(论文速读)CCM:使用文本到图像一致性模型的实时可控视觉内容创建
CCM框架,首次实现了基于一致性模型(CMs)的实时可控图像生成。研究探索了三种控制策略:直接迁移扩散模型ControlNet、一致性训练定制ControlNet和统一适配器方法。实验表明,定制训练的CM ControlNet在4步生成时达到0.9秒/图(加速26倍),FID仅7.61,接近扩散模型质量。关键发现包括:1)CMs可作为独立生成模型;2)模型间存在语义层一致但细节层差异;3)适配器能
论文题目:CCM: Real-Time Controllable Visual Content Creation Using Text-to-Image Consistency Models(使用文本到图像一致性模型的实时可控视觉内容创建)
会议:ICML2024
摘要:一致性模型(CMs)已经显示出用很少的步骤创建高质量图像的前景。然而,在预训练的CMs中添加新的条件控制的方法尚未被探索。在本文中,我们探讨了利用一致性模型的生成能力和效率来促进通过ControlNet创建可控视觉内容的关键主题。首先,我们观察到为扩散模型(DMs)训练的ControlNet可以直接应用于CMs进行高级语义控制,但牺牲了图像的低级细节和真实感。为了解决这个问题,我们使用一致性训练为ControlNet开发了一个cms定制的训练策略(Song et al., 2023)。验证了通过一致性训练技术可以成功地建立ControlNet。此外,利用一致性训练可以训练出统一的适配器,增强了DM控制网的自适应能力。我们定量和定性地评估了各种条件控制下的所有策略,包括素描、头部、轮廓、深度、人体姿势、低分辨率图像和蒙面图像,并使用预训练的文本到图像的潜在一致性模型。
CCM:一致性模型实现实时可控图像生成的突破
引言
在AI图像生成领域,扩散模型(Diffusion Models)凭借其卓越的生成质量已经成为主流技术。然而,扩散模型有一个显著的缺陷:生成速度慢。以Stable Diffusion为例,生成一张1024×1024的高质量图像通常需要50步迭代,耗时约23.6秒。这种缓慢的生成速度严重限制了实时应用的可能性。
一致性模型(Consistency Models, CMs)作为新一代生成模型,展现出了用极少步骤(甚至1步)生成高质量图像的潜力。但一个关键问题始终悬而未决:如何为一致性模型添加条件控制能力,就像ControlNet为扩散模型所做的那样?
来自中国科学技术大学、阿里巴巴集团等机构的研究团队在ICML 2024上发表的论文《CCM: Real-Time Controllable Visual Content Creation Using Text-to-Image Consistency Models》,首次系统性地解决了这个问题。本文将深入解读这篇论文的核心贡献和技术细节。
问题背景与挑战
现有技术的局限
-
扩散模型的速度瓶颈
- 需要多次迭代(通常50-100步)才能生成高质量图像
- 使用ControlNet进行可控生成时,需要双倍的函数评估(因为classifier-free guidance)
- 在1024×1024分辨率下,单张图像生成耗时约23.6秒
-
一致性模型的空白
- 虽然一致性模型可以实现1-4步生成,但缺乏条件控制机制
- 如何为一致性模型训练ControlNet尚未被探索
- 扩散模型的ControlNet能否直接迁移到一致性模型存疑
核心研究问题
论文聚焦于三个关键问题:
- 能否直接将扩散模型的ControlNet应用于一致性模型?
- 能否使用consistency training技术从头训练专属的ControlNet?
- 如何更好地适配扩散模型的ControlNet到一致性模型?
技术方法:三种训练策略
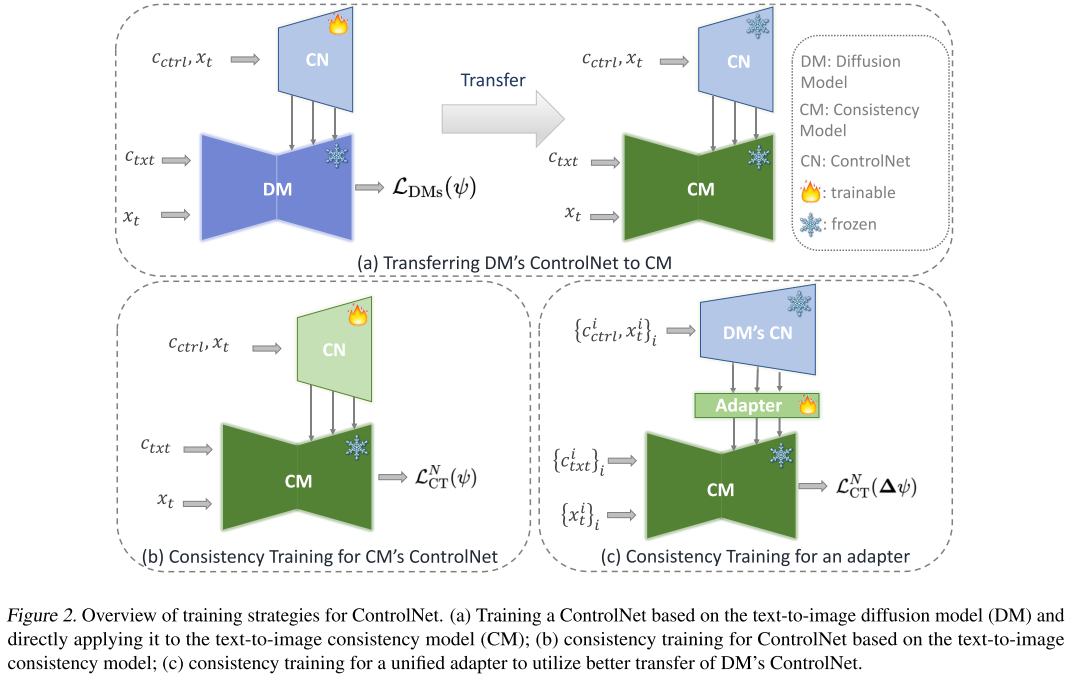
研究团队提出并比较了三种为一致性模型添加条件控制的策略。
策略一:直接迁移(DM's ControlNet + CM)
核心思想:先为扩散模型训练ControlNet,然后直接应用到一致性模型。
理论基础:
- 一致性模型直接将概率流ODE轨迹上的任意点投影到数据
- 扩散模型通过迭代ODE求解器沿着概率流ODE生成数据
- 两者共享相同的概率流ODE,因此ControlNet的知识可能(部分)可迁移
训练目标:
![]()
其中ψ是ControlNet的参数,目标是最小化噪声预测误差。
优势与劣势:
- ✅ 可以直接复用现成的扩散模型ControlNet
- ✅ 无需重新训练,部署简单
- ❌ 性能次优,特别是低层细节和真实感方面
- ❌ 添加新控制时仍需通过扩散模型作为中介
策略二:Consistency Training(CM's ControlNet + CM)
核心思想:使用consistency training技术直接为一致性模型从零训练ControlNet。
理论创新: 论文证明了一致性模型可以作为独立的生成模型家族,通过consistency training技术训练ControlNet,而无需依赖扩散模型。
训练目标:
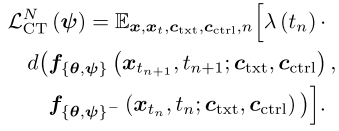
其中:
- f_{θ,ψ}是集成了ControlNet的一致性模型
- f_{θ,ψ}^-是teacher模型(通过stopgrad获得)
- d是距离函数(实验中使用L1距离表现最佳)
- 只有ControlNet的参数ψ是可训练的
训练细节:
- 超参数N=50(将[0,T]区间划分为50段)
- 批大小:32
- 训练步数:100,000步
- 距离函数:L1距离(优于MSE和Charbonnier函数)
- 教师模型:θ^- = stopgrad(θ)(不使用EMA)
优势:
- ✅ 端到端训练,性能最优
- ✅ 可以同时实现高层语义控制和低层细节控制
- ✅ 生成图像真实感更强
策略三:统一适配器(DM's ControlNet + Adapter + CM)
核心思想:训练一个统一的适配器(adapter),增强扩散模型ControlNet到一致性模型的适配能力。
动机:
- 直接迁移虽然可行但性能次优
- 完全重新训练成本高
- 适配器可以在保留DM's ControlNet知识的同时,弥合CM和DM之间的gap
训练目标:
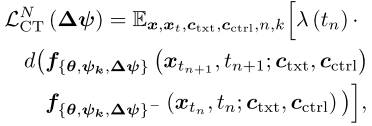
其中:
- k ~ U([1, K]),K是涉及的条件数量
- Δψ + ψ_k构成新的ControlNet
- 适配器在多个条件上联合训练(论文中使用5个条件:sketch, canny, mask, pose, SR)
适配器架构:
- 残差块结构:Conv → Conv → Skip Connection
- 残差块数量与对应ControlNet的输出长度一致
- 每个残差块包含两个卷积模块和一个跳跃连接
优势:
- ✅ 可以适用于训练集内的条件(in-context)
- ✅ 对训练集外的条件也有效果(training-free,如depth和hed)
- ✅ 训练成本较低,一次训练多条件共享
实验设置与评估
实验配置
文本到图像一致性模型训练:
- 基础模型:从Stable Diffusion蒸馏的Latent Consistency Model (LCM)
- 分辨率:1024×1024
- N=200,CFG=5.0
- 批大小:128,学习率:8e-6
- 训练成本:约160 A100 GPU天
- 特殊处理:强制zero-terminal SNR对齐训练和推理
条件控制类型(7种):
- Sketch:边缘检测模型 + 简化算法提取草图
- Canny:Canny边缘检测器
- Hed:整体嵌套边缘检测
- Depthmap:Midas深度估计模型
- Human Pose:人体姿态检测
- Mask:随机遮罩(4通道:3通道RGB + 1通道二值掩码)
- Super-resolution:16×超分辨率(下采样到64×64作为条件)
训练数据集:
- ImageNet21K
- WebVision
- 过滤版LAION(去除重复、低分辨率和有害内容)
评估指标
- 图像质量:FID (Fréchet Inception Distance),越低越好
- 条件一致性:Fidelity = ‖h(y) - c_ctrl‖₁
- h(·)是提取条件的模型
- y是生成图像
- c_ctrl是输入条件
- 越低表示生成图像与条件越一致
- 效率指标:
- NFEs:函数评估次数
- Time:实际运行时间(单个A100 GPU)
实验结果
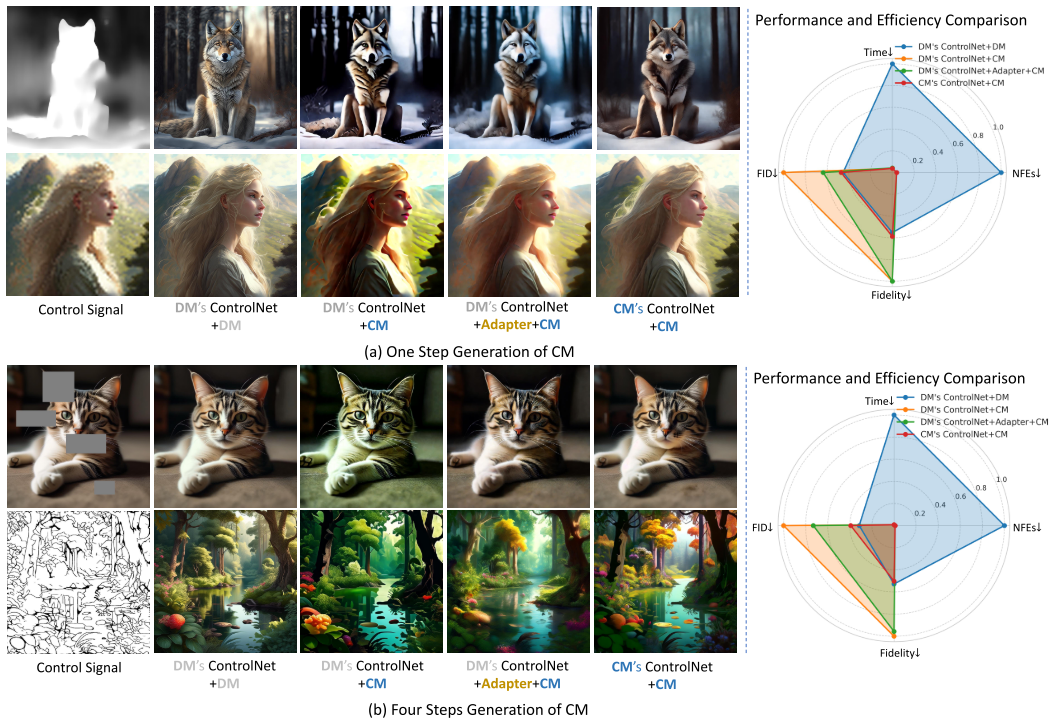
整体性能比较(Table 2数据)
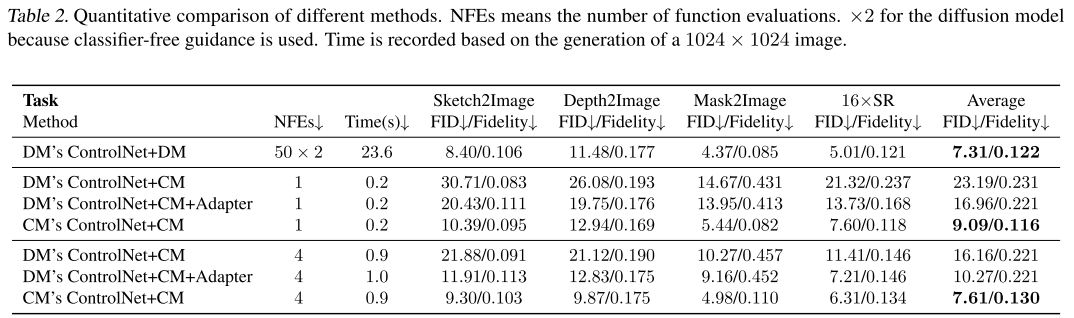
下表展示了四种方法在四个典型任务上的定量对比(4步生成):
| 方法 | NFEs↓ | Time(s)↓ | Sketch2Image<br/>FID↓/Fidelity↓ | Depth2Image<br/>FID↓/Fidelity↓ | Mask2Image<br/>FID↓/Fidelity↓ | 16×SR<br/>FID↓/Fidelity↓ | 平均<br/>FID↓/Fidelity↓ |
|---|---|---|---|---|---|---|---|
| DM's ControlNet+DM | 50×2 | 23.6 | 8.40/0.106 | 11.48/0.177 | 4.37/0.085 | 5.01/0.121 | 7.31/0.122 |
| DM's ControlNet+CM | 4 | 0.9 | 21.88/0.091 | 21.12/0.190 | 10.27/0.457 | 11.41/0.146 | 16.16/0.221 |
| DM's ControlNet+CM+Adapter | 4 | 1.0 | 11.91/0.113 | 12.83/0.175 | 9.16/0.452 | 7.21/0.146 | 10.27/0.221 |
| CM's ControlNet+CM | 4 | 0.9 | 9.30/0.103 | 9.87/0.175 | 4.98/0.110 | 6.31/0.134 | 7.61/0.130 |
关键发现:
-
效率提升显著:
- CM仅需4步,而DM需要50×2=100步
- 时间从23.6秒降至0.9秒,加速26倍
- NFEs减少25倍
-
性能保持出色:
- CM's ControlNet的平均FID为7.61,仅略高于DM的7.31
- 在某些任务上甚至超越DM(如Depth2Image: 9.87 vs 11.48)
-
适配器有效性:
- 加入Adapter后,FID从16.16降至10.27
- 即使对未训练的条件(如Depth)也有改善
单步生成性能(极致速度)
| 方法 | NFEs↓ | Time(s)↓ | Sketch2Image<br/>FID↓/Fidelity↓ | Depth2Image<br/>FID↓/Fidelity↓ | Mask2Image<br/>FID↓/Fidelity↓ | 16×SR<br/>FID↓/Fidelity↓ | 平均<br/>FID↓/Fidelity↓ |
|---|---|---|---|---|---|---|---|
| DM's ControlNet+CM | 1 | 0.2 | 30.71/0.083 | 26.08/0.193 | 14.67/0.431 | 21.32/0.237 | 23.19/0.231 |
| DM's ControlNet+CM+Adapter | 1 | 0.2 | 20.43/0.111 | 19.75/0.176 | 13.95/0.413 | 13.73/0.168 | 16.96/0.221 |
| CM's ControlNet+CM | 1 | 0.2 | 10.39/0.095 | 12.94/0.169 | 5.44/0.082 | 7.60/0.118 | 9.09/0.116 |
重要观察:
- 即使在1步生成下,CM's ControlNet仍能保持较好的质量(FID=9.09)
- 生成时间仅0.2秒,相比DM的23.6秒,加速118倍
- 这为实时应用开辟了可能
深度技术分析
分析1:为什么DM's ControlNet迁移效果次优?
论文通过相关性分析揭示了DM和CM的ControlNet之间的差异:
实验设计:
- 计算DM's ControlNet和CM's ControlNet在不同网络深度生成的控制信号之间的余弦相似度
- 网络深度从0.0(浅层,对应U-Net瓶颈层)到1.0(深层,对应输出层)
结果(Figure 5a):
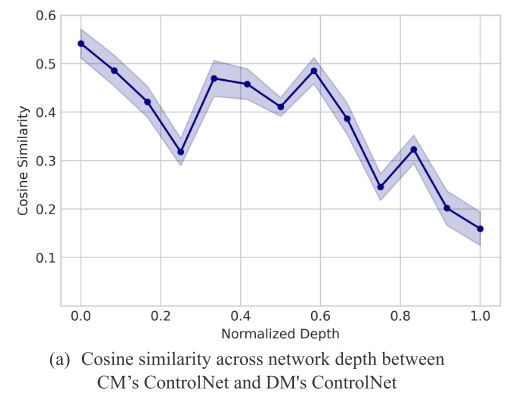
- 浅层(Depth=0.0)相似度高:约0.55
- 浅层对应高层语义控制
- 两个ControlNet在高层语义上基本一致
- 这解释了为什么直接迁移可以工作
- 深层(Depth=1.0)相似度低:约0.16
- 深层对应低层细节控制
- 两个ControlNet在低层细节上差异显著
- 这解释了为什么直接迁移会损失细节和真实感
傅里叶分析(Figure 5b):
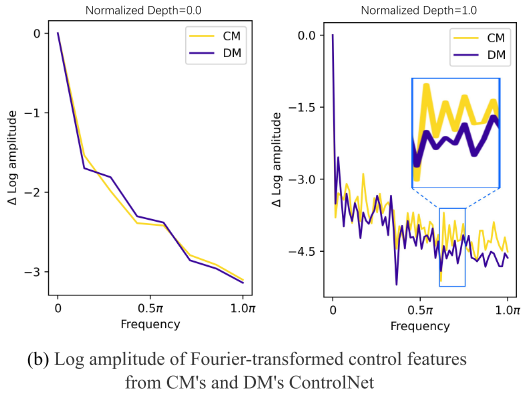
- 在浅层,两个信号的频谱幅度接近
- 在深层,频谱波动模式相似但尺度不同
- 进一步证实了高层一致、低层差异的结论
实际影响:
- DM's ControlNet可以正确理解和传递语义信息(如"这是一只狗")
- 但在细节刻画上失真(如毛发纹理、光影效果不自然)
分析2:距离函数的选择(Table 4)
论文测试了四种距离函数:
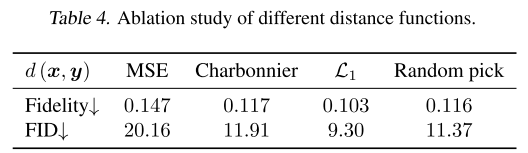
| 距离函数 | FID↓ | Fidelity↓ |
|---|---|---|
| MSE (均方误差) | 20.16 | 0.147 |
| Charbonnier | 11.91 | 0.117 |
| L1 (绝对值) | 9.30 | 0.103 |
| Random pick (随机选择) | 11.37 | 0.116 |
结论:L1距离显著优于其他选项,这可能因为L1对异常值更鲁棒。
分析3:超参数N的影响(Table 5)
N控制时间区间的划分粒度:
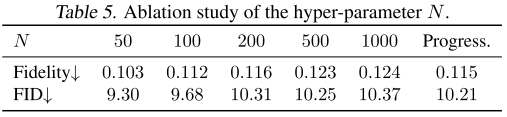
结论:N=50是最佳选择,过大的N反而降低性能。
分析4:对文本提示的鲁棒性(Table 3)
测试了两种提示方式:
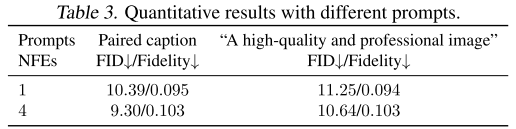
- 配对标题:与图像相匹配的详细描述
- 通用提示:"A high-quality and professional image"
结论:通用提示仅略微影响FID,模型对文本提示具有一定鲁棒性。
分析5:反向迁移实验
论文还测试了将CM's ControlNet迁移到DM的效果(Figure 6):

结果:
- 可以迁移语义级控制
- 但在调节图像细节上仍然次优
- 进一步证明了CM和DM之间的本质差异
分析6:定制化生成(Figure 7)
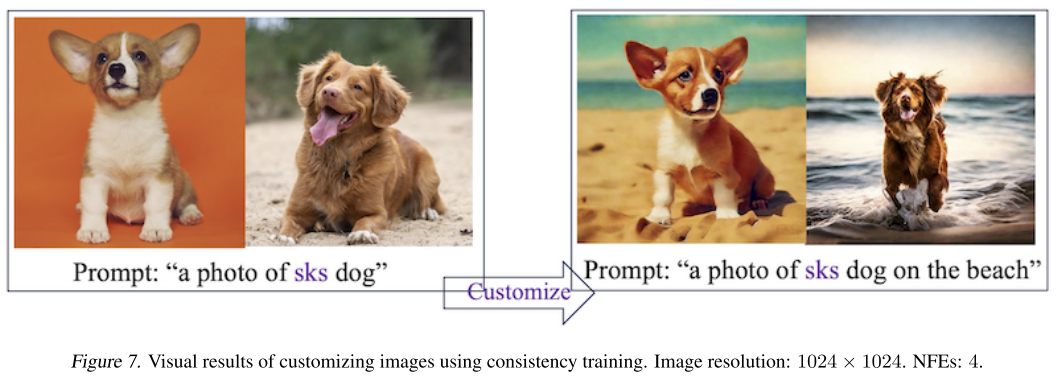
论文验证了consistency training loss可以兼容图像定制化过程:
- 使用DreamBooth技术
- 基于CM进行个性化生成
- 成功生成了定制化的图像
视觉结果展示
多方法对比(Figure 3)

论文在多种条件下对比了四种方法的视觉效果:
Sketch条件:
- DM's ControlNet+DM:质量最高,细节丰富,但慢
- DM's ControlNet+CM:能理解草图语义,但图像不够真实
- DM's ControlNet+CM+Adapter:比直接迁移好,但仍有改进空间
- CM's ControlNet+CM:质量接近DM,速度快26倍
Mask Inpainting条件:
- DM's ControlNet+CM:在遮罩区域外产生明显变化(控制失败)
- CM's ControlNet+CM:正确只修改遮罩区域内容
Depth和Hed条件:
- 适配器对未训练条件也有改善效果
- CM's ControlNet始终表现最佳
不同文本提示效果(Figure 4)

使用同一草图条件,测试不同文本提示:
- "A high-quality and professional image"(通用提示)
- "A yellow dog lies on the grassland and enjoys the sun"(详细描述)
- "watercolor style, a dog lies on the beach"(艺术风格)
结论:模型能够灵活响应不同的文本提示,保持条件控制的同时适应文本描述。
技术洞察与启示
1. 一致性模型的独立性
论文最重要的发现是:一致性模型可以作为完全独立的生成模型家族,而不是扩散模型的"附庸"。通过consistency training,可以直接为CM训练各种控制机制,无需依赖DM。
2. 模型间的gap是真实存在的
虽然CM和DM都基于概率流ODE,但两者在:
- 训练目标(直接预测vs迭代去噪)
- 网络架构(单步vs多步)
- 信息流动(直接投影vs渐进细化)
等方面存在本质差异。这种差异导致ControlNet不能完美迁移。
3. 适配器的潜力
统一适配器的成功表明:
- 可以用轻量级模块弥合不同模型间的gap
- 多条件联合训练的适配器具有泛化能力
- 这为模型间知识迁移提供了新思路
4. 速度与质量的新平衡
CCM证明了可以在保持接近DM质量的同时,将生成速度提升26-118倍。这为实时应用(如视频生成、交互式编辑)开辟了道路。
实际应用价值
1. 实时图像编辑
- 0.2-0.9秒的生成速度支持实时反馈
- 用户可以即时看到编辑效果
2. 视频生成
- 快速生成速度降低视频生成成本
- 30fps视频理论上可行(0.033秒/帧)
3. 移动设备部署
- 更少的计算需求
- 适合边缘设备运行
4. 大规模应用
- 降低服务器成本
- 支持更多并发用户
局限性与未来方向
当前局限
- 质量仍有小幅损失:平均FID从7.31提升到7.61
- 训练成本较高:基础CM需要160 A100 GPU天
- 某些条件表现不够稳定:如Mask inpainting的Fidelity相对较高
未来研究方向
-
更多条件类型:
- 语音控制
- 3D几何控制
- 时序控制(视频)
-
进一步加速:
- 探索亚线性步数生成
- 模型压缩和量化
-
质量提升:
- 改进consistency training目标
- 更好的适配器设计
-
理论理解:
- 深入分析CM和DM的差异
- 探索最优迁移策略
结论
CCM这篇论文在文本到图像生成领域做出了重要贡献:
- 首次系统性探索了为一致性模型添加条件控制的方法,填补了这一领域的空白
- 证明了consistency training可以直接训练ControlNet,确立了CM作为独立生成模型家族的地位
- 实现了26-118倍的速度提升,同时保持接近扩散模型的质量
- 揭示了模型间迁移的机制,通过相关性分析解释了为什么直接迁移在低层细节上失败
这项工作不仅推动了一致性模型的发展,也为实时可控图像生成开辟了新的可能。随着技术的进一步成熟,我们有望在不久的将来看到更多基于一致性模型的实时AI应用。
关键词:一致性模型、ControlNet、实时生成、条件控制、扩散模型、文本到图像生成

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)