最好懂 | 经典机器学习算法入门
机器学习经典算法最好懂!看不了吃亏看不了上当!没有术语堆砌!小白友好!图文并茂!AI盛行的年代还有人坚持手搓!
本篇纯手搓,适合新手入门,想对机器学习算法原理有初步了解的那种。主包也是0基础自学的,看了很多帖子,有的帖子很多术语,就又去找另外的帖子又去问AI的。所以现在写出来的都是自己再过一遍的,一些术语也有附带解释,自认为没什么疑难点了。可能不全面,但一定能懂。
目录
一、线性回归
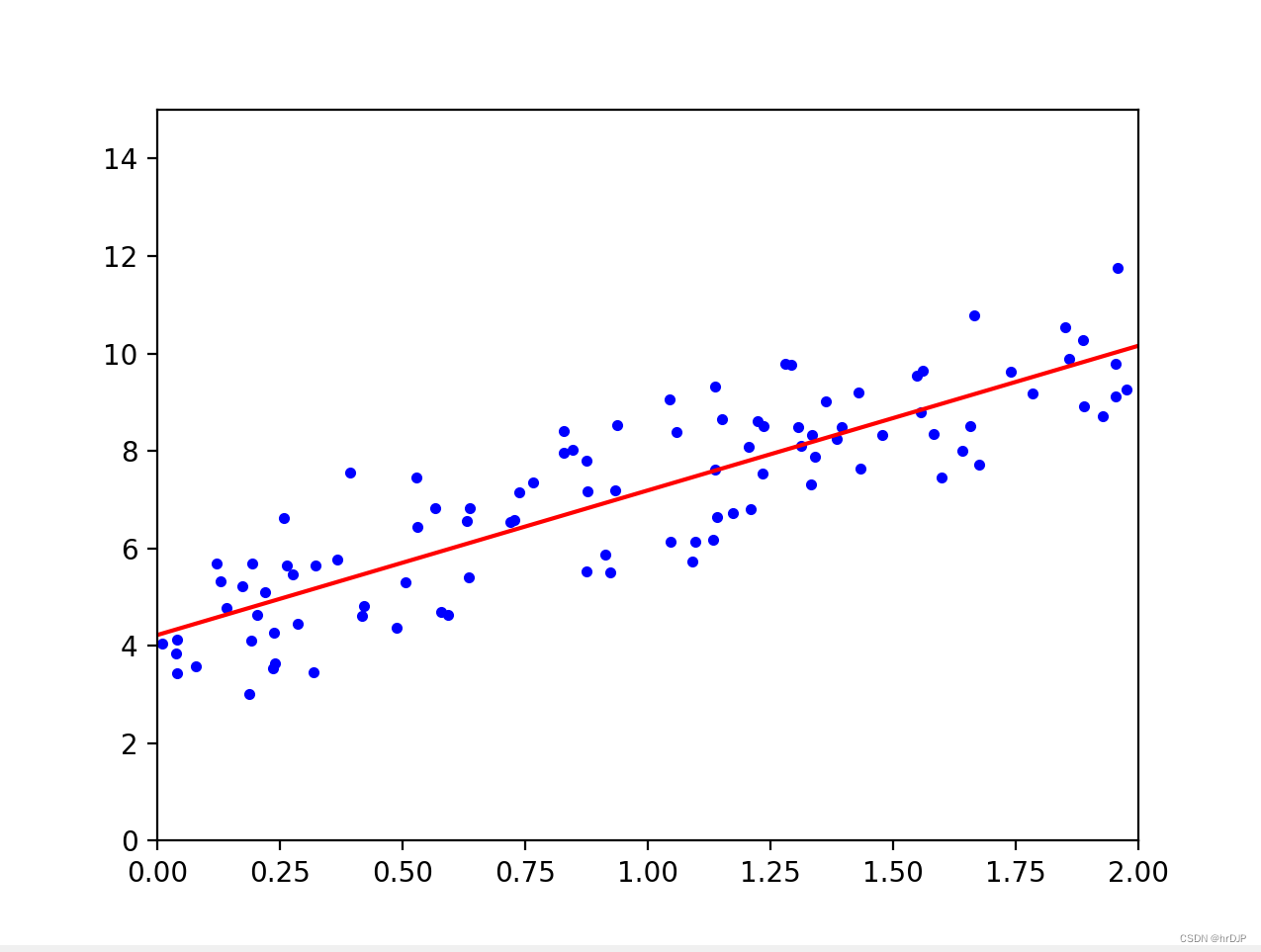
机器学习的祖师爷,原理也很简单,通过对XOY二维平面上的点线性拟合,来预测只知道X值的点对应的Y值是多少。
| 优点 | 缺点 |
| 实现简单 | 对高复杂数据不适用 |
| 非线性模型的基础 | 非线性或数据特征间具有相关性的多项式难以建模 |
二、逻辑回归
用于分类任务(通常是二分类),利用Sigmoid 函数将线性回归的输出映射为一个概率值,从而进行分类。
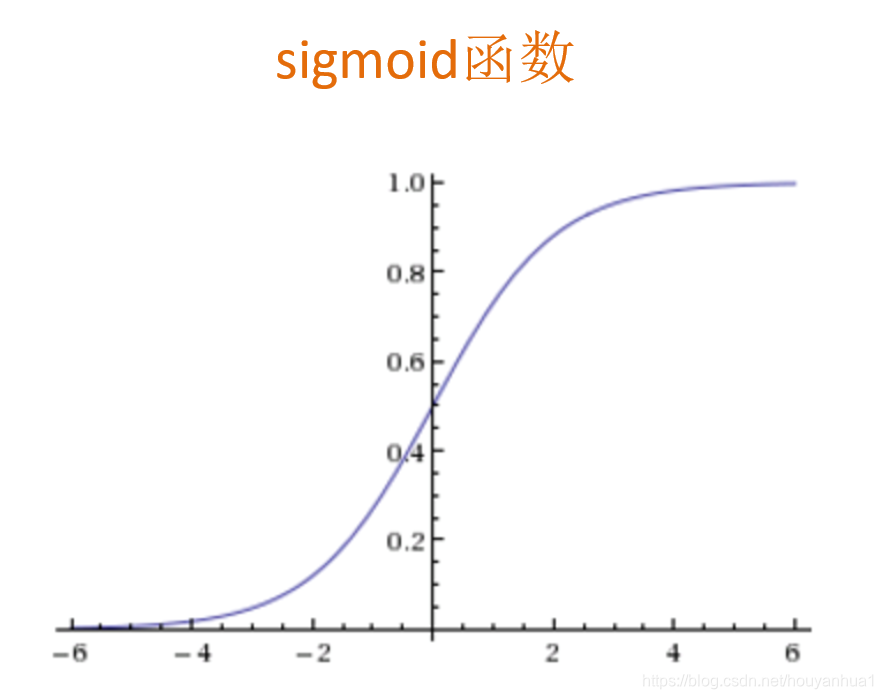
sigmoid函数取值在(0,1)之间,所以解释为概率。
当概率大于阈值时,判断为类别a,否则为类别b。
| 优点 | 缺点 |
| 实现简单 | 特征空间很大时,性能欠佳 |
| 计算量小 | 只能处理二分类线性可分问题 |
| 可观测样本的概率分数 | 容易欠拟合,一般准确度不高 |
三、KNN(K近邻算法)
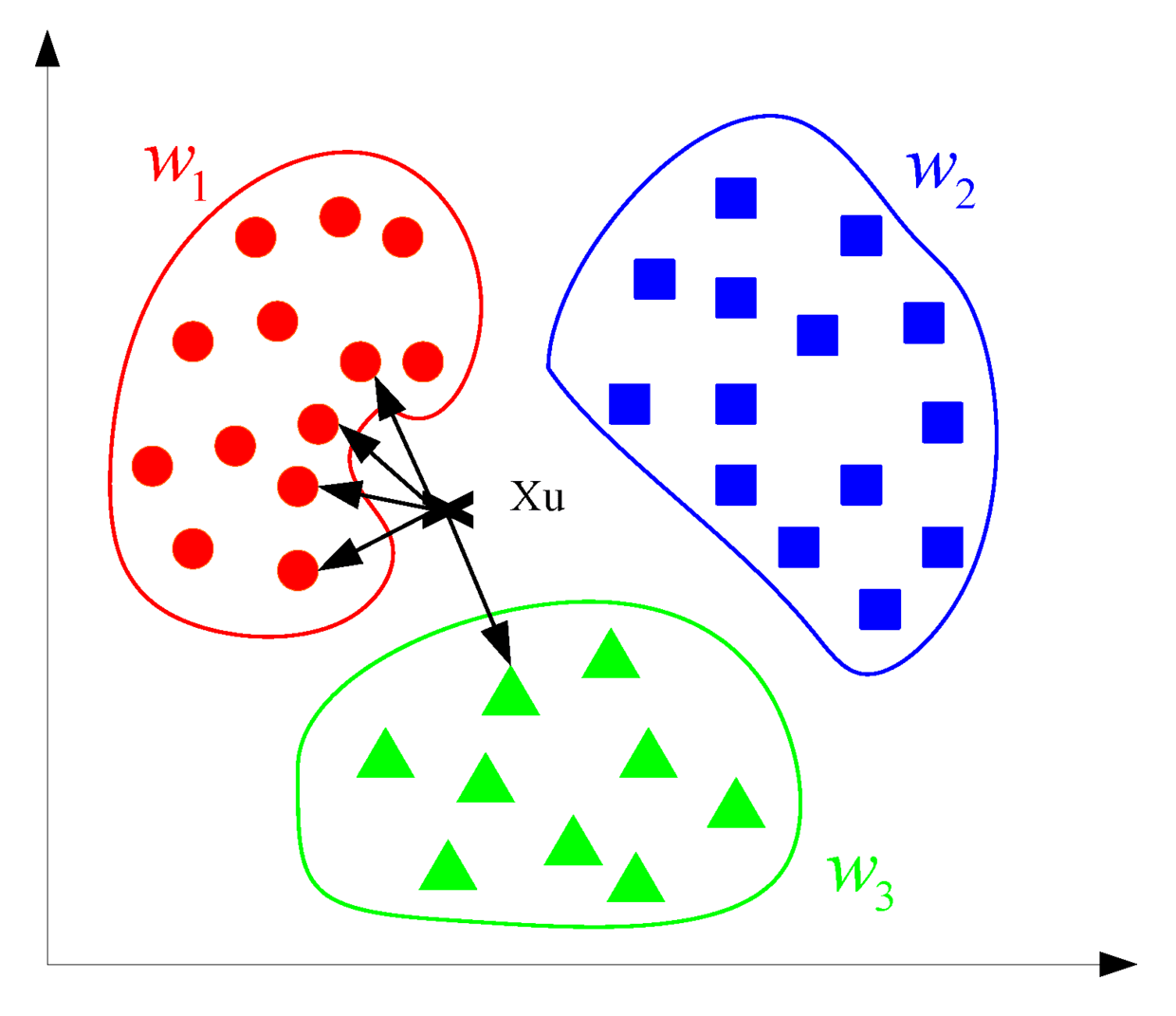
对于待判断的点,找到离它最近的几个数据点,根据它们的类型决定待判断点的类型。
| 优点 | 缺点 |
| 思想简单 | 计算量大 |
| 适用非线性 | 样本不均衡问题 |
| 准确度高 | 需大量内存 |
| 对异常值不敏感 |
四、K-means
聚类算法,将数据分为K个簇,使每个数据点属于距离最近的簇头。
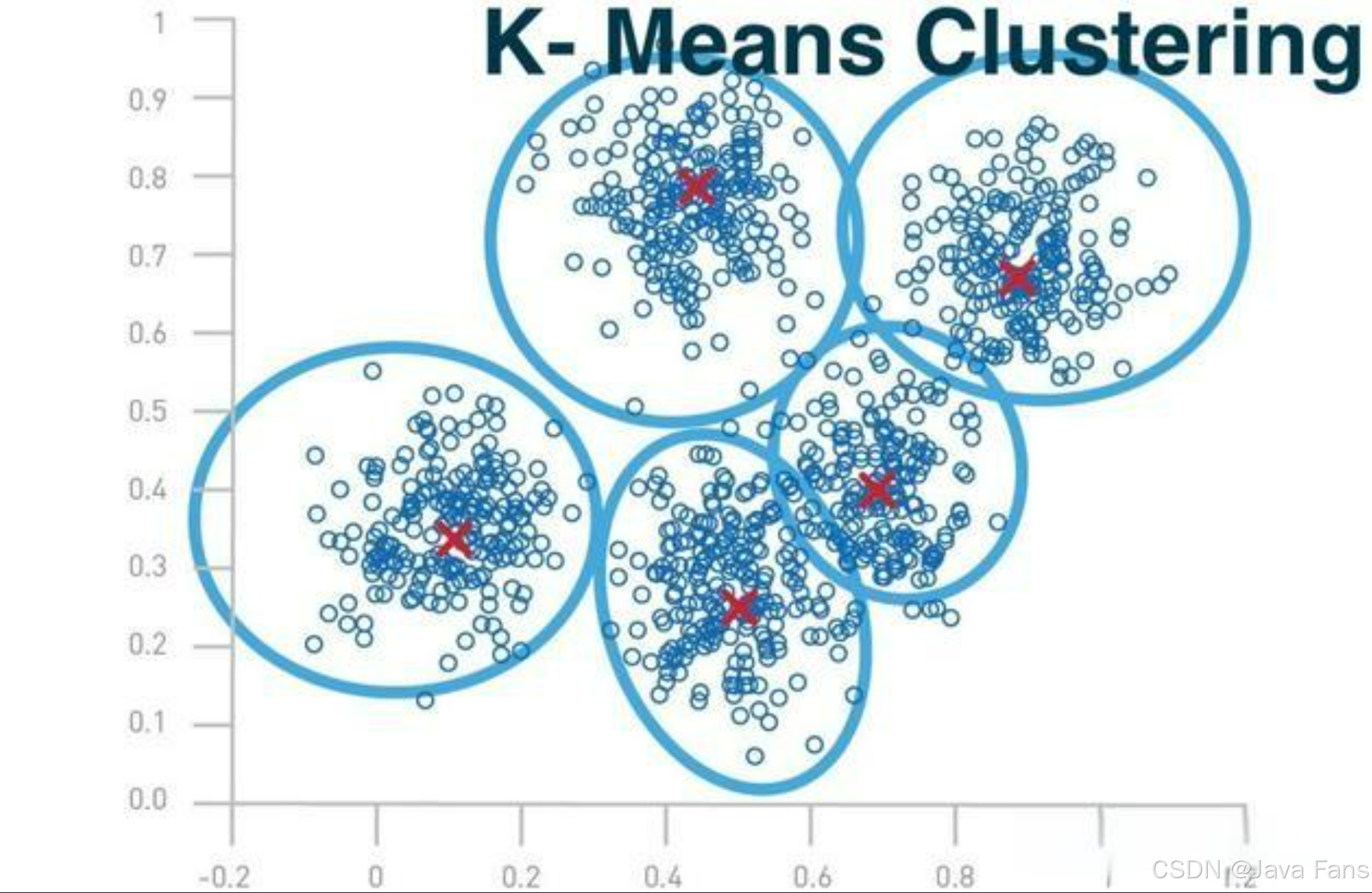
步骤:
- 随机选择K个簇中心(初始簇中心)。
- 将数据中的每个点分配到最近簇中心的簇(目标是最小化每个节点到簇中心的距离)。
- 计算每个簇的中心(簇中所有点的均值作为新的簇中心)。
- 重新分配与更新(重复步骤2~3),直至簇中心不再发生变化。
| 优点 | 缺点 |
| 易实现 | K值需先确定 |
| 内存占用小 | 需先选取初始聚类中心点 |
| 不适合所有数据类型 | |
| 需检测离群点 |
五、朴素贝叶斯(NB)
朴素贝叶斯基于条件概率,可以理解为人脑在知道新的证据后如何更新信念。

核心公式:
以下是对公式的解释:
- Y=c:样本属于类别c
- X:样本的特征
- P(Y=c|X):后验概率。即已知样本特征X时,它属于类别c的概率。也可以理解为,获取样本特征信息后,对“样本属于某类”的概率的修正结果。
- P(Y=c):先验概率。类别c在所有样本中出现的基础概率。无任何特征信息,仅基于统计/历史。
- P(X|Y=c):似然概率。已知样本属于类别c时,它拥有特征X的概率。
- P(X):样本出现特征X的总概率。
举个🌰:
假设我们统计了 100 封邮件,其中垃圾邮件 30 封,正常邮件 70 封。
同时在这些邮件里,统计两个关键词“中奖”/“发票”的出现情况:
- 垃圾邮件中,有 “中奖” 这个词的概率是 80%,有 “发票” 这个词的概率是 70%。
- 正常邮件中,有 “中奖” 这个词的概率是 5%,有 “发票” 这个词的概率是 10%。
现在收到一封新邮件,里面同时有 “中奖” 和 “发票” 两个词,要判断它是不是垃圾邮件。
- 概率 1:这封邮件是垃圾邮件的概率=垃圾邮件的基础概率 × 垃圾邮件里有‘中奖’的概率 × 垃圾邮件里有‘发票’的概率=30% × 80% × 70% = 16.8%。
- 概率 2:这封邮件是正常邮件的概率=正常邮件的基础概率 × 正常邮件里有‘中奖’的概率 × 正常邮件里有‘发票’的概率= 70% × 5% × 10% = 0.35%。
在这个例子中,P(X)视为1。
因为概率1远大于概率2,所以判定这封邮件为垃圾邮件。
注意,朴素贝叶斯一定要特征相互独立(相互独立才能概率相乘)。
| 优点 | 缺点 |
| 有坚实的数学基础 | 需计算先验概率 |
| 对小规模数据表现好 | 不适用于特征相关数据 |
| 对缺失值不敏感 |
六、支持向量机SVM
找到不同类别之间的分类面(也称“超平面”),使两类样本尽量落在面的两边,且离分类面尽量远。
- 几何间隔:样本到超平面的垂直距离。
- 支持向量:几何间隔最小的样本(决定了超平面的位置)。(实际上起作用的也只有这部分向量)
支持向量机的目标是最大化最小间隔。
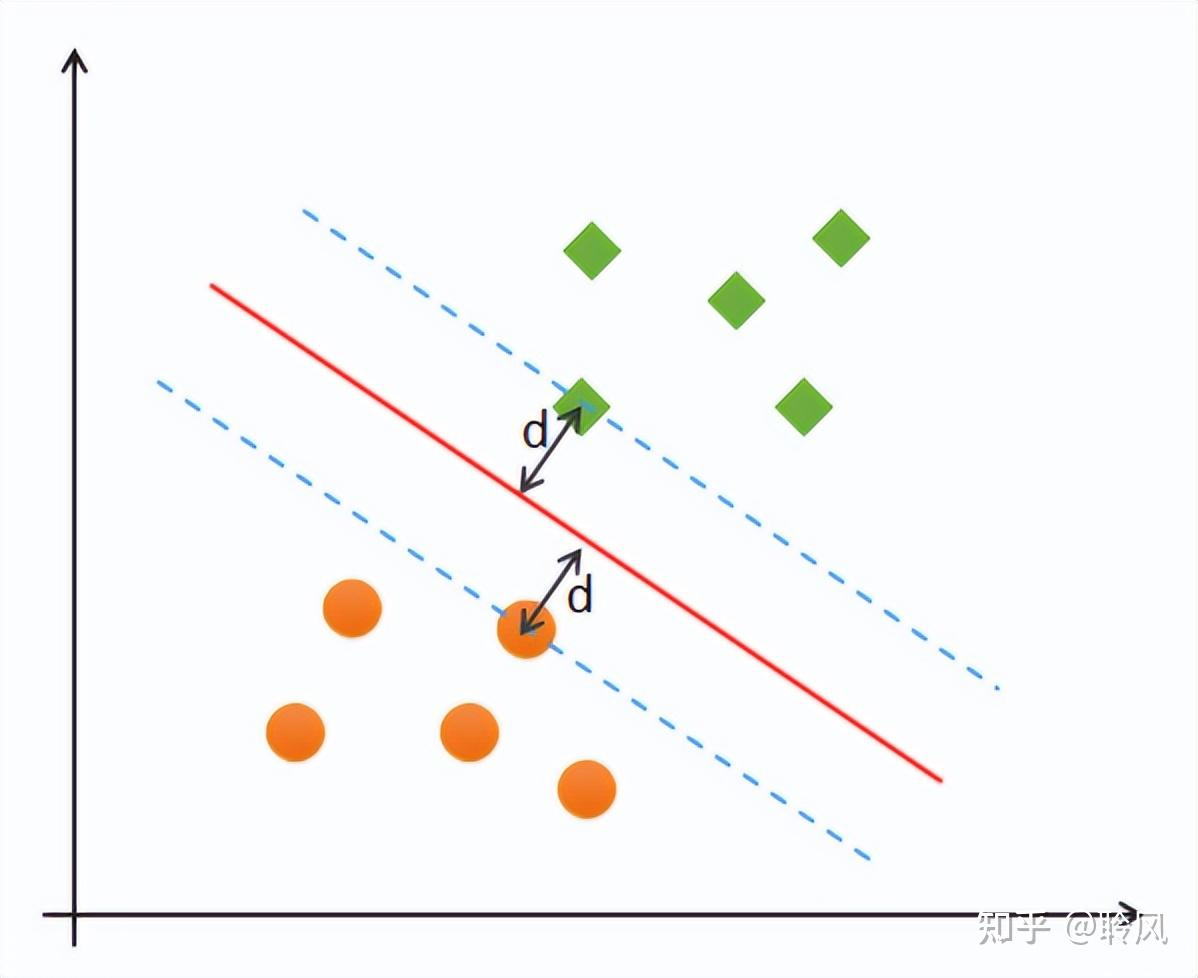
有两种分类情况:
1. 线性可分
分类约束条件:所有样本被超平面正确分类,且几何间隔≥1
2. 线性不可分
线性不可分总共有两种情况:1)低维空间找不到超平面分开两类样本;2)样本中存在异常值
1)2)分别对应的解决方法:
1)引入核函数(知道这个名称就好了具体是啥不用管,不同样本分类中核函数都不一样),将样本映射到高维空间(结合向量映射理解),使其变得线性可分;
2)引入软间隔(也称“松弛变量”),退一步,允许少量样本违反分类约束条件。软间隔表示样本的“违规程度”。
目的是平衡“间隔最大化”和“分类错误最小化”。
| 优点 | 缺点 |
| 可解决高维问题 | 当样本多时,效率不高 |
| 能处理非线性特征的相互作用 | 对非线性问题难以找到通用的核函数 |
| 无需依赖整个数据 | 对缺失数据敏感 |
七、决策树(DT)
以树状结构做决策:每个“分叉点”是对一个特征的判断;每个“终点”是最终的分类结果。
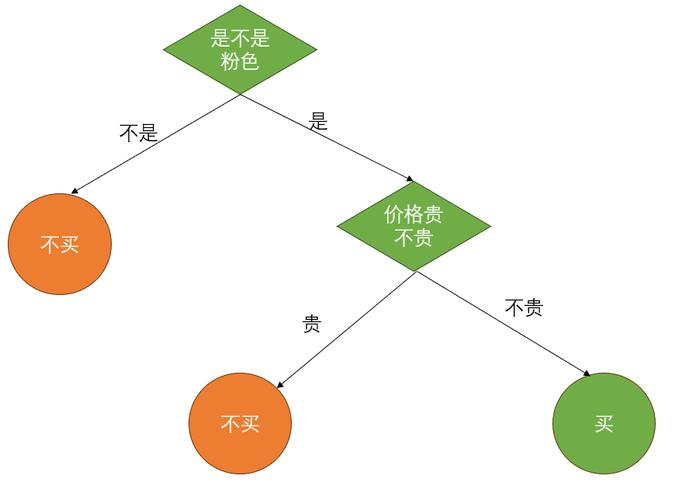
纯度:节点中样本类别的集中程度(纯度越高,判断越明确)
🌰: 初始样本集有10个样本(6个"去野餐",4个"不去"),纯度较低;用"天气是否晴朗"划分后,"晴朗"子集中有6个"去野餐"(纯度100%),"不晴朗"子集中有4个"不去"(纯度100%),这就是最优划分。
最大化纯度方法:
1. 信息熵+信息增益
信息熵衡量“样本集混乱程度”
信息增益 = 划分前信息熵 - 划分后各节点信息熵的加权和
【增益越大,纯度提升越多,分类效果也越好】
存在偏好“多取值特征”的问题。举个🌰,如果用身份证号做判断条件,信息增益都很大,无法比较;这样分类出来也没有意义,没有泛化能力。
2.信息增益比
针对信息增益的问题,引入信息增益比。
增益比=信息增益/特征熵
还是上面身份证号的例子,这种情况下特征熵极大,于是增益比被压小到可比较的范围。
3. 基尼系数
衡量“随机抽取两个样本是不同类别”的概率。基尼系数越小,纯度越高。
目的:最小化类别划分后子节点的基尼系数加权和
| 优点 | 缺点 |
| 计算简单 | 容易过拟合 |
| 能处理不相关的特征 | 易被攻击 |
| 适合有缺失特征的样本 | 忽略了数据间的相关性 |
八、由决策树集成学习的算法
集成学习:通过组合多个弱学习器(如决策树),以获得比单一模型更好的性能。
8.1 随机森林(RF)
并行集成决策树,每棵决策树随机选取训练样本,随机选取特征。
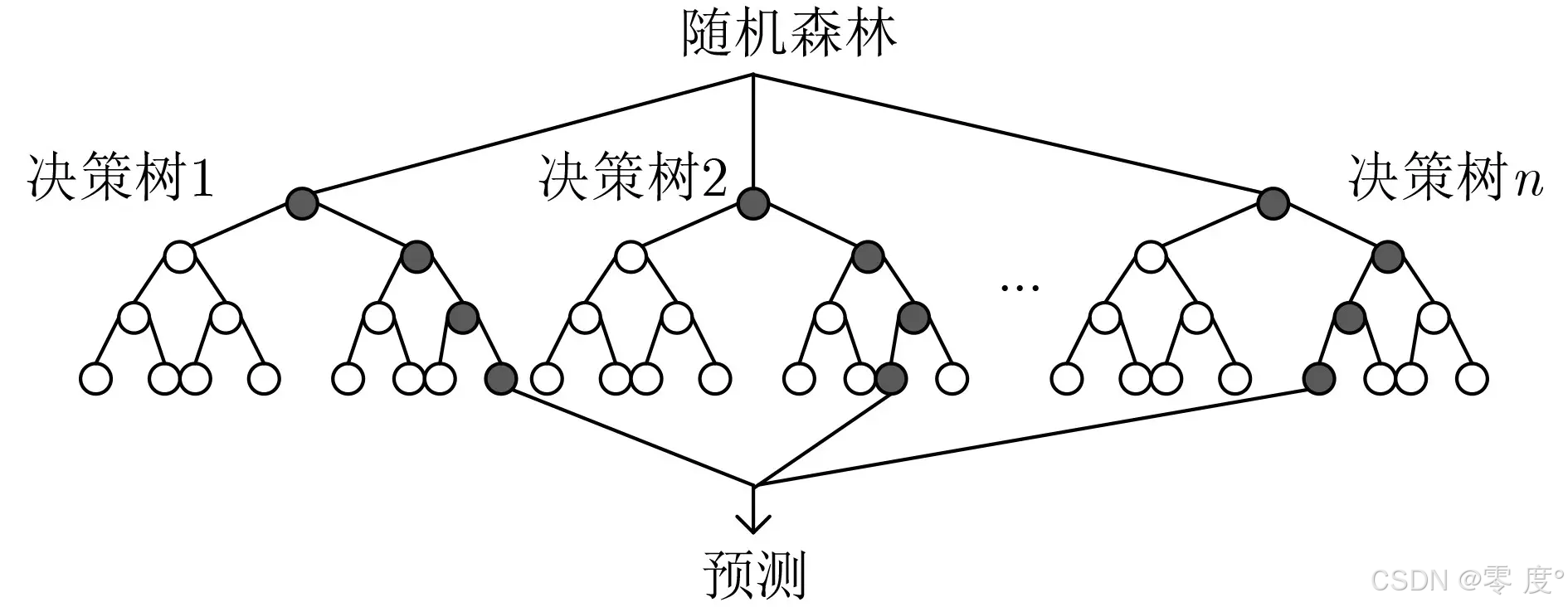
随机森林解决两类问题:
1)分类问题:每棵树给出一个预测,最终预测结果是所有树预测结果的多数投票。
2)回归问题:所有树预测结果的平均值。
8.2 GBDT
串行集成决策树,逐棵树迭代纠错,最终叠加所有树的结果形成完整模型。
步骤:
- 从初始模型起步。先设定一个简单的初始模型,一般是训练集标签的均值,这个初始模型能给出一个基础的预测值。
-
计算伪残差,确定纠错目标。有了初始模型的预测值后,就可以算出当前模型的预测和真实值之间的误差(即伪残差)。它代表了当前模型还没拟合到的部分,是下一棵树需要修正的 “目标”。
-
训练新树拟合伪残差。接下来训练一棵新的CART回归树,这棵树的训练数据是伪残差。这棵树的作用就是学习 “怎么调整当前模型的预测值,才能减小误差”。
-
加法集成,更新模型。新树训练好之后,把这棵树的预测结果乘以一个小的学习率(控制每棵新树的预测结果在集成模型中的贡献权重),串行加到原来的模型上,形成更新后的模型。
-
重复上述步骤,迭代直到收敛。
残差:模型预测值和真实值的差距。
伪残差:负梯度,损失减小最快的方向。在MSE损失(平方损失)下,伪残差=残差。
CART回归树:按样本的特征把数据分成小群体,用每个小群体的平均值预测新样本连续数值的工具。GBDT的每棵树都是CART回归树,输出连续纠错值,才能叠加。
8.3 XGBoost
原理同GBDT。
对GBDT的改进:
- 在目标函数中加入正则化项,降低模型复杂度,提高泛化能力。
- GBDT仅用损失函数的一阶梯度优化,而XGBoost利用泰勒展开将损失函数近似为二阶函数,收敛更快。
- 生成更优树。计算每个特征分裂点的“分裂增益”(目标函数降低的程度),选择增益最大的分裂点。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)