构建 Agent 智能体:OpenStation 与 Coze Studio开发平台集成实践
本文介绍了OpenStation+CozeStudio组合架构在AI私有化部署中的应用方案。该方案解决了模型管理分散、服务化成本高、应用迭代慢三大痛点:OpenStation负责模型本地化部署与全生命周期管理,CozeStudio实现可视化应用编排。文章详细展示了Qwen3模型部署流程、与CozeStudio的集成配置方法,并通过Agent智能体案例演示了从搭建到发布的完整流程。该组合架构通过标准
一、为什么需要 OpenStation + Coze Studio 组合架构?
在私有化部署的实际场景中,AI 工程团队往往会遭遇三大核心难题:
-
模型管理处于分散状态:像 LLaMA、ChatGLM 等众多本地模型,没有一个统一的调度机制来协调运作;
-
服务化过程耗费较高成本:API 封装、鉴权设计以及推理资源监控等工作,都需要人工手动完成;
-
应用迭代速度较为迟缓:每当有新的需求变更出现,前后端功能都得重新进行开发。
而本次实践给出的解决办法是:
-
OpenStation 负责大模型的本地化部署与服务全生命周期管理;
-
Coze Studio 承担 AI 可视化应用编排和业务逻辑快速实现。
二者通过标准 API 解耦,且都支持本地及私有化部署,由此能够构建起一条完整的 AI 工程流水线,从而高效地解决上述存在的痛点问题。
二、实战部署:OpenStation 的模型服务化关键步骤
1. 模型文件来源(以部署 Qwen3 模型为例)
OpenStation平台支持两种模型加载方式:
-
从预下载的模型库加载(如:DeepSeek-R1/Qwen3 系列);
-
直接挂载本地模型文件路径。
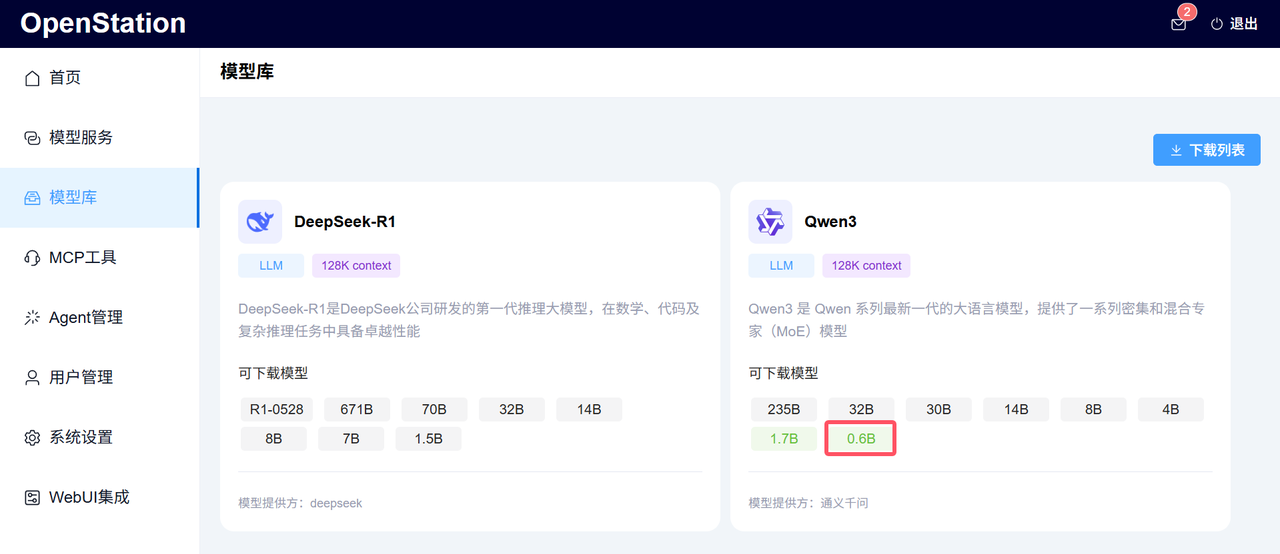
2. 模型服务部署
在「模型服务」中点击「新增部署」按钮即可完成部署。实测以从模型库下载的 Qwen3-0.6B 模型为例,部署后界面如下:
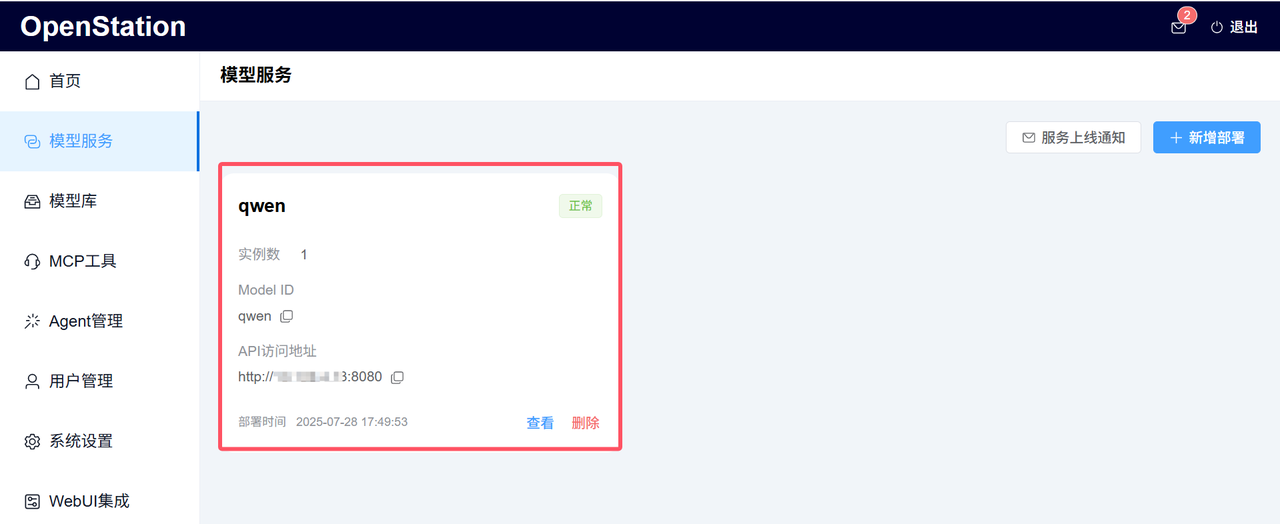
3. 服务上线自动通知
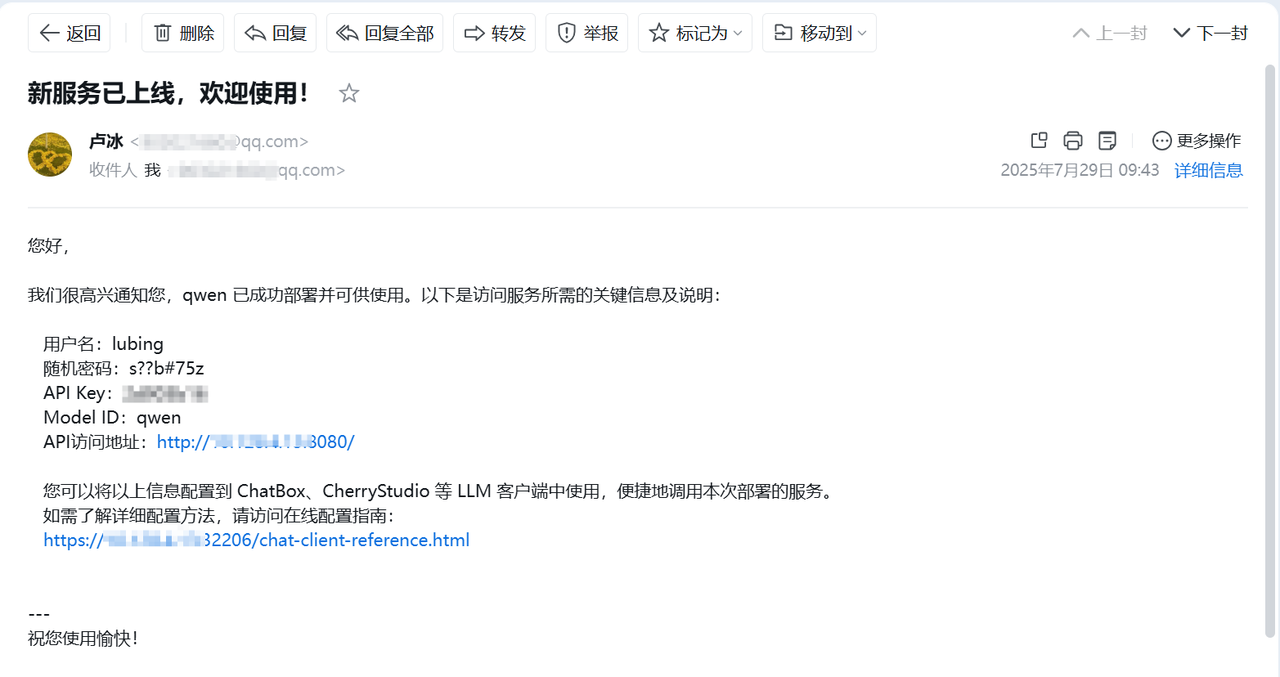
模型服务部署成功后,将瞬间生成标准 OpenAI 格式接口,并自动通过邮件推送关键信息(Model ID、API Key、API 访问地址等)至指定邮箱,便于快速调用。
三、与 Coze Studio 的深度融合:打造生产级 AI 应用
关键配置步骤
本次实践是以qwen模型为例,将 OpenStation 的私有模型服务qwen连接到 Coze中,执行步骤如下:
-
拷贝模版文件:复制coze自带的model_template_qwen.yaml模版配置到coze-studio/backend/conf/model路径下并重命名为qwen.yaml;
-
修改模版配置:参考OpenStation发送的服务通知邮件,填写模型服务的地址、API Key、模型ID等信息到qwen.yaml配置中;
-
模型启动编排:执行 docker compose --profile "*" restart coze-server 命令将模型服务添加到coze中。
具体配置信息如下:
id: 2005
name: Qwen3-0.6B
icon_uri: default_icon/qwen_v2.png
icon_url: ""
description:
zh: 通义千问模型
en: qwen model description
default_parameters:
- name: temperature
label:
zh: 生成随机性
en: Temperature
desc:
zh: '- **temperature**: 调高温度会使得模型的输出更多样性和创新性,反之,降低温度会使输出内容更加遵循指令要求但减少多样性。建议不要与“Top p”同时调整。'
en: '**Temperature**:\n\n- When you increase this value, the model outputs more diverse and innovative content; when you decrease it, the model outputs less diverse content that strictly follows the given instructions.\n- It is recommended not to adjust this value with \"Top p\" at the same time.'
type: float
min: "0"
max: "1"
default_val:
balance: "0.8"
creative: "1"
default_val: "1.0"
precise: "0.3"
precision: 1
options: []
style:
widget: slider
label:
zh: 生成多样性
en: Generation diversity
- name: max_tokens
label:
zh: 最大回复长度
en: Response max length
desc:
zh: 控制模型输出的Tokens 长度上限。通常 100 Tokens 约等于 150 个中文汉字。
en: You can specify the maximum length of the tokens output through this value. Typically, 100 tokens are approximately equal to 150 Chinese characters.
type: int
min: "1"
max: "4096"
default_val:
default_val: "4096"
options: []
style:
widget: slider
label:
zh: 输入及输出设置
en: Input and output settings
- name: top_p
label:
zh: Top P
en: Top P
desc:
zh: '- **Top p 为累计概率**: 模型在生成输出时会从概率最高的词汇开始选择,直到这些词汇的总概率累积达到Top p 值。这样可以限制模型只选择这些高概率的词汇,从而控制输出内容的多样性。建议不要与“生成随机性”同时调整。'
en: '**Top P**:\n\n- An alternative to sampling with temperature, where only tokens within the top p probability mass are considered. For example, 0.1 means only the top 10% probability mass tokens are considered.\n- We recommend altering this or temperature, but not both.'
type: float
min: "0"
max: "1"
default_val:
default_val: "0.95"
precision: 2
options: []
style:
widget: slider
label:
zh: 生成多样性
en: Generation diversity
meta:
name: Qwen3-0.6B
protocol: qwen
capability:
function_call: true
input_modal:
- text
input_tokens: 128000
json_mode: false
max_tokens: 128000
output_modal:
- text
output_tokens: 16384
prefix_caching: false
reasoning: false
prefill_response: false
conn_config:
base_url: "http://IP地址:8080/v1"
api_key: "xxxxxxx"
timeout: 0s
model: "qwen"
temperature: 1
frequency_penalty: 0
presence_penalty: 0
max_tokens: 4096
top_p: 0.95
top_k: 0
stop: []
openai: null
claude: null
ark: null
deepseek: null
qwen:
response_format:
type: text
jsonschema: null
gemini: null
custom: {}
status: 0集成优势对比
|
传统方式 |
OpenStation + Coze Studio 组合 |
|
需手动维护 API 客户端 |
原生兼容 OpenAI SDK 标准 |
|
需自建负载均衡机制 |
自动将流量分发到多个模型副本 |
|
需独立实现 Stream 响应 |
开箱即用流式输出功能 |
四、实战案例:构建 Agent 智能体
Coze Studio支持Prompt、RAG、Plugin、Workflow等核心技术,通过可视化工作流编排,开发者可以零代码或低代码开发复杂AI应用。平台内置插件框架,可将第三方API或私有能力封装为插件,扩展智能体功能。本次实践以创建「Agent智能体」为例,展示从搭建到发布的完整流程。
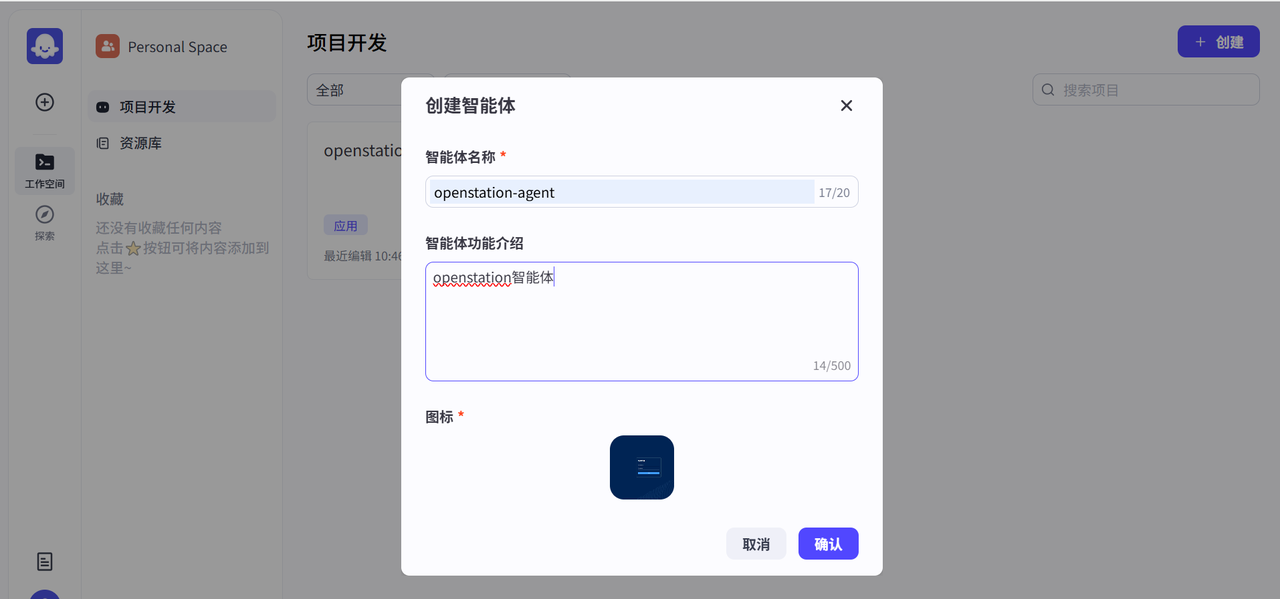
智能体创建步骤
在首页“项目开发”中选择“创建”按钮:支持「创建智能体」或「创建应用」(本次以创建智能体为例);
-
配置基础信息:智能体名称、智能体功能介绍、图标,最后点击确认。
核心配置与发布
点击新创建的智能体(如 “openstation-agent”),支持以下配置并发布:
-
配置插件:支持创建、配置和管理插件,可封装第三方API或私有功能,扩展智能体的能力;
-
添加工作流:通过拖拽节点的方式,快速构建复杂的工作流,方便开发者设计业务逻辑;
-
发布:调试完成后,点击右上角「发布」按钮,生成独立Agent智能体,如下图所示;
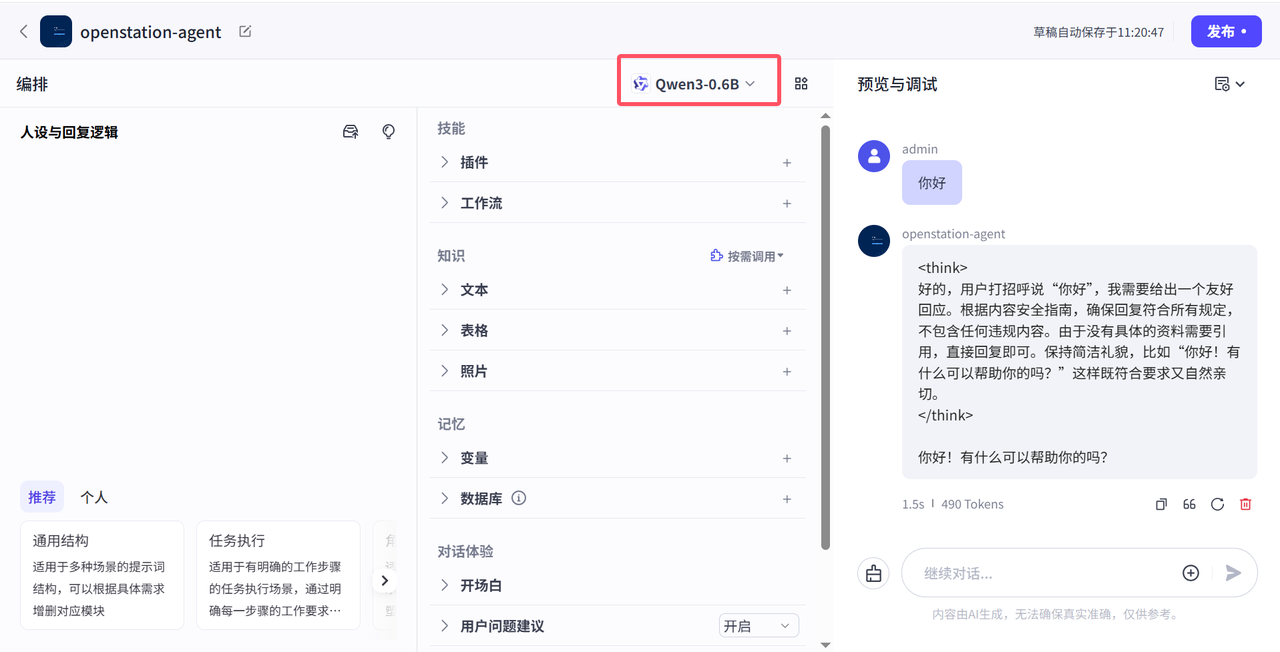
openstation-agent智能体发布后如下图所示:
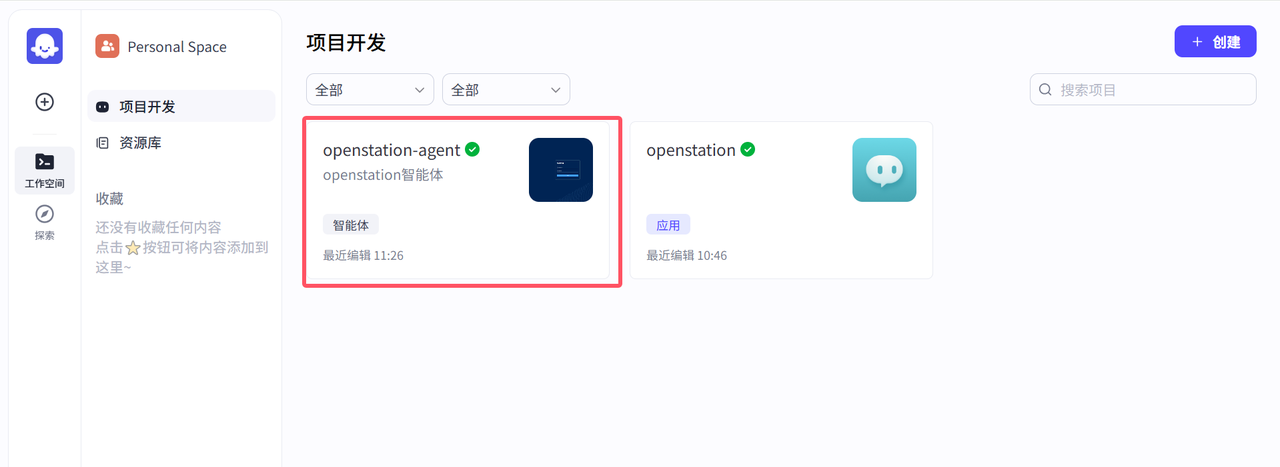
五、部署指南:如何快速上手
OpenStation 部署步骤
项目地址:https://github.com/fastaistack/OpenStation
1. 在线安装(支持Ubuntu22.04 / 20.04 / 18.04系列及Centos7系列)
curl -O https://fastaistack.oss-cn-beijing.aliyuncs.com/openstation/openstation-install-online.sh
bash openstation-install-online.sh --version latest也可直接下载在线安装包(openstation-pkg-online-latest.tar.gz),上传至Linux服务器后执行:
tar -xvzf openstation-pkg-online-latest.tar.gz
cd openstation-pkg-online-latest/deploy
bash install.sh true2. 离线安装(仅支持Ubuntu 22.04.2/20.04.6/18.04.6)
点击「离线 OpenStation 安装包下载」,参考官方离线安装文档。
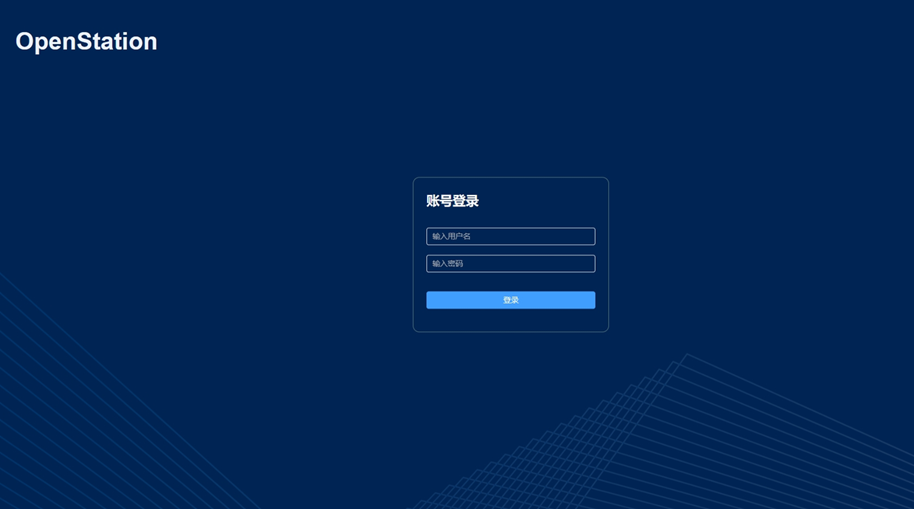
部署完成后,登录页面如下:
Coze Studio 部署参考
Coze Studio 具体部署方式请参考官方项目地址:https://github.com/coze-dev/coze-studio
结论:加速 AI 应用落地
OpenStation 与 Coze Studio 二者通过标准 API 解耦且支持私有化部署,形成了完整的 AI 工程流水线,能有效降低生产级 AI 应用的构建门槛,助力团队快速落地各类复杂 AI 场景,从模型部署到应用发布的全流程实践表明:
-
OpenStation 凭借便捷的模型本地化部署、全生命周期管理及自动服务化能力,解决了模型管理碎片化、服务化成本高的痛点;
-
Coze Studio 则以可视化编排、零代码 / 低代码开发模式,加速了 AI 应用迭代与企业级智能体构建。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)