包教会!本地构建一个实用AI Agent
本地开发的优势在于:开发者可以在熟悉的环境中快速验证想法,无需等待云端部署,同时保持与生产环境一致的代码结构。
Amazon Bedrock AgentCore是一套专为AI Agent设计的企业级基础设施服务。它解决了Agent从原型到生产过程中的核心挑战:
- AgentCore Runtime: Serverless运行时环境,支持最长8小时的任务执行和100MB的请求负载
- AgentCore Memory: 提供短期和长期记忆管理,支持跨会话的上下文保持
- AgentCore Gateway: 统一的工具网关,支持MCP协议的工具发现和调用
- AgentCore Identity: 安全的身份认证和授权管理
本地开发的优势在于:开发者可以在熟悉的环境中快速验证想法,无需等待云端部署,同时保持与生产环境一致的代码结构。
第一部分:环境准备
1.1 安装Python包管理器
建议您使用uv作为Python包管理器,它具有更快的依赖解析速度和更可靠的环境隔离能力。
macOS和Linux系统
curl -LsSf https://astral.sh/uv/install.sh | sh
左右滑动查看完整示意
Windows系统
powershell -c "irm https://astral.sh/uv/install.ps1 | iex"
左右滑动查看完整示意
安装完成后,请重新打开终端以使环境变量生效。
1.2 配置亚马逊云科技凭证
AgentCore需要访问Amazon Bedrock服务,因此需要配置有效的亚马逊云科技凭证。
# 验证当前凭证配置
aws sts get-caller-identity
如果尚未配置凭证,请执行:
aws configure
系统会提示您输入Access Key ID、Secret Access Key、默认区域和输出格式。
1.3 开启模型访问权限
在亚马逊云科技控制台中,导航至Amazon Bedrock服务,在“Model access”页面中启用Anthropic Claude系列模型的访问权限。本文示例使用Claude Sonnet 4模型。
1.4 创建项目并安装依赖
# 创建新项目,指定 Python 版本为 3.13
uv init my-agent-project --python 3.13
# 进入项目目录
cd my-agent-project
# 安装核心依赖包
uv add bedrock-agentcore strands-agents
# 安装开发工具包(用于后续部署)
uv add --dev bedrock-agentcore-starter-toolkit
左右滑动查看完整示意
依赖包说明
- bedrock-agentcore:AgentCore的Python SDK,提供运行时封装和服务集成;
- strands-agents:Strands Agent框架,简化Agent的构建过程;
- bedrock-agentcore-starter-toolkit:部署工具包,提供CLI命令和自动化部署能力
第二部分:构建第一个本地Agent
2.1 创建Agent入口文件
在项目根目录下创建main.py文件:
from bedrock_agentcore import BedrockAgentCoreApp
from strands import Agent
from strands.models import BedrockModel
app = BedrockAgentCoreApp(debug=True)
model = BedrockModel(
model_id="us.anthropic.claude-sonnet-4-20250514-v1:0",
temperature=0.7,
max_tokens=4096
)
agent = Agent(
model=model,
system_prompt="你是一个专业的技术助手,回答问题时准确、简洁。"
)
@app.entrypoint
def invoke(payload):
user_message = payload.get("prompt", "")
ifnot user_message:
return {"error": "prompt 参数不能为空"}
result = agent(user_message)
return {"response": result.message["content"][0]["text"]}
if __name__ == "__main__":
app.run()
左右滑动查看完整示意
2.2 代码逐行解析
下文将详细分析每一部分代码的作用:
导入模块
from bedrock_agentcore import BedrockAgentCoreApp
左右滑动查看完整示意
BedrockAgentCoreApp是AgentCore应用的核心类。它封装了HTTP服务器、请求路由和生命周期管理,使您的Agent代码能够以标准化的方式运行,无论是在本地还是云端。
from strands import Agent
左右滑动查看完整示意
Agent是Strands框架的核心类,负责管理对话流程、工具调用和模型交互。它提供了简洁的API来构建具有推理能力的AI Agent。
from strands.models import BedrockModel
左右滑动查看完整示意
BedrockModel是Bedrock模型的封装类,处理与Amazon Bedrock服务的通信,包括认证、请求格式化和响应解析。
创建应用实例:
app = BedrockAgentCoreApp(debug=True)
左右滑动查看完整示意
创建AgentCore应用实例。debug=True参数启用调试模式,会输出详细的请求和响应日志,便于开发阶段排查问题。在生产环境中,建议将此参数设为False。
配置模型
model = BedrockModel(
model_id="us.anthropic.claude-sonnet-4-20250514-v1:0",
temperature=0.7,
max_tokens=4096
)
左右滑动查看完整示意
- model_id:指定使用的基础模型。这里使用Claude Sonnet 4,us.前缀表示使用美国区域的跨区域推理端点
- temperature:控制输出的随机性,范围0-1。较低的值产生更确定性的输出,较高的值增加创造性
- max_tokens:限制单次响应的最大token数量,防止输出过长
创建 Agent
agent = Agent(
model=model,
system_prompt="你是一个专业的技术助手,回答问题时准确、简洁。"
)
左右滑动查看完整示意
- model:传入上面配置的模型实例
- system_prompt:系统提示词,定义Agent的角色和行为准则。这段文本会在每次对话开始时发送给模型,引导其行为
定义入口函数
@app.entrypoint
def invoke(payload):
左右滑动查看完整示意
@app.entrypoint装饰器将invoke函数注册为Agent的入口点。当收到HTTP请求时,AgentCore会自动调用此函数,并将请求体解析为payload字典传入。
user_message = payload.get("prompt", "")
左右滑动查看完整示意
从请求负载中提取prompt字段。使用get方法并提供默认值,可以安全地处理字段缺失的情况。
ifnot user_message:
return {"error": "prompt 参数不能为空"}
左右滑动查看完整示意
输入验证:确保用户提供了有效的输入。返回的字典会被自动序列化为JSON响应。
result = agent(user_message)
左右滑动查看完整示意
调用Agent处理用户消息。Agent会将消息发送给模型,获取响应,并在需要时执行工具调用。返回的result对象包含完整的对话结果。
return {"response": result.message["content"][0]["text"]}
左右滑动查看完整示意
从结果中提取文本响应并返回。result.message是模型返回的消息对象,content是内容数组,我们取第一个元素的text字段。
启动应用
if __name__ == "__main__":
app.run()
左右滑动查看完整示意
Python的标准入口点检查。当直接运行此文件时,启动HTTP服务器。app.run()默认在0.0.0.0:8080启动服务,这是AgentCore Runtime的标准端口。
2.3 运行和测试
启动Agent
打开终端,在项目目录下执行:
uv run main.py
您将看到类似以下的输出:
INFO: Started server process [12345]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080
左右滑动查看完整示意
发送测试请求
打开另一个终端窗口,使用curl发送请求:
curl -X POST http://localhost:8080/invocations \
-H "Content-Type: application/json" \
-d '{"prompt": "请解释什么是微服务架构"}' | jq .
左右滑动查看完整示意
运行结果示例
{
"response": "微服务架构是一种软件设计模式,它将大型应用程序拆分为多个小型、独立的服务,每个服务负责特定的业务功能。
### 核心特征
**1. 服务独立性**
- 每个微服务可以独立开发、部署和扩展
- 拥有自己的数据库和业务逻辑
- 通过 API 进行通信
**2. 单一职责**
- 每个服务专注于一个业务领域
- 服务边界清晰,功能内聚
**3. 去中心化**
- 没有中央控制器
- 服务间通过轻量级协议通信(如 HTTP/REST、消息队列)
### 主要优势
- **可扩展性**:可针对性地扩展高负载服务
- **技术多样性**:不同服务可使用不同技术栈
- **故障隔离**:单个服务故障不会影响整个系统
- **开发效率**:小团队可独立维护服务
- **部署灵活**:支持持续集成和部署
### 主要挑战
- **复杂性增加**:网络通信、数据一致性问题
- **运维成本**:需要更多的监控和管理工具
- **性能开销**:服务间调用的网络延迟
- **分布式系统问题**:如分布式事务、服务发现
微服务架构特别适合大型、复杂的企业应用,以及需要快速迭代和高可用性的系统。"
}
左右滑动查看完整示意
从响应结果可以看到,Agent成功接收了请求并返回了结构化的回答。响应时间约为9秒,这包括了模型推理的时间。
请求解析:
- -X POST:指定HTTP方法为POST
- http://localhost:8080/invocations:AgentCore的标准调用端点
- -H “Content-Type: application/json”:设置请求头,表明请求体为JSON格式
- -d ‘{“prompt”: “…”}’:请求体,包含发送给Agent的消息
- | jq .:将响应通过jq工具格式化输出(需要预先安装 jq)
第三部分:为Agent添加工具能力
Agent的真正威力在于能够调用外部工具来完成任务。接下来,我们将为Agent添加自定义工具。
3.1 安装工具依赖
uv add strands-agents-tools
左右滑动查看完整示意
strands-agents-tools包含了一系列预构建的工具,如计算器、文件操作等。
3.2 创建带工具的Agent
更新main.py文件:
from bedrock_agentcore import BedrockAgentCoreApp
from strands import Agent, tool
from strands.models import BedrockModel
from strands_tools import calculator
app = BedrockAgentCoreApp(debug=True)
@tool
def get_weather(city: str) -> str:
"""
获取指定城市的当前天气信息。
Args:
city: 城市名称,例如 "北京"、"上海"、"深圳"
Returns:
包含温度和天气状况的字符串
"""
weather_data = {
"北京": "晴天,气温 22°C,湿度 45%",
"上海": "多云,气温 26°C,湿度 65%",
"深圳": "阵雨,气温 28°C,湿度 80%",
}
return weather_data.get(city, f"暂无 {city} 的天气数据")
@tool
def search_database(query: str, limit: int = 5) -> str:
"""
在数据库中搜索相关信息。
Args:
query: 搜索关键词
limit: 返回结果的最大数量,默认为 5
Returns:
搜索结果的摘要信息
"""
return f"找到 {limit} 条与「{query}」相关的记录(模拟数据)"
model = BedrockModel(
model_id="us.anthropic.claude-sonnet-4-20250514-v1:0"
)
agent = Agent(
model=model,
tools=[calculator, get_weather, search_database],
system_prompt="""你是一个智能助手,具备以下能力:
1. 使用 calculator 工具进行数学计算
2. 使用 get_weather 工具查询城市天气
3. 使用 search_database 工具搜索数据库
请根据用户的问题,选择合适的工具来提供准确的答案。"""
)
@app.entrypoint
def invoke(payload):
user_message = payload.get("prompt", "")
ifnot user_message:
return {"error": "prompt 参数不能为空"}
result = agent(user_message)
return {"response": result.message["content"][0]["text"]}
if __name__ == "__main__":
app.run()
左右滑动查看完整示意
3.3 工具定义详解
@tool 装饰器:
@tool
def get_weather(city: str) -> str:
左右滑动查看完整示意
@tool装饰器将普通Python函数转换为Agent可调用的工具。Strands框架会自动:
- 提取函数签名作为工具的输入参数定义
- 解析docstring作为工具的描述信息
- 处理参数类型转换和验证
类型注解的重要性:
def get_weather(city: str) -> str:
左右滑动查看完整示意
- city: str:参数类型注解,告诉模型这个参数应该是字符串类型
- -> str:返回值类型注解,表明函数返回字符串
类型注解不仅是代码文档,更是模型理解工具用法的关键信息。模型会根据这些信息决定如何构造工具调用参数。
Docstring规范:
"""
获取指定城市的当前天气信息。
Args:
city: 城市名称,例如 "北京"、"上海"、"深圳"
Returns:
包含温度和天气状况的字符串
"""
左右滑动查看完整示意
Docstring包含三个部分:
- 第一行:工具的简要描述,模型会用它来判断何时使用此工具
- Args部分:每个参数的详细说明,包括示例值
- Returns部分:返回值的描述
清晰的Docstring能显著提高模型选择和使用工具的准确性。
带默认值的参数
def search_database(query: str, limit: int = 5) -> str:
左右滑动查看完整示意
limit: int = 5定义了一个带默认值的可选参数。模型可以选择是否提供此参数,如果不提供则使用默认值5。
注册工具到Agent
agent = Agent(
model=model,
tools=[calculator, get_weather, search_database],
...
)
左右滑动查看完整示意
tools参数接受一个工具列表。calculator是从strands_tools导入的内置工具,get_weather和search_database是我们自定义的工具。
3.4 测试工具调用
重启Agent后,测试不同类型的请求:
测试计算功能:
curl -X POST http://localhost:8080/invocations \
-H "Content-Type: application/json" \
-d '{"prompt": "计算 (125 + 375) * 2.5 的结果"}' | jq .
左右滑动查看完整示意
Agent会识别这是一个数学计算问题,自动调用calculator工具。
计算功能运行结果
{
"response": "计算结果:(125 + 375) * 2.5 = 1250
计算过程:
1. 先计算括号内:125 + 375 = 500
2. 再乘以 2.5:500 * 2.5 = 1250"
}
左右滑动查看完整示意
测试天气查询
curl -X POST http://localhost:8080/invocations \
-H "Content-Type: application/json" \
-d '{"prompt": "上海今天天气怎么样?"}' | jq .
左右滑动查看完整示意
Agent会调用get_weather工具,传入参数city=“上海”。
天气查询运行结果
{
"response": "上海今天的天气情况:多云,气温 26°C,湿度 65%。
温度适中,湿度稍高,建议外出时携带一把伞以防万一。"
}
左右滑动查看完整示意
测试复合任务
curl -X POST http://localhost:8080/invocations \
-H "Content-Type: application/json" \
-d '{"prompt": "查一下北京的天气,如果温度超过20度,计算开10小时空调需要多少度电(假设功率1.5千瓦)"}' | jq .
左右滑动查看完整示意
这个请求需要Agent协调多个工具:先查询天气获取温度,然后根据条件决定是否进行计算。
复合任务运行结果
{
"response": "让我先查询北京的天气,然后根据温度情况进行计算。
**北京天气**:晴天,气温 22°C,湿度 45%
由于当前温度 22°C 超过了 20 度,我来计算空调用电量:
**计算过程**:
- 空调功率:1.5 千瓦(kW)
- 使用时间:10 小时
- 耗电量 = 功率 × 时间 = 1.5 kW × 10 h = 15 度电
**结论**:开 10 小时空调大约需要消耗 15 度电。按照一般民用电价(约 0.5 元/度)计算,费用约为 7.5 元。"
}
左右滑动查看完整示意
从这个结果可以看到,Agent成功地:
- 调用get_weather工具获取北京天气
- 判断温度(22°C)超过20度
- 调用calculator工具计算用电量
- 综合信息给出完整回答
第四部分:构建MCP Server
Model Context Protocol(MCP)是一种标准化协议,允许Agent动态发现和调用工具。MCP Server可以被任何支持MCP的客户端(如Claude Desktop、Cursor、Kiro等)调用。
4.1 安装MCP依赖
uv add mcp
左右滑动查看完整示意
4.2 创建MCP Server
创建新文件mcp_server.py:
from mcp.server.fastmcp import FastMCP
mcp = FastMCP(
name="Financial Tools Server",
host="0.0.0.0",
stateless_http=True
)
@mcp.tool()
def add_numbers(a: int, b: int) -> int:
"""Add two numbers together"""
return a + b
@mcp.tool()
def multiply_numbers(a: int, b: int) -> int:
"""Multiply two numbers together"""
return a * b
@mcp.tool()
def get_stock_price(symbol: str) -> str:
"""
Get the current stock price for a given symbol.
Args:
symbol: Stock ticker symbol like AAPL, GOOGL, AMZN
Returns:
Stock symbol and current price
"""
prices = {
"AAPL": 178.50,
"GOOGL": 141.20,
"AMZN": 178.90,
"MSFT": 378.50
}
price = prices.get(symbol.upper())
if price:
return f"{symbol.upper()} current price: ${price}"
return f"Price data not found for {symbol}"
@mcp.tool()
def greet_user(name: str) -> str:
"""Greet a user by name"""
return f"Hello, {name}! Nice to meet you."
if __name__ == "__main__":
print("MCP Server 启动中...")
print("MCP 端点: http://localhost:8000/mcp")
mcp.run(transport="streamable-http")
左右滑动查看完整示意
4.3 MCP Server代码解析
导入FastMCP:
from mcp.server.fastmcp import FastMCP
左右滑动查看完整示意
FastMCP是MCP Python SDK提供的高级封装类,简化了MCP Server的创建过程。
创建MCP Server实例:
mcp = FastMCP(
name="Financial Tools Server",
host="0.0.0.0",
stateless_http=True
)
左右滑动查看完整示意
- name:Server的名称,用于标识和日志记录
- host:监听地址,0.0.0.0表示接受所有网络接口的连接
- stateless_http=True:启用无状态HTTP模式,这是AgentCore Runtime要求的配置
定义工具:
@mcp.tool()
def add_numbers(a: int, b: int) -> int:
"""Add two numbers together"""
return a + b
左右滑动查看完整示意
@mcp.tool()装饰器将Python函数注册为MCP工具:
- 函数名成为工具名称
- 参数类型注解定义输入参数的类型
- Docstring成为工具的描述信息
- 返回值类型注解定义输出类型
启动服务:
mcp.run(transport="streamable-http")
左右滑动查看完整示意
transport="streamable-http"指定使用Streamable HTTP传输协议,这是MCP推荐的生产环境传输方式,支持流式响应。
4.4 运行和测试MCP Server
启动服务
uv run mcp_server.py
左右滑动查看完整示意
运行输出
MCP Server 启动中...
MCP 端点: http://localhost:8000/mcp
INFO: Started server process [12345]
INFO: Uvicorn running on http://0.0.0.0:8000
左右滑动查看完整示意
使用Python客户端测试
首先安装MCP客户端依赖(如果尚未安装):
uv add mcp httpx
左右滑动查看完整示意
创建测试客户端文件mcp_client.py:
import asyncio
from mcp import ClientSession
from mcp.client.streamable_http import streamablehttp_client
async def main():
"""测试 MCP Server 的连接和工具调用"""
mcp_url = "http://localhost:8000/mcp"
print(f"连接到 MCP Server: {mcp_url}")
# 建立连接
async with streamablehttp_client(mcp_url)as(
read_stream,
write_stream,
_,
):
async with ClientSession(read_stream, write_stream) as session:
# 初始化会话
await session.initialize()
print("✓ 连接成功\n")
# 列出可用工具
tools = await session.list_tools()
print("可用工具:")
for tool in tools.tools:
print(f" - {tool.name}: {tool.description}")
print("\n" + "=" * 50 + "\n")
# 测试 add_numbers 工具
result = await session.call_tool("add_numbers", {"a": 10, "b": 20})
print(f"add_numbers(10, 20) = {result.content[0].text}")
# 测试 multiply_numbers 工具
result = await session.call_tool("multiply_numbers", {"a": 7, "b": 8})
print(f"multiply_numbers(7, 8) = {result.content[0].text}")
# 测试 get_stock_price 工具
result = await session.call_tool("get_stock_price", {"symbol": "AAPL"})
print(f"get_stock_price('AAPL') = {result.content[0].text}")
# 测试 greet_user 工具
result = await session.call_tool("greet_user", {"name": "开发者"})
print(f"greet_user('开发者') = {result.content[0].text}")
if __name__ == "__main__":
asyncio.run(main())
左右滑动查看完整示意
代码解析
from mcp import ClientSession
from mcp.client.streamable_http import streamablehttp_client
左右滑动查看完整示意
导入MCP客户端所需的模块:
- ClientSession:MCP客户端会话管理类
- streamablehttp_client:Streamable HTTP传输客户端,用于连接使用该协议的MCP Server
async with streamablehttp_client(mcp_url)as(read_stream, write_stream, _):
左右滑动查看完整示意
建立与MCP Server的连接,返回读写流用于双向通信。
async with ClientSession(read_stream, write_stream) as session:
await session.initialize()
左右滑动查看完整示意
创建客户端会话并初始化,这会与服务器交换能力信息。
tools = await session.list_tools()
左右滑动查看完整示意
获取服务器提供的所有工具列表。
result = await session.call_tool("add_numbers", {"a": 10, "b": 20})
左右滑动查看完整示意
调用指定工具,传入参数字典,返回执行结果。
运行测试
确保MCP Server正在运行,然后执行:
uv run mcp_client.py
左右滑动查看完整示意
运行结果
连接到 MCP Server: http://localhost:8000/mcp
✓ 连接成功
可用工具:
- add_numbers: Add two numbers together
- multiply_numbers: Multiply two numbers together
- get_stock_price: Get the current stock price for a given symbol.
- greet_user: Greet a user by name
==================================================
add_numbers(10, 20) = 30
multiply_numbers(7, 8) = 56
get_stock_price('AAPL') = AAPL current price: $178.5
greet_user('开发者') = Hello, 开发者! Nice to meet you.
左右滑动查看完整示意
使用curl测试(CLI方式)
MCP Server使用Streamable HTTP传输协议,需要设置正确的Accept header:
# 初始化连接
curl -X POST http://localhost:8000/mcp \
-H "Content-Type: application/json" \
-H "Accept: application/json, text/event-stream" \
-d '{
"jsonrpc": "2.0",
"id": 1,
"method": "initialize",
"params": {
"protocolVersion": "2024-11-05",
"capabilities": {},
"clientInfo": {"name": "curl-client", "version": "1.0.0"}
}
}'
左右滑动查看完整示意
# 列出可用工具
curl -X POST http://localhost:8000/mcp \
-H "Content-Type: application/json" \
-H "Accept: application/json, text/event-stream" \
-d '{"jsonrpc": "2.0", "id": 2, "method": "tools/list", "params": {}}'
左右滑动查看完整示意
# 调用 add_numbers 工具
curl -X POST http://localhost:8000/mcp \
-H "Content-Type: application/json" \
-H "Accept: application/json, text/event-stream" \
-d '{
"jsonrpc": "2.0",
"id": 3,
"method": "tools/call",
"params": {"name": "add_numbers", "arguments": {"a": 10, "b": 20}}
}'
左右滑动查看完整示意
curl响应示例
列出工具的响应:
{
"jsonrpc": "2.0",
"id": 2,
"result": {
"tools": [
{"name": "add_numbers", "description": "Add two numbers together", ...},
{"name": "multiply_numbers", "description": "Multiply two numbers together", ...},
{"name": "get_stock_price", "description": "Get the current stock price for a given symbol.", ...},
{"name": "greet_user", "description": "Greet a user by name", ...}
]
}
}
左右滑动查看完整示意
调用工具的响应:
{"jsonrpc": "2.0", "id": 3, "result": {"content": [{"type": "text", "text": "30"}]}}
左右滑动查看完整示意
注意:curl命令必须包含 -H “Accept: application/json, text/event-stream” header,否则会收到“Not Acceptable”错误。
使用MCP Inspector测试(可选)
MCP Inspector是一个可视化测试工具,提供图形界面来测试MCP Server:
npx @modelcontextprotocol/inspector
左右滑动查看完整示意
在浏览器中打开http://localhost:6274,选择“Streamable HTTP”传输类型,输入MCP Server地址http://localhost:8000/mcp,即可进行交互式测试。您可以:
- 查看所有可用工具及其参数定义
- 手动调用工具并查看返回结果
- 调试工具执行过程
第五部分:构建A2A Server
Agent-to-Agent(A2A)协议专为多Agents系统设计,允许Agent之间相互发现和通信。A2A使用JSON-RPC格式进行通信,并通过Agent Card描述Agent的能力。
5.1 安装A2A依赖
uv add 'strands-agents[a2a]'
左右滑动查看完整示意
5.2 创建A2A Server
创建新文件a2a_server.py:
import os
import logging
from strands import Agent
from strands.multiagent.a2a import A2AServer
from strands.models import BedrockModel
from strands_tools import calculator
import uvicorn
from fastapi import FastAPI
logging.basicConfig(level=logging.INFO)
# 从环境变量获取运行时 URL,本地开发时使用默认值
runtime_url = os.environ.get(
'AGENTCORE_RUNTIME_URL',
'http://127.0.0.1:9000/'
)
logging.info(f"Runtime URL: {runtime_url}")
# 创建模型
model = BedrockModel(
model_id="us.anthropic.claude-sonnet-4-20250514-v1:0"
)
# 创建 Agent
strands_agent = Agent(
name="Calculator Agent",
description="A calculator agent that can perform basic arithmetic operations.",
model=model,
tools=[calculator],
callback_handler=None
)
# 创建 A2A Server
a2a_server = A2AServer(
agent=strands_agent,
http_url=runtime_url,
serve_at_root=True # 在根路径提供服务
)
# 创建 FastAPI 应用
app = FastAPI(title="Calculator A2A Server")
@app.get("/ping")
def health_check():
"""健康检查端点"""
return {"status": "healthy"}
# 挂载 A2A Server
app.mount("/", a2a_server.to_fastapi_app())
if __name__ == "__main__":
print("A2A Server 启动中...")
print("Agent Card: http://localhost:9000/.well-known/agent-card.json")
print("健康检查: http://localhost:9000/ping")
uvicorn.run(app, host="0.0.0.0", port=9000)
左右滑动查看完整示意
5.3 A2A Server代码解析
导入A2A模块
from strands.multiagent.a2a import A2AServer
左右滑动查看完整示意
A2AServer是Strands SDK提供的A2A协议实现,需要安装strands-agents[a2a]扩展包。
环境变量配置
runtime_url = os.environ.get(
'AGENTCORE_RUNTIME_URL',
'http://127.0.0.1:9000/'
)
左右滑动查看完整示意
从环境变量读取运行时URL,如果未设置则使用本地默认值。**这种设计使同一份代码可以在本地和云端运行,只需通过环境变量切换配置。**部署到AgentCore Runtime时,该环境变量会自动设置。
创建A2A Server
a2a_server = A2AServer(
agent=strands_agent,
http_url=runtime_url,
serve_at_root=True
)
左右滑动查看完整示意
- agent:要暴露的Strands Agent实例
- http_url:Agent的可访问URL,用于生成Agent Card中的端点信息
- serve_at_root=True:在根路径(/)提供服务,这是AgentCore Runtime要求的配置
组合FastAPI应用
app = FastAPI(title="Calculator A2A Server")
@app.get("/ping")
def health_check():
return {"status": "healthy"}
app.mount("/", a2a_server.to_fastapi_app())
左右滑动查看完整示意
我们创建一个FastAPI应用作为容器,添加健康检查端点,然后将A2A Server挂载到根路径。A2A Server默认使用9000端口,与MCP Server(8000)和AgentCore Runtime(8080)区分。
5.3 运行和测试A2A Server
启动服务
uv run a2a_server.py
左右滑动查看完整示意
获取Agent Card
curl http://localhost:9000/.well-known/agent-card.json | jq .
左右滑动查看完整示意
Agent Card是A2A协议的核心概念,它描述了Agent的能力、支持的协议和调用方式。其他Agent可以通过读取Agent Card来了解如何与此Agent交互。
调用Agent(使用JSON-RPC格式)
由于我们创建的是Calculator Agent(计算器Agent),测试请求应该是数学计算相关的问题:
curl -X POST http://localhost:9000/ \
-H "Content-Type: application/json" \
-d '{
"jsonrpc": "2.0",
"id": "request-001",
"method": "message/send",
"params": {
"message": {
"role": "user",
"parts": [
{
"kind": "text",
"text": "请计算 (256 + 128) * 3 的结果"
}
],
"messageId": "msg-001"
}
}
}' | jq .
左右滑动查看完整示意
请求格式解析
- jsonrpc:JSON-RPC协议版本
- id:请求标识符,用于匹配响应
- method:调用的方法,message/send是发送消息的标准方法
- params.message:消息内容
- role:消息角色,user表示用户消息
- parts:消息内容数组,支持多模态(文本、图片等)
- messageId:消息唯一标识
运行结果示例
{
"jsonrpc": "2.0",
"id": "request-001",
"result": {
"artifacts": [
{
"artifactId": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"name": "agent_response",
"parts": [
{
"kind": "text",
"text": "让我来计算这个表达式。\n\n**计算过程:**\n1. 先计算括号内:256 + 128 = 384\n2. 再乘以 3:384 × 3 = 1152\n\n**结果:(256 + 128) × 3 = 1152**"
}
]
}
],
"contextId": "65c4af3b-ef98-4c3a-9433-1287936d9703"
}
}
左右滑动查看完整示意
从响应可以看到,Calculator Agent成功调用了calculator工具完成了数学计算,并返回了详细的计算过程。
第六部分:本地容器化部署
在部署到云端之前,我们可以先在本地使用Docker容器运行Agent。AgentCore Starter Toolkit提供了便捷的CLI命令,可以自动生成Dockerfile并在本地构建运行容器,无需手动编写配置文件。
7.1 配置Agent
首先使用agentcore configure命令配置Agent:
agentcore configure -e main.py
左右滑动查看完整示意
参数说明
- -e main.py:指定Agent的入口文件
如果是首次运行,CLI会以交互式方式引导您完成配置,包括设置Agent名称、选择区域等。您也可以使用-ni(non-interactive)参数跳过交互式提示,使用默认值:
agentcore configure -e main.py -ni
左右滑动查看完整示意
执行后,CLI会在项目目录下生成.agentcore/配置目录,包含配置文件和Dockerfile。
7.2 本地容器运行
使用agentcore launch --local命令在本地Docker容器中构建并运行Agent:
agentcore launch --local
左右滑动查看完整示意
此命令会自动:
- 生成优化的Dockerfile
- 构建容器镜像
- 启动容器并映射端口8080
- 挂载本地亚马逊云科技凭证到容器中
- 输出容器日志到终端
运行输出示例
🏠 Launching Bedrock AgentCore(local mode)...
• Build and run container locally
• Requires Docker/Finch/Podman to be installed
• Perfect for development and testing
Launching Bedrock AgentCore agent 'main' locally
⠏ Launching Bedrock AgentCore...Docker image built: bedrock_agentcore-main:latest
✓ Docker image built: bedrock_agentcore-main:latest
✓ Ready to run locally
Starting server at http://localhost:8080
Press Ctrl+C to stop
Configuration of aws_configurator not loaded, configurator already loaded
Attempting to instrument while already instrumented
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
左右滑动查看完整示意
按Ctrl+C可以停止容器。
注意:agentcore launch --local需要本地安装Docker、Finch或Podman。
7.3 测试容器化Agent
在另一个终端窗口中,发送测试请求:
curl -X POST http://localhost:8080/invocations \
-H "Content-Type: application/json" \
-d '{"prompt": "用 Python 写一个快速排序算法"}' | jq .
左右滑动查看完整示意
运行结果
{
"response": "下面是 Python 实现的快速排序算法:
def quicksort(arr):
# 基准情况:空列表或单元素列表已经有序
if len(arr) <= 1:
return arr
# 选择中间元素作为基准值
pivot = arr[len(arr) // 2]
# 分区:小于、等于、大于基准值的元素
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
# 递归排序并合并结果
return quicksort(left) + middle + quicksort(right)
**算法说明:**
- 时间复杂度:平均 O(n log n),最坏 O(n²)
- 空间复杂度:O(n)(使用了额外的列表)"
}
左右滑动查看完整示意
7.4 本地容器运行的优势
使用agentcore launch --local相比直接uv run main.py有以下优势:
- **环境一致性:**容器环境与云端AgentCore Runtime一致,避免“本地能跑,云端报错”的问题
- **依赖隔离:**所有依赖都在容器内,不会污染本地Python环境
- **真实模拟:**模拟生产环境的资源限制和网络配置
- **快速验证:**在部署到云端前,先在本地验证容器化后的行为
7.5 查看生成的Dockerfile
如果您想了解CLI生成的Dockerfile内容,可以查看:
cat .agentcore/Dockerfile
左右滑动查看完整示意
生成的Dockerfile示例
FROM public.ecr.aws/docker/library/python:3.13-slim
WORKDIR /app
# 安装系统依赖
RUN apt-get update && apt-get install -y --no-install-recommends \
curl \
&& rm -rf /var/lib/apt/lists/*
# 安装 uv 包管理器
RUN curl -LsSf https://astral.sh/uv/install.sh | sh
ENV PATH="/root/.local/bin:$PATH"
# 复制依赖文件并安装
COPY pyproject.toml uv.lock ./
RUN uv sync --frozen
# 复制应用代码
COPY . .
# 暴露端口
EXPOSE 8080
# 启动命令
CMD ["uv", "run", "main.py"]
左右滑动查看完整示意
CLI自动生成的Dockerfile遵循最佳实践,包括多阶段构建优化、依赖缓存等。
第七部分:部署到云端
本地开发和容器化测试完成后,可以使用AgentCore Starter Toolkit将Agent部署到亚马逊云科技。
7.1 使用CLI部署
如果您在第六部分已经执行过agentcore configure,可以直接部署。否则先配置:
agentcore configure -e main.py
左右滑动查看完整示意
部署Agent
agentcore launch
左右滑动查看完整示意
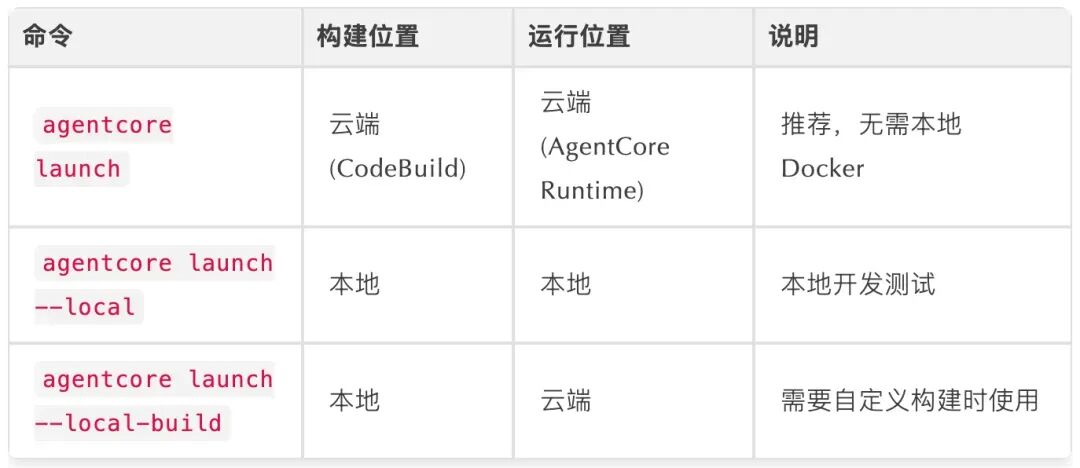
此命令会(默认使用CodeBuild云端构建):
- 使用Amazon CodeBuild构建ARM64容器镜像
- 将镜像推送到Amazon ECR
- 创建AgentCore Runtime
- 等待Runtime就绪
部署模式说明
测试云端Agent
agentcore invoke '{"prompt": "你好,这是来自云端的测试"}'
左右滑动查看完整示意
查看状态
agentcore status
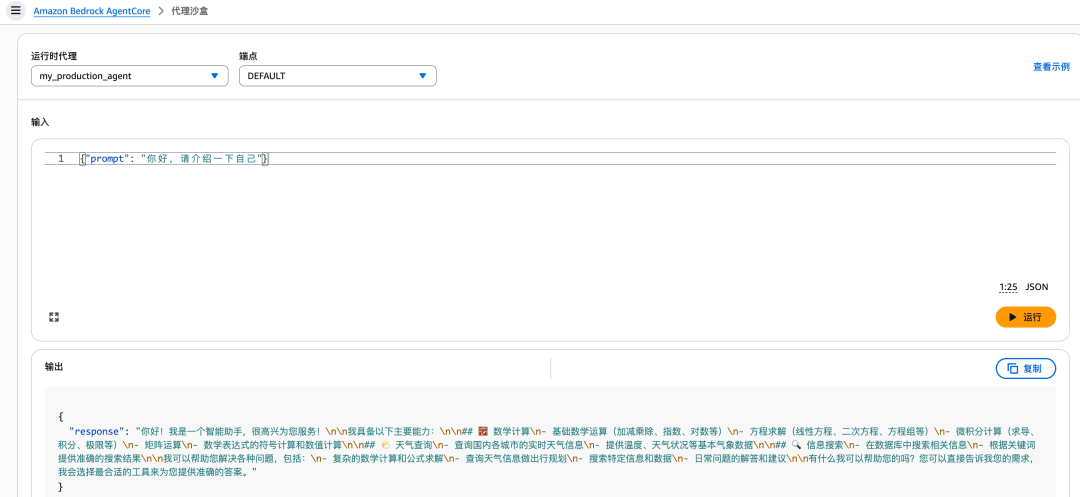
7.2 使用Python SDK部署
对于需要在Jupyter Notebook或Python脚本中进行更多控制的场景,可以使用Python SDK:
from bedrock_agentcore_starter_toolkit import Runtime
from boto3.session import Session
# 获取当前区域
session = Session()
region = session.region_name
# 创建 Runtime 实例
runtime = Runtime()
# 配置部署参数
runtime.configure(
entrypoint="main.py",
auto_create_execution_role=True,
auto_create_ecr=True,
region=region,
agent_name="my_production_agent"
)
# 执行部署(默认使用 CodeBuild 云端构建)
runtime.launch()
print("部署成功!")
# 调用云端 Agent
response = runtime.invoke({
"prompt": "请介绍一下 Amazon Bedrock AgentCore"
})
print(f"响应: {response}")
# 清理资源请使用 CLI: agentcore destroy
左右滑动查看完整示意
配置输出示例
Bedrock AgentCore configured: /path/to/project/.bedrock_agentcore.yaml
🚀 CodeBuild mode: building in cloud(RECOMMENDED - DEFAULT)
• Build ARM64 containers in the cloud with CodeBuild
• No local Docker required
左右滑动查看完整示意
部署模式说明
Python SDK支持与CLI相同的三种部署模式:
# 默认模式:CodeBuild 云端构建 + 云端部署(推荐)
runtime.launch()
# 本地开发模式:本地构建 + 本地运行
runtime.launch(local=True)
# 混合模式:本地构建 + 云端部署
runtime.launch(local_build=True)
左右滑动查看完整示意
7.3 清理资源
# 预览将要删除的资源(不实际删除)
agentcore destroy --dry-run
# 删除所有资源(保留 ECR 仓库,只删除镜像)
agentcore destroy
# 同时删除 ECR 仓库
agentcore destroy --delete-ecr-repo
# 跳过确认提示,直接删除
agentcore destroy --force
左右滑动查看完整示意
第八部分:常见问题与解决方案
8.1 端口占用
问题:启动时提示端口8080已被占用
解决方案:
# 查找占用端口的进程
lsof -i :8080
# 终止进程(将 PID 替换为实际进程 ID)
kill -9 <PID>
左右滑动查看完整示意
8.2 模型访问权限
问题:调用时报AccessDeniedException
解决方案:
- 确认亚马逊云科技凭证有效:aws sts get-caller-identity
- 确认已在Amazon Bedrock控制台开启模型访问权限
- 确认使用的区域支持所选模型
8.3 工具未被调用
问题:Agent没有使用定义的工具
解决方案:
- 检查@tool装饰器是否正确应用
- 确保docstring清晰描述了工具的用途
- 在system_prompt中明确说明可用的工具
- 检查工具是否已添加到Agent的tools列表
8.4 部署超时
问题:agentcore launch执行时间过长
解决方案:
- 检查网络连接是否稳定
- 确认Amazon IAM权限包含Amazon CodeBuild、Amazon ECR、Amazon Bedrock相关权限
- 查看Amazon CodeBuild控制台中的构建日志
8.5 本地容器构建失败:
Multiple top-level modules
问题:执行agentcore launch --local时报错:
Multiple top-level modules discovered in a flat-layout: ['main', 'mcp_server', 'a2a_server', ...]
左右滑动查看完整示意
原因:项目目录中有多个Python文件(如main.py、mcp_server.py、a2a_server.py等),setuptools无法确定哪个是主模块。
解决方案:
在pyproject.toml中添加[tool.setuptools]配置,明确指定要打包的模块:
[project]
name = "my-agent-project"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.13"
dependencies = [
"bedrock-agentcore>=1.1.1",
"strands-agents>=1.19.0",
"strands-agents-tools>=0.2.17",
]
[dependency-groups]
dev = [
"bedrock-agentcore-starter-toolkit>=0.2.4",
]
[tool.setuptools]
py-modules = ["main"] # 只打包 main.py 作为主模块
左右滑动查看完整示意
添加[tool.setuptools]部分后,重新运行agentcore launch --local即可。
8.6 本地容器运行时OTLP导出错误
问题:执行agentcore launch --local后,
日志中出现大量重试警告
Transient error StatusCode.UNAVAILABLE encountered while exporting traces to localhost:4317, retrying in 1s.
Transient error StatusCode.UNAVAILABLE encountered while exporting logs to localhost:4317, retrying in 2s.
左右滑动查看完整示意
原因:容器内的OpenTelemetry尝试将追踪数据发送到localhost:4317(默认OTLP端点),但本地没有运行OTLP接收服务。
解决方案:
这个警告不影响Agent正常运行,可以忽略。如果想消除警告,可以禁用OTLP导出:
agentcore launch --local \
--env OTEL_TRACES_EXPORTER=none \
--env OTEL_LOGS_EXPORTER=none
左右滑动查看完整示意
总结
本文详细介绍了Amazon Bedrock AgentCore的本地开发流程:
- **环境搭建:**安装uv、配置亚马逊云科技凭证、创建项目
- **基础Agent:**使用BedrockAgentCoreApp和Strands Agent构建简单的对话Agent
- **工具集成:**通过@tool装饰器定义自定义工具,扩展Agent能力
- **MCP Server:**构建MCP服务,支持工具发现和调用
- **A2A Server:**构建支持Agent间通信的服务
- **本地容器化:**使用agentcore launch --local在本地模拟生产环境
- **云端部署:**使用agentcore launch一键部署到亚马逊云科技
**通过本文的学习,您已经掌握了从本地开发到容器化测试,再到云端部署的完整流程。**这种渐进式的开发方式能够帮助您:
- 在本地快速验证Agent逻辑
- 通过容器化确保环境一致性
- 无缝迁移到AgentCore Runtime生产环境
本地开发与云端部署的无缝衔接,使开发者能够在保持高效迭代的同时,确保代码在生产环境中的可靠运行。
相关资源
1.Amazon Bedrock AgentCore官方文档
https://docs.aws.amazon.com/bedrock/latest/userguide/agentcore.html
2.Strands Agents SDK文档
https://strandsagents.com/
3.MCP协议规范
https://modelcontextprotocol.io/
4.A2A协议规范
https://google.github.io/A2A/
5.AgentCore Starter Toolkit
https://github.com/aws/bedrock-agentcore-starter-toolkit
6.AgentCore Python SDK
https://github.com/aws/bedrock-agentcore-sdk-python
7.A2A协议规范
https://a2a-protocol.org/
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 27
27 0
0- 0



 已为社区贡献546条内容
已为社区贡献546条内容

所有评论(0)