AI大模型接入
AI 大模型是指具有超大规模参数(通常为数十亿到数万亿)的深度学习模型,通过对大规模数据的训练,能够理解、生成人类语言,处理图像、音频等多种模态数据,并展示出强大的推理和创作能力。大模型的强大之处在于它的涌现能力—— 随着模型参数量和训练数据量的增加,模型会展现出训练过程中未明确赋予的新能力,比如逻辑推理、代码编写、多步骤问题解决等。模型参数量达到,训练数据覆盖文本、图像、音频等多模态海量
一、AI大模型概念
1、什么是AI大模型
AI 大模型是指具有超大规模参数(通常为数十亿到数万亿)的深度学习模型,通过对大规模数据的训练,能够理解、生成人类语言,处理图像、音频等多种模态数据,并展示出强大的推理和创作能力。
大模型的强大之处在于它的 涌现能力 —— 随着模型参数量和训练数据量的增加,模型会展现出训练过程中未明确赋予的新能力,比如逻辑推理、代码编写、多步骤问题解决等。
| 特点维度 | 详细描述 | 典型示例 |
|---|---|---|
| 规模效应显著 | 模型参数量达到数十亿至万亿级,训练数据覆盖文本、图像、音频等多模态海量信息;参数量与数据量突破临界阈值后,会涌现出小模型不具备的复杂能力 | GPT-4(万亿级参数)、文心一言(千亿级参数) |
| 涌现能力突出 | 随规模增长自发形成非预设的新能力,如逻辑推理、代码编写、多步骤问题拆解等,能力无法通过小模型线性叠加实现 | 数学定理证明、复杂代码调试、跨语言精准翻译 |
| 通用化能力强 | 基于预训练+微调范式,无需针对单一任务重新训练;通过提示词(Prompt)即可适配不同场景,实现“一模型多任务” | 同一模型完成论文摘要、文案创作、数据分析、聊天交互 |
| 上下文理解与记忆能力优异 | 具备超长上下文窗口(可达数万至百万token),能精准捕捉长文本中的逻辑关联与细节信息,保持内容连贯性 | 处理万字合同文档的问答、总结百万字小说的核心情节 |
| 多模态融合能力 | 打破单一模态限制,支持文本、图像、音频、视频等多种信息的输入与输出,实现跨模态内容生成与理解 | 输入一张图片生成详细描述文案、语音指令生成代码、文本描述生成绘画 |
| 持续迭代与自适应优化 | 可通过增量预训练、强化学习人类反馈(RLHF) 不断优化模型效果,适配新领域知识与用户需求;同时支持领域微调,满足垂直场景的高精度要求 | 针对医疗领域微调后辅助诊断、针对法律领域微调后生成合同条款 |
2、AI大模型的分类
了解 AI 大模型的分类有助于我们进行大模型的技术选型,可以从模态、开源性、规模、用途等角度进行划分。
1、按模态分类
- 单模态模型:仅处理单一类型的数据,如纯文本(早期的 GPT-3)
- 多模态模型:能够处理多种类型的信息
- 文本 + 图像:GPT-4V、Gemini、Claude 3
- 文本 + 音频 + 视频:GPT-4o
2、按开源性分类
- 闭源模型:不公开模型权重和训练方法
- 代表:GPT-4、Claude、Gemini
- 特点:通常通过 API 访问,付费使用
- 开源模型:公开模型权重,允许下载和自行部署
- 代表:Llama 系列、Mistral、Falcon
- 特点:可以本地部署,自由调整,但通常性能略逊于同等规模闭源模型
3、按规模分类
- 超大规模模型:参数量在数千亿到数万亿
- 代表:GPT-4 (1.76T 参数)
- 特点:能力强大,但需要大量计算资源
- 中小规模模型:参数量在几十亿到几百亿
- 代表:Llama 3 (70B 参数)、Mistral 7B
- 特点:能在较普通的硬件上运行,适合特定任务的精调
4、按用途分类
- 通用模型:能处理广泛的任务
- 代表:GPT-4、Claude 3、Gemini
- 特定领域模型:针对特定领域优化
- 医疗领域:Med-PaLM 2
- 代码领域:CodeLlama、StarCoder
- 科学领域:Galactica
3、如何对比和选择大模型
| 一级维度 | 二级评估点 | 具体说明 |
|---|---|---|
| 功能支持维度 | 多模态能力 | • 纯文本处理 • 图像理解(GPT-4V、Gemini) • 音频/视频处理(GPT-4o) • 代码生成与理解(CodeLlama) |
| 工具使用能力 | • 函数调用支持 • 工具集成能力 • 外部 API 连接能力 | |
| 上下文窗口大小 | • 输入上下文长度(4K 至 128K tokens) • 长文档处理能力 | |
| 指令遵循能力 | • 复杂指令处理能力 • 多步骤任务执行能力 • 回答格式控制能力 | |
| 性能指标维度 | 准确性 | • 知识准确度 • 推理能力水平 • 幻觉倾向性 |
| 响应质量 | • 输出流畅性与连贯性 • 回答相关性与深度 • 语言表达自然度 | |
| 知识时效性 | • 知识截止日期 • 更新频率 | |
| 部署与集成维度 | 部署方式 | • 云 API 服务 • 本地部署可能性 • 私有云部署支持 |
| API 接口 | • 接口稳定性与可靠性 • SDK 支持情况 • 开发框架集成 | |
| 并发处理能力 | • 请求吞吐量 • 并发请求处理能力 • 服务水平协议 (SLA) 保障 | |
| 商业与合规维度 | 成本效益 | • API 调用价格 • 批量调用折扣 • 计算资源成本 |
| 数据安全与隐私 | • 数据使用政策 • 是否支持不保存用户数据 • 企业级安全合规 | |
| 法律合规性 | • 地区可用性 • 版权与知识产权问题 • 内容安全审查机制 | |
| 生态与支持维度 | 社区支持 | • 开发者社区活跃度 • 问题解决资源丰富度 • 第三方扩展与工具 |
| 文档完善度 | • API 文档质量 • 示例代码丰富度 • 最佳实践指南 | |
| 技术支持 | • 官方支持渠道 • 响应时间 • 企业级支持选项 |
对大多数开发者来说,更关注的是 准确度 + 功能支持 + 性能 + 成本 四大核心维度。
作为开发者,我们经常需要通过开发框架让程序对接大模型,因此可通过以下开发框架的官方文档,快速了解和对比不同大模型的功能支持:
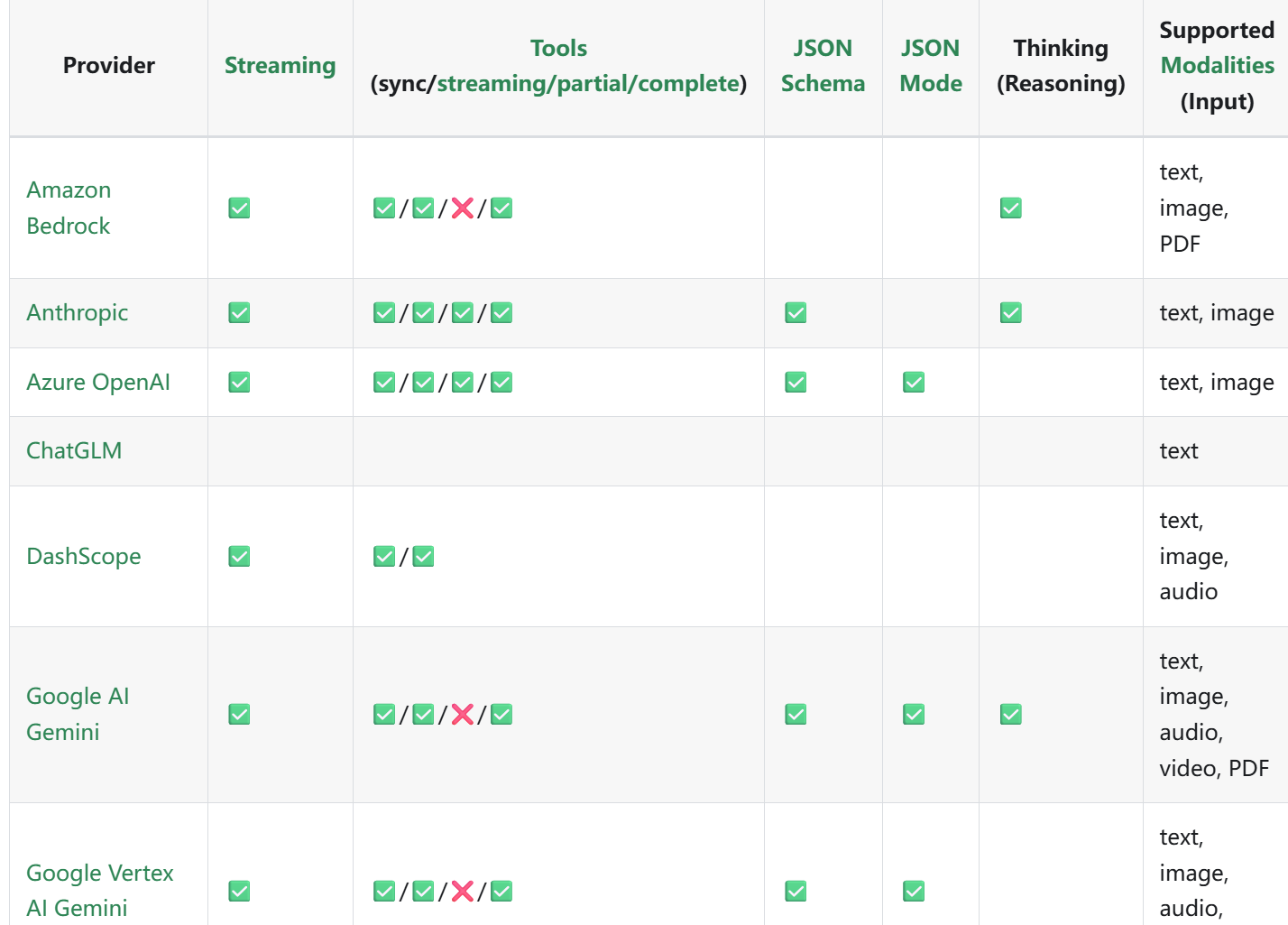
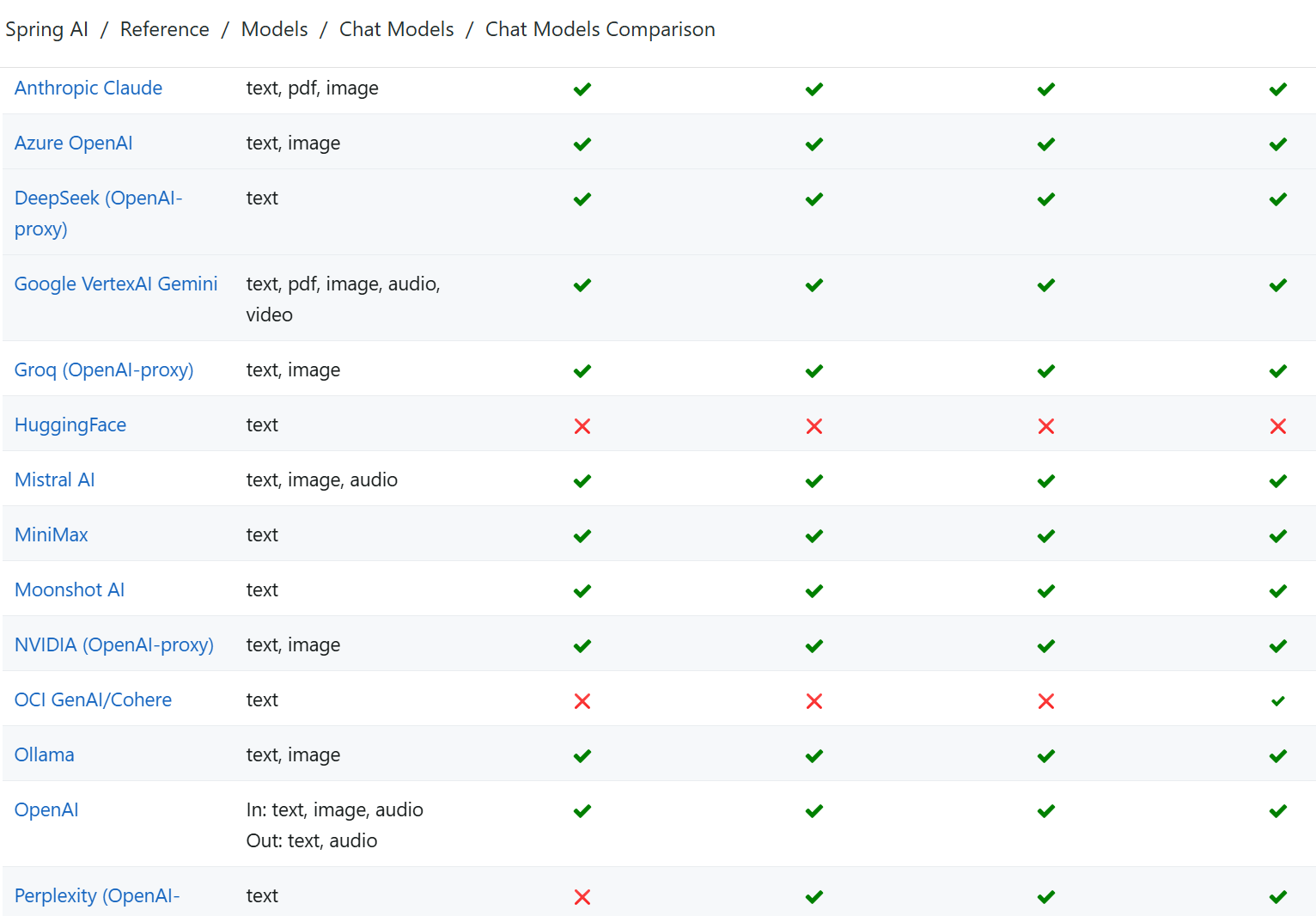
- LangChain4j 支持的大模型对比:https://docs.langchain4j.dev/integrations/language-models/
- Spring AI 大模型对比文档:https://docs.spring.io/springai/reference/1.0/api/chat/comparison.html-
二、接入AI大模型
1、使用大模型的途径
在实际开发过程中,使用 AI 大模型的核心途径主要分为 云服务 和 自部署 两类,二者基于不同的技术架构与使用场景,各有优劣,具体分析如下:
4种AI大模型接入方式 优缺点对比 & 适用场景
| 接入方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| SDK 接入 | • 类型安全,支持编译时语法检查 • 官方封装完善的错误处理机制 • 配套详细的官方技术文档 • 底层做过针对性性能优化 | • 强依赖对应SDK的特定版本 • 引入SDK会增加项目打包体积 • 有开发语言的使用限制 | • 业务需要与大模型深度集成 • 项目仅对接单一模型提供商 • 生产环境对调用性能要求高 |
| HTTP 接入 | • 无开发语言限制,跨语言友好 • 不引入额外依赖包,轻量化 • 接口调用灵活性极高,无框架约束 | • 需要手动编写代码处理各类异常错误 • 请求/响应的序列化、反序列化需手动实现 • 接口调用相关代码偏冗长繁琐 | • 项目开发语言无对应官方SDK支持 • 简单的功能原型验证、快速试错 • 临时性的小功能模块集成大模型 |
| Spring AI | • 提供统一的抽象调用接口,规范统一 • 极低成本无缝切换不同模型提供商 • 与Spring生态完美融合,开箱即用 • 内置RAG、工具调用等高级AI能力 | • 多一层框架抽象层,有少量性能损耗 • 部分小众/专属模型特性可能不支持 • 框架版本迭代较快,部分特性兼容性待完善 | • 基于Spring/SpringBoot的Java项目 • 业务需要兼容、切换多种大模型 • 开发中需用到RAG、知识库等高级AI功能 |
| LangChain4j | • 提供完整的AI应用开发工具链 • 原生支持复杂的AI业务工作流编排 • 组件/工具生态丰富,开箱即用 • 极致适配AI代理、智能体类场景开发 | • 框架体系复杂,学习曲线较陡峭 • 部分细分功能的文档相对偏少 • 多层抽象封装会引入一定性能开销 | • 构建复杂的企业级AI应用系统 • 业务需要多步链式调用的场景 • RAG知识库、智能体、多工具组合类开发 |
一、云服务
直接使用云服务商在云端已部署好的大模型服务,无需自行搭建基础设施(如服务器、GPU 算力),是主流的轻量化使用方式。
核心特点
- 提供纯净的大模型能力和构建应用(智能体)的工具,开箱即用
- 按需付费模式,无需前期大量基础设施投入,成本可控
- 随时可用,无需关注底层维护,维护成本低
- 自动更新到最新版本的模型,持续获得能力升级
- 通常具备更完善的安全措施和合规保障,符合行业规范
二、自部署
开发者自行在本地服务器或私有云环境部署开源大模型,拥有完全的自主控制权。
核心特点
- 完全控制数据流,数据不对外传输,具备更高的数据隐私保障
- 可根据业务特定需求进行模型微调和定制化开发
- 无网络依赖与网络延迟,响应速度快,适合对实时性有严格要求的场景
- 一次性投入成本较高(硬件采购、算力储备),且需要专业技术团队负责运维
- 适配性强,适合企业级复杂应用和对数据安全、合规性有严格要求的场景
3、接入大模型的 3 种方式
1、AI 应用平台接入
通过云服务商提供的 AI 应用平台使用 AI 大模型,是最便捷的接入方式之一 —— 平台已完成大模型的部署、运维与升级,开发者无需关注底层技术细节,可直接聚焦应用开发。
以 阿里云百炼(官方地址)为例,作为一站式大模型开发及应用构建平台,其核心优势与接入价值如下:
- 全流程支持:覆盖从模型调用(支持多种主流大模型)、应用搭建(智能体开发、插件集成)到部署上线的完整链路,无需额外对接多个工具;
- 低代码 / 无代码友好:提供可视化开发界面,开发者可通过拖拽、配置等方式快速构建应用,降低技术门槛;
- 企业级保障:自带阿里云的安全合规能力、稳定算力支撑与运维服务,适合快速落地商业级应用;
- 生态联动:可无缝对接阿里云其他产品(如存储、计算、安全服务),丰富应用场景的拓展性。
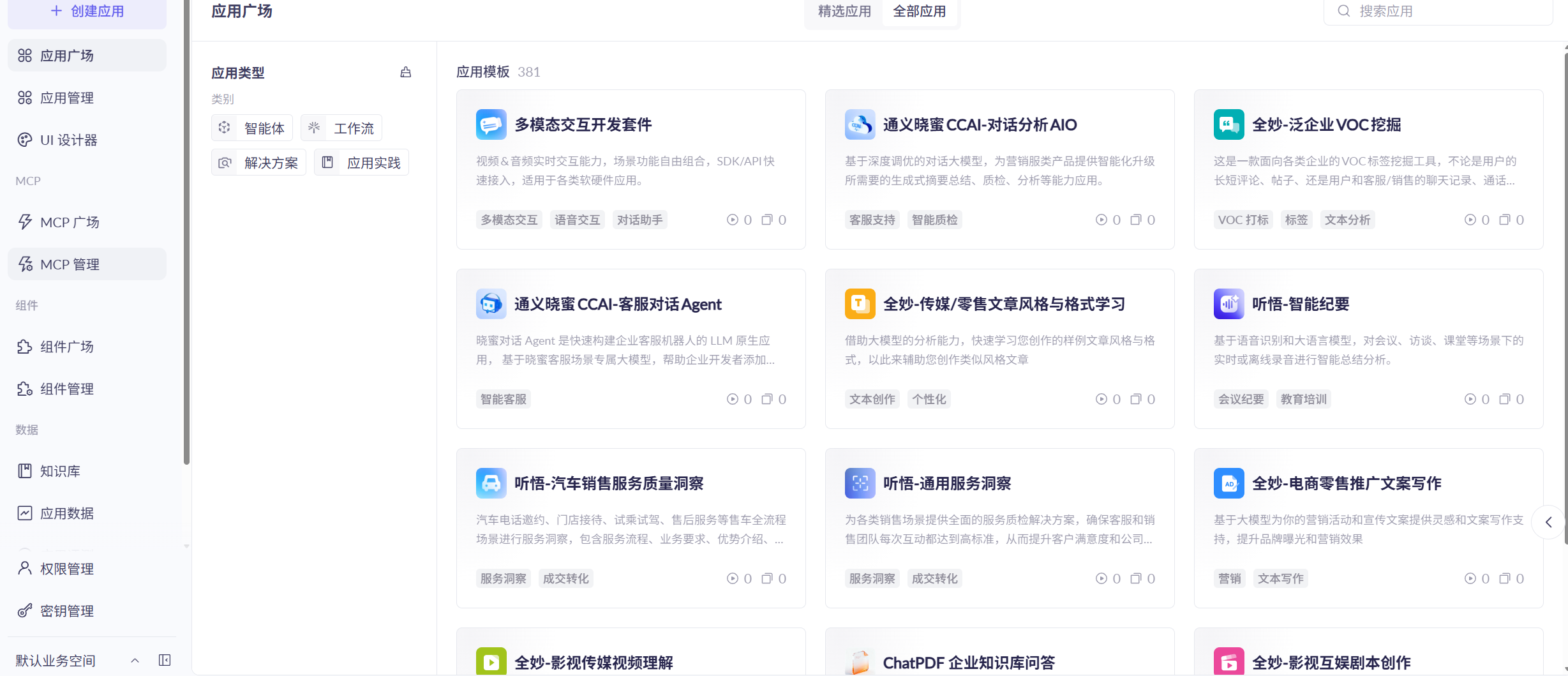
此外,还提供了知识库管理、应用评测、应用观测等功能,能够帮企业快速构建智能客服等应用。
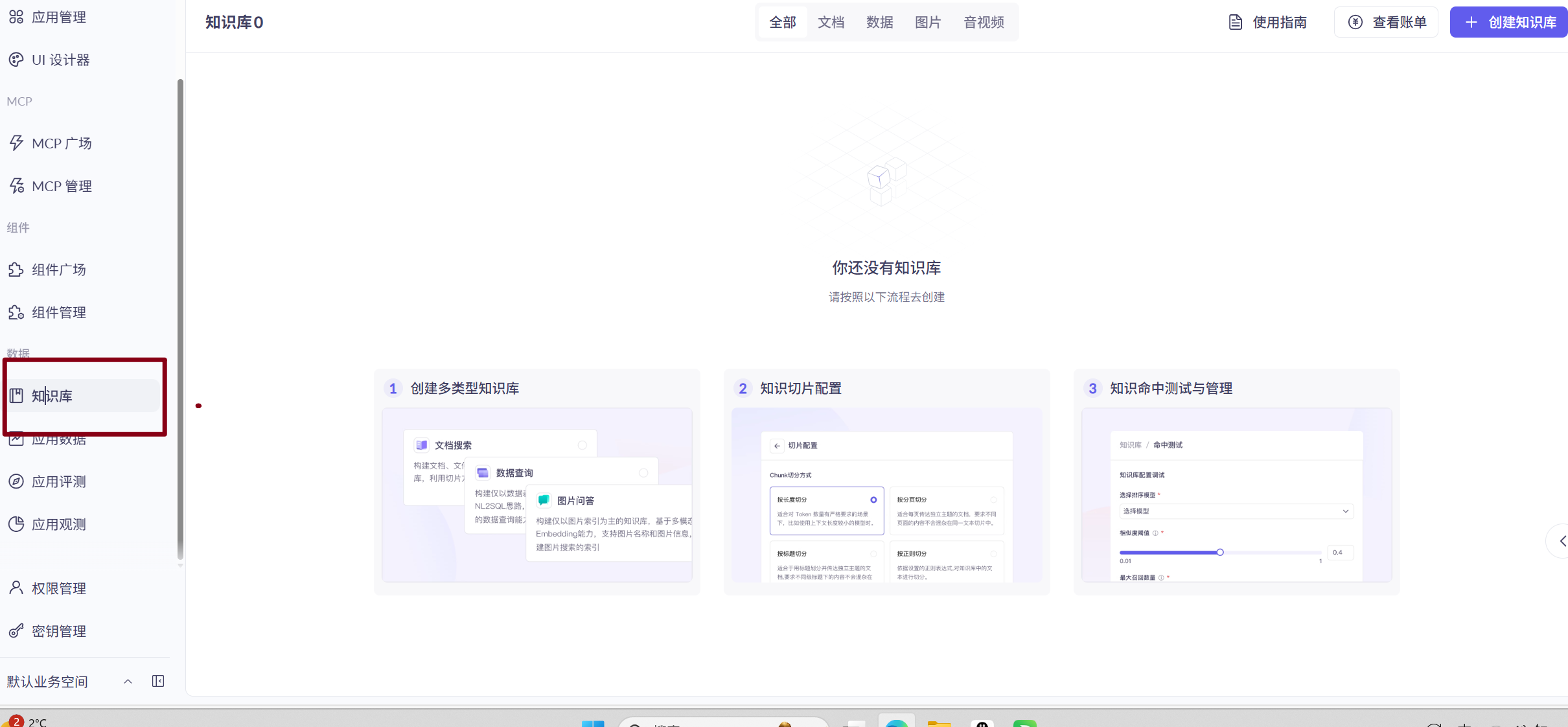
大家在使用阿里云百炼产品时,可能会看到另外一个产品 —— 模型服务灵积(DashScope),很容易把这两个产品混淆。百炼是一个可视化平台,同时服务于技术和非技术同学,使用更简单,更上层;而灵积旨在通过灵活、易用的 模型 API 接口,让开发者能够快速调用丰富的大模型能力,面向技术开发同学,更底层。后续我们通过编程来调用 AI 大模型,更多的是和灵积打交道。
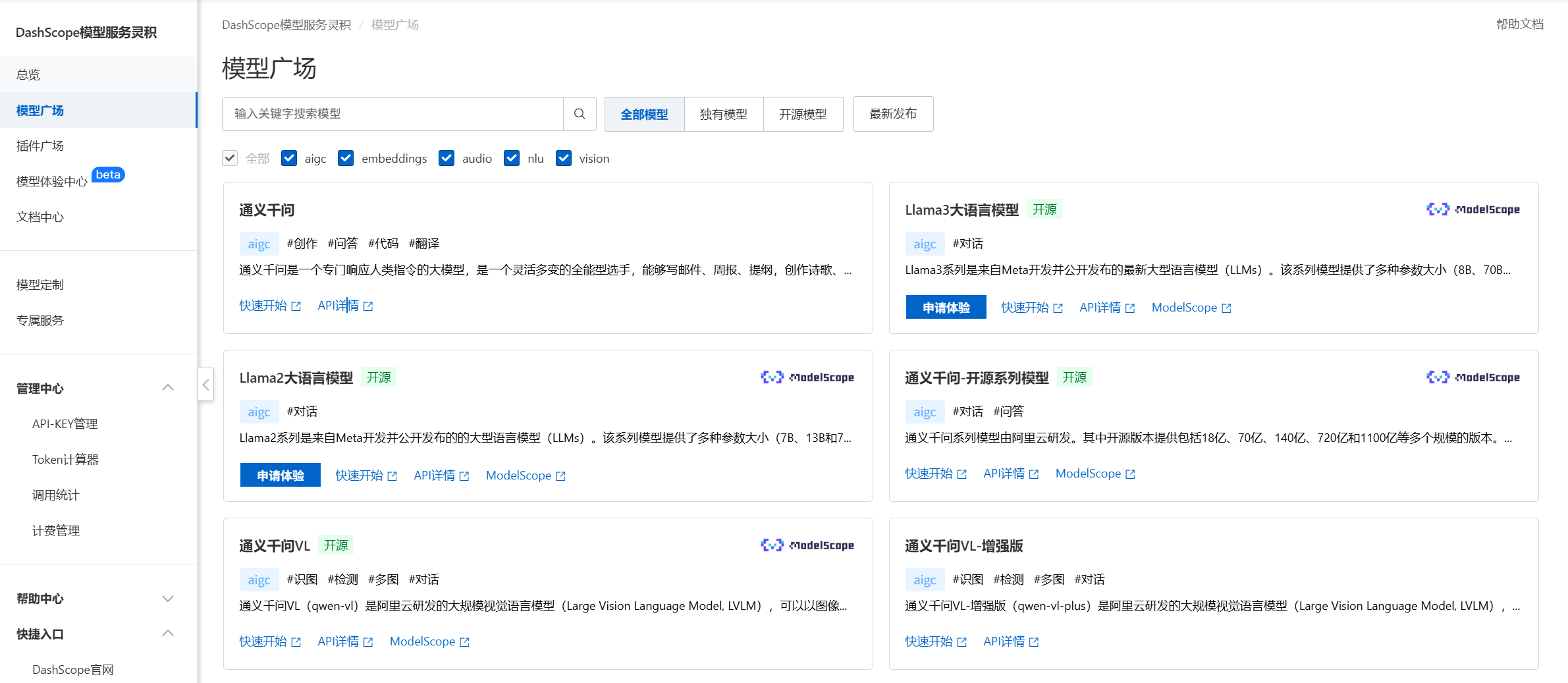
利用阿里云百炼平台,我们可以轻松体验 AI 大模型和构建 AI 应用。
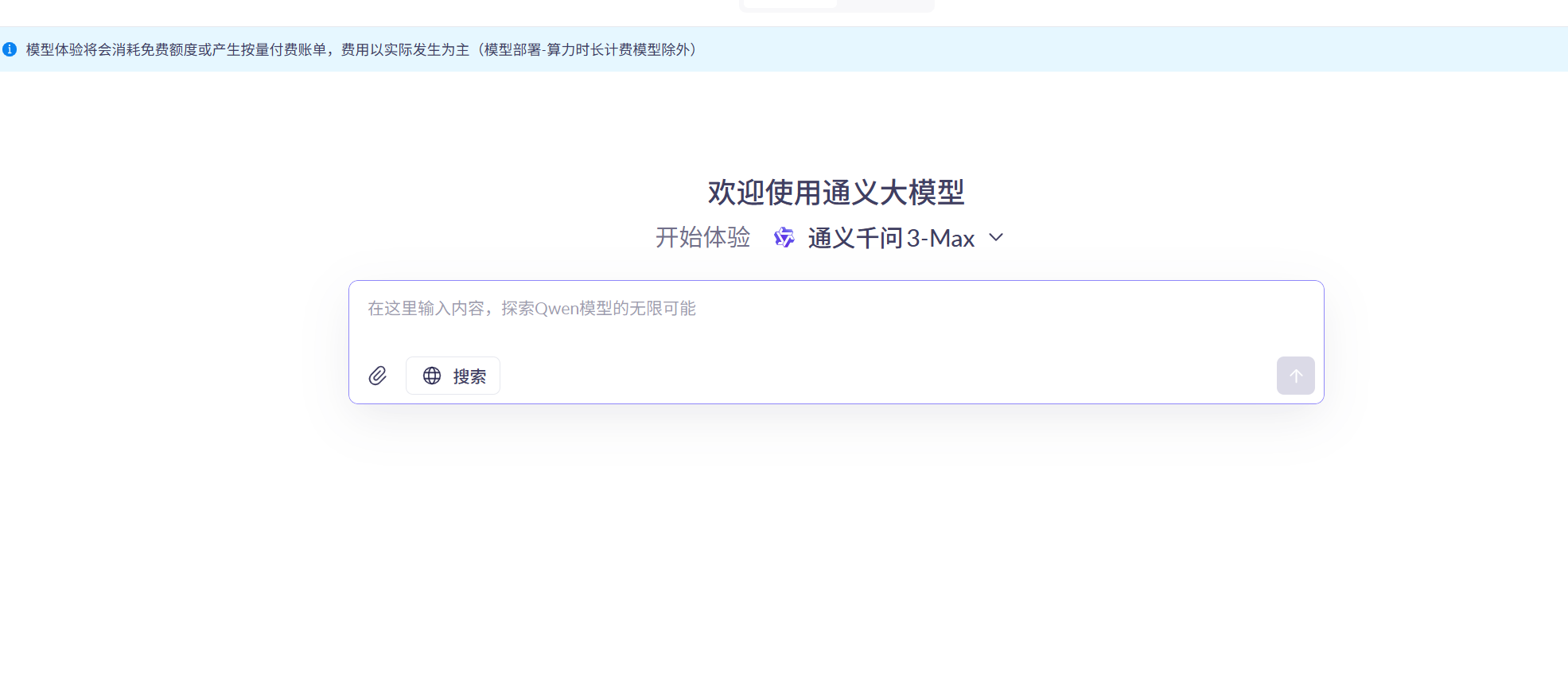
1)快速体验 AI 大模型 阿里云百炼 - 模型市场
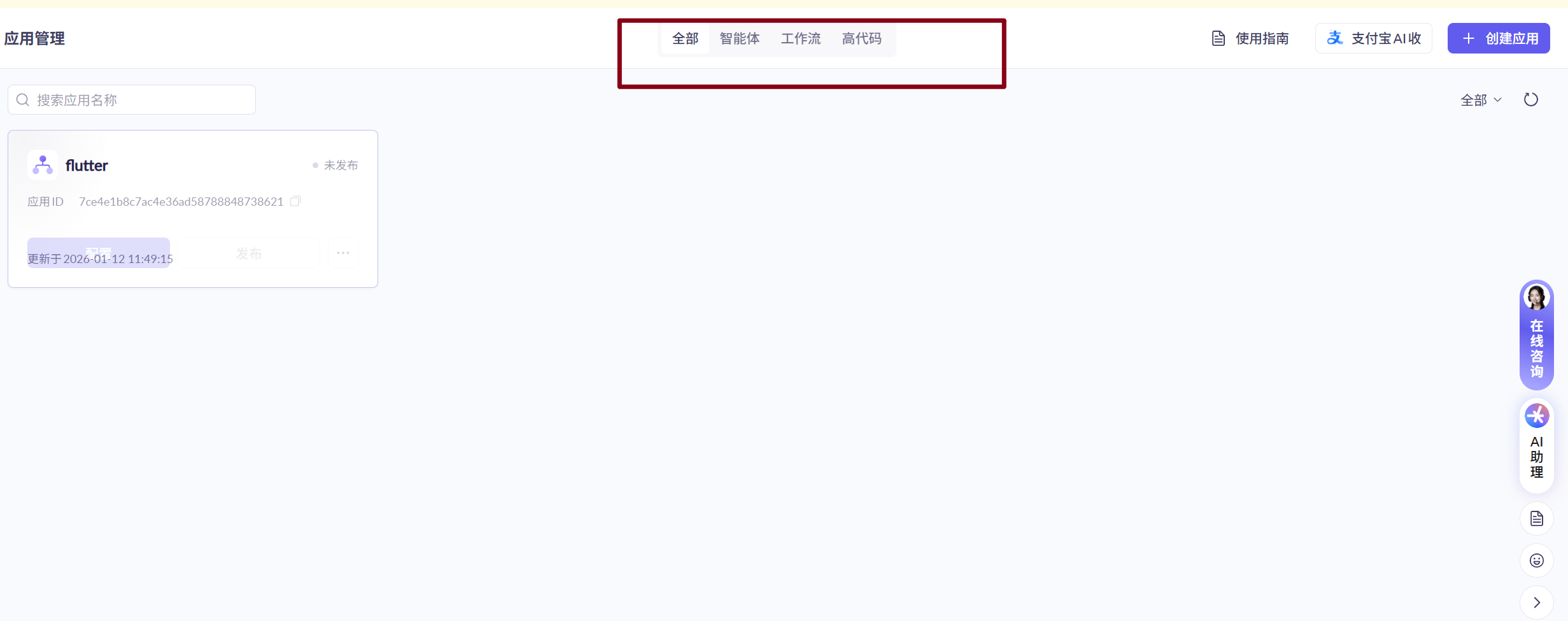
2)创建自己的 AI 应用,支持智能体、工作流和智能体编排应用。
通过 阿里云百炼 - 模型市场,可基于平台提供的大模型能力,快速搭建符合自身需求的 AI 应用,核心支持 智能体、工作流、智能体编排 三类应用形态,无需复杂底层开发。
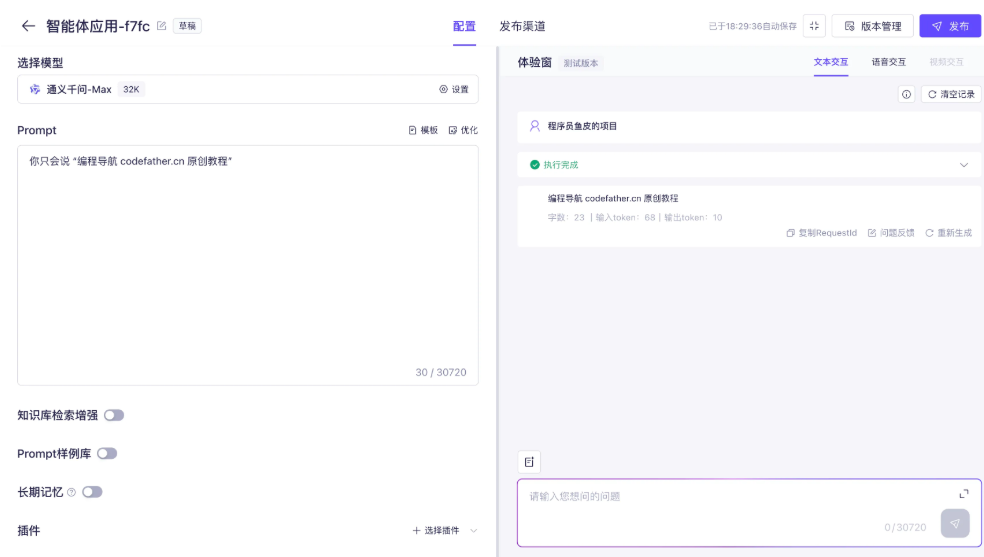
智能体应用:
工作流应用,可以自主编排多个工作节点,完成复杂任务。适用于需要结合大模型执行 高确定性 的业务逻辑的流程型应用,如可执行不同任务的智能助理工作流、自动化分析会议记录工作流等。
智能体编排应用支持用户通过画布的自定义智能体执行逻辑,编排主体为智能体,如智能体节点、智能体组及节点等,可快速实现复杂多智能体协同的逻辑设计和业务效果验证。适用于需要处理大量数据、进行复杂计算或执行多任务处理的场景。
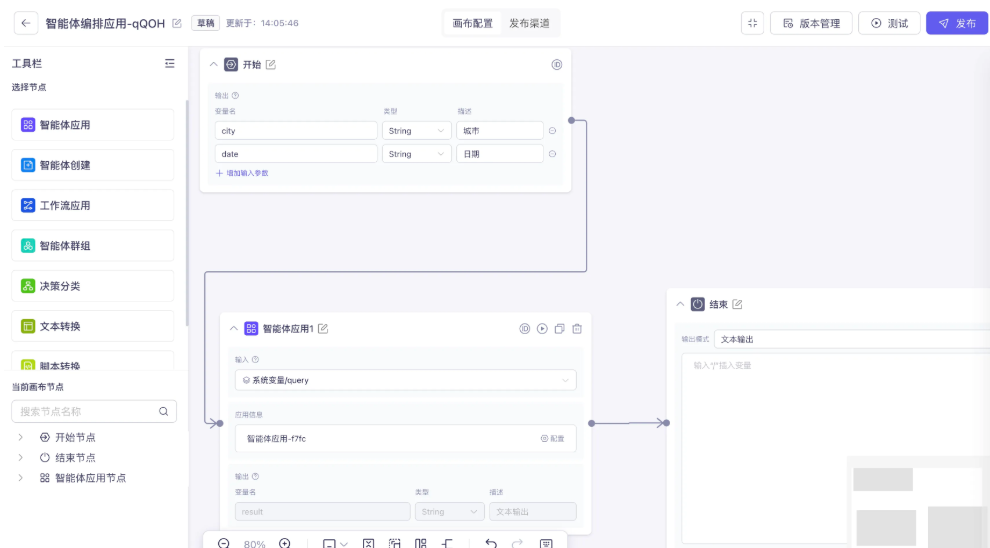
创建好了应用(智能体、工作流或智能体编排)后,可以参考 应用调用文档,通过 DashScope SDK 或 HTTP 的方式在自己的项目中集成应用。
2、AI 软件客户端接入
1)Cherry Studio:一款集多模型对话、知识库管理、AI 绘画、翻译等功能于一体的全能 AI 助手平台。Cherry Studio 提供高度自定义的设计、强大的扩展能力和友好的用户体验。
3、程序接入
可以通过编程的方式在自己的项目中调用 AI 大模型,又可以分为 2 种方式:
大模型的开发接入主要分为以下两种方式,适用于不同开发需求与技术场景:
| 调用方式 | 核心描述 | 优势 | 适用场景 |
|---|---|---|---|
| 1. 直接调用 AI 大模型(原生接入) | 跳过第三方应用封装,直接对接大模型的底层能力 | 性能损耗低、功能调用更全面、参数配置更灵活 | 对模型能力有精细化需求、需深度定制参数的开发场景 |
| 2. 调用 AI 大模型平台创建的应用/智能体 | 复用平台已配置好的应用模板或智能体,直接调用封装后的能力 | 开发效率高、无需关注模型细节、支持快速集成 | 快速验证产品原型、无需复杂定制的标准化场景 |
方式 1:直接调用 AI 大模型(技术实现方案)
这种方式可通过 SDK/API 原生接入 或 AI 开发框架接入 两种路径实现,满足不同灵活度需求:
1.1 SDK/API 原生接入
- 核心逻辑:直接使用大模型官方提供的 SDK 或 REST API,按平台文档规范编写调用代码。
- 操作步骤:
- 注册大模型平台账号,获取 API Key/Token(如 DeepSeek、OpenAI 等平台的开发者凭证);
- 引入官方 SDK(如 Maven/Gradle 依赖、Python pip 包);
- 按文档示例编写调用代码,配置模型参数(如温度值、最大响应长度、上下文窗口等);
- 调试接口响应,集成到业务系统中。
- 特点:针对性强,但切换不同大模型时需修改适配代码(不同平台 API 规范差异较大)。
1.2 AI 开发框架接入(推荐灵活适配场景)
通过标准化开发框架封装底层调用逻辑,实现“一次编码,多模型切换”,主流框架包括 Spring AI、Spring AI Alibaba、LangChain4j 等。
以 Spring AI Alibaba(官方地址)为例,核心优势与接入价值如下:
- 「Spring 生态原生兼容」:基于 Spring AI 开源项目,无缝适配 Spring Boot 体系,Java 开发者可通过熟悉的 Bean 注入、配置文件等方式快速集成;
- 「多模型灵活切换」:内置对阿里云通义系列、DeepSeek、Llama 等主流模型的支持,切换模型时仅需修改配置文件,无需改动业务代码;
- 「全链路能力封装」:覆盖低层次抽象(提示词模板、函数调用、格式化输出)与高层次抽象(RAG 检索增强、智能体、对话记忆),满足从简单调用到复杂应用的全场景需求;
- 「云原生深度集成」:适配阿里云网关、Nacos 配置中心、RocketMQ 消息队列等云原生基础设施,支持 Serverless 部署、可观测性监控(如 LLM 调用日志、性能指标),适合企业级生产环境。
- 接入核心逻辑(Spring Boot 场景):
- 引入 Spring AI Alibaba 依赖(如通义模型、DeepSeek 模型的 Starter 包);
- 在
<font style="color:rgb(31, 31, 31);">application.yml</font>中配置模型类型、API Key、参数(统一配置规范,与具体模型解耦); - 通过框架提供的
<font style="color:rgb(31, 31, 31);">ChatClient</font>、<font style="color:rgb(31, 31, 31);">EmbeddingClient</font>等标准化接口调用模型能力; - 如需切换模型,仅需修改配置文件中的
<font style="color:rgb(31, 31, 31);">model.name</font>等参数(如从 DeepSeek 切换为通义千问)。
方式 2:调用 AI 大模型平台创建的应用/智能体
- 核心逻辑:先在大模型平台(如阿里云百炼)可视化配置应用/智能体(已预设模型、提示词、工具集成逻辑),再通过平台提供的“应用调用 API”将能力集成到系统中。
- 操作步骤:
- 在平台(如阿里云百炼模型市场)创建应用/智能体,配置业务逻辑(如客服机器人的对话流程、工具调用规则);
- 发布应用后,获取应用专属的调用 API 与凭证;
- 在业务系统中调用该 API,传入请求参数(如用户提问、上下文信息);
- 接收平台返回的标准化响应结果,集成到产品中。
- 特点:开发成本极低,无需关注模型参数与底层逻辑,但灵活度受平台配置能力限制。
四、程序调用 AI 大模型
在实际开发中,有多种方式可以在应用程序中调用 AI 大模型。下面详细介绍 4 种主流的接入方式,并通过实例代码展示如何在 Java 项目中实现与 AI 大模型的交互。
- SDK 接入:使用官方提供的软件开发工具包,最直接的集成方式
- HTTP 接入:通过 REST API 直接发送 HTTP 请求调用模型
- Spring AI:基于 Spring 生态系统的 AI 框架,更方便地接入大模型
- LangChain4j:专注于构建 LLM 应用的 Java 框架,提供丰富的 AI 调用组件
1、SDK形式
SDK(软件开发工具包)是官方提供的最直接的集成方式,通常提供了完善的类型支持和错误处理机制。
1)首先需要按照官方文档安装 SDK:安装 SDK 官方指南
在选择 SDK 版本时,建议在 Maven 仓库查看最新的版本号:Maven 中央仓库版本信息
在 <font style="color:rgb(31, 35, 41);background-color:rgba(0, 0, 0, 0);">pom.xml</font> 中引入依赖:
<!-- 此处粘贴对应的 Maven 依赖坐标即可 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>dashscope-sdk-java</artifactId>
<version>2.22.4</version>
</dependency>
package com.lyf.maxaiagent.demo.invoke;
// Copyright (c) Alibaba, Inc. and its affiliates.
import com.alibaba.dashscope.aigc.videosynthesis.VideoSynthesis;
import com.alibaba.dashscope.aigc.videosynthesis.VideoSynthesisParam;
import com.alibaba.dashscope.aigc.videosynthesis.VideoSynthesisResult;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.InputRequiredException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.utils.Constants;
import com.alibaba.dashscope.utils.JsonUtils;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.Base64;
import java.util.HashMap;
import java.util.Map;
/**
* 环境要求
* dashscope java SDK >= 2.20.9
* 更新maven依赖:
* https://mvnrepository.com/artifact/com.alibaba/dashscope-sdk-java
*/
class VideoSdkInvoke {
static {
// 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/api/v1
Constants.baseHttpApiUrl = "https://dashscope.aliyuncs.com/api/v1";
}
// 若没有配置环境变量,请用百炼API Key将下行替换为:apiKey="sk-xxx"
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
static String apiKey = "key";
/**
* 图像输入方式说明:三选一即可
*
* 1. 使用公网URL - 适合已有公开可访问的图片
* 2. 使用本地文件 - 适合本地开发测试
* 3. 使用Base64编码 - 适合私有图片或需要加密传输的场景
*/
//【方式一】公网URL
static String firstFrameUrl = "img1";
static String lastFrameUrl = "img2";
//【方式二】本地文件路径(file://+绝对路径 or file:///+绝对路径)
// static String firstFrameUrl = "file://" + "/your/path/to/first_frame.png"; // Linux/macOS
// static String lastFrameUrl = "file:///" + "C:/path/to/your/img.png"; // Windows
//【方式三】Base64编码
// static String firstFrameUrl = Kf2vSync.encodeFile("/your/path/to/first_frame.png");
// static String lastFrameUrl = Kf2vSync.encodeFile("/your/path/to/last_frame.png");
public static void syncCall() {
Map<String, Object> parameters = new HashMap<>();
parameters.put("prompt_extend", true);
parameters.put("resolution", "720P");
VideoSynthesis videoSynthesis = new VideoSynthesis();
VideoSynthesisParam param =
VideoSynthesisParam.builder()
.apiKey(apiKey)
.model("wan2.2-kf2v-flash")
.prompt("写实风格,一只黑色小猫好奇地看向天空,镜头从平视逐渐上升,最后俯拍它的好奇的眼神。")
.firstFrameUrl(firstFrameUrl)
.lastFrameUrl(lastFrameUrl)
.parameters(parameters)
.build();
VideoSynthesisResult result = null;
try {
System.out.println("---sync call, please wait a moment----");
result = videoSynthesis.call(param);
} catch (ApiException | NoApiKeyException e){
throw new RuntimeException(e.getMessage());
} catch (InputRequiredException e) {
throw new RuntimeException(e);
}
System.out.println(JsonUtils.toJson(result));
}
/**
* 将文件编码为Base64字符串
* @param filePath 文件路径
* @return Base64字符串,格式为 data:{MIME_type};base64,{base64_data}
*/
public static String encodeFile(String filePath) {
Path path = Paths.get(filePath);
if (!Files.exists(path)) {
throw new IllegalArgumentException("文件不存在: " + filePath);
}
// 检测MIME类型
String mimeType = null;
try {
mimeType = Files.probeContentType(path);
} catch (IOException e) {
throw new IllegalArgumentException("无法检测文件类型: " + filePath);
}
if (mimeType == null || !mimeType.startsWith("image/")) {
throw new IllegalArgumentException("不支持或无法识别的图像格式");
}
// 读取文件内容并编码
byte[] fileBytes = null;
try{
fileBytes = Files.readAllBytes(path);
} catch (IOException e) {
throw new IllegalArgumentException("无法读取文件内容: " + filePath);
}
String encodedString = Base64.getEncoder().encodeToString(fileBytes);
return "data:" + mimeType + ";base64," + encodedString;
}
public static void main(String[] args) {
syncCall();
}
}
2、Http形式接入
对于 SDK 不支持的编程语言或需要更灵活控制的场景,可以直接使用 HTTP 请求调用 AI 大模型的 API。
💡 使用建议:一般来说,如果有官方 SDK 支持,优先使用 SDK;只有在不支持 SDK 的情况下,再考虑直接 HTTP 调用
HTTP 调用的详细说明可参考官方文档:通过 API 调用通义千问
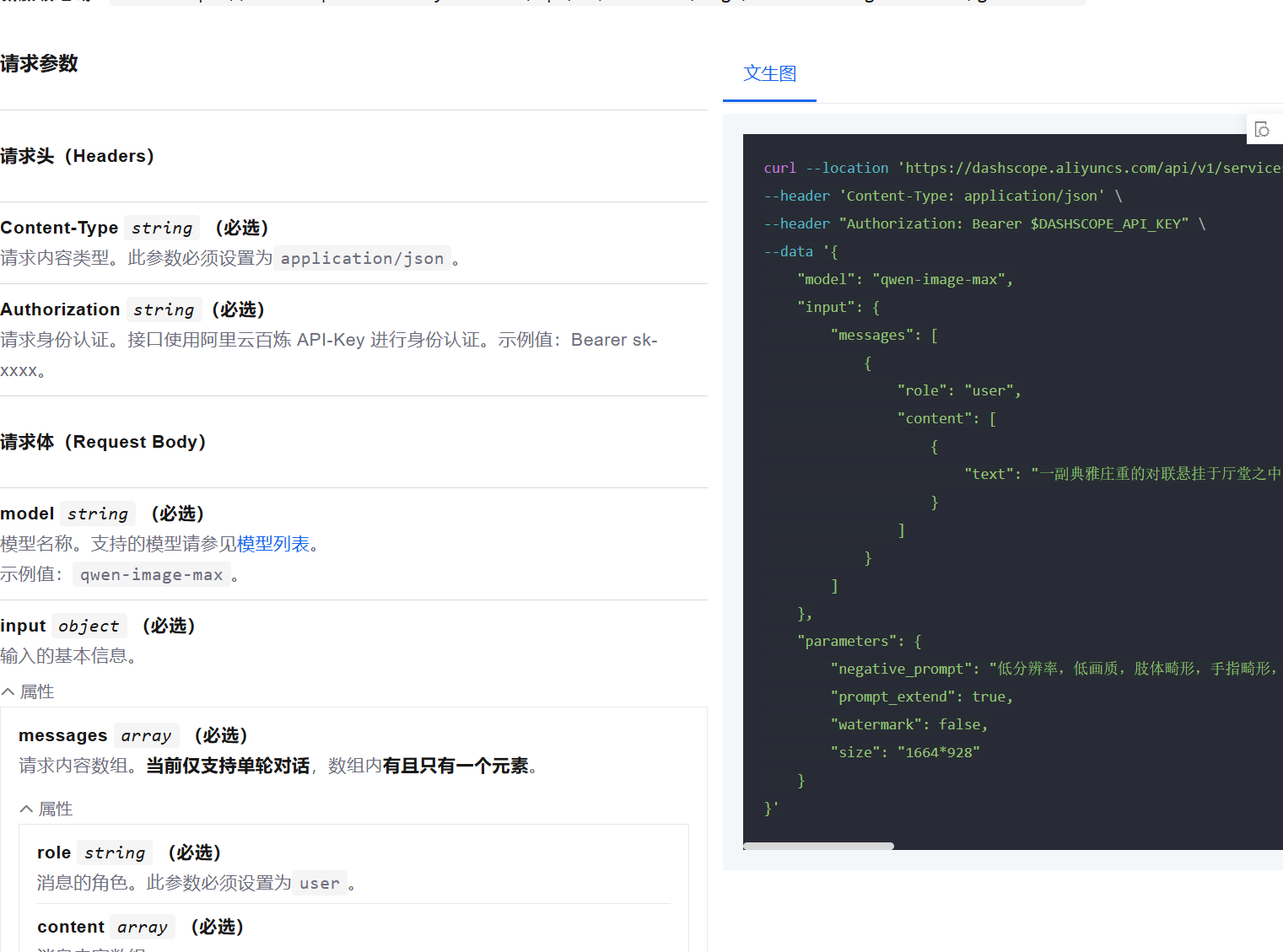
curl --location 'https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation' \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer $DASHSCOPE_API_KEY" \
--data '{
"model": "qwen-image-max",
"input": {
"messages": [
{
"role": "user",
"content": [
{
"text": "一副典雅庄重的对联悬挂于厅堂之中,房间是个安静古典的中式布置,桌子上放着一些青花瓷,对联上左书“义本生知人机同道善思新”,右书“通云赋智乾坤启数高志远”, 横批“智启通义”,字体飘逸,在中间挂着一幅中国风的画作,内容是岳阳楼。"
}
]
}
]
},
"parameters": {
"negative_prompt": "低分辨率,低画质,肢体畸形,手指畸形,画面过饱和,蜡像感,人脸无细节,过度光滑,画面具有AI感。构图混乱。文字模糊,扭曲。",
"prompt_extend": true,
"watermark": false,
"size": "1664*928"
}
}'
package com.lyf.maxaiagent.demo.invoke;
import org.json.JSONObject;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.nio.charset.StandardCharsets;
/**
* 阿里云DashScope API调用示例
* 用于调用qwen-image-max模型生成图像
*/
public class DemoInvoke {
// API密钥,建议从环境变量或配置文件中读取
private static final String DASHSCOPE_API_KEY = "key";
// API端点URL
private static final String API_URL = "https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation";
public static void main(String[] args) {
try {
// 调用API生成图像
String response = callQwenImageMaxAPI();
// 打印响应结果
System.out.println("API响应:");
System.out.println(response);
} catch (Exception e) {
// 打印异常信息
System.err.println("调用API时发生错误:");
e.printStackTrace();
}
}
/**
* 调用阿里云DashScope qwen-image-max模型生成图像
*
* @return API响应的JSON字符串
* @throws Exception 网络请求或数据处理异常
*/
public static String callQwenImageMaxAPI() throws Exception {
// 创建URL对象
URL url = new URL(API_URL);
// 打开HTTP连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
try {
// 设置请求方法为POST
connection.setRequestMethod("POST");
// 设置Content-Type请求头,指定请求体格式为JSON
connection.setRequestProperty("Content-Type", "application/json");
// 设置Authorization请求头,使用Bearer Token进行身份验证
connection.setRequestProperty("Authorization", "Bearer " + DASHSCOPE_API_KEY);
// 启用输出流,允许发送请求体数据
connection.setDoOutput(true);
// 构建请求体JSON数据
JSONObject requestBody = buildRequestBody();
// 获取输出流并写入请求体数据
try (OutputStream os = connection.getOutputStream()) {
// 将JSON对象转换为字符串并写入输出流,使用UTF-8编码
byte[] input = requestBody.toString().getBytes(StandardCharsets.UTF_8);
os.write(input, 0, input.length);
}
// 获取HTTP响应码
int responseCode = connection.getResponseCode();
System.out.println("HTTP响应码: " + responseCode);
// 读取响应内容
BufferedReader reader;
// 根据响应码判断读取输入流还是错误流
if (responseCode >= 200 && responseCode < 300) {
// 成功响应,读取正常输入流
reader = new BufferedReader(new InputStreamReader(connection.getInputStream(), StandardCharsets.UTF_8));
} else {
// 错误响应,读取错误流
reader = new BufferedReader(new InputStreamReader(connection.getErrorStream(), StandardCharsets.UTF_8));
}
// 使用StringBuilder拼接响应内容
StringBuilder response = new StringBuilder();
String line;
// 逐行读取响应数据
while ((line = reader.readLine()) != null) {
response.append(line);
}
// 关闭读取器
reader.close();
// 返回响应字符串
return response.toString();
} finally {
// 断开连接,释放资源
connection.disconnect();
}
}
/**
* 构建请求体JSON对象
*
* @return 包含完整请求参数的JSONObject
*/
private static JSONObject buildRequestBody() {
// 创建最外层JSON对象
JSONObject requestBody = new JSONObject();
// 设置使用的模型名称
requestBody.put("model", "qwen-image-max");
// 创建input对象,包含messages消息列表
JSONObject input = new JSONObject();
// 创建messages数组
JSONObject messages = new JSONObject();
// 设置消息角色为user(用户)
messages.put("role", "user");
// 创建content数组,包含消息的具体内容
JSONObject contentItem = new JSONObject();
// 设置文本提示词,描述要生成的图像内容
contentItem.put("text", "一副典雅庄重的对联悬挂于厅堂之中,房间是个安静古典的中式布置,桌子上放着一些青花瓷,对联上左书"+"义本生知人机同道善思新,右书通云赋智乾坤启数高志远, 横批智启通义,字体飘逸,在中间挂着一幅中国风的画作,内容是岳阳楼。");
// 构建完整的消息结构
messages.put("content", new org.json.JSONArray().put(contentItem));
input.put("messages", new org.json.JSONArray().put(messages));
requestBody.put("input", input);
// 创建parameters对象,设置生成参数
JSONObject parameters = new JSONObject();
// 设置负向提示词,描述不希望出现的内容
parameters.put("negative_prompt", "低分辨率,低画质,肢体畸形,手指畸形,画面过饱和,蜡像感,人脸无细节,过度光滑,画面具有AI感。构图混乱。文字模糊,扭曲。");
// 启用提示词扩展,自动优化提示词
parameters.put("prompt_extend", true);
// 关闭水印
parameters.put("watermark", false);
// 设置生成图像的尺寸
parameters.put("size", "1664*928");
// 将参数添加到请求体
requestBody.put("parameters", parameters);
return requestBody;
}
}
3、Spring AI
Spring AI 是 Spring 生态系统的新成员,旨在简化 AI 功能与 Spring 应用的集成。Spring AI 通过提供统一接口、支持集成多种 AI 服务提供商和模型类型、各种 AI 开发常用的特性(比如 RAG 知识库、Tools 工具调用和 MCP 模型上下文协议),简化了 AI 应用开发代码,使开发者能够专注于业务逻辑,提高了开发效率。
Spring AI 核心特性如下:
- 跨 AI 供应商的可移植 API 支持:适用于聊天、文本转图像和嵌入模型,同时支持同步和流式 API 选项,并可访问特定于模型的功能。
- 支持所有主流 AI 模型供应商:如 Anthropic、OpenAI、微软、亚马逊、谷歌和 Ollama,支持的模型类型包括:聊天补全、嵌入、文本转图像、音频转录、文本转语音。
- 结构化输出:将 AI 模型输出映射到 POJO(普通 Java 对象)。
- 支持所有主流向量数据库:如 Apache Cassandra、Azure Cosmos DB、Azure Vector Search、Chroma、Elasticsearch、GemFire、MariaDB、Milvus、MongoDB Atlas、Neo4j、OpenSearch、Oracle、PostgreSQL/PGVector、PineCone、Qdrant、Redis、SAP Hana、Typesense 和 Weaviate。
- 跨向量存储供应商的可移植 API:包括新颖的类 SQL 元数据过滤 API。
- 工具 / 函数调用:允许模型请求执行客户端工具和函数,从而根据需要访问必要的实时信息并采取行动。
- 可观测性:提供与 AI 相关操作的监控信息。
- 文档 ETL 框架:适用于数据工程场景。
- AI 模型评估工具:帮助评估生成内容并防范幻觉响应。
- Spring Boot 自动配置和启动器:适用于 AI 模型和向量存储。
- ChatClient API:与 AI 聊天模型通信的流式 API,用法类似于 WebClient 和 RestClient API。
- Advisors API:封装常见的生成式 AI 模式,转换发送至语言模型(LLM)和从语言模型返回的数据,并提供跨各种模型和用例的可移植性。
- 支持聊天对话记忆和检索增强生成(RAG)。
Spring AI 默认没有支持所有的大模型(尤其是国产的),更多的是支持兼容 OpenAI API 的大模型的集成,参考 官方的模型对比。因此,我们如果想要调用阿里系大模型(比如通义千问),推荐直接使用阿里自主封装的 Spring AI Alibaba 框架,它不仅能直接集成阿里系大模型,用起来更方便,而且与标准的 Spring AI 保持兼容。
可以参考下列官方文档,来跑通调用大模型的流程:
- 灵积(DashScope)模型接入指南:适用于接入灵积平台全系列模型,支持基础对话、流式调用、动态参数配置及结构化返回。
- 通义千问 QWQ 32B 模型接入指南:专注 QWQ 32B 模型接入,支持对话记忆、思维链输出,含专属 Advisor 配置示例。
spring:
application:
name: MaxAiAgent
profiles:
active: dev
ai:
dashscope:
api-key: ${spring.ai.dashscope.api-key}
chat:
options:
model: ${spring.ai.dashscope.chat.options.model}
server:
port: 8123
servlet:
context-path: /maxaiagent
# springdoc-openapi????
springdoc:
swagger-ui:
path: /swagger-ui.html
tags-sorter: alpha
operations-sorter: alpha
api-docs:
path: /v3/api-docs
group-configs:
- group: 'default'
paths-to-match: '/**'
packages-to-scan: com.lyf.maxaiagent.controller
knife4j:
enable: true
setting:
language: zh_cn
package com.lyf.maxaiagent.demo.invoke;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
@Component
public class SpringAiAiInvoke implements CommandLineRunner {
@Resource
private ChatModel dashscopeChatModel;
@Override
public void run(String... args) throws Exception {
AssistantMessage output = dashscopeChatModel.call(new Prompt("你好,我是贝贝"))
.getResult()
.getOutput();
System.out.println(output.getText());
}
}
上述代码实现了 CommandLineRunner 接口,我们启动 Spring Boot 项目时,会自动注入大模型 ChatModel 依赖,并且单次执行该类的 run 方法,达到测试的效果。
💡 上述代码中我们是通过 ChatModel 对象调用大模型,适合简单的对话场景。除了这种方式外,Spring AI 还提供了 ChatClient 调用方式,提供更多高级功能(比如会话记忆),适合复杂场景,在后续 AI 应用开发章节中会详细介绍。
4、LangChain4j
和 Spring AI 作用一样,LangChain4j 是一个专注于构建基于大语言模型(LLM)应用的 Java 框架,作为知名 AI 框架 LangChain 的 Java 版本,它提供了丰富的工具和抽象层,简化了与 LLM 的交互和应用开发。
LangChain 官方本身未提供阿里系大模型的原生支持,如需集成需使用社区版本的整合大模型包:langchain4j-community/tree/main/models。可在官方文档中查询完整的支持模型列表:LangChain4j 模型集成
要接入阿里云灵积模型,可参考官方集成文档:DashScope 模型集成,文档内提供了完整的依赖坐标和可直接运行的示例代码。
<dependencies>
<!-- 接入阿里云百炼平台 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<!--引入百炼依赖管理清单-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
package com.lyf.maxaiagent.demo.invoke;
import com.lyf.maxaiagent.util.TestApiKey;
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.model.chat.ChatLanguageModel;
public class LangChainAiInvoke {
public static void main(String[] args) {
ChatLanguageModel qwenModel = QwenChatModel.builder()
.apiKey(TestApiKey.API_KEY)
.modelName("qwen-max")
.build();
String answer = qwenModel.chat("我是超极笨");
System.out.println(answer);
}
}
5、接入方式对比
下面是四种方式对比情况:
4种AI大模型接入方式 优缺点对比 & 适用场景
| 接入方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| SDK 接入 | • 类型安全,支持编译时语法检查 • 官方封装完善的错误处理机制 • 配套详细的官方技术文档 • 底层做过针对性性能优化 | • 强依赖对应SDK的特定版本 • 引入SDK会增加项目打包体积 • 有开发语言的使用限制 | • 业务需要与大模型深度集成 • 项目仅对接单一模型提供商 • 生产环境对调用性能要求高 |
| HTTP 接入 | • 无开发语言限制,跨语言友好 • 不引入额外依赖包,轻量化 • 接口调用灵活性极高,无框架约束 | • 需要手动编写代码处理各类异常错误 • 请求/响应的序列化、反序列化需手动实现 • 接口调用相关代码偏冗长繁琐 | • 项目开发语言无对应官方SDK支持 • 简单的功能原型验证、快速试错 • 临时性的小功能模块集成大模型 |
| Spring AI | • 提供统一的抽象调用接口,规范统一 • 极低成本无缝切换不同模型提供商 • 与Spring生态完美融合,开箱即用 • 内置RAG、工具调用等高级AI能力 | • 多一层框架抽象层,有少量性能损耗 • 部分小众/专属模型特性可能不支持 • 框架版本迭代较快,部分特性兼容性待完善 | • 基于Spring/SpringBoot的Java项目 • 业务需要兼容、切换多种大模型 • 开发中需用到RAG、知识库等高级AI功能 |
| LangChain4j | • 提供完整的AI应用开发工具链 • 原生支持复杂的AI业务工作流编排 • 组件/工具生态丰富,开箱即用 • 极致适配AI代理、智能体类场景开发 | • 框架体系复杂,学习曲线较陡峭 • 部分细分功能的文档相对偏少 • 多层抽象封装会引入一定性能开销 | • 构建复杂的企业级AI应用系统 • 业务需要多步链式调用的场景 • RAG知识库、智能体、多工具组合类开发 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)