【大模型系列篇】LoRA微调方法详解
本文详细拆解 LoRA(Low-Rank Adaptation,低秩适应) 这种当前最流行、最高效的大模型微调方法。它从根本上改变了我们微调大型语言模型的方式。
本文详细拆解 LoRA(Low-Rank Adaptation,低秩适应) 这种当前最流行、最高效的大模型微调方法。它从根本上改变了我们微调大型语言模型的方式。
背景
现在大模型非常火爆,大家都在想方设法应用大模型。 当前很多大模型虽说可以zero-shot直接使用, 但是在具体应用上一般还是微调一下效果更好, 也就是常说的finetune。 在小模型时代, finetune不是个问题。 但大模型时代, finetune是个大问题。 这是因为现在的大模型参数动辄10B起, 训练的代价非常高昂,即使是finetune也对计算资源有很高要求(finetune只是训练的步数少, 对显存等计算资源的占用并没有少)。 没个上百G的显存是玩不动的, 这对普通人的门槛实在太高了。
那么高效的finetune方式就非常必要了。LoRA就是高效finefune方法的一种。
一、核心思想:用“打补丁”代替“换衣服”
想象一下,你要为一台精密的仪器(大模型)增加一项新功能(适配新任务)。
-
传统全量微调:相当于把仪器拆开,更换和调整里面成千上万个核心零部件。成本极高,风险大(可能破坏原有功能),且每次新任务都需要一套独立的零部件(保存完整的模型副本)。
-
LoRA微调:相当于在仪器外壳上,通过一种“万能接口”插上几个小巧的、专门针对新任务的“适配模块”。仪器内部的核心零部件完全不动,通过极少的额外参数(适配模块)来引导仪器以新的方式工作。
LoRA的核心洞见是:大模型在适配新任务时,其权重变化矩阵(ΔW) 具有极低的“内在维度”。这意味着,ΔW 这个巨大的矩阵,可以用两个小得多的矩阵相乘来近似表示。
二、数学原理:低秩分解
对于预训练模型中的任何一个权重矩阵 W(例如,W ∈ ℝ^{d×k},在Transformer中通常是注意力层的 Q, K, V, O 或FFN层的 up, down 投影矩阵),其微调更新可表示为:W' = W + ΔW
LoRA 的核心操作是,将这个更新矩阵 ΔW 用一个低秩分解来近似:ΔW = B * A
其中:
-
B ∈ ℝ^{d×r} -
A ∈ ℝ^{r×k} -
r是一个远小于d和k的值,称为 秩(Rank),是LoRA最重要的超参数(通常为 4, 8, 16, 64)。
前向传播公式变为:h = Wx + ΔWx = Wx + BAx
参数量的巨大差异:
-
全量微调
W的参数数量:d × k(可能上亿) -
LoRA 微调
A和B的参数数量:d × r + r × k = r × (d + k)(通常只有数万到数十万)
举个例子:
对于一个 d=1024, k=1024 的权重矩阵,全量微调参数为 1,048,576。
如果使用 r=8 的LoRA,LoRA参数仅为 8 * (1024 + 1024) = 16,384,参数减少到原来的 1/64。
三、LoRA的优势与特点
-
极高的参数效率:仅需训练原模型 0.01% ~ 1% 的参数,大幅降低显存和存储消耗。
-
显著降低硬件门槛:原本需要多张A100才能微调的模型,现在一张消费级显卡(如RTX 4090/3090)就能胜任。
-
避免灾难性遗忘:由于基础模型权重
W被冻结,其原有的通用知识得到了很好的保护,只是通过BA这个“旁路”进行任务引导。 -
模块化与快速切换:不同的任务可以训练不同的
(A, B)矩阵对。推理时,只需像插拔乐高积木一样,加载不同的LoRA权重,即可让同一个基座模型执行不同任务,无需保存多个完整模型副本。 -
无推理延迟:在部署时,可以将
BA合并回W中,形成W' = W + BA。合并后的模型在结构上和原模型完全一致,不会引入任何额外的计算开销或延迟。
四、实践步骤与关键决策
下面是一个标准的LoRA微调流程和关键决策点图示,可以帮你直观地理解整个过程:
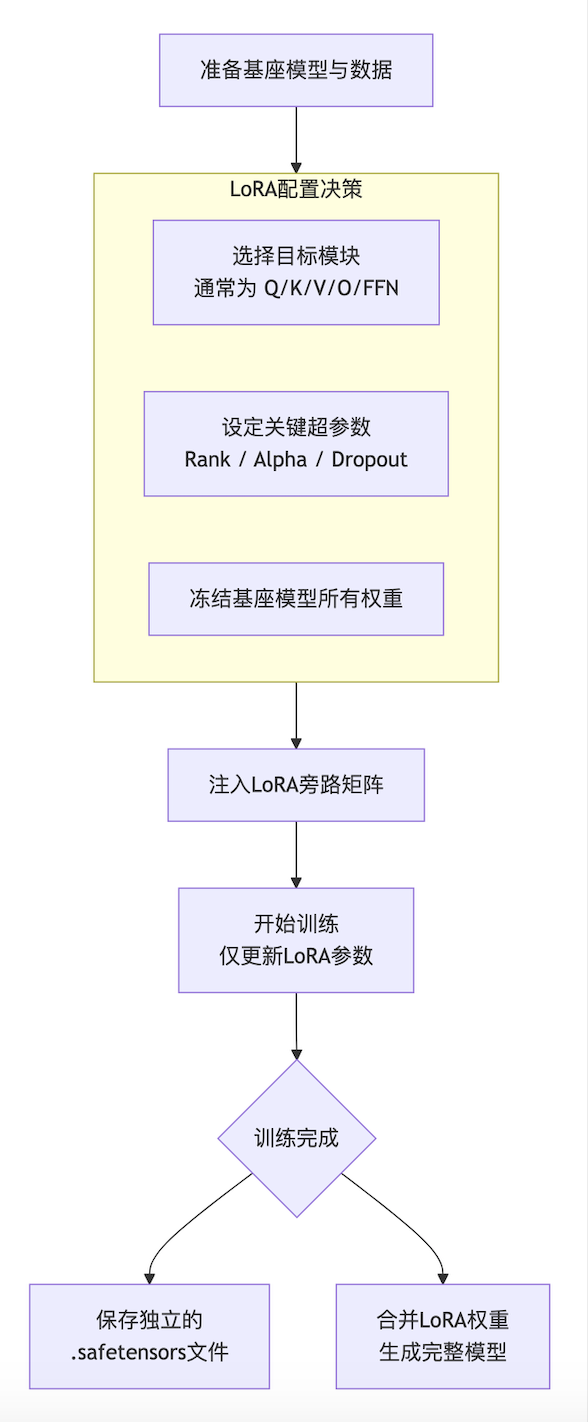
决策点详解:
-
选择目标模块:
-
常见选择:Transformer中的
query,key,value,output(注意力层)和up,down(FFN层)投影矩阵。 -
经验:通常对所有注意力层应用LoRA已能取得很好效果。增加FFN层可以提升能力,但参数会增多。指令微调常关注
q_proj,v_proj。
-
-
设置超参数:
-
秩
r:最重要的参数。r越小,参数越少,训练越快,但容量越低。通常从 8 或 16 开始尝试。对于复杂任务或数据量较大时,可尝试 32 或 64。 -
缩放因子
alpha:与r相关,控制ΔW被缩放的程度。通常设定alpha = r作为一个好的起点(此时缩放比例为1)。更大的alpha意味着更大的更新强度。 -
Dropout:LoRA层本身的Dropout率,用于防止过拟合,一般设置在 0~0.1。
-
-
训练与部署:
-
训练:使用PEFT(Parameter-Efficient Fine-Tuning)库(如 Hugging Face
peft)可以极其方便地注入LoRA层,并配置只训练这些参数。 -
保存:只需保存
adapter_model.bin(或.safetensors),文件非常小(几MB到几百MB)。 -
推理:
-
动态加载:将基座模型与LoRA权重分开加载,
peft库会自动处理前向传播。 -
合并导出:可以将LoRA权重合并到基座模型中,导出一个完整的、标准的模型文件(如
.gguf格式),便于在LM Studio、Ollama等工具中直接使用。
-
-
五、一个简化的代码示例(基于 Hugging Face transformers + peft)
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments
from peft import LoraConfig, get_peft_model, TaskType
import torch
# 1. 加载基座模型和分词器
model_name = "meta-llama/Llama-3.2-1B" # 示例模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
# 2. 配置LoRA
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM, # 因果语言模型任务
r=8, # LoRA的秩
lora_alpha=16, # 缩放因子alpha
lora_dropout=0.05, # LoRA层的dropout
target_modules=["q_proj", "v_proj"], # 目标模块:只作用在query和value投影层
bias="none", # 不训练偏置项
)
# 3. 将基座模型转换为PEFT模型(注入LoRA层)
peft_model = get_peft_model(model, lora_config)
peft_model.print_trainable_parameters() # 打印可训练参数量,会发现它非常小!
# 4. 准备训练数据(此处为示意,需根据实际情况构建)
# train_dataset = ...
# 5. 配置训练参数
training_args = TrainingArguments(
output_dir="./lora_finetuned_model",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
num_train_epochs=3,
learning_rate=2e-4,
fp16=True, # 或bf16,取决于硬件
logging_steps=10,
save_steps=100,
save_total_limit=2,
)
# 6. 使用Trainer进行训练
# trainer = Trainer(
# model=peft_model,
# args=training_args,
# train_dataset=train_dataset,
# data_collator=...,
# )
# trainer.train()
# 7. 保存LoRA权重(非常小)
peft_model.save_pretrained("./my_lora_adapter")
# 8. 加载与推理(动态加载方式)
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
loaded_peft_model = PeftModel.from_pretrained(base_model, "./my_lora_adapter")六、重要变体与进阶概念
-
QLoRA:在LoRA的基础上,将基座模型量化为4位精度(如NF4),同时采用双重量化等技巧。QLoRA让在单张24GB显存的消费级显卡上微调70B级别的模型成为可能,是LoRA发展史上的里程碑。
-
DoRA(Weight-Decomposed Low-Rank Adaptation):将预训练权重
W分解为幅度(magnitude)和方向(direction) 两部分。LoRA只微调方向部分,而DoRA同时微调方向和幅度,通常能取得比原始LoRA更好的效果,尤其接近全量微调的性能。 -
LoRA应用位置:除了标准的线性层,LoRA思想也被扩展应用到卷积层、交叉注意力层(如文生图模型Stable Diffusion的微调)等。
-
AdaLoRA:动态地为不同的权重矩阵分配不同的秩
r,而不是固定的。它会根据重要性评分,在训练过程中自适应地调整每个LoRA模块的秩,从而在相同参数预算下获得更优性能。
七、总结与最佳实践建议
何时使用LoRA?
-
当你资源有限(显存、存储)时。
-
当你需要快速实验不同任务适配时。
-
当你希望保留基座模型的通用能力,避免遗忘时。
-
当你需要轻松管理和切换多个微调模型时。
典型工作流:
-
选择基座模型:根据你的任务(代码生成、聊天、推理)选择一个强大的预训练模型(如 Llama、Qwen、Gemma)。
-
准备高质量数据:数据质量远比数量重要。对于指令微调,精心构造的指令-输出对是关键。
-
初步配置:从
r=8, alpha=16, target_modules=[“q_proj”, “v_proj”]开始。 -
开始实验:在一个较小的数据集上快速跑一个epoch,检查损失下降情况。
-
调优:如果效果不佳,可以尝试:增大
r(如16、32),将LoRA应用到更多层(如加上k_proj,o_proj,up_proj,down_proj),调整学习率。 -
评估与部署:在验证集上评估性能,然后保存LoRA权重或合并模型用于生产。
总而言之,LoRA 及其变体已成为大模型定制化的首选技术,它极大地 democratize(民主化)了大模型的微调,让个人开发者和研究者也能高效地利用前沿大模型的能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)