复刻10W+爆款视频!我用Coze搭了个“人物故事”自动流水线,太香了!
大家好!我是小肥肠,专注AI智能体干货教程分享,今天给大家带来的教程是基于Coze工作流一键生成人物故事视频感兴趣就速度码住跟练哦~
大家好!我是小肥肠,专注AI智能体干货教程分享,今天给大家带来的教程是基于Coze工作流一键生成人物故事视频感兴趣就速度码住跟练哦~
目录
1. 前言
最近人物故事视频流量不错,社群里的群友问Coze工作流能不能做?我去看了一下视频号上的原视频(点赞10w+,转发10w+,小心心10w+),制作方式就是简单的图片,字幕时间线稍作合并处理后进行素材拼接:
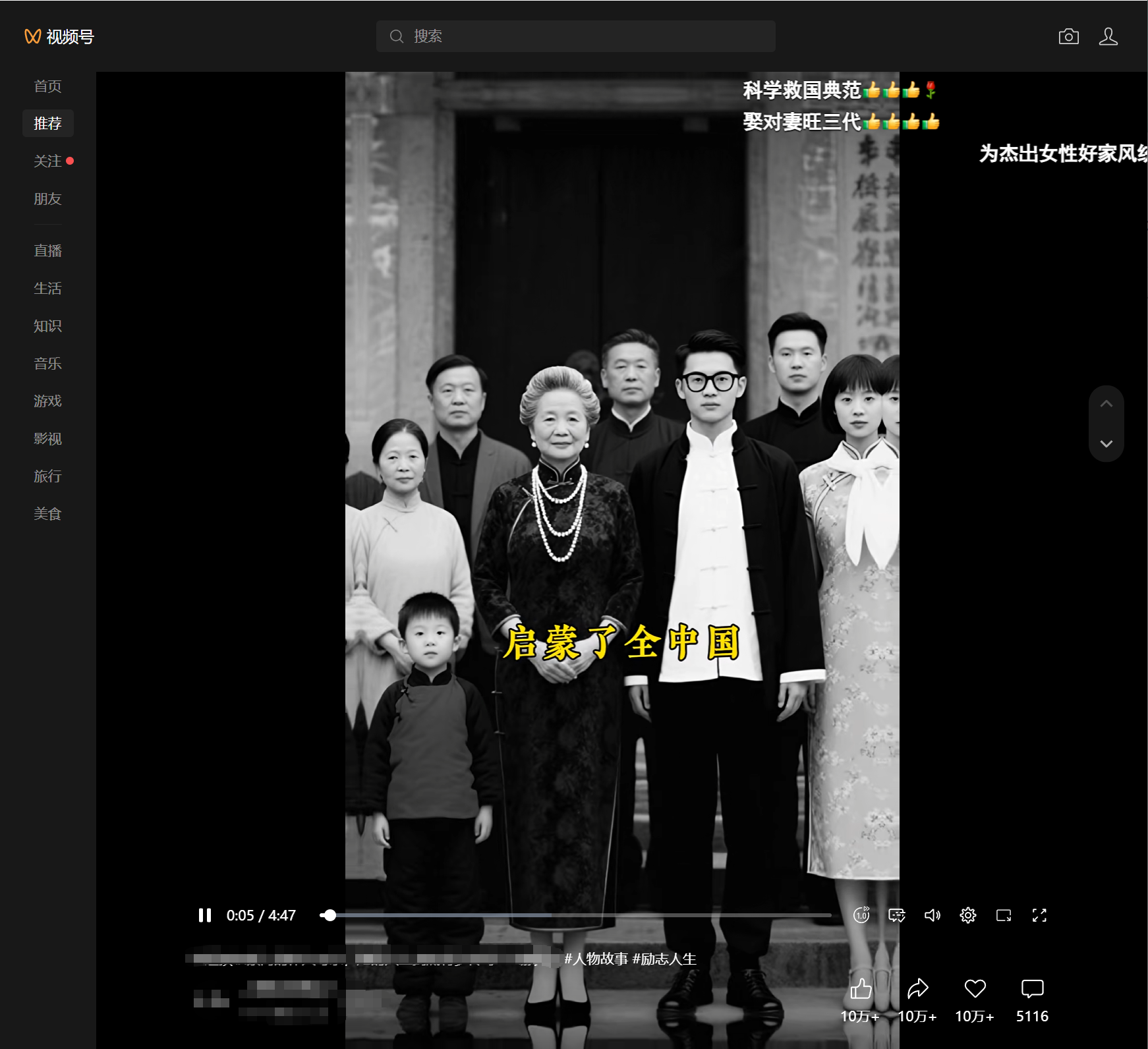
这类视频现在流量不错,关键可以开通橱窗,从下图中可以看出同类视频的橱窗公开数据也很不错(示例数据,非本人实际收益):
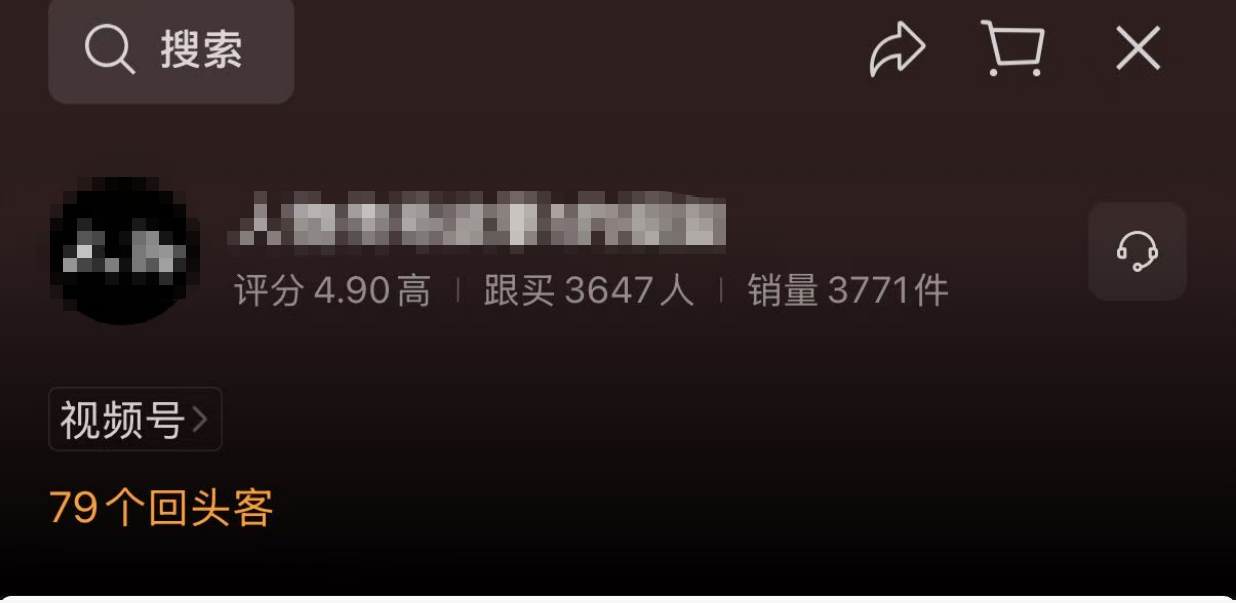
心动不如行动,我昨晚带着群友连夜实现了这个工作流:
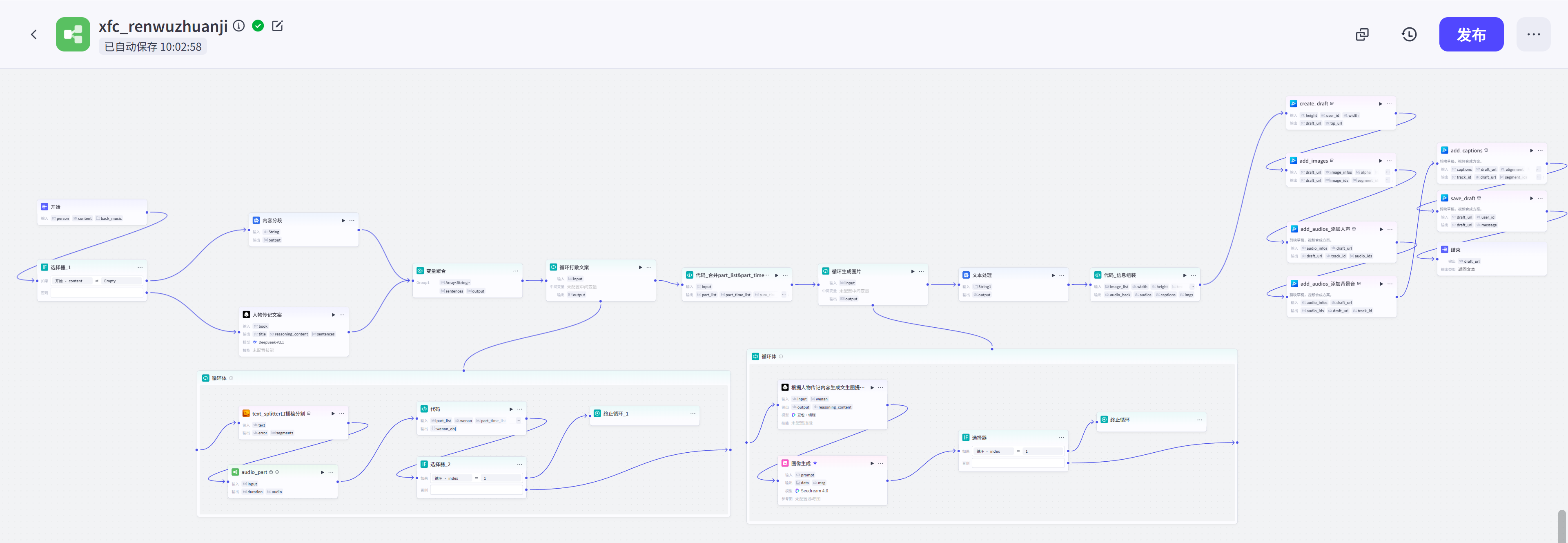
工作流的使用方法很简单,只需要在开始节点输入人名,自定义文案(非必填),背景音乐,等待几分钟即可获得剪映草稿:
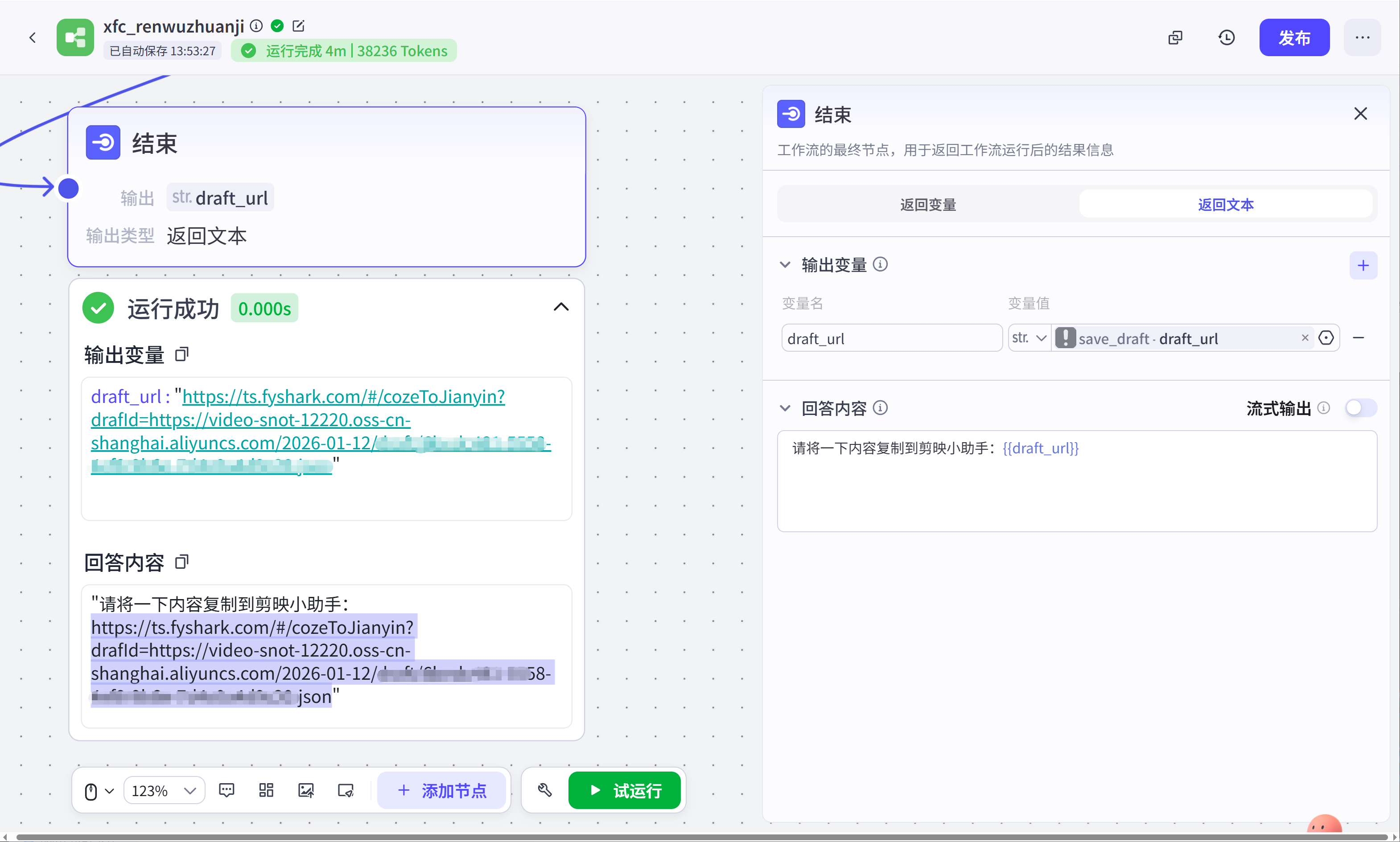
我们所要做的只是将其导入到剪映中即可获得完整视频(我做了前几个分段,主做展示使用):
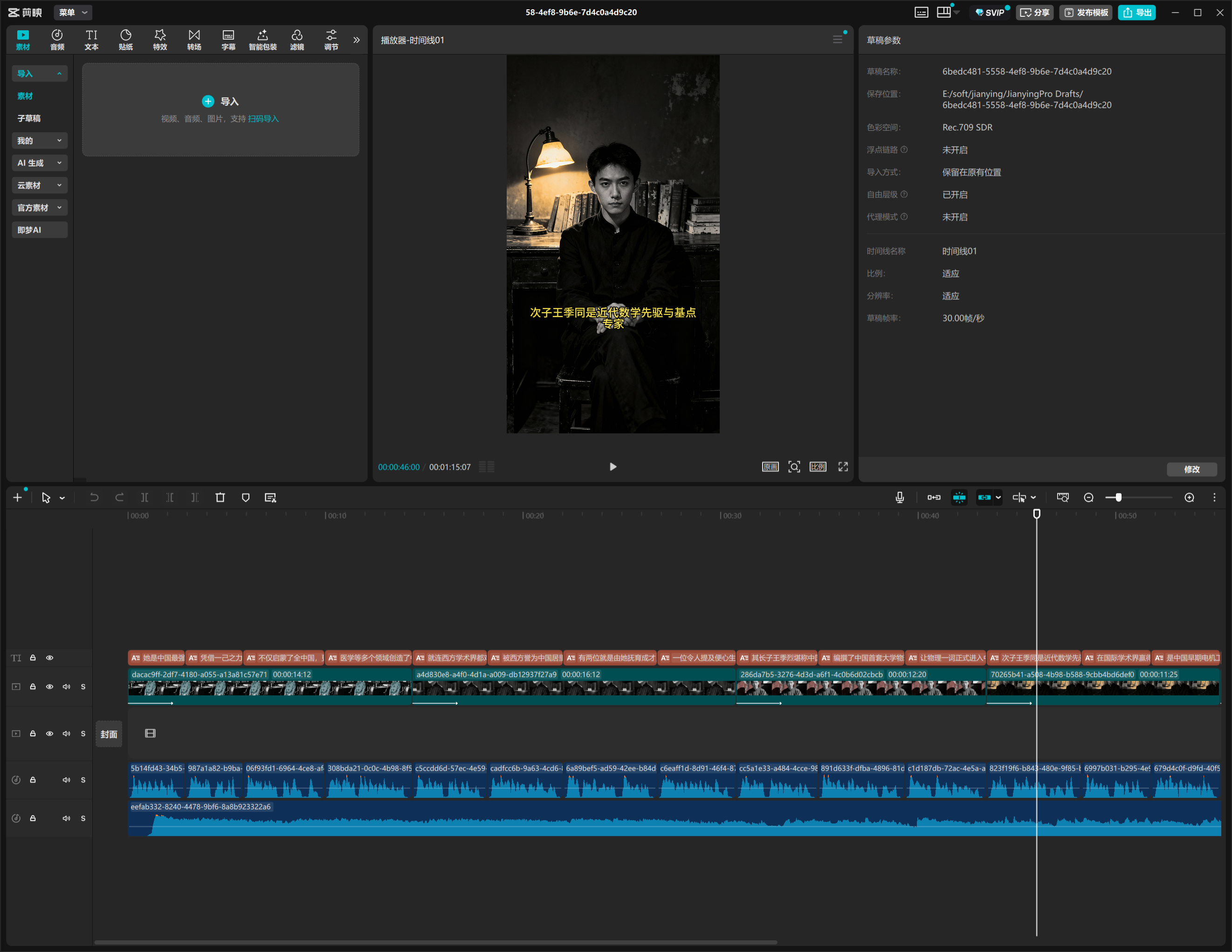
成品视频:

2. 工作流搭建
完整工作流如下图,接下来就给大家依次拆解工作流每个节点的作用。
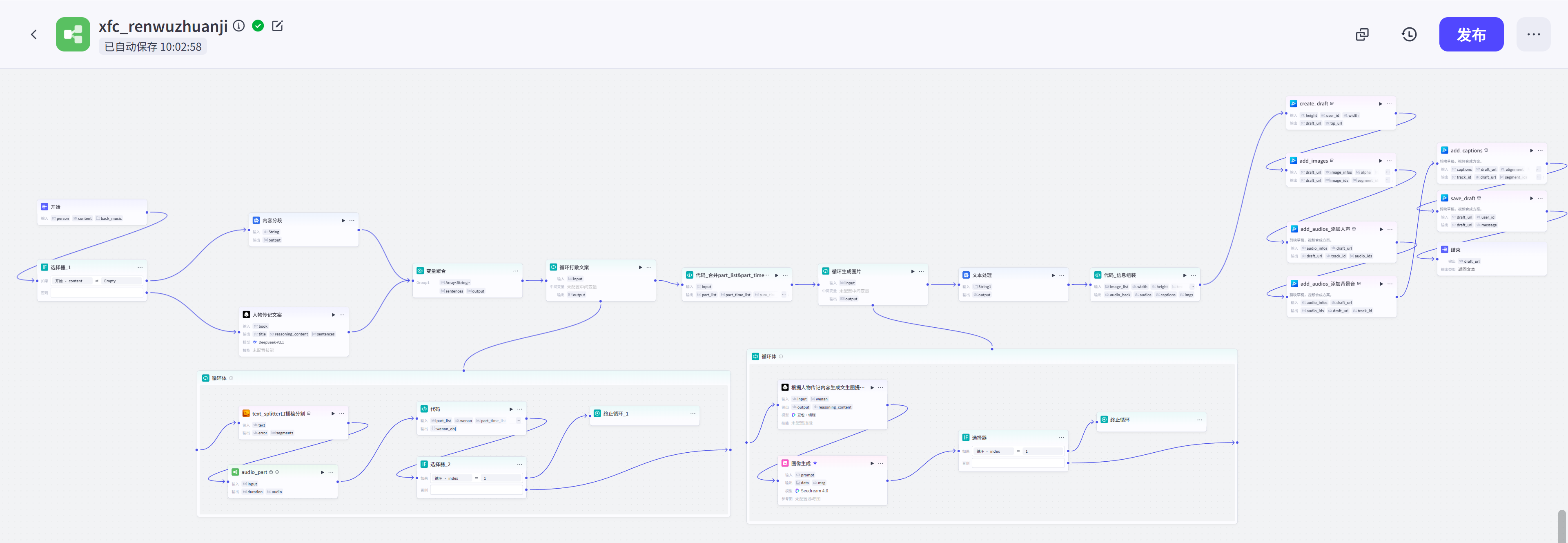
本工作流的构建方式可以整理为以下步骤:
1. 输入人物名称,输入文案(可选),上传背景音乐
2. 判断用户是否输入了文案,如已经上传了文案就对文案进行分段成为文案列表,若没有上传文案则由大模型自主生成视频文案列表
3. 对文案列表进行拆分,时间线合并处理操作
4. 基于文案生成视频配音,获取配音时间线
5. 基于文案生成文生图提示词,生成图片
6. 利用代码将配音,图片,背景音乐,文案字幕整理为剪映小助手需要的格式
7. 创建剪映草稿,将字幕、配音,图片、背景音乐添加到剪映草稿
话不多说正式开始工作流拆解。
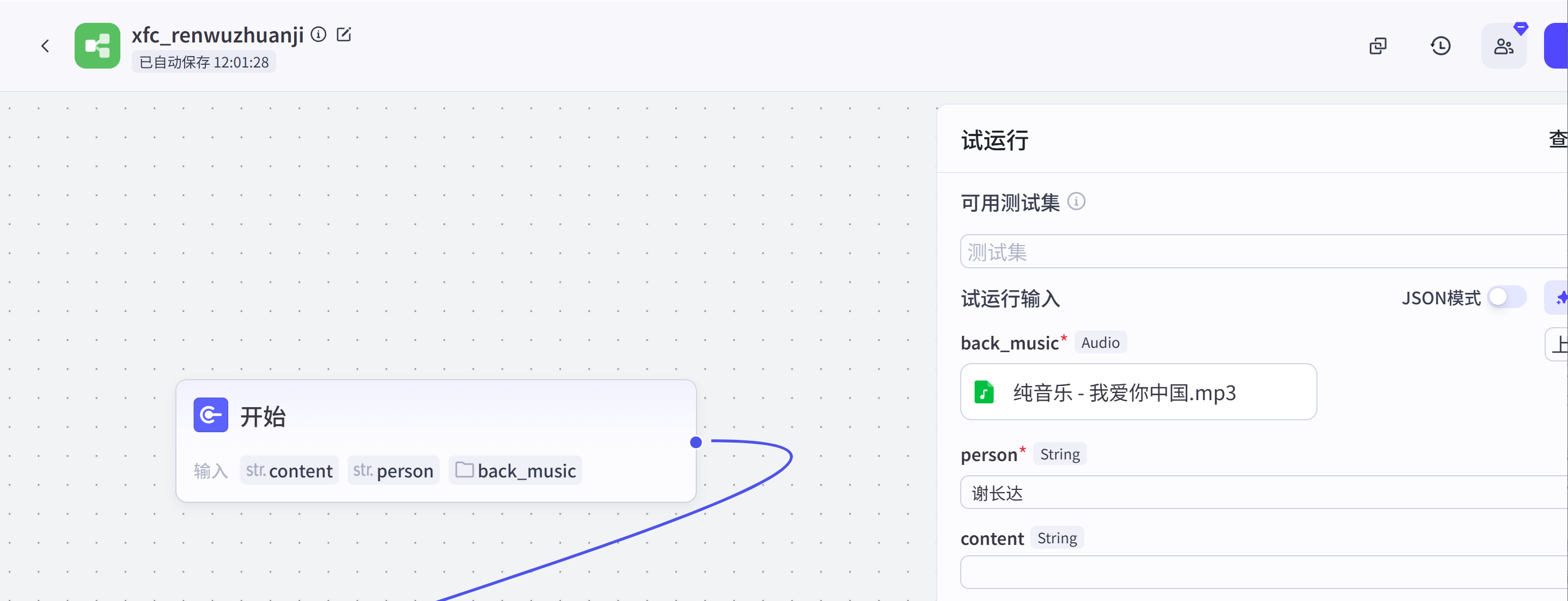
开始节点:开始节点传入的参数主要有back_music文件(.MP3),person(人物名字),content(视频文案,如果你想自定义文案可以直接传入)。
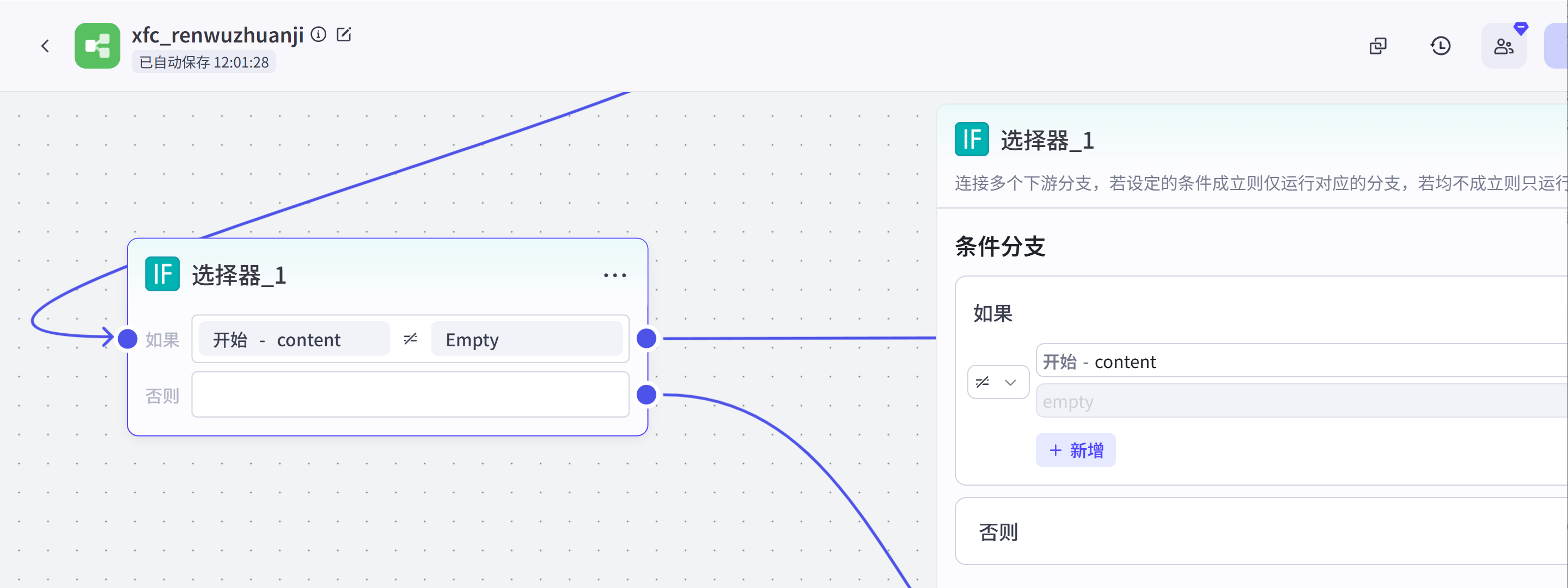
选择器:这个节点位于开始节点后,接收开始节点传入的content,判断content是否为空,若为空则调用下游大模型节点创建视频文案,否则基于文本处理节点对文案内容进行分段。
内容分段:这是一个文本处理节点,它的作用是基于句号对用户输入的文案进行分隔,成为字符串数组。
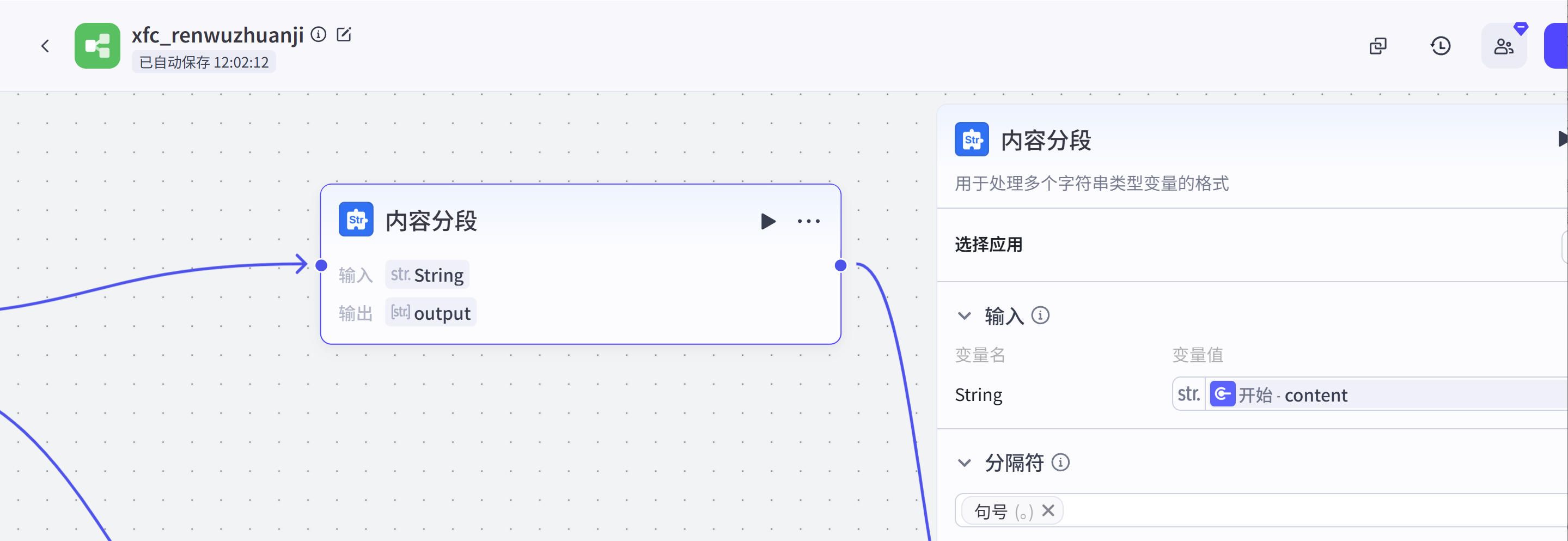
以防小白不理解,我这边做一个说明,节点输入:
句子1。句子2。句子3。经过内容分段节点处理后,节点输出:
[
句子1,
句子2,
句子3
]人物传记(大模型):这是一个大模型节点,它的作用是基于开始节点传入的人名来生成人物故事视频文案,采用了DeepSeekV3.2大模型,注意在技能处要加一下搜索插件,这样出来的文案更贴实际。
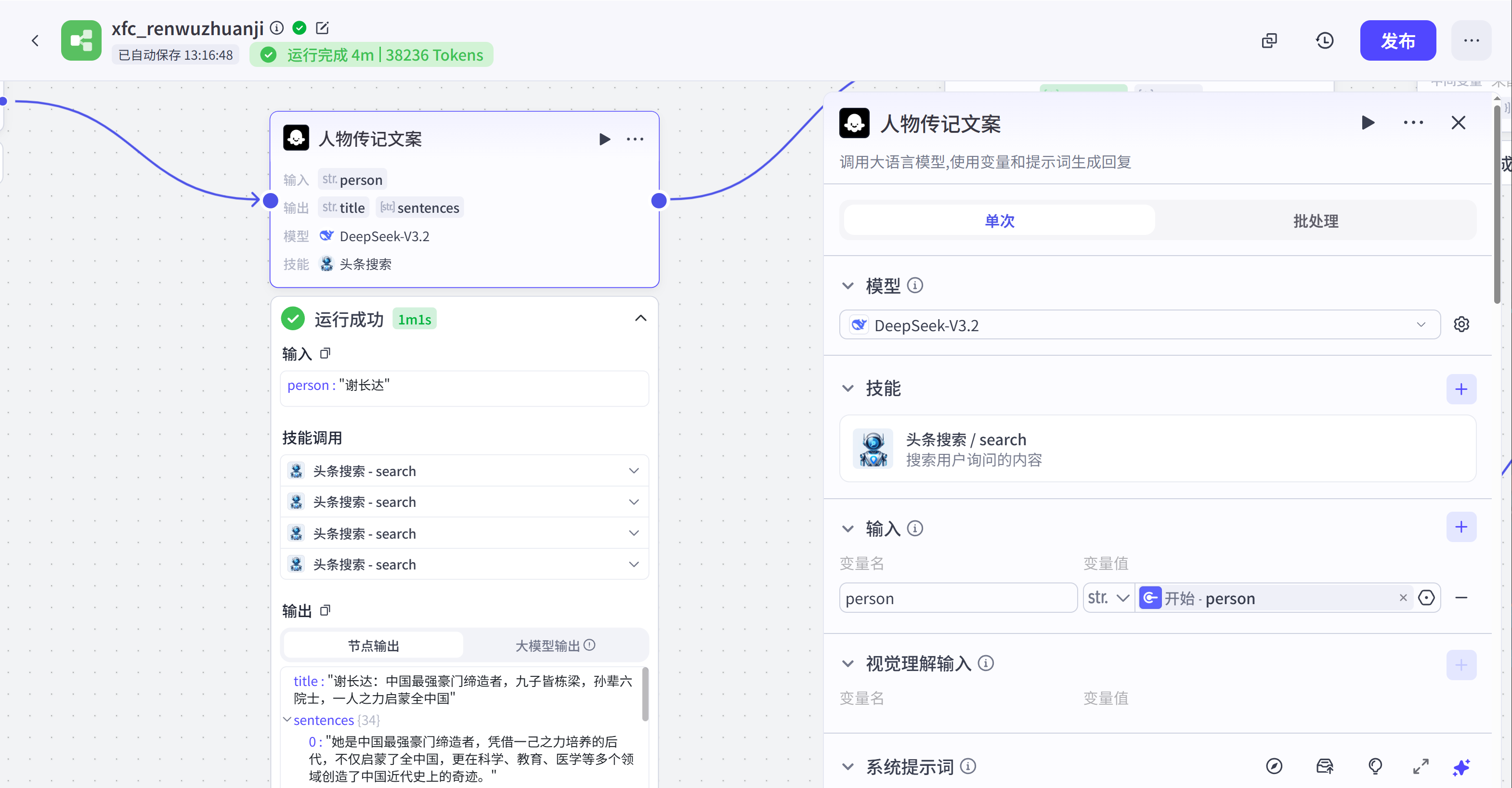
提示词编写思路(把一下思路投喂给豆包来生成提示词):
根据人物名称调用搜索插件区互联网搜索人物的生平事迹,按以下格式编写自传:
1. 利用搜索工具搜索人物的生平事迹
2. 编写文案,根据开通,成就叙事。深挖内核,主题神话的结构来编写视频文案
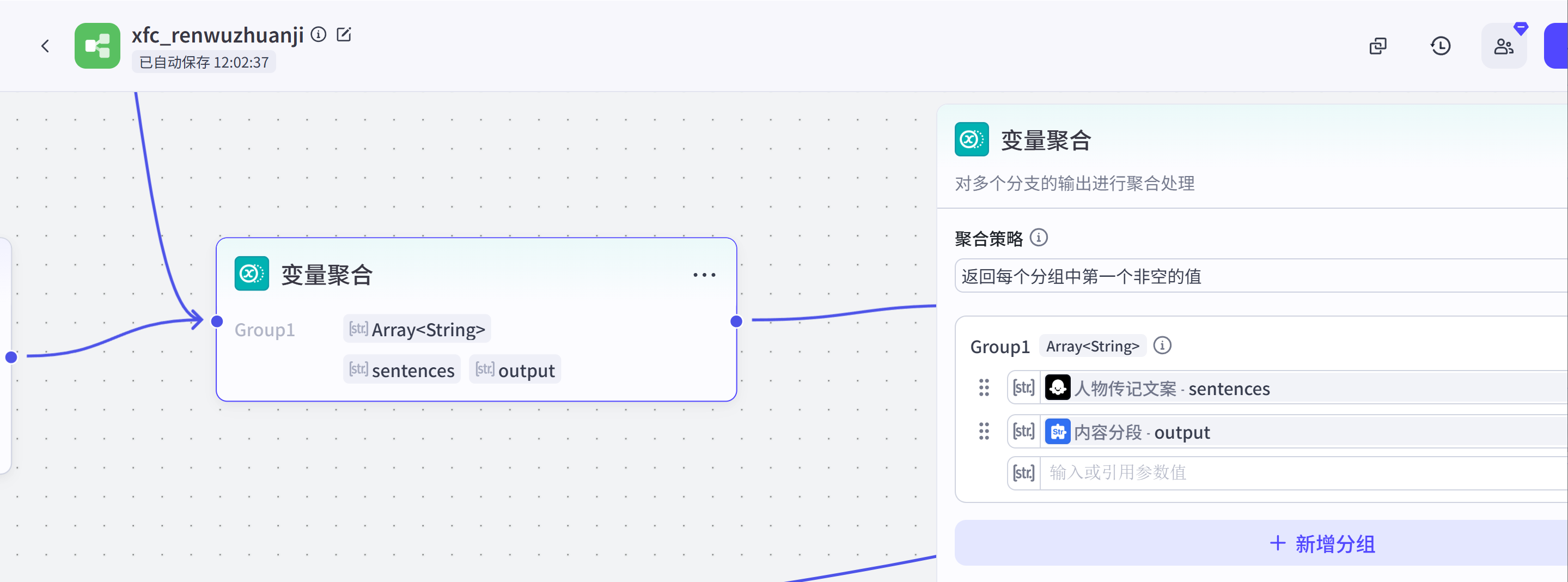
4. 不要出现语病,夸大事实等硬伤错误变量聚合:这个节点作用是取出最终版本的视频文案。
循环文案打散:前置人物传记(大模型)节点生成的文案列表中,一句话占用的时间比较长,我们要将它进行一个打散的操作,然后统计每个小文案片段的时长,求取他们的时间游标,为后续添加到剪映草稿做前置准备。
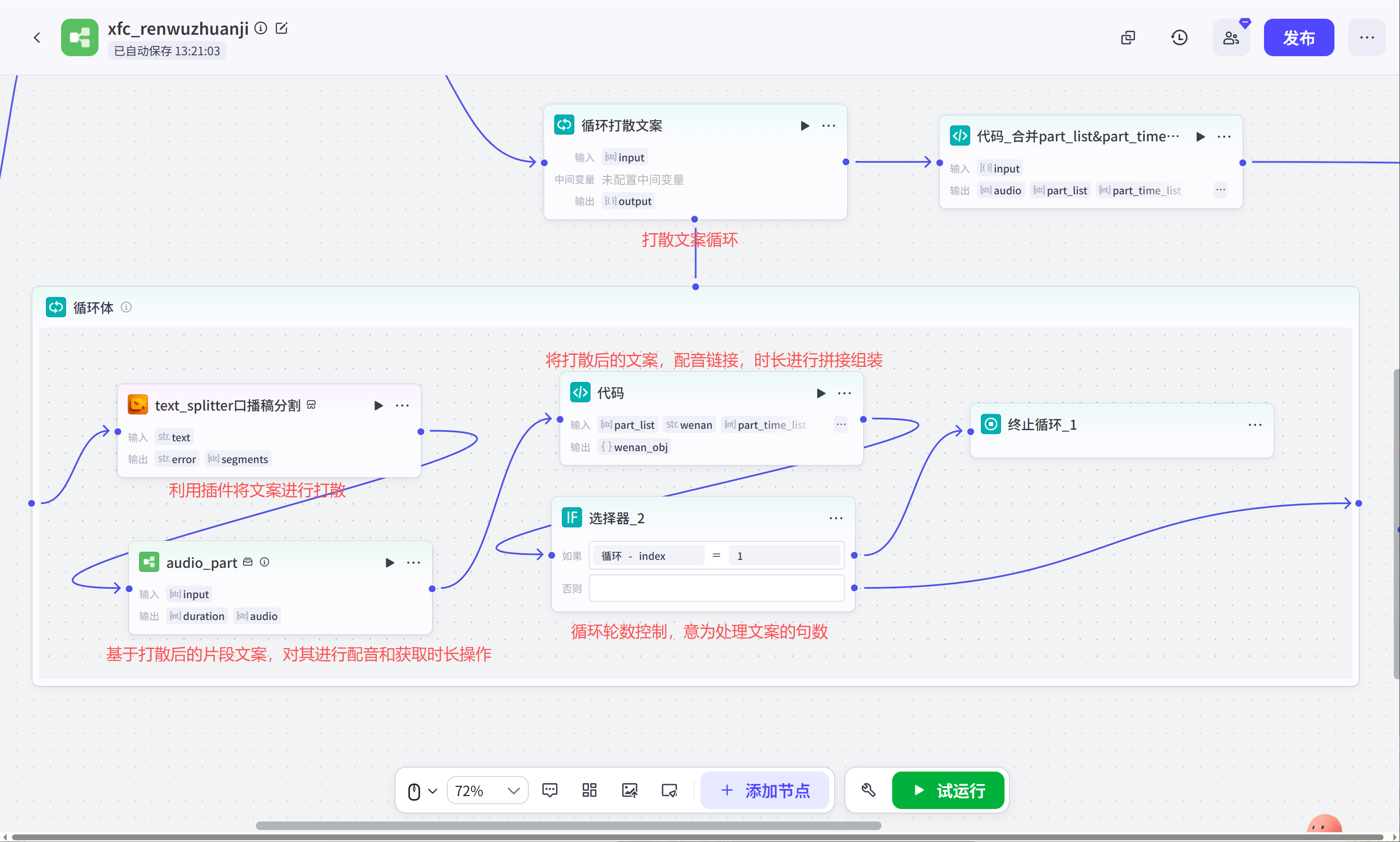
audio_part(文案配音与获取时长子工作流):这个工作流主要是处理基于text_splitter口播稿分割打散后的文案进行配音和获取配音时长操作。
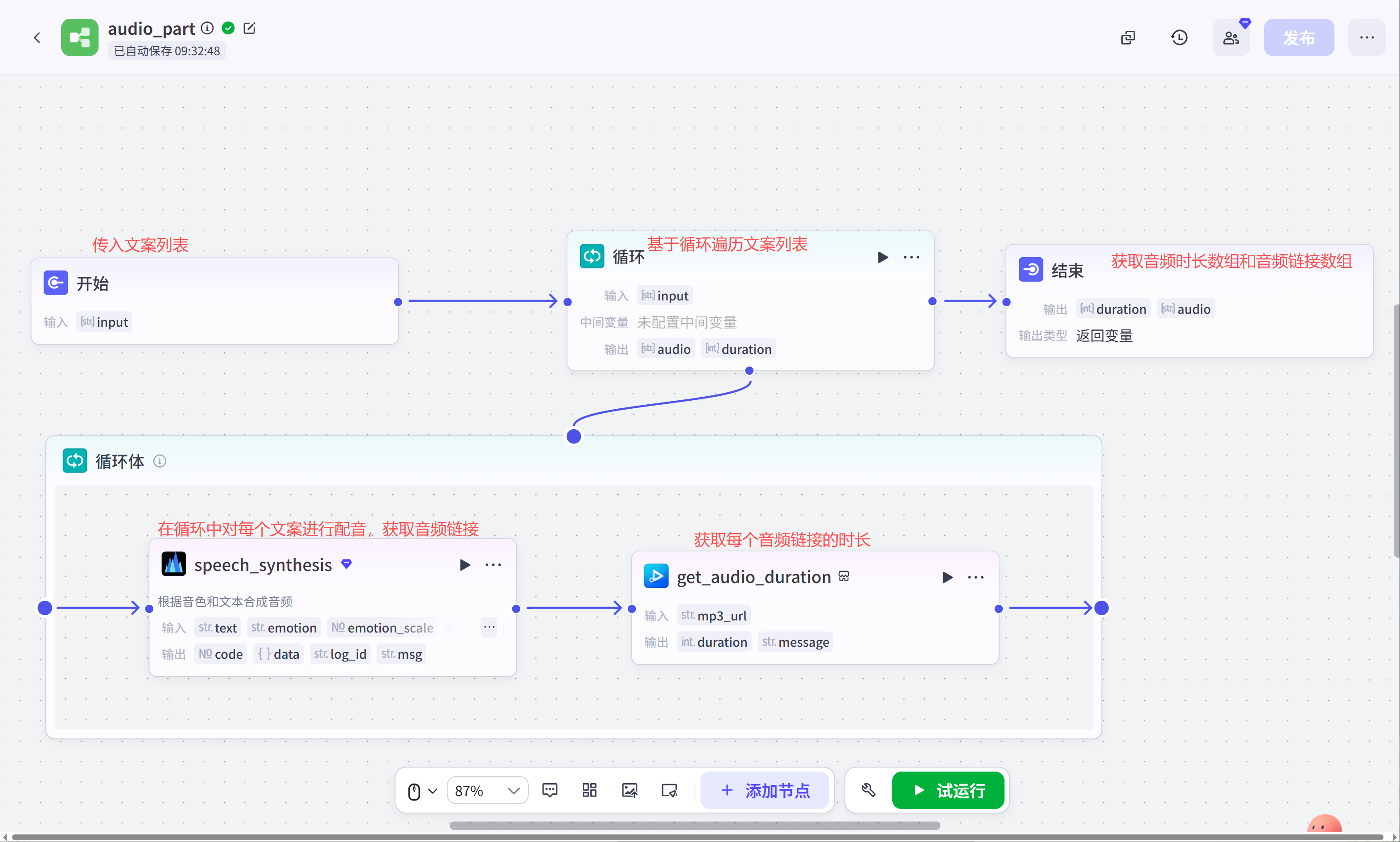
代码(合并打散后的音频、文案、音频时间线):在循环文案打散环节,我们将文案进行了打散操作,现在还要将其拼接为对应的属性数组方便后续进行文生图和组装为剪映草稿数据的操作。
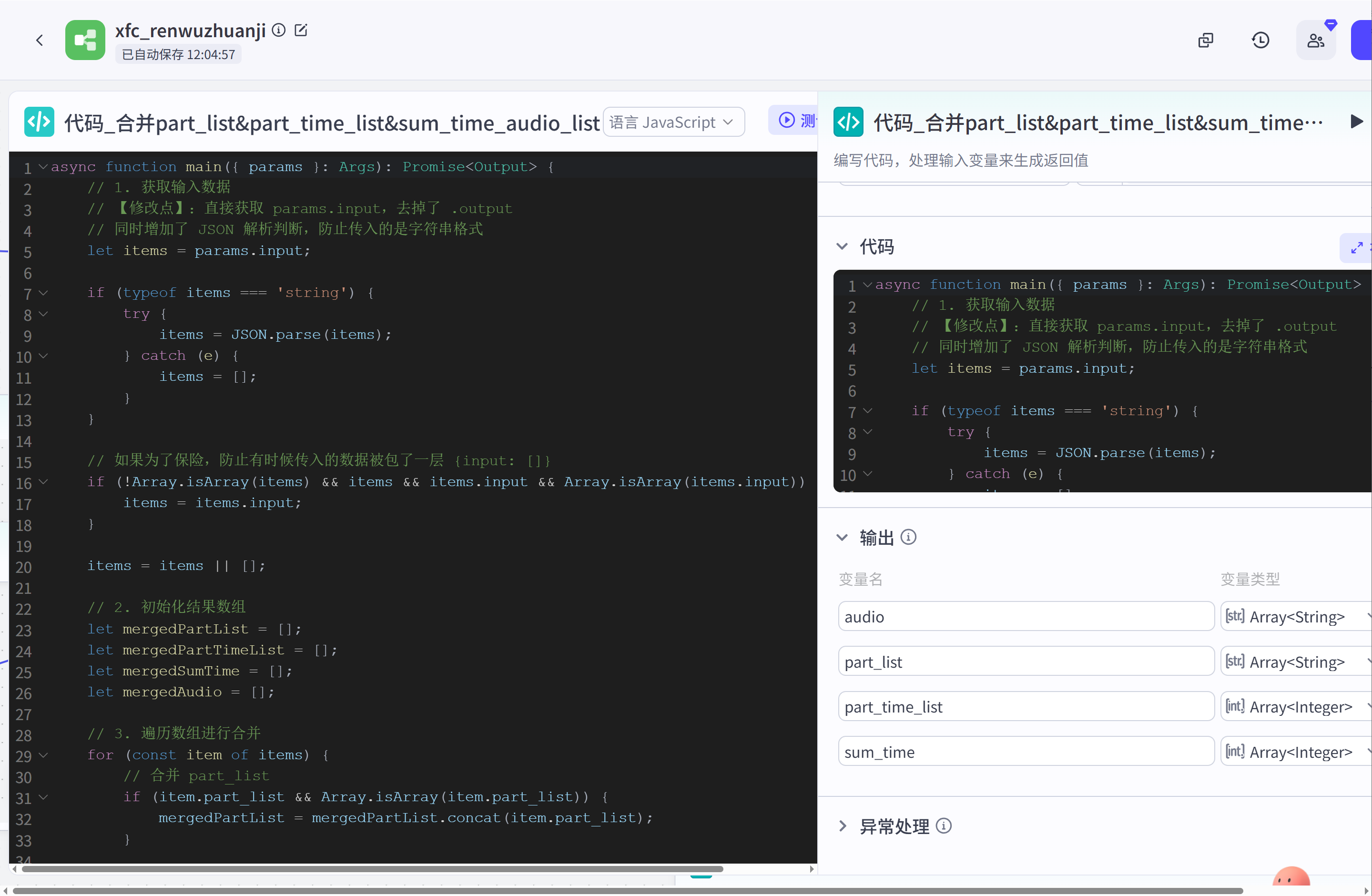
以防小白不懂,这里列举一下输入和输出节点的数据示例,节点输入:
{
"audio_list": [
"https://lf3-appstore-sign.oceancloudapi.com/ocean-cloud-tos/VolcanoUserVoice/speech_7426725529589628955_eba04d02-ca0a-453e-be97-2e063d8049a5.mp3?lk3s=da27ec82&x-expires=1768453983&x-signature=7kS%2BQUTS5xUxecMmMEMswjl4vLs%3D",
"https://lf6-appstore-sign.oceancloudapi.com/ocean-cloud-tos/VolcanoUserVoice/speech_7426725529589628955_d51cf1e3-b6e0-4d82-b4a0-b8a2a7c386f6.mp3?lk3s=da27ec82&x-expires=1768453984&x-signature=4jhmAhvehNqD3tnBgoV83K4PCI0%3D",
"https://lf3-appstore-sign.oceancloudapi.com/ocean-cloud-tos/VolcanoUserVoice/speech_7426725529589628955_c4514ed9-a5d1-4a52-9060-70a5dfa72251.mp3?lk3s=da27ec82&x-expires=1768453986&x-signature=DirWU3cdxKx8Ja62xURNqbynIE0%3D",
"https://lf6-appstore-sign.oceancloudapi.com/ocean-cloud-tos/VolcanoUserVoice/speech_7426725529589628955_b55d24f3-b331-4585-b29d-43afe6a5d216.mp3?lk3s=da27ec82&x-expires=1768453987&x-signature=NFEGzbLoWR5UeBvrXCiL2UzU45M%3D"
],
"part_list": [
"她是中国最强豪门缔造者",
"凭借一己之力培养的后代",
"不仅启蒙了全中国,更在科学、教育",
"医学等多个领域创造了中国近代史上的奇迹"
],
"part_time_list": [
2880000,
2928000,
4152000,
4416000
],
"sum_time": 14376000,
"wenan": "她是中国最强豪门缔造者,凭借一己之力培养的后代,不仅启蒙了全中国,更在科学、教育、医学等多个领域创造了中国近代史上的奇迹。"
}经过代码节点处理后,输出为:
{
"part_list": [
"她是中国最强豪门缔造者",
"凭借一己之力培养的后代",
"不仅启蒙了全中国,更在科学、教育",
"医学等多个领域创造了中国近代史上的奇迹"
],
"part_time_list": [
2880000,
2928000,
4152000,
4416000
],
"sum_time": [
14376000
],
"audio": [
"https://lf3-appstore-sign.oceancloudapi.com/ocean-cloud-tos/VolcanoUserVoice/speech_7426725529589628955_eba04d02-ca0a-453e-be97-2e063d8049a5.mp3?lk3s=da27ec82&x-expires=1768453983&x-signature=7kS%2BQUTS5xUxecMmMEMswjl4vLs%3D",
"https://lf6-appstore-sign.oceancloudapi.com/ocean-cloud-tos/VolcanoUserVoice/speech_7426725529589628955_d51cf1e3-b6e0-4d82-b4a0-b8a2a7c386f6.mp3?lk3s=da27ec82&x-expires=1768453984&x-signature=4jhmAhvehNqD3tnBgoV83K4PCI0%3D",
"https://lf3-appstore-sign.oceancloudapi.com/ocean-cloud-tos/VolcanoUserVoice/speech_7426725529589628955_c4514ed9-a5d1-4a52-9060-70a5dfa72251.mp3?lk3s=da27ec82&x-expires=1768453986&x-signature=DirWU3cdxKx8Ja62xURNqbynIE0%3D",
"https://lf6-appstore-sign.oceancloudapi.com/ocean-cloud-tos/VolcanoUserVoice/speech_7426725529589628955_b55d24f3-b331-4585-b29d-43afe6a5d216.mp3?lk3s=da27ec82&x-expires=1768453987&x-signature=NFEGzbLoWR5UeBvrXCiL2UzU45M%3D"
]
}循环生图:这个节点的操作是基于前置生成的文案列表(part_list)来进行文生图操作。
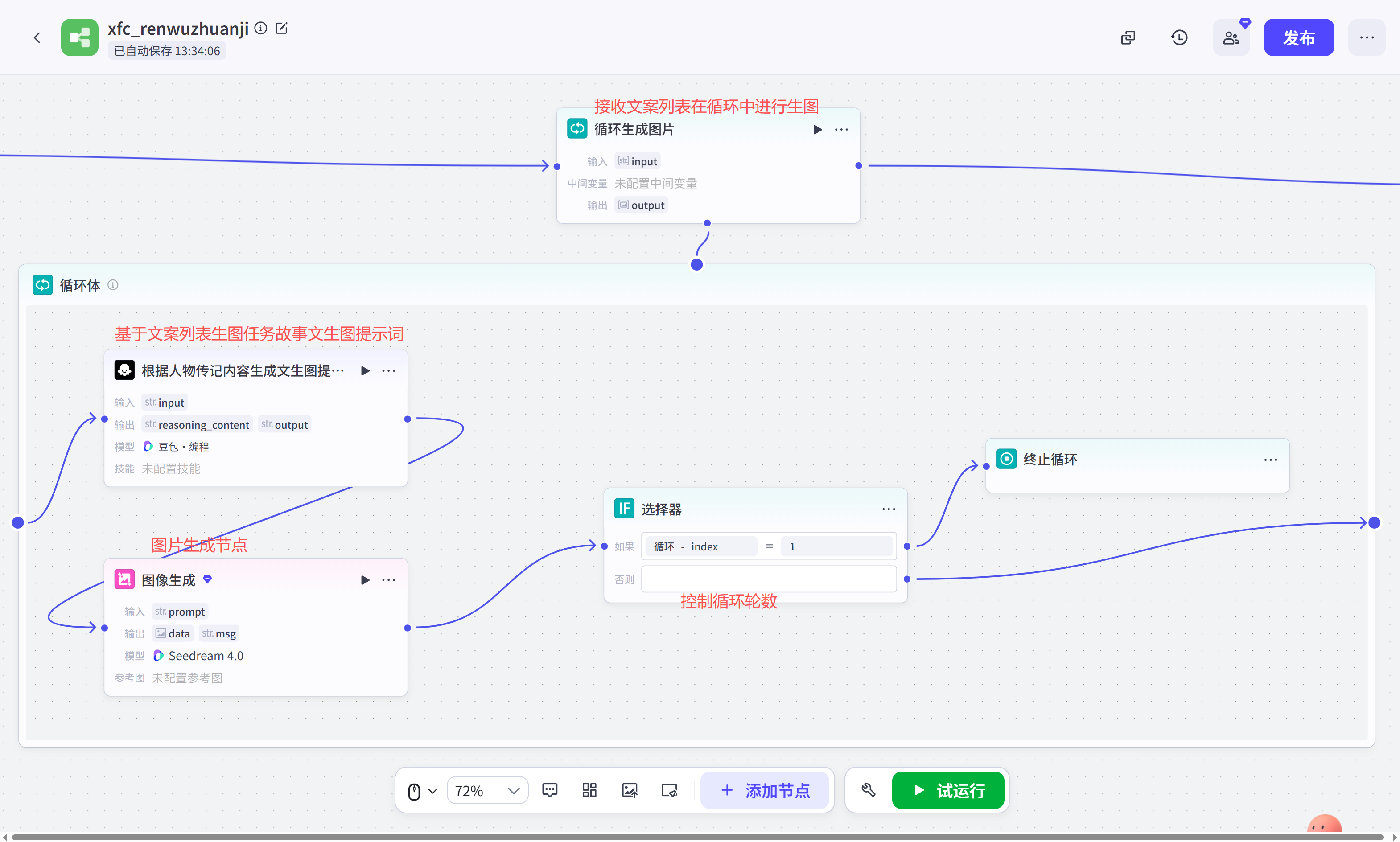
循环生图—根据人物传记内容生成文生图提示词(大模型):这是一个大模型节点,采用豆包编程模型,它的核心是根据传入的文案来生成人物故事文生图提示词。
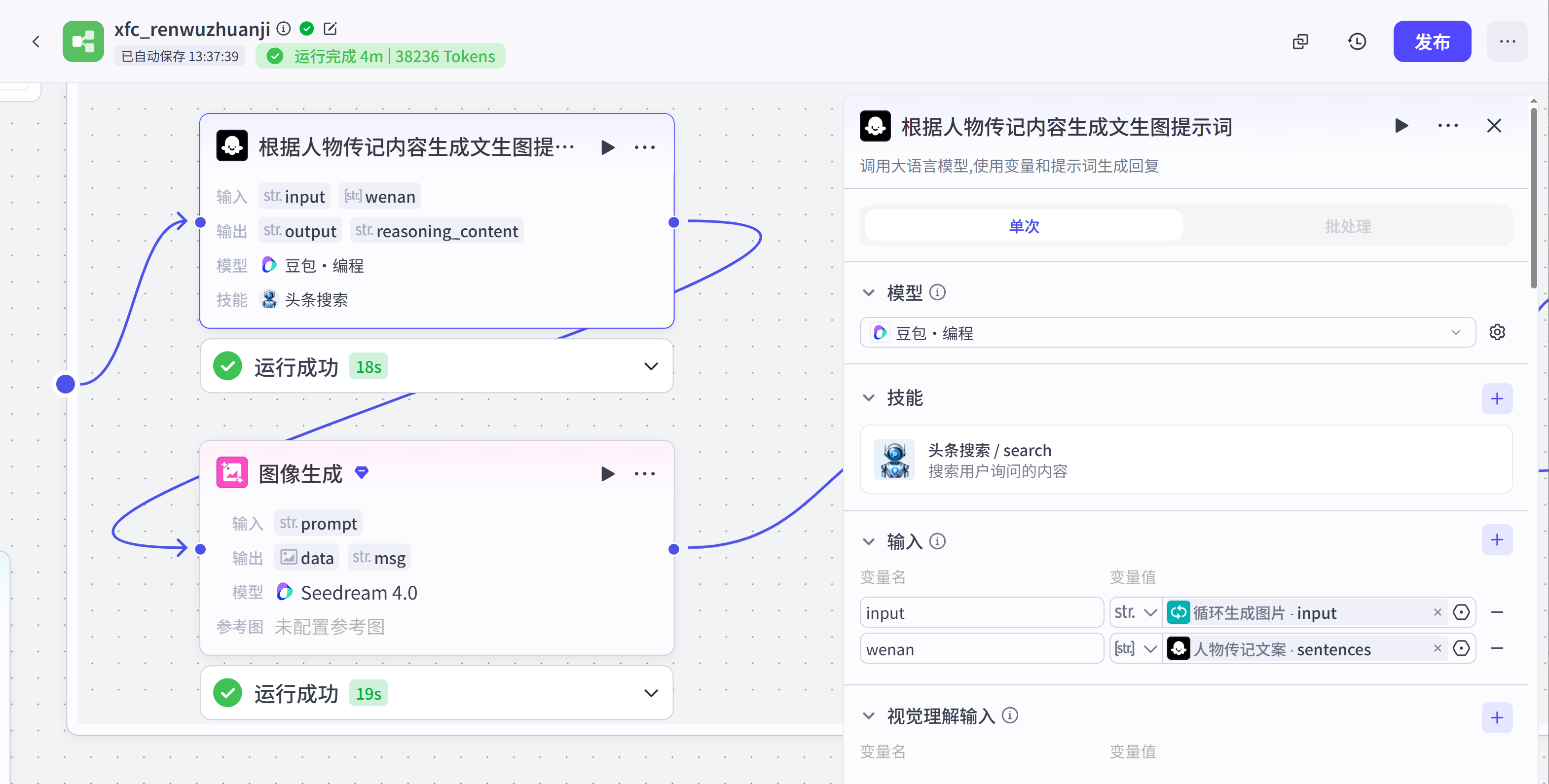
提示词编写思路(把一下思路投喂给豆包来生成提示词):
你是一名经典人像摄影师,擅长拍摄干净、庄重、高画质的黑白肖像。
你的核心任务是:根据全篇文案 (wenan)理解人物身份与气质,结合片段文案 (input) 描绘具体动作与画面。
视觉红线:无论剧情多么跌宕,画面必须保持影楼级的洁净感。严禁生成任何斑点、噪点、脏痕或过度的皮肤瑕疵。循环生图—图像生成:这是扣子内置的图像生成节点,模型采用Seedream4.0模型,绘制比例采用9:16,绘图提示词采用循环生图—根据人物传记内容生成文生图提示词(大模型)输出的文生图提示词。
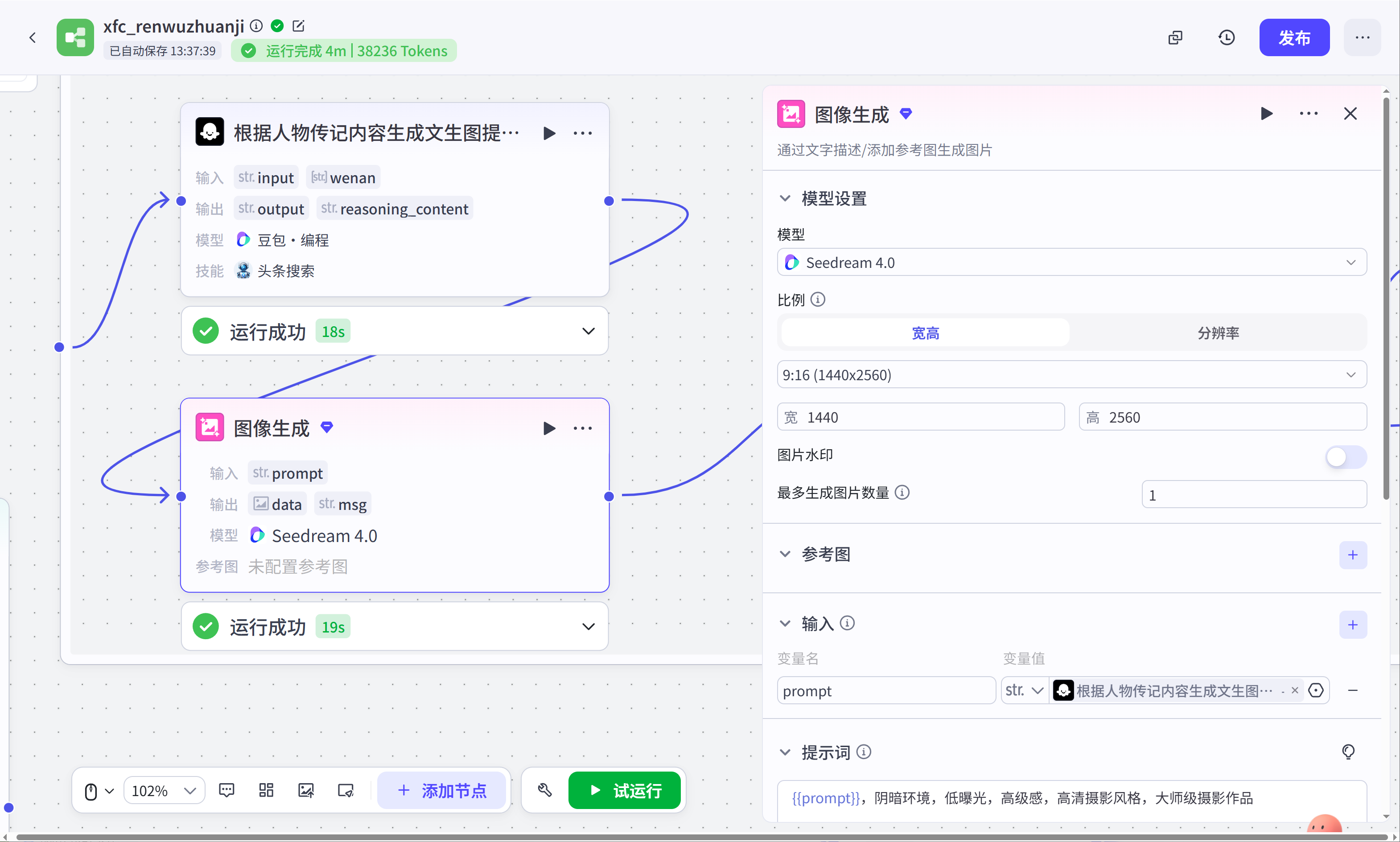
文本处理(获取背景音乐链接):这个节点是文本处理节点,它的功能是根据开始节点上传的.mp3背景音乐提取音乐文件链接地址。
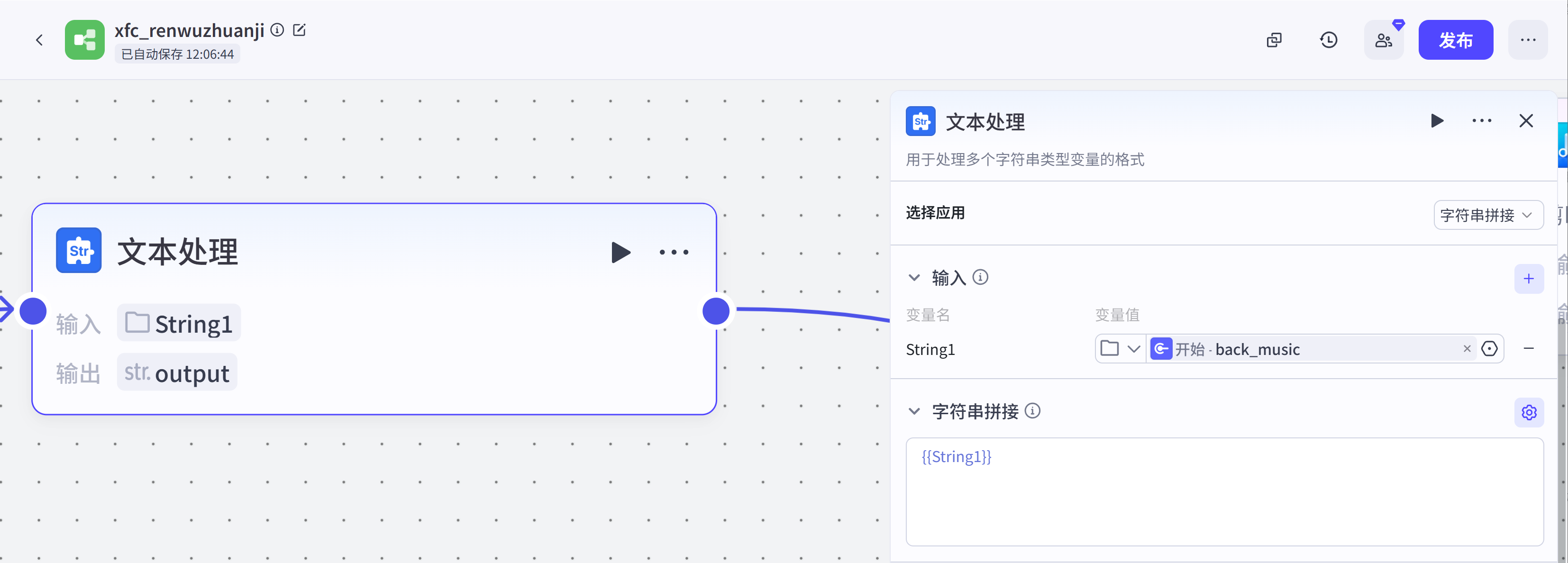
信息组装代码:在前置节点中我们生成了图片,背景音乐,配音,字幕这几个视频要素,该节点就是将前置生成的视频要素进行数组格式规整,成为视频剪映小助手需要的格式。这一步也可以用插件节点来实现,看你自己。
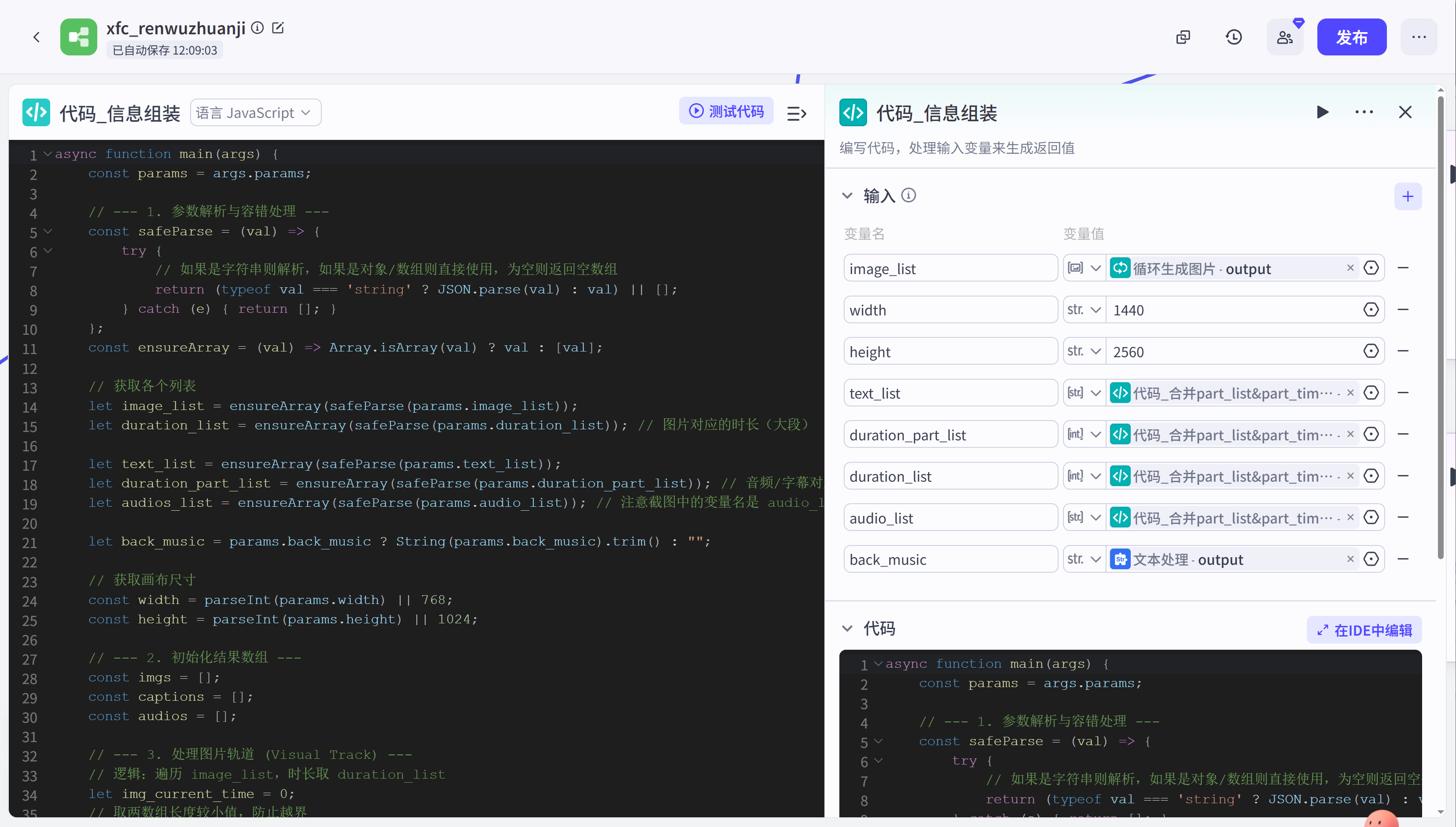
create_draft:这是剪映小助手插件,用于创建剪映空草稿。
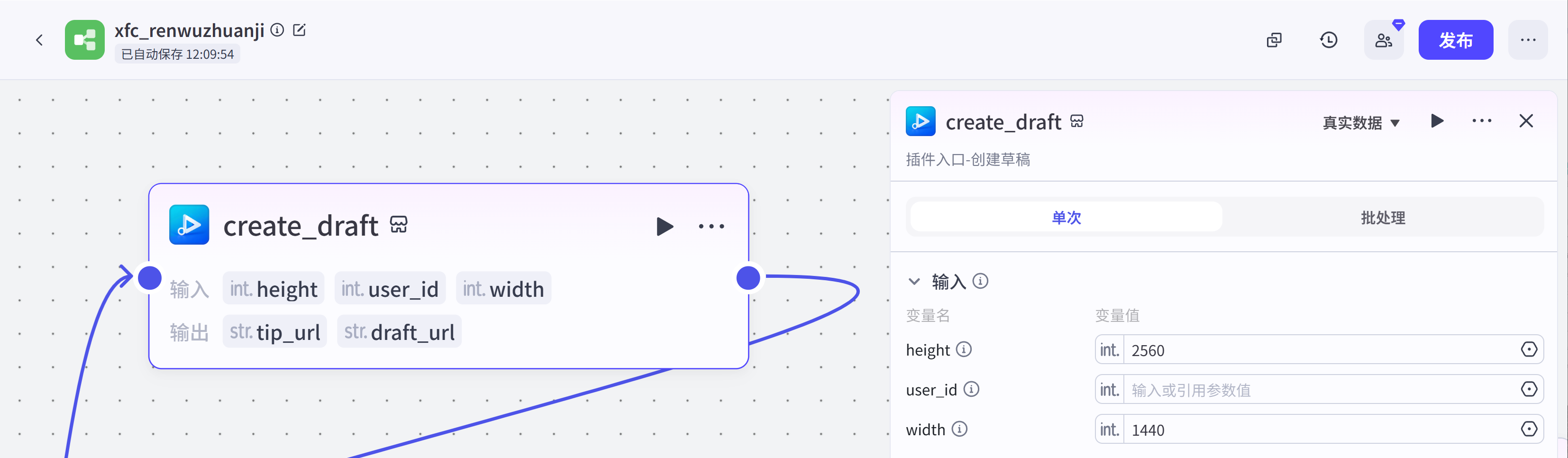
add_images:这是剪映小助手插件,用于在空草稿中添加图片。
add_audios_添加人声:这是剪映小助手插件,用于在空草稿中添加人声解说。
add_audios_添加背景音:这是剪映小助手插件,用于在空草稿中添加背景音乐。
add_captions:这是剪映小助手插件,用于在空草稿中添加字幕。
save_draft:这是剪映小助手插件,用于保存草稿。
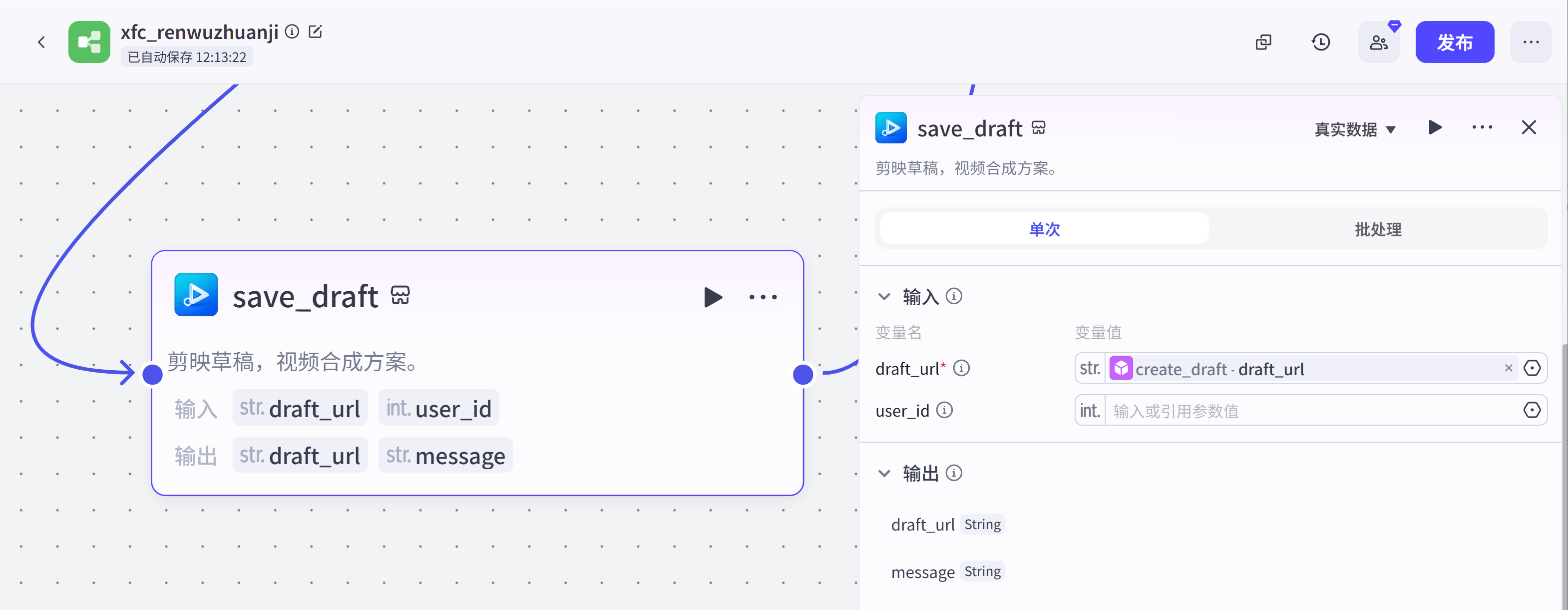
结束节点:结束节点接收的是save_draft节点输出的剪映草稿,可用于合成最终视频。
以上就是整个工作流的完整流程拆解,动手能力强的读者可以跟着教程实践一遍。上述工作流已经被收录到了小肥肠共学群中,需要原件可以加入社群直接使用哦。
3. 结语
通过这个 Coze + 剪映 的自动化工作流,我们成功将原本需要耗费数小时的文案撰写、素材搜寻、配音对轨、剪辑合成全流程,压缩到了短短几分钟。这不仅极大地降低了中视频、短视频的制作门槛,更重要的是实现了高质量内容的批量化生产。
如本次分享对你有帮助,麻烦一键三连支持一下小肥肠,我们下期再见~


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)