大模型化身苏格拉底:通过主动提问挖掘人机协作的深度
大语言模型正在从单纯的文本生成工具演变为解决推理任务的合作伙伴,无论是起草法律文书、调试代码还是撰写学术论文,用户对 AI 的期望已不再止于执行指令,而是希望其能作为思维伙伴参与到多轮对话中。现实情况是用户的初始提示词往往充满了信息不对称。用户以为自己说清楚了,或者用户默认 AI 知道某些背景,但实际上模型只能看到显性的文本。现有的模型在面对这种模糊性时,通常采取一种避重就轻的策略。它们倾向于通过
由被动答复者向主动思维伙伴进化的关键一步,在于大语言模型能否学会像人类专家一样,在信息缺失时主动追问那些决定成败的隐性细节。

微软与南加州大学联合团队发表的,被顶会 EMNLP 2025 接收的研究成果,揭示了一种通过强化学习激发大模型主动提问能力的新范式,让AI学会了如何审题和挖掘。
我们习惯了向 AI 提问并期待即时回答,却很少意识到这种一问一答的模式正在限制解决复杂问题的上限,真正的高质量协作往往始于 AI 对我们的反向提问。
当前的大语言模型在处理明确指令时表现优异,但在面对现实世界中普遍存在的模糊、不完整需求时,往往显得束手无策。
它们要么给出一个泛泛而谈的万金油回复,要么提出一些无关痛痒的表面问题。
这种被动性导致模型无法触及用户未言明的核心需求,那些深藏在用户脑海中的领域知识、隐性约束和具体偏好。
研究团队提出了一种全新的任务范式:主动信息收集(Proactive Information Gathering)。
这不仅仅是让 AI 多问几个问题,而是要通过强化学习(Reinforcement Learning)训练模型敏锐地感知信息真空,精准地向用户索取那些能够决定任务成败的关键拼图。
定义模糊时代的协作新标准
大语言模型正在从单纯的文本生成工具演变为解决推理任务的合作伙伴,无论是起草法律文书、调试代码还是撰写学术论文,用户对 AI 的期望已不再止于执行指令,而是希望其能作为思维伙伴参与到多轮对话中。
现实情况是用户的初始提示词往往充满了信息不对称。用户以为自己说清楚了,或者用户默认 AI 知道某些背景,但实际上模型只能看到显性的文本。
现有的模型在面对这种模糊性时,通常采取一种避重就轻的策略。它们倾向于通过询问澄清性问题来解决表面的歧义。
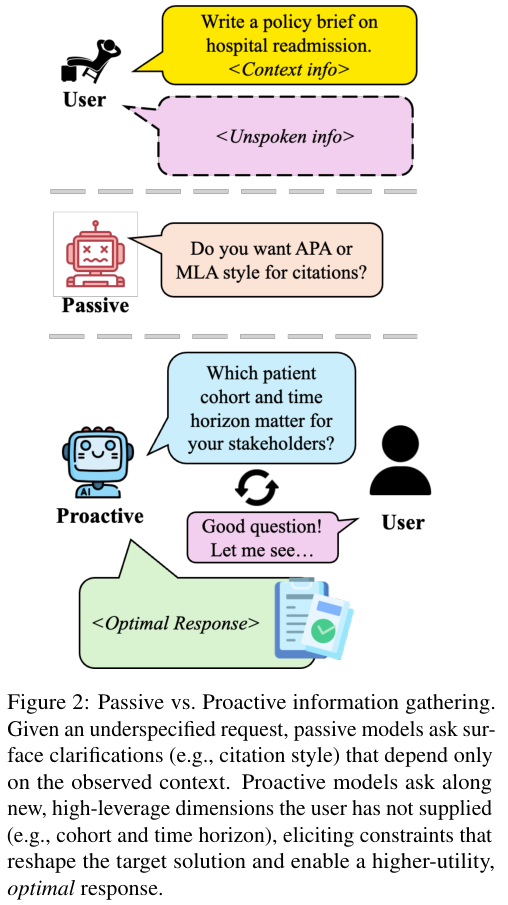
例如,当用户要求写一份关于医院再入院的政策简报时,被动模型可能会问关于文章长度或引用格式的问题。这些问题虽然能消除形式上的不确定性,但对于提升内容的实质质量毫无帮助。
一个真正高水平的合作伙伴会意识到,要写好这份简报,必须知道针对哪些利益相关者、关注哪个时间段的患者队列以及有什么特定的政策约束。
为了系统性地研究这一能力,研究人员形式化定义了主动信息收集任务。
在这个框架下,任务信息被严格划分为显性信息(Explicit Information)和隐性信息(Implicit Information)。
显性信息是用户直接提供的目标和上下文,而隐性信息则包含了完成高质量回复所必需的、但未直接说明的假设、领域惯例和细粒度要求。
模型的最终目标是产出一个与理想解决方案高度对齐的输出,而这个理想方案依赖于显性和隐性信息的结合。
由于隐性信息在初始阶段对助手不可见,助手必须通过策略性的提问,从持有完整信息的用户那里引出这些关键信息。
这种转变在不同学科中已成趋势。

如图所示,无论是在社会科学、人文还是理工科,协作式交互的比例都超过了直接问答。
这意味着,能够进行多轮深度对话、主动消除歧义的模型,才是未来人机交互的主流。
然而,现有的数据并不支持这种能力的训练。高质量的协作对话数据稀缺且难以规模化,众包数据往往质量参差不齐,无法捕捉到领域专家那种一针见血的提问能力。
更深层次的挑战在于奖励机制的设计。
什么样的提问才算是好问题?是有用性、新颖性还是上下文的互补性?
这些指标不仅主观,而且难以用简单的启发式规则来衡量。
如果仅依靠最终生成的长文本来评估,反馈信号会变得极其稀疏,在多轮对话的早期,很难判断一个问题是否对最终那篇 500 字的文章有贡献。
研究团队利用 DOLOMITES 数据集构建了一个合成对话引擎。
DOLOMITES 包含 519 个任务模板,覆盖医学、法律、土木工程等 25 个专业领域。
为了适应主动信息收集的任务设定,研究者对数据进行了巧妙的改造:将每个任务实例拆解为四元组,分别代表任务目标(Objective)、任务过程/领域提示(Procedure)、输入信息(Input Context)和输出规范(Output Specification)。
在实验设置中,显性信息仅包含任务目标和输入信息,这是模拟真实用户通常会给出的不完整提示。
而隐性信息则包含过程知识和输出规范,这部分信息被掩盖起来,不可见于模型,但对于生成高质量内容至关重要。模型必须通过提问,将这些隐性信息挖掘出来。
这种掩码机制(Masking Scheme)创造了一个部分可观察的马尔可夫决策过程(POMDP)。
助手模型必须在有限的对话轮次内(实验中设定为最多 5 轮),决定是继续提问以获取更多信息,还是停止提问开始起草回复。
这不仅考验模型的语言生成能力,更考验其对信息价值的判断策略。
基于证据发现的强化微调策略
解决这个问题的核心创新在于一种专门设计的强化微调(Reinforcement Fine-Tuning, RFT)策略。
传统的监督微调(SFT)依赖于模仿人类或更强模型的对话记录,但在主动提问这个任务上,SFT 表现出了明显的局限性。
它倾向于让模型记住提问的句式,而不是学会提问的逻辑。
为了真正教会模型思考该问什么,研究者引入了强化学习中的近端策略优化(PPO)算法,并设计了一个关键的奖励信号:证据句子奖励(Evidence-Sentence Reward)。
这个奖励机制的设计直觉非常朴素却有力:一个好的提问,应该能从用户那里引出之前完全未知的信息。
在模拟对话中,当助手模型提出一个问题时,扮演用户的 Oracle 模型会根据其掌握的全部信息(包括显性和隐性)来回答。
系统会检查这个回答引用了隐性信息中的哪些句子。如果回答的内容确实源自那些被掩盖的隐性字段(即隐性信息集合,模型就会获得即时奖励1;否则,奖励为 0。

这种二元奖励机制极大地简化了学习目标,同时保证了方向的正确性。
它直接激励模型去触碰那些它不知道的领域,而不是在已知信息里打转。
与传统的基于最终文本质量的稀疏奖励相比,这种每一步都能获得反馈的密集奖励信号,极大地加速了模型的训练收敛。

为了验证这一方法的有效性,研究团队基于 Qwen-2.5-7B 模型进行了为期三个周期的微调。
训练使用了 8 张 A100 GPU,采用 verl 框架实现 PPO 算法。
训练过程中,每次对话的提问轮次预算被设定为 5 次。
除了针对提问的奖励,训练还引入了一个冻结的 LLM 裁判,对模型最终生成的草稿进行评分,确保模型不仅会问问题,还能利用问到的信息写出好文章。
实验对比了多种基线模型,包括:
-
GPT-4o Direct:不提问,直接硬写的盲答模式。
-
Vanilla LLMs with QA:利用提示词(Prompting)让 GPT-4o、o3-mini 和 Qwen-2.5-7B-Instruct 尝试提问。
-
SFT LLMs:在合成对话数据上进行监督微调的模型。
结果显示,经过 RFT 训练的 Qwen-2.5 模型展现出了压倒性的优势。
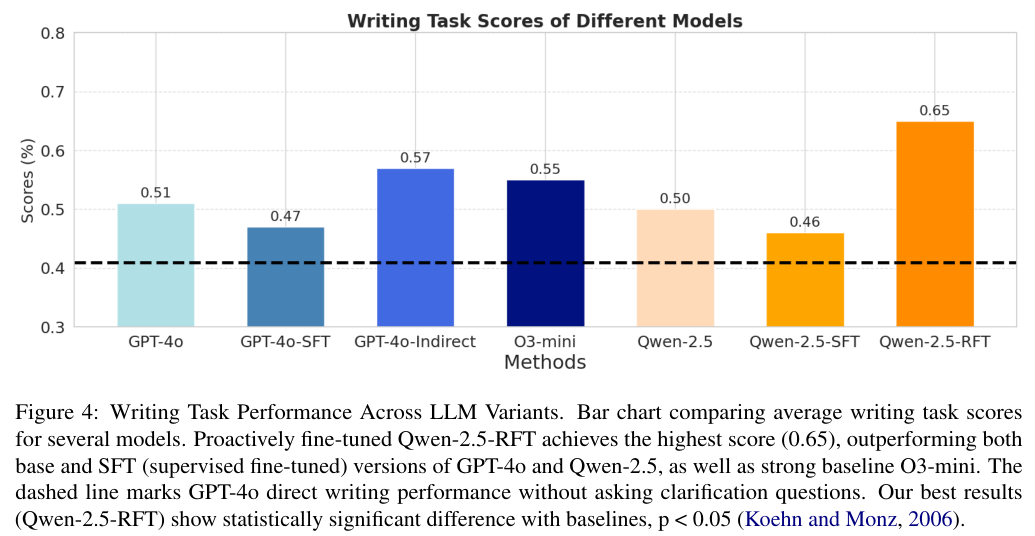
从图中可以清晰地看到,Qwen-2.5-RFT 的得分为 0.65,比直接回答的 GPT-4o(0.51)高出了 27%,比拥有强大推理能力的 o3-mini(0.55)也高出了 18%。
这是一个非常显著的提升,特别是考虑到基座模型只是 7B 参数量的 Qwen-2.5,而对手是闭源的顶尖大模型。
更令人惊讶的是,监督微调(SFT)的效果并不理想。
GPT-4o-SFT(0.47)和 Qwen-2.5-SFT(0.46)的表现甚至不如它们的原始版本。
这表明,仅仅让模型模仿提问的形式,并不能赋予它在未见场景下进行情境化主动提问的能力。
SFT 模型往往学到了形而未得神,提出的问题虽然通顺,但缺乏针对性,无法触及核心信息。
而 RFT 带来的收益则是实打实的策略进化。
深入剖析主动提问的质量维度
除了自动化的评分指标,研究团队还通过热力图分析了模型提问时关注的信息分布。
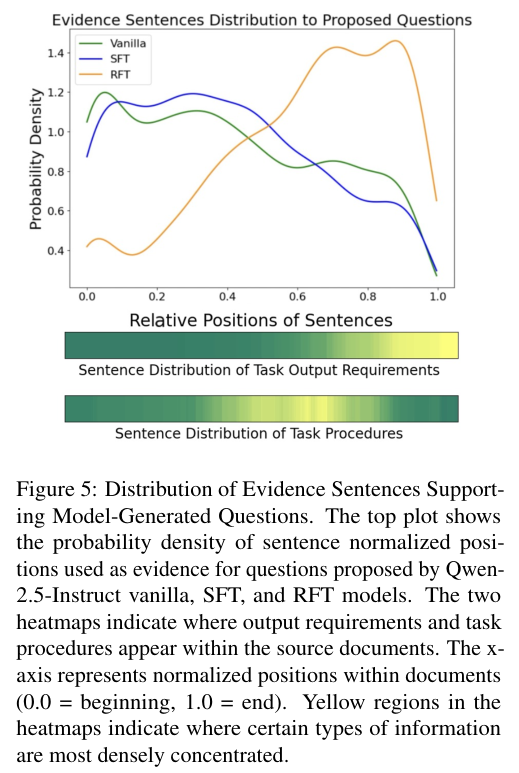
图中展示了模型生成的提问所引出的证据在文档中的位置分布。
对比分析发现,Vanilla(原版)和 SFT 模型的提问倾向于集中在文档的已有信息部分,或者是那些容易猜到的通用信息上。
而 RFT 模型(橙色曲线)的关注点与文档中任务过程和输出要求(底部热力图的黄色高亮区域)的分布高度重合。
这证明了 RFT 模型通过奖励信号,学会了精准定位那些通常被隐藏的关键信息区域。
在不同领域的细分测试中,RFT 模型的鲁棒性得到了进一步验证。
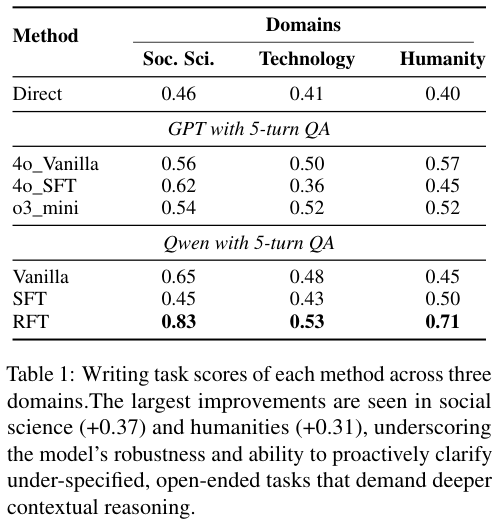
如表所示,在社会科学、技术和人文学科这三个主要领域,RFT 模型都取得了最佳成绩。
这种在社会科学和人文领域的巨大优势(分别提升了 0.37 和 0.31 分)尤为值得玩味。
这些领域的任务通常更加开放,缺乏标准化的流程,更加依赖对背景、受众和隐性规则的理解。
相比之下,技术类任务往往有更明确的程序性逻辑。
RFT 模型在复杂、模糊领域的高分表现,恰恰证明了其主动挖掘策略在解决非结构化问题时的巨大价值。
为了直观展示这种差异,研究者在文中列举了一个小学二年级数学教案编写的具体案例。
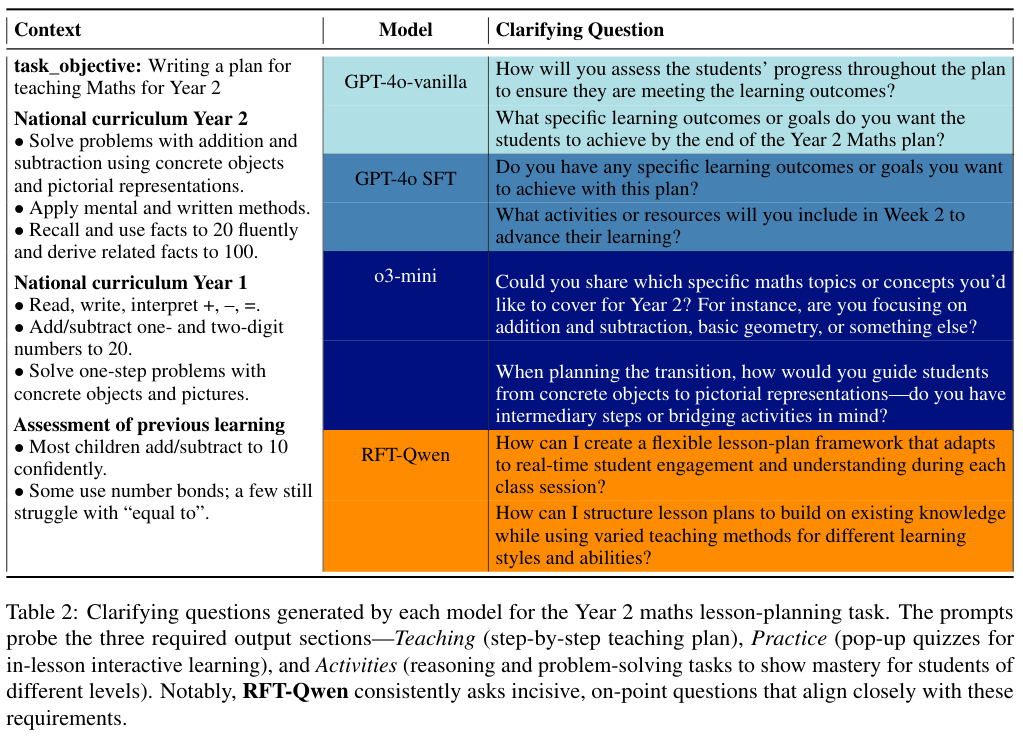
在这个案例中,GPT-4o 问的是通用的评估方法和学习目标,o3-mini 试图缩小数学主题的范围。
这些问题固然合理,但略显平庸。相比之下,RFT-Qwen 提出的问题(如何构建灵活的框架以适应实时课堂参与度以及如何针对不同学习风格构建基于已有知识的教学计划)展现出了极强的教学法洞察力。
这些问题直接对应了被隐藏的高阶要求(如教学活动、练习设计),能够引导出一份兼具深度和广度的教案。
人类评估的结果也支持了这一结论。

在盲测中,人类评估员在 62% 的情况下认为 RFT-Qwen 的提问优于 o3-mini,在 50% 的情况下认为 RFT-Qwen 最终生成的教案大纲更好。
这说明,机器通过强化学习获得的提问直觉,不仅能骗过算法判分器,更能真正打动人类专家。
从应答者到思想者的进化
这项研究最激动人心的意义在于它重新定义了大模型在人类工作流中的角色。
过去,我们把 LLM 当作一个知识渊博但被动的百科全书或打字员,我们必须小心翼翼地设计提示词(Prompt Engineering),生怕漏掉一个细节导致输出偏差。
RFT 模型的出现暗示了一种新的可能性:我们只需要给出一个模糊的意图,AI 就有能力通过几轮高质量的追问,帮助我们将意图具体化、结构化。
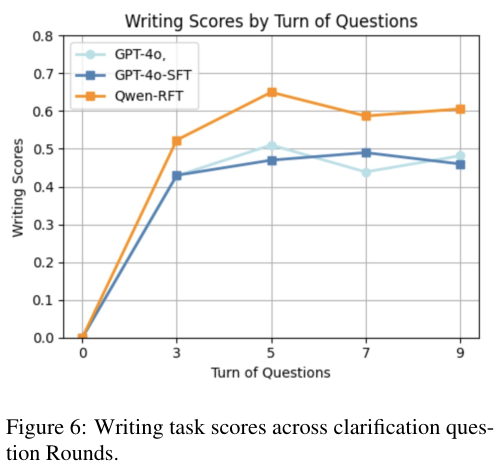
从图中的轮次分析中可以看出,普通模型在问了 3 轮之后,再问更多问题对结果已经没有帮助了,甚至可能因为引入噪音而变差。
但 RFT 模型随着对话轮次的增加,表现持续上升,在 5 轮时达到顶峰。这说明它具备了长程规划和持续挖掘信息的能力,知道如何利用每一次交互机会来累积价值。
这种能力让 AI 不再仅仅是任务的执行者,而是变成了任务的共同定义者。
在头脑风暴式的评估中,人类评估员特别指出,好的提问应该是鼓舞人心的(inspiring),能够开启新的视角。RFT 模型学到的正是这种能力——它不是在为了问而问,而是在为了更好的结果而探索。
当然,该研究目前仅在 DOLOMITES 这一个基准上进行了验证,且主要侧重于单轮的主动澄清(尽管在多轮设置下评估,但策略偏向单步优化)。
未来的研究方向将是更复杂的多轮博弈,甚至包括与用户的谈判和动态意图对齐。
这项工作向我们展示了 AI 进化的下一个阶段:不仅仅是回答问题,而是提出正确的问题。
参考资料:
https://aclanthology.org/2025.findings-emnlp.843/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献190条内容
已为社区贡献190条内容

所有评论(0)