3种大模型微调技术对比:全参、LoRA、RAG,你的项目该怎么选?
本文深入浅出地解析了大语言模型适应专业场景的三种核心技术:**全参数微调 (Full Fine-Tuning)**、**LoRA微调 (Low-Rank Adaptation)** 和 **检索增强生成 (RAG)**。文章通过生动的比喻,将通用大模型比作“通才毕业生”,而三种技术则是为其“开小灶”的不同路径:
> 面对专业领域任务,通用大模型往往显得"泛而不精"。本文用最直白的语言,为你拆解为模型"开小灶"的三大核心技术,通过原理对比和一张清晰的决策树,帮你找到最适合自己项目的技术路径。
## 1. 引言:为什么通用大模型需要"开小灶"?
想象一下,你招了一位顶尖大学的通才毕业生(比如 ChatGPT),他博古通今,能说会道。但现在,你需要他立刻上岗成为你公司的资深法律顾问或芯片设计专家。直接让他看合同、画电路图,他大概率会表现得像个 "懂王"——说得多,但对得少。
这就是通用大模型的现状:**广度惊人,深度不足**。它们缺乏你业务场景中的私有数据、专业术语、内部流程和特定风格。
这时,你有三条路可以走,对应着我们今天要讲的三大技术:
1. **全参数微调**:送他回法学院/工程学院,花巨资让他重学一遍专业课程。(成本高,效果深)
2. **LoRA 微调**:给他报一个高效的"行业精英速成班",只学习核心差异。(成本低,效果好)
3. **RAG**:不培训他本人,而是给他配一个超级助理,随时帮他查阅最新的行业资料和公司文件。(成本最低,见效快)
选哪条路,直接决定了你的项目成本、周期和最终效果。
## 2. 技术原理对比:三大技术方案详解
### 2.1 全参数微调:脱胎换骨的"专家重塑"
* **核心比喻**:让通才回炉重造,成为一名彻头彻尾的领域专家。
* **技术原理**:用你的专业数据集,对预训练大模型的**每一个参数(权重)** 进行重新训练。
* **优点**:
* **效果上限最高**:模型能进行深度推理
* **部署简单**:训练完就是一个独立的模型,拿来就用
* **缺点**:
* **"土豪"游戏**:需要大量 GPU(如多张 A100),成本惊人
* **"灾难性遗忘"风险**:可能忘了原来的通用常识
* **不灵活**:每个新任务都要从头训练
### 2.2 LoRA 微调:四两拨千斤的"技能插件"
* **核心比喻**:给通才装备一个轻便的"专业技能扩展包"。
* **技术原理**:**冻结**大模型原有参数,只插入并训练微小的"适配器"矩阵。
* **优点**:
* **性价比之王**:单张消费级显卡(如 RTX 4090)就能玩转
* **模块化神器**:"技能包"只有几 MB,可以轻松切换、组合
* **保底能力强**:完美保留模型的通用能力
* **缺点**:
* 理论性能上限略低于全参数微调
* 需要一些调参经验
### 2.3 RAG:即插即用的"外挂知识库"
* **核心比喻**:不给专家做培训,而是给他配一个能秒查所有资料的神级秘书。
* **技术原理**:**完全不修改大模型**。提问时,先从外部知识库检索相关信息,再连同问题一起交给大模型生成答案。
* **优点**:
* **零训练成本**:无需任何 GPU 训练,立即部署
* **知识实时更新**:更新文档,答案立刻更新
* **答案可溯源**:能告诉用户答案出自哪里,可信度高
* **有效减少"幻觉"**:答案基于提供的事实
* **缺点**:
* **答案质量依赖检索**:检索错了,模型再强也白搭
* **推理链可能不深入**:模型更像是在"总结"你给的信息
* **消耗更多 Token**:每次问答都附带检索内容,成本更高
## 3. 实战指南:以 LoRA 为例的完整实现步骤
LoRA 是在资源、效果和灵活性之间取得最佳平衡点的技术。下面是完整的实现流程:
### 3.1 步骤一:准备训练数据
准备一个 JSON 或 JSONL 文件,推荐使用指令跟随式格式:
```json
{
"instruction": "翻译成英文",
"input": "今天天气真好",
"output": "The weather is really nice today."
}
```
收集几百到几千条**高质量**样本,涵盖各种业务场景。
### 3.2 步骤二:选择基础模型
根据需求选择合适的基座模型:
- **中文偏好**:Qwen(通义千问)、ChatGLM、InternLM
- **英文/代码强**:Llama、Mistral
- **尺寸选择**:7B(入门),13B/14B(效果更好),70B(资源充足选)
### 3.3 步骤三:使用微调框架
LLaMA-Factory 是目前最流行的微调框架之一,支持全参、LoRA、QLoRA 等多种方式。对于希望**免除环境配置、快速开始实验**的开发者,还可以关注其在线版本 **LLaMA-Factory Online**,它提供了开箱即用的微调环境。
本地安装使用:
```bash
# 克隆项目
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
# 安装依赖
pip install -r requirements.txt
```
### 3.4 步骤四:配置并启动训练
LoRA 训练的关键配置:
```bash
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path /path/to/your/base_model \
--dataset your_dataset_name \
--finetuning_type lora \ # 使用LoRA
--output_dir ./saves/your_lora_model \
--per_device_train_batch_size 4 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--fp16
```
**QLoRA 提示**:想用有限显存微调大模型?在命令中加入 `--quantization_bit 4` 即可启用 QLoRA,大幅降低显存占用。
### 3.5 步骤五:加载与使用模型
训练完成后加载和使用:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
import torch
# 加载基座模型
base_model = AutoModelForCausalLM.from_pretrained(
"path/to/base_model",
torch_dtype=torch.float16,
device_map="auto"
)
# 加载LoRA适配器
model = PeftModel.from_pretrained(base_model, "./saves/your_lora_model")
# 使用模型生成回答
inputs = tokenizer("你的专业问题:", return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## 4. 效果评估:科学验证微调成果
### 4.1 定量评估
- 观察训练损失曲线是否平稳下降
- 使用预留测试集计算指标:
- 分类任务:准确率、F1 分数
- 生成任务:困惑度(PPL)、BLEU/ROUGE 分数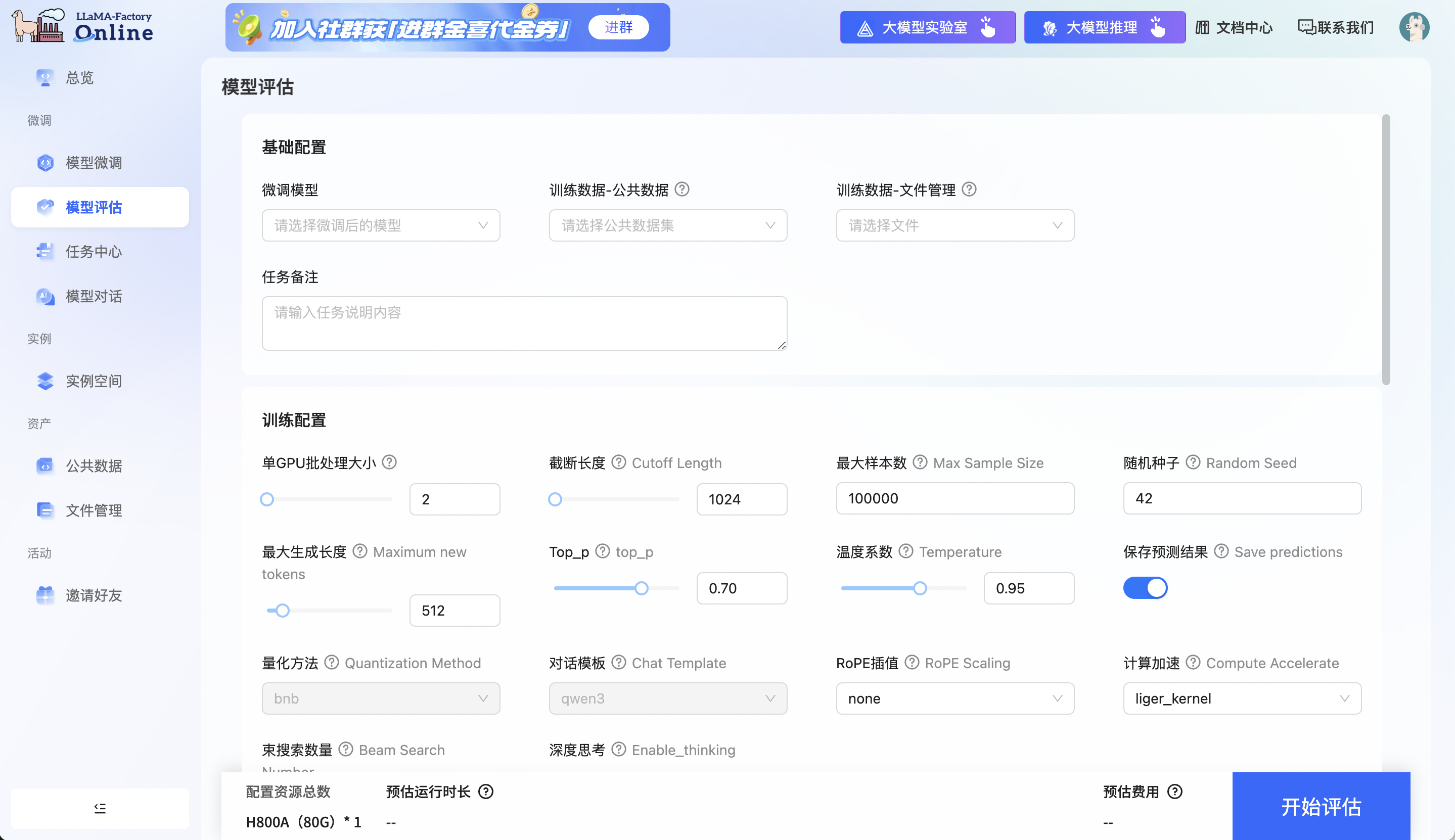
### 4.2 定性评估(更重要)
- 设计核心业务问题进行"考试"
- **A/B 对比测试**:让原模型、LoRA 模型、ChatGPT 同时回答
- **检查"遗忘"**:测试通用常识问题,确保模型能力未退化
### 4.3 端到端验收
将模型集成到原型系统中,让真实用户试用并收集反馈。
## 5. 技术选型决策树
你的项目该如何选择?参考以下决策流程:
```mermaid
graph TD
A[开始技术选型] --> B{知识需要实时更新<br>或答案需要严格溯源?}
B -->|是| C[**首选RAG**]
B -->|否| D{任务需要深度推理<br>且GPU预算充足?}
D -->|是| E[考虑**全参数微调**]
D -->|否| F{希望掌握特定技能/知识<br>且追求高性价比?}
F -->|是| G[**LoRA是最优解**]
```
## 6. 总结与展望
### 6.1 核心结论
- **RAG** 适用于知识需要实时更新或答案需溯源的场景
- **全参数微调** 适用于追求极致性能且资源充足的深度推理任务
- **LoRA** 是大多数场景下的**最佳平衡选择**,以 1% 的成本实现 90% 以上的效果
### 6.2 未来趋势
**RAG + LoRA 混合模式** 正成为业界主流解决方案:
1. **RAG 负责**:接入实时、准确的事实知识
2. **LoRA 负责**:训练领域特定的思维方式和泛化能力
这种组合既能保证知识的新鲜度和准确性,又能让模型具备专业的推理能力。
### 6.3 实践建议
在这个快速发展的领域,**启动和迭代的速度比追求一次性的完美更重要**。借助 **LLaMA-Factory Online** 这类自动化工具,可以极大地降低技术门槛,让你更专注于业务逻辑和数据的优化,从而快速验证想法并持续迭代。
---
**欢迎在评论区分享你的微调实践经验或遇到的问题!** 如果觉得这篇文章有帮助,记得点赞收藏哦~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)