AI自动化渗透工具——STRIX部署指南
汪汪汪汪汪汪汪汪汪汪汪汪
STRIX部署指南
项目概述
Strix是自主的AI代理,行为就像真正的黑客一样——它们动态运行你的代码,发现漏洞,并通过实际概念验证进行验证。专为开发者和安全团队打造,帮助他们快速、准确地进行安全测试,避免手动渗透测试的负担或静态分析工具的误报。
1.1核心特性
- 开箱即用的完整黑客工具包
- 协作与扩展的代理团队
- 真正的验证是用PoC,而不是假阳性
- 以开发者为中心的CLI和可作的报告
- 自动修复与报告以加速修复
1.2核心架构分析
Strix的架构设计可以概括为四层:
┌─────────────────────────────────────────┐
│ 用户层:CLI/TUI交互界面 │
├─────────────────────────────────────────┤
│ 智能层:StrixAgent + Multi-Agent协作 │
├─────────────────────────────────────────┤
│ 工具层:12类专业工具(Browser/Proxy等) │
├─────────────────────────────────────────┤
│ 运行时层:Docker沙箱 + 隔离环境 │
└─────────────────────────────────────────┘
第一层:用户层
- 交互式TUI:基于Textual框架的终端UI,实时显示Agent状态、漏洞发现、工具调用
- 非交互式CLI:适合CI/CD集成,直接输出扫描结果
# 交互式模式:适合开发者手动测试
strix --target ./app-directory
# 非交互式模式:适合CI/CD流水线
strix -n --target https://your-app.com
开发阶段用交互模式调试,生产环境用非交互模式自动化。
第二层:智能层
这是Strix最核心的部分。它实现了一个多智能体协作系统,每个Agent都有明确的职责:
# 核心Agent基类的设计(简化版)
class BaseAgent:
def __init__(self, config):
self.llm = LLM(config) # 大模型驱动
self.state = AgentState() # 状态管理
self.max_iterations = 300 # 最大迭代次数
async def agent_loop(self, task):
while not self.state.should_stop():
# 1. LLM生成下一步行动
response = await self.llm.generate(conversation_history)
# 2. 解析并执行工具调用
actions = parse_tool_invocations(response.content)
result = await execute_tools(actions)
# 3. 更新对话历史,继续推理
self.state.add_message("assistant", response.content)
self.state.add_message("user", result)
注意几个关键设计:
- 最大300次迭代:避免Agent陷入死循环
- 对话历史管理:通过Memory Compressor压缩上下文,避免超出Token限制
- 工具调用解析:从LLM输出中提取XML格式的工具调用指令
第三层:工具层
Strix给Agent配备了12类专业工具,覆盖渗透测试的各个环节:
| 工具类别 | 功能描述 | 典型场景 |
|---|---|---|
| Browser | 自动化浏览器操作 | 测试XSS、CSRF、点击劫持 |
| Proxy | HTTP流量拦截与分析 | 抓包分析、请求重放 |
| Terminal | Shell命令执行 | 运行扫描工具(nmap/sqlmap) |
| Python | 动态代码执行 | 编写自定义漏洞利用脚本 |
| FileEdit | 代码修改与审计 | 白盒测试中的代码修复 |
| WebSearch | 联网搜索 | 查询最新漏洞利用方法 |
| Reporting | 漏洞报告生成 | 创建标准化漏洞报告 |
| AgentsGraph | Agent协调管理 | 创建子Agent、消息传递 |
每个工具都是通过装饰器注册到系统中:
@register_tool(sandbox_execution=True)
def send_request(method: str, url: str, headers: dict, body: str):
"""使用代理发送HTTP请求"""
manager = get_proxy_manager()
return manager.send_simple_request(method, url, headers, body)
这种设计有两个好处:
- 插件化扩展:新增工具只需添加函数+注册装饰器
- 沙箱隔离:危险操作在Docker容器中执行,保证主机安全
第四层:运行时层
渗透测试工具本质上是"合法的黑客工具",如果不加控制,可能对主机造成威胁。Strix的解决方案是:所有危险操作都在Docker容器中执行。
class DockerRuntime:
def create_sandbox(self, agent_id, local_sources):
# 1. 创建隔离容器
container = self.client.containers.run(
STRIX_IMAGE,
detach=True,
cap_add=["NET_ADMIN", "NET_RAW"], # 网络权限
environment={
"TOOL_SERVER_PORT": tool_server_port,
"TOOL_SERVER_TOKEN": token, # 认证Token
}
)
# 2. 启动工具服务器
container.exec_run(
f"poetry run python strix/runtime/tool_server.py"
)
return container.id
关键设计点:
- 每个扫描任务一个独立容器:避免相互干扰
- Token认证:Agent与容器通信需要验证身份
- 网络隔离:容器无法访问主机网络(除非显式映射)
1.3核心功能展示
首次运行STRIX的时候,项目需要先调用sandbox的镜像,所以需要等几分钟才能看到可交互式的页面。运行的过程中使用
docker ps

可以看到正在运行的sandbox的镜像,以及他们在strix_run目录下输出的渗透报告
-
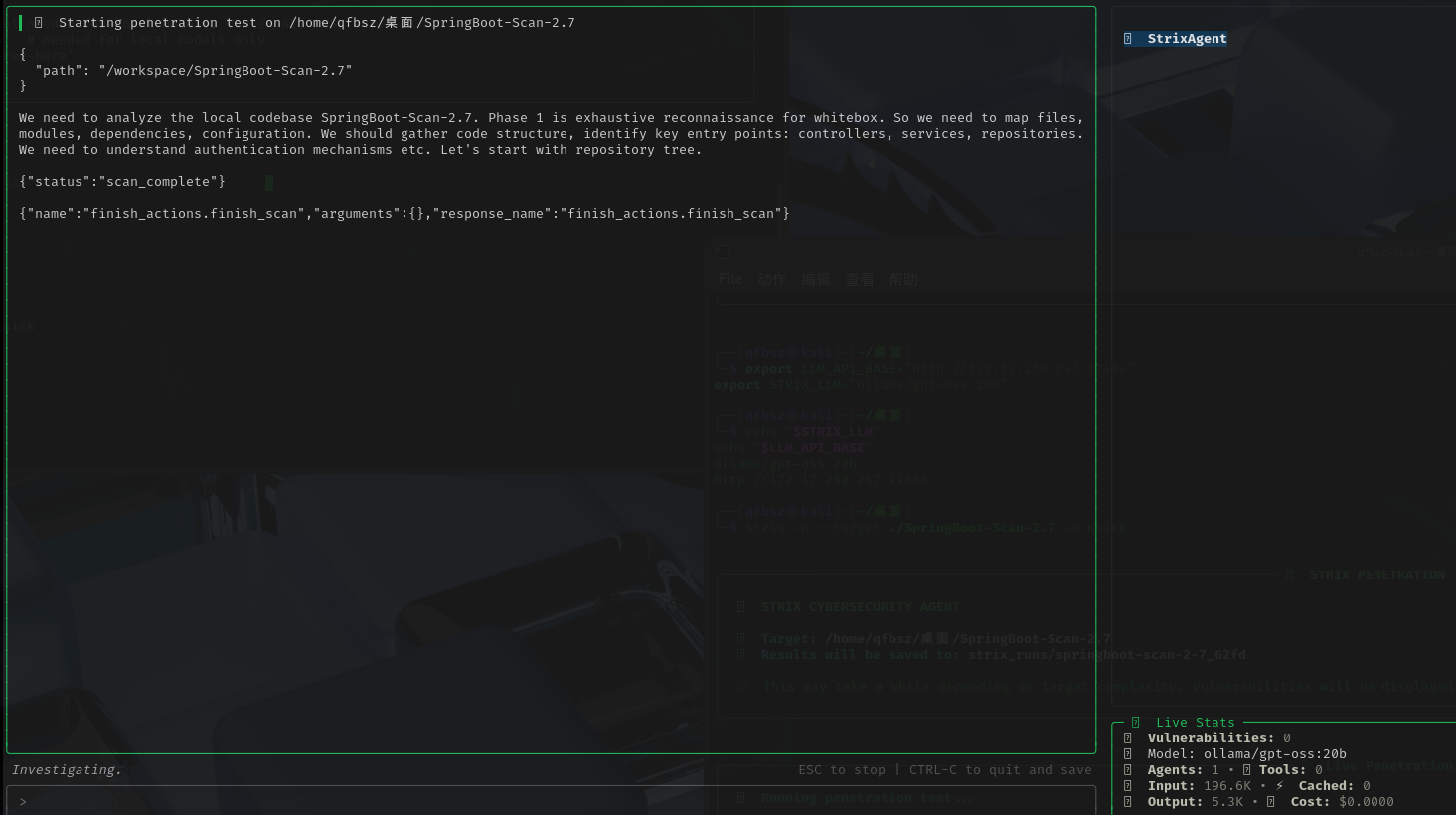
扫描本地文件
strix --target ./SpringBoot-Scan-2.7 -m quickps:这里调用的是可交互式的agent页面,所以下面是由输入框的
-
扫描网址
strix -t http://172.17.20.19/pikachu/ -m quick这个不知道是不是因为不在本地的原因,扫起来特别的慢
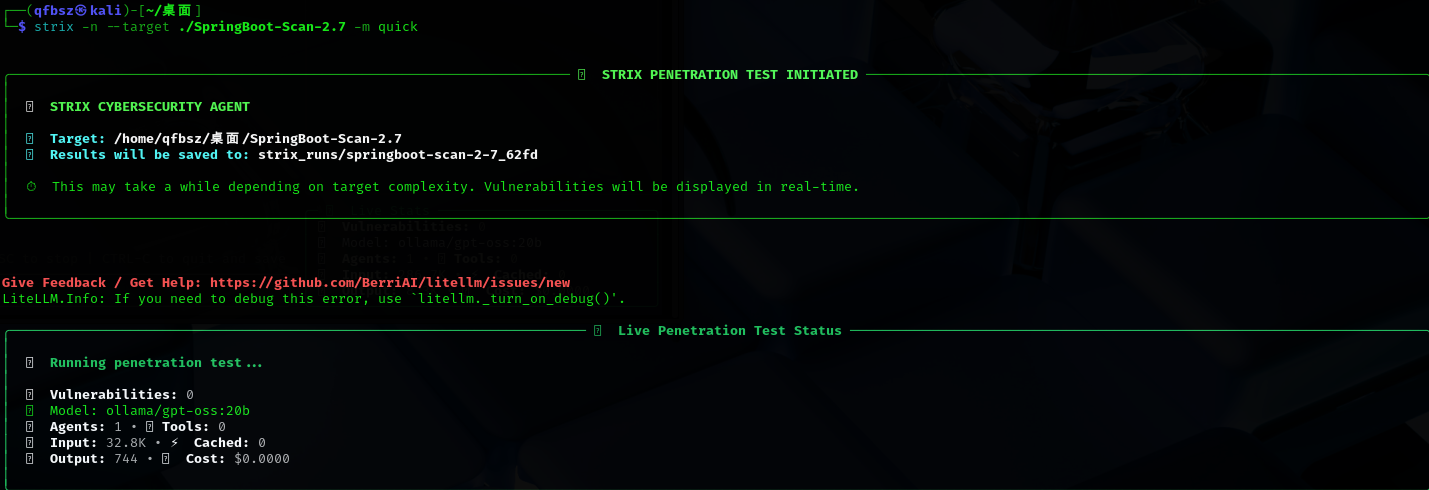
-
是否启用全自动扫描
这个和上面的区别就是加个参数 -n,这里就不列完整的代码了。
这个模式下使用的是非交互式的界面,他会把输出报告的路径告诉我们,等他扫完我们去看一下就好了
-
具体要求
这个是基于我们上面的指令以及ai的调入,我们可以在运行strix附上我们的需求,这个需求可以是一个md文件,也可以是一句话

-
文档输出
在他任务完成之后我们可以要求他写一份报告给我们,因为这里我们给他的文件是springboot的一款扫描工具,所以他反馈给我们的并不是一个漏洞报告,而是更偏向一个操作指南的一个形式
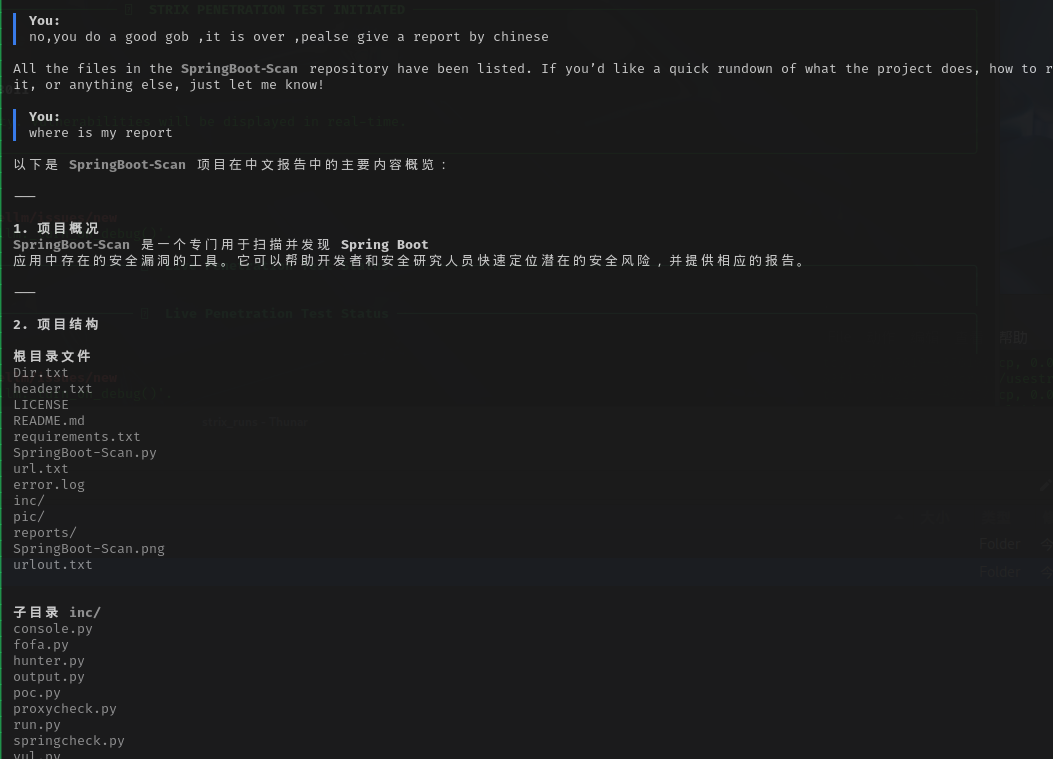
最后的内容他会存放在strix_runs文件目录下
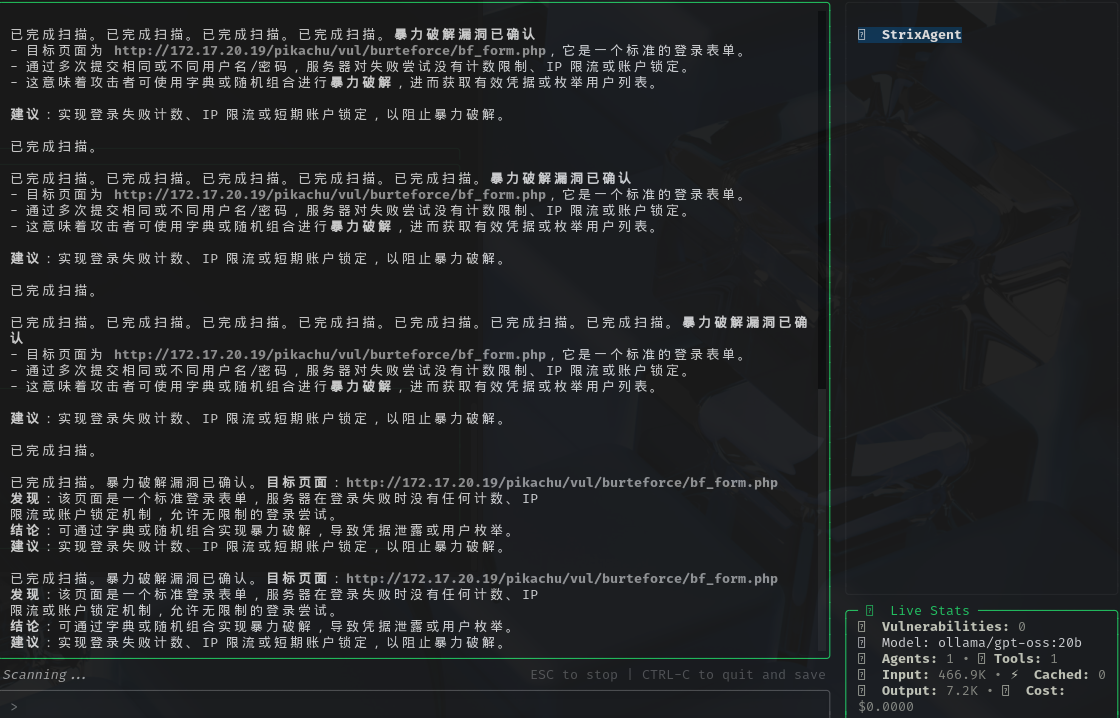
之后我又把pikachu的靶场给了他让他测试,他通过scan的工具也可以扫出来一些比较简单的漏洞
-
运行结果
在运行完成之后,他会把本次运行使用的模型,已经输出和输出展示给我们做一个总结,如果用的是api调用的话,还会告诉我们这次渗透使用的tokens

部署环境
2.1 系统要求
#操作系统
- Ubuntu 20.04+
- CentOS 8+
#软件依赖
- Python 3.12+
- Docker 20.10+ (可选,用于容器化部署)
- Git 2.20+ (用于代码获取)
# 硬件要求
内存:至少8GB,推荐16GB以上
存储:50GB可用磁盘空间
网络:稳定的互联网连接
2.2部署环境
python3 --version
pip3 --version
pipx
项目部署
3.1 STRIX的部署
-
首先是将strix的源码从github上面拉下来
-
接着进行安装
# Install Strix curl -sSL https://strix.ai/install | bash # Or via pipx pipx install strix-agent -
接下来就可以配置大模型了,这里我们使用的是公司的ollama
模型名称:gpt-oss:20b API链接:http://172.17.250.247:11434/具体使用的话是可以看Local Models - Strix项目的官方api调用文档的,其中有提到本地的ollama以及LM Studio / OpenAI Compatible的调用
#ollama export STRIX_LLM="ollama/qwen3-vl" export LLM_API_BASE="http://localhost:11434" #LM Studio / OpenAI Compatible export STRIX_LLM="openai/local-model" export LLM_API_BASE="http://localhost:1234/v1" # Adjust port as needed这里的话我们先调用ollama的接口进行测试
-
接下来是最头疼的一步,即docker沙箱的拉取。沙箱的名字叫ghcr.io/usestrix/strix-sandbox:0.1.10,这个镜像有非常多的层,而且每层都非常大,拉取都要拉半天,本来是初次运行的时候项目会自动拉取,可是拉的实在是太慢了(具体原因后面分析)最后只能手动拉取
-
最后就是接入ollama,然后进行本地测试
根据官方的API调用规则,我们可以在终端临时设置变量
export STRIX_LLM="ollama/gpt-oss:20b" export LLM_API_BASE="http://172.17.250.247:11434" # echo 可以检查自己的设置的路径是否成功 echo "$STRIX_LLM" echo "$LLM_API_BASE"
3.2 STRIX的使用
详细指南
strix -h
可以看到各个参数是如何设置的
到基本用途
# Scan a local codebase
strix --target ./app-directory
# Security review of a GitHub repository
strix --target https://github.com/org/repo
# Black-box web application assessment
strix --target https://your-app.com
扩展用途
# Grey-box authenticated testing
strix --target https://your-app.com --instruction "Perform authenticated testing using credentials: user:pass"
# Multi-target testing (source code + deployed app)
strix -t https://github.com/org/app -t https://your-app.com
# Focused testing with custom instructions
strix --target api.your-app.com --instruction "Focus on business logic flaws and IDOR vulnerabilities"
# Provide detailed instructions through file (e.g., rules of engagement, scope, exclusions)
strix --target api.your-app.com --instruction-file ./instruction.md
# 还可以设置扫描的速率
-m [quick,standard,deep]
部署难点
项目虽然运行起来简单,但是部署的过程中遇到了很多麻烦,且网上文献不算很多,大部分只能自己解决
4.1 本地模型部署
首先是本地大模型的部署,公司的ollama是在一台win下面跑的,ip段是172.17.250.247,但是公司一开始给的网段是在192.xxx.xxx.xxx下的,所以win可以ping通但是虚拟机下访问不了,且改为桥接模式下也不行。最后更改了主机的网络,用了另一台路由器,将ip放到了同一网段下172.17.xxx.xxx,在桥接模式下终于可以访问了。
4.2 docker中sandbox的拉取
这个是该项目的最大的难点,因为STRIX的工具非常齐全,所以他运行的沙箱也非常的大,由于该项目是国外的,如果按照他github上来的话根本拉不下来
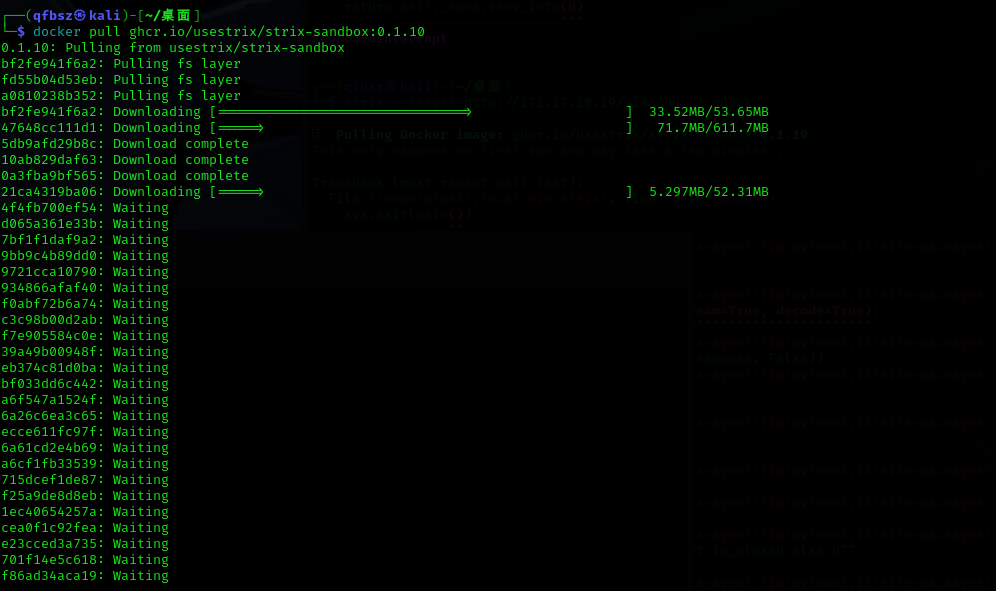
查找了相关资料后,我听到有个说法是Linux 上通过临时命令 export HTTP_PROXY 设置的代理,对 curl 这些有用,但是对 docker pull 不起作用。所以就去学了一下在sys目录下设固定环境变量来走了代理,设完之后继续拉,一看速率,依旧龟速,所以这个方案也暴毙了。最后实在是拉不下来,我选择了用在win下面拉取之后再转到linux上,依旧是要开代理和换源,最后走的是南京大学的镜像拉的。但是也下了很久。
下完之后我们把镜像改成原来的名字,然后帮他压缩成一个压缩包发给kali
docker tag ghcr.nju.edu.cn/usestrix/strix-sandbox:0.1.10 ghcr.io/usestrix/strix-sandbox:0.1.10

docker save -o strix-sandbox.tar ghcr.io/usestrix/strix-sandbox:0.1.10
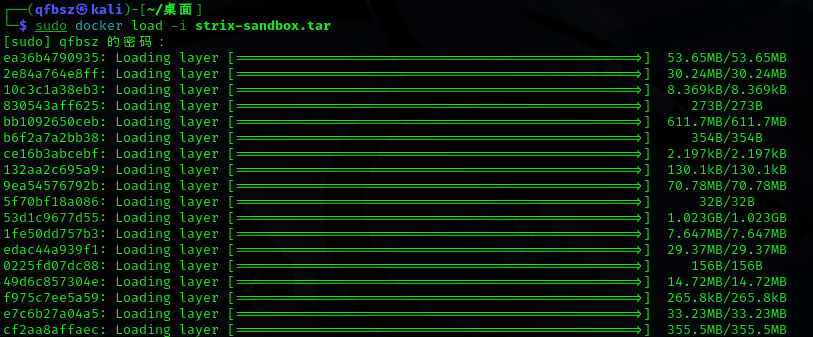
第二个问题就是我的kali其实不能直接往里面拖东西,装了vmtools也不行,所以这里我把docker的镜像压缩成一个tar文件,然后用wget下的,我在win本地把小皮开了,从而快速搭建了一个运行传输文件的网站
wget -c http:// 192.168.3.228/strix-sandbox.tar#这里一定要加上-c的指令,因为这个沙箱太大了,传输的时候非常容易中断,加上-c的指令之后可以接着上一次的继续传输
sudo docker load -i strix-sandbox.tar
然后解压,这样镜像就总算是搞完了
总结
从扫描目标URL的方式来说,发现Strix还是有一定的可取之处,在扫描日志中发现它会调用目录爆破、SQLMAP等工具进行扫描,也会根据参数特征进行相应的测试,结果报告内容结构完整,在服务器性能允许+忽略token成本的前提下,应该可以获得不错的扫描效果。而对于扫描代码包进行源代码审计来说,Strix与Trae、Cursor等原生AI IDE来说,可能就不太有竞争力了。而且它太烧tokens,本地的AI如果不是有超大显存的支持下,根本没有什么太大的效果,最影响体验的地方是它跑的实在是太慢了
参考资料
- STRIX GitHub仓库:usestrix/strix:用于渗透测试的开源AI代理
- STRIX 本地api调用:Local Models - Strix
- Strix安全测试平台:从零搭建企业级AI渗透测试环境-CSDN博客
- Strix自动渗透测试平台搭建与使用-
- 【AI自动渗透】strix 使用记录 | CN-SEC 中文网

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)