论文深度解析:多模态大模型在城市骑行环境感知模拟中的潜力探索
随着全球对环境、社会、治理(ESG)原则的重视日益提升,城市骑行凭借其环境友好、有益健康、促进社交等多重优势,已成为可持续交通系统的核心组成部分(United Nations General Assembly, 2022)。然而,要通过提升骑行率实现相关政策目标,关键在于深入理解影响个体骑行决策的核心因素——骑行环境感知。人类对城市骑行环境的主观感知,是连接客观环境与个体出行行为的关键中介(Bli
论文深度解析:多模态大模型在城市骑行环境感知模拟中的潜力探索
原文:Exploring multimodal large language models’ potential in simulating human perception of urban cycling environments: A street-view perspective
一、论文概述
1. 研究背景与核心问题
随着全球对环境、社会、治理(ESG)原则的重视日益提升,城市骑行凭借其环境友好、有益健康、促进社交等多重优势,已成为可持续交通系统的核心组成部分(United Nations General Assembly, 2022)。然而,要通过提升骑行率实现相关政策目标,关键在于深入理解影响个体骑行决策的核心因素——骑行环境感知。人类对城市骑行环境的主观感知,是连接客观环境与个体出行行为的关键中介(Blitz, 2021),直接决定了骑行行为的意愿与频率。
传统的骑行环境感知评估方法面临显著瓶颈:问卷调查、深度访谈、焦点小组等定性方法,虽能深入捕捉骑行者的主观体验,但存在成本高、耗时长、样本量有限的问题;GPS、生理传感器、实地实验等定量方法,虽能获取客观数据,却受限于传感器部署成本与地理覆盖范围,难以支撑城市级的系统性分析(A. Li et al., 2020; S. Li et al., 2021)。
街景图像(SVI)的出现为解决规模化问题提供了新可能,其高真实性与广覆盖性使其成为城市环境研究的热门数据源(Ito et al., 2024; Ito and Biljecki, 2021)。但现有基于SVI的研究仍存在核心局限:无论是用共享单车骑行量等客观行为数据验证指标,还是依赖志愿者评分训练预测模型,均离不开大量人工输入,主观判断与验证环节的自动化缺失,严重制约了研究的规模化推广(Zeng et al., 2024)。
多模态大语言模型(MLLMs)的跨模态感知与推理能力,为模拟人类复杂感知提供了新路径,已在城市步行便利性(Ki et al., 2025)、城市吸引力(Malekzadeh et al., 2025)、景观偏好(Tung et al., 2025)等领域取得显著成果。但在骑行环境感知领域,MLLMs的应用仍存在两大空白:一是其模拟人类感知的有效性尚未得到充分验证;二是现有研究多将MLLMs视为“黑箱评估器”,仅关注其数值输出,忽视了其生成的文本解释中蕴含的感知逻辑与决策过程,导致模型的认知机制难以被理解(Wang et al., 2025)。
为此,本文聚焦两大核心研究问题:
- 多模态大模型能否利用街景图像(SVI)有效模拟人类对城市骑行环境的感知(包括客观安全维度与主观美学维度)?
- 如何构建可解释性分析框架,系统揭示大模型在骑行环境评估中的感知逻辑、决策过程及认知局限?
2. 核心贡献
- 方法论创新:提出级联感知解析框架(CPPF),通过“二级LLM解析MLLM文本解释+语义分割验证幻觉+XGBoost代理模型+SHAP可解释分析”的全流程设计,首次系统性打开了MLLMs在城市感知任务中的“决策黑箱”,解决了传统研究中模型不可解释的核心痛点。
- 实证发现突破:明确了MLLMs在骑行环境感知中的能力边界——在交通安全、公共安全等客观维度与人类判断高度一致,而在景观美感等主观维度表现不佳,揭示了AI“秩序偏好”的简化美学逻辑与人类“语境化”复杂直觉的本质差异。
- 理论与实践价值:从理论上区分了AI“统计美学”与人类“语境化美学”两大范式;从实践上为城市规划者提供了“AI快速审计+人类专业决策”的人机协同方案,既发挥AI的规模化优势,又避免AI美学偏误导致的城市空间同质化。
二、文献综述(Literature Review)
文献综述部分围绕“骑行环境感知评估”的技术演进脉络展开,从传统方法、SVI基于方法到AI模拟方法,层层递进地梳理研究现状、局限与缺口,为本文的创新点提供坚实的理论支撑。
2.1 传统骑行环境感知评估方法
传统方法的核心逻辑是“直接捕捉人类感知与行为反馈”,可分为定性与定量两大类,其发展历程反映了从“深度挖掘个体体验”到“尝试客观量化”的演进,但始终未能突破可扩展性瓶颈。
2.1.1 骑行环境感知的核心影响因素体系
研究普遍将影响骑行环境感知的因素归纳为三大维度,且各维度呈现从“即时交互”到“宏观环境”的空间递进特征,形成完整的感知链条:
- 交通安全维度(即时交互层):作为骑行者最直接的感知对象,核心影响因素包括机动车的速度与流量(Rivera Olsson and Ellder, 2023)、超车时的安全距离(Von Stülpnagel et al., 2022)、机非隔离程度(Teixeira et al., 2020; Von Stülpnagel and Binnig, 2022)等。这些因素直接决定了骑行者的即时风险判断,是影响骑行意愿的首要因素。
- 基础设施条件维度(路径设施层):聚焦骑行路径本身的物理特征,包括道路坡度(Berghoefer and Vollrath, 2023)、路面平整度(Gao et al., 2018)、自行车道的连续性与宽度(G€ossling and McRae, 2022)等。这类因素影响骑行的舒适度与可控感,长期积累会显著改变骑行者的环境评价。
- 环境干扰维度(宏观环境层):涵盖骑行场景的整体氛围,包括街景建筑的空间特征(Cho et al., 2009)、交通噪音(Apparicio et al., 2021)、夜间照明质量(Beckers et al., 2024)、空气质量(Apparicio et al., 2021)等。这些因素虽不直接构成即时风险,但会通过影响心理负荷,间接改变骑行者的整体体验与感知评价。
这一因素体系的形成,是众多学者通过长期实证研究逐步完善的结果。例如,Cho等(2009)通过对行人与骑行者安全感知的研究,发现街景建筑的布局会影响骑行者对环境安全性的判断;Beckers等(2024)针对佛兰德斯地区的研究表明,夜间照明不足会显著降低骑行者的安全感,尤其对女性骑行者的影响更为明显。
2.1.2 定性评估方法:深度捕捉主观体验
定性方法以“理解骑行者内心感受与偏好”为核心目标,通过灵活的交互方式获取深度信息,是早期骑行环境感知研究的主流方法:
- 问卷调查:通过结构化或半结构化问卷,大规模收集骑行者对环境各维度的主观评价。G€ossling and McRae(2022)通过问卷调查,识别出骑行者认为“主观安全”的骑行基础设施关键特征,为城市骑行道设计提供了直接参考;Fernandez-Heredia等(2014)通过面向不同人群的问卷,发现通勤骑行者更关注效率与安全,而休闲骑行者更重视景观与舒适度。
- 深度访谈与焦点小组:聚焦小范围样本,深入挖掘感知背后的深层原因。Simpson(2017)通过深度访谈,提出“骑行环境氛围”的概念,指出骑行者的感知不仅源于物理环境,还包括对空间“归属感”与“舒适度”的主观体验;Kalra等(2023)通过焦点小组讨论,发现不同年龄、性别、骑行经验的群体,对骑行环境的需求存在显著差异,年轻男性更能容忍混合交通,而老年人与女性更依赖专用自行车道。
定性方法的优势在于能捕捉到难以量化的主观感受与隐性需求,但局限性也十分突出:样本量通常较小(一般不超过100人),地理覆盖范围有限(多集中于单一城市或社区),且数据处理依赖人工编码,耗时耗力,难以推广至城市级分析(Zhang et al., 2024)。
2.1.3 定量评估方法:尝试客观量化感知
为克服定性方法的主观性与局限性,学者们引入技术工具,通过客观数据间接反映骑行环境感知:
- GPS与轨迹分析:通过GPS设备记录骑行者的路线选择、停留时间、速度变化等数据,间接推断其对环境的偏好。Battiston等(2023)利用大规模GPS数据,发现女性骑行者更倾向于选择机非隔离的自行车道,而男性骑行者更愿意选择shortcut(捷径),即使这些路线存在混合交通;S. Li等(2021)通过分析深圳共享单车的GPS轨迹,揭示了骑行行为的时空规律与环境因素的关联。
- 生理传感器与物理指标测量:通过加速度计、心率监测器等设备,捕捉骑行者的生理反应,作为感知舒适度与安全性的客观代理指标。Gao等(2018)利用加速度计测量路面振动,发现振动强度与骑行者的舒适度评分呈显著负相关;Nu~nez等(2020)结合垂直加速度测量与环境质量评估,构建了骑行基础设施舒适度指数。
- 实地观测与实验:通过人工观测或控制实验,获取环境特征与感知的直接关联。Von Stülpnagel等(2022)通过实地观测,记录了不同道路类型下机动车超越骑行者的安全距离,发现专用自行车道的超车距离显著大于混合车道,且这一差异与骑行者的安全感知高度相关;Berghoefer and Vollrath(2023)通过自行车模拟器实验,发现道路坡度对骑行者的偏好影响显著,坡度超过5%时,骑行意愿下降40%以上。
定量方法的优势在于数据客观性强、可重复性高,但仍面临规模化瓶颈:传感器部署成本高昂,难以覆盖大规模区域;实地实验的控制条件与真实场景存在差异,结果的外推性有限;且多数定量指标只能间接反映感知,难以完全替代人类的主观判断(Ahmed et al., 2025)。
2.1.4 传统方法的共性瓶颈与研究缺口
综合来看,传统方法的核心问题是可扩展性不足与主观-客观脱节:
- 可扩展性不足:无论是定性方法的人工访谈、问卷编码,还是定量方法的传感器部署、实地观测,均需大量人力物力投入,导致样本量有限、地理覆盖范围狭窄,无法满足城市级、系统性的骑行环境评估需求(Zhang et al., 2024)。
- 主观-客观脱节:定性方法过于依赖主观体验,缺乏客观数据支撑;定量方法过于侧重客观指标,难以捕捉人类感知的复杂性与情境依赖性,两者未能有效融合(Blitz, 2021)。
这些瓶颈促使学者们寻找新的数据源与方法,街景图像(SVI)的兴起正是这一需求的直接回应。
2.2 基于街景图像(SVI)的骑行环境感知评估方法
基于SVI的方法核心逻辑是“通过图像提取客观环境特征,预测人类主观感知或客观行为”,其突破了传统方法的地理覆盖限制,但仍未解决“主观判断依赖人工”的核心问题。
2.2.1 SVI的技术优势与应用基础
街景图像之所以能成为城市环境研究的核心数据源,源于其三大关键优势:
- 高真实性:SVI能真实还原城市街道的物理环境,包括道路布局、建筑形态、植被覆盖、交通设施等,提供与实地观测一致的视觉信息(Ito and Biljecki, 2021)。
- 广覆盖性:主流地图服务商(如百度地图、谷歌地图)的街景数据已覆盖全球多数城市的主要道路,能轻松实现城市级甚至区域级的大范围数据采集(Xu et al., 2025)。
- 低成本与可重复性:相较于传统实地调查,SVI数据可通过API批量获取,无需现场部署设备或投入大量人力,且数据具有时间戳,支持跨时间维度的动态分析(Ito et al., 2024)。
这些优势使SVI有效弥补了传统方法“真实性与规模化不可兼得”的缺陷,为骑行环境感知的大规模研究提供了可行路径(Gao and Fang, 2025)。
2.2.2 基于SVI的两大研究范式
现有基于SVI的研究可分为两大范式,分别聚焦“客观行为预测”与“主观感知模拟”,但均依赖人工输入作为核心支撑:
范式一:以客观行为数据为反馈的骑行便利性评估
该范式的核心是构建“环境特征-骑行行为”的预测模型,通过SVI提取多维物理环境特征,构建骑行便利性指数(bikeability index),并以真实骑行行为数据验证模型有效性:
- Xu等(2025)通过SVI提取道路类型、机非隔离程度、交通标志密度、植被覆盖等多维特征,构建了综合骑行便利性指数,并利用共享单车骑行量数据进行验证,发现该指数能解释35%的骑行量空间变异,为城市骑行基础设施规划提供了量化工具。
- Gao and Fang(2025)在类似框架中,引入机器学习预测的“感知质量”作为中间变量,将客观环境特征与主观感知相结合,显著提升了对骑行量的解释力(R²从0.32提升至0.47),证明了主观感知在连接环境与行为中的关键作用。
该范式的优势在于能直接对接城市规划的实际需求,提供可量化的决策依据,但局限在于:骑行行为数据(如共享单车骑行量)受多种因素影响(如出行距离、目的地分布),难以单独剥离环境感知的作用;且模型缺乏对主观感知的直接刻画,无法解释“为何该环境更适合骑行”的深层原因。
范式二:以主观感知评分为反馈的感知预测模型
该范式的核心是直接模拟人类对骑行环境的主观感知,通过招募志愿者对SVI进行评分,训练计算机视觉模型,实现感知的自动化预测:
- Ito and Biljecki(2021)首次将SVI与主观感知结合,招募志愿者对街景图像的“吸引力”“安全感”“舒适度”三个维度进行评分,利用计算机视觉技术提取图像特征,训练预测模型,成功将主观感知纳入骑行便利性评估体系,使评估更贴合骑行者的实际体验。
- Zeng等(2024)提出SSB(Public Security-公共安全、Traffic Safety-交通安全、Scenic Beauty-景观美感)框架,系统界定了骑行环境感知的三大核心维度。基于51名志愿者的评分数据,利用语义分割等计算机视觉技术,训练了K-means SMOTE-RF模型,实现了三大维度感知的自动化预测,准确率分别达到82%、85%、76%,为本文的研究奠定了重要基础。
- 其他延伸研究:Apparicio等(2021)利用SVI评估德里市骑行环境的噪音与空气污染暴露风险,结合志愿者对“环境舒适度”的评分,发现视觉上的“绿色覆盖”与实际舒适度呈正相关;Beckers等(2024)通过SVI分析夜间照明条件,结合骑行者的安全感知评分,构建了夜间骑行安全评估模型。
该范式的优势在于直接聚焦主观感知,能更精准地反映骑行者的体验,但核心局限在于:志愿者评分的获取仍需大量人工投入,且评分结果受评估者的年龄、性别、骑行习惯等因素影响,难以实现大规模、多样化人群的感知模拟(Cui et al., 2023);同时,模型训练依赖标注数据,当应用于新的城市或场景时,泛化能力有限。
2.2.3 基于SVI方法的共性局限与研究缺口
尽管基于SVI的方法解决了传统方法的规模化问题,但仍存在三大未解决的核心挑战:
- 主观反馈的人工依赖:无论是行为数据的整理(如共享单车骑行量的清洗与匹配),还是感知评分的获取(如志愿者标注),均离不开大量人工参与,人工成本仍是制约研究规模扩大的关键瓶颈(A. Li et al., 2020)。
- 感知维度的简化:现有研究多聚焦于单一或少数几个感知维度(如安全、舒适),未能全面覆盖骑行者的复杂感知需求(如社交氛围、文化认同);且对感知的刻画多为数值评分,缺乏对评分背后“为什么”的逻辑解释(Zeng et al., 2024)。
- 环境特征的浅层提取:现有计算机视觉技术多提取低层次视觉特征(如像素比例、颜色分布)或结构化特征(如道路类型、建筑密度),难以捕捉街景的整体氛围、空间布局等高层次特征,而这些特征恰恰是影响人类主观感知的关键(Ewing and Handy, 2009)。
这些挑战为多模态大语言模型(MLLMs)的介入提供了契机——MLLMs的跨模态理解能力的文本生成能力,有望同时解决“主观感知自动化”与“感知逻辑可解释”两大问题。
2.3 AI在城市感知中的模拟与解释:从黑箱到可解释
随着人工智能技术的发展,学者们开始尝试用AI模拟人类的城市感知,从早期的计算机视觉模型到近期的多模态大语言模型,技术路径不断演进,但“模型可解释性”始终是核心痛点。
2.3.1 早期AI城市感知:基于计算机视觉的特征映射
在MLLMs兴起之前,AI在城市感知中的应用主要依赖传统计算机视觉模型,核心逻辑是“低层次视觉特征→感知评分”的直接映射:
- 这类模型通过卷积神经网络(CNN)、语义分割等技术,从SVI中提取建筑密度、植被覆盖、道路宽度等客观特征,再通过回归模型预测人类的感知评分(如安全度、美观度)(Zhao et al., 2024)。
- 典型应用包括:Naik等(2014)利用CNN模型从街景图像中提取特征,预测街道的“安全感知评分”,准确率达到78%;Suel等(2019)通过深度学习分析街景图像,测量城市的社会、环境与健康不平等,发现视觉特征与区域贫困水平呈显著相关。
早期AI模型的优势在于运算效率高、可解释性相对较强(能明确哪些客观特征影响感知),但局限也十分明显:
- 感知模拟的深度不足:仅能捕捉低层次、结构化的环境特征,无法理解街景的整体氛围、文化内涵等高层次信息,模拟的感知缺乏复杂性与灵活性(Ewing and Handy, 2009)。
- 泛化能力有限:模型训练高度依赖特定区域的标注数据,当应用于不同城市或文化背景时,性能显著下降(Malekzadeh et al., 2025)。
- 缺乏逻辑解释:仅能输出感知评分,无法解释“为什么该场景被评为安全/美观”,难以支撑后续的规划决策与模型优化(Lundberg and Lee, 2017)。
2.3.2 多模态大语言模型(MLLMs)的突破与应用现状
多模态大语言模型(MLLMs)的出现,彻底改变了AI城市感知的技术路径。MLLMs以强大的大语言模型(LLM)为核心,能接收、理解并生成文本、图像等多模态信息,具备跨模态推理与类人化表达能力(Yin et al., 2024),其优势在于:
- 能理解高层次、非结构化的环境特征(如“街道氛围”“空间归属感”);
- 能同时输出感知评分与文本解释,为模型可解释性提供基础;
- 具备更强的泛化能力,能适应不同城市与文化背景(Bai et al., 2025)。
目前,MLLMs已在多个城市感知领域取得显著进展:
- 城市步行便利性评估:Ki等(2025)利用ChatGPT的视觉推理能力,结合多源空间数据,构建了精细化的步行便利性评估模型,不仅能输出评分,还能识别影响步行体验的关键问题(如人行道狭窄、障碍物多),准确率达到83%,显著高于传统计算机视觉模型。
- 城市吸引力与景观偏好:Malekzadeh等(2025)对比了ChatGPT与人类对赫尔辛基城市空间的吸引力评价,发现AI更偏好秩序井然、绿色覆盖高的郊区,而人类更重视充满活力、具有文化特色的城市中心;Tung等(2025)分析了ChatGPT-4与LLaVA模型对自然景观的偏好,发现模型能较好地识别典型的优美景观,但对具有独特文化内涵的景观感知不足。
- 其他城市感知任务:Sun等(2025)利用MLLMs分析滨海城市空间的受欢迎度影响机制,发现模型能有效识别“视野开阔”“植被丰富”等关键特征;Hou等(2025)提出“城市感知的大语言模型时代”,认为MLLMs有望实现城市感知的自动化、精细化与可解释化。
在骑行环境感知领域,MLLMs的应用仍处于起步阶段,现有研究仅初步验证了其可行性,尚未形成系统性的研究框架:
- 现有研究多聚焦于单一感知维度(如交通安全),缺乏对多维度感知(尤其是主观美学维度)的综合评估;
- 仅关注模型输出的数值评分,忽视了文本解释中蕴含的感知逻辑,模型仍处于“黑箱”状态(Wang et al., 2025);
- 未深入探讨MLLM感知与人类感知的差异根源,难以指导模型优化与实际应用。
2.3.3 大语言模型(LLMs)的文本分析能力:可解释性的关键支撑
要打开MLLMs的“决策黑箱”,核心在于挖掘其生成的文本解释。随着自然语言处理技术的成熟,LLMs已具备强大的文本分析能力,为解析MLLM的感知逻辑提供了工具支撑:
- 文本理解与信息提取:LLMs能精准识别文本中的关键信息、逻辑关系与情感倾向,可从MLLM的解释文本中提取其关注的环境要素、要素间的关联及对感知的影响方向(Liu et al., 2024)。
- 细粒度情感分析:专门的情感大模型(如EmoLLMs)能实现细粒度的情感强度识别与语义分类,可量化文本解释中对不同环境要素的情感倾向,为感知逻辑的量化分析提供基础(Liu et al., 2024)。
- 城市研究中的应用先例:在城市研究中,LLMs已被用于分析社交媒体评论、在线评价等非结构化文本,挖掘公众对城市服务、环境质量的态度与需求(Bhakuni et al., 2022; Hu et al., 2025)。例如,Bhakuni等(2022)利用LLMs分析Twitter数据中的讽刺言论,识别公众对城市交通政策的潜在不满;Hu等(2025)通过LLMs推断中国微博用户对新冠疫情的非二元情绪,为城市应急管理提供参考。
这些应用表明,LLMs的文本分析能力已足够支撑对MLLM解释文本的深度挖掘,有望构建“MLLM感知输出→LLM文本解析→感知逻辑量化”的可解释性分析链条。
2.3.4 现有研究的核心缺口与本文的创新切入点
综合上述三大研究领域的现状,现有研究存在四大核心缺口,构成了本文的创新基础:
- MLLM在骑行环境感知中的系统性验证缺失:现有研究未全面验证MLLM在多维度(客观安全+主观美学)骑行环境感知中的表现,其能力边界与适用场景尚不明确。
- MLLM感知逻辑的可解释性研究不足:现有研究仅关注MLLM的数值输出,忽视了文本解释的价值,未能揭示模型“为何如此判断”的内在逻辑,模型仍为“黑箱”。
- 人机感知差异的根源未被深入探究:现有研究仅发现AI与人类感知存在差异,但未量化差异的模式、场景及核心影响因素,难以指导模型优化。
- 缺乏兼顾规模化与可解释性的研究框架:现有方法要么难以规模化(传统方法),要么缺乏可解释性(早期AI模型),要么未充分利用文本解释(现有MLLM研究),尚未形成兼顾三者的系统性框架。
针对这些缺口,本文的创新切入点在于:
- 构建“人机感知一致性验证+级联感知解析”的双阶段研究框架,既验证MLLM的感知模拟效果,又揭示其内在逻辑;
- 利用LLM的文本分析能力,结合语义分割与可解释AI(XAI)技术,解决MLLM的“黑箱”问题与“幻觉”风险;
- 从客观安全与主观美学两大维度,全面探究人机感知差异的模式与根源,明确MLLM的能力边界与应用场景。
三、研究方法(Method)
本文的方法论体系围绕“验证MLLM感知效果→解析MLLM感知逻辑→解释人机感知差异”的核心目标展开,分为“研究区域与数据准备”“人机感知一致性验证”“级联感知解析框架(CPPF)”“数据分析与模型验证”四大模块,流程严谨且创新性突出。
3.1 研究区域与数据
3.1.1 研究区域
选取中国深圳市南山区、福田区、罗湖区三大核心建成区作为研究区域(图1),选择该区域的核心原因包括:
- 骑行基础设施完善:深圳是中国骑行友好城市的代表,核心城区已建成较为密集的自行车道网络,骑行活动频繁,为感知评估提供了丰富的场景基础;
- 空间异质性显著:三大区域涵盖现代 arterial roads、传统小巷、商业街区、公园绿道等多种地形与景观类型,骑行环境从“有序安全”到“拥堵复杂”呈梯度分布,能充分检验MLLM在多样化场景下的感知能力;
- 数据可获得性强:百度地图在深圳核心城区的街景覆盖完整,数据质量高,且团队前期已积累该区域的人类感知评分数据集(Zeng et al., 2024),为人机对比提供了可靠基准。
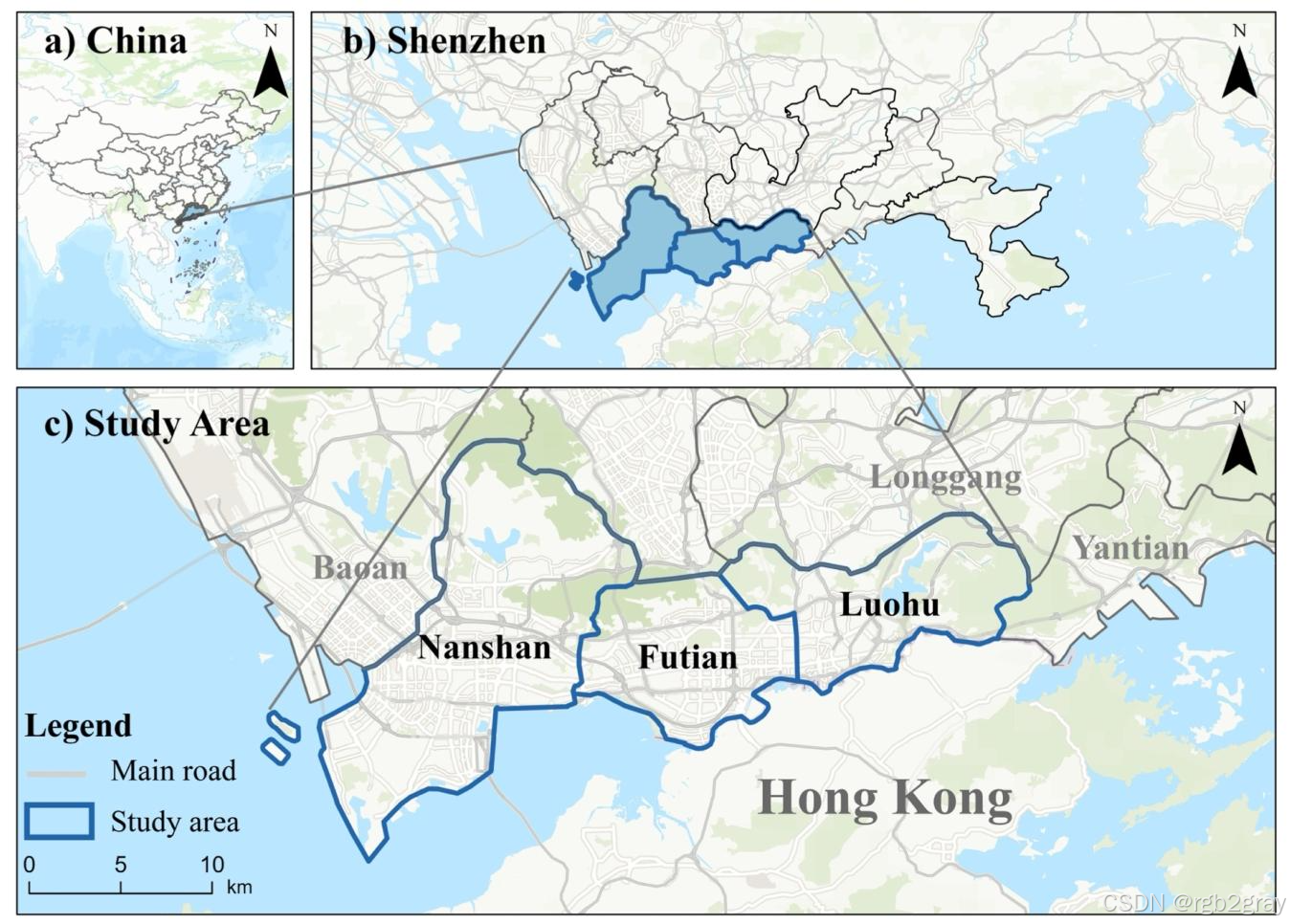
图1 研究区域示意图:(a) 研究区域在中国的地理位置;(b) 深圳市行政区划,高亮显示核心建成区;© 研究区域详细地图,包含南山区、福田区、罗湖区及主要道路网络,比例尺为10km
3.1.2 街景图像数据(SVI)
- 数据来源:百度地图街景API,该API覆盖中国大陆主要城市,数据更新及时,图像分辨率高,能满足精细化分析需求;
- 采集条件:为保证数据的时间一致性与光照可比性,所有图像均采集于2017年白天(9:00-17:00),天气为晴天或多云,避免雨天、雾天等恶劣天气对图像质量的影响;
- 样本设计:采用系统采样法,在研究区域内均匀设置7519个街景采样点,确保覆盖所有主要道路与骑行热点区域;每个采样点采集4个方向(0°、90°、180°、270°)的全景图像,形成360°无死角的街景覆盖,共获取30076张图像,单张图像分辨率为1024×1024像素;
- 预处理与质量控制:
- 空间筛选:通过GIS技术验证采样点位置,确保其均匀分布且覆盖所有主要道路、自行车道及骑行相关区域;
- 图像质量审核:人工剔除模糊、过曝光、严重遮挡(如施工围挡、大型车辆遮挡)、镜头污染等低质量图像,共剔除213张,最终保留29863张有效图像;
- 畸变校正:全景图像边缘存在固有镜头畸变,通过图像处理技术提取每张图像的核心视野部分(中心区域,畸变最小),确保输入MLLM的图像能真实反映实际场景。
3.1.3 人类感知评分数据集
基于团队前期研究(Zeng et al., 2024)构建的SSB框架(Public Security-公共安全、Traffic Safety-交通安全、Scenic Beauty-景观美感),该数据集是目前骑行环境感知领域质量较高的人类标注基准:
- 评估者招募:招募51名广州大学在读大学生志愿者(25名男性,26名女性),年龄范围为19-24岁,其中经常骑行(每周≥3次)23人,偶尔骑行(每月1-2次)18人,极少骑行(每年≤3次)10人,覆盖不同骑行习惯人群,确保评分的多样性;
- 评估流程:
- 统一培训:在评分前,向志愿者详细讲解SSB三个维度的定义、评估标准及示例(如“交通安全”定义为“骑行过程中避免与机动车、行人发生冲突的概率”,示例包括“有机非隔离带的道路=安全”“混合交通且无交通标志=不安全”);
- 评分任务:采用二分类强制选择设计(0=差,1=好),每位志愿者对500张随机抽取的街景图像进行评分,每张图像的评分时间不低于10秒,避免快速判断导致的误差;
- 质量控制:通过一致性检验(Cronbach’s α系数)验证评分可靠性,三个维度的α系数分别为0.87(交通安全)、0.89(公共安全)、0.78(景观美感),均高于0.7的可接受水平,表明评分数据可靠;
- 数据特点:将人类主观美学判断的固有差异性(如不同志愿者对同一景观的不同评价)视为“人类感知基准的有意义特征”,而非测量误差,这与传统研究中将差异性视为噪声的处理方式不同,更符合人类感知的真实特征(Tung et al., 2025)。
3.2 研究框架与数据生成
3.2.1 人机感知一致性验证
该阶段的核心目标是验证MLLM能否有效模拟人类对骑行环境的感知,通过构建“数字骑行者代理”,实现MLLM与人类评估的一对一对比。
(1)核心模型选择:Qwen-2.5-VL-72B
选择该模型作为核心MLLM,基于四大关键考量:
- 模型性能:720亿参数量确保其具备细粒度视觉识别与复杂推理能力,在图像理解、跨模态关联等任务中表现优异(Bai et al., 2025);
- 中文适配性:训练语料包含大量中文多模态数据,能更好地理解中国城市的街景语义(如“共享单车停放区”“非机动车道”等本土场景术语),减少文化与语言偏差(Qwen et al., 2025);
- 结构化输出支持:原生支持JSON等结构化格式输出,能同时输出评分与文本解释,便于大规模自动化数据处理与分析;
- 隐私与安全:支持本地部署,可避免街景数据外传,保障研究数据的隐私与安全,尤其适用于涉及城市敏感区域的研究。
(2)数字骑行者代理构建
为确保MLLM评估与人机评估的可比性,避免因“评估者身份差异”导致的偏差,构建个性化的数字骑行者代理,具体设计如下:
- 个性化提示词注入:将每位人类志愿者的背景信息(性别、年龄、骑行频率)动态注入系统提示词,使MLLM模拟该志愿者的感知视角(如“你是一名22岁的女性,每周骑行3次,请基于SSB框架对以下街景图像进行评分”);
- 评估任务对齐:指令MLLM对与人类志愿者完全相同的图像集进行评分,采用与人类一致的二分类标准(0=差,1=好),确保任务设计的一致性;
- 特殊提示优化:明确告知MLLM街景图像可能存在镜头畸变,要求其在评估时忽略畸变影响,仅关注实际环境特征;同时,提供Cityscapes标准词汇表(如Road、Sidewalk、Building、Vegetation等),引导MLLM在文本解释中使用标准化术语,便于后续解析。
提示词的最终结构如图3所示,通过四步迭代优化(从通用提示词→简单个性化提示词→包含评估标准的个性化提示词→包含标准化词汇的个性化提示词),确保提示词的有效性与稳定性。

图3 MLLM个性化提示词结构:包含人类感知模拟(注入志愿者背景信息)、任务定义(SSB维度定义与引导问题)、理由说明指南(要求引用环境要素并使用标准化词汇)、输出格式(JSON结构化输出,包含评分与文本解释)四大模块
(3)输出数据与稳定性验证
- 输出内容:每张图像的评估结果以JSON格式存储,包含两部分核心数据:① SSB三个维度的二分类评分(MLLM Scores);② 每个维度的文本解释(MLLM Comments),说明评分的依据(如“交通安全评分为1,理由:道路有明确的非机动车道隔离带,交通标志清晰,无明显交通冲突点”);
- 稳定性验证:为确保MLLM评分的可靠性,对20000张随机抽取的图像进行20次独立评估,固定采样参数(temperature=0.5,top_k=0.5),计算各维度评分的标准差:
- 公共安全维度:标准差0.035;
- 交通安全维度:标准差0.065;
- 景观美感维度:标准差0.199;
结果表明,MLLM在客观维度的评分稳定性极高,主观维度的稳定性相对较低,但仍处于可接受范围,验证了数据的可靠性。
3.2.2 级联感知解析框架(CPPF)
该阶段的核心目标是解析MLLM的文本解释,揭示其感知逻辑,同时解决MLLM的“幻觉”问题(即文本解释中提及的环境要素在图像中不存在)。CPPF框架分为“LLM文本解析”“幻觉过滤与数据融合”两大阶段,流程如图2所示。
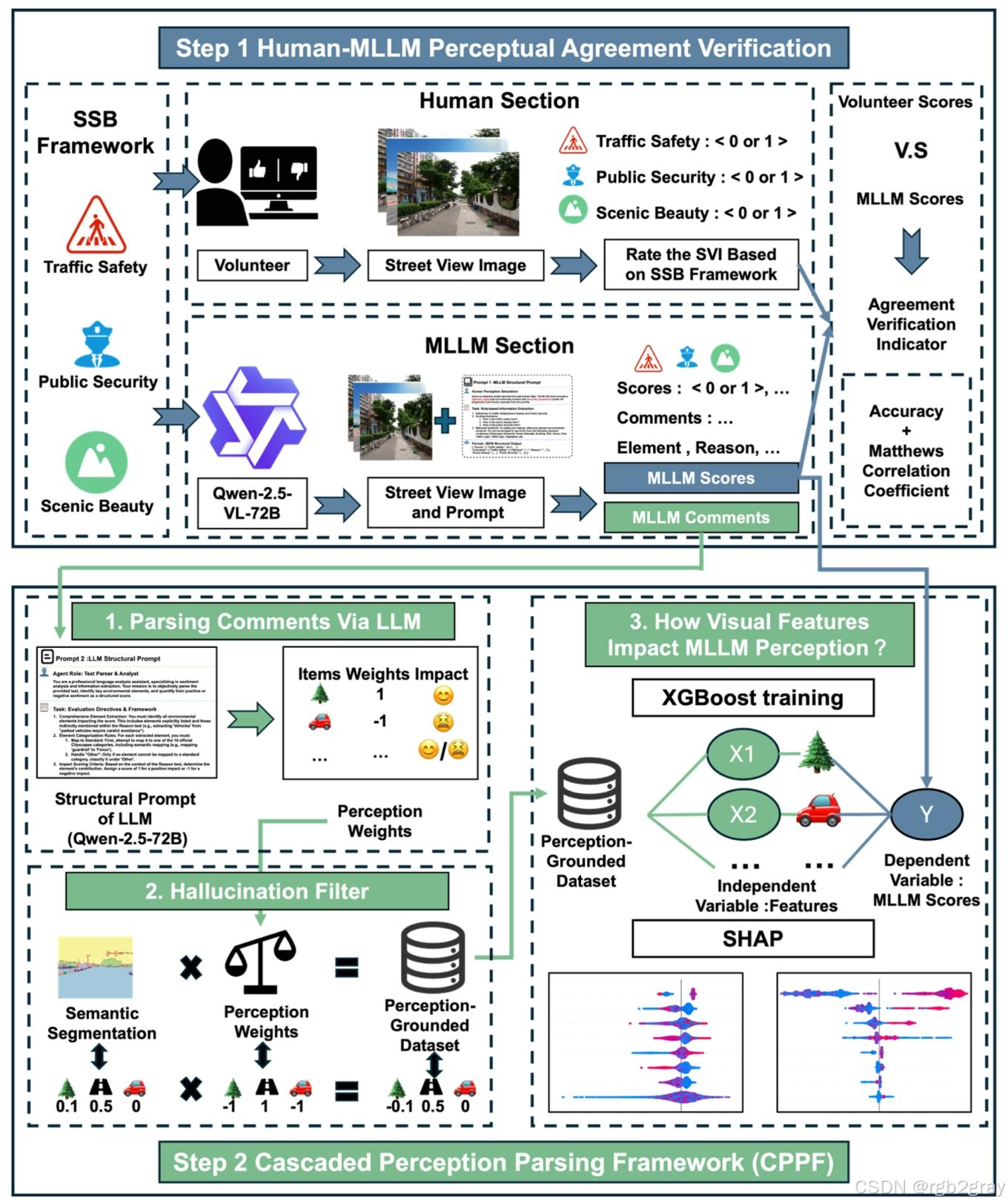
图2 研究方法框架:Step1为“人机感知一致性验证”,通过对比人类与MLLM的SSB评分,评估MLLM的模拟效果;Step2为“级联感知解析框架(CPPF)”,通过二级LLM解析MLLM的文本解释,结合语义分割进行幻觉过滤,生成“感知-现实对齐数据集”,为后续可解释性分析提供基础
阶段1:LLM文本解析与感知要素提取
- 解析模型选择:选用Qwen-2.5-72B作为二级LLM,该模型与核心MLLM同属Qwen家族,中文处理能力优异,且在文本理解、信息提取任务中表现突出(Bai et al., 2025);
- 结构化提示词设计:为确保解析的准确性与标准化,设计结构化提示词(图4),明确二级LLM的角色(文本解析师与分析师)、任务目标与操作规则:
- 全面要素提取:要求提取文本解释中明确提及或间接隐含的所有环境要素(如从“需避让停放车辆”中提取“停放车辆”),确保无遗漏;
- 要素标准化分类:将提取的要素映射到Cityscapes的18个官方类别(如“护栏”映射到“Fence”),无法映射的要素归类为“Other”,确保要素分类的统一性;
- 影响量化:根据文本语境判断要素对感知的影响方向,赋予+1(正向影响)或-1(负向影响)的评分(如“清晰的交通标志”对应+1,“密集的行人”对应-1);
- 输出结果:生成结构化数据集,包含每个图像在SSB三个维度下的“环境要素-影响评分”键值对,如“交通安全:{Road:1, Pedestrian:-1, Traffic Sign:1}”。

图4 二级LLM解析提示词结构:明确代理角色(文本解析师与分析师)、任务指令(要素提取、分类、影响量化)、操作规则(全面性、标准化、语境判断)与输出格式(JSON结构化输出),确保解析结果的准确性与一致性
阶段2:幻觉过滤与感知-现实数据融合
该阶段的核心是通过语义分割验证环境要素的物理真实性,过滤MLLM的幻觉,实现主观感知与客观现实的对齐:
- 语义分割模型选择:采用Segformer-B0模型,该模型预训练于Cityscapes数据集,在城市街景语义分割任务中兼具高准确率与高处理效率,能精准提取18类城市环境要素的像素占比(Xie et al., 2021; Zhao et al., 2024);
- 客观特征提取:利用Segformer-B0模型对每张街景图像进行语义分割,计算Road、Building、Vegetation、Pedestrian等18类要素的像素占比,作为客观物理特征数据;
- 幻觉过滤机制:将阶段1提取的“环境要素-影响评分”与语义分割得到的“要素像素占比”进行逐元素相乘:
- 若某环境要素在图像中的像素占比>0(即真实存在),则保留其影响评分,并用像素占比加权(如“Vegetation”的影响评分为+1,像素占比为0.3,则加权后得分为0.3);
- 若某环境要素的像素占比=0(即MLLM的幻觉),则其影响评分被置零,从数据集中剔除;
- 数据融合:将加权后的主观感知权重与客观物理特征合并,生成“感知-现实对齐数据集(Perception-Grounded Dataset)”,该数据集的所有特征均基于物理现实,无幻觉干扰,为后续的可解释性分析提供可靠数据基础。
3.3 数据分析与模型验证
3.3.1 人机感知一致性评估指标
考虑到人类评分数据集存在显著的类别不平衡问题(负面评分占比68%,正面评分占比32%),仅使用准确率(Accuracy)会导致评估结果失真(模型倾向于预测多数类即可获得高准确率),因此采用“准确率+马修斯相关系数(MCC)”的组合指标:
- 准确率(Accuracy):直观反映MLLM与人类评分的整体一致率,公式如下:
Accuracy=TP+TNTP+TN+FP+FN×100% Accuracy =\frac{TP+TN}{TP+TN+FP+FN} × 100 \% Accuracy=TP+TN+FP+FNTP+TN×100%
其中,TP(True Positive)为真阳性(人类评1,MLLM评1),TN(True Negative)为真阴性(人类评0,MLLM评0),FP(False Positive)为假阳性(人类评0,MLLM评1),FN(False Negative)为假阴性(人类评1,MLLM评0); - 马修斯相关系数(MCC):综合混淆矩阵的四个元素,能有效处理类别不平衡数据,取值范围为[-1,1],+1表示完美预测,0表示随机猜测,-1表示完全相反预测,公式如下:
MCC=TP×TN−FP×FN(TP+FP)(TP+FN)(TN+FP)(TN+FN)×100% MCC=\frac{TP × TN-FP × FN}{\sqrt{(TP+FP)(TP+FN)(TN+FP)(TN+FN)}} × 100 \% MCC=(TP+FP)(TP+FN)(TN+FP)(TN+FN)TP×TN−FP×FN×100%
该指标能更真实地反映MLLM的分类性能,避免因数据不平衡导致的误判。
3.3.2 基于XGBoost代理模型的可解释性分析
为揭示MLLM的感知逻辑,构建XGBoost代理模型模拟MLLM的决策行为,并通过SHAP框架进行可解释性分析:
(1)代理模型构建
- 自变量(X):感知-现实对齐数据集中的18类环境要素像素占比(客观特征)与加权后的感知权重(主观特征);
- 因变量(Y):MLLM生成的SSB三个维度的二分类评分;
- 模型训练:采用XGBoost分类器,目标函数设为binary:logistic,通过网格搜索优化超参数(学习率、树深度、叶子节点数等),交叉验证折数设为5,确保模型的泛化能力;
- 模型优势:XGBoost作为高效的梯度提升算法,能有效拟合复杂的非线性关系,适合模拟MLLM的输入-输出决策行为,且训练速度快、对高维数据适应性强(Chen and Guestrin, 2016)。
(2)SHAP解释框架
SHAP(SHapley Additive exPlanations)基于合作博弈论中的沙普利值,能公平地将模型的预测结果归因于每个输入特征,是目前最有效的可解释AI(XAI)工具之一(Lundberg and Lee, 2017):
- 沙普利值计算公式:
ϕi=∑S⊆N∖{i}∣S∣!(M−∣S∣−1)!M![f(S∪{i})−f(S)] \phi_i = \sum_{S \subseteq N \setminus \{i\}} \frac{|S|! (M - |S| - 1)!}{M!} [f(S \cup \{i\}) - f(S)] ϕi=S⊆N∖{i}∑M!∣S∣!(M−∣S∣−1)![f(S∪{i})−f(S)]
其中,ϕi\phi_iϕi为特征i对预测结果的贡献值,N为所有输入特征集合,M为特征总数,S为不含特征i的任意子集,f(S)为特征子集S的预测结果; - 分析维度:
- 全局分析:通过汇总所有样本的SHAP值绝对值,排序得到各特征对MLLM决策的影响权重,识别核心影响因素;
- 局部分析:通过SHAP依赖图(Dependence Plots),分析单个特征的SHAP值随其自身取值的变化规律,揭示特征与MLLM感知的非线性关系;
- 交互分析:通过SHAP交互图,分析两个特征的联合作用对MLLM感知的影响,揭示特征间的复杂关联。
四、研究结果(Results)
4.1 MLLM作为人类感知代理的性能表现
(1)整体一致性结果
MLLM在不同感知维度的表现差异显著,呈现“客观维度优异,主观维度不足”的特征(图5、表1):
- 交通安全维度:平均准确率89.3%,表现稳定,多数人类评估者的人机一致率在85%以上;
- 公共安全维度:平均准确率96.1%,是表现最佳的维度,人机一致率最高达98.7%,表明MLLM能精准识别影响公共安全的核心环境特征;
- 景观美感维度:平均准确率仅63.3%,且波动性大(一致率范围52.1%-75.3%),表明MLLM在主观美学感知上与人类存在显著差距。
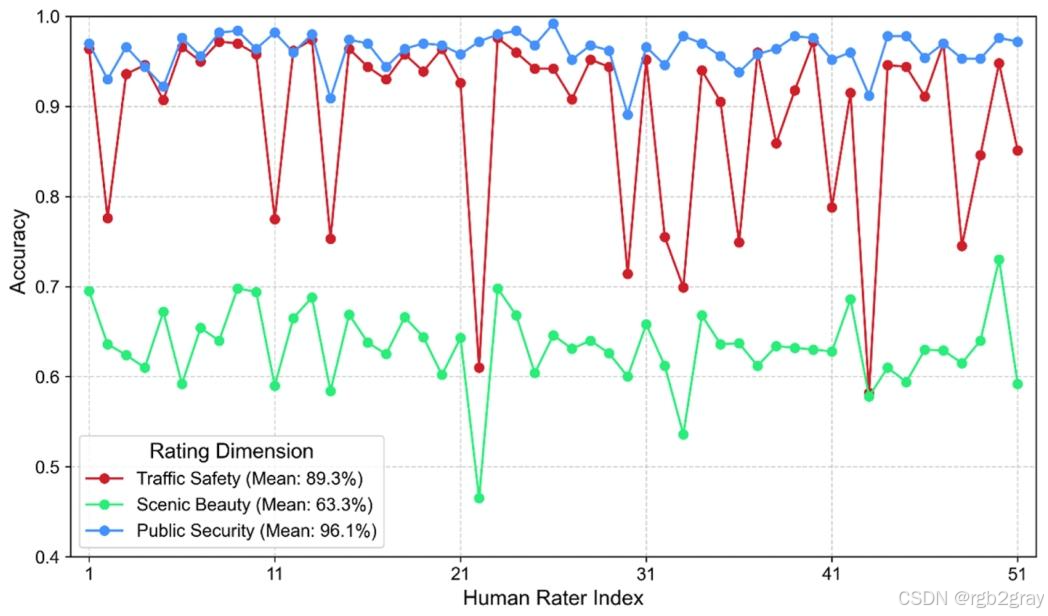
图5 不同感知维度的人机一致性对比:横轴为人类评估者编号(1-51),纵轴为一致率(0-1),可见公共安全维度的一致率最高且波动最小,景观美感维度的一致率最低且波动最大
| 感知维度 | 准确率(平均一致率) | 平均MCC |
|---|---|---|
| 交通安全 | 89.3% | 0.3% |
| 公共安全 | 96.1% | 1.5% |
| 景观美感 | 63.3% | -0.4% |
表1 人机感知一致性指标汇总:MCC值普遍极低,远低于准确率,揭示高准确率源于数据不平衡,而非模型真正理解了人类感知
(2)核心发现:高准确率与低MCC的悖论
尽管MLLM在客观维度的准确率接近90%,但MCC值仅为0.3%(交通安全)和1.5%(公共安全),景观美感维度的MCC值甚至为-0.4%,形成“高准确率-低真实相关性”的核心悖论。
这一悖论的根源在于人类评分数据集的类别不平衡:负面评分占比68%,MLLM为最大化准确率,采用“保守预测策略”——倾向于预测所有样本为负面评分,导致高准确率但低分类性能。具体表现为:
- MLLM能精准识别多数类(负面评分)的核心特征(如混合交通、无隔离带、光线昏暗);
- 但无法有效学习少数类(正面评分)的复杂特征(如适度的行人活动、植被与建筑的平衡),导致对正面样本的预测准确率极低(仅32.7%)。
这一发现表明,单纯的准确率无法反映MLLM的真实性能,必须结合MCC等抗不平衡指标,且需深入分析模型的决策逻辑,而非仅关注数值输出。
4.2 MLLM感知决策机制的可解释性分析
通过SHAP分析XGBoost代理模型,揭示了MLLM在三个感知维度的决策逻辑差异,从“客观风险审计”到“情境感知”再到“简化美学偏误”,反映了MLLM在不同复杂度感知任务中的能力变化。
4.2.1 交通安全维度:物理秩序与风险的客观审计者
MLLM在交通安全维度的决策逻辑清晰,聚焦于可量化的物理风险特征,表现为“客观、精准、风险规避”:
- 核心影响特征(按SHAP值绝对值排序):Road(道路占比)、Pedestrian(行人密度)、Traffic Sign(交通标志密度)(图6);
- 决策逻辑细节:
- 行人密度:SHAP值呈显著负相关,行人密度越高,SHAP值越低(负面影响越大),表明MLLM将混合交通视为交通安全的首要风险,这与人类对“人车混行”的风险认知一致;
- 交通标志密度:SHAP值呈显著正相关,交通标志越清晰、密度越高,SHAP值越高(正面影响越大),表明MLLM将交通标志视为“秩序与安全”的信号;
- 道路占比:呈非线性影响,道路占比在0.3-0.5之间时,SHAP值最高(正面影响最大),过高(>0.7)或过低(<0.2)均会导致SHAP值下降,表明MLLM偏好结构合理、规模适中的骑行路径,过宽的道路可能意味着更多机动车流量,过窄的道路可能导致骑行空间不足。
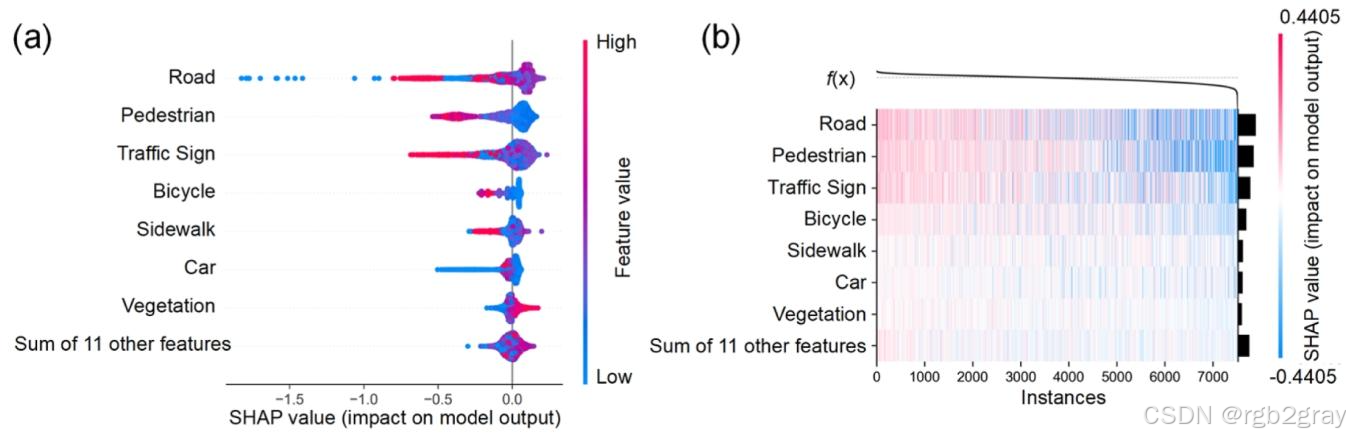
图6 交通安全维度特征重要性SHAP分析:(a) 蜂群图展示各特征的SHAP值分布,颜色表示特征自身取值(红色为高值,蓝色为低值);(b) 热力图展示全局特征重要性,颜色越深表示影响越大,可见Road、Pedestrian、Traffic Sign是核心影响因素
视觉示例验证(图7):MLLM评为“好”(评分=1)的场景,均具备“机非隔离带清晰、交通标志完整、无密集行人”的特征;评为“差”(评分=0)的场景,均存在“人车混行、无交通标志、道路狭窄”的问题,与SHAP分析揭示的决策逻辑高度一致。

图7 交通安全维度街景示例:左图(评分=1)为有机非隔离带、交通标志清晰的安全场景;右图(评分=0)为人车混行、无隔离设施的高风险场景
4.2.2 公共安全维度:情境感知的判断者
与交通安全维度不同,MLLM在公共安全维度的决策逻辑从“单纯物理风险”转向“情境氛围评估”,表现出初步的情境感知能力:
- 核心影响特征(按SHAP值绝对值排序):Pedestrian(行人密度)、Sky(天空开阔度)、Vegetation(植被密度)(图8);
- 决策逻辑转变:
- 行人密度的角色反转:与交通安全维度相反,公共安全维度中,行人密度过低(<0.05)会导致SHAP值显著下降(负面影响),适度的行人活动(0.05-0.15)会提升SHAP值(正面影响),表明MLLM将“适度人流”视为“自然监视”的信号,符合环境心理学中的“防御空间理论”;
- 天空开阔度:呈显著正相关,天空占比越高(>0.3),SHAP值越高,表明MLLM认为开阔的视野能减少隐蔽空间,提升公共安全;
- 植被密度:呈显著负相关,植被占比过高(>0.4)会导致SHAP值下降,表明MLLM将密集植被视为“潜在隐蔽点”,可能增加安全风险。
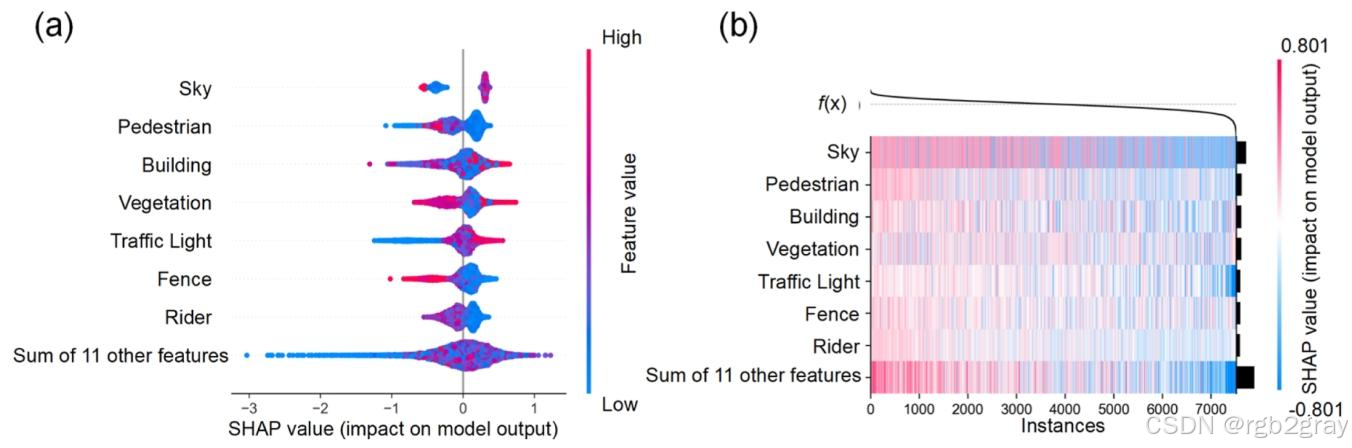
图8 公共安全维度特征重要性SHAP分析:(a) 蜂群图展示各特征的SHAP值分布;(b) 热力图展示全局特征重要性,核心影响因素与交通安全维度完全不同,体现了决策逻辑的转变
视觉示例验证(图9):MLLM评为“好”(评分=1)的场景,均为“视野开阔、有适度行人、植被分布合理”的开放空间;评为“差”(评分=0)的场景,均为“偏僻、视野受阻、无行人活动”的封闭环境,与SHAP分析揭示的情境感知逻辑一致。

图9 公共安全维度街景示例:左图(评分=1)为视野开阔、有行人活动的安全场景;右图(评分=0)为偏僻、植被密集、视野受阻的高风险场景
4.2.3 景观美感维度:简化的亲自然偏误
MLLM在景观美感维度的决策逻辑显著退化,表现为“简化、单一、亲自然”的偏误,无法模拟人类复杂的美学感知:
- 核心影响特征(按SHAP值绝对值排序):Vegetation(植被密度)、Building(建筑密度)、Sky(天空开阔度)(图10);
- 决策逻辑局限:
- 植被密度:绝对主导的正向特征,植被占比越高(>0.3),SHAP值越高,几乎决定了景观美感的评分,表明MLLM将“绿色覆盖”等同于“美观”;
- 建筑密度:绝对主导的负向特征,建筑占比越高(>0.2),SHAP值越低,表明MLLM对人工建筑存在“天然排斥”,将其视为“破坏美感”的因素;
- 其他特征的忽视:空间构图、色彩协调、建筑风格等影响人类美学感知的关键因素,在MLLM的决策中几乎无影响,表明其美学逻辑缺乏复杂性与深度。
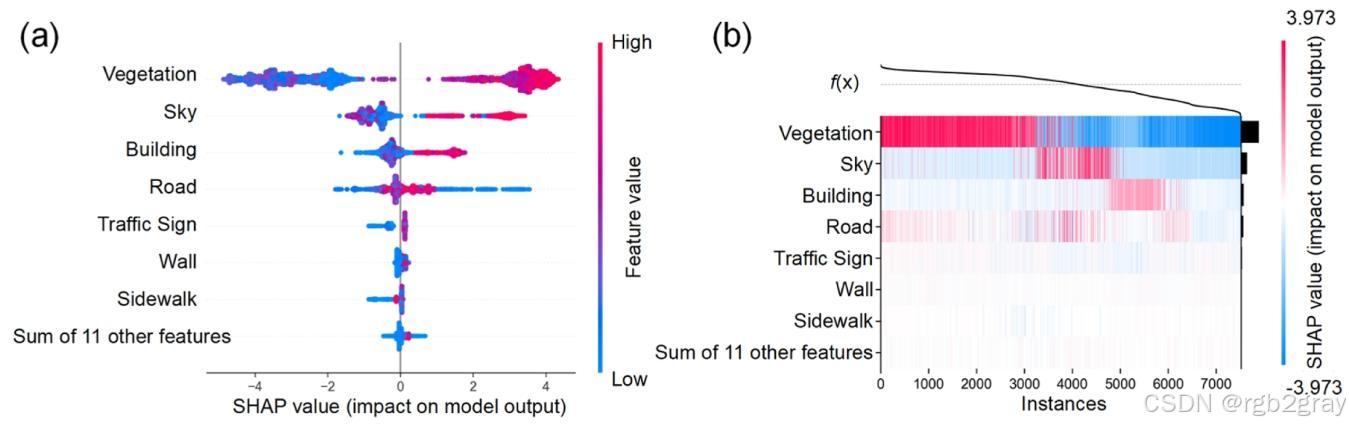
图10 景观美感维度特征重要性SHAP分析:(a) 蜂群图展示各特征的SHAP值分布,Vegetation的SHAP值普遍为正且数值较大,Building的SHAP值普遍为负;(b) 热力图展示全局特征重要性,Vegetation和Building的影响远高于其他特征
视觉示例验证(图11):MLLM评为“好”(评分=1)的场景,均为“植被密集、建筑稀少”的公园式环境;评为“差”(评分=0)的场景,均为“建筑密集、植被稀少”的城市街道,即便这些街道具备“建筑风格统一、商业活力强”等人类认可的美学特征,也被MLLM评为“差”,充分体现了其简化的亲自然偏误。

图11 景观美感维度街景示例:左图(评分=1)为植被密集、无明显建筑的公园场景;右图(评分=0)为建筑密集、植被稀少的城市商业街道
4.3 人机美学差异的根源探究
为深入理解MLLM与人类在景观美感维度的差异,通过“差异模式分析→差异场景特征提取→关键影响因素识别”的三步分析法,揭示了差异的核心根源。
(1)差异模式:MLLM的“过度美化”倾向
将景观美感维度的样本分为“一致集”(人机评分相同)和“差异集”(人机评分不同),混淆矩阵分析(图12(a))显示:
- 差异集共2519个样本,其中95%(2397个)为“假阳性”(人类评0,MLLM评1),仅5%(122个)为“假阴性”(人类评1,MLLM评0);
- 核心结论:人机美学差异的核心不是随机误差,而是MLLM系统性地“过度美化”了人类认为无吸引力的场景,尤其是“高植被、低建筑、低复杂度”的单调场景。
(2)差异场景特征:低视觉复杂度与高秩序性
引入香农熵(Shannon Entropy)量化街景图像的视觉复杂度(香农熵越高,视觉元素越丰富、复杂度越高),分析发现:
- 差异集的平均香农熵(0.87)显著低于一致集(1.32)(t检验,p<0.01);
- 概率密度图(图12(b))显示,差异集的香农熵集中在0.5-1.2之间,一致集的香农熵集中在1.0-1.8之间;
- 结论:MLLM倾向于将“视觉秩序性强、元素单一、复杂度低”的场景评为“美观”,而人类认为这类场景“单调、缺乏活力”,难以产生美学共鸣。
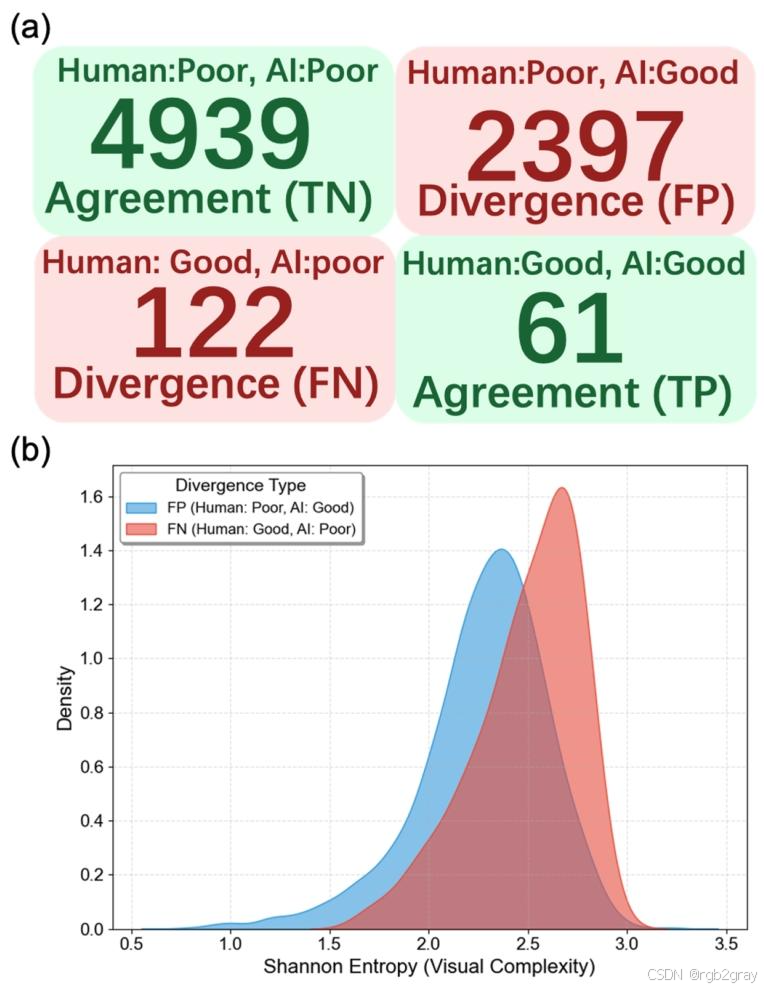
图12 人机美学差异模式与复杂度分析:(a) 混淆矩阵展示差异主要源于MLLM的假阳性判断;(b) 概率密度图展示差异集的视觉复杂度(香农熵)显著低于一致集
(3)关键影响因素:植被与建筑的平衡
对差异集单独进行XGBoost建模与SHAP分析,揭示了导致人机差异的核心因素(图13):
- 核心影响特征(按SHAP值绝对值排序):Building(建筑密度)、Shannon Entropy(视觉复杂度)、Vegetation(植被密度);
- 特征交互关系:
- 植被与建筑的平衡:SHAP依赖图(图13(b))显示,当植被占比高(>0.4)且建筑占比低(<0.1)时,SHAP值为负(导致人机差异),表明人类不认可“纯自然、无人工痕迹”的单调场景;
- 平衡区间:当植被占比在0.3-0.4之间,且建筑占比在0.1-0.2之间时,SHAP值为正(减少人机差异),表明人类偏好“自然与人工和谐共存”的场景;
- 视觉复杂度的作用:视觉复杂度(香农熵)与SHAP值呈正相关,复杂度越高(>1.2),SHAP值越高,表明人类重视场景的丰富性与活力,而MLLM忽视这一维度。
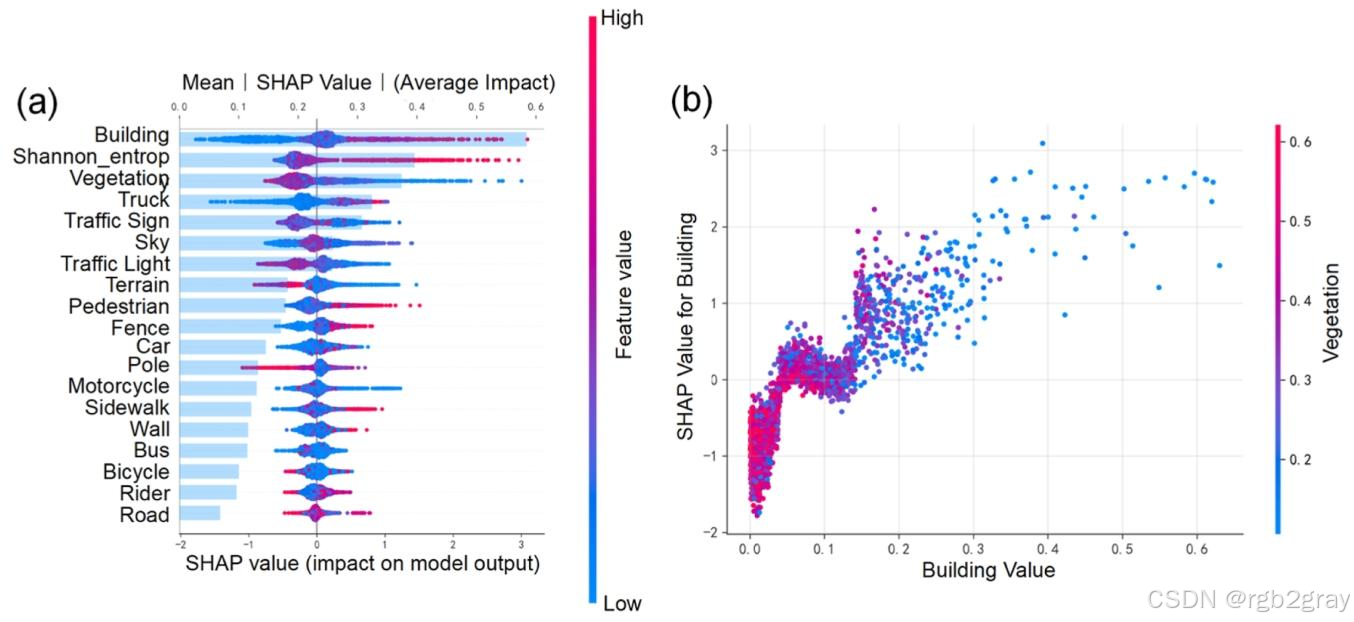
图13 差异集特征归因分析:(a) 关键影响特征SHAP汇总图,Building、Shannon Entropy、Vegetation是核心因素;(b) 建筑与植被的交互依赖图,显示两者的平衡对减少人机差异至关重要
视觉示例验证(图14):左图(人类=0,MLLM=1)为“高植被、低建筑、低复杂度”的单调公园场景,人类认为缺乏活力;右图(人类=1,MLLM=0)为“植被与建筑平衡、视觉复杂度适中”的城市街道,人类认为具备商业活力与美学价值,但MLLM因建筑占比高而评为“差”。

图14 人机美学差异示例:左图为MLLM过度美化的低复杂度场景;右图为MLLM误判的平衡型城市街道场景
五、讨论(Discussion)
5.1 核心悖论的深层解读:MLLM在不平衡数据下的策略偏误
本文揭示的“高准确率-低MCC”悖论,并非MLLM独有的问题,而是当前AI模型在真实世界不平衡数据中的普遍现象。其深层原因在于:
- MLLM的训练目标是“最小化预测误差”,在不平衡数据中,预测多数类能以最低成本实现高准确率,导致模型形成“策略偏误”;
- 这种偏误反映了MLLM的“工具理性”——优先优化表面指标,而非真正理解人类感知的本质;
- 解决这一问题的关键,并非单纯调整模型参数,而是通过“感知-现实对齐”(如本文的CPPF框架)引导模型关注少数类的核心特征,或采用数据增强、加权损失函数等方法平衡样本分布。
这一发现为后续MLLM在城市感知领域的应用提供了重要启示:评估模型性能时,必须结合抗不平衡指标(如MCC、F1-score),且需深入分析模型的决策逻辑,而非仅关注表面准确率。
5.2 MLLM的核心应用价值:低推理任务的高效审计工具
本文的研究结果明确了MLLM在骑行环境感知中的核心应用场景——低推理复杂度的客观维度评估(交通安全、公共安全):
- 低推理任务的定义:判断标准与物理实体直接映射,无需文化、情境、经验等复杂背景知识,仅需识别明确的风险或安全特征(如隔离带、交通标志、行人密度);
- MLLM的优势:
- 规模化:可快速处理城市级的海量街景数据,替代传统人工实地审计,大幅提升评估效率(如本文7519个采样点的评估,MLLM仅需24小时,而人工评估需51人×10天);
- 一致性:避免人工评估的主观偏差,输出结果稳定可靠(如本文MLLM在公共安全维度的评分标准差仅0.035);
- 低成本:无需部署传感器或组织实地调查,仅需街景数据与模型部署成本,降低城市规划的调研成本。
这一价值与Ki等(2025)的研究结论一致,Ki等发现ChatGPT能有效评估影响步行便利性的微观环境特征,而本文将这一结论扩展到骑行环境领域,证明MLLM在客观环境审计中的普适性。
5.3 人机美学差异的本质:统计美学vs语境化美学
MLLM与人类在景观美感维度的显著差异,本质上反映了两种截然不同的美学范式:
- AI的统计美学:基于训练数据的模式识别,将美学简化为“可量化特征的统计组合”(如高植被、低建筑、低复杂度),追求秩序性与典型性,缺乏对语境、文化、情感的理解;
- 人类的语境化美学:基于文化背景、生活经验、情感共鸣的复杂认知过程,追求“典型性与新颖性的平衡”“自然与人工的和谐”“空间与情感的关联”(Nasar, 1990),重视场景的活力、内涵与场所感(Sense of Place)。
这一差异的根源在于:
- MLLM缺乏“具身经验”:无法像人类一样通过亲身骑行体验理解空间的舒适度与情感价值,只能通过图像像素与文本描述间接学习;
- MLLM缺乏“文化语境”:无法理解城市空间的文化内涵(如历史建筑的价值、商业街道的活力),只能识别表面的视觉特征;
- MLLM的美学还原主义:将复杂的美学感知还原为单一维度的特征(如植被占比),忽视了空间构图、色彩协调、风格统一等高层次美学要素(Ewing and Handy, 2009)。
这一发现与Malekzadeh等(2025)、Tung等(2025)的研究结论高度一致,表明AI的美学偏误是系统性问题,而非单一模型的局限。
5.4 理论与实践启示
(1)实践启示:人机协同的城市骑行环境规划方案
基于本文的研究结果,提出“AI审计+人类决策”的人机协同规划框架,既发挥MLLM的规模化优势,又避免其美学偏误:
- 第一步:MLLM自动化审计(客观维度):利用MLLM快速扫描城市街景,识别交通安全与公共安全的风险点(如无隔离带、视线遮挡、光线昏暗),生成“风险清单”,为规划者提供精准的整改方向;
- 第二步:人类专业决策(主观维度):针对MLLM识别的风险点与潜在优化区域,由规划师、骑行者代表、景观设计师共同评估,重点关注景观美感、空间活力、文化内涵等主观维度,制定兼顾安全与体验的优化方案;
- 第三步:方案验证与迭代:将优化方案转化为虚拟街景图像,由MLLM与人类共同评估,验证安全维度的改善效果与美学维度的合理性,形成闭环迭代。
这一框架符合“以人为本的AI”原则(Shneiderman, 2020),将AI定位为“辅助工具”而非“替代者”,确保城市规划既高效又贴合人类需求。
(2)理论启示:AI城市感知的新研究方向
本文的研究为AI城市感知领域提供了两大理论启示:
- 明确了AI与人类的认知边界:AI擅长低推理、客观维度的感知模拟,人类擅长高推理、主观维度的感知判断,未来研究应聚焦“人机互补”而非“人机替代”;
- 提出了可解释性研究的新范式:CPPF框架为打开MLLM的“黑箱”提供了可行路径,未来可将其扩展到城市活力、社区归属感、公共空间满意度等其他依赖主观感知的城市问题研究中;
- 揭示了AI美学的优化方向:要提升AI的主观感知能力,需突破“统计特征映射”的局限,引入文化语境、具身经验、情感计算等维度,构建更贴近人类认知的美学模型。
5.5 研究局限与未来方向
(1)研究局限
- 研究区域与样本的局限性:研究区域仅覆盖深圳核心城区,城市形态、文化背景相对单一,结果的泛化性需在其他城市(如北方城市、中小城市)验证;评估者均为大学生,年龄、职业单一,未能覆盖通勤者、老年人、儿童等多样化人群的感知需求;
- 数据模态的局限性:仅使用静态街景图像,缺乏动态信息(如车辆流动、行人行为)与非视觉信息(如噪音、振动、气味),而这些信息对骑行环境感知至关重要;
- 模型选择的局限性:二级解析模型与核心MLLM同属Qwen家族,可能存在相关误差,未系统对比不同LLM(如GPT-4、Gemini)的解析效果;
- 算法与方法的局限性:未深入探索解决MLLM策略偏误的方法,如数据增强、加权损失函数等;缺乏人类标注的“黄金标准”文本解释,无法验证MLLM文本解释的语义一致性。
(2)未来研究方向
- 扩展研究范围与样本:纳入不同城市形态、文化背景的研究区域,招募多样化人群(不同年龄、职业、骑行习惯)作为评估者,验证结果的泛化性;
- 丰富数据模态:整合动态街景视频、音频(噪音)、传感器数据(振动、温度),构建多模态骑行环境感知模型,更贴近真实骑行体验;
- 优化模型与方法:系统对比不同MLLM(如GPT-4V、Gemini 2.5、LLaVA)的感知效果,不同LLM的解析性能;探索数据平衡技术与损失函数优化,缓解MLLM的策略偏误;
- 深化可解释性与语义一致性:构建人类标注的“环境要素-感知逻辑”黄金标准数据集,验证MLLM文本解释的语义一致性;引入情感计算、文化地理学理论,提升AI的主观感知能力。
六、结论
本文通过构建“人机感知一致性验证+级联感知解析框架(CPPF)”,系统探究了多模态大模型在城市骑行环境感知模拟中的潜力与局限,得出以下核心结论:
- MLLM在客观安全维度(交通安全、公共安全)表现优异,与人类判断高度一致,具备作为城市环境高效审计工具的潜力,能大幅提升骑行环境评估的规模化与效率;
- MLLM在主观美学维度(景观美感)存在显著局限,其简化的“亲自然、低复杂度”美学逻辑与人类的“语境化、平衡型”美学感知存在本质差异,无法替代人类的主观判断;
- 级联感知解析框架(CPPF)有效打开了MLLM的“决策黑箱”,通过LLM文本解析、语义分割幻觉过滤、XGBoost代理模型与SHAP分析的组合,实现了对MLLM感知逻辑的量化与可视化;
- 人机协同是未来城市骑行环境规划的最优路径:MLLM作为客观维度的自动化审计工具,人类作为主观维度的最终决策者,两者互补能实现“高效、精准、以人为本”的城市规划目标。
本研究不仅为AI在城市感知领域的应用提供了实证依据与方法论支撑,也为未来可持续交通系统的构建与以人为本的城市规划提供了重要参考。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)