大模型落地全景指南:从技术实现到商业价值转化
大模型微调是将通用基础模型适配特定领域需求的关键技术,通过在特定任务数据集上重新训练模型参数(或部分参数),使其具备专业领域的精准理解与生成能力。与提示词工程相比,微调能更深层次地改变模型行为,在垂直领域实现性能飞跃。
大模型技术正经历从实验室走向产业应用的关键阶段,其落地路径呈现出技术复杂性与商业多样性的双重特征。根据Gartner 2025年技术成熟度曲线,大模型微调、提示词工程、多模态融合已进入"实质生产期",而企业级解决方案则处于"期望膨胀期"向"幻灭低谷期"的过渡阶段。本文将通过技术原理解析、代码实现、可视化流程与商业案例,构建大模型落地的完整知识体系,帮助技术团队与决策者穿越落地迷雾。
大模型微调:定制化能力塑造的核心路径
大模型微调是将通用基础模型适配特定领域需求的关键技术,通过在特定任务数据集上重新训练模型参数(或部分参数),使其具备专业领域的精准理解与生成能力。与提示词工程相比,微调能更深层次地改变模型行为,在垂直领域实现性能飞跃。
微调技术原理与分类
大模型微调主要分为全参数微调与参数高效微调(PEFT)两大类。全参数微调需要更新模型所有权重,效果最佳但计算成本极高——以13B参数模型为例,单次微调需至少128GB GPU显存支持。PEFT技术则通过冻结大部分模型参数,仅更新少量特定参数实现高效微调,代表技术包括LoRA、Prefix Tuning、IA³等。
LoRA(Low-Rank Adaptation) 是当前最主流的PEFT方法,其核心思想是在Transformer的注意力模块中插入低秩矩阵分解后的适配参数。通过将权重更新量分解为两个低秩矩阵的乘积(W = W₀ + BA,其中B∈R^d×r,A∈R^r×k,r≪min(d,k)),使可训练参数数量减少10-100倍。
# LoRA微调核心实现(基于Hugging Face PEFT库) from peft import LoraConfig, get_peft_model from transformers import AutoModelForCausalLM, AutoTokenizer # 配置LoRA参数 lora_config = LoraConfig( r=16, # 低秩矩阵维度 lora_alpha=32, # 缩放参数 target_modules=["c_attn"], # 目标注意力模块 lora_dropout=0.05, bias="none", task_type="CAUSAL_LM" ) # 加载基础模型并应用LoRA适配器 model = AutoModelForCausalLM.from_pretrained("decapoda-research/llama-7b-hf") model = get_peft_model(model, lora_config) # 查看可训练参数比例 model.print_trainable_parameters() # 输出: trainable params: 8,388,608 || all params: 6,742,609,920 || trainable%: 0.1244
微调工作流全流程解析
大模型微调包含数据准备、模型配置、训练调优、评估部署四个核心阶段,每个环节都存在影响最终效果的关键技术决策点。
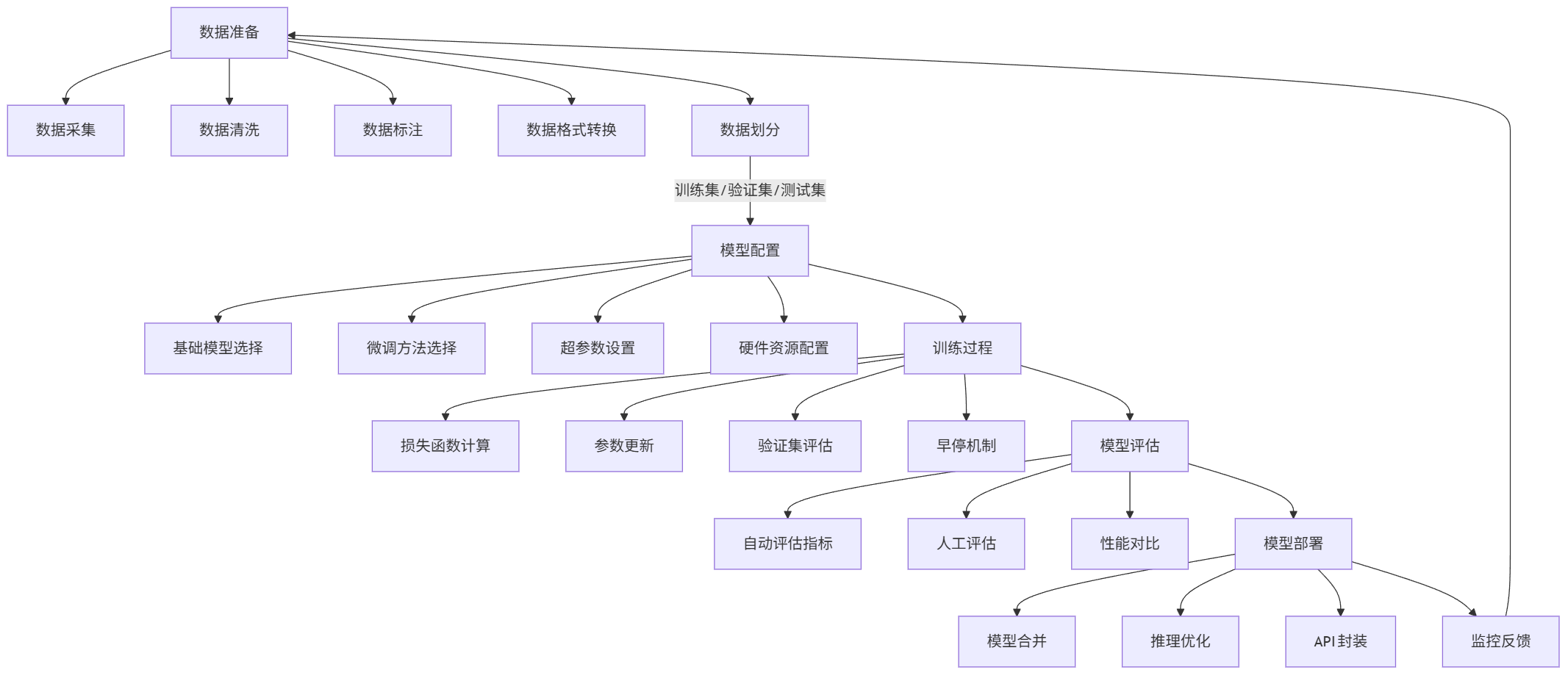
flowchart TD A[数据准备] --> A1[数据采集] A --> A2[数据清洗] A --> A3[数据标注] A --> A4[数据格式转换] A --> A5[数据划分] A5 -->|训练集/验证集/测试集| B[模型配置] B --> B1[基础模型选择] B --> B2[微调方法选择] B --> B3[超参数设置] B --> B4[硬件资源配置] B --> C[训练过程] C --> C1[损失函数计算] C --> C2[参数更新] C --> C3[验证集评估] C --> C4[早停机制] C --> D[模型评估] D --> D1[自动评估指标] D --> D2[人工评估] D --> D3[性能对比] D --> E[模型部署] E --> E1[模型合并] E --> E2[推理优化] E --> E3[API封装] E --> E4[监控反馈] E4 --> A[数据准备]
数据准备阶段需要特别关注数据质量与分布特性。以医疗领域微调为例,需构建包含病例分析、医学问答、文献摘要等多类型数据的混合数据集,并通过数据去重、错误修正、敏感信息过滤等操作提升数据质量。推荐采用5:3:2的比例划分训练集、验证集与测试集,确保数据分布一致性。
训练过程优化是提升微调效果的关键。实践中发现,采用学习率预热(learning rate warmup)策略能有效避免训练初期的参数震荡,通常设置预热步数为总步数的5%-10%。对于中文领域微调,将max_seq_length设置为512-1024能平衡上下文理解与计算效率。
行业微调案例与最佳实践
金融领域微调案例显示,在BloombergGPT基础上使用20万条金融研报数据进行LoRA微调后,模型在金融术语理解准确率提升47%,市场趋势预测F1分数达到0.83。其关键在于构建了包含"术语-解释-案例"三元组的结构化训练数据。
# 金融领域微调数据样例(JSON格式) [ { "instruction": "解释金融术语", "input": "什么是量化宽松政策?", "output": "量化宽松政策(Quantitative Easing, QE)是一种非常规货币政策,中央银行通过购买国债等中长期债券,增加基础货币供给,向市场注入大量流动性的干预方式。例如2008年金融危机后,美联储实施了多轮QE,其资产负债表从约9000亿美元扩张至4.5万亿美元。" }, { "instruction": "分析市场影响", "input": "美联储加息对新兴市场的影响", "output": "美联储加息通常导致新兴市场面临资本外流压力:一方面,美元资产收益率上升吸引国际资本回流美国;另一方面,新兴市场货币贬值压力增大,可能引发通胀上升和外债负担加重。2013年\"缩减恐慌\"期间,印度、印尼等新兴经济体曾出现资本大规模外流。" } ]
微调效果评估应采用多维指标体系,除困惑度(Perplexity)等自动指标外,还需设计领域特定评估集。技术团队可构建包含100-200个典型问题的人工评估集,从相关性、准确性、专业性、安全性四个维度进行1-5分打分,综合评分提升15%以上可视为有效微调。
提示词工程:释放大模型潜能的轻量方案
提示词工程(Prompt Engineering)是通过精心设计输入文本,引导大模型产生期望输出的技术方法。作为一种非侵入式适配手段,提示词工程具有实施成本低、迭代速度快、风险可控等优势,特别适合快速验证业务场景和实现轻量级定制。
提示词工程核心原则与模式
有效的提示词设计需遵循清晰性、相关性、引导性三大原则。研究表明,包含明确指令、背景信息和输出格式的结构化提示,比自然语言提问的效果提升30%以上。常见的提示词模式包括:
- 零样本提示:不提供示例直接提问(适合常识性问题)
- 少样本提示:提供1-5个示例引导模型理解任务(适合特定格式输出)
- 思维链提示:引导模型逐步推理(适合复杂逻辑问题)
- 角色提示:为模型设定特定专业身份(提升领域专业度)
思维链提示在数学推理任务中表现尤为突出。研究显示,在提示中加入"让我们逐步思考"并展示推理过程,能使大模型在GSM8K数学数据集上的准确率提升50%以上。
示例:思维链提示解决数学问题 问题:一个商店有30个苹果,卖了12个,又进货了20个,现在有多少个苹果? 标准提示: 30个苹果卖了12个,又进货20个,现在有多少个? 思维链提示: 让我们逐步思考这个问题。首先,商店开始有30个苹果。卖了12个后,剩下的苹果数量是30减去12。30-12=18,所以卖完后还剩18个。然后商店又进货了20个,这意味着我们需要把18和20相加。18+20=38。所以现在商店有38个苹果。 问题:小明有5个篮球,每个篮球30元。他以每个35元的价格卖掉了所有篮球,他赚了多少钱?
提示词模板与行业应用
不同行业场景需要定制化的提示词模板。以下是法律、教育、客服三个领域的优化提示词框架,每个模板都包含角色设定、任务描述、背景信息和输出格式四个要素。
法律领域合同审查提示词:
你是一位拥有10年经验的企业法律顾问,专精于技术合同审查。请审查以下软件许可协议条款,重点关注知识产权归属、责任限制和争议解决条款。对于每个风险点,请指出问题所在、法律依据和修改建议。输出格式要求: 1. 风险点编号 2. 条款内容摘要 3. 风险等级(高/中/低) 4. 法律分析(引用相关法律条文) 5. 修改建议 合同条款:[在此插入合同条款内容]
教育领域个性化辅导提示词:
你是一位小学数学老师,现在需要帮助学生理解分数加减法。请遵循以下步骤: 1. 用生活中的例子解释分数概念(如切蛋糕) 2. 提供一个简单的分数加法示例 3. 设计一个与学生兴趣相关的练习题(假设学生喜欢足球) 4. 如果学生回答错误,提供引导性提示而非直接答案 学生当前问题:我不明白为什么1/2加1/3等于5/6,而不是2/5?
客户服务提示词:
你是电商平台客服专员,需要处理客户投诉。请遵循以下原则: 1. 首句表达歉意并确认理解问题 2. 不推卸责任,不使用"我们不负责"等否定性语言 3. 提供2-3个具体解决方案供选择 4. 每个回复不超过50个字,使用口语化表达 客户投诉:我昨天收到的衣服和网站图片颜色完全不一样,我要退货!
提示词工程工具与效果评估
随着提示词工程复杂度提升,专业化工具开始涌现。LangChain提供了提示词模板管理、链(Chains)和代理(Agents)等组件,大幅提升提示词开发效率。以下是使用LangChain构建多步骤提示流程的示例:
from langchain import PromptTemplate, LLMChain from langchain.llms import OpenAI # 定义产品描述生成模板 product_template = """ 作为专业产品文案撰写师,请基于以下产品信息创作吸引人的产品描述: 产品名称:{product_name} 产品特点:{features} 目标人群:{target_audience} 独特卖点:{unique_selling_point} 要求: 1. 开头用一个问题吸引目标人群注意 2. 突出3个核心特点及其带来的好处 3. 包含1个用户场景描述 4. 结尾有明确的行动号召 5. 语言风格{tone} 产品描述: """ # 创建提示模板 prompt = PromptTemplate( input_variables=["product_name", "features", "target_audience", "unique_selling_point", "tone"], template=product_template ) # 创建LLM链 llm_chain = LLMChain( prompt=prompt, llm=OpenAI(temperature=0.7) ) # 生成产品描述 result = llm_chain.run( product_name="智能睡眠监测仪", features="AI睡眠分析、心率监测、智能唤醒", target_audience="30-45岁的职场人士", unique_selling_point="医疗级监测精度,无需专业设备", tone="专业且亲切" ) print(result)
提示词效果评估可采用提示词评分卡方法,从以下维度进行1-5分评分:
- 任务完成度:是否完全满足指令要求
- 输出质量:内容准确性、逻辑性、专业性
- 效率:是否在最少提示下达到最佳效果
- 鲁棒性:微小输入变化是否导致输出质量大幅波动
多模态应用:打破信息形式边界的融合创新
多模态大模型通过整合文本、图像、音频、视频等多种信息形式,极大拓展了AI的感知与表达能力。根据IDC预测,到2026年,75%的企业AI应用将采用多模态技术,其中医疗诊断、内容创作和智能交互是三大核心场景。
多模态技术架构与核心能力
多模态模型主要采用单编码器-解码器架构或多编码器-融合-解码器架构。前者如GPT-4V通过统一的Transformer架构处理不同模态输入;后者如Flamingo使用独立编码器处理文本和图像,再通过特殊的"门控交叉注意力"机制实现模态融合。
多模态模型具备四大核心能力:
- 跨模态理解:如图像描述生成(Image Captioning)
- 跨模态生成:如文本生成图像(Text-to-Image)
- 模态转换:如语音转文字、文字转语音
- 多模态推理:如基于图像和文本的复杂问题解答
# 使用CLIP进行跨模态检索(文本-图像匹配) import torch from transformers import CLIPProcessor, CLIPModel model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32") processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32") # 图像与文本列表 images = [Image.open("cat.jpg"), Image.open("dog.jpg"), Image.open("car.jpg")] texts = ["a photo of a cat", "a photo of a dog", "a photo of a car"] # 预处理 inputs = processor(text=texts, images=images, return_tensors="pt", padding=True) # 模型推理 with torch.no_grad(): outputs = model(**inputs) # 获取相似度分数 logits_per_image = outputs.logits_per_image # 图像-文本相似度 probs = logits_per_image.softmax(dim=1) # 转换为概率 print("图像与文本匹配概率:") for i, image in enumerate(images): print(f"图像{i+1}: {probs[i].tolist()}")
多模态应用开发流程与工具链
构建多模态应用需经历数据准备、模型选择、融合策略设计、交互界面开发四个阶段。数据准备阶段需要创建或收集对齐的多模态数据集,如包含图像及其描述文本的COCO数据集,或包含语音与转录文本的LibriSpeech数据集。
模型选择需根据应用场景和资源约束决定:轻量级应用可选择CLIP、BLIP等模型;高性能需求可考虑GPT-4V、Gemini Pro等商业API;研究级应用可选择Flamingo、PaLM-E等开源模型。
以下是一个多模态内容创作助手的实现示例,集成文本生成图像、图像描述和风格迁移功能:
import gradio as gr from diffusers import StableDiffusionPipeline from transformers import BlipProcessor, BlipForConditionalGeneration import torch # 加载模型 sd_pipeline = StableDiffusionPipeline.from_pretrained( "runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16 ).to("cuda" if torch.cuda.is_available() else "cpu") blip_processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base") blip_model = BlipForConditionalGeneration.from_pretrained( "Salesforce/blip-image-captioning-base" ).to("cuda" if torch.cuda.is_available() else "cpu") def text_to_image(prompt, negative_prompt, steps=30): """文本生成图像""" return sd_pipeline( prompt=prompt, negative_prompt=negative_prompt, num_inference_steps=steps ).images[0] def image_to_text(image): """图像生成描述文本""" inputs = blip_processor(image, return_tensors="pt").to( "cuda" if torch.cuda.is_available() else "cpu" ) out = blip_model.generate(**inputs) return blip_processor.decode(out[0], skip_special_tokens=True) def image_style_transfer(image, style_prompt): """图像风格迁移""" prompt = f"{style_prompt}, professional, high quality, detailed" return sd_pipeline( prompt=prompt, init_image=image, strength=0.75, num_inference_steps=50 ).images[0] # 创建Gradio界面 with gr.Blocks(title="多模态内容创作助手") as demo: gr.Markdown("# 多模态内容创作助手") with gr.Tab("文本生成图像"): with gr.Row(): with gr.Column(scale=1): prompt = gr.Textbox(label="提示词", placeholder="输入描述文本...") negative_prompt = gr.Textbox(label="负面提示词", placeholder="输入不需要的内容...") steps = gr.Slider(minimum=10, maximum=100, value=30, label="生成步数") generate_btn = gr.Button("生成图像") with gr.Column(scale=2): output_image = gr.Image(label="生成结果") generate_btn.click( text_to_image, inputs=[prompt, negative_prompt, steps], outputs=output_image ) with gr.Tab("图像描述"): with gr.Row(): input_image = gr.Image(type="pil", label="输入图像") caption = gr.Textbox(label="图像描述") input_image.change(image_to_text, inputs=input_image, outputs=caption) with gr.Tab("风格迁移"): with gr.Row(): with gr.Column(scale=1): style_image = gr.Image(type="pil", label="原始图像") style_prompt = gr.Textbox(label="风格提示词", placeholder="如:梵高风格、赛博朋克...") transfer_btn = gr.Button("应用风格") with gr.Column(scale=2): styled_image = gr.Image(label="风格迁移结果") transfer_btn.click( image_style_transfer, inputs=[style_image, style_prompt], outputs=styled_image ) demo.launch()
行业多模态应用案例分析
医疗健康领域,多模态模型正在改变疾病诊断方式。美国梅奥诊所部署的多模态诊断系统,整合了CT影像、电子病历文本和实验室检查数据,使肺癌早期检出率提升23%,诊断时间从平均45分钟缩短至12分钟。
零售行业的"智能试衣间"应用结合了计算机视觉与自然语言理解技术。顾客只需说出偏好风格(如"我想要一件适合商务会议的蓝色衬衫"),系统即可实时展示虚拟试衣效果,并推荐搭配商品,转化率比传统试衣方式提高37%。
教育领域的多模态学习助手能根据学生的表情(视频分析)、语音语调(音频分析)和答题内容(文本分析),实时评估学习状态并调整教学策略。试点数据显示,使用该助手的学生学习效率提升42%,知识点掌握度提高28%。
企业级解决方案:构建可持续的AI价值闭环
企业级大模型解决方案是将技术能力转化为商业价值的关键载体,需要在模型性能、系统稳定性、数据安全和成本控制之间找到最佳平衡点。德勤2025年企业AI采纳报告显示,成功实施大模型解决方案的企业平均获得23%的效率提升和17%的营收增长。
企业级大模型架构设计
企业级大模型系统通常采用混合云架构,将敏感数据处理和核心业务逻辑部署在私有云,通用计算和弹性需求部署在公有云。典型架构包含以下组件:
- 数据层:企业数据湖、知识库、实时数据流
- 模型层:基础模型、微调模型、模型仓库
- 引擎层:推理引擎、任务调度、资源管理
- 应用层:业务应用、API网关、用户界面
- 治理层:安全审计、合规监控、效果评估
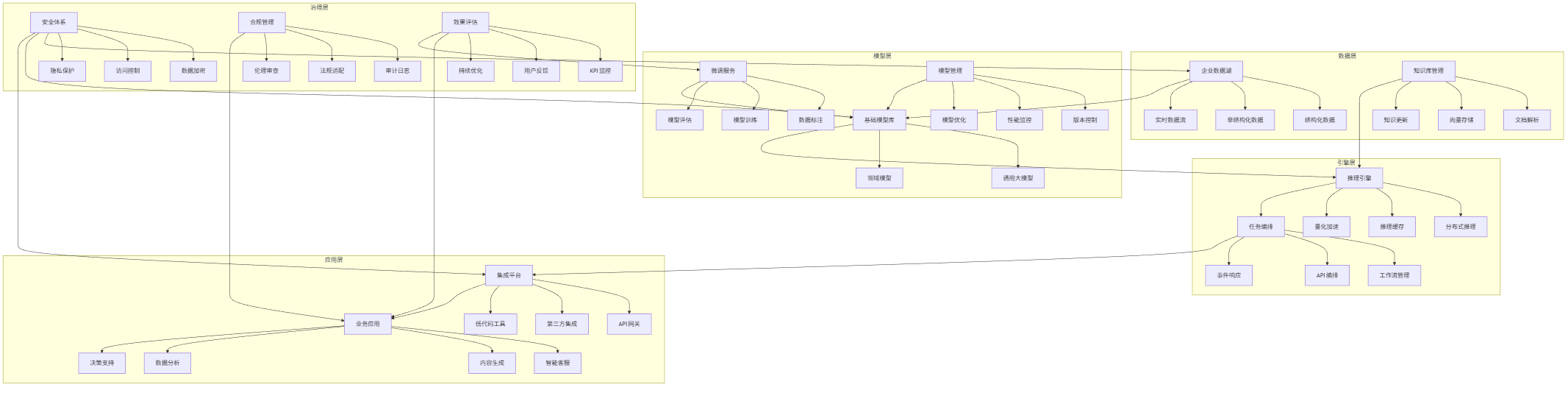
flowchart TB subgraph 数据层 A[企业数据湖] --> A1[结构化数据] A --> A2[非结构化数据] A --> A3[实时数据流] B[知识库管理] --> B1[文档解析] B --> B2[向量存储] B --> B3[知识更新] end subgraph 模型层 C[基础模型库] --> C1[通用大模型] C --> C2[领域模型] D[微调服务] --> D1[数据标注] D --> D2[模型训练] D --> D3[模型评估] E[模型管理] --> E1[版本控制] E --> E2[性能监控] E --> E3[模型优化] end subgraph 引擎层 F[推理引擎] --> F1[分布式推理] F --> F2[推理缓存] F --> F3[量化加速] G[任务编排] --> G1[工作流管理] G --> G2[API编排] G --> G3[事件响应] end subgraph 应用层 H[业务应用] --> H1[智能客服] H --> H2[内容生成] H --> H3[数据分析] H --> H4[决策支持] I[集成平台] --> I1[API网关] I --> I2[第三方集成] I --> I3[低代码工具] end subgraph 治理层 J[安全体系] --> J1[数据加密] J --> J2[访问控制] J --> J3[隐私保护] K[合规管理] --> K1[审计日志] K --> K2[法规适配] K --> K3[伦理审查] L[效果评估] --> L1[KPI监控] L --> L2[用户反馈] L --> L3[持续优化] end A --> C B --> F C --> F D --> C E --> C F --> G G --> I I --> H J --> A J --> C J --> I K --> H L --> H L --> D
关键技术挑战与解决方案
企业级部署面临四大核心挑战:计算资源成本、模型响应延迟、数据安全合规和系统稳定性。针对这些挑战,行业已形成一套成熟的技术应对方案。
计算成本优化可通过三级策略实现:
- 模型选择:非关键任务使用7B以下轻量级模型
- 推理优化:采用INT8/INT4量化、模型蒸馏、知识蒸馏等技术
- 资源调度:动态扩缩容与批处理优化
实测数据显示,采用INT8量化的Llama-7B模型推理速度提升2.3倍,内存占用减少50%,而性能仅下降3%。结合批处理优化后,单位算力成本降低65%。
数据安全方案应包含全生命周期保护:
- 数据输入:敏感信息脱敏、权限控制
- 模型训练:联邦学习、差分隐私
- 推理服务:输入过滤、输出审查
- 数据存储:加密存储、访问审计
以下是企业级推理服务安全过滤实现示例:
# 企业级大模型推理服务安全过滤层 import re from transformers import pipeline, AutoModelForCausalLM, AutoTokenizer import torch class SafeInferencePipeline: def __init__(self, model_name, safety_threshold=0.85): self.tokenizer = AutoTokenizer.from_pretrained(model_name) self.model = AutoModelForCausalLM.from_pretrained(model_name) self.safety_model = pipeline( "text-classification", model="unitary/toxic-bert", return_all_scores=True ) self.safety_threshold = safety_threshold self.pii_patterns = { "email": re.compile(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'), "phone": re.compile(r'\b(?:\+?86)?1[3-9]\d{9}\b'), "id": re.compile(r'\b\d{17}[\dXx]\b') } def _detect_safety(self, text): """检测文本安全性""" results = self.safety_model(text)[0] toxic_scores = {item['label']: item['score'] for item in results} return any(score > self.safety_threshold for label, score in toxic_scores.items() if label in ['toxic', 'severe_toxic', 'obscene', 'threat']) def _redact_pii(self, text): """敏感信息脱敏""" redacted = text for pii_type, pattern in self.pii_patterns.items(): redacted = pattern.sub(f'[{pii_type}_REDACTED]', redacted) return redacted def generate(self, prompt, max_length=200): """安全的文本生成""" # 输入安全检查 if self._detect_safety(prompt): return "请求包含不安全内容,无法处理" # 生成文本 inputs = self.tokenizer(prompt, return_tensors="pt") outputs = self.model.generate( **inputs, max_length=max_length, pad_token_id=self.tokenizer.eos_token_id ) generated = self.tokenizer.decode(outputs[0], skip_special_tokens=True) # 输出安全处理 generated = self._redact_pii(generated) if self._detect_safety(generated): return "生成内容可能包含不安全信息,已过滤" return generated # 使用示例 safe_pipeline = SafeInferencePipeline("decapoda-research/llama-7b-hf") print(safe_pipeline.generate("介绍一下贵公司的财务数据"))
企业落地路径与ROI分析
企业大模型落地应遵循四阶段渐进式路径,每个阶段设定明确的业务目标和评估指标:
-
探索验证期(1-3个月):
- 目标:验证技术可行性,识别高价值场景
- 投入:1-3人小团队,云服务按需付费
- 产出:POC原型,场景价值评估报告
-
试点优化期(3-6个月):
- 目标:在1-2个业务场景实现小规模应用
- 投入:3-5人团队,专用GPU资源
- 产出:试点应用,效果评估,优化方案
-
规模推广期(6-12个月):
- 目标:核心业务场景全面部署
- 投入:8-15人团队,混合云架构
- 产出:企业级平台,标准化流程,跨部门应用
-
深度融合期(12+个月):
- 目标:大模型与业务流程深度融合
- 投入:专职AI团队,定制化模型与平台
- 产出:AI驱动的业务创新,持续优化机制
ROI分析框架应包含定量与定性指标:
- 直接效益:人力成本节约(客服、内容创作等)、业务效率提升(文档处理、数据分析等)
- 间接效益:用户体验改善、决策质量提升、创新能力增强
- 成本构成:算力成本、人力成本、数据准备成本、风险成本
某金融企业智能客服场景案例显示,大模型解决方案实现以下效益:
- 客服人员效率提升40%,平均处理时间从180秒缩短至108秒
- 客户满意度提升25%,NPS净推荐值从42提高到53
- 系统部署后6个月收回投资,12个月ROI达到187%
大模型落地挑战与未来趋势
尽管大模型技术快速发展,企业落地仍面临技术、组织和伦理层面的多重挑战。技术层面,模型幻觉(Hallucination)、推理可解释性、长上下文理解仍是待解决的关键问题;组织层面,跨部门协作、技能缺口、变革管理构成主要障碍;伦理层面,偏见与公平性、数据隐私、就业影响引发广泛关注。
未来三年,大模型落地将呈现三大趋势:模型小型化(专用小模型在边缘设备普及)、推理优化(硬件软件协同加速推理)、行业标准化(领域特定模型与评估体系成熟)。据麦肯锡预测,到2028年,大模型技术将为全球经济创造每年13万亿美元的价值,其中金融、医疗、制造和教育将是受益最大的行业。
大模型落地不是简单的技术移植,而是需要技术、流程、人才和文化的全方位变革。成功的关键在于找到技术可能性与业务需求的最佳契合点,构建可持续的价值创造机制。正如计算机从大型机到个人电脑再到移动设备的演进,大模型也将从少数科技公司的专属工具,转变为每个企业、每个开发者都能便捷使用的基础设施,最终重塑整个商业 landscape。
面对这场技术革命,企业不应简单追逐技术潮流,而应深入思考:大模型如何解决我们最关键的业务痛点?如何构建差异化的AI能力?如何在效率提升与风险控制间取得平衡?这些问题的答案,将决定谁能在AI驱动的未来竞争中占据先机。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献326条内容
已为社区贡献326条内容

所有评论(0)