【技术干货】AI Agent上下文工程:50次工具调用后的记忆保持策略 | 程序员必学
AI Agent在执行多次工具调用后会出现"上下文腐烂"问题,导致性能下降。Manus公司提出三大解决策略:缩减(双版本机制和结构化摘要)、隔离(多Agent架构)和卸载(分层动作空间与文件存储)。这些策略相互支撑,通过简化设计、跨模型验证和多维度评测体系,确保架构能适应未来模型发展。核心观点是"简化优于扩展",避免过度设计成为性能瓶颈。
本文探讨AI Agent在多次工具调用后的"上下文腐烂"问题,介绍Manus公司三大解决策略:缩减(双版本机制和结构化摘要)、隔离(多Agent架构)和卸载(分层动作空间与文件存储)。这些策略相互支撑,帮助Agent保持长期任务性能。文章强调简化设计优于扩展,建议采用跨模型验证和多维度评测体系,确保架构能适应未来模型发展,避免成为性能瓶颈。
当 AI Agent 执行 50 次工具调用后,它的"记忆"还能保持清醒吗?
写在前面
最近因为在做上下文工程/Memory 相关的事情,完整地看了一下 Lance Martin 与 Manus 联合创始人兼 CSO Yichao “Peak” Ji 的网络研讨会技术分享[1](原文笔记[2])。
本文来自我看完网络研讨会后的笔记(文中配图也来源于原文),仅用作学习交流用,可能存在理解偏差或事实问题,欢迎指正。如有内容侵权,可联系本人删除。
这篇文章的初衷主要是:
- 自己做笔记
- 让更多人知道这个分享
我还是推荐大家去读原文、看原视频。 我这里的笔记都存在压缩,或者是在通过自己的理解转译之后,可能存在些许偏差。如果你是专业做这个领域的,一定要去读原文和视频。
Manus 是目前最受欢迎的通用 AI Agent 之一,一个典型的 Manus 任务平均需要调用 50 次工具。这意味着什么?意味着上下文窗口会被大量的对话历史、工具调用结果、中间状态填满。
而随着上下文窗口填满,LLM 的性能会显著下降——这就是所谓的「上下文腐烂[3]」(Context Rot)。
正如 Andrej Karpathy[4] 所说:
上下文工程是一门精细的艺术和科学,旨在为 Agent 轨迹的下一步填充恰到好处的信息。
那么,Manus 是如何解决这个问题的?
三大核心策略
Manus 的上下文工程可以概括为三个核心策略:
缩减(Reduction)→ 隔离(Isolation)→ 卸载(Offloading)
这三者不是孤立的,而是相互支撑的系统。
策略一:上下文缩减(Context Reduction)
1. 工具结果的双版本机制
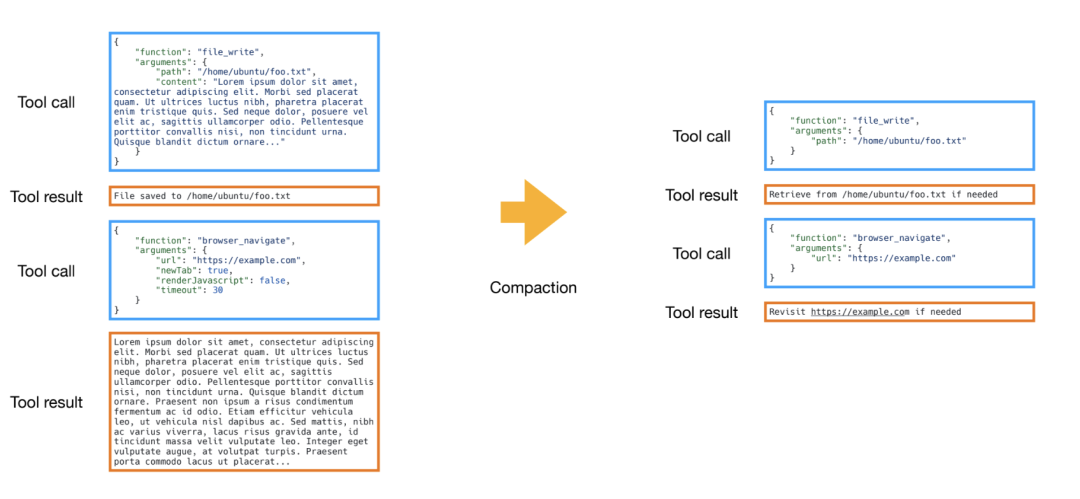
Manus 为每个工具调用维护两个版本:
| 版本 | 说明 |
|---|---|
| 完整版 | 原始内容(如完整搜索结果),存储在文件系统 |
| 紧凑版 | 只存储引用(如文件路径) |
压缩策略:
- 对「陈旧」的工具结果应用压缩,用紧凑版替换完整版
- 保留较新的结果完整版,以指导 Agent 的下一步决策
- Agent 需要时仍可通过引用获取完整内容
这就像是把不常用的文件移到外部硬盘——节省空间,但随时可取。
2. 结构化摘要
当压缩达到收益递减点时,Manus 会对整体轨迹进行摘要。
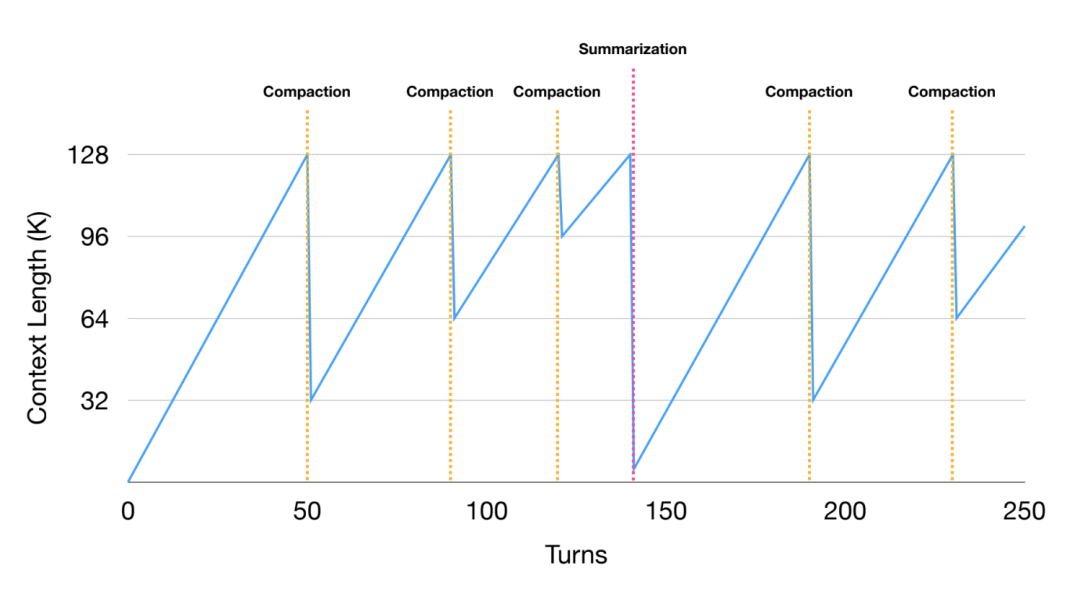
💡 所谓「收益递减点」,是指继续逐条压缩工具结果的边际收益开始下降——此时与其继续逐条微调,不如直接做一次整体摘要。这通常发生在上下文积累到一定规模后,冗余信息增多,继续压缩的复杂度和成本上升。
如何确保摘要的准确率?
关键技巧是避免 free-form 格式,采用结构化 Schema:
- ❌ 不要让 AI 自由发挥写摘要(容易遗漏关键信息、格式不一致)
- ✅ 预定义摘要的 Schema/表格结构,让 AI 直接往格式里填充
- 这样可以确保摘要的完整性和一致性,减少信息丢失
策略二:上下文隔离(Context Isolation)
务实的多 Agent 设计
很多人设计多 Agent 系统时,喜欢模拟人类分工——设计师、工程师、项目经理……
但 Peak 的观点很直接:避免拟人化分工。
人类因认知限制而按角色组织,但 LLM 不一定有这些限制。
子 Agent 的核心目标是隔离上下文,而非模拟人类分工。
架构设计
| 组件 | 职责 |
|---|---|
| 规划器(Planner) | 分配任务 |
| 知识管理器(Knowledge Manager) | 审查对话,决定什么应保存到文件系统 |
| 执行器子 Agent(Executor) | 执行规划器分配的任务 |
上下文共享的艺术
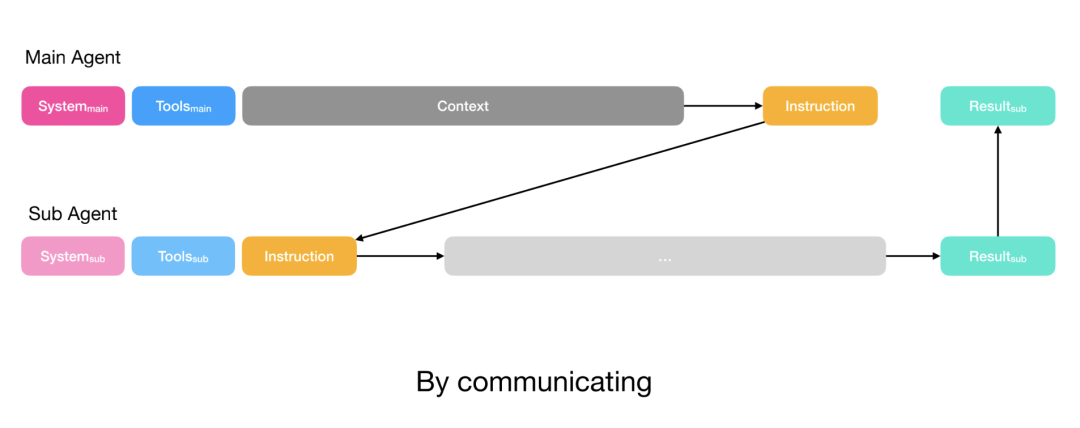
根据任务复杂度采用不同策略:
- 简单任务:规划器通过函数调用传递指令,只需获取输出
- 复杂任务:共享完整上下文,子 Agent 有自己的工具和指令
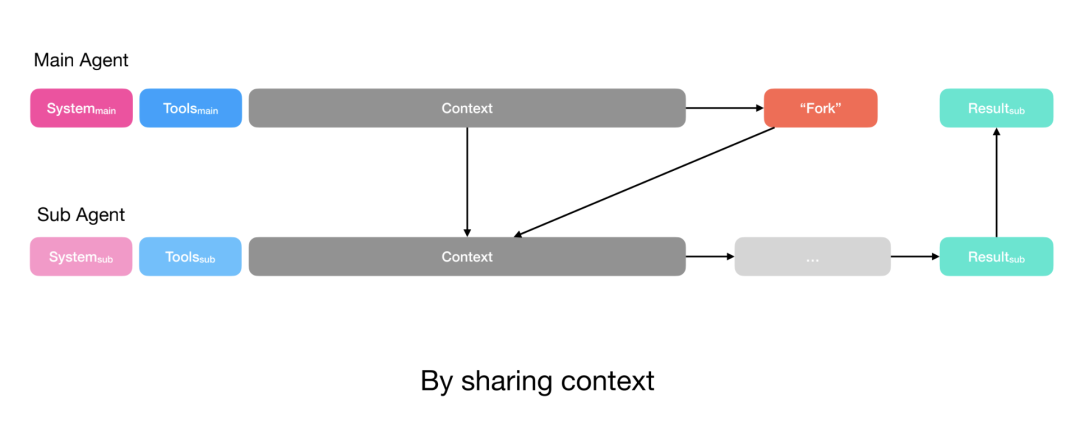
💡 踩坑教训
Manus 最初用 todo.md 做任务规划,结果发现约 1/3 的动作都在更新待办列表,浪费了宝贵的 token。
后来改用专门的规划器 Agent,问题迎刃而解。
策略三:上下文卸载(Context Offloading)
分层动作空间(Hierarchical Action Space)
绑定大量工具会消耗 token,且可能造成模型困惑。Manus 的解决方案是三层架构:
Level 1: Function Calling(函数调用层)
- 标准的、schema-safe 的调用方式
- 使用少量(< 20 个)原子函数:message, shell, search, file, browser 等
- ⚠️ 缺点:每次变化都会破坏 KV Cache,太多函数会导致上下文混淆
Level 2: Sandbox Utilities(沙箱工具层)
- 每个会话运行在完整的 VM 沙箱中
- 模型可以调用 shell 工具(CLI),如
$ manus-mcp-cli、$ manus-render-diagram - ✅ 优点:易于扩展,无需修改模型上下文;适合大输出 → 写入文件
Level 3: Packages & APIs(包与 API 层)
- Manus 编写 Python 脚本来调用预授权的 API
- 适合数据密集型或链式任务
- 例如:
fetch city → get ID → get weather → summarize - ✅ 核心理念:保持模型上下文干净,只用上下文做推理
工具结果的卸载
- 工具结果卸载到文件系统,生成紧凑版引用
- 使用基本工具(如
glob和grep)搜索文件系统,无需索引或向量存储
设计理念
这与 Claude Code 的 Skills 功能[5]理念相似——渐进式披露(Progressive Disclosure)。
Skills 存储在文件系统而非绑定为工具,Claude 只需几个简单的函数调用就能按需发现和使用它们。
三大策略的协同关系
这三个策略不是孤立的,而是相互支撑:
卸载 + 检索 → 使压缩成为可能(完整数据可按需恢复) ↓可靠的检索 → 使隔离成为可能(子 Agent 可获取需要的上下文) ↓隔离 → 减少压缩频率(每个子 Agent 有独立窗口) ↓ 所有策略都在 KV Cache 优化的框架下运作
模型路由策略
Manus 采用任务级路由,不同任务使用不同模型:
| 任务类型 | 推荐模型 |
|---|---|
| 编码 | Claude |
| 多模态任务 | Gemini |
| 数学和推理 | OpenAI |
同时利用 KV Cache 优化成本和延迟。
构建时牢记 Bitter Lesson
Lance 在原文中将 Manus 的设计理念与**苦涩的教训(Bitter Lesson)[6]**联系起来:
- 保持简单和无偏见的设计——更容易适应模型改进
- 接受持续变化——Manus 自 3 月发布以来已重构 5 次!
- 避免限制性框架——Agent 的 harness 可能限制性能随模型提升
验证方法:跨模型测试
在 Peak 的分享中,被问及如何验证不同 Agent 有没有受到限制性框架影响智能时,他的方法是:
- 在不同强度的模型上运行 Agent 评估
- 如果性能没有随更强模型提升,说明你的框架正在拖累 Agent(harness is hobbling the agent)
- 这可以帮助验证你的架构是否「面向未来」(能够适应未来模型的进展)
正如 Hyung Won Chung[7] 也曾建议道:
“Add structures needed for the given level of compute and data available. Remove them later, because these shortcuts will bottleneck further improvement.”
(根据当前可用的计算和数据添加必要的结构,之后再移除它们,因为这些捷径会成为进一步改进的瓶颈。)
关于评测
Manus 最初也使用公开评测集(如 GAIA),但发现与实际用户行为和预期偏差很大。现在采用三层评测体系:
| 评测方式 | 说明 | 适用场景 |
|---|---|---|
| 黄金标准:用户评分 | 每次任务结束后让用户评分,计算完成任务的平均用户得分 | 真实用户满意度 |
| 内部自动化测试 | 自建评测集(答案清晰): ① 公开评测集(偏 read-only 任务) ② 自设计的执行/事务性任务(有可重置的测试沙盒) | 回归测试、架构验证 |
| 实习生人工评测 | 网站生成、数据可视化等难以量化的任务,依赖主观人工评测 | 创意/生成类输出 |
💡 启示:单一评测维度不够,需要结合用户反馈、自动化测试和人工评测才能全面评估 Agent 质量。
最后的忠告
Peak 在分享最后特别强调了一点:
More context ≠ more intelligence
更多上下文 ≠ 更多智能
Simplification beats expansion
简化优于扩展
Our biggest gains came from removing, not adding.
最大的收益来自移除,而非添加。
Keep the boundary clear — then get out of the model’s way!
保持边界清晰,然后让开,别挡模型的路!
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
人工智能时代最缺的是什么?就是能动手解决问题还会动脑创新的技术牛人!智泊AI为了让学员毕业后快速成为抢手的AI人才,直接把课程升级到了V6.0版本。
这个课程就像搭积木一样,既有机器学习、深度学习这些基本功教学,又教大家玩转大模型开发、处理图片语音等多种数据的新潮技能,把AI技术从基础到前沿全部都包圆了!
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
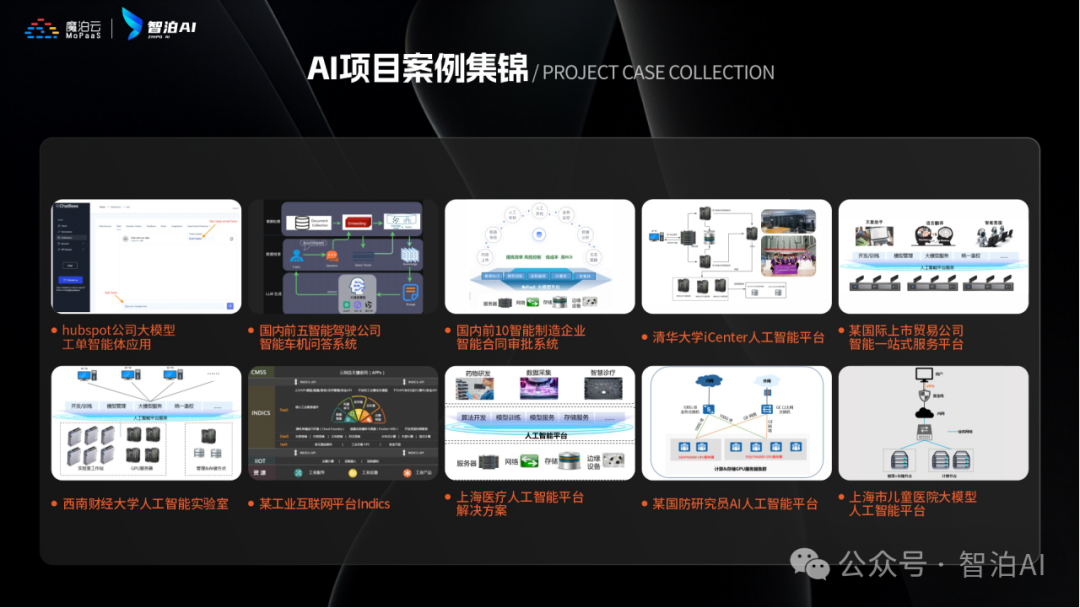
课程还教大家怎么和AI搭档一起工作,就像程序员带着智能助手写代码、优化方案,效率直接翻倍!
这么练出来的学员确实吃香,83%的应届生都进了大厂搞研发,平均工资比同行高出四成多。
智泊AI还特别注重培养"人无我有"的能力,比如需求分析、创新设计这些AI暂时替代不了的核心竞争力,让学员在AI时代站稳脚跟。
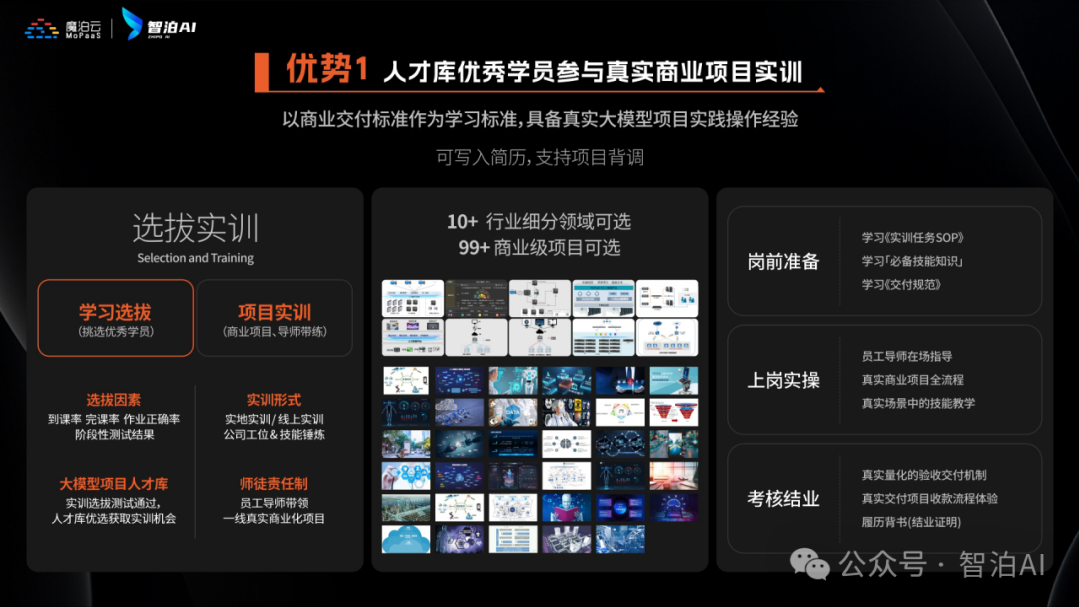
课程优势一:人才库优秀学员参与真实商业项目实训
课程优势二:与大厂深入合作,共建大模型课程

课程优势三:海外高校学历提升

课程优势四:热门岗位全覆盖,匹配企业岗位需求
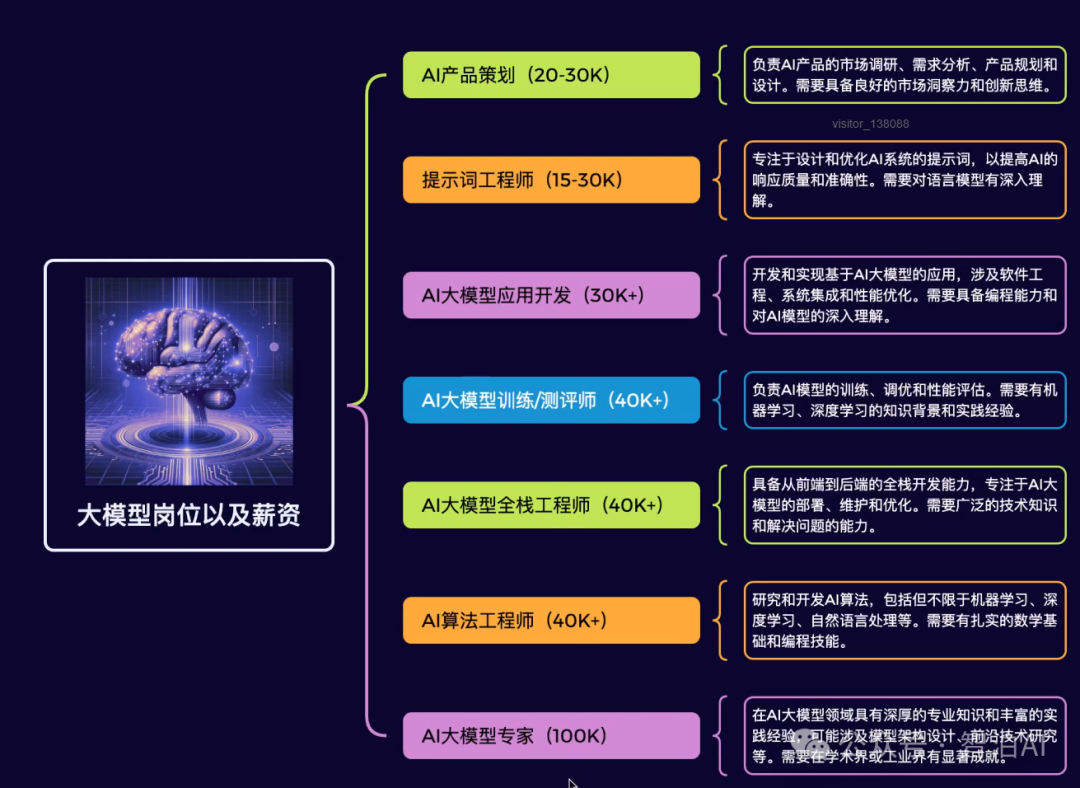
如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
·应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
·零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
·业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
重磅消息
人工智能V6.0升级两大班型:AI大模型全栈班、AI大模型算法班,为学生提供更多选择。

由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【最新最全版】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
来智泊AI,高起点就业
培养企业刚需人才
扫码咨询 抢免费试学
⬇⬇⬇

AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献451条内容
已为社区贡献451条内容

所有评论(0)