μP神话破灭!复旦邱锡鹏团队推翻OpenAI关键理论,大模型学习率设置有了新公式
在大模型预训练这一高成本系统工程中,Batch Size(批大小)与 Learning Rate(学习率)的设定,直接影响训练效率与模型性能。它们如同赛车的动力与操控:Batch Size 决定每次迭代处理的数据量,影响训练速度与稳定性;Learning Rate 则控制模型参数更新的步幅,关乎收敛效果与最终性能。长期以来,行业普遍依赖两大经典理论指导超参设置:然而,随着 WSD(热身‑稳定‑衰减
在大模型预训练这一高成本系统工程中,Batch Size(批大小)与 Learning Rate(学习率)的设定,直接影响训练效率与模型性能。它们如同赛车的动力与操控:Batch Size 决定每次迭代处理的数据量,影响训练速度与稳定性;Learning Rate 则控制模型参数更新的步幅,关乎收敛效果与最终性能。
长期以来,行业普遍依赖两大经典理论指导超参设置:
- OpenAI 的 Critical Batch Size 理论:基于梯度噪声尺度确定最佳批大小;
- 微软的 μP(最大更新参数化):通过参数化方法,试图将小模型上的最优超参迁移至大模型。
然而,随着 WSD(热身‑稳定‑衰减)调度器 与 MoE(混合专家)架构 逐渐成为主流训练配置,传统方法在新环境下的适用性正面临显著挑战。
近期,复旦大学邱锡鹏教授团队与上海人工智能实验室合作,发表两篇实证研究论文,分别对 Batch Size 与 Learning Rate 展开大规模实验分析,提出了适配现代预训练范式的 Scaling Laws。研究不仅揭示了原有理论在 WSD 模式下的局限,更进一步给出了具体的计算公式与可操作的配置策略,让超参设置摆脱经验依赖,走向系统化与可复现。
这一工作为未来大模型的高效训练提供了重要依据,也为超参数调整奠定了新的理论基础。
Part 1. Batch Size:WSD 打破了旧理论

论文标题: How to Set the Batch Size for Large-Scale Pre-training?
论文链接: https://arxiv.org/abs/2601.05034
1.1 OpenAI 理论在 WSD 下的失效
OpenAI 在 2018 年提出的“临界批大小”(Critical Batch Size)理论一直是业界的金科玉律。该理论假设:在达到相同 Loss 的前提下,增大 BS 会减少训练步数但增加总 Token 消耗,且两者呈现单调的双曲线关系。
然而,在使用现代主流的 WSD (Warmup-Stable-Decay) 学习率调度器时,研究人员发现这一假设不再成立。在 WSD 的 Stable 阶段(即 LR 保持恒定阶段),不同 BS 的 Loss 曲线出现了交叉 (Intersection) 现象。
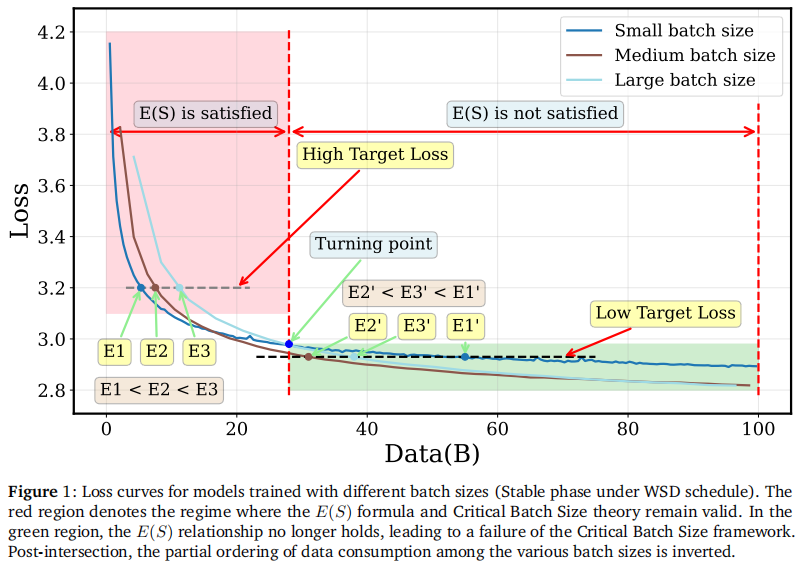
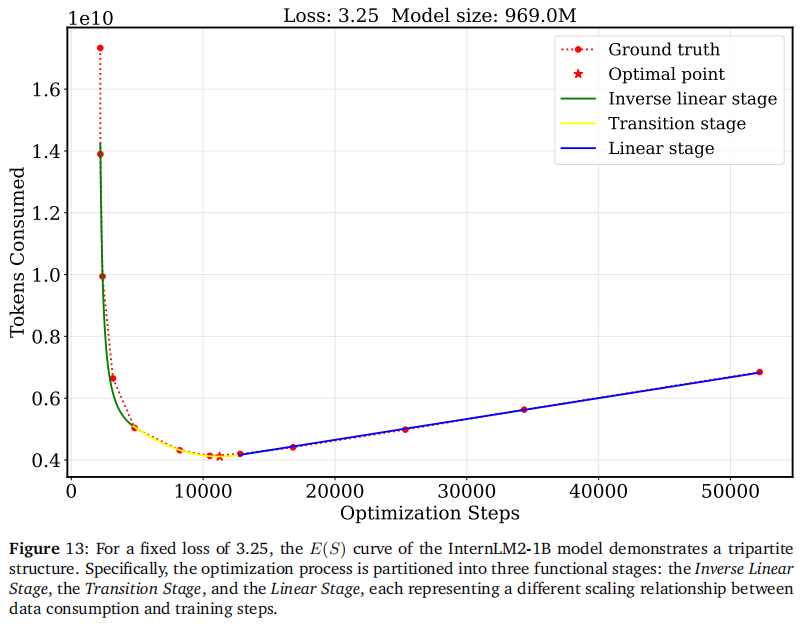
1.2 针对 WSD 的新 E(S)E(S)E(S) 动力学
为了修正这一偏差,作者深入分析了 WSD Stable 阶段的动力学特性,提出了一个新的分段 E(S)E(S)E(S) 公式(数据消耗 EEE 与步数 SSS 的关系)。新理论将训练过程解构为三个阶段:
- 反线性阶段 (Inverse Linear):受限于梯度噪声。
- 过渡阶段 (Transition):动力学特性发生转变。
- 线性阶段 (Linear):逐渐趋于饱和。
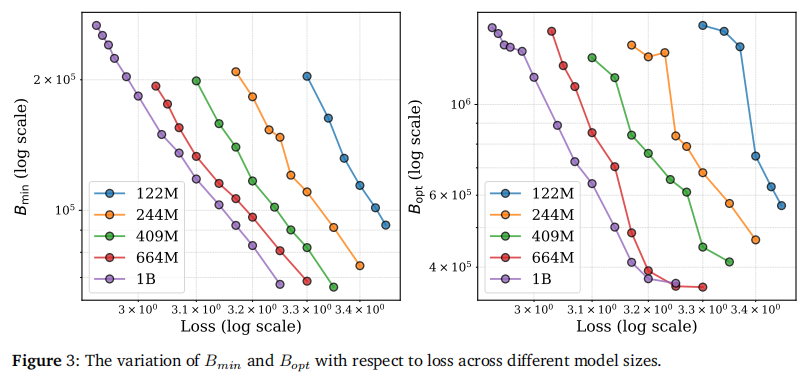
1.3 关键发现:BoptB_{opt}Bopt 是动态增长的
基于新公式,论文揭示了两个核心物理量的演变规律:
- BminB_{min}Bmin (最小阈值):达到特定 Loss 所需的最小物理 BS。
- BoptB_{opt}Bopt (最优 BS):达到特定 Loss 时,能使总 Token 消耗最少的 BS。
核心结论: 随着 Loss 的不断降低(模型越来越强),BoptB_{opt}Bopt 呈现单调递增的趋势。
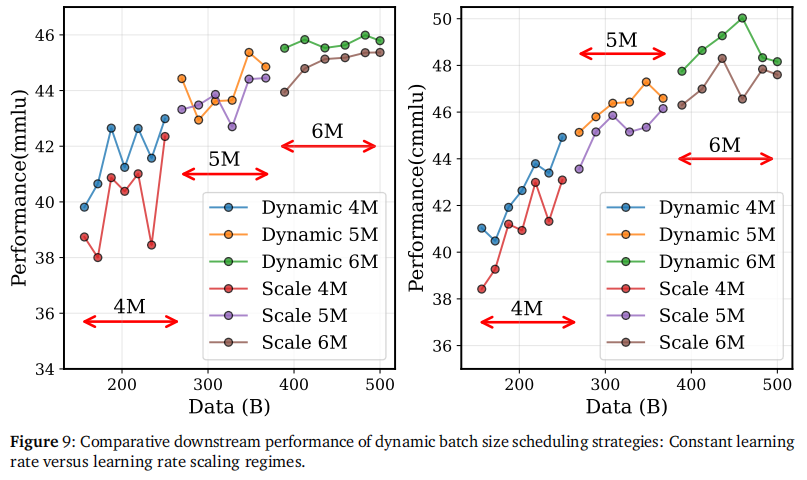
1.4 策略革新:动态 BS + 恒定 LR
既然 BoptB_{opt}Bopt 是动态变化的,全程固定 BS 显然不是最优解。作者提出了一种 动态 Batch Size 调度器 (Dynamic Batch Size Scheduler),即在训练过程中逐步增大 BS。
打破常识的发现: 传统经验认为增大 BS 必须同步放大 LR(如线性缩放或平方根缩放)。但该论文通过消融实验证明,在 WSD 的动态 BS 策略下,保持 LR 不变(Constant LR)效果最好。
Part 2. Learning Rate:拟合优于迁移

论文标题: How to Set the Learning Rate for Large-Scale Pre-training?
论文链接: https://arxiv.org/abs/2601.05049
2.1 范式之争:Fitting vs. Transfer
在大模型时代,如何确定最优 LR?目前存在两大阵营:
- 拟合范式 (Fitting Paradigm):在小模型上搜索,总结 Scaling Law 公式直接计算大模型参数。
- 迁移范式 (Transfer Paradigm):以微软 μ\muμP (μ\muμTransfer) 为代表,通过特定的参数初始化方式,试图让大模型直接复用小模型的最优 LR。
作者在 0.55B 到 3B 的规模上进行了高精度的 Grid Search,并将结论外推至 12B (MoE) 规模进行了验证。
2.2 结论:Scaling Law 的胜利
实验结果令人惊讶:在现代大模型架构下,直接拟合 (Fitting) 得到的最优 LR,在效果上显著优于 μ\muμTransfer 预测的 LR。
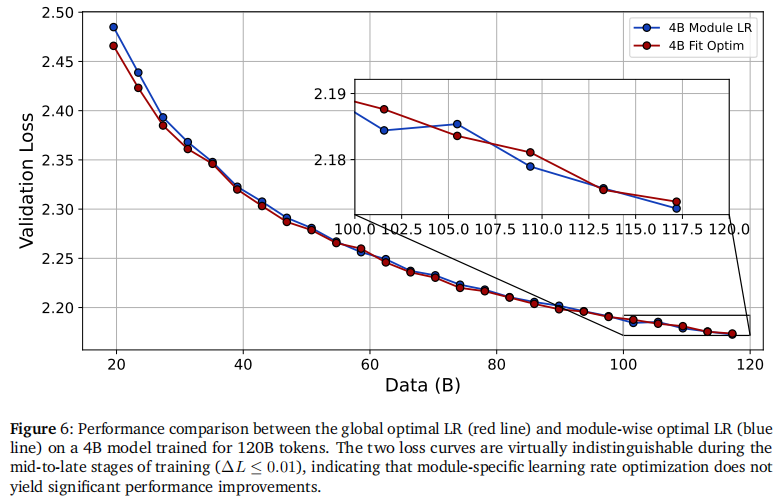
2.3 为什么 μ\muμP 失效了?
论文对 μ\muμP 在超大规模训练中表现不佳进行了归因:
- 架构红利 (QK-Norm):现代 LLM 标配的 QK-Norm 等技术已经极大地稳定了训练稳定性,解决了 μ\muμP 最想解决的“Logits 爆炸”问题。
- 数据量 (D) 的被忽视:μ\muμP 主要关注模型宽度 (Width) 的迁移,但忽略了训练数据量 (Data Size) 对最优 LR 的巨大影响。
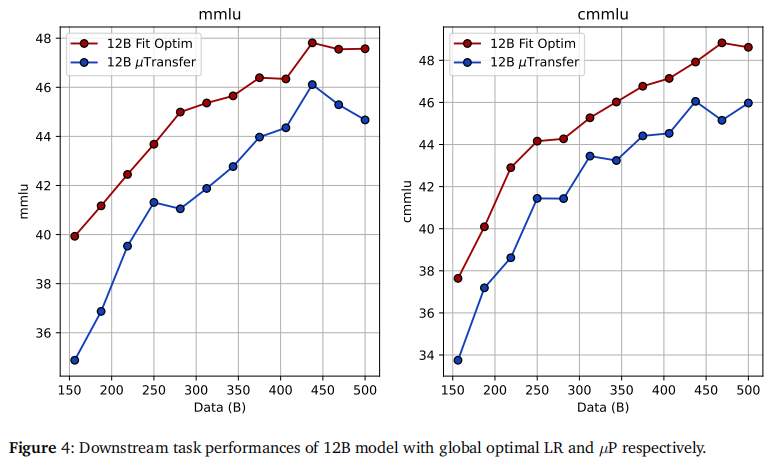
2.4 新的 LR Scaling Law 公式
回归拟合范式,作者提出了一个同时考虑模型参数量 (NNN) 和数据量 (DDD) 的最优学习率计算公式:
ηopt∝N−α⋅D−β \eta_{opt} \propto N^{-\alpha} \cdot D^{-\beta} ηopt∝N−α⋅D−β
实验拟合得到的参数为 α≈0.22\alpha \approx 0.22α≈0.22, β≈0.35\beta \approx 0.35β≈0.35。
重要启示: β>α\beta > \alphaβ>α,意味着数据量的增加比模型参数量的增加更需要大幅降低学习率。这对于当下动辄数万亿 Token 的训练极具指导意义。
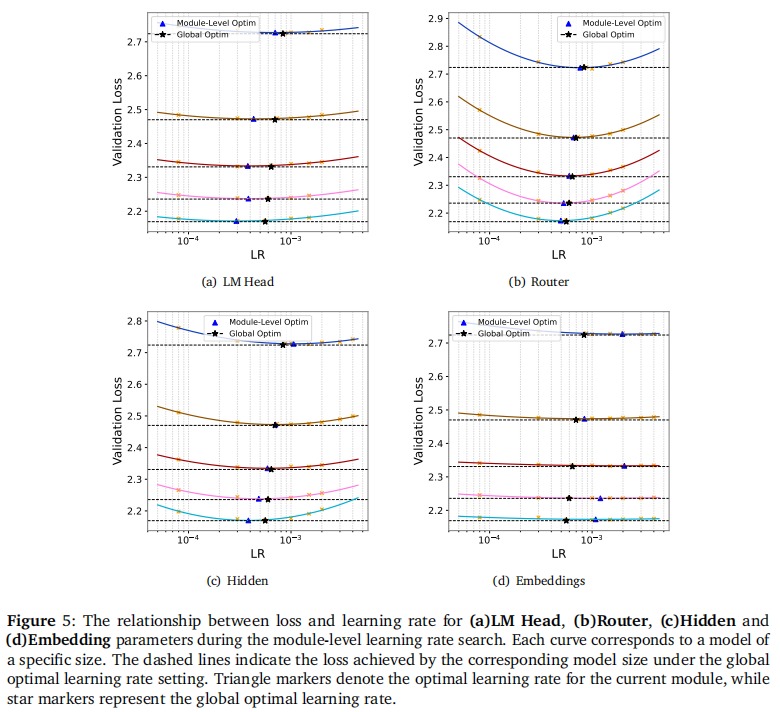
2.5 拒绝过度微操:全局 LR 足矣
针对“是否需要对 Embedding、Router、Head 分别设置不同 LR”的问题,作者进行了细粒度搜索。
结语:大模型训练的新“菜谱”
这两篇姊妹篇论文为 2026 年的大模型预训练提供了极具实操价值的建议:
- 拥抱动态 BS:不要死守固定 Batch Size,尝试随着训练 Loss 的下降逐步增大 BS,这是提升数据效率的低成本手段。
- 解耦 BS 与 LR:在动态 BS 策略中,不要按比例放大 LR,保持 WSD 的恒定 LR 策略即可。
- 回归 Fitting:在 QK-Norm 等现代架构下,μ\muμP 的必要性下降。使用 NNN 和 DDD 的双变量 Scaling Law 来预测 LR 更加准确。
- 关注数据量:数据规模对 LR 的影响比模型规模更大,数据越多,LR 应该越小。
- 大道至简:全局统一的 LR 配合正确的 Scaling Law,性价比远高于复杂的分层调参。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)