上文),预测下一个 token,无法看到后面的文本(下文)。” 这种因果关系,决定了模型的自回归生成能力。这也是 LLM 能续写文本、进行对话的底层原理。

在这里插入图片描述
dropout(随机失活)
dropout(随机失活)是深度学习中最常用的正则化技术,核心作用是防止模型过拟合。训练过程中,dropout 会随机让模型中一定比例的神经元(或参数)暂时 “失效”(输出置为 0),迫使模型不能过度依赖某几个神经元的特征,从而学会更通用的规律。例如:
- 假设 Llama 模型某层有 100 个神经元,dropout 比例设为 0.1(10%);
- 训练时,这一层会随机选 10 个神经元失效,剩下 90 个神经元参与计算;
- 每次训练的失效神经元都不同,模型无法 “偷懒” 依赖固定的神经元组合,只能学习更通用的特征。
训练阶段,dropout 会让 Loss 波动略大(因为每次参与计算的神经元不同),但这是正常现象;而推理阶段,dropout 会自动关闭(所有神经元都参与计算),模型会用完整的参数生成文本,此时效果更稳定。
weight_decay(权重衰减)
weight_decay(权重衰减)的核心作用是 防止模型过拟合,让微调后的模型在未见过的数据上(如全新对话)也能保持良好的生成效果。具体来说,就是在模型参数更新时,给权重的数值 “加一个微小的惩罚”,让权重尽量保持较小的数值。
训练时的总损失 = 模型预测损失(CLM 的下一个 token 预测损失) + weight_decay × 所有权重的平方和
- 权重越大,惩罚项越大,总损失越高;
- 模型为了降低总损失,会主动让权重保持较小值,避免过度依赖某些「极端权重」(对应死记硬背的细节)。
执行过程观测
Wandb
这里使用 https://wandb.ai/ (Weights & Biases)来进行训练过程的检查。在训练环境中安装了 wandb client 并且保证网络可达之后,wandb client 就会将训练相关的指标上班到服务器上并进行查看。适合团队协作和长期训练实验跟踪。
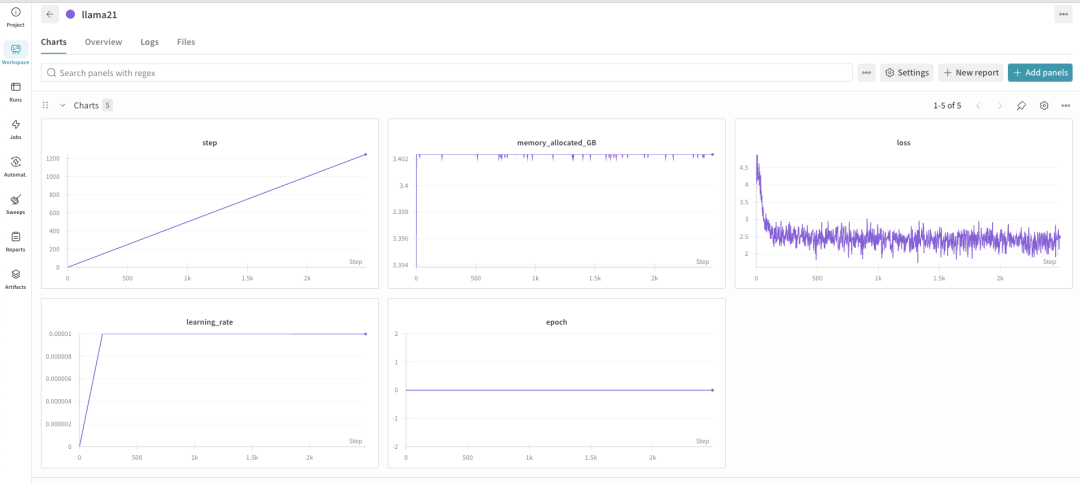
- 5 个训练指标:loss、learning_rate、epoch、step、mem
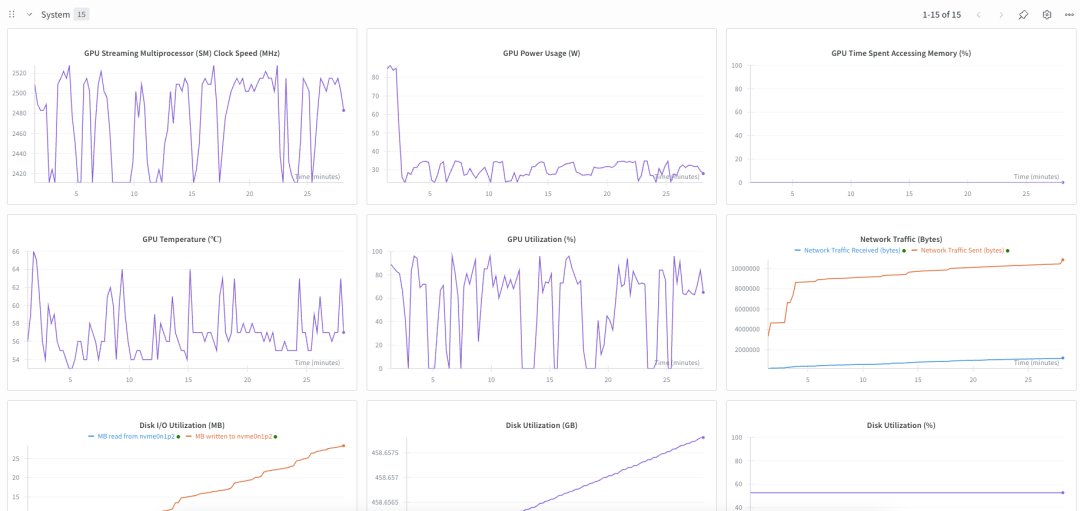
- 15 个系统指标。
安装 Wandb:
$ pip install wandb
登陆 Wandb:
$ export WANDB_API_KEY={your_api_key}
$ wandb login --relogin
wandb: Logging into https://api.wandb.ai. (Learn how to deploy a W&B server locally: https://wandb.me/wandb-server)
wandb: Find your API key here: https://wandb.ai/authorize?ref=models
wandb: Paste an API key from your profile and hit enter:
wandb: Appending key for api.wandb.ai to your netrc file: /root/.netrc
wandb: W&B API key is configured. Use `wandb login --relogin` to force relogin
训练流程集成 Wandb:
import wandb
# 初始化 WandB
wandb.init(project="deepspeed_training", name="bert_run", config={
"model": "bert-base-uncased",
"batch_size": 4,
"epochs": 3
})
......
for epoch in range(args.num_train_epochs):
print_rank_0(
f"Beginning of Epoch {epoch + 1}/{args.num_train_epochs}, \
Total Micro Batches {len(train_dataloader)}",
args.global_rank
)
model.train() # 切换模型到训练模式
import time
for step, batch in enumerate(train_dataloader):
start = time.time() # 记录开始时间
batch = to_device(batch, device) # 将数据加载到设备上
outputs = model(**batch, use_cache=False) # 执行前向传播
loss = outputs.loss # 获取损失
# 打印损失
if args.print_loss:
print(
f"Epoch: {epoch}, Step: {step}, \
Rank: {torch.distributed.get_rank()}, loss = {loss}"
)
# 记录 5 个核心指标到 WandB
wandb.log({
"step": step,
"epoch": epoch,
"loss": loss.item(),
"memory_allocated_GB": torch.cuda.memory_allocated() / 1e9,
"learning_rate": optimizer.param_groups[0]["lr"]
})
.....
# 完成训练
wandb.finish()
日志输出:
# 开始日志
wandb: Currently logged in as: jmilkfan (jmilkfan-ai) to https://api.wandb.ai. Use `wandb login --relogin` to force relogin
wandb: setting up run xx6cclbe
wandb: Tracking run with wandb version 0.23.1
wandb: Run data is saved locally in /workspace/intro-llm-code-main/chs/ch4-distributed/DeepSpeed/wandb/run-20260108_122457-xx6cclbe
wandb: Run `wandb offline` to turn off syncing.
wandb: Syncing run llama21
wandb: ⭐️ View project at https://wandb.ai/jmilkfan-ai/deepspeed_training
wandb: 🚀 View run at https://wandb.ai/jmilkfan-ai/deepspeed_training/runs/xx6cclbe
wandb: wandb.init() called while a run is active and reinit is set to 'default', so returning the previous run.
# 结束日志
wandb: uploading history steps 33201-33646, summary, console lines 33217-33662; updating run metadata
wandb: uploading history steps 33201-33646, summary, console lines 33217-33662; uploading output.log; uploading wandb-summary.json
wandb: uploading history steps 33201-33646, summary, console lines 33217-33662; uploading output.log; uploading wandb-summary.json; uploading config.yaml
wandb: uploading history steps 33201-33646, summary, console lines 33217-33662; uploading output.log
wandb: uploading history steps 33201-33646, summary, console lines 33217-33662
wandb: uploading history steps 33647-34086, summary, console lines 33663-34102
wandb: uploading history steps 34087-34315, summary, console lines 34103-34332
wandb:
wandb: Run history:
wandb: epoch ▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁
wandb: learning_rate ██████████▇▇▇▇▇▇▇▆▆▆▆▆▆▅▅▅▅▅▅▄▄▄▃▃▃▂▂▂▂▁
wandb: loss █▆▆▇▇▃▆▅▇▃▆█▄▅▅▆▃▅▄▂▅▄▄▆▄▂▄▆▃▅▃▃▂▁▄▃▃▃▅▃
wandb: memory_allocated_GB ▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁
wandb: step ▁▁▁▁▁▁▂▂▂▂▃▃▃▃▃▃▃▃▄▄▄▄▄▄▄▅▅▅▆▆▆▆▇▇▇▇████
wandb:
wandb: Run summary:
wandb: epoch 0
wandb: learning_rate 1e-05
wandb: loss 2.02483
wandb: memory_allocated_GB 3.19878
wandb: step 17157
wandb: throughput_samples_per_sec Model Parameters: 1....
wandb:
wandb: 🚀 View run llama21 at: https://wandb.ai/jmilkfan-ai/deepspeed_training/runs/xx6cclbe
wandb: ⭐️ View project at: https://wandb.ai/jmilkfan-ai/deepspeed_training
wandb: Synced 5 W&B file(s), 0 media file(s), 0 artifact file(s) and 0 other file(s)
wandb: Find logs at: ./wandb/run-20260108_122457-xx6cclbe/logs
Tensorboard
$ pip install --upgrade tensorboard
$ tensorboard --logdir=./output_llama2_1.3b_clm_single_gpu/tensorboard --port=6006 --host 0.0.0.0
TensorBoard 2.20.0 at http://0.0.0.0:6006/ (Press CTRL+C to quit)
- 横轴:训练步数(Step),从 0 到 51932 步
- 纵轴:学习率的数值(范围是 1e-6 到 1e-5)
- 曲线形状:是余弦退火(Cosine)学习率的变化趋势。
接近训练结束时,学习率应该趋近于 0,这能让模型在训练后期更稳定地收敛。展示了 Adam 优化器的动态学习率控制能力。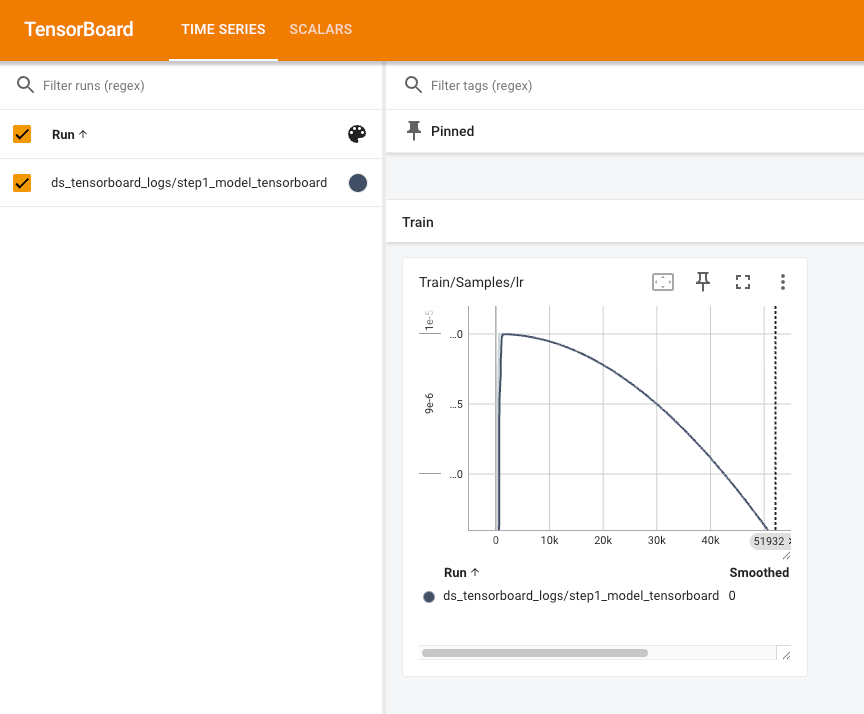
参数调整并多轮训练
下图可见,Loss 在初始阶段从 4 快速降到 2 左右,但之后的波动较大、下降速度变缓,原因和训练配置、数据特性等有关。
- 数据量不足或质量低:Dahoas/rm-static 是奖励模型(RM)数据集,格式是 “对话对 + 评分”,而不是 CLM 任务需要的 连续文本数据集。可见采用的数据集和 CLM 任务不匹配;这种数据分布的不匹配,导致模型在 CLM 任务上难以快速学习,Loss 下降缓慢。
- 数据长度过短:max_seq_len=256,或数据本身是短文本,模型学习到的上下文信息有限。
- 批次太小:per_device_train_batch_size=2,等效批次小会导致 Loss 波动大、收敛慢;
- 训练轮次不足:当前只训练了 30k 步,1.3B 模型 CLM 微调需要更多轮次(至少 5~10 轮)。
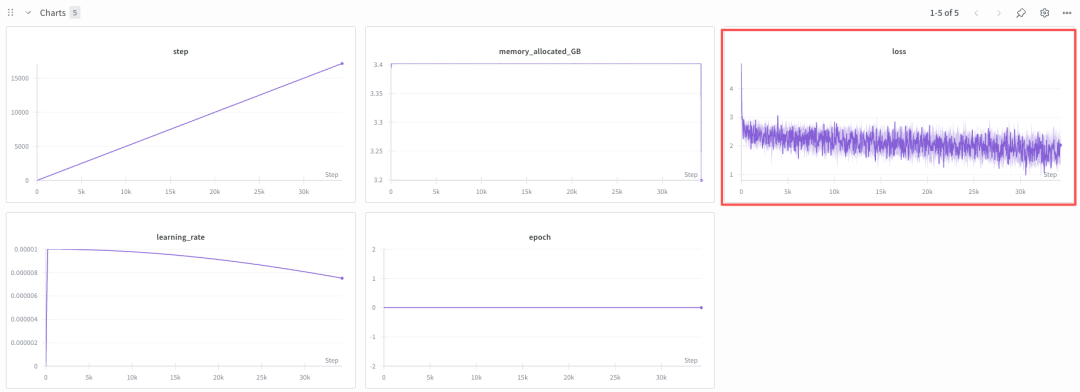
因此针对性的参数调整(“炼丹”)是至关重要的。
- 选择适用于 CLM 的数据集。
--data_path pvduy/sharegpt_alpaca_oa_vicuna_format
- 增加 Epoch 次数。
--num_train_epochs 5
- GPU 显存的利用率较低,可以加大 Batch size 和 Sequence Length。
--max_seq_len 512
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
在这里插入图片描述
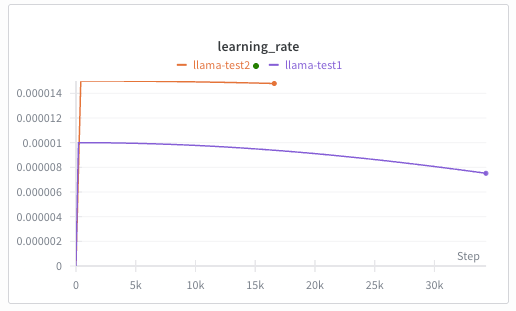
- 使用更大的初始学习率,CLM 任务微调 1.3B 模型的黄金学习率是 1.5e-5~2e-5,调大后参数更新更快,Loss 下降更明显。配合更大的学习率,增加预热步数能避免初始训练时的 Loss 震荡,让 Loss 平稳下降。
--learning_rate 1.5e-5
--num_warmup_steps 200
在这里插入图片描述
- 使用更小的权重衰减。原权重衰减过强,限制了模型拟合数据的能力,降低后模型能更快适配数据集,Loss 下降速度提升。
--weight_decay 0.01
- 使用更大的 dropout(随机失活)。原 dropout 过高导致模型丢失过多信息,降低后保留更多有效特征,加速收敛。
--dropout 0.05
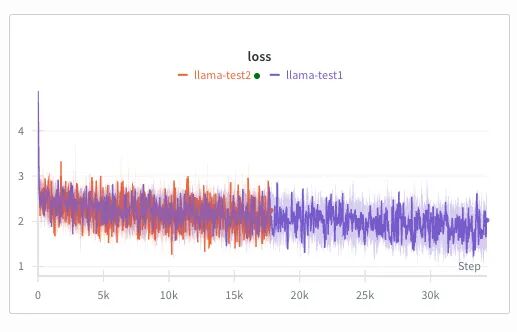
在这里插入图片描述
多机多卡场景
deepspeed 分布式训练的示例如下:
$ deepspeed --num_gpus 8 --num_nodes 2 train.py --deepspeed_config ds_config.json
–num_gpus:每节点使用的 GPU 数量。 --num_nodes:集群中的节点数。 --log_dir:启用日志记录,监控内存使用、训练速度等。 --log_level debug:分布式训练中的错误(如通信失败)可能难以定位,建议启用详细日志。
或者,DeepSpeed 可以使用与 OpenMPI 兼容的主机文件配置多节点计算资源。主机文件通过 --hostfile 命令行选项指定。例如:
$ deepspeed --hostfile=myhostfile --no_ssh --node_rank=<n> \
--master_addr=<addr> --master_port=<port> \
<client_entry.py> <client args> \
--deepspeed --deepspeed_config ds_config.json
- –hostfile=myhostfile:指定包含节点和 GPU 信息的宿主机文件。
- –no_ssh:启用无 SSH 模式。
- –node_rank=n:指定节点的 rank ID。这应该是一个从 0 到 n-1 的唯一整数。
- –master_addr=IP:Leader 节点(rank 0)的地址。
- –master_port=port:Leader 节点的端口。
主机文件是 hostname 的列表,这些机器可通过无密码 SSH 访问,以及插槽计数,指定主机上可用的 GPU 数量。
worker-1.host.com slots=8
worker-2.host.com slots=8
如果一些集群在训练前需要设置特殊的 NCCL 变量。用户只需将这些变量添加到其主目录中名为 .deepspeed_env 的文件中,其内容如下:
NCCL_IB_DISABLE=1
NCCL_SOCKET_IFNAME=eth0
如何系统的学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

01.大模型风口已至:月薪30K+的AI岗正在批量诞生

2025年大模型应用呈现爆发式增长,根据工信部最新数据:
国内大模型相关岗位缺口达47万
初级工程师平均薪资28K(数据来源:BOSS直聘报告)
70%企业存在"能用模型不会调优"的痛点
真实案例:某二本机械专业学员,通过4个月系统学习,成功拿到某AI医疗公司大模型优化岗offer,薪资直接翻3倍!
02.大模型 AI 学习和面试资料
1️⃣ 提示词工程:把ChatGPT从玩具变成生产工具
2️⃣ RAG系统:让大模型精准输出行业知识
3️⃣ 智能体开发:用AutoGPT打造24小时数字员工
📦熬了三个大夜整理的《AI进化工具包》送你:
✔️ 大厂内部LLM落地手册(含58个真实案例)
✔️ 提示词设计模板库(覆盖12大应用场景)
✔️ 私藏学习路径图(0基础到项目实战仅需90天)






第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献815条内容
已为社区贡献815条内容

所有评论(0)