【万字长文】手把手教你用向量引擎+GPT-5.2构建企业级AI舆情监控系统:从反爬虫沙箱到可视化报告的全链路实战解析
你是否经历过这样的至暗时刻?凌晨三点,公司的负面舆情已经在社交媒体上发酵成了热搜。而你引以为傲的传统爬虫脚本,因为对方网站的一次前端更新,全线崩溃。你的分析系统还在机械地抓取着无关的噪音数据,像个无头苍蝇。老板的电话打来时,你甚至连一份像样的、基于实时数据的分析报告都拿不出来。在 GPT-5.2-pro 和 Sora2 已经重塑生产力的今天,如果我们还在用上个时代的工具——那些脆弱的脚本、僵化的规

摘要/前言
你是否经历过这样的至暗时刻?
凌晨三点,
公司的负面舆情已经在社交媒体上发酵成了热搜。
而你引以为傲的传统爬虫脚本,
因为对方网站的一次前端更新,
全线崩溃。
你的分析系统还在机械地抓取着无关的噪音数据,
像个无头苍蝇。
老板的电话打来时,
你甚至连一份像样的、基于实时数据的分析报告都拿不出来。
在 GPT-5.2-pro 和 Sora2 已经重塑生产力的今天,
如果我们还在用上个时代的工具——
那些脆弱的脚本、僵化的规则——
去对抗海量且瞬息万变的互联网信息,
那无异于骑着马去追赶光速飞船。
今天,
我要带你通过向量引擎(Vector Engine),
构建一套真正的“下一代”AI舆情实时分析系统。
这不仅仅是一个教程,
更是一次对 Agentic AI 基础设施的深度探索。
我们将利用向量引擎提供的 Browser Sandbox(浏览器沙箱)技术,
结合 LLM 的大脑,
实现从“数据采集”到“深度分析”再到“可视化报告”的全自动闭环。
准备好了吗?
让我们开始这场技术盛宴。
第一章: 为什么传统的舆情系统已经“死”了?
1.1 传统爬虫的“猫鼠游戏”困局
做过数据采集的兄弟都知道,
现在的互联网环境对爬虫有多么不友好。
以前写个 Python 脚本,
用 Requests 库发个请求,
数据就哗哗地来了。
现在呢?
各种复杂的 JavaScript 动态渲染,
各种变态的滑动验证码,
还有无处不在的风控指纹识别。
为了绕过这些,
你需要维护庞大的代理 IP 池,
你需要不停地逆向混淆的 JS 代码,
你需要模拟各种浏览器指纹。
这简直就是一场无休止的猫鼠游戏,
耗费了我们 80% 的精力,
却只解决了 20% 的问题。
1.2 LLM 的“幻觉”与数据的“断层”
后来,大模型出现了。
我们以为救星来了。
但是,
单纯的 LLM 无法直接访问实时互联网。
即使是联网模式,
也往往受限于上下文长度和搜索深度。
更可怕的是,
如果数据源本身就是脏数据,
LLM 再聪明,
输出的也只能是“一本正经的胡说八道”。
这就是数据的“断层”。
我们需要一个桥梁。
一个能像真人一样操作浏览器,
又能像专家一样思考的桥梁。
1.3 向量引擎:破局者
这就是为什么我们需要向量引擎。
它不仅仅是一个存储向量的数据库,
它是以高代码为核心的一站式 Agentic AI 基础设施平台。
它解决了三个核心痛点:
第一,环境隔离。
它提供了安全的 Browser Sandbox,
让每一个采集任务都在独立的沙箱中运行,
互不干扰,彻底解决环境污染问题。
第二,真实模拟。
它基于真实的 Chrome 浏览器内核,
支持完整的 JS 执行和复杂的页面交互,
极大地降低了被反爬机制识别拦截的概率。
第三,Serverless 弹性。
你不需要维护昂贵的服务器集群,
有任务就起,没任务就停,
成本直接降低 60%。

第二章: 系统架构设计的艺术
2.1 核心理念:分层与控制
在设计这个系统时,
我们遵循了一个核心原则:
“让 AI 做决策,让程序做执行,让沙箱做隔离。”
我们不能把所有事情都扔给 LLM 去“猜”。
我们需要一个严格的流程控制。
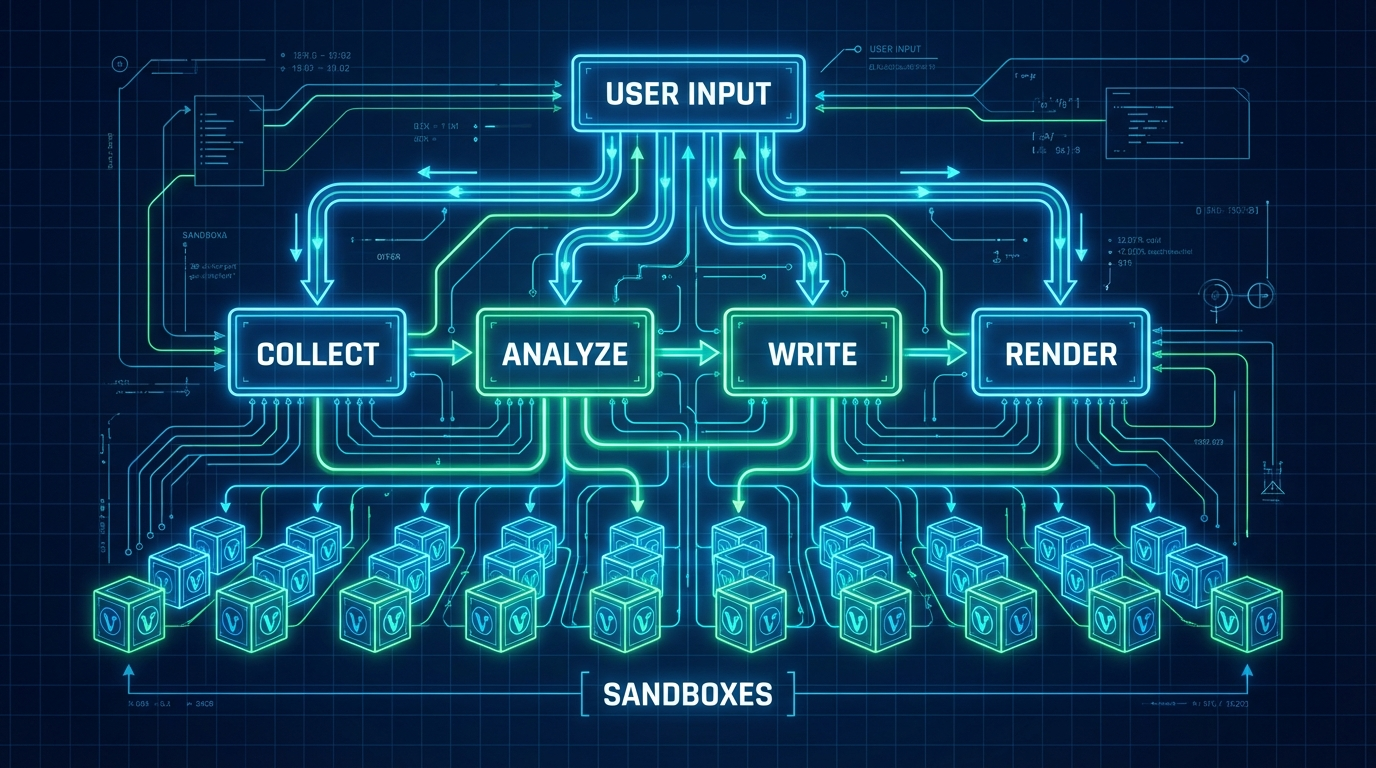
整个架构分为三层:
1. 交互层(User Interface):
用户输入关键词,
接收实时的流式反馈,
查看最终的可视化报告。
2. 智能体层(Agent Layer):
基于 PydanticAI 构建的智能体。
它拥有四个核心工具:
collect_data(数据采集)
analyze_data(深度分析)
write_report(报告撰写)
render_html(页面渲染)
这一层是系统的大脑,
负责调度和逻辑判断。
3. 基础设施层(Infrastructure Layer):
这是向量引擎的主场。
包含 Browser Sandbox(浏览器沙箱),
负责执行具体的页面访问、点击、滚动操作。
包含 VNC 服务,
负责将浏览器的画面实时传输给用户。
2.2 流程的“严丝合缝”
不同于完全依赖 LLM 自主决策的 Agent,
我们在舆情分析场景下,
设计了严格的执行顺序:
第一步:关键词触发。
用户输入“某品牌最新产品质量问题”。
第二步:多平台数据收集。
Agent 调用向量引擎的浏览器沙箱,
同时在微博、知乎、B站等平台进行检索。
第三步:Browser Sandbox 实时推送。
沙箱内的操作画面,
通过 VNC 实时推送到前端,
用户可以看到 AI 是怎么“逛”网站的。
第四步:深度分析与状态更新。
采集到的数据被送回 LLM(如 GPT-5.2),
进行情感打分和关键信息提取。
第五步:报告撰写与渲染。
生成 Markdown 格式的深度报告,
并自动渲染成包含 ECharts 图表的 HTML 页面。
第三章: 深入后端核心——Agent 工具链的魔法
3.1 PydanticAI:给 AI 立规矩
我们使用了 PydanticAI 来构建智能体。
为什么要用它?
因为在工程化落地中,
结构化的输出比天马行空的对话更重要。
我们需要 AI 输出确定的 JSON 格式,
而不是一段散文。
通过定义 Tool(工具),
我们将复杂的业务逻辑封装成函数,
让 LLM 只需要决定“调用哪个函数”和“传什么参数”。
3.2 智能数据质量控制(Data Quality Control)
垃圾进,垃圾出。
这是数据分析的铁律。
在 collect_data 阶段,
我们引入了智能过滤机制。
多维度评估:
系统会计算采集内容与关键词的匹配度。
如果一个网页虽然包含关键词,
但上下文完全不相关(比如广告),
会被直接丢弃。
时效性加分:
舆情分析讲究一个“快”。
系统会识别发布时间,
对 24 小时内的数据给予更高的权重,
对一年前的“旧闻”自动降权。
3.3 真正的流式输出(Real-time Streaming)
用户最怕的是什么?
是等待。
尤其是在处理复杂任务时,
如果屏幕静止不动一分钟,
用户就会以为系统挂了。
我们实现了全链路的流式输出。
不仅仅是 LLM 生成文字是流式的,
连后台的任务状态更新也是流式的。
每完成一个步骤(比如“已抓取知乎Top5回答”),
前端都会立刻收到通知。
甚至在报告撰写阶段,
每生成 100 个字符,
或者每隔 0.3 秒,
就会推送一次更新。
这种极致的交互体验,
让用户感觉系统是“活”的。
官方资源插播
在继续深入之前,
如果你想亲手尝试构建这样的系统,
或者获取本文提到的向量引擎平台资源,
请务必关注以下信息。
官方地址及注册通道: https://api.vectorengine.ai/register?aff=QfS4
详细的使用教程文档: https://www.yuque.com/nailao-zvxvm/pwqwxv?#
兑换码:
546c6789c9b64bb0ba5b07bf1fbb1cfe
78c65b800b7a41caac2392955f1abe08
4dd5d7e1a81a41b0aa54e46e9eaf1bb4
65cf9df856db4208a0dff72d56067614
4cefd678d0854a49af6133855e51ed90
1bdad829b4524610acc8dfa5673ddf9d
e970ba25223748e1830daf6eb371fb2e
36516563532849f893c2f8cd67fde058
1ae7ff22c9fd4acbaca8fdfd5f2ff36c
d504ab3e653945d2acc4bdfee6c168e1
d308ecaddb9d43f6a91185b3448323e8
福利时间: 现在注册并登录控制台, 在钱包页面使用兑换码, 即可获得免费的测试额度! 不要错过这个白嫖算力的机会。
第四章: 深度内容抓取技术——攻破平台壁垒
4.1 平台适配策略:定制化的智慧
每个社交平台都有自己的“脾气”。
通用的爬虫策略在这里行不通。
我们需要针对不同平台定制抓取逻辑。
微博(Weibo):
微博的核心在于“传播”。
我们不仅要抓取正文,
还要利用 CSS 选择器 .WB_feed_expand,
精准定位并抓取评论和转发链条。
知乎(Zhihu):
知乎的价值在于“观点”。
我们重点关注 .AnswerItem,
提取高赞回答,
并过滤掉没有实质内容的“抖机灵”回答。
B站(Bilibili):
B站是视频的海洋,但舆情在弹幕和评论里。
我们通过 .reply-item 抓取视频下方的热评,
甚至结合 Veo3 等多模态模型,
未来可以直接分析视频内容的帧画面。
4.2 LLM 驱动的智能探索(Smart Exploration)
这是最精彩的部分。
传统的爬虫是“死”的,
它只会按照预定的规则翻页。
而我们的系统,
是由 LLM 驱动的。
当 Agent 打开一个页面时,
它会“看”一眼当前的内容。
然后,LLM 会进行决策:
“这个页面的评论区似乎吵得很凶,我需要展开看看。”
或者:
“这个页面虽然提到了关键词,但主要是广告,跳过。”
基于关键词、页面 URL 和已获取的内容,
LLM 会权衡时间成本,
决定是否进行深入抓取(如点击“查看更多评论”)。
为了防止陷入无限抓取的黑洞,
我们限制每个页面最多探索 1-2 个操作。
这就是“智能”与“克制”的平衡。

第五章: Browser Sandbox——向量引擎的“核动力”
5.1 什么是 Browser Sandbox?
你可以把它理解为一个“云端的、一次性的、完全隔离的电脑”。
在向量引擎平台上,
每当你发起一个舆情分析任务,
系统就会在毫秒级的时间内,
为你动态创建一个全新的沙箱环境。
这个环境里运行着一个真实的 Chrome 浏览器。
5.2 为什么它比 Docker 里的 Headless Chrome 强?
很多开发者会说:
“我自己用 Docker 跑一个 Headless Chrome 不行吗?”
行,但是有坑。
第一,指纹问题。
Headless Chrome 有非常明显的特征指纹(User-Agent, WebGL, Canvas 等)。
现在的反爬系统,
一眼就能认出你不是人。
而向量引擎的沙箱,
经过了深度的内核级改造,
模拟了真实用户的硬件环境,
极大地提升了通过率。
第二,资源隔离与安全。
如果你在自己的服务器上跑爬虫,
万一爬到了挂马网站,
或者浏览器崩溃导致内存泄漏,
你的整个服务可能就挂了。
向量引擎的沙箱是完全隔离的。
单个采集任务故障,
绝对不会影响系统整体运行。
用完即焚,
不留任何痕迹。
5.3 VNC 集成:看见 AI 的思考
为了让用户“看见” AI 的工作,
我们集成了 VNC(Virtual Network Computing)。
动态库加载技术:
前端 VNC 播放器需要加载一些资源。
我们设计了智能加载逻辑,
优先加载本地资源,
如果失败,自动切换到 CDN 回退。
确保在任何网络环境下都能流畅播放。
多协议适配:
现在的网络环境很复杂。
有的用户在 HTTP 环境,有的在 HTTPS。
我们的系统会自动适配 WebSocket 协议。
在 HTTPS 下自动切换为 wss://,
在 HTTP 下切换为 ws://。
这看似微小的细节,
却是企业级应用稳定性的基石。
第六章: 智能分析与可视化报告
6.1 标准化情感分析:给情绪打分
抓取到了数据,
接下来就是 GPT-5.2 发挥威力的时候了。
我们不仅仅是让 LLM 总结全文,
我们引入了量化的情感分析。
基于关键词词典和上下文语义,
系统会计算出一个情感得分(Score)。
范围从 -1.0(极度负面)到 1.0(极度正面)。
正向关键词:
优秀、创新、好评、遥遥领先...
负向关键词:
糟糕、故障、差评、智商税...
通过这个得分,
我们可以生成舆情趋势图,
一眼就能看出品牌声誉的走向。
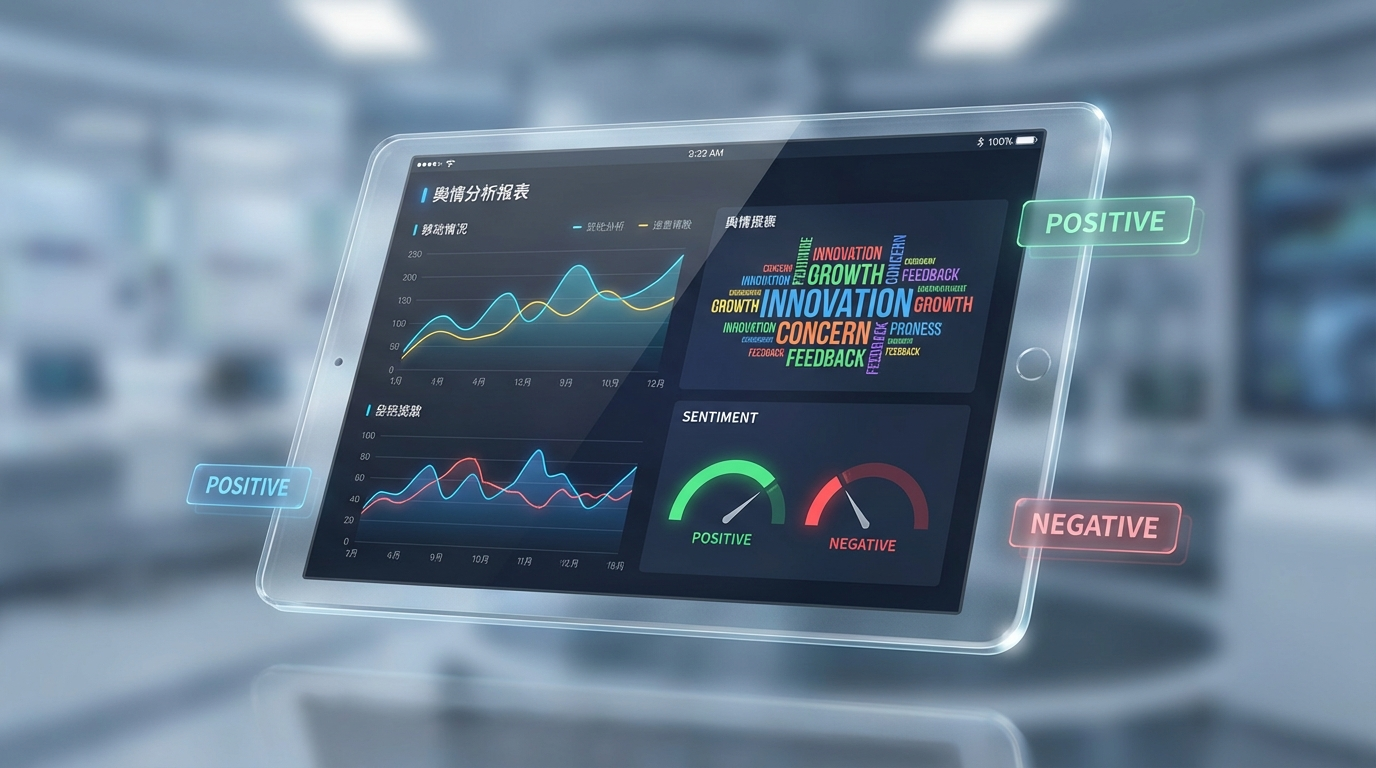
6.2 报告生成:图文并茂的艺术
纯文字的报告没人爱看。
我们要的是 PPT 级别的可视化。
Agent 在撰写报告时,
会自动调用 render_html 工具。
它会将分析结果转化为 ECharts 的配置项。
词云图(WordCloud):
展示用户讨论最热烈的关键词。
饼图(Pie Chart):
展示正负面情绪的比例。
折线图(Line Chart):
展示舆情随时间的变化趋势。
最终,
用户得到的是一个交互式的 HTML 页面,
既有深度的文字洞察,
又有炫酷的数据图表。
第七章: 运维与性能——企业级的基石
7.1 弹性扩展:从 0 到 100万
这是 Serverless 的核心优势。
向量引擎天然支持多 Sandbox 并行处理。
当突发舆情事件发生时,
比如某明星塌房,
瞬间涌入成千上万的查询请求。
系统会自动动态创建大量的浏览器实例。
支持百万级沙箱并发,
每分钟调度能力超过 3.5 万个沙箱。
而当夜深人静没有任务时,
系统会自动缩容到 0。
你不需要为闲置的资源付一分钱。
7.2 自动化运维与自愈
在分布式系统中,
故障是常态。
网络会抖动,浏览器会崩溃。
关键在于如何恢复。
我们内置了强大的监控与自恢复机制。
自动重连:
如果连接失败,
前端会每 10 秒尝试自动重连。
实例重建:
如果后台检测到某个沙箱实例异常(比如卡死),
会自动销毁并重建一个新的实例,
重新执行当前任务。
这一切对用户都是透明的。
用户只会感觉到:“嗯,这次加载稍微慢了一秒”,
而不会看到报错页面。
第八章: 快速体验与部署指南
8.1 极简部署流程
说了这么多,
怎么用起来?
非常简单。
第一步:
打开阿里云函数计算向量引擎探索页面。
第二步:
找到“舆情分析专家”案例卡片。
第三步:
点击“部署”。
你只需要填写几个简单的参数(如 API Key)。
第四步:
确认创建。
系统会自动为你拉起所有的后端服务、数据库和前端页面。
8.2 在线二次开发
获取到体验地址(main_web 地址)后,
你不仅可以直接使用,
还可以进行在线二次开发。
向量引擎提供了 Web IDE,
你可以直接修改 Python 代码,
调整提示词(Prompt),
或者增加新的采集平台。
结语: 拥抱 Agentic AI 的时代
我们正处于一个时代的转折点。
从“人找信息”到“信息找人”,
再到现在的“AI 替人处理信息”。
基于函数计算向量引擎构建的这套舆情分析系统,
不仅是一个技术 Demo,
更是未来工作方式的一个缩影。
它展示了如何将 LLM 的认知能力,
与浏览器的行动能力,
以及 Serverless 的弹性能力完美结合。
平均 TCO(总拥有成本)降低 60%,
让开发者可以从繁琐的基础设施维护中解放出来,
专注于业务逻辑的创新。
不管你是技术管理者,
还是在一线奋斗的开发者,
我都强烈建议你动手试一试。
因为,
未来已来,
而它属于那些善于利用工具的人。
再次提醒:
想要获取源码、免费额度以及更多技术支持, 请务必访问
官方通道: https://api.vectorengine.ai/register?aff=QfS4
教程地址: https://www.yuque.com/nailao-zvxvm/pwqwxv?#
别忘了在评论区分享你的部署体验! 让我们一起, 用 AI 重塑世界。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 27
27 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)