收藏学习:Mixture-of-Transformers - 稀疏可扩展的多模态基础模型架构
Mixture-of-Transformers (MoT) 是一种高效的多模态transformer架构,通过解耦非嵌入参数(前馈网络、注意力矩阵和层归一化)实现模态特定处理。实验显示,MoT在文本、图像和语音任务中仅需55.8%-37.2%的FLOPs即可达到密集基线性能,显著降低计算成本。该架构保持全局自注意力以捕捉跨模态关系,在Chameleon和Transfusion等任务中展现出优越性能
Mixture-of-Transformers (MoT)是一种创新的稀疏多模态transformer架构,通过按模态解耦非嵌入参数(前馈网络、注意力矩阵和层归一化),实现高效处理文本、图像和语音数据。实验表明,MoT在多模态任务中,仅使用55.8%和37.2%的FLOPs就达到密集基线性能,显著降低了预训练计算成本,同时保持全局自注意力以捕获跨模态关系,为多模态大模型的训练提供了高效解决方案。
Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models
【背景】大型语言模型(LLMs)的发展已扩展到多模态系统,能够在统一框架内处理文本、图像和语音。
【挑战】与仅处理文本的 LLMs 相比,训练这些模型需要更大的数据集和计算资源。
【方法】为解决扩展挑战,我们提出了 Mixture-of-Transformers(MoT),一种稀疏多模态 transformer 架构,可显著降低预训练计算成本。
【细节】MoT 按模态解耦模型的非嵌入参数——包括前馈网络、注意力矩阵和层归一化——实现对特定模态的处理,同时保持对完整输入序列的全局自注意力。
【效果1】我们在多种设置和模型规模下评估了 MoT。在 Chameleon 7B 设置(自回归文本和图像生成)中,MoT 仅使用 55.8%的 FLOPs 就达到了密集基线的性能。当扩展到包含语音时,MoT 仅使用 37.2%的 FLOPs 就达到了与密集基线相当的语音性能。在 Transfusion 设置中,文本和图像使用不同目标进行训练,7B MoT 模型仅使用三分之一 FLOPs 就达到了密集基线的图像模态性能,而 760M MoT 模型在关键图像生成指标上超过了 1.4B 密集基线模型。
【效果2】系统分析进一步突显了 MoT 的实际优势,在 AWS p4de.24xlarge 实例(配备 NVIDIA A100 GPU)上,MoT 以 47.2%的墙钟时间达到密集基线的图像质量,以 75.6%的墙钟时间达到文本质量。
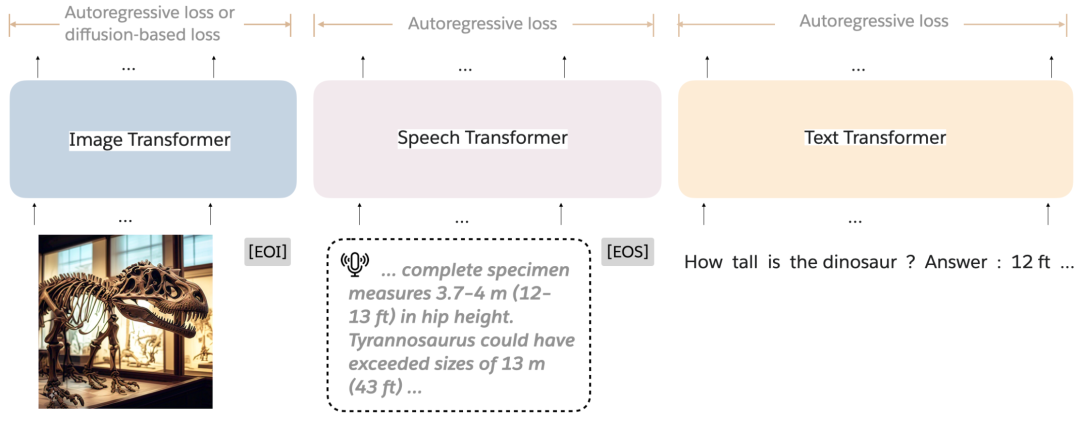
图 1:Mixture-of-transformer(MoT)架构。MoT 是一种生成模型架构,旨在处理任意交错模态(如文本、图像和语音)的序列。每种模态使用一组独立的非嵌入 transformer 参数——包括前馈网络、注意力矩阵和层归一化。在训练过程中,每种模态可以使用特定于模态的损失函数进行监督。

多模态模型训练的观察:
- 多个模态让优化变得复杂:经验表明,在密集的 transformer 模型中,这些模态通常表现出冲突的训练动态(图 15),这使优化复杂化并增加了计算负载。
- 不同模态 ⇒ 特征空间的不同位置:尽管输入被处理为没有模态特定先验的统一 tokens,但不同模态在特征空间中占据不同的区域(图 2(e),附录图 23),这表明模态处理方式存在固有差异。
一种自然的想法是使用 MoE,不同模态对应不同的专家
MoE 的优点:通过路由减少整体计算负载
MoE 的缺点:专家激活不均衡;训练动态复杂化
受到这样的想法的启发,先前的工作在 MoE 层中引入了模态感知稀疏性 ⇒ 表明基于模态的简单规则路由优于 MoE 中常用的学习路由
这种成功,可能归因于更稳定的训练动态,避免了在早期阶段专家和路由器都训练不足时出现的不稳定性。
与先前的方法不同,MoT 在整个 transformer 中应用模态感知稀疏性,而不是特定层或模块。MoT 接收交错的多模态序列(如文本、图像、语音)作为输入,并为每个令牌动态应用不同的、模态特定的参数,包括 FFN、attention矩阵和层归一化。
因此,MoT 设计产生了一个稀疏模型,其计算结构和 FLOP 计数与其密集 transformer 对应模型完全相同。
设计了下面几种实验:
- 自回归的文本目标+图像目标
- 自回归的文本目标+图像目标+语音目标(Chameleon 数据集)
- 自回归的文本目标+基于扩散的图像目标【具体意思可以看下面的图3,因为模型中都是token表示,所以其实只是 loss 的不同】
2 方法:Mixture-of-Transformers 架构
2.1 背景:多模态生成的基础模型
之前的工作:
- Chameleon:将图像标记为 1,024 个离散 token,允许文本和图像的统一训练
- Transfusion:使用连续图像 token 和基于扩散的训练目标来改进连续模态(如图像)的生成
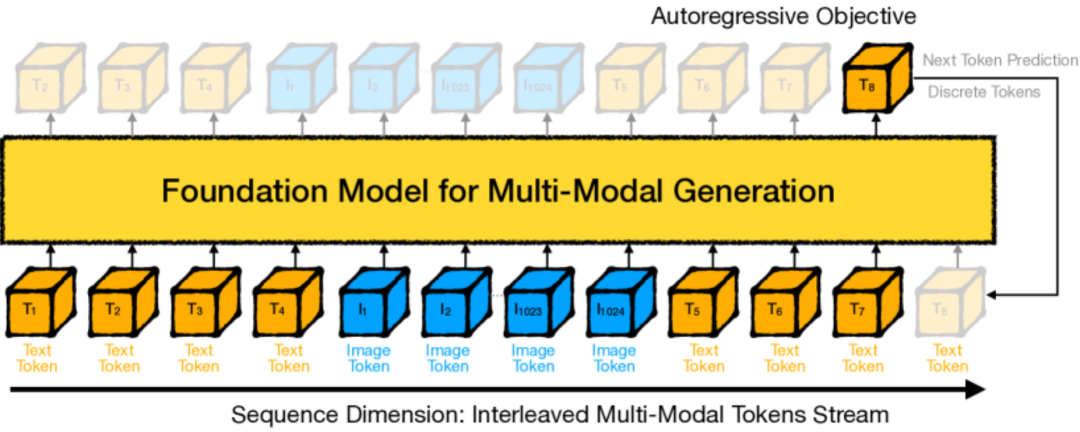
图(2) a 典型的多模态基础模型处理交错文本(T)和图像(I)令牌(例如,Chameleon)。图像 token 源自预训练的 VQGAN 模型,将图像转换为 1,024 个离散令牌。
本文做了一个小实验,对 transformer 不同层的特征空间进行了聚类,结果如下。主成分分析(PCA)显示特征空间中不同模态有明显的区域划分,尽管输入作为离散令牌被统一处理,没有模态特定的先验。这种自然聚类表明模态处理存在固有差异,为我们的后续方法提供了信息。
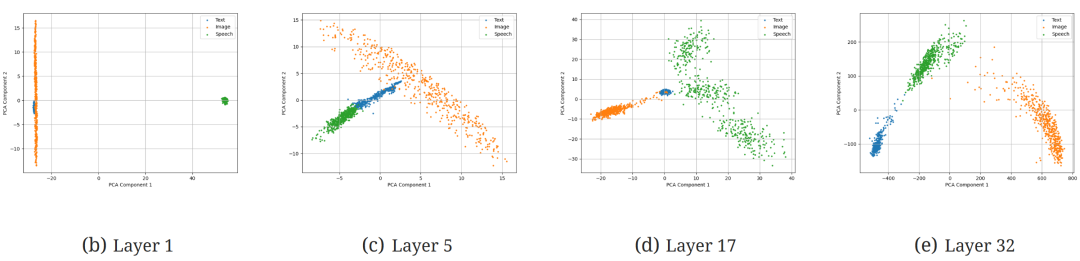
图(2) b Chameleon+Speech 7B Dense 模型在层 1、5、17 和 32 的潜在特征空间的 PCA 结果。 † 尽管模型的架构将所有输入作为均匀离散 token 处理,没有模态特定的先验,但在特征空间中观察到按模态(文本、语音、图像)的明显聚类。这种自然聚类突显了模态之间的固有差异,表明模型可能以不同方式处理它们。
图(2) b Chameleon+Speech 7B Dense 模型在层 1、5、17 和 32 的潜在特征空间的 PCA 结果。 † 尽管模型的架构将所有输入作为均匀离散 token 处理,没有模态特定的先验,但在特征空间中观察到按模态(文本、语音、图像)的明显聚类。这种自然聚类突显了模态之间的固有差异,表明模型可能以不同方式处理它们。
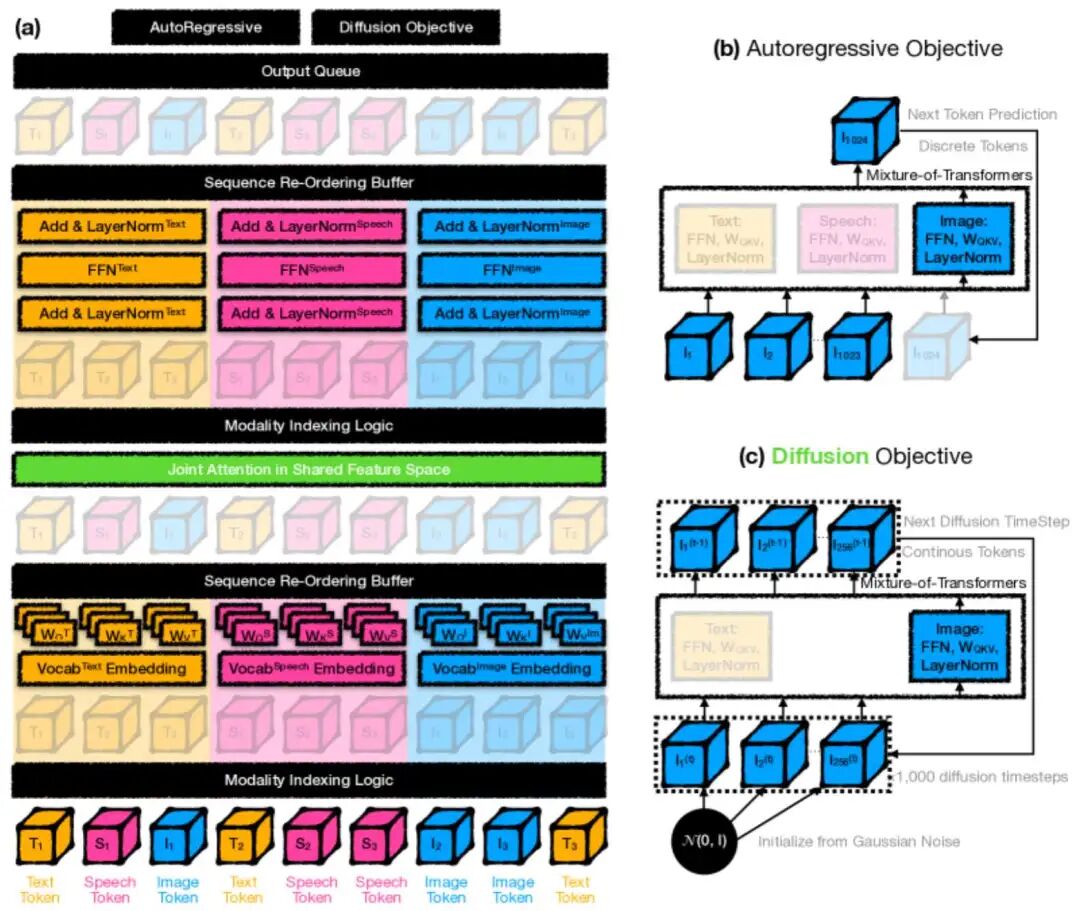
图 3:用于多模态生成 AI 的 Mixture-of-Transformers 架构。 a:稀疏激活的 Mixture-of-Transformers(MoT)架构示意图。对于每个输入令牌,MoT 激活模态特定权重(包括前馈网络、注意力投影矩阵和层归一化),然后在整个序列上应用自注意力。T、S 和 I 分别表示文本、语音和图像令牌。【就是说,除了注意力层外,别的都是各自模态算各自的】 b-c:模态表示和训练目标的灵活性。图像可以表示为(b)离散令牌序列,使用自回归目标训练(Chameleon 设置),或©连续令牌序列,使用扩散目标训练(Transfusion 设置)。这允许集成多样化的学习任务,如文本的自回归目标和图像的基于扩散的目标。
图 3:用于多模态生成 AI 的 Mixture-of-Transformers 架构。 a:稀疏激活的 Mixture-of-Transformers(MoT)架构示意图。对于每个输入令牌,MoT 激活模态特定权重(包括前馈网络、注意力投影矩阵和层归一化),然后在整个序列上应用自注意力。T、S 和 I 分别表示文本、语音和图像令牌。【就是说,除了注意力层外,别的都是各自模态算各自的】 b-c:模态表示和训练目标的灵活性。图像可以表示为(b)离散令牌序列,使用自回归目标训练(Chameleon 设置),或©连续令牌序列,使用扩散目标训练(Transfusion 设置)。这允许集成多样化的学习任务,如文本的自回归目标和图像的基于扩散的目标。
2.2 MoT 架构:模态特定参数解耦
这是一种新颖的架构,旨在加速多模态预训练同时降低计算成本。
MoT 通过为所有非嵌入模型参数(包括前馈网络、注意力矩阵和层归一化)引入模态特定权重,扩展了标准 Transformer 架构。
这种方法使模型能够更高效地处理不同模态,同时保留学习跨模态交互的能力。
考虑输入序列:
x=(x1,…,xn) 每个 xi 都有模态 mi ∈{text,image,speech}
经典 transformer :
θθ
MoT 中,我们按模态解耦参数,同时保持全局自注意力:
θθ
与利用交叉注意力来融合不同模态信息的研究(Alayrac et al., 2022; Aiello et al., 2023)相比,我们采用的全局自注意力公式在跨模态 token 间归一化注意力权重的同时,还减少了架构中的层数。
全局自注意力机制跨所有模态运行,尽管存在模态特定的参数解耦,仍能捕获跨模态关系:
【明明都是特定参数的解耦,为什么说能捕获跨模态关系呢?答:可以看看下面的算法,这里只是一个token的计算,但是实际上所有 Qi Ki Vi 会各自拼在一起,最后用公式 (7) 进行计算】
θ
在这里,上标包含mi的变量都是特定模态的投影矩阵
这种方法使 MoT 能够根据每种模态的特定特征调整其处理方式,同时保持多模态学习的统一架构。
MoT 中的计算过程首先按模态对输入令牌进行分组(算法 1,第 3-5 行)。
然后应用模态特定的投影进行注意力计算(第 6 行),接着是跨所有模态的全局自注意力(第 8-9 行)。
随后,应用模态特定的输出投影(第 11 行)、层归一化和前馈网络(第 12-13 行)。
最后通过组合输出,包含残差连接和层归一化来结束该过程(第 14-16 行)。

image.png
3 实验
- 对于文本,我们使用 Llama 2 分词器和语料库,该语料库包含来自不同领域的 2 万亿个 token。图像使用变分自编码器 (VAE) 编码为潜在块,其中每个块对应一个连续向量。我们使用 3.8 亿张授权的 Shutterstock 图像及其标题。每张图像都经过中心裁剪并调整为 256×256 像素大小。我们的 VAE 模型对图像进行 8×8 空间下采样。
- 对于多模态示例,我们在将图像序列整合到文本序列之前,用特殊 token——图像开始(BOI)和图像结束(EOI)——包围每个图像序列。这种方法产生了一个单一序列,其中可能包含离散元素(文本 token)和连续元素(图像块)。我们随机排列图像和标题,有 80% 的时间将标题放在前面。在大多数实验中,我们从两种模态中以 1:1 的比例采样 0.5 万亿个 token(或块)。
训练了五种不同规模的模型——参数量分别为 0.16B、0.76B、1.4B 和 7B。我们在所有配置中保持 U-Net 块编码参数固定为 0.27B 额外参数。我们随机初始化所有模型参数,并使用 AdamW(β1=0.9, β2=0.95, ϵ=1e-8)进行优化,学习率为 3e-4,预热 4000 步后,使用余弦调度器衰减至 1.5e-5。我们在 4096 个 token 的序列上以每批 2M token 的批量进行训练,共训练 250k 步,总计达到 0.5T token。我们使用 0.1 的权重衰减进行正则化,并通过范数(1.0)裁剪梯度。在推理过程中,我们进行 250 步扩散。
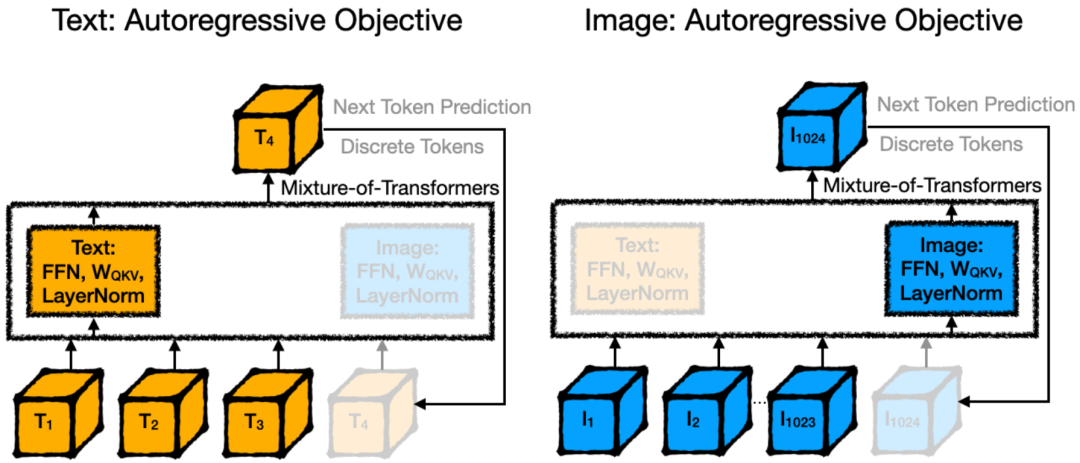
图 4:具有自回归目标的多模态实验设置(Chameleon)。文本和图像都使用自回归目标进行训练。图像使用预训练的 VQ-VAE 模型被标记为 1,024 个离散令牌。此设置展示了使用单一目标函数在模态间的统一处理。
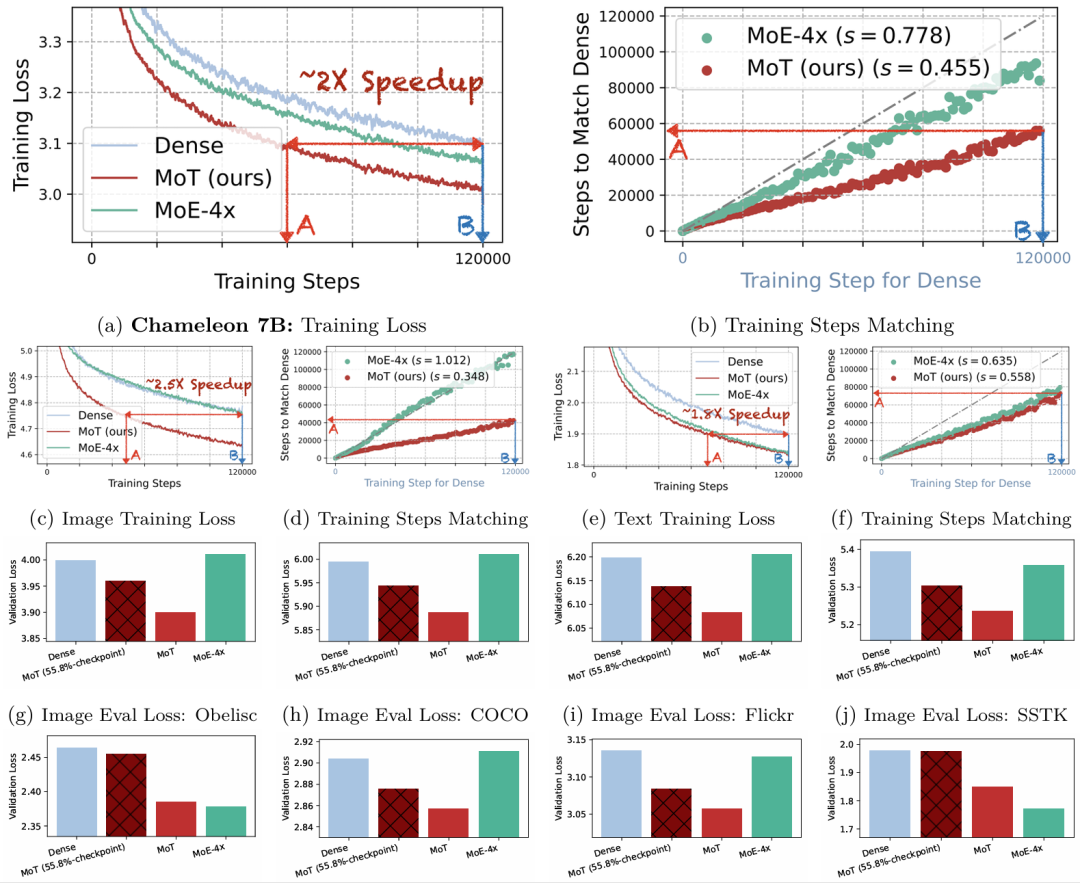
图 5:MoT 在 7B 参数 Chameleon 多模态模型上的预训练加速。
图 5:MoT 在 7B 参数 Chameleon 多模态模型上的预训练加速。 a,全局训练损失曲线。MoT 比密集模型和 MoE-4x 模型更快地降低损失,在 60,000 步内达到密集模型在 120,000 步时的最终损失。 b,a 中训练损失的步数匹配图。MoT 仅需密集模型训练步数的 45.5%即可获得 comparable 性能。 c,d,图像模态训练损失及相应的步数匹配图。 e,f,文本模态训练损失及相应的步数匹配图。 MoT 对图像模态特别有效,仅需密集模型训练步数的 34.8%即可匹配最终损失。MoT 和 MoE-4x 在文本模态上都优于密集模型。 g-j,图像模态验证损失。 k-n,文本模态验证损失。 所有模型和 MoT 在 55.8%训练检查点处的最终验证损失比较。MoT 在 55.8%训练步数时实现了与密集模型最终损失相当或更低的验证损失,表明所需训练 FLOPs 减少了 44.2%。稀疏模型的模型大小表示激活的参数。所有运行都是 FLOPs 控制的,并且从头开始预训练。
后面有很多实验,这里先不仔细看了。但是需要注意的是,这个模型是支持生成图片的
不过,似乎这个论文更看重loss,而没有很多目前常测的 benchmark
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
人工智能时代最缺的是什么?就是能动手解决问题还会动脑创新的技术牛人!智泊AI为了让学员毕业后快速成为抢手的AI人才,直接把课程升级到了V6.0版本。
这个课程就像搭积木一样,既有机器学习、深度学习这些基本功教学,又教大家玩转大模型开发、处理图片语音等多种数据的新潮技能,把AI技术从基础到前沿全部都包圆了!
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
课程还教大家怎么和AI搭档一起工作,就像程序员带着智能助手写代码、优化方案,效率直接翻倍!
这么练出来的学员确实吃香,83%的应届生都进了大厂搞研发,平均工资比同行高出四成多。
智泊AI还特别注重培养"人无我有"的能力,比如需求分析、创新设计这些AI暂时替代不了的核心竞争力,让学员在AI时代站稳脚跟。
课程优势一:人才库优秀学员参与真实商业项目实训
课程优势二:与大厂深入合作,共建大模型课程

课程优势三:海外高校学历提升

课程优势四:热门岗位全覆盖,匹配企业岗位需求
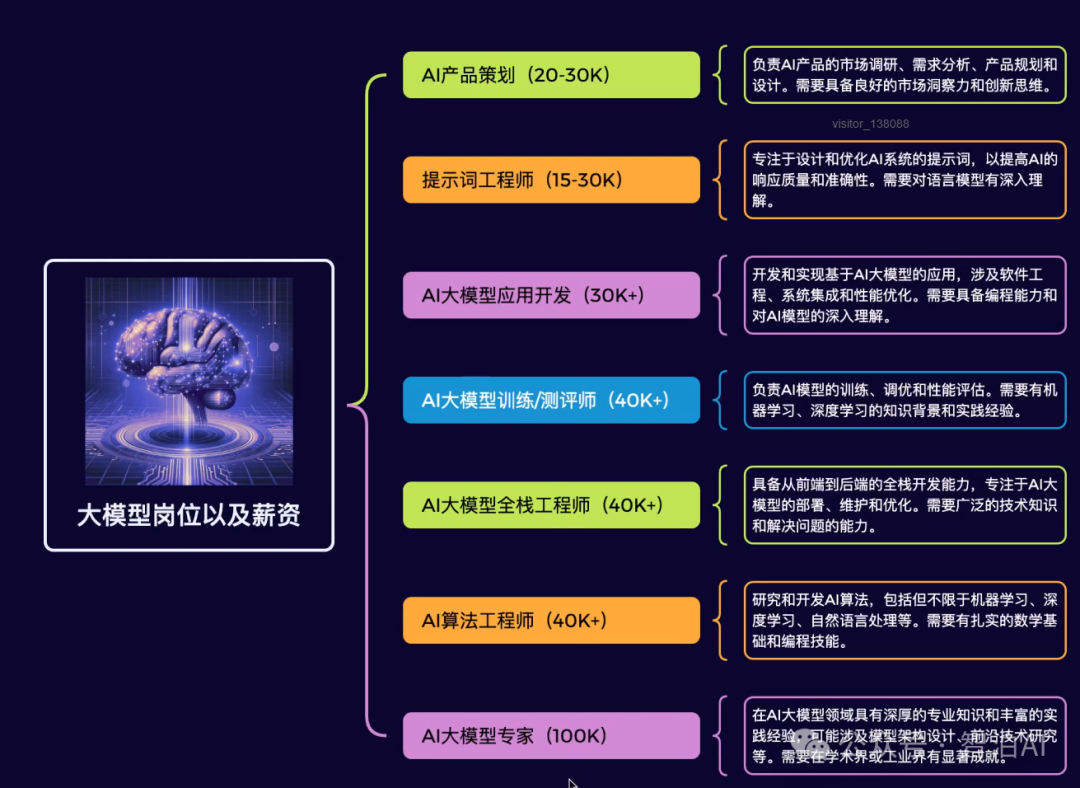
如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
·应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
·零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
·业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
重磅消息
人工智能V6.0升级两大班型:AI大模型全栈班、AI大模型算法班,为学生提供更多选择。

由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【最新最全版】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
来智泊AI,高起点就业
培养企业刚需人才
扫码咨询 抢免费试学
⬇⬇⬇

AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献224条内容
已为社区贡献224条内容

所有评论(0)