大模型学习—总结LLM模型结构上的变化
multi-head在注意力机制中multi-head是将Q、K、V三者使用view将张量拆分为多个head,分别进行self-attention最后再将结果合并,这种方法使的。
目录
多头注意力机制变化
multi-head
在注意力机制中multi-head是将Q、K、V三者使用view将张量拆分为多个head,分别进行self-attention最后再将结果合并,这种方法使的每个头完全独立捕捉不同的特征关联(如语法、语义、局部 / 长距离依赖等),表达能力最强。但其缺点也很明显,随着计算和内存开销大(K、V 数量随头数线性增加),尤其是当模型头数多(如 32 头、64 头)时,推理速度慢。
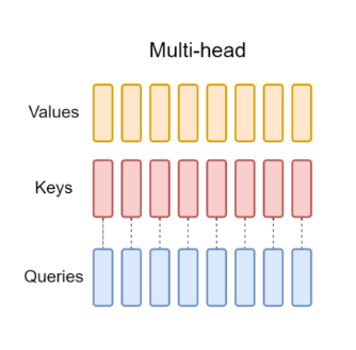
Grouped Query
Grouped Query是为了解决multi-head内存占用大,推理速度慢而演变而来的变体,例如将K、V分成4组每个组有1个head,Q分为4组每个组有2个head,每个组内的头共享同一套 K 和 V,但每个头仍有独立的 Q,这样就比 Multi-Head 减少了 K、V 的数量,降低计算 / 内存开销;同时保留了较多独立的 Q,比 Multi-Query 保留了更强的表达能力,是现在比较主流的方式
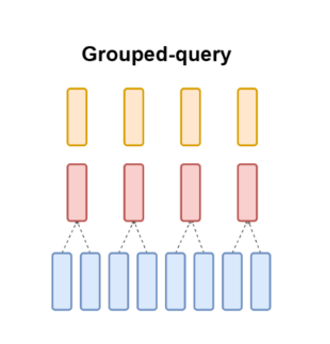
Multi-Query
所有头共享同一套 K 和 V,只有 Q 保持独立(数量等于头数)这种方式反应速度最快,效率最高
内存占用最小,但其缺点也很明显,表达能力最弱,所有头被迫共享相同的 K 和 V,容易丢失如语法、语义等信息,不适合在复杂任务
归一化层位置选择的变化
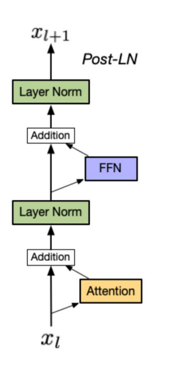
Post-LN(后置归一化)
该结构是输入x首先通过一个attention层再与原数据进行残差拼接,然后进行归一化操作,最后再传递到下一个层。这种方式可以保持上下层的信息流动,在进行反向传播时能更好的控制梯度,不过缺点也很明显,随着网络层数的加深,很容易出现上一层输出分布极端(比如方差过大 / 过小无限趋近于0)出现梯度爆炸或消失,这种结构的transformer训练并不稳定
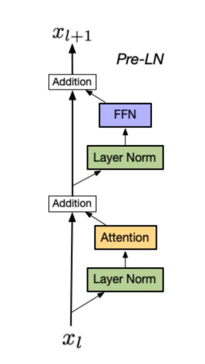
Pre-LN(前置归一化)
该结构是在进入神经网络层的计算之前先对输入数据x进行归一化操作,强制输入分布满足均值 0、方差 1的稳定状态,同时切断了层与层之间的连接关系下一层接收的输入,不再依赖于上一层子层的原始输出,减少了模型层之间的耦合能力,同时解决了输入分布极端(比如方差过大 / 过小无限趋近于0)也能减少反向传播梯度爆炸或梯度消失,这种方式可以缓解transformer训练不稳定问题
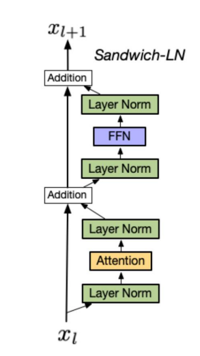
Sandwich-LN(夹心归一化)
Sandwich-LN是一种结合了Post-LN和Pre-LN的归一化方式,该结构一定程度结合了Post-LN和Pre-LN的优点。先对输入数据x进行归一化操作减少了模型层之间的耦合能力,在Attention层后进行归一化保持上下层的信息流动,但缺点是容易崩溃,因为多层归一化会导致数据过度归一化特征同质化
归一化层变化
LayerNorm
第一步:对于输入张量 x计算均值,其形状为 (batch_size,seq_len,d_model)特征维度为d_model
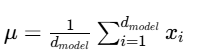
第二步:计算在特征维度 d_model上的标准差
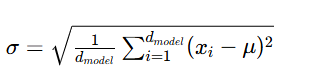
第三步:进行归一化
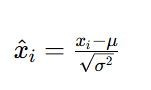
第四步:进行缩放和平移,其中γ 和 β 是可学习的参数
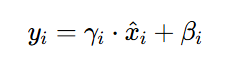
以[1, 2, 3, 4, 5]为例用具体数字和数学公式表示:
算均值 μ:
μ = (1+2+3+4+5)/5 = 15/5 = 3
算方差(每个数减均值后平方的平均):
方差 = [(1-3)² + (2-3)² + (3-3)² + (4-3)² + (5-3)²]/5
= [4 + 1 + 0 + 1 + 4]/5 = 10/5 = 2
算标准差 σ:
σ = √方差 = √2 ≈ 1.414
归一化(减均值 ÷ 标准差):
y1 = (1-3)/1.414 ≈ -1.414
y2 = (2-3)/1.414 ≈ -0.707
y3 = (3-3)/1.414 ≈ 0
y4 = (4-3)/1.414 ≈ 0.707
y5 = (5-3)/1.414 ≈ 1.414
————————————————
版权声明:本文为CSDN博主「MYH516」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/mayaohao/article/details/150616329
RMSNorm
RMSNorm归一化去掉了 减均值 这一步,只使用 均方根来归一化
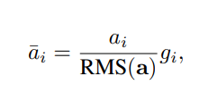
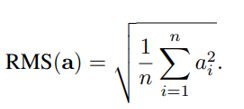
以[1, 2, 3, 4, 5]为例用具体数字和数学公式表示:
计算过程:
算每个数的平方:
1²=1,2²=4,3²=9,4²=16,5²=25
算平方后的均值:
平方均值 = (1+4+9+16+25)/5 = 55/5 = 11
算均方根 RMS:
RMS = √11 ≈ 3.317
归一化(直接除以 RMS):
y1 = 1 / 3.317 ≈ 0.301
y2 = 2 / 3.317 ≈ 0.603
y3 = 3 / 3.317 ≈ 0.904
y4 = 4 / 3.317 ≈ 1.206
y5 = 5 / 3.317 ≈ 1.507
RMSNorm 结果:[0.301, 0.603, 0.904, 1.206, 1.507]
————————————————
版权声明:本文为CSDN博主「MYH516」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/mayaohao/article/details/150616329
激活函数
Gelu
Gelu是输入值乘于标准正态分布的累积分布函数
![]()
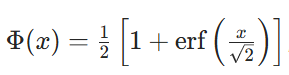
Relu
ReLU 的定义非常简单,是一个分段线性函数,仅保留输入的非负部分,将负部分置 0
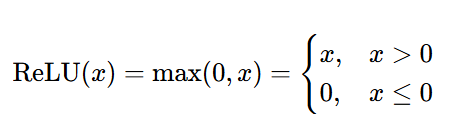
Swish
Swish 是 输入 x 与 sigmoid 变换后的 x 相乘,公式如下
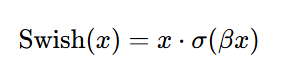
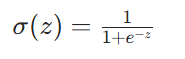
模型结构
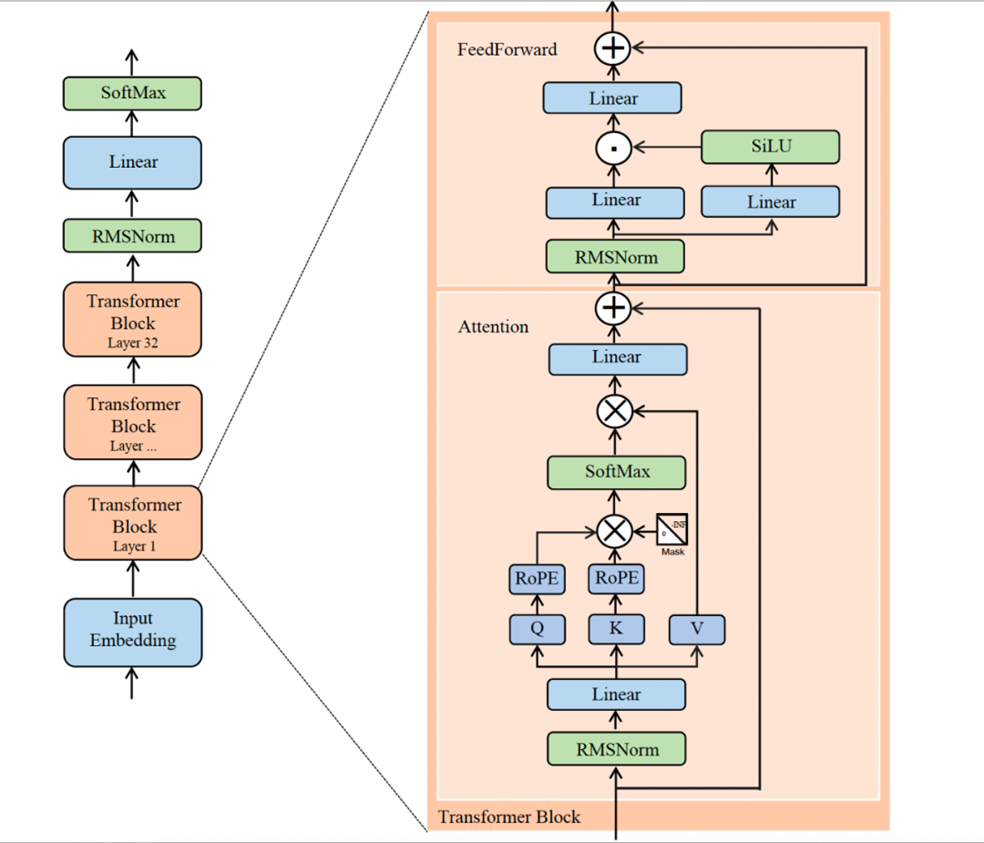
LLama2结构
与传统的Transformer架构相比,Llama 2架构具有以下的特点
1、使用的结构是Decoder-only,只做分布式任务
2、使用RMSNorm函数进行归一化,采用了Pre-LN(前置归一化)结构
3、在Q和K上使用RoPE相对位置编码
4、多头注意力机制采用了Grouped Query结构,降低计算 / 内存
5、激活函数使用SILU
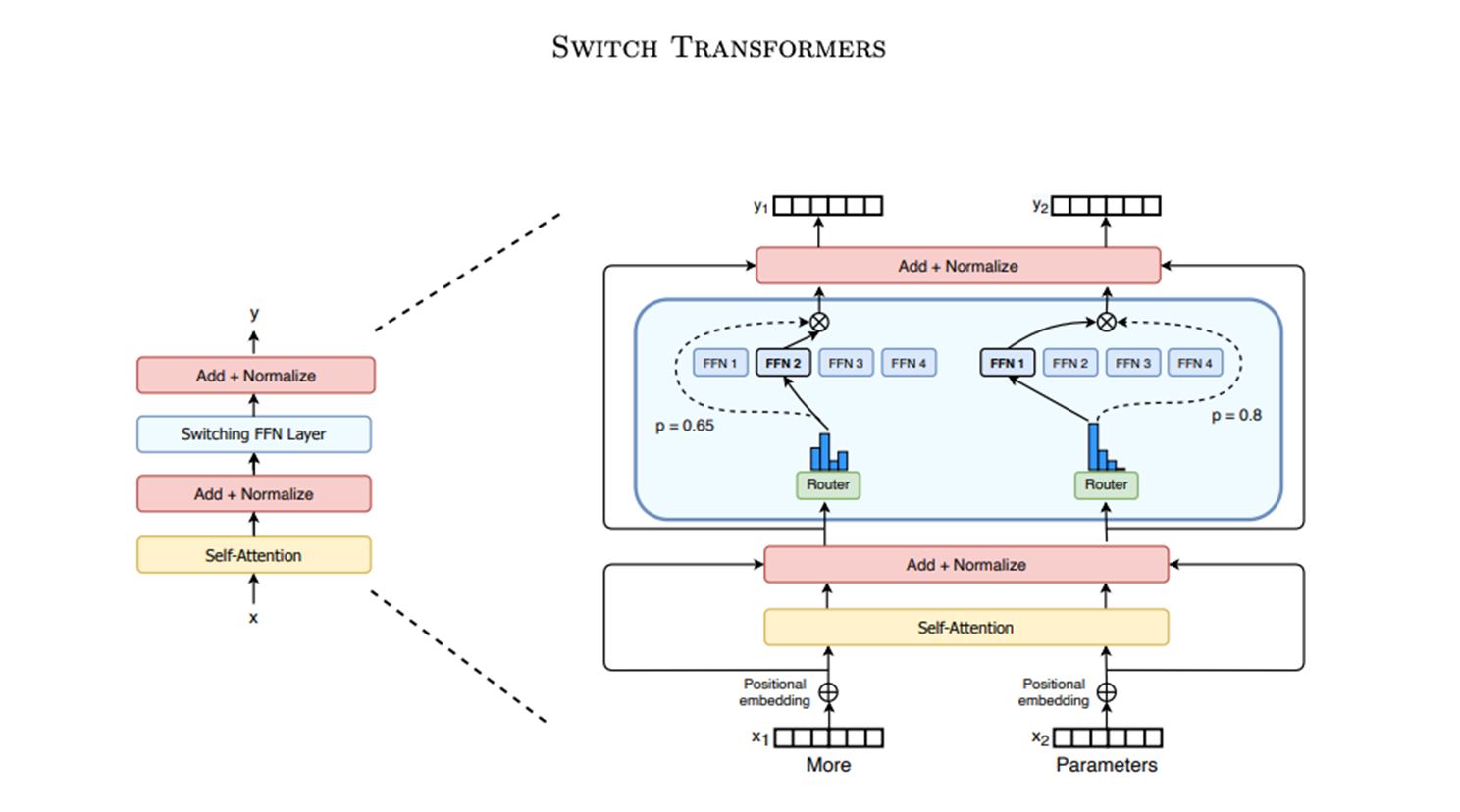
MoE架构 混合专家模型
核心思想是将一个庞大的神经网络分解为多个专门的子网络(称为"专家"),并通过动态路由机制为每个输入选择最适合的专家进行处理。输入X经过self-attention后进行残差和归一化,经过Router(可以为一个线性层+softmax函数)通过结果概率分配不同的子网络(称为"专家")
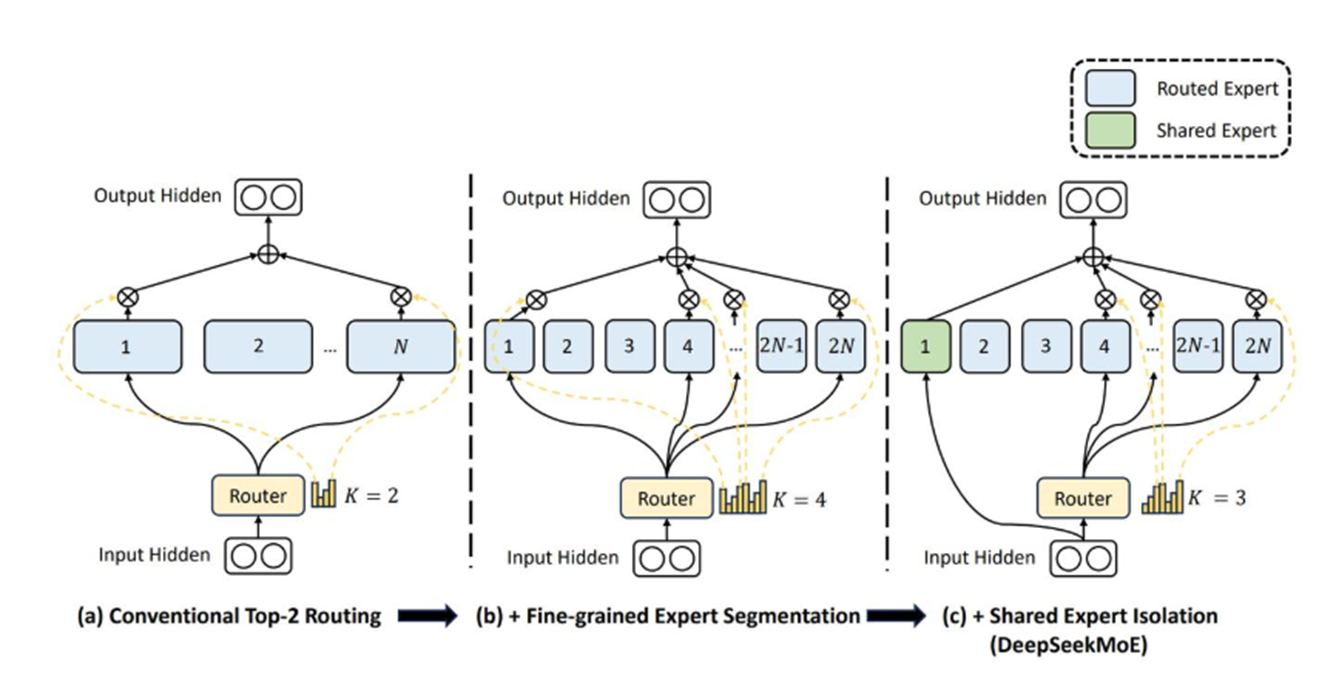
DeepSeek Moe
增加了“共享专家”Shared Expert,总是会使用这个“专家”进行计算,其余的按照传统moe方式由模型自己挑选
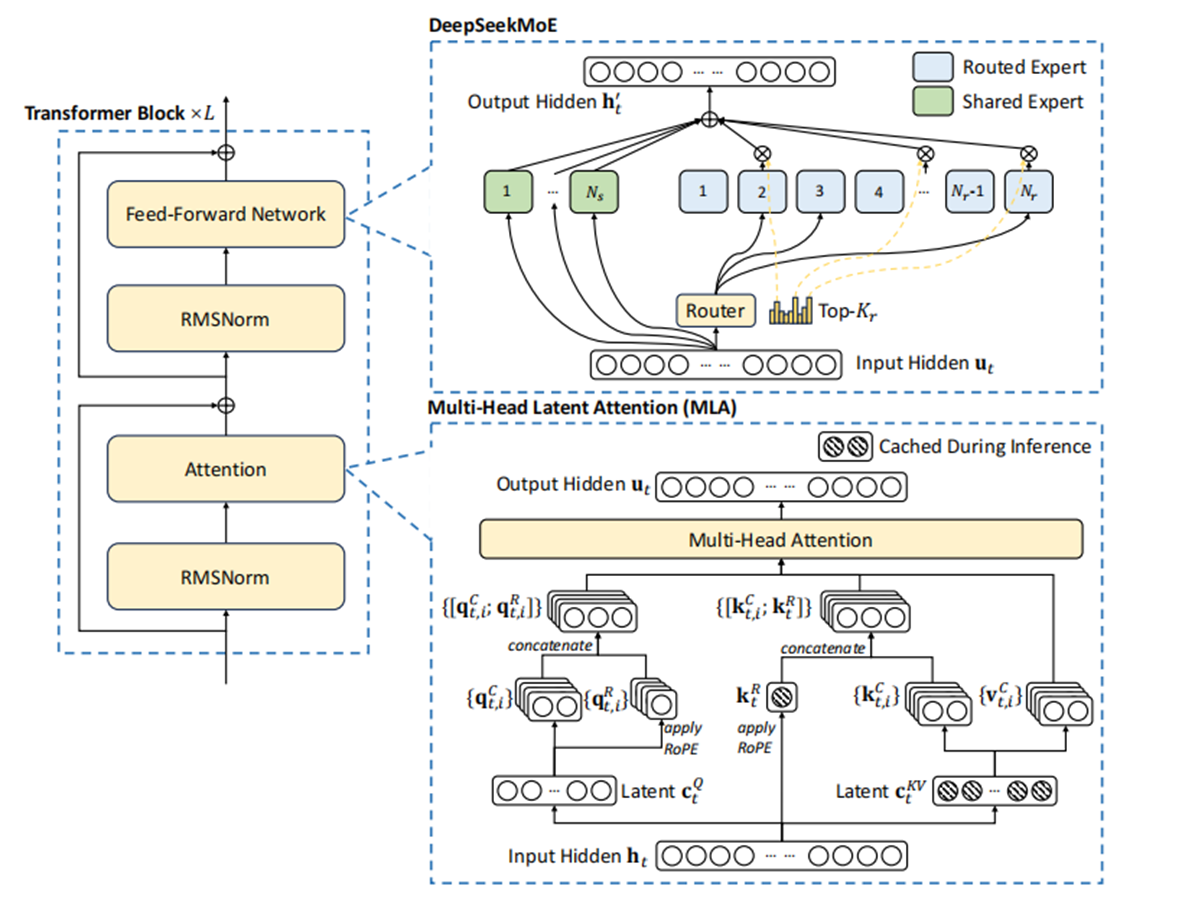
DeepSeek MLA
创造性的提出多头潜在注意力:Multi-head Latent Attention(简称MLA),替代传统多头注意力(Multi Head Attention),先对KV联合压缩后升维,再对Q压缩后升维。通过对Query和Key进行拆分为和
,其中一部分做压缩
、一部分做RoPE编码
版权声明:本文为CSDN博主「v_JULY_v」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/v_JULY_v/article/details/141535986

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)