一文讲清:RAG中语义理解和语义检索的区别到底是什么?有何应用?
本文探讨了语义理解和语义检索在RAG架构中的区别与应用。语义理解是大模型固有的语言解析能力,在智能体架构中处于核心地位;而语义检索则是基于向量相似度计算的检索方法,主要用于匹配用户问题的相关文档。文章指出,向量数据库的本质是在传统数据库基础上增加向量计算功能,并非完全颠覆性技术。在RAG流程中,语义理解负责解析用户意图并生成查询参数,语义检索则负责召回相关信息。最后强调了AI大模型领域的人才需求和
语义理解是模型的根基能力,语义检索则是一种特定的检索方法。
尽管语义理解和语义检索常被提及,但许多人仍未能清晰辨析二者之间的异同、内在关联及其实际应用场域。
在大语言模型的自然语言处理框架中,系统运作通常划分为自然语言理解(NLU)与自然语言生成(NLG)两个阶段;而在RAG架构中,同样对应着两类核心机制——语义理解与语义检索。
那么,在RAG体系内,语义理解与语义检索究竟有何不同?各自适用于哪些场景?或者说,RAG流程中的哪个环节归属于语义理解,哪个环节又属于语义检索?
语义理解和语义检索
在 RAG 的流程中,用户发起查询后,系统依据该问题执行标量(条件查询)或向量检索(语义检索),旨在获取与问题语义匹配的文档片段,继而用于支撑模型的增强式生成。
简单流程如下图所示:

最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
在传统RAG架构中,语义检索占据核心地位,这是因为自然语言问答本质上依赖对语义的匹配,而非基于关键词的条件筛选;正因如此,RAG系统引入向量数据库——其根本动因在于语义检索的技术底层是向量空间中的相似度计算。
部分人对向量数据库存在误解,或将其过度神化;实际上,它与传统关系型数据库并无本质差异,唯一的扩展在于新增了向量列,用以支持向量计算能力;因此,任何涉及向量运算的场景,均可适用向量数据库,涵盖智能问答、智能搜索等典型应用。
向量数据库的本质,是在关系型数据库结构上追加了向量列,而该列的唯一功能是执行相似度检索;真正驱动模型生成的,仍是原始文档内容——这正如我们通过ID或Name字段定位记录,但实际使用的却是表中其他字段的数据。
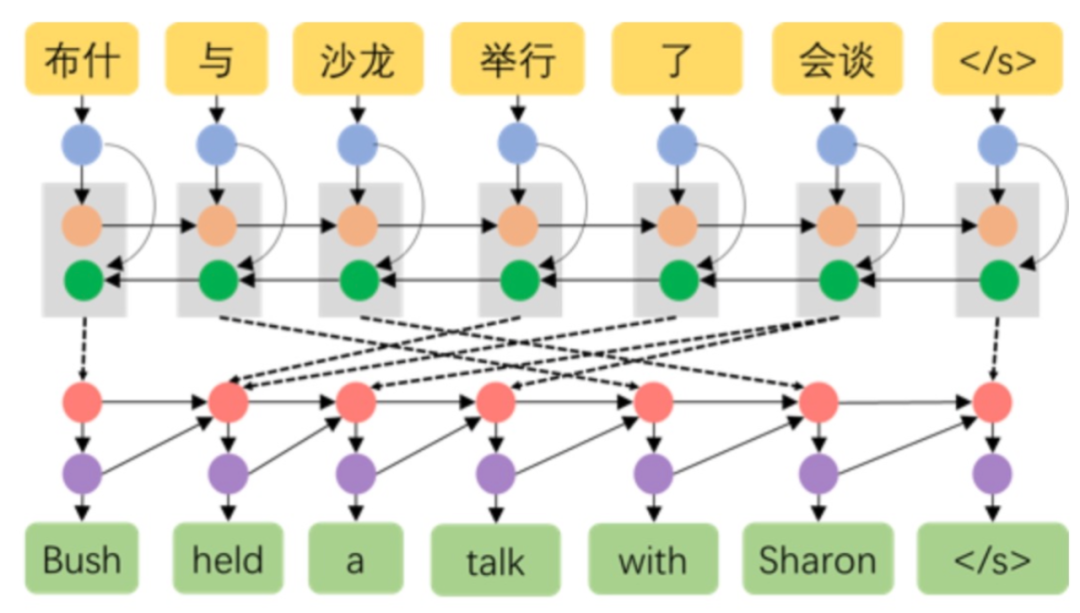
OK,明白了语义检索的底层逻辑,接下来聊聊语义理解;此前提到,大模型在生成过程中需依赖语义理解与语义生成两个环节;而在基于智能体的RAG系统里,语义理解同样扮演着关键角色,甚至可以说,它才是智能体真正的核心所在。
在增强型检索的智能体架构中,我们部署了多个查询工具,每个工具都配置了专属的查询参数;这些参数的核心功能,正是用于执行语义查询或条件筛选——但这些参数,究竟是如何被构建出来的呢?
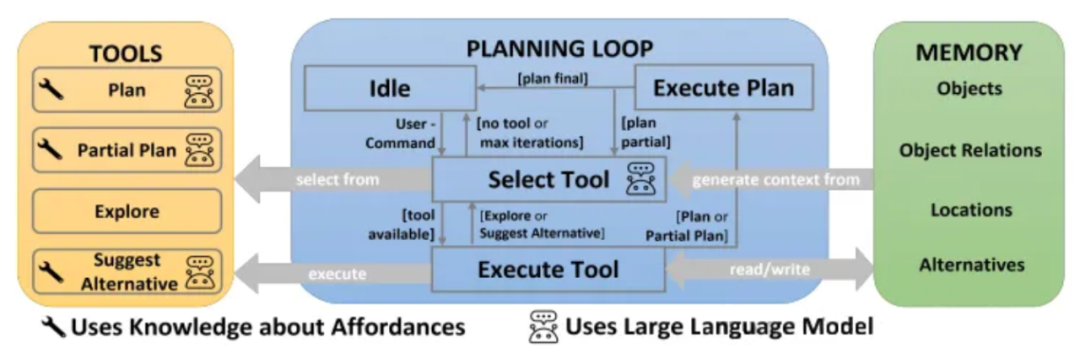
大模型通过解析用户问题,推导出工具调用所需的参数值,进而执行外部操作——由此可见,语义理解在智能体架构中居于核心地位;一旦该能力失效,工具调用的输出必然偏离预期。
在RAG框架下,语义理解与语义检索分属不同功能模块:前者是模型固有的语言解析能力,后者则是实现信息召回的一种方式,虽突破了传统基于关键词的精确匹配机制,但其底层逻辑仍与之同源。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献160条内容
已为社区贡献160条内容

所有评论(0)