LlamaIndex(八)使用Qdrant 完成向量存储与检索
本文介绍了基于LlamaIndex框架结合阿里云千问大模型和Qdrant向量数据库构建PDF文档检索系统的完整方案。系统采用千问模型进行文本嵌入和问答生成,通过PyMuPDF解析PDF文档,利用Qdrant实现高效向量检索。详细阐述了从环境配置、文档加载切分、向量索引构建到语义检索的全流程实现,并分析了该方案的轻量化部署、本土化适配等优势。该系统可扩展为完整的RAG问答系统,适用于企业知识库和个人
在大语言模型技术飞速发展的当下,基于文档的智能检索与问答系统成为企业和开发者的重要需求。本文将详细介绍如何利用 LlamaIndex 框架,结合阿里云千问(DashScope)大模型与 Qdrant 向量数据库,构建一套高效的 PDF 文档检索系统,实现对本地 PDF 文档的精准语义检索。
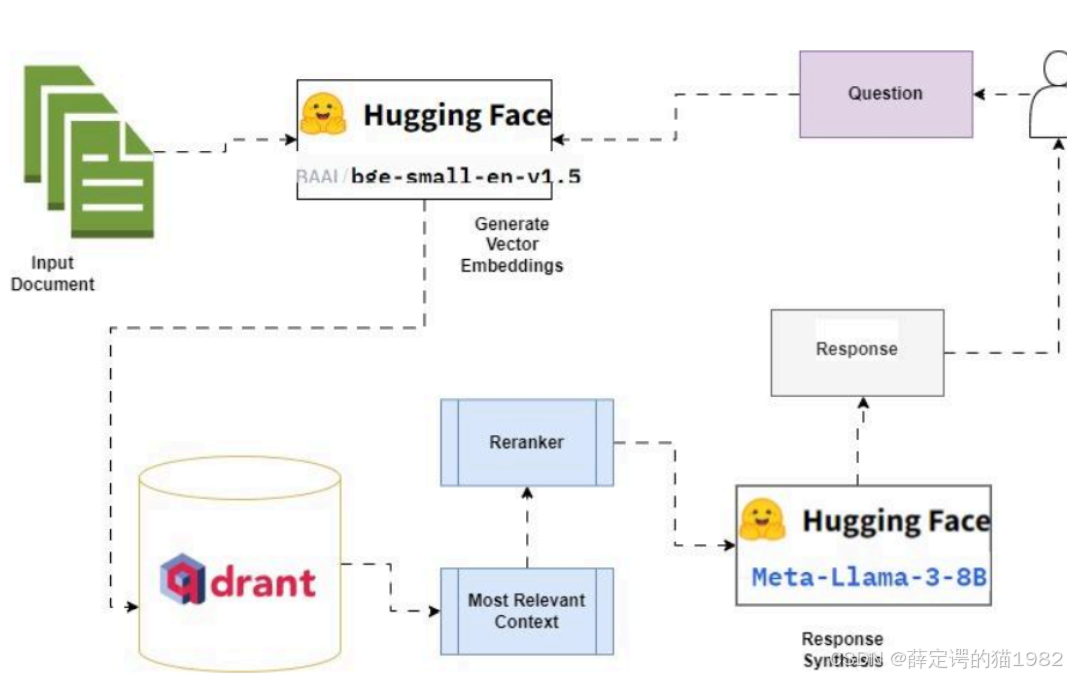
Qdrant简介
Qdrant是一个开源的向量搜索引擎,由Qdrant团队开发。它提供了高性能的向量检索和相似度搜索功能,支持多种向量类型和距离度量方法。Qdrant还提供了丰富的查询语法和灵活的配置选项,使得用户可以根据自己的需求进行定制化的搜索。
Qdrant 因其易用性和用户友好的开发者文档,面世不久即获得关注。
Qdrant 以 Rust 语言构建,提供 Rust、Python、Golang 等客户端 API,能够满足当今主流开发人员的需求。
一、技术栈选型与核心依赖
构建该检索系统的核心技术栈围绕 LlamaIndex 生态展开,同时结合了阿里云千问大模型与 Qdrant 向量存储,具体依赖如下:
# 核心框架与工具
pip install llama-index llama-index-embeddings-dashscope llama-index-llms-dashscope
# PDF解析与环境配置
pip install pymupdf python-dotenv
# 兼容OpenAI接口的LLM适配
pip install llama-index-llms-openai-like
# Qdrant向量存储
pip install llama-index-vector-stores-qdrant
- LlamaIndex:作为核心的检索增强生成(RAG)框架,提供文档加载、切分、向量化、检索等全流程能力;
- DashScope(千问):阿里云推出的大模型服务,提供高质量的文本嵌入与大语言模型能力;
- PyMuPDF:高效的 PDF 文件解析工具,支持精准提取 PDF 中的文本内容;
- Qdrant:轻量级向量数据库,支持快速的向量相似度检索;
- python-dotenv:用于加载环境变量,安全管理 API 密钥等敏感信息。
二、系统实现流程
1. 环境配置与密钥管理
首先通过环境变量加载千问模型的 API 密钥,避免硬编码敏感信息,需提前在.env文件中配置DASHSCOPE_API_KEY=你的密钥:
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
api_key = os.getenv("DASHSCOPE_API_KEY")
2. 千问模型配置
系统核心依赖千问的两大能力:文本嵌入(用于将文档转为向量)和大语言模型(用于后续问答生成),通过 LlamaIndex 的适配层快速接入:
from llama_index.embeddings.dashscope import DashScopeEmbedding
from llama_index.llms.openai_like import OpenAILike
# 配置千问嵌入模型(文本向量化)
embed_model = DashScopeEmbedding(
model_name="text-embedding-v2", # 千问轻量级嵌入模型,输出维度1536
api_key=api_key,
timeout=30 # 超时时间保障
)
# 配置千问大语言模型(回答生成)
llm = OpenAILike (
model="qwen-plus", # 千问增强版模型
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1", # 兼容OpenAI接口的地址
api_key=api_key,
is_chat_model=True # 标记为对话模型
)
3. PDF 文档加载与解析
通过 LlamaIndex 的SimpleDirectoryReader结合PyMuPDFReader解析器,批量加载指定目录下的 PDF 文件,提取文本内容:
from llama_index.core import SimpleDirectoryReader
from llama_index.readers.file import PyMuPDFReader
# 加载指定目录下的所有PDF文件
documents = SimpleDirectoryReader(
input_dir="./data", # 本地PDF文档存放目录
required_exts=[".pdf"], # 仅加载PDF格式文件
file_extractor={".pdf": PyMuPDFReader()} # 指定PDF解析器
).load_data()
4. 文档切分:适配模型上下文长度
原始 PDF 文本通常较长,需按 Token 粒度切分为小片段(Node),保证向量化和检索的精准性:
from llama_index.core.node_parser import TokenTextSplitter
# 按Token切分文档
node_parser = TokenTextSplitter(
chunk_size=300, # 每个文本块300个Token
chunk_overlap=50 # 块间重叠50个Token,避免语义断裂
)
nodes = node_parser.get_nodes_from_documents(documents)
5. Qdrant 向量库初始化与索引构建
将切分后的文本块通过千问嵌入模型转为向量,存储到 Qdrant 向量库中,构建可检索的向量索引:
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance
from llama_index.core import StorageContext, VectorStoreIndex
from llama_index.vector_stores.qdrant import QdrantVectorStore
# 初始化Qdrant客户端(内存模式,也可配置为持久化)
client = QdrantClient(location=":memory:")
collection_name = "demo"
# 创建向量集合,指定向量维度(text-embedding-v2输出1536维)和相似度计算方式(余弦相似度)
client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=1536, distance=Distance.COSINE)
)
# 关联Qdrant向量存储
vector_store = QdrantVectorStore(client=client, collection_name=collection_name)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 构建向量索引:将文本块向量化并存储到Qdrant
index = VectorStoreIndex(
nodes,
storage_context=storage_context,
embed_model=embed_model # 指定千问嵌入模型
)
6. 语义检索:实现精准内容查找
基于构建好的向量索引,创建检索器并指定返回最相似的 Top-K 结果,实现对目标问题的语义检索:
# 创建检索器,返回Top2相似结果
vector_retriever = index.as_retriever(similarity_top_k=2)
# 检索与“所获荣誉”相关的内容
results = vector_retriever.retrieve("所获荣誉")
# 输出最相似的检索结果
print(results[0])
三、核心优势与扩展方向
1. 核心优势
- 轻量化部署:Qdrant 支持内存模式运行,无需复杂的数据库部署,适合快速开发与测试;
- 本土化适配:基于阿里云千问模型,无需访问海外服务,稳定性和合规性更优;
- 精准语义检索:结合余弦相似度计算与 Token 级文档切分,检索精度远高于传统关键词匹配;
- 灵活扩展:LlamaIndex 框架支持多类型文档(Word、Markdown 等)和多向量库(Milvus、Chroma 等)适配。
2. 扩展方向
- 持久化存储:将 Qdrant 从内存模式改为磁盘持久化,避免重启后索引丢失;
- 问答生成:结合千问 LLM,在检索结果基础上生成自然语言回答,实现端到端的问答系统;
- 批量处理与增量索引:支持新增文档的增量索引构建,无需重复处理全部文档;
- Web 化部署:结合 FastAPI/Flask 搭建 Web 接口,提供可视化的检索界面。
四、总结
本文基于 LlamaIndex 框架,完整实现了从 PDF 文档加载、解析、切分、向量化,到基于 Qdrant 向量库的语义检索全流程,核心依赖阿里云千问模型提供的嵌入能力,构建了一套轻量、高效的本地文档检索系统。该方案无需复杂的基础设施,适合开发者快速搭建私有化文档检索服务,也可基于此扩展为完整的 RAG 问答系统,满足企业知识库、个人文档管理等多场景需求。
关键点回顾
- 系统核心流程为:文档加载→切分→向量化→向量存储→语义检索,基于 LlamaIndex 实现全流程串联;
- 千问模型提供嵌入和 LLM 双重能力,通过 OpenAILike 适配层快速接入 LlamaIndex;
- Qdrant 向量库支持高效的相似度检索,结合余弦相似度计算实现精准的语义匹配。
完整代码如下
#pip install llama-index llama-index-embeddings-dashscope llama-index-llms-dashscope pymupdf python-dotenv
#pip install llama-index-llms-openai-like、
#pip install llama-index-vector-stores-qdrant
import os
from dotenv import load_dotenv
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, StorageContext
from llama_index.core.node_parser import TokenTextSplitter
from llama_index.readers.file import PyMuPDFReader
from llama_index.embeddings.dashscope import DashScopeEmbedding
from llama_index.llms.openai_like import OpenAILike
from llama_index.vector_stores.qdrant import QdrantVectorStore
# 1. 加载环境变量(提前在 .env 文件配置 DASHSCOPE_API_KEY=你的密钥)
load_dotenv()
api_key = os.getenv("DASHSCOPE_API_KEY")
# 2. 配置千问嵌入模型(用于文本向量化)
embed_model = DashScopeEmbedding(
model_name="text-embedding-v2", # 千问嵌入模型版本
api_key=api_key,
timeout=30 # 超时时间
)
# 3. 配置千问大语言模型(用于生成回答)
llm =OpenAILike (
model="qwen-plus",
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
is_chat_model=True
)
# 4. 加载PDF文档(可替换为其他格式)
documents = SimpleDirectoryReader(
input_dir="./data", # 本地文档目录
required_exts=[".pdf"], # 只加载PDF文件
file_extractor={".pdf": PyMuPDFReader()} # PDF解析器
).load_data()
# 5. 文档切分(按token分块,适配千问上下文长度)
node_parser = TokenTextSplitter(
chunk_size=300, # 每个块300个token
chunk_overlap=50 # 块之间重叠50个token,保证语义连贯
)
nodes = node_parser.get_nodes_from_documents(documents)
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance
client = QdrantClient(location=":memory:")
collection_name = "demo"
collection = client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=1536, distance=Distance.COSINE)
)
vector_store = QdrantVectorStore(client=client, collection_name=collection_name)
# 创建 storage: 指定存储空间
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 创建 index: 通过 Storage Context 关联到自定义的 Vector Store
index = VectorStoreIndex(nodes, storage_context=storage_context, embed_model=embed_model)
# 获取 retriever
vector_retriever = index.as_retriever(similarity_top_k=2)
# 检索
results = vector_retriever.retrieve("所获荣誉")
print(results[0])
多轮对话
#pip install llama-index llama-index-embeddings-dashscope llama-index-llms-dashscope pymupdf python-dotenv
#pip install llama-index-llms-openai-like、
#pip install llama-index-vector-stores-qdrant
import os
from dotenv import load_dotenv
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, StorageContext
from llama_index.core.node_parser import TokenTextSplitter
from llama_index.readers.file import PyMuPDFReader
from llama_index.embeddings.dashscope import DashScopeEmbedding
from llama_index.llms.openai_like import OpenAILike
from llama_index.vector_stores.qdrant import QdrantVectorStore
# 1. 加载环境变量(提前在 .env 文件配置 DASHSCOPE_API_KEY=你的密钥)
load_dotenv()
api_key = os.getenv("DASHSCOPE_API_KEY")
# 2. 配置千问嵌入模型(用于文本向量化)
embed_model = DashScopeEmbedding(
model_name="text-embedding-v2", # 千问嵌入模型版本
api_key=api_key,
timeout=30 # 超时时间
)
# 3. 配置千问大语言模型(用于生成回答)
llm =OpenAILike (
model="qwen-plus",
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
is_chat_model=True
)
# 4. 加载PDF文档(可替换为其他格式)
documents = SimpleDirectoryReader(
input_dir="./data", # 本地文档目录
required_exts=[".pdf"], # 只加载PDF文件
file_extractor={".pdf": PyMuPDFReader()} # PDF解析器
).load_data()
# 5. 文档切分(按token分块,适配千问上下文长度)
node_parser = TokenTextSplitter(
chunk_size=300, # 每个块300个token
chunk_overlap=50 # 块之间重叠50个token,保证语义连贯
)
nodes = node_parser.get_nodes_from_documents(documents)
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance
client = QdrantClient(location=":memory:")
collection_name = "demo"
collection = client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=1536, distance=Distance.COSINE)
)
vector_store = QdrantVectorStore(client=client, collection_name=collection_name)
# 创建 storage: 指定存储空间
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 创建 index: 通过 Storage Context 关联到自定义的 Vector Store
index = VectorStoreIndex(nodes, storage_context=storage_context, embed_model=embed_model)
#单轮对话
#qa_engine = index.as_query_engine(llm)
#response = qa_engine.query("所获荣誉有哪些?")
#print(response)
#流式
#qa_engine = index.as_query_engine(llm,streaming=True)
#response = qa_engine.query("所获荣誉有哪些?")
#response.print_response_stream()
# 8. 构建 Chat Engine(显式指定千问 LLM,核心解决 OpenAI 密钥报错)
chat_engine = index.as_chat_engine(
llm=llm, # 关键:指定千问模型为聊天引擎的 LLM
chat_mode="context", # 基于文档上下文的对话模式(推荐)
similarity_top_k=2, # 检索Top2相似文档作为上下文
streaming=False # 非流式输出,如需流式可设为True
)
# 9. 测试多轮对话(无 OpenAI 密钥也能运行)
# 第一轮对话
response1 = chat_engine.chat("所获荣誉有哪些?")
print("第一轮回复:", response1)
# 第二轮对话(上下文关联)
response2 = chat_engine.chat("分几类?")
print("第二轮回复:", response2)
# 可选:清空对话历史
chat_engine.reset()
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)