把 LLM 应用放上“手术台”:LangSmith 与 Phoenix 可观测性实战指南
随着大模型应用进入生产环境,可观测性成为关键挑战。LangSmith和Phoenix两大工具形成互补:LangSmith提供云端自动化追踪和预置仪表盘,适合快速调试和业务监控;Phoenix则专注本地化漂移检测和可视化分析,满足合规需求。最佳实践表明,开发阶段使用LangSmith监控性能指标,投产后结合Phoenix进行算法优化,可实现完整的可观测闭环。二者配合能有效解决延迟飙升、成本失控和回答
一、为什么“可观测性”突然成了 LLM 项目的生死线?
2024 年起,越来越多企业把大模型从 Demo 搬到生产,结果普遍遇到三类“灰犀牛”:
- 慢:P99 延迟从 800 ms 飙到 8 s,却不知道卡在哪一步。
- 贵:上线一周 Token 费用抵掉一个月预算,仍找不到“漏水”点。
- 错:用户投诉答非所问,开发却复现不了现场上下文。
传统 APM 只能看到“HTTP 200/500”,对 LLM 内部的 Prompt→Chain→Tool→Retry 完全失明。于是专为语言模型设计的可观测性栈——LangSmith 与 Phoenix——成了救火队长。
二、能力速览:LangSmith vs. Phoenix 一张表看懂
| 维度 | LangSmith(LangChain 官方) | Phoenix(Arize 开源) |
|---|---|---|
| 接入成本 | 两行环境变量即可自动追踪 LangChain | 需手动包裹 phoenix.trace.llm, phoenix.trace.retriever |
| 数据留存 | 云端 SaaS,30 天滚动(免费层) | 完全本地,PG/Parquet 自托管 |
| 评估深度 | 内置 LLM-as-Judge、多轮对话 Eval | 自带 UMAP 漂移检测、聚类可视化 |
| 告警通道 | Webhook / PagerDuty / Slack | 依赖 Grafana/Loki,可 DIY 任意阈值 |
| 适用场景 | 快速调试、业务指标大盘 | 隐私合规、算法漂移、免费无限流量 |
一句话总结:LangSmith 像“仪表盘”,Phoenix 像“显微镜”;二者互补,而非二选一。
三、LangSmith 监控落地 30 分钟教程
1. 开通与密钥
- 登录 smith.langchain.com → 用 GitHub 一键授权
- Settings → API Keys → Create → 复制
LANGCHAIN_API_KEY
2. 两行代码开启自动追踪
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "lsv2_pt_xxxx"
os.environ["LANGCHAIN_PROJECT"] = "rag-demo" # 项目名自定义
只要用了 LangChain,后续所有 Chain/Agent/Tool 调用会自动上传 Trace,包括:
- 每步输入/输出文本
- Token 消耗与模型名
- 耗时(ms 级)
- 异常堆栈
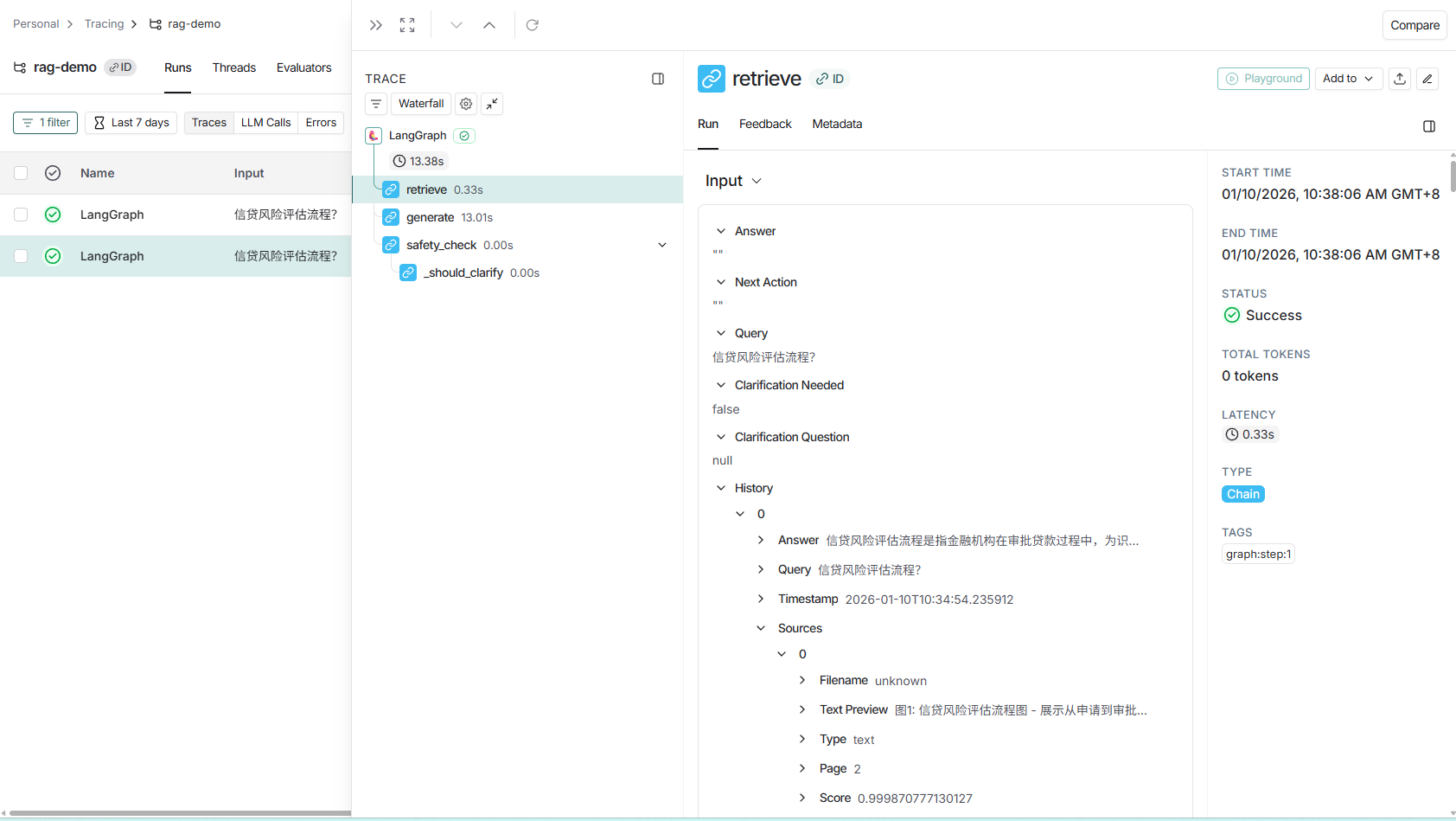
3. 预置仪表盘:性能-成本-错误 三板斧
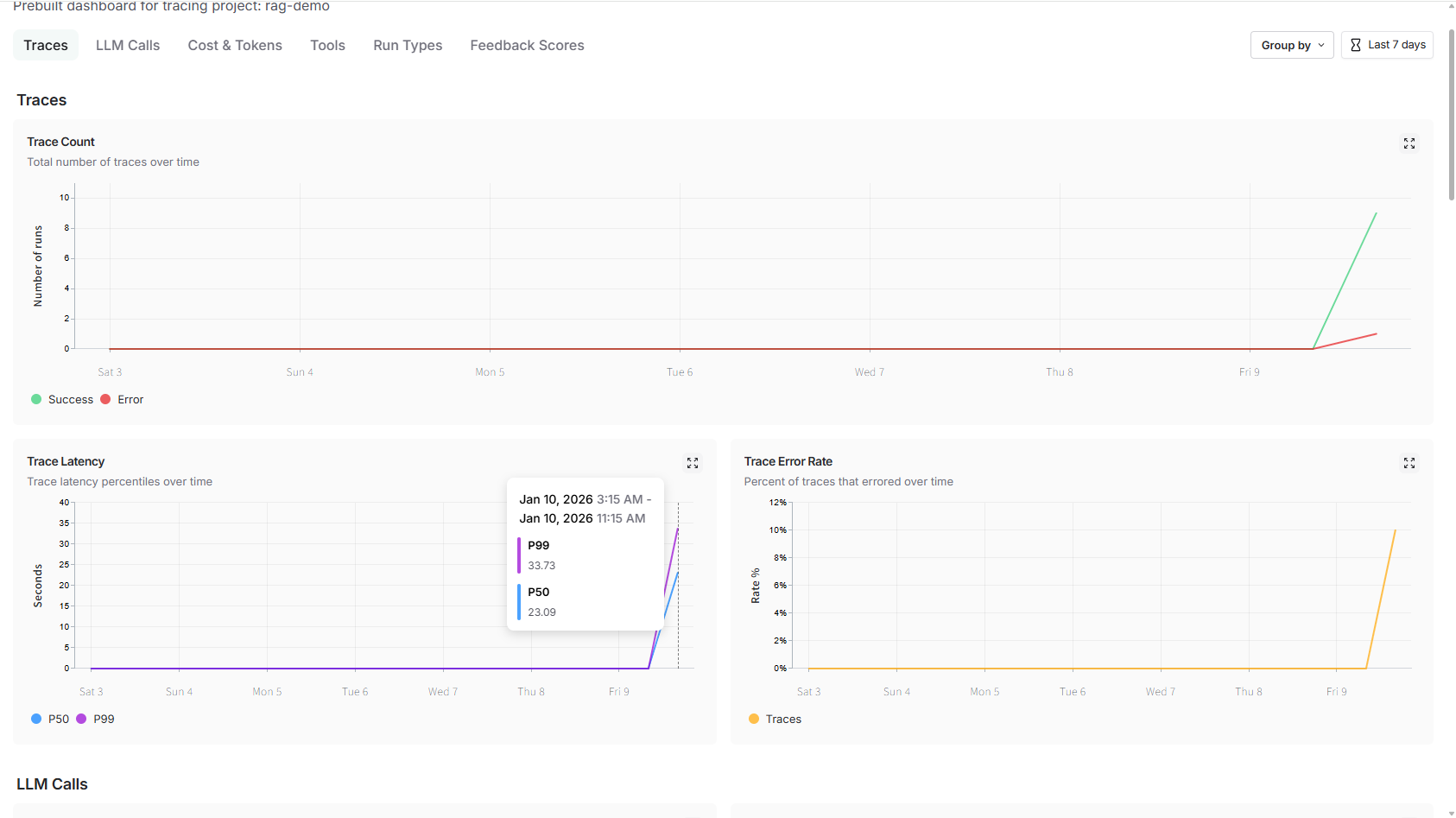
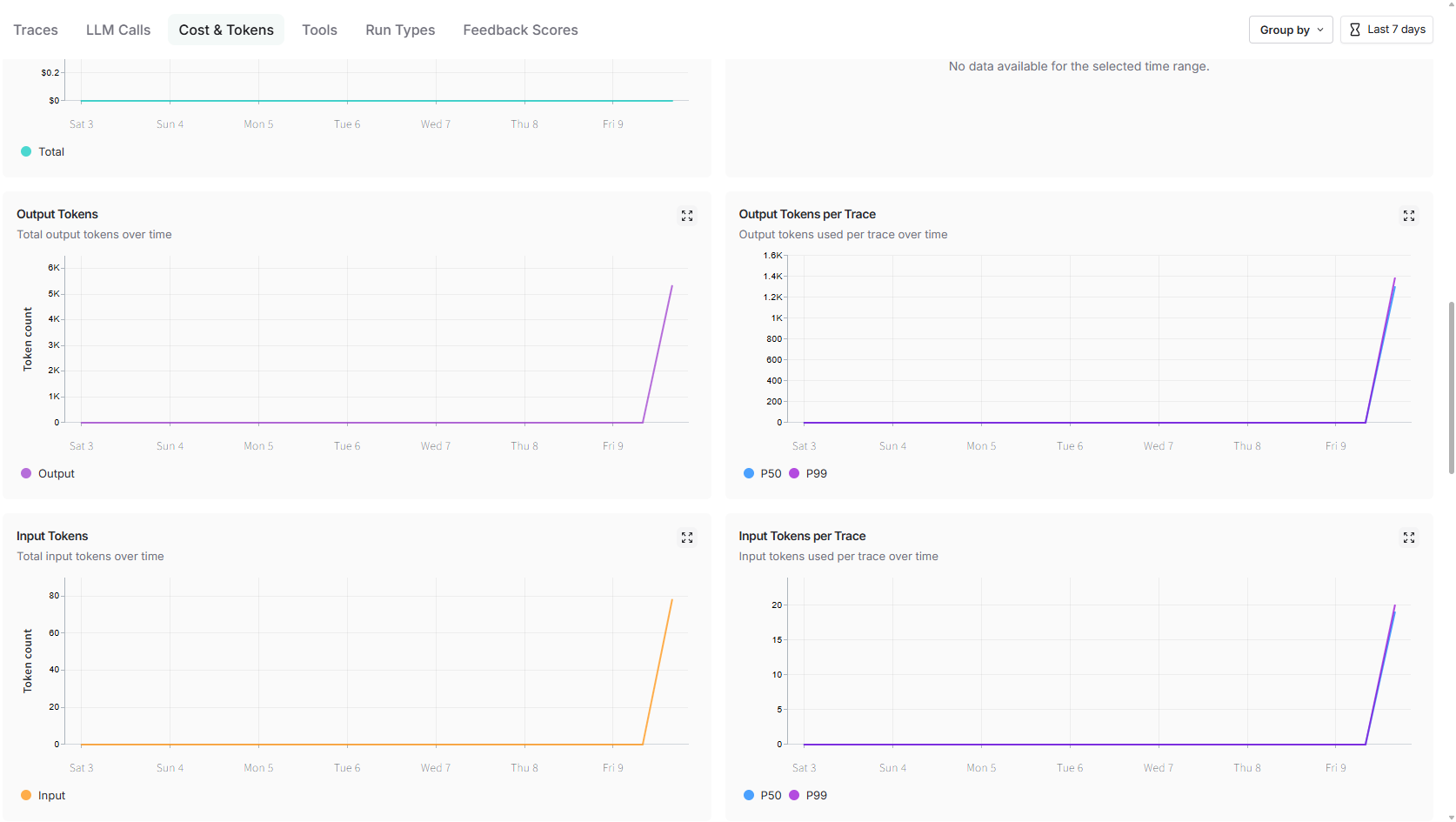
进入项目即可看到官方自动生成的 Pre-built Dashboard:
- P50/P99 延迟曲线
- 按模型分组的 Token 成本(已按官方单价折算成美元)
- 错误率 & 异常分类(429/500/Tool Timeout…)
实战技巧
- 在链里加
metadata={"user_id": "u_123", "plan": "pro"},就能在仪表盘按客户套餐做下钻。 - 设置告警:当“错误率 > 5% 持续 5 min”或“日 Token > 10 k$”时飞书机器人轰炸。
四、Phoenix 本地显微镜:漂移 + 聚类 + 可视化
1. 启动零依赖
pip install arize-phoenix
phoenix serve # 默认 6060 端口
浏览器打开 http://localhost:6060 即进入 Notebook 式 UI。
2. 把 LangChain 对象“裹”一层
from phoenix.trace.langchain import LangChainInstrumentor
LangChainInstrumentor().instrument() # 同样零侵入
执行后,Phoenix 会本地存储每一次 Embedding/Retriever/LLM 调用,数据不落第三方,适合金融、医疗等强合规场景。
3. 漂移检测实战:RAG 回答开始“胡说”怎么办?
import phoenix as px
# 1. 导出过去 7 天的 retriever 结果
df = px.Client().get_spans("span_kind == 'retriever'", start_time="7d")
# 2. UMAP 降维可视化
px.umap_viewer(df, color="cosine_distance") # 离群点一眼看见
当簇心漂移 > 0.15 且异常点占比 > 3% 时,即可触发“知识库需要重新切片/向量化”的告警;比人工抽测省时 80%。
五、一条龙 Demo:从“零追踪”到“可观测闭环”
场景:内部问答 Bot,链路 ChatOpenAI → Prompt → Retriever → LLM → OutputParser,目标是把 P99 < 2 s,幻觉率 < 5%。
Step 0 无追踪基线
chain = prompt | llm | parser
chain.invoke({"question": "Q4 财报发布时间?"})
→ 完全黑盒,不知道 Token 花在哪。
Step 1 接入 LangSmith(5 分钟)
见第三节,零代码改动即可在云端看到 Trace 瀑布图:
- 发现
retriever.get_relevant_documents()平均 1.8 s,占整条链 72%。 - 把向量库从欧氏距离改为 Inner Product,并加 IVF256 索引,延迟降至 0.4 s,P99 达标。
Step 2 接入 Phoenix(本地 Notebook)
LangChainInstrumentor().instrument()
# 跑 500 条历史问题
for q in questions:
chain.invoke({"question": q})
→ UMAP 图出现两条明显离群簇,人工确认均为切片重叠导致的重复上下文。
→ 调大 chunk_overlap=0,幻觉率从 8% 降到 3%,达成目标。
Step 3 持续评估(LangSmith Multi-turn Eval)
把上述 500 条对话导出为 Dataset,用官方 Multi-turn Eval 模板:
- 指标:任务完成度 / 工具选择正确率 / 语义一致性
- 自动 LLM-as-Judge 打分,结果回写 LangSmith
- 配置告警:当“平均完成度 < 90%”即 @全员
至此,“监控→定位→修复→评估→再监控” 闭环跑通,两周后再看仪表盘,三项核心指标均稳定在绿灯区。
六、踩坑与最佳实践
| 坑点 | 解法 |
|---|---|
| LangSmith 免费层 30 天自动删数据 | 关键 trace 手动加 star 或升级到 Plus |
| Phoenix 本地盘爆掉 | 开 PHOENIX_CLEANUP_INTERVAL=86400 自动清理 7 天前 spans |
| 多线程并发写 Phoenix 锁表 | 用 px.Client().log_spans_async() 批量写,性能 ×10 |
| 生产环境不能出公网 | LangSmith 可开 VPC 单向推送(Enterprise 功能) |
| 只想看 Token 账单,不想看 Trace | LangSmith 提供 Cost API,一条 curl 按天/按模型拉账单 |
七、总结:一张图记住选型
场景\工具 | LangSmith | Phoenix
------------|-------------------|-------------------
Debug 阶段 | ★★★★☆ 自动追踪 | ★★★☆☆ 需包裹
评估/实验 | ★★★★★ 内置 Eval | ★★★★☆ 漂移可视化
生产监控 | ★★★★☆ 告警丰富 | ★★☆☆☆ 需接 Grafana
数据合规 | ★☆☆☆☆ 走 SaaS | ★★★★★ 纯本地
费用 | 免费→Plus $$$ | 完全开源
一句话:
开发期用 LangSmith 看仪表盘,投产后再用 Phoenix 做显微镜;
一个管“业务指标”,一个管“算法漂移”,两条腿走路,LLM 可观测性才算真正闭环。
八、延伸阅读
- 官方 Cookbook:github.com/langchain-ai/langsmith-cookbook
- Phoenix 示例集:github.com/Arize-ai/phoenix/tree/main/examples
参考资料
LangSmith 监控仪表盘与告警官方文档
LangSmith Multi-turn Eval 与 Insights Agent 发布纪要
LangChain 与 LangSmith 集成追踪示例
学习代码

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)