Qwen3-VL实现打架斗殴异常行为实时视频分析
本文介绍了基于Qwen3-VL多模态大模型构建的打架斗殴异常行为实时分析系统。系统通过微调Qwen3-VL模型,实现对视频中打架斗殴行为的精准识别与描述。项目包含200个训练视频和100个测试视频,采用ShareGPT格式标注数据。技术方案包括模型微调、LoRA参数合并及vLLM部署,最终通过Gradio开发了支持文本、图片和视频交互的Web服务。系统可应用于智慧安防等场景,实现异常行为的实时监测
Qwen3-VL实现打架斗殴异常行为实时视频分析
目录
1. 前言
在智慧安防、智慧社区、智慧校园等场景中,对视频中的异常行为(尤其是打架斗殴)进行实时、精准的自动识别与预警,是一项具有重大社会价值和安全意义的技术需求。传统的监控系统严重依赖人工值守,效率低下且易产生疏漏。随着多模态大语言模型技术的突破,基于视觉-语言理解的智能分析方案正在成为解决这一痛点的前沿方向。
通义千问团队发布的Qwen3-VL模型,作为一款强大的多模态视觉语言大模型,在图像理解、视觉推理和细粒度视觉问答任务上展现了卓越的性能。本博文基于Qwen3-VL多模态大模型构建一个端到端的视频异常行为分析系统,通过模型微调等技术路径,构建一个专门针对“打架斗殴”场景的异常行为实时分析系统,并详细介绍从数据准备、模型训练到部署测试的全流程。
| 模型 | 准确率 |
| Qwen3-VL-2B-Instruct | 84.0% |
| Qwen3-VL-2B-Instruct(lora微调) | 90.0% |
原始的Qwen3-VL-2B-Instruct模型,打架斗殴异常行为识别测试准确率只有84%;经过lora微调后,准确率提升到90%,提升了6%。
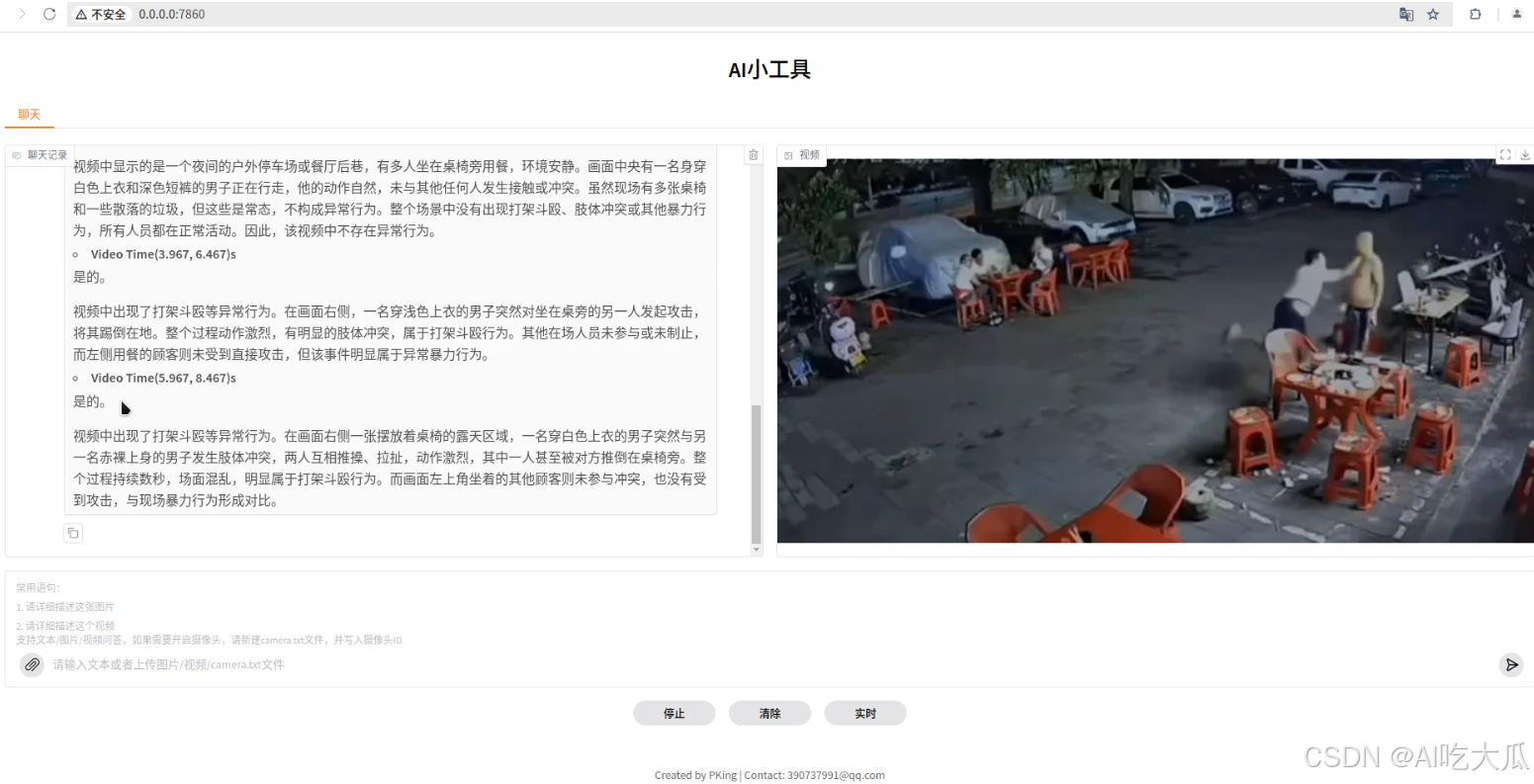
下面视频是打架斗殴异常行为实时分析的测试效果:
打架斗殴异常行为视频分析
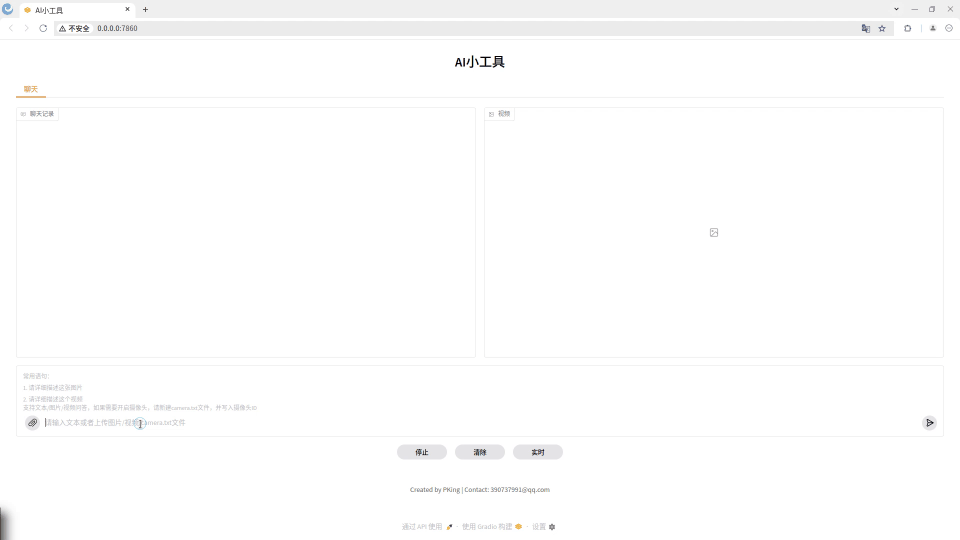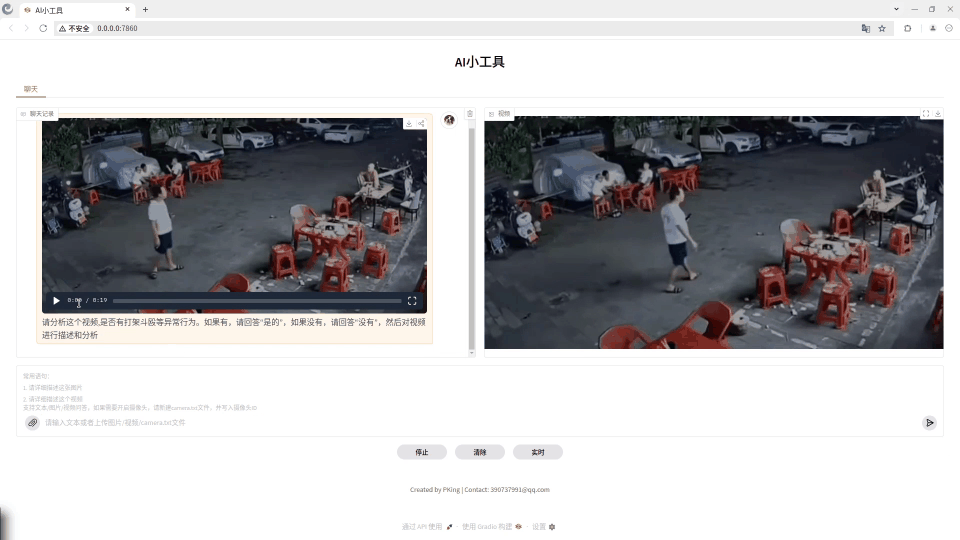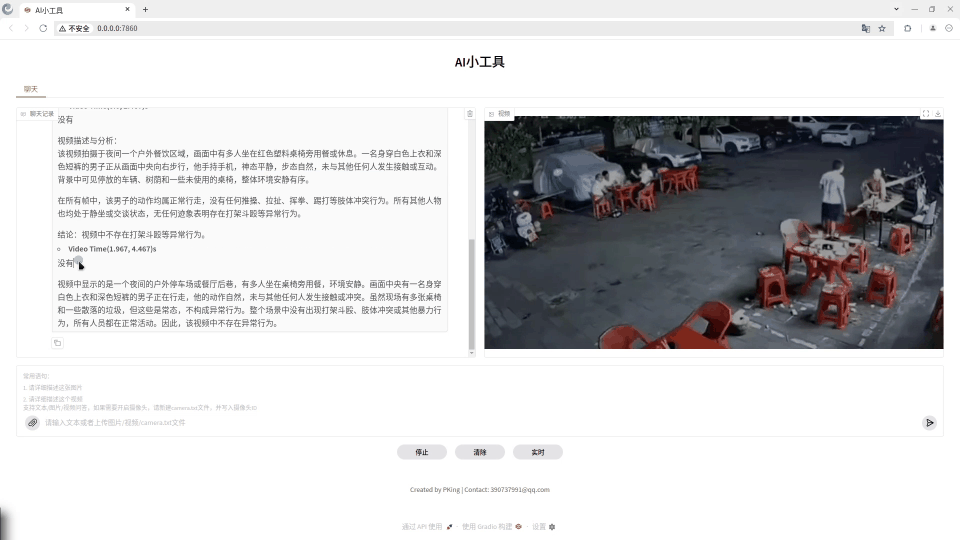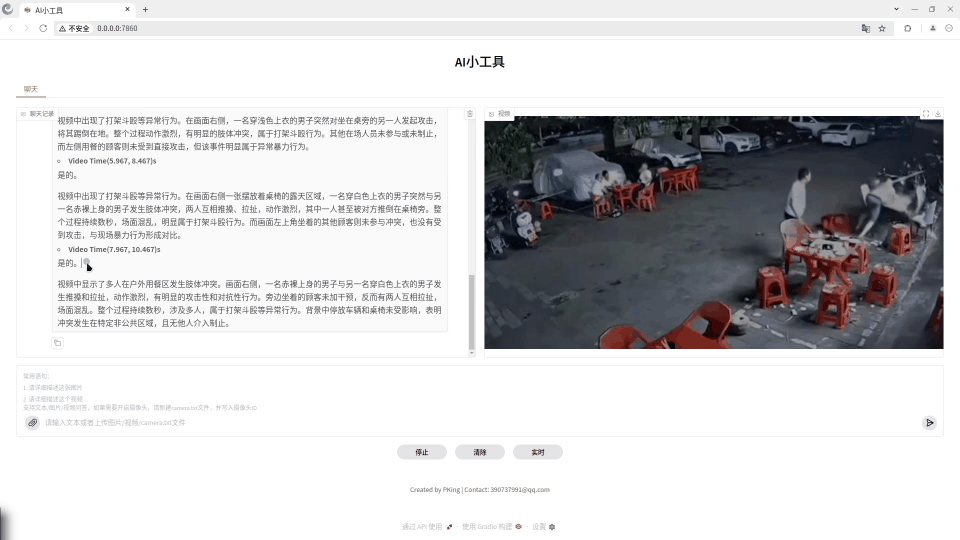
【尊重原创,转载请注明出处】https://blog.csdn.net/guyuealian/article/details/156240847
2. 实现方案
目前,针对视频异常行为分析,尤其是特定行为如打架斗殴,主流技术方案可分为以下几类:
(1)传统计算机视觉方法
- 基于手工特征(HOG, SIFT等)与机器学习分类器(SVM等):早期方法,对动作的时空特征进行提取和分类,但特征表达能力有限,在复杂场景下鲁棒性差。
- 光流法:通过计算视频中像素点的运动矢量来表征运动模式。打架斗殴通常伴随着剧烈、无序的运动,可通过分析光流场的强度和混乱度进行初步判断,但易受光照、遮挡干扰。
(2)基于深度学习的视频分析方法:
- 双流网络:分别从视频的空间(RGB帧) 和时间(光流帧) 维度提取特征并融合,能较好地表征动作,是行为识别领域的经典框架。
- 3D卷积神经网络(如C3D, I3D):直接处理视频片段,使用3D卷积核同时捕捉时空特征,比双流网络更端到端,计算量较大。
- 基于时序建模的网络(如LRCN, TCN):通常使用CNN提取每帧特征,再送入RNN(LSTM/GRU)或Transformer进行时序建模,理解动作的动态演变过程。
(3)基于目标检测与姿态估计的后分析方法:
- 先使用目标检测模型(如YOLO系列)定位人员,再利用姿态估计模型(如OpenPose, MMPose)获取人体关键点。
- 通过对关键点序列(骨骼序列)进行分析,提取肢体运动的幅度、速度、交互角度等特征,利用规则或分类模型判断是否发生扭打、踢踹等异常交互行为。这种方法可解释性较强。
(4)基于多模态大模型(VLMs)的端到端理解方案:
- 以Qwen3-VL、GPT-4V、Gemini等为代表的多模态大模型,将图像/视频帧与文本指令/问题进行统一理解。
- 优势:
- 强大的视觉语义理解能力:能直接理解复杂的场景、人物关系、物体交互,无需复杂的特征工程。
- 零样本/少样本学习潜力:具备强大的泛化能力,即使在训练数据未覆盖的类似场景下也可能做出合理判断。
- 自然语言交互:可以直接以问答形式进行分析,例如:“画面中是否有人正在打架?”、“描述一下第三秒到第五秒之间的异常行为”。
- 无需复杂的预处理流水线:可以一个模型同时完成目标检测、场景理解、行为推理等多个子任务。
- 挑战:对计算资源要求高;推理速度优化是实时应用的关键;需要高质量、针对性的指令微调数据以激发其在特定任务上的潜能。
本博文选择Qwen3-VL多模态大模型构建一个端到端的视频异常行为分析系统。其核心思路是利用其强大的原生视觉-语言理解能力,通过在大规模通用数据上预训练获得的先验知识,再使用高质量的“打架斗殴”场景指令数据进行监督微调,使模型学会针对该类异常行为的精准识别与描述,最终实现端到端的视频分析。
3. 项目结构
项目构建的一个多模态大模型(MLLM Factory)代码仓库,目录结构如下:
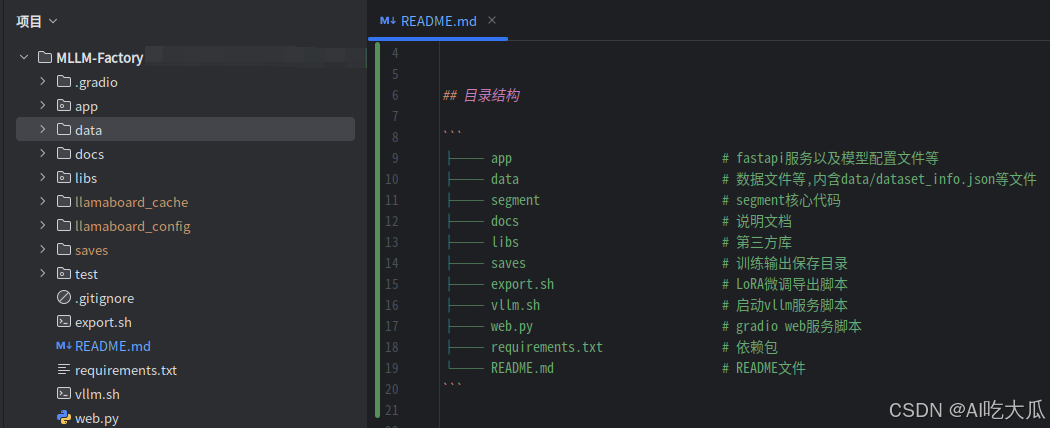
├── app # fastapi服务以及模型配置文件等
├── data # 数据文件等,内含data/dataset_info.json等文件
├── segment # segment核心代码
├── docs # 说明文档
├── libs # 第三方库
├── saves # 训练输出保存目录
├── export.sh # LoRA微调导出脚本
├── vllm.sh # 启动vllm服务脚本
├── web.py # gradio web服务脚本
├── requirements.txt # 依赖包
└── README.md # README文件MLLM-Factory代码仓库中data/dataset_info.json是从LLaMA Factory/data拷贝的数据集信息配置文件(dataset_info.json),包含了所有经过预处理的本地数据集以及在线数据集。后面使用LLaMA Factory微调模型时,数据路径请填写MLLM-Factory/data/dataset_info.json的绝对路径。
4. 打架斗殴异常行为数据集
项目构建了一个打架斗殴异常行为多模态视频数据集(anomaly),这些数据都从网上收集的打架斗殴异常行为视频数据。其中训练集约200个短视频,测试机约100个短视频,绝大部分视频截取关键视频内容,时长约0.5~3秒。视频样本数据保存在fight和normal文件夹中,其中fight文件夹表示这些样本视频,是打架斗殴异常行为;而normal文件夹属于负样本数据,是非异常行为的视频数据。
数据结构如下:
.
├── anomaly
│ ├── test
│ │ ├── fight
│ │ └── normal
│ └── train
│ ├── fight
│ └── normal
├── anomaly-test.json
├── anomaly-train.json
└── dataset_info.jsonanomaly-train.json(训练集)和anomaly-test.json(测试集)是多模态对话数据集,采用sharegpt格式,可直接使用LLaMA Factory加载数据进行训练。样例数据如下:
[
{
"messages": [
{
"content": "<video>请分析这个视频,是否有打架斗殴等异常行为。如果有,请回答“是的”,如果没有,请回答“没有”,然后对视频进行描述和分析",
"role": "user"
},
{
"content": "是的。\n\n视频中显示两名男子在ATM机前发生肢体冲突。其中一名穿深色衣服的男子对另一名穿条纹上衣的男子进行推搡和拉扯,动作幅度较大,明显属于打架斗殴行为。该行为发生在室内公共区域(银行自助服务区),具有潜在危险性和社会危害性,属于典型的异常行为。监控视角为俯视角度,画面虽略模糊,但足以辨识双方存在激烈肢体对抗。",
"role": "assistant"
}
],
"videos": [
"anomaly/test/fight/fi101.mp4"
]
},
{
"messages": [
{
"content": "<video>请分析这个视频,是否有打架斗殴等异常行为。如果有,请回答“是的”,如果没有,请回答“没有”,然后对视频进行描述和分析",
"role": "user"
},
{
"content": "是的\n\n视频中出现了明显的打架斗殴行为。画面显示多人聚集在一起,其中至少有两人正在发生肢体冲突,有人被推搡、拉扯甚至倒地。周围其他人似乎在围观或试图介入。整个场景混乱,动作激烈,符合“打架斗殴”的定义。由于画质模糊,无法辨识具体人物身份或冲突原因,但肢体冲突的存在明确构成异常行为。",
"role": "assistant"
}
],
"videos": [
"anomaly/test/fight/fi102.mp4"
]
},
]MLLM-Factory代码仓库中data/dataset_info.json是从LLaMA Factory/data拷贝的数据集信息配置文件(dataset_info.json),包含了所有经过预处理的本地数据集以及在线数据集。后面使用LLaMA Factory微调模型时,数据路径请填写MLLM-Factory/data/dataset_info.json的绝对路径。
dataset_info.json数据集信息配置文件,可以参考如下填写,其中anomaly-train.json和anomaly-test.json是项目配套的训练和测试数据集:
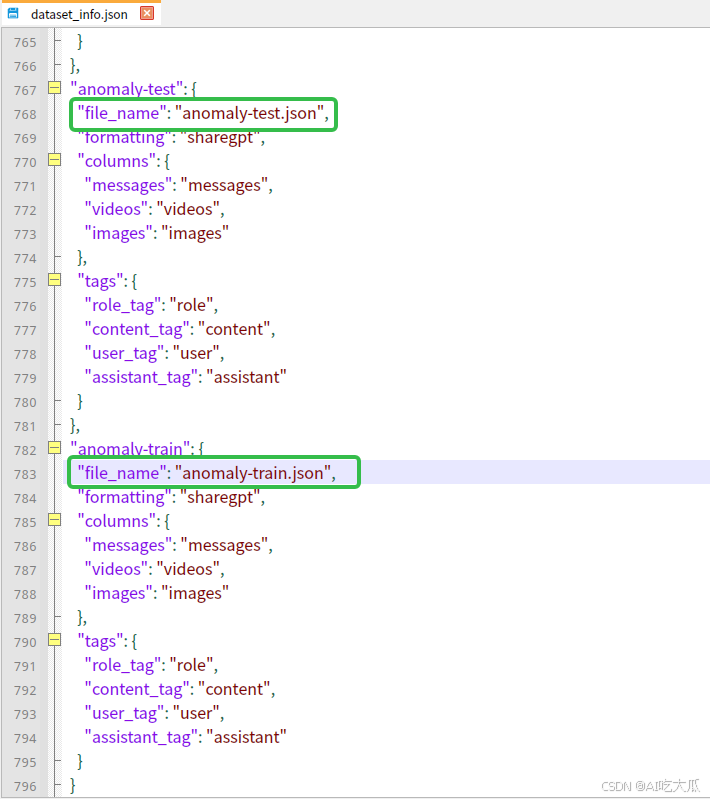
关于数据格式的说明,请参考这里:https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/data_preparation.html
5. Qwen3-VL微调
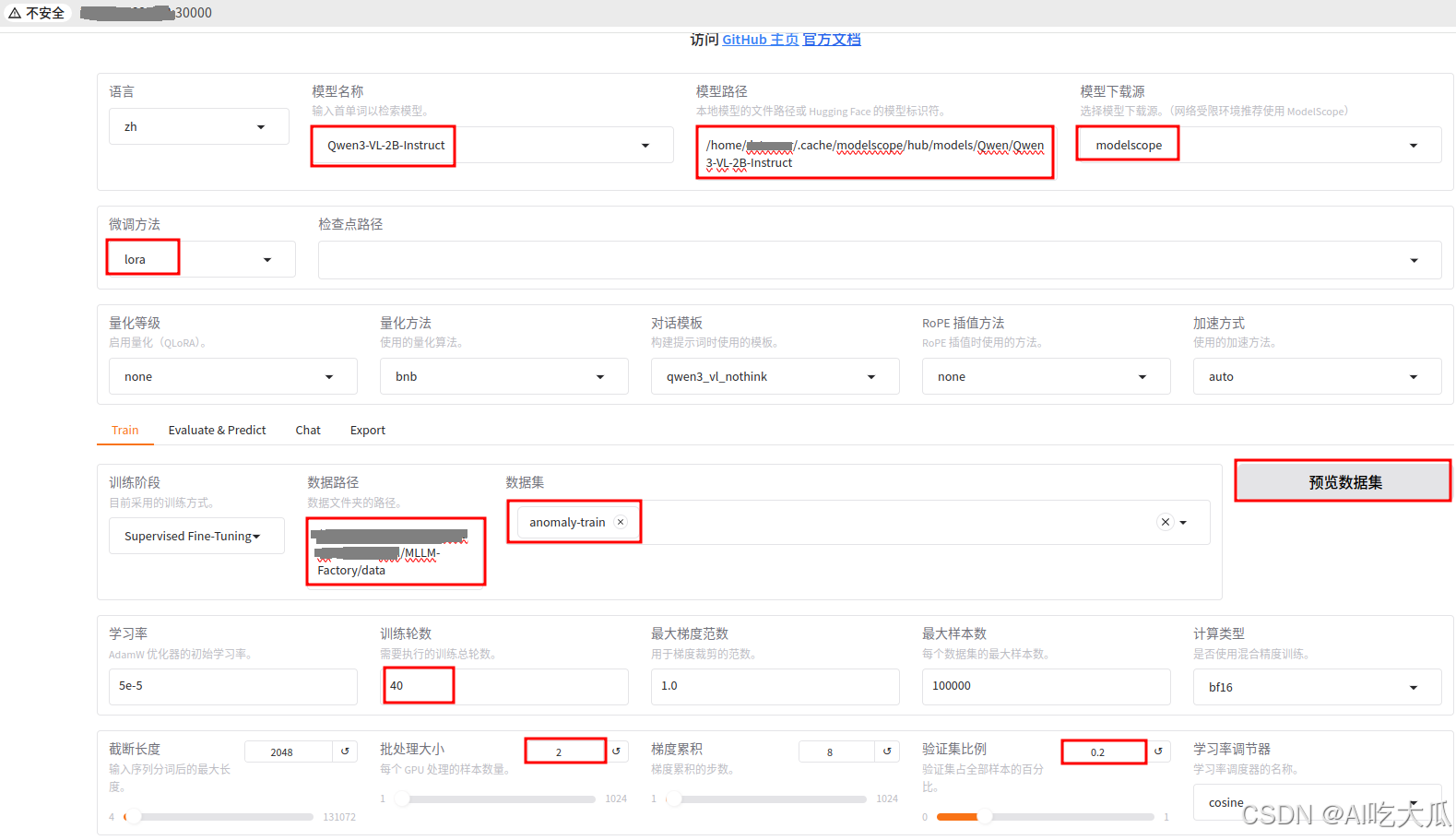
项目采用大型语言模型工厂(LLaMA-Factory)对大模型微调,目前可支持Qwen3 / Qwen2.5-VL / Gemma 3 / GLM-4.1V / InternLM 3 / MiniCPM-o-2.6等大模型。下面以微调Qwen3-VL-2B-Instruct作为例子进行说明。
微调之前,请先下载Qwen3-VL基础模型。下载方法可以选择modelscope和huggingface,国内建议选择modelscope,避免翻墙问题。
modelscope下载Qwen3-VL-2B-Instruct方法,模型默认保存在~/.cache/modelscope/hub/models/
# 使用modelscope下载模型Qwen3-VL-2B-Instruct
# 模型保持在 ~/.cache/modelscope/hub/models/
modelscope download --model Qwen/Qwen3-VL-2B-Instruct 详细的微调方法和教程,请参考这篇博文:
https://blog.csdn.net/guyuealian/article/details/156157608
6. Qwen3-VL部署
(1)模型导出
基于LoRA训练的模型,默认情况下,输出目录只保存了增量的训练参数;你还需要将原始基础模型(--model_name_or_path)和LoRA适配器参数(--adapter_name_or_path)进行合并,生成一个独立的、无需额外加载适配器即可运行的完整模型,便于后续部署或分享。
#!/usr/bin/env bash
# TODO Lora+model合并,参数说明:
#--model_name_or_path:原始基础模型路径,可使用modelscope download --model Qwen/Qwen3-VL-2B-Instruct下载
#--adapter_name_or_path:LoRA适配器路径(即训练输出目录)
#--export_dir:合并后模型的保存路径
#--template default:Qwen3-VL 可使用 default,也可尝试qwen_vl(但通常自动识别)
#--trust_remote_code True:Qwen系列模型必需
export CUDA_VISIBLE_DEVICES=0
model_name_or_path=~/.cache/modelscope/hub/models/Qwen/Qwen3-VL-2B-Instruct
adapter_name_or_path=saves/Qwen3-VL-2B-Instruct/lora/train_2025-12-22-18-08-22/checkpoint-440
export_dir=saves/Qwen3-VL-2B-Instruct/lora/train_2025-12-22-18-08-22/Qwen3-VL-2B-Instruct
llamafactory-cli export \
--model_name_or_path $model_name_or_path \
--adapter_name_or_path $adapter_name_or_path \
--template default \
--finetuning_type lora \
--export_dir $export_dir \
--trust_remote_code True
llamafactory-cli export调用 LLaMA-Factory 的命令行接口(CLI),执行export操作,即导出合并后的模型。model_name_or_path $model_name_or_path指定基础模型(base model)的路径或 Hugging Face 模型 ID。例如:Qwen/Qwen3-VL-2B-Instruct或本地路径~/.cache/modelscope/hub/models/Qwen/Qwen3-VL-2B-Instruct。adapter_name_or_path $adapter_name_or_path指定微调后保存的 LoRA 适配器(adapter)的路径。通常是通过 LLaMA-Factory 微调后生成的包含adapter_model.safetensors或adapter_model.bin的目录。template default指定对话模板(chat template)名称。default表示使用 LLaMA-Factory 中预设的默认模板(通常适用于无特殊对话格式的模型)。其他值如llama3、chatglm3等会根据模型格式自动选择对应的输入格式。finetuning_type lora指定微调方法类型。此处为lora,表示使用的是 LoRA(Low-Rank Adaptation)微调。LLaMA-Factory 也支持full(全参数微调)或pissa等类型。export_dir $export_dir指定合并后模型的输出目录。导出的模型将保存在此路径下,包含 tokenizer、config、权重等完整结构,可直接用于推理或部署。trust_remote_code True允许加载远程自定义代码(如某些 Hugging Face 模型需要modeling_xxx.py等自定义文件)。对于需要自定义建模逻辑的模型(如 ChatGLM、Qwen 等)必须启用该选项。
(2)模型部署
模型训练好后,项目推荐使用vLLM部署模型
- 源码:https://github.com/vllm-project/vllm
- 文档:https://vllm.hyper.ai/docs/
- 安装:pip install vllm
#!/usr/bin/env bash
# TODO 启动vllm服务
export CUDA_VISIBLE_DEVICES=0
# http://0.0.0.0:8000/v1
# model_path=~/.cache/modelscope/hub/models/Qwen/Qwen3-VL-2B-Instruct # 原始基础模型路径
model_path=saves/Qwen3-VL-2B-Instruct/lora/train_2025-12-22-18-08-22/Qwen3-VL-2B-Instruct # Lora微调(合并)后的模型路径
vllm serve $model_path --dtype auto --max-model-len 7680 --max_num_seqs 32 --api-key token-abc123 --gpu_memory_utilization 0.95 --trust-remote-code
- api-key是自定义的服务接口的API访问密钥,后面接口调用需要使用。户端请求需包含:Authorization: Bearer token-abc123,保护服务器免受未授权访问
- model_path 请填写Lora微调(合并)后的模型路径
- dtype auto自动选择模型加载的数据类型,优先使用模型配置文件指定的 dtype。如果没有指定,会根据模型大小和可用 GPU 内存自动选择。常见选择:float16、bfloat16、float32
- max-model-len 设置模型支持的最大上下文长度(token 数),通常是 2048 或 4096
- max_num_seqs 设置批处理的最大序列数,控制同时处理的最大请求
- gpu_memory_utilization 设置 GPU 内存利用率目标,0.95 的含义:尝试使用 95% 的可用 GPU 内存
启动成功后,可以看到 Starting vLLM API server 0 on http://0.0.0.0:8000等信息,这是就是vLLM服务接口,后续可以基于该接口实现聊天对话功能。关于vLLM服务的接口说明,请参考https://vllm.hyper.ai/docs/
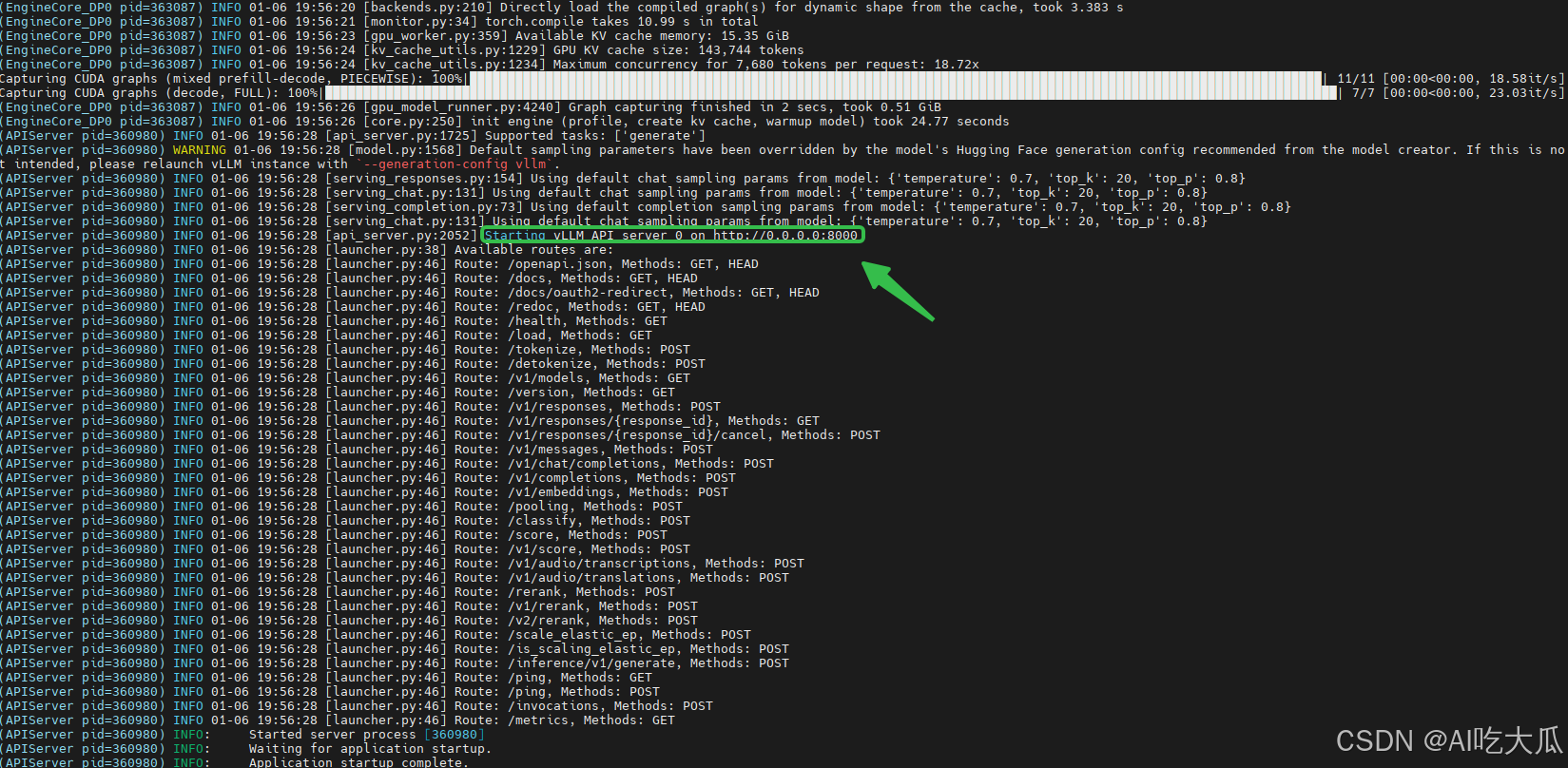
7. 模型测试
(1)测试准确率
项目提供测试打架斗殴异常行为识别准确率的脚本,test/test_accuracy.py,请将url地址改为vLLM服务的接口地址,key修改为启动vLLM服务时设置的(--api-key),然后运行:
# 请先修改url和key,再运行
python test/test_accuracy.py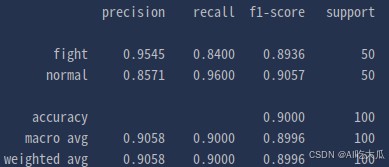
| 模型 | 准确率 |
| Qwen3-VL-2B-Instruct | 84.0% |
| Qwen3-VL-2B-Instruct(lora微调) | 90.0% |
原始的Qwen3-VL-2B-Instruct模型,打架斗殴异常行为识别测试准确率只有84%;经过lora微调后,准确率提升到90%,提升了6%。
(2)Demo测试
项目提供文本、图片和视频接口调用的例子:
# 请将url地址改为vLLM服务的接口地址,key修改为启动vLLM服务时设置的(--api-key)
python test/test_texts.py # 文本对话
python test/test_images.py # 图像理解
python test/test_videos.py # 短视频理解此外,项目基于Gradio开发了一个VQA视觉问答对话Web服务,支持文本、图片和视频以及摄像头对话和聊天。
在MLLM-Factory根目录,修改文件web.py,请将url地址改为vLLM服务的接口地址,key修改为启动vLLM服务时设置的(--api-key):
# 编辑修改web.py
key = "token-abc123" # API密钥,需与vLLM启动服务时设置的(--api-key)保持一致
url = "http://0.0.0.0:8000/v1" # vllm地址然后运行
# cd MLLM-Factory
python web.py然后浏览器打开:http://0.0.0.0:7860/
使用说明:
- 可以直接在输入框输入文本,开启文本对话模式
- 点击附件上传图片并输入问题,开启图文问答模式(注意一次只能上传一张图片)
- 点击附件上传视频并输入问题,开启视频问答模式(注意一次只能上传一个视频)。如果需要开启摄像头,请新建camera.txt文件,并写入摄像头ID,然后作为附件上传对话即可。
- 注意:开启视频或者摄像头分析时,系统默认1秒抽2帧(fps=2),每6帧(约3秒视频)组成图片序列,且序列之间重叠40%(overlap=0.4),发起请求进行视频分析。受显卡性能影响,视频播放可能会出现卡顿现象(在RTX 3090测试几乎可以实时);如果,你需要实时分析模式,请点击输入框下面的按钮【实时】,这时系统通过队列缓冲的方式,实时读取缓冲数据进行分析,但分析数据可能会出现丢帧问题。
demo效果:
打架斗殴异常行为视频分析
输入提示词:请分析这个视频,是否有打架斗殴等异常行为。如果有,请回答“是的”,如果没有,请回答“没有”,然后对视频进行描述和分析
8. 常见错误
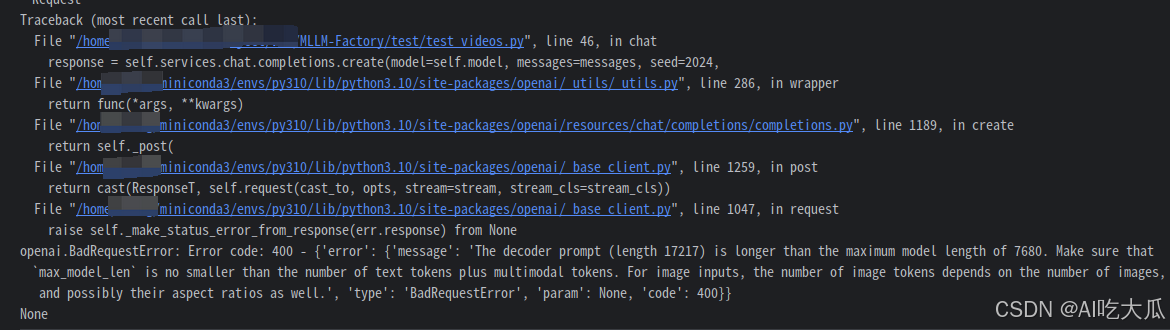
(1)错误:'The decoder prompt (length 17217) is longer than the maximum model length of 7680
- 问题原因:这个问题是输入给模型的提示(prompt)太长了。当文本和多模态内容,如图视频/图片的总token数超过了模型处理的最大限制,就会出现这个异常。
- 解决方法:启动vllm服务时,增加max-model-len 7680的数值,但这需要更大显存。或者减少视频/图片的总数。max-model-len=7680,仅支持5秒内的短视频。
9. 项目代码
如需下载项目源码,请WX关注【AI吃大瓜】,回复【打架斗殴】即可下载
(1) 打架斗殴异常行为多模态视频数据集
- 训练集约200个短视频,测试机约100个短视频,绝大部分视频截取关键视频内容,时长约0.5~3秒。视频样本数据保存在fight和normal文件夹中,其中fight文件夹表示这些样本视频,是打架斗殴异常行为;而normal文件夹属于负样本数据,是非异常行为的视频数据。
- 提供多模态对话视频数据集的标注文件,anomaly-train.json(训练集)和anomaly-test.json(测试集),采用sharegpt格式,可直接使用LLaMA Factory加载数据进行训练
(2) 打架斗殴异常行为多模态视频数据集+项目配套代码
- 训练集约200个短视频,测试机约100个短视频,绝大部分视频截取关键视频内容,时长约0.5~3秒。视频样本数据保存在fight和normal文件夹中,其中fight文件夹表示这些样本视频,是打架斗殴异常行为;而normal文件夹属于负样本数据,是非异常行为的视频数据。
- 提供多模态对话视频数据集的标注文件,anomaly-train.json(训练集)和anomaly-test.json(测试集),采用sharegpt格式,可直接使用LLaMA Factory加载数据进行训练
- 提供测试打架斗殴异常行为识别准确率的脚本,test/test_accuracy.py
- 提供文本、图片和视频接口调用的例子test/test_texts.py,test/test_images.py和test/test_videos.py
- 提供Gradio开发的web服务(python web.py),支持文本、图片和视频以及摄像头对话和聊天;视频和摄像头对话支持实时和非实时两种模式。
- 提供完整的项目代码和以及微调后模型文件,配置好开发环境,即可运行,可用于二次开发。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 46
46 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)