多目标强化学习新突破!NVIDIA揭秘GRPO“缺陷”,GDPO让大模型训练不再“顾此失彼“
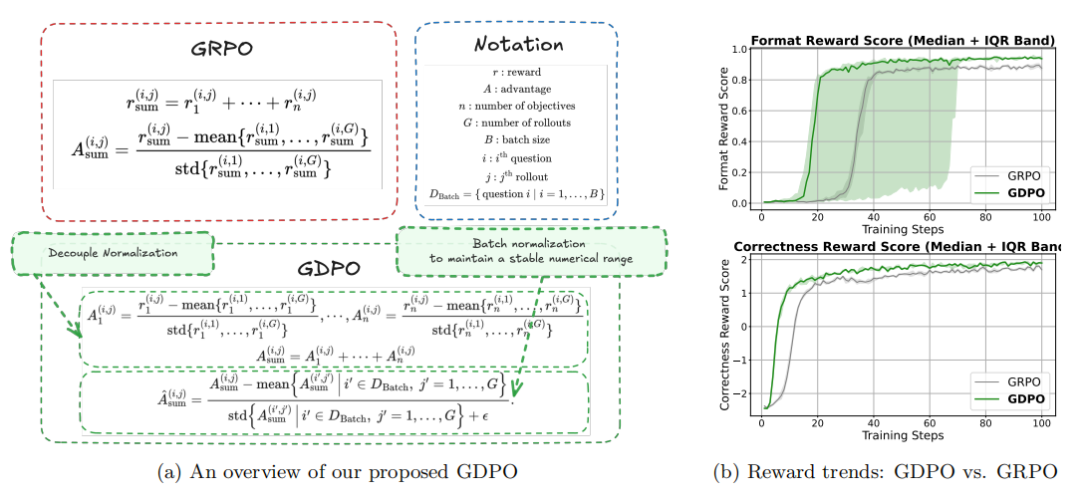
这篇论文的价值在于,它揭示了一个被广泛使用但少有人质疑的假设:GRPO适合多奖励优化。通过理论分析和大量实验,研究者证明了这个假设是错误的。GDPO的核心洞察非常简单:不要先把不同奖励混在一起再归一化,而是先分别归一化每个奖励,再组合起来。这个看似微小的改变,却能保留奖励之间的细微差异,避免信号坍缩,从而带来更稳定的训练和更好的性能。实际意义更稳定的训练:避免了GRPO在多目标场景下的早期训练失败
多目标强化学习新突破!NVIDIA揭秘GRPO“缺陷”,GDPO让大模型训练不再"顾此失彼"
原创 ChallengeHub ChallengeHub 2026年1月11日 09:59 北京
在小说阅读器中沉浸阅读
多目标强化学习新突破!GDPO让AI训练不再"偏科",NVIDIA提出优雅解法
研究背景:让AI既准又快,多目标优化的难题
想象一下,你在训练一个AI模型,既希望它回答准确,又希望它的回复简洁高效,还要格式规范。这就像让一个学生同时在数学、语文、体育上都拿高分——听起来很美好,但实际操作中,模型往往会"偏科":可能为了追求准确率,生成了冗长的回答;或者为了控制长度,牺牲了答案质量。
这篇来自NVIDIA的论文揭示了一个被广泛忽视的问题:当前主流的多目标强化学习方法GRPO(Group Relative Policy Optimization)在处理多个奖励信号时,存在严重的"信号坍缩"问题。
核心问题是什么? 研究者发现,GRPO在处理多个奖励时,会把不同的奖励组合"压缩"成相同的优势值(advantage values)。打个比方,假设你有两个二进制奖励(0或1),那么总奖励可能是0、1或2。但GRPO归一化后,奖励为(0,2)和(0,1)这两种明显不同的情况,竟然会得到完全相同的训练信号!这就像老师给两个学生打分,一个得了50分和100分的组合,另一个得了50分和75分,但最后给的评语却一模一样——这显然无法正确引导学习。
研究动机很直接:随着大语言模型能力的提升,用户期待模型不仅要准确,还要在安全性、效率、格式规范等多个维度表现出色。但现有的GRPO方法在多目标场景下表现不佳,甚至会导致训练早期就失败。

论文链接:https://arxiv.org/abs/2601.05242
代码链接:https://github.com/NVlabs/GDPO
项目链接:https://nvlabs.github.io/GDPO/
HF链接:https://huggingface.co/papers/2601.05242
主要贡献包括:
-
首次系统性分析了GRPO在多奖励场景下的"信号坍缩"问题
-
提出GDPO(Group reward-Decoupled normalization Policy Optimization)方法,通过解耦各个奖励的归一化过程来保留奖励之间的细微差异
-
提供了处理不同优先级奖励的系统性方案,特别是当奖励难度差异较大时
-
在工具调用、数学推理、代码生成三个任务上验证了GDPO的有效性
相关工作:GRPO变体与多奖励强化学习的探索
GRPO及其变体的发展脉络
GRPO作为一种高效的策略优化方法,因为不需要额外的价值模型而备受青睐。研究社区在此基础上提出了多个改进版本:
-
GSPO(Group Sequence Policy Optimization)从序列层面而非token层面定义重要性比率,提升了稳定性
-
DAPO引入了更高的裁剪阈值、动态采样、token级策略梯度损失等技术来提升性能
-
GFPO通过过滤响应长度来解决推理过程中的"长度爆炸"问题
-
DLER提出了批次级奖励归一化、更高裁剪阈值等训练配方,在准确率-效率权衡上达到了最优
值得注意的是,最近的Dr.GRPO和DeepSeek-V3.2采用了移除标准差归一化的GRPO变体。虽然这个修改是为了缓解问题级别的难度偏差,但研究者发现它对解决多奖励场景下的信号坍缩问题帮助有限。
多奖励强化学习的应用方向
多奖励RL的应用主要分为两大类:
第一类是建模多样化的人类偏好。比如Safe RLHF将"有用性"和"无害性"解耦,动态调整两者的平衡;RLPHF针对不同(有时甚至冲突)的偏好训练不同的策略模型;ALARM引入层级化奖励结构,联合捕捉响应质量、风格、公平性等维度。
第二类是在保持性能的同时提升推理效率。这在最近的大模型开发中尤为重要。例如,DeepSeek V3.2整合了基于规则的结果奖励、长度惩罚和语言一致性奖励;O1-Pruner和相关工作应用归一化的长度惩罚来压缩响应;L1提出了LCPO方法在优化准确率的同时确保响应不超过目标长度。
但这些工作都默认使用GRPO作为优化方法,很少质疑GRPO本身是否适合多奖励场景——而这正是本文填补的空白。
核心方法:GDPO如何优雅地解决信号坍缩
GRPO的问题本质:信号被"压扁"了
让我们先看一个具体例子来理解问题。假设有两个二进制奖励 ,每个问题生成2个rollout。传统GRPO的做法是:
然后对总奖励进行组内归一化:
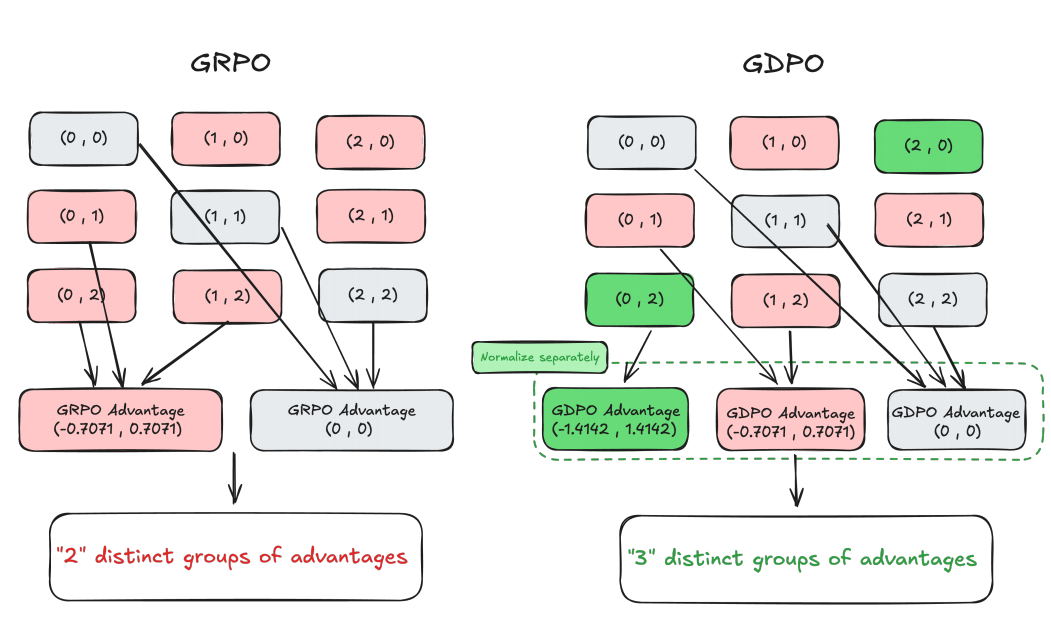
从图2可以看到,虽然有6种不同的奖励组合,但归一化后只剩下2组不同的优势值!比如(0,1)、(0,2)、(1,2)都被映射成了相同的(-0.7071, 0.7071)。直觉上,(0,2)应该产生比(0,1)更强的学习信号,因为总奖励2意味着同时满足了两个目标,而1只满足了一个。但GRPO把它们混为一谈了。
GDPO的核心思想:分开归一化再组合
GDPO的解决方案出奇地简洁优雅——既然问题出在"先求和再归一化",那就改成"先归一化再求和"!
具体来说,GDPO对每个奖励分别进行组内归一化:
然后将归一化后的优势值相加:
这样一来,同样的例子中,(0,1)会得到(-0.7071, 0.7071),而(0,2)会得到(-1.4142, 1.4142),完美保留了两者的差异!
批次级归一化:保持数值稳定
为了确保最终的优势值不会随着奖励数量增加而爆炸,GDPO还加入了批次级归一化:
这一步不改变不同优势组的数量,但能确保训练的数值范围保持稳定。实验表明,去掉这一步偶尔会导致训练失败(见附录A)。
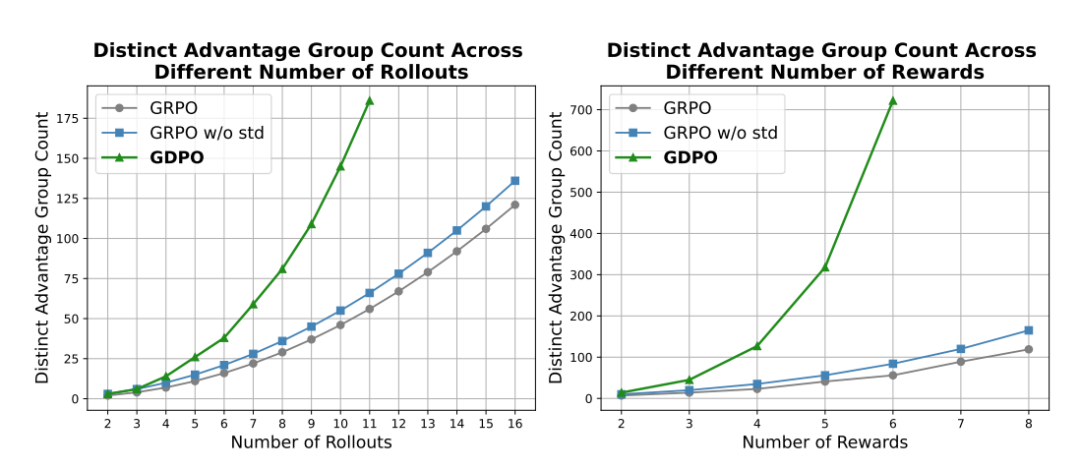
从图3可以看到定量对比:随着rollout数量或奖励数量增加,GDPO保留的不同优势组数量远超GRPO和移除标准差的GRPO变体。这意味着GDPO提供了更丰富、更精确的训练信号。
处理优先级差异的策略
在实际应用中,不同目标的重要性往往不同。论文提供了两种处理方式:
-
调整权重:直接给不同奖励赋予不同权重 。但研究发现,当奖励难度差异很大时,仅调整权重效果有限——模型会倾向于优化更容易的目标,无论权重如何设置。
-
条件化奖励:将简单的奖励条件化到困难的奖励上。例如,只有当正确性奖励 时,才给长度奖励:
这种方法强制模型先满足困难目标,再考虑简单目标,效果显著更好。
三大任务全面验证,GDPO胜于GRPO
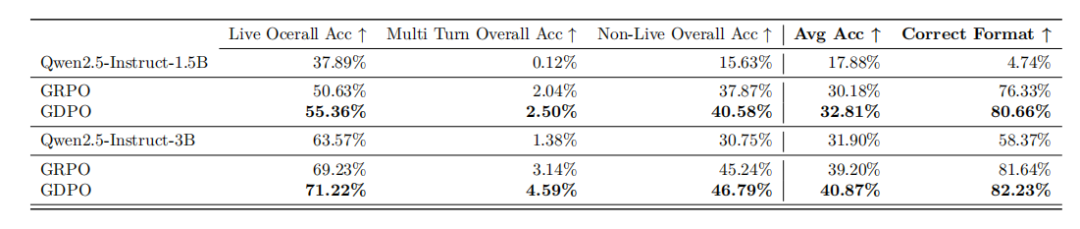
工具调用任务:格式和准确率双提升
在工具调用任务中,模型需要学会按照特定格式调用外部工具。这涉及两个奖励:格式奖励(检查输出是否符合<think>...</think>,<tool_call>...</tool_call>,<response>...</response>的结构)和正确性奖励(评估工具调用与标准答案的匹配度)。
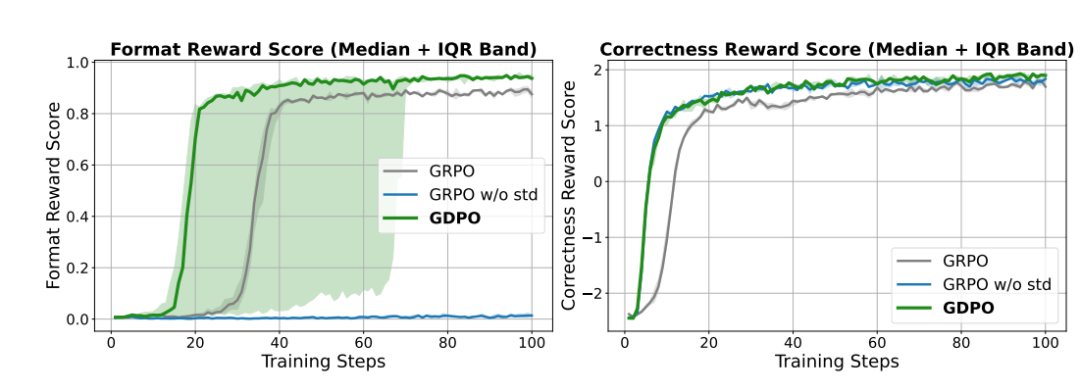
从训练曲线(图4)可以清晰看到:
-
GDPO在格式奖励和正确性奖励上都收敛到更高的值
-
虽然GDPO在格式奖励上收敛步数方差较大,但最终都能达到比GRPO更好的效果
-
移除标准差的GRPO虽然在正确性上与GDPO相当,但格式奖励完全没有提升(收敛到0%!)
在Berkeley Function Call Leaderboard评测中:
-
Qwen2.5-1.5B:GDPO比GRPO在平均准确率上提升2.7%,格式正确率提升4.3%
-
Qwen2.5-3B:GDPO在所有子任务上都优于GRPO,Live/Non-Live任务准确率提升约2%,格式正确率提升0.6%
数学推理任务:准确率与效率的微妙平衡
数学推理任务更具挑战性,因为准确率和长度约束是两个隐式竞争的目标。研究者在DeepScaleR-Preview数据集上训练DeepSeek-R1(1.5B和7B)以及Qwen3-4B,优化正确性奖励和长度奖励。
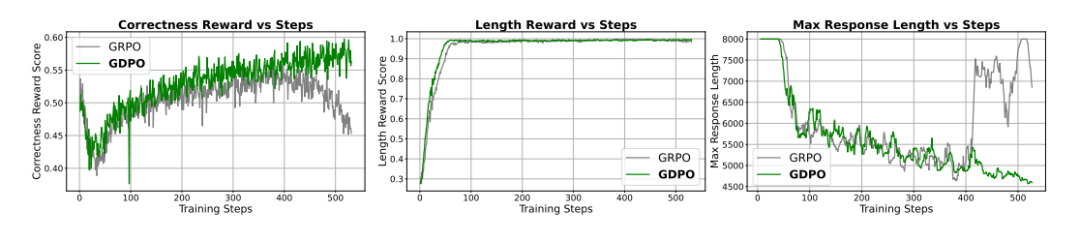
图5展示了训练过程中的有趣现象:
-
两种方法都在前100步快速最大化了更容易的长度奖励,导致正确性奖励短暂下降
-
GDPO能更好地恢复正确性奖励,并持续提升
-
GRPO在400步后出现训练不稳定,正确性开始下降,最大响应长度开始增加
-
GDPO全程保持稳定,正确性持续提升,响应长度控制得更好
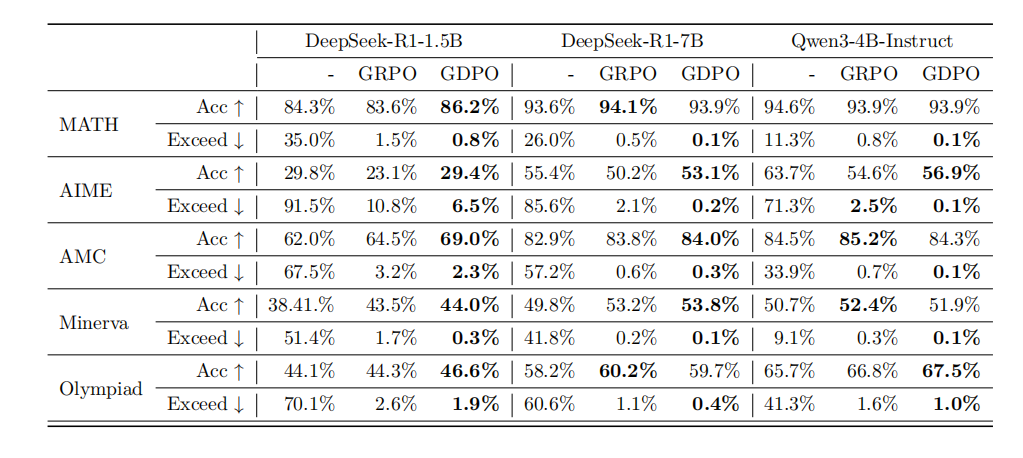
在AIME、AMC、MATH等基准测试中,GDPO展现了全面优势:
-
DeepSeek-R1-1.5B:GDPO在AIME上比GRPO高6.3%,在MATH上高2.6%,同时长度超标率大幅降低(AIME从10.8%降到6.5%)
-
DeepSeek-R1-7B:GDPO在AIME上准确率提升近3%,长度超标率从2.1%降到0.2%
-
在所有任务上,GDPO都实现了更好的准确率-效率权衡
优先级调整实验:条件化奖励的威力
研究者还系统性地研究了如何处理优先级差异。实验发现:
-
仅调整长度奖励权重从1.0降到0.5,长度超标率几乎不变(变化小于1%)
-
只有将权重降到0.25时,才能看到明显的长度约束放松,但代价是准确率下降
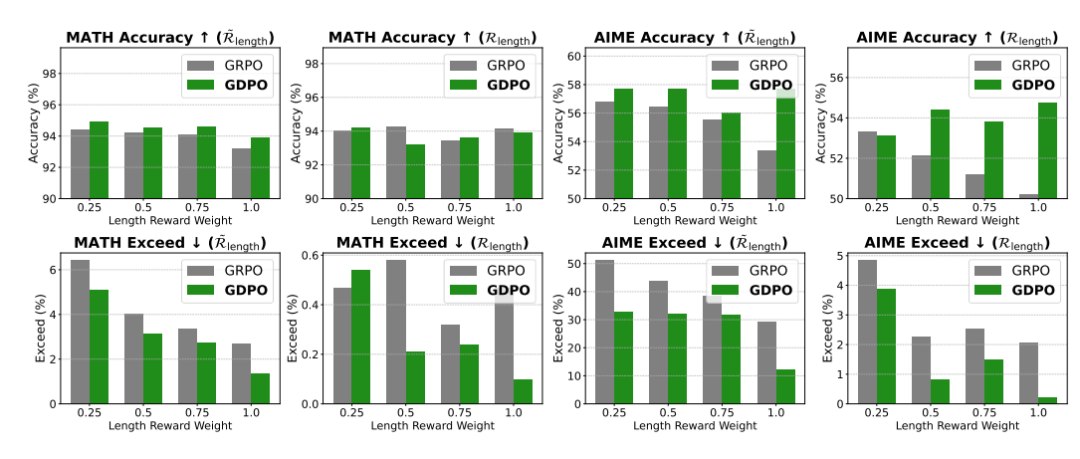
使用条件化长度奖励后(图6):
-
模型不再在训练初期激进地最大化长度奖励,避免了正确性的大幅下降
-
GDPO配合条件化奖励,在AIME上准确率提升4.4%,同时长度超标率反而降低16.9%
-
权重调整变得更可控:降低权重能稳定地增加长度超标率,符合预期
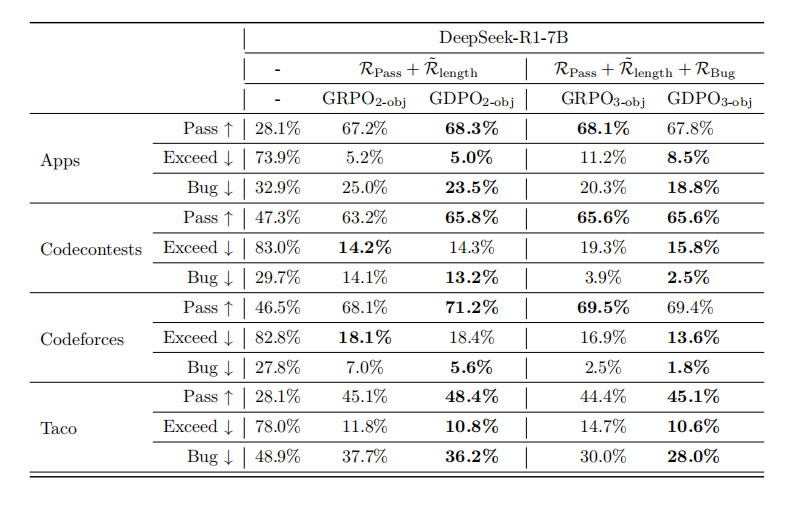
代码推理任务:三目标优化仍然稳健
为了验证GDPO在更多目标下的表现,研究者在代码生成任务上优化了三个奖励:通过率、条件化长度奖励和bug率。
在PRIME基准的四个子任务上:
-
两目标设置:GDPO在所有任务上通过率都高于GRPO(如Codecontests提升2.6%,Taco提升3.3%),同时长度控制相当甚至更好
-
三目标设置:GDPO保持相似的通过率,但在长度超标率和bug率上都显著优于GRPO(如Codecontests的bug率从3.9%降到2.5%)
这证明GDPO的优势不局限于两个奖励,即使在三目标场景下依然有效。
论文总结:简单而优雅的范式转变
这篇论文的价值在于,它揭示了一个被广泛使用但少有人质疑的假设:GRPO适合多奖励优化。通过理论分析和大量实验,研究者证明了这个假设是错误的。
GDPO的核心洞察非常简单:不要先把不同奖励混在一起再归一化,而是先分别归一化每个奖励,再组合起来。这个看似微小的改变,却能保留奖励之间的细微差异,避免信号坍缩,从而带来更稳定的训练和更好的性能。
实际意义体现在多个方面:
-
更稳定的训练:避免了GRPO在多目标场景下的早期训练失败
-
更好的性能:在工具调用、数学推理、代码生成三大任务上全面超越GRPO
-
更灵活的优先级控制:配合条件化奖励,能更好地处理难度差异大的目标
-
易于实现:GDPO的修改很小,已经集成到HF-TRL、verl、Nemo-RL等主流框架
局限性方面,论文主要聚焦于2-3个奖励的场景,对于更多奖励(如5个以上)的扩展性还需要进一步验证。此外,如何自动确定是否需要条件化奖励,以及如何选择合适的阈值,仍然依赖人工经验。
总的来说,GDPO代表了多目标强化学习的一个重要进步。它提醒我们,在追逐复杂的奖励设计之前,应该先确保优化算法本身适合多目标场景。这种回归基础、解决根本问题的研究思路,或许比盲目堆砌技巧更有价值。对于正在训练大语言模型、需要平衡多个目标的研究者和工程师来说,GDPO提供了一个简单但强大的工具,值得在实践中尝试。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献243条内容
已为社区贡献243条内容

所有评论(0)