大模型还在硬编码?Spring AI 实现“动态热切换”全攻略(下)
摘要:在上篇中,我们完成了动态模型工厂的搭建。本篇将继续深入业务层,结合项目代码,详细拆解如何实现手动控制的 RAG (检索增强生成) 以及 SSE (Server-Sent Events) 流式接口。
0. 技术栈说明
- JDK: 17+
- Spring Boot: 3.3.x
- Spring AI: 1.1.x
1. 业务层核心拆解:ChatServiceImpl
在复杂的业务场景下,Spring AI 提供的默认 Advisor 可能无法满足需求(例如需要自定义 RAG 模板或动态过滤元数据)。因此,我们在 Service 层通过编程式的方式,将"检索"和"生成"两个步骤串联起来。
1.1 关键概念说明
在正式拆解代码之前,我们先明确几个核心概念:
RAG (Retrieval-Augmented Generation,检索增强生成):一种结合了信息检索和文本生成的技术模式。当用户提问时,系统先从知识库中检索相关文档,然后将这些文档作为上下文,连同用户问题一起发送给大模型,从而让模型基于企业私有知识进行回答。
VectorStore (向量数据库):专门用于存储和检索文本 Embedding(向量化数据)的数据库。常见的实现包括 Redis、PostgreSQL (pgvector)、Milvus 等。Spring AI 提供了统一的 VectorStore 接口,屏蔽了底层差异。
Context Stuffing (上下文填充):最基础也是最常用的 RAG 模式。它将检索到的知识块(Chunks)直接拼接后作为 Prompt 的一部分发送给大模型。需要注意的是,填充的内容不能超过模型的最大 Context Window(如 GPT-4o 的 128k tokens)。
Conversation ID (会话 ID):用于串联多轮对话的唯一标识。ChatMemory(如 InMemoryChatMemory 或 RedisChatMemory)通过这个 ID 来区分不同用户的聊天历史记录,实现上下文记忆功能。
SSE (Server-Sent Events,服务器推送事件):一种允许服务器向浏览器单向推送更新的 HTTP 技术。相比于 WebSocket,SSE 更轻量级,天然基于 HTTP 协议,非常适合实现大模型"打字机"效果的流式输出场景。
Flux:Project Reactor 中的核心响应式类型,表示一个包含 0 到 N 个元素的异步序列。在本场景中,它代表大模型不断吐出的一个个 Token(字符片段),前端可以通过订阅这个流来实时展示内容。
1.2 RAG 检索流程图
为了更直观地理解数据流向,我们通过以下时序图展示 RAG 的完整生命周期:
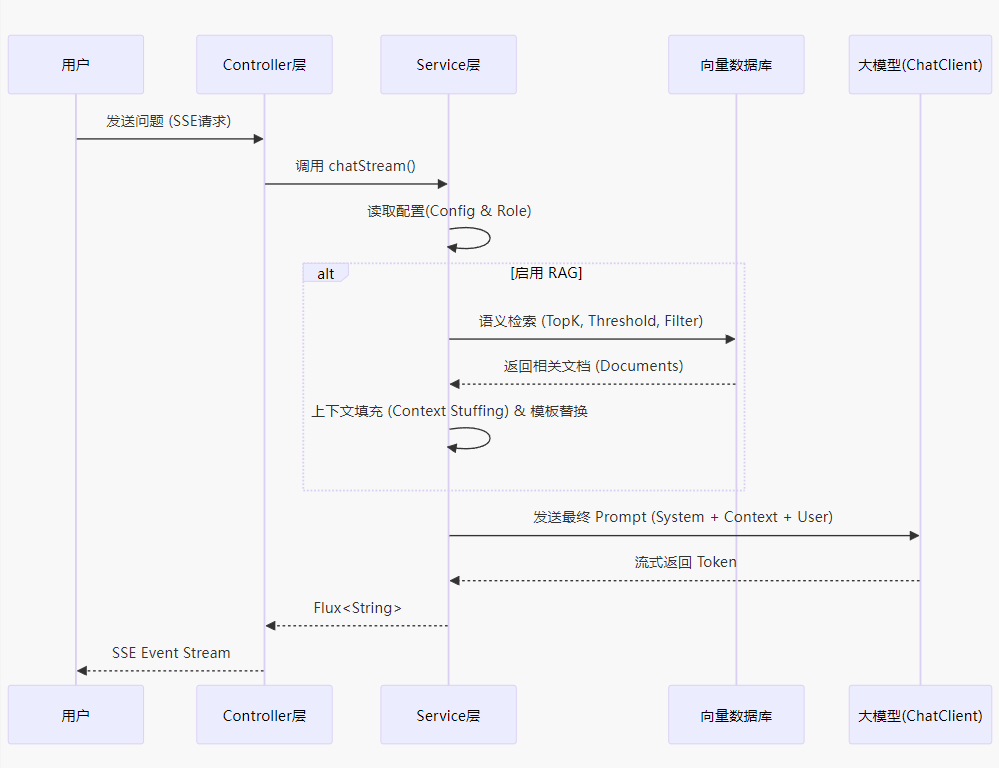
1.3 步骤一:获取配置并初始化客户端
在发起聊天前,我们首先需要获取当前的运行环境配置。这一步涉及以下几个关键操作:
- 通过动态工厂获取
ChatClient实例 - 读取
AiModelConfig表中的默认配置 - 如果配置绑定了角色,则读取
AiRolePrompt表中的角色提示词配置 - 判断该角色是否启用了 RAG 功能
AiModelConfig 表记录了当前使用的模型配置(如 API Key、Base URL 等),这些配置在上篇文章)中已经详细介绍过。
AiRolePrompt 表则定义了不同的 AI 角色人设,包括系统提示词、RAG 开关、检索参数等。通过 role_id 字段将配置与角色关联起来。
is_rag_enabled 字段控制是否启用 RAG。当值为 1 时,系统会执行向量检索;为 0 时,则直接将用户问题发送给大模型,适用于不需要知识库支持的通用对话场景。
下面是这部分的代码实现:
// 获取工厂构建的动态客户端
ChatClient chatClient = dynamicChatClientFactory.buildDefaultClient();
AiModelConfig config = aiModelConfigService.getDefaultConfig();
AiRolePrompt rolePrompt = null;
boolean enableRag = true;
// 检查配置中是否绑定了角色,以及角色是否开启了RAG
if (config != null && config.getRoleId() != null) {
rolePrompt = aiRolePromptService.getById(config.getRoleId());
if (rolePrompt != null && rolePrompt.getIsRagEnabled() != null) {
enableRag = rolePrompt.getIsRagEnabled() == 1;
}
}
getDefaultConfig() 方法实现:该方法用于获取系统当前使用的默认模型配置。在实际项目中,我们通过数据库查询来实现:
// AiModelConfigServiceImpl.java
@Override
public AiModelConfig getDefaultConfig() {
LambdaQueryWrapper<AiModelConfig> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(AiModelConfig::getIsDefault, 1) // is_default = 1 表示默认配置
.last("LIMIT 1");
return this.getOne(wrapper);
}
配置加载完成后,我们需要将 Conversation ID 注入到请求上下文中。这个 ID 贯穿整个对话生命周期,ChatMemory 会根据它来存储和检索历史消息:
// 注入会话ID,用于上下文记忆
var prompt = chatClient.prompt()
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, conversationId));
1.4 步骤二:构建精准的检索请求
RAG 的质量很大程度上取决于检索的质量。如果检索到的文档不相关,大模型可能会产生"幻觉"或给出错误答案。因此,我们需要精心设计检索参数。
在 AiRolePrompt 表中,我们配置了以下关键参数:
top_k:指定最多返回多少条相关文档。例如设置为 5,表示只返回语义相似度最高的前 5 条记录。这个值不宜过大,否则会占用过多的 Token 配额,也会降低模型的推理质量。
similarity_threshold:相似度阈值(取值范围 0-1)。只有相似度高于这个值的文档才会被返回。例如设置为 0.7,则只保留相似度 ≥ 0.7 的文档,可以有效过滤掉不相关的噪声数据。
custom_filter:元数据过滤表达式。Spring AI 提供了一种类 SQL 的表达式语言,允许我们在检索时附加元数据条件。例如 category == 'finance' 可以让检索只在"财务类"文档中进行;department in ['HR', 'IT'] 可以指定多个部门范围。这极大提高了检索的准确率和数据安全性,避免跨部门数据泄露。
下面是构建检索请求的代码:
// 如果启用了检索增强,并且有对应的角色配置
if (enableRag && rolePrompt != null) {
// 如果未配置 TopK,默认为 5
int topK = rolePrompt.getTopK() != null && rolePrompt.getTopK() > 0 ? rolePrompt.getTopK() : 5;
Double threshold = rolePrompt.getSimilarityThreshold();
SearchRequest.Builder builder = SearchRequest.builder()
.query(message) // 用户的原始问题
.topK(topK);
// 设置相似度阈值,过滤掉相关性低的文档
if (threshold != null) {
builder = builder.similarityThreshold(threshold);
}
// 元数据过滤 (Spring AI 的高级特性,类似 SQL 的过滤)
if (StringUtils.isNotBlank(rolePrompt.getCustomFilter())) {
builder = builder.filterExpression(rolePrompt.getCustomFilter());
}
SearchRequest searchRequest = builder.build();
// ... 执行检索(下一步)...
}
1.5 步骤三:执行检索并拼装上下文
构建好 SearchRequest 后,我们调用 VectorStore 的 similaritySearch 方法来执行实际的向量检索。这个方法会:
- 将用户问题文本转换为向量(Embedding)
- 在向量数据库中执行相似度计算
- 根据 TopK 和阈值筛选结果
- 应用元数据过滤条件
- 返回
List<Document>结果集
Document 是 Spring AI 中表示文档片段的核心类。每个 Document 对象包含:
id:文档唯一标识text:文档的文本内容metadata:元数据(如来源、分类、时间戳等)
接下来,我们需要将检索到的多个文档拼接成一个连贯的上下文字符串。这个过程称为 Context Stuffing(上下文填充)。最简单的策略就是用分隔符(如 ---)将各个文档内容串联起来:
// 执行向量检索
var docs = vectorStore.similaritySearch(searchRequest);
// 拼接上下文 (Context Stuffing)
StringBuilder contextBuilder = new StringBuilder();
for (Document doc : docs) {
if (contextBuilder.length() > 0) {
contextBuilder.append("\n\n---\n\n"); // 文档间的分隔符
}
String content = doc.getText();
if (content == null) {
content = doc.toString();
}
contextBuilder.append(content);
}
String context = contextBuilder.toString();
1.6 步骤四:模板渲染与 Prompt 组装
拼接好上下文后,我们需要将其与用户问题整合到一起,形成最终发送给大模型的 Prompt。为了提高灵活性,我们在 AiRolePrompt 表中设计了 rag_template 字段。
rag_template 是一个模板字符串,支持变量占位符。系统会在运行时将占位符替换为实际内容。常用的占位符包括:
{context}:检索到的知识库内容{query}:用户的原始问题
典型的模板示例:
你是一个专业的客服助手。请根据以下知识库内容回答用户问题:
【知识库】
{context}
【用户问题】
{query}
请基于知识库内容给出准确、专业的回答。如果知识库中没有相关信息,请明确告知用户。
这种模板化设计的好处是:
- 可以灵活调整 Prompt 结构,无需修改代码
- 可以针对不同角色设计不同的引导语
- 便于 A/B 测试和 Prompt 工程优化
代码实现如下:
// 模板渲染:将上下文和用户问题填入模板
String template = rolePrompt.getRagTemplate();
if (StringUtils.isNotBlank(template)) {
finalUserInput = template
.replace("{context}", context) // 替换知识库内容
.replace("{query}", message); // 替换用户问题
}
1.7 步骤五:发起流式响应
准备工作全部完成后,我们终于可以向大模型发起请求了。这里使用的是 Spring AI 的流式 API:
// 发起流式请求,返回 Flux 数据流
return prompt.user(finalUserInput)
.stream() // 开启流式模式
.content(); // 只获取文本内容(不包括元数据)
为什么要用流式响应?
- 用户体验:流式输出可以实现"打字机"效果,用户能立即看到模型开始生成内容,而不是长时间等待
- 降低延迟感知:即使总耗时相同,逐字显示也会让用户感觉更快
- 节省资源:如果用户中途满意,可以提前中断,避免浪费后续计算
这个方法返回的 Flux<String> 会被直接传递到 Controller 层,最终通过 SSE 推送给前端。
2. Service 完整代码清单
将前面所有步骤整合,我们得到了具备完整 RAG 能力的 ChatServiceImpl:
package com.lanjii.biz.admin.ai.service.impl;
import com.lanjii.biz.admin.ai.model.entity.AiModelConfig;
import com.lanjii.biz.admin.ai.model.entity.AiRolePrompt;
import com.lanjii.biz.admin.ai.service.AiModelConfigService;
import com.lanjii.biz.admin.ai.service.AiRolePromptService;
import com.lanjii.biz.admin.ai.service.ChatService;
import com.lanjii.biz.admin.ai.service.DynamicChatClientFactory;
import lombok.RequiredArgsConstructor;
import org.apache.commons.lang3.StringUtils;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
/**
* 聊天业务实现
*
* @author lanjii
*/
@Service
@RequiredArgsConstructor
public class ChatServiceImpl implements ChatService {
private final DynamicChatClientFactory dynamicChatClientFactory;
private final AiModelConfigService aiModelConfigService;
private final AiRolePromptService aiRolePromptService;
private final VectorStore vectorStore;
@Override
public Flux<String> chatStream(String message, String conversationId) {
ChatClient chatClient = dynamicChatClientFactory.buildDefaultClient();
AiModelConfig config = aiModelConfigService.getDefaultConfig();
AiRolePrompt rolePrompt = null;
boolean enableRag = true;
if (config != null && config.getRoleId() != null) {
rolePrompt = aiRolePromptService.getById(config.getRoleId());
if (rolePrompt != null && rolePrompt.getIsRagEnabled() != null) {
enableRag = rolePrompt.getIsRagEnabled() == 1;
}
}
var prompt = chatClient.prompt()
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, conversationId));
String finalUserInput = message;
if (enableRag && rolePrompt != null) {
int topK = rolePrompt.getTopK() != null && rolePrompt.getTopK() > 0 ? rolePrompt.getTopK() : 5;
Double threshold = rolePrompt.getSimilarityThreshold();
SearchRequest.Builder builder = SearchRequest.builder()
.query(message)
.topK(topK);
if (threshold != null) {
builder = builder.similarityThreshold(threshold);
}
if (StringUtils.isNotBlank(rolePrompt.getCustomFilter())) {
builder = builder.filterExpression(rolePrompt.getCustomFilter());
}
SearchRequest searchRequest = builder.build();
var docs = vectorStore.similaritySearch(searchRequest);
StringBuilder contextBuilder = new StringBuilder();
for (Document doc : docs) {
if (contextBuilder.length() > 0) {
contextBuilder.append("\n\n---\n\n");
}
String content = doc.getText();
if (content == null) {
content = doc.toString();
}
contextBuilder.append(content);
}
String context = contextBuilder.toString();
String template = rolePrompt.getRagTemplate();
if (StringUtils.isNotBlank(template)) {
finalUserInput = template
.replace("{context}", context)
.replace("{query}", message);
}
}
return prompt.user(finalUserInput)
.stream()
.content();
}
}
3. Web 层接口:ChatBotController
Service 层返回的是一个 Flux<String> 响应式流。要将其暴露为 HTTP 接口,我们需要在 Controller 层配置正确的 Content-Type。
Spring WebFlux 提供了对 SSE 的原生支持。只需将 produces 属性设置为 MediaType.TEXT_EVENT_STREAM_VALUE,框架就会自动将 Flux 转换为 SSE 格式的流式响应。
produces = MediaType.TEXT_EVENT_STREAM_VALUE 这个配置告诉 Spring:
- 响应的 Content-Type 为
text/event-stream - 连接需要保持长连接(Keep-Alive)
- 每个 Flux 元素会被包装成
data: xxx\n\n格式发送
代码实现非常简洁:
package com.lanjii.biz.admin.ai.controller;
import com.lanjii.biz.admin.ai.service.ChatService;
import lombok.RequiredArgsConstructor;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
/**
* AI 智能问答
*
* @author lanjii
*/
@RestController
@RequestMapping("/chat")
@RequiredArgsConstructor
public class ChatBotController {
private final ChatService chatService;
/**
* 流式问答接口
*
* 前端通过 EventSource 连接此接口,即可实现打字机效果
*/
@GetMapping(value = "/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> chatStream(String message, String conversationId) {
return chatService.chatStream(message, conversationId);
}
}
4. 前端对接指南
如果你想快速验证这个接口,可以使用浏览器原生的 EventSource API。这是一个专门用于处理 SSE 的客户端 API,无需任何第三方库。
4.1 基础用法
下面是一个极简的 HTML 示例,展示如何建立 SSE 连接并实时接收数据:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>AI 对话测试</title>
</head>
<body>
<div id="output"></div>
<script>
const outputDiv = document.getElementById('output');
// 1. 建立 SSE 连接
const eventSource = new EventSource('/chat/stream?message=介绍一下Spring AI&conversationId=test123');
// 2. 监听消息推送
eventSource.onmessage = function(event) {
console.log("收到 Token:", event.data);
outputDiv.innerHTML += event.data; // 实时打字机效果
};
// 3. 处理错误或结束
eventSource.onerror = function() {
console.log("连接关闭或出错");
eventSource.close();
};
</script>
</body>
</html>
4.2 进阶实现:带输入框的交互式界面
如果需要实现用户可输入、可多次对话的界面,可以参考以下代码:
function sendMessage() {
const userInput = document.getElementById('userInput').value;
const conversationId = 'conv_' + Date.now(); // 生成唯一会话ID
const outputDiv = document.getElementById('output');
// 显示用户消息
outputDiv.innerHTML += `<div class="user-msg">${userInput}</div>`;
// 创建 AI 消息容器
const aiMsgDiv = document.createElement('div');
aiMsgDiv.className = 'ai-msg';
outputDiv.appendChild(aiMsgDiv);
// 建立 SSE 连接
const url = `/chat/stream?message=${encodeURIComponent(userInput)}&conversationId=${conversationId}`;
const eventSource = new EventSource(url);
eventSource.onmessage = (event) => {
aiMsgDiv.innerHTML += event.data; // 逐字显示
};
eventSource.onerror = () => {
eventSource.close();
console.log('流式响应结束');
};
}
4.3 常见问题
Q: EventSource 是否支持 POST 请求? A: 原生 EventSource 只支持 GET 请求。如果需要 POST,可以使用 fetch API 配合 ReadableStream 来实现。
Q: 如何取消正在进行的请求? A: 调用 eventSource.close() 即可断开连接。
Q: 跨域问题如何处理? A: 服务端需要在响应头中添加 Access-Control-Allow-Origin 等 CORS 配置。
5. 项目资源
- Gitee 源码仓库:https://gitee.com/leven2018/lanjii这里提供了项目的完整源代码、SQL 脚本以及后续的功能更新。
- 在线体验地址:http://106.54.167.194/admin/login无需本地部署,您可以直接访问此系统体验文中的动态模型配置与流式对话功能。
6. 总结与架构优势
通过这两篇文章,我们展示了如何在 Spring Boot 项目中构建一个企业级的 AI 对话模块:
架构特点
- 动态工厂模式:解决了模型热切换的问题,无需重启服务即可更换 AI 提供商或模型版本
- 可配置的角色系统:通过数据库配置实现不同的 AI 人设,支持品牌专属对话风格
- 编程式 RAG:在 Service 层实现了更精细的知识检索控制,支持自定义过滤和模板渲染
- 流式响应:提供了高性能的 SSE 接口,大幅提升用户体验
- 元数据过滤:通过 Spring AI 的表达式语言实现了细粒度的数据权限控制

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)