引导式问答-主动式思维链提示-ProCoT
为弥补现有 LLM 在主动对话中的不足,本文提出一种**主动式思维链提示方法(Proactive Chain-of-Thought, ProCoT)**,旨在通过显式引导大语言模型进行**目标导向的推理与规划**,从而提升其在多种主动对话场景下的决策与交互能力。
论文:Prompting and Evaluating Large Language Models for Proactive Dialogues: Clarification, Target-guided, and Non-collaboration
会议:emnlp 2023
作者:Yang Deng et al.
一、动机 & 问题背景
当前 LLM 驱动的对话系统能够进行相对准确的回答,但不擅长主动;而真实可用的对话系统必须具备主动性。
主动对话(Proactive Dialogue):
对话系统主动对话不仅被动回应用户输入,而是能够判断何时需要介入、能够提前规划对话目标、 能够在多种行动之间做策略性选择
单一LLM 在真实对话中存在的主动性问题:
(1)模糊问题下,不会主动澄清
用户问的问题 本身不完整 / 有歧义,但 LLM 往往猜一个答案或给出泛化、错误的回答。
(2)有明确系统目标时,不会引导对话
推荐系统想推荐某个目标物品,任务型对话有隐藏目标。LLM 往往话题跳转太直接 或 完全丢失目标。
(3)非合作场景下,没有主动问询的策略
如讨价还价、说服、谈判; LLM 容易妥协,缺乏策略规划, 不会为了自身目标而对话。
为了提高基于LLM的对话的主动性,本文提出了主动式思维链提示Proactive Chain-of-Thought(ProCoT)方案。
二、ProCoT 方案概述
为弥补现有 LLM 在主动对话中的不足,本文提出一种主动式思维链提示方法(Proactive Chain-of-Thought, ProCoT),旨在通过显式引导大语言模型进行目标导向的推理与规划,从而提升其在多种主动对话场景下的决策与交互能力。
2.1 设计核心
传统的 Prompting 方法通常将对话建模为一个条件文本生成问题,即在给定对话历史和任务背景的情况下,直接生成下一轮回复。这种方式忽略了对话中隐含的决策过程,使模型难以判断“是否该回答、该如何回答、回答是否有利于长期目标”。
ProCoT 的核心思想是:
在生成回复之前,显式引导模型进行一次“对话层面的思考与规划”,而非仅在词级或句级进行表面推理。
通过将“思考—决策—生成”这一过程结构化,模型能够更好地模拟人类在对话中的主动行为。
2.2 三种 Prompting 方案的层级演进
如下图所示,本文描述了Prompting方案,包括Standard、Proactive和主动思维链(ProCoT)提示三个层级: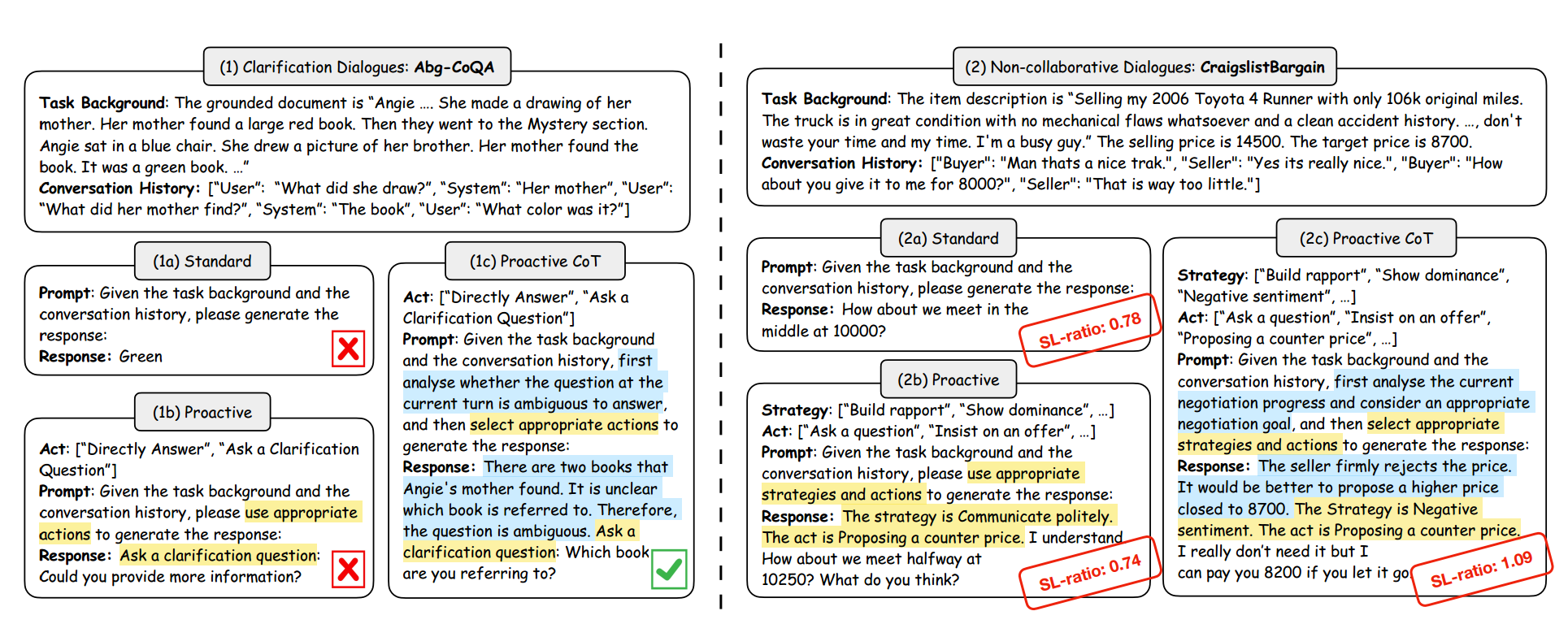
(1)Standard Prompting(标准提示)
标准提示仅要求模型根据任务背景和对话历史直接生成回复,其形式可表示为:
p ( r ∣ D , C ) p(r \mid D, C) p(r∣D,C)
其中,D 表示任务背景,C 表示对话历史,r 为生成的回复。
该方式完全依赖模型的语言生成能力,不具备显式的决策或规划机制,因此在面对模糊输入或复杂对话目标时往往表现被动。
Standard Prompting为了指导LLM执行特定的对话任务,典型的提示方案可以表述为:给定任务背景D和会话历史C,指示LLM生成响应r。具体地,任务背景可以是澄清对话中的基础文档或目标引导对话中的目标描述
(2)Proactive Prompting(主动式提示)
为增强模型的决策意识,主动式提示引入了**对话行动(Dialogue Act / Strategy)**的选择过程:
p ( a , r ∣ D , C , A ) p(a, r \mid D, C, A) p(a,r∣D,C,A)
其中,A 为预定义的行动集合,模型需先选择合适的行动 a,再据此生成回复 r。
Proactive Prompting 主动提示旨在为LLM提供替代选项,以决定应在响应中采取何种行动,而不是简单地响应指令。
给定任务背景D、对话历史C和一组可能的对话动作A,指示LLM选择最合适的对话动作a ∈ A,然后生成响应r。
例如,对话行为可以是在澄清对话中提出澄清问题或直接回答问题,在非协作对话中采用不同的协商策略,或者在目标引导对话中采用不同的对话主题。
该方法在一定程度上缓解了盲目回复的问题,但其行动选择仍然是局部且静态的,缺乏对整体对话目标和长期收益的系统性规划。
(3)Proactive Chain-of-Thought Prompting(ProCoT)
Proactive Chain-of-Thought Prompting 通过执行动态推理和计划来分析下一步要采取的行动,以实现会话目标。
ProCoT 在主动式提示的基础上,引入了一个关键变量——思维链(Thought),将对话生成过程扩展为:
p ( t , a , r ∣ D , C , A ) p(t, a, r \mid D, C, A) p(t,a,r∣D,C,A)
其中,t 表示模型在当前轮次中对对话状态、目标进展和潜在风险的分析与规划过程。例如,在澄清对话中,t可以是当前用户问题的歧义分析,如上图(1c)所示。而在非协作对话中,t可以是当前谈判进度的目标完成分析,如上图(2c)所示。
在该框架下,模型需要完成以下三个步骤:
-
状态分析与目标评估
判断当前用户输入是否存在歧义、是否偏离对话目标、当前对话所处阶段等; -
行动规划与决策
基于上述分析,选择最合适的对话行动或策略; -
基于行动的响应生成
生成与所选行动一致、且符合长期目标的自然语言回复。
2.3 ProCoT 的核心特性
ProCoT 具有以下几个关键特征:
-
目标导向性:
思维链围绕对话目标展开,而非仅服务于局部语言生成; -
决策可解释性:
通过显式生成中间思考过程,使模型的行动选择更加透明; -
任务通用性:
统一适用于澄清对话、目标引导对话和非合作对话等多种主动对话场景; -
无需模型参数更新:
仅通过 Prompt 设计即可激发模型的规划能力,适合零样本或少样本场景。
2.4 方法直观理解
从更直观的角度来看,ProCoT 并非简单地让模型多想一步,而是先规划再回复,即将对话从“语言生成任务”提升为“序列决策问题”:模型不再只是回答“说什么”, 而是先思考“现在该做什么”,再决定“怎么说”。
这一转变是实现主动对话能力的关键,也是 ProCoT 相较于传统 Prompting 方法的本质区别。
三、测试与评估(Evaluation)
为系统性验证大语言模型在 主动对话(Proactive Dialogue) 场景下的能力,本文围绕三类典型对话任务进行了全面评估,分别对应主动对话中的三种核心能力:
- 提问澄清问题的时刻(澄清能力)
- 围绕目标逐步引导对话的能力(目标导向能力)
- 非合作场景下进行策略性交互的能力(对抗与谈判能力)
在每一类任务中,本文均对比了不同 Prompting 策略(Standard / Proactive / ProCoT),并结合自动指标与人工评估进行分析。
3.1 澄清对话任务(Clarification Dialogues)
3.1.1 任务定义
澄清对话关注的问题是:
当用户输入本身存在歧义或信息缺失时,对话系统能否意识到“现在不该直接回答”,并主动提出恰当的澄清问题?
该能力是主动对话系统的基础,否则系统只能被动猜测用户意图。
本文将澄清对话拆解为两个子任务:
(1)澄清需求预测(Clarification Need Prediction, CNP)
判断当前用户输入是否需要进一步澄清,是一个二分类任务。
(2)澄清问题生成(Clarification Question Generation, CQG)
在需要澄清的前提下,生成一个有针对性、信息增益高的澄清问题。
3.1.2 测试数据集
本文选用了两个难度不同、领域不同的数据集:
-
Abg-CoQA
通用领域澄清对话数据集,主要考察模型的基础澄清能力。 -
PACIFIC
金融领域澄清对话数据集,包含大量专业术语和隐含约束,对模型的领域理解能力要求更高。
3.1.3 评估指标与结果分析
本文在零样本设置下,对比了上述三类方法。
其中,ProCoT 要求模型在生成回复前,显式输出其对当前对话是否存在歧义的分析,以及提出澄清的理由。
(1) 自动评估
- Helpfulness:判断模型是否正确识别澄清需求
- BLEU / ROUGE:评估生成澄清问题与参考问题的相似度
结果表明:
- Standard Prompting 几乎无法触发澄清行为
- Proactive Prompting 对 ChatGPT 有一定提升,但效果不稳定
- ProCoT 显著提升澄清识别与问题生成质量
(2) 人工评估
人工评估主要关注:
- 澄清问题是否切中关键信息
- 是否避免无关或冗余提问
在 PACIFIC 数据集中,尽管 ProCoT 显著优于其他 Prompting 方法,但仍明显落后于领域微调模型,表明: ProCoT 能提升“是否要澄清”的判断能力,但无法弥补领域知识缺失。
3.2 目标引导对话任务(Target-guided Dialogues)
3.2.1 任务定义
目标引导对话模拟一种常见场景:
系统在对话中具有一个隐藏目标(如推荐某个物品或话题),需要通过多轮对话逐步引导用户接近该目标,而非直接强行输出。
该任务考察模型是否具备:
- 对长期目标的保持能力
- 在自然对话中逐步推进目标的能力
3.2.2 测试设置
在该任务中,模型需要在每一轮对话中选择一个下一个话题或对话方向,使对话最终到达目标话题。
评估从两个层面进行:
- Turn-level Evaluation:单轮对话是否向目标靠近
- Dialogue-level Evaluation:完整对话是否成功到达目标
3.2.3 评估指标
- hits@k:目标话题是否出现在模型推荐的前 k 个选项中
- G-Coherence(全局连贯性):人工评估对话整体是否自然、合理
- Dialogue Length:完成目标所需的轮数
3.2.4 实验结果分析
实验结果呈现出一个有代表性的现象:
- LLM 在 hits@k 指标上表现极强,甚至超过微调模型
- 但在人类评估中,对话连贯性得分偏低
进一步分析发现:
- Standard Prompting 和 Proactive Prompting 往往过于激进
- 模型倾向于在极少轮数内强行切入目标话题
- ProCoT 能有效拉长对话路径,使目标引导更加自然
这说明 ProCoT 在一定程度上缓解了 LLM 的目标过拟合问题,使其更接近人类的渐进式引导方式。
3.3 非合作对话任务(Non-collaborative Dialogues)
3.3.1 任务定义
非合作对话主要模拟讨价还价、谈判、说服 等场景。
在这些场景中,对话双方目标并不一致,系统需要在对话中为自身目标争取利益。
3.3.2 测试方式
本文采用模拟谈判环境,对模型进行测试,重点考察其:
- 策略选择能力
- 对目标的坚持程度
- 对话自然性与说服力
3.3.3 评估指标
- Strategy Accuracy:是否选择了合理的谈判策略
- Dialogue Act Accuracy:对话行为是否符合策略
- SL Ratio:最终达成结果与系统目标的接近程度
- Human Evaluation:自然性、说服性、可信度
3.3.4 实验结论
实验结果显示:
- ProCoT 相比其他 Prompting 方法,在 SL Ratio 上有所提升
- 但在策略预测与对抗能力上,仍明显弱于微调模型
一个关键发现是:LLM 即使具备较强的语言能力,也倾向于在对抗场景中过早妥协。
这表明,仅通过 Prompting 难以让模型真正学会“为自己而对话”,策略学习与强化机制仍不可或缺。
四、 结论
- ProCoT 能显著提升 LLM 在主动对话中的决策意识;
- Prompting 可以弥补“是否该行动”的问题,但难以解决“如何长期最优行动”;
- 领域任务严重依赖外部知识。,即在复杂、对抗性强或领域依赖高的场景中,Prompting 并不能替代模型训练。
- ProCoT等提示词方案覆盖三类关键主动对话任务
- ProCoT 依赖 prompt engineering,稳定性不足
- 未涉及多目标 或动态目标切换
参考与原文
https://aclanthology.org/2023.findings-emnlp.711/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)