少脚手架多模型:新一代编程智能体架构拆解
当上下文接近容量:中间过程丢弃或摘要,保留开头(目标/约束)与结尾(最新状态/错误)。这是一种非常实用的经验主义:开头决定方向,结尾决定下一步。3.3 子代理:用隔离换清醒✅。
为什么未来主流编程Agent会回归while循环+少量工具,并用上下文管理与安全沙箱把它变成可用的工程系统。简单的设计往往是更好的设计。当模型持续变强时,最值钱的不是写了多少聪明的流程,而是把系统的复杂性安放在能长期复用的地方:工具接口、上下文管理、安全边界与评测体系。
1 主循环范式
1.1 从DAG到while循环:范式迁移
过去两年很多团队做编程/客服代理,常见路线是多分支工作流(DAG)+分类器+正则+意图识别+RAG。它确实能带来确定性:哪些情况走哪条路径、哪些内容必须被拦截、哪些步骤必须执行。代价也很直观:节点越多,维护越像在养一张会长毛的蜘蛛网:功能越加越难改,边界条件越补越多。
新路线,几乎反其道而行:一个主循环 + 工具调用(tool call)= 一个能跑起来的代理核心。逻辑非常朴素:
-
模型输出下一步(可能包含工具调用)
-
如果要调用工具:执行工具,把结果喂回模型
-
重复,直到模型不再要工具调用
-
再询问用户下一步目标
这就是所谓主外循环。它的革命性不在代码多聪明,而在它承认一件事:模型在变强,系统应该把复杂性让渡给模型,而不是把复杂性固化成流程图。

1.2 DAG vs 主循环:不是孰优孰劣,是适用面不同
| 对比维度 | DAG工作流(多分支) | 主循环+工具调用 |
|---|---|---|
|
优势 |
可控、可审计、强约束 |
适应性强、迭代快、维护轻 |
|
代价 |
架构膨胀、边界爆炸 |
更依赖模型能力与评测体系 |
|
适用 |
高合规、高风险(银行/风控) |
探索型、工程型、快速迭代 |
主循环保留,但把必须确定的部分塞进严格工具里,用工具的输入/输出可测试性来承接风险。
1.3 别为三个月后的问题造永久轮子
如果某些缺陷很可能在3~6个月内被新模型补齐,那么你今天花大价钱搭的补丁脚手架,未来可能变成技术债。
-
更好的工具接口(可复用、可测试、可版本化)
-
更好的上下文管理(长期都会需要)
-
更好的安全边界(永远需要)
而不是把精力耗在为了当前模型不够聪明而设计的复杂分流体系。
少脚手架、多用模型本质上是:把系统的复杂度从静态流程转移到动态推理,从而降低维护成本,让系统随着模型升级自动变强。
2 工具即接口
2.1 少工具,但要严谨
演讲列举了一组核心工具观:read / grep(或ripgrep)/ edit(diff) / bash / web fetch / todo / 子代理(task)。这些工具很像人类在终端里解决问题的基本动作:
-
先读(read)
-
再搜(grep)
-
再改(diff edit)
-
再跑(bash)
-
必要时查资料(web)
-
用清单保持方向(todo)
-
把大任务切碎隔离(子代理)
关键点:工具要少,但每个要可依赖。工具越多,模型选工具的空间越大,反而更容易走偏;工具越严谨,你越容易评测、回归、版本控制。
2.2 read为何不是cat:token与读的策略*
read工具的意义不只是读取文件,而是把读取行为纳入控制:
-
控制一次读多少(token限制)
-
控制读哪里(片段、范围、重要段)
-
为后续摘要/压缩提供结构化入口 这其实是在对抗编程代理的最大敌人:上下文爆炸。
2.3 grep替代复杂RAG
在通用编程代理里,grep往往更快、更便宜、更贴近人类习惯。很多代码检索场景,人类就是全局搜关键字、搜函数名、搜错误信息,然后沿调用链读下去。
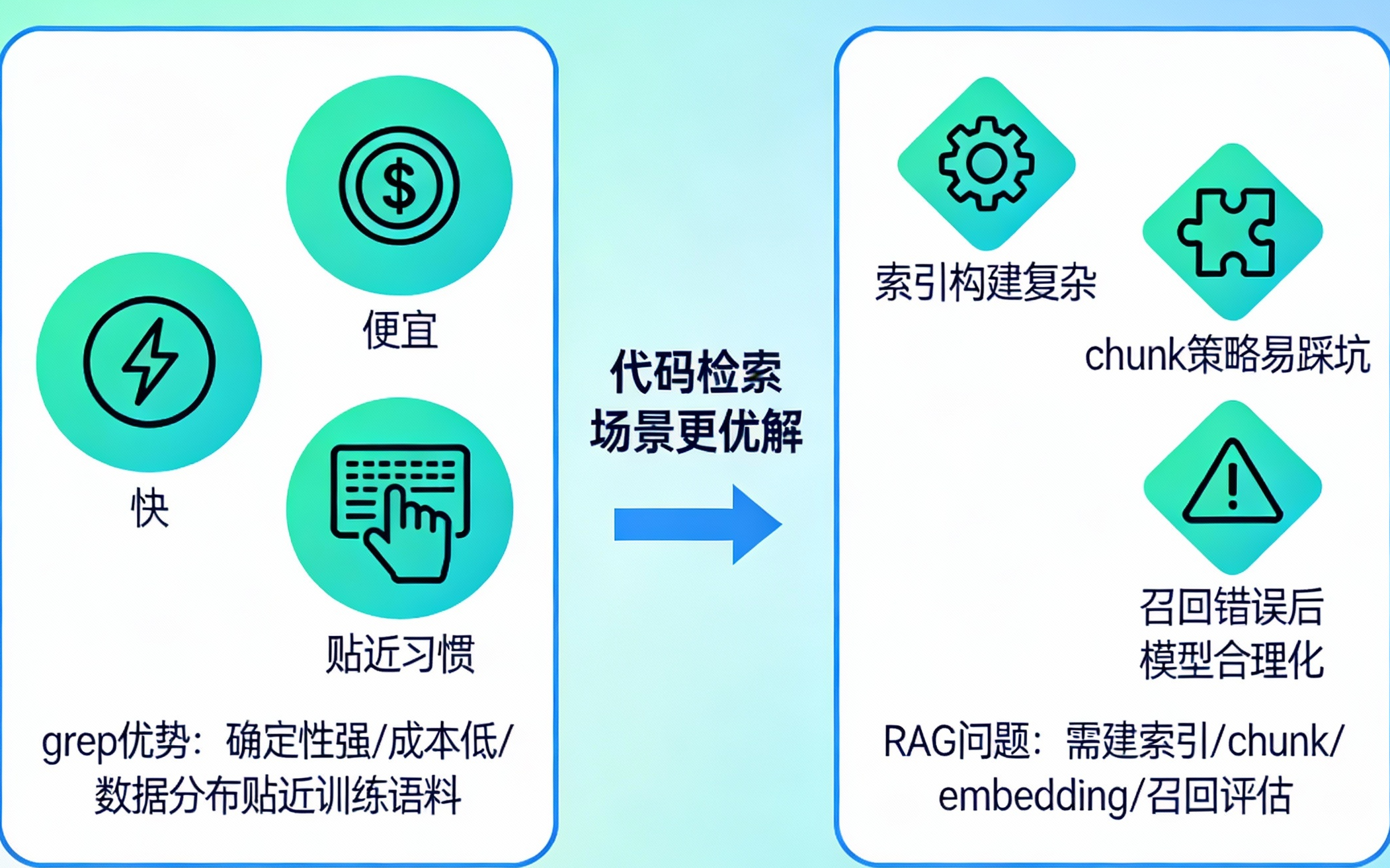
RAG的问题是:
-
要建索引、做chunk、做embedding、做召回评估
-
对代码库这类强结构文本,chunk策略很容易踩坑
-
一旦召回错了,模型会在错上下文里合理化
而grep的优势是:
-
确定性强(匹配就是匹配)
-
成本低、速度快
-
数据分布上更贴近训练语料(大量开发者都这么干)
需要跨大量文档、语义近似匹配、或自然语言问答(而不是代码符号检索)时,RAG仍然是强工具。
2.4 diff编辑为何是防错机制
edit工具走diff路线很关键:
-
改动更小 → 需要的上下文更少
-
误伤概率更低 → 减少改A坏B
-
更适合代码审查 → 变更可读可追踪
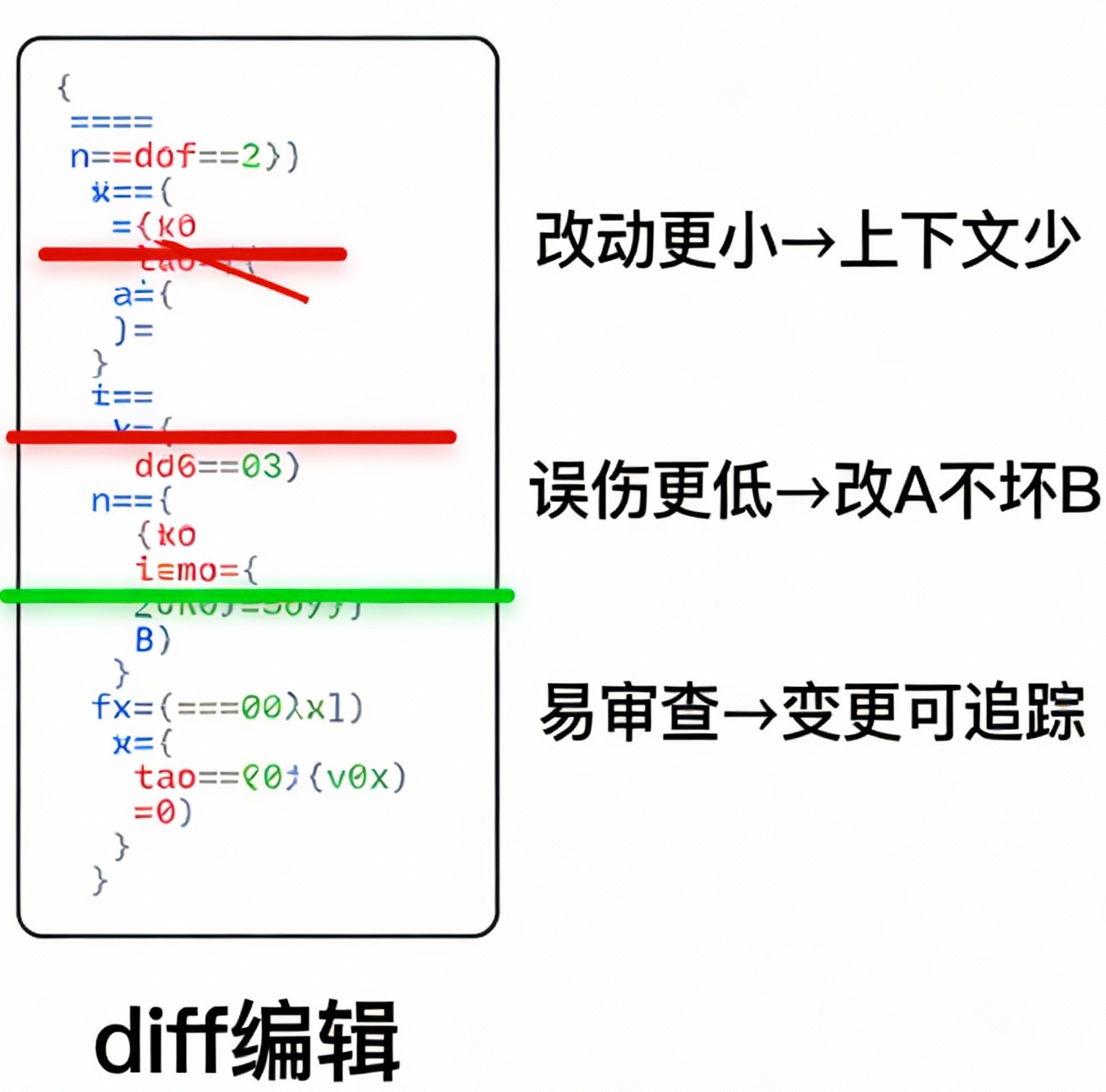
让你把全文抄一遍再改,肯定更容易出错;直接划掉再补充,才符合人类纠错方式。
2.5 bash是通用适配器
把其他工具都去掉,只留bash,也能跑。原因有两层:
-
bash能力上几乎无上限:文件、网络、进程、编译、测试、脚本生成……
-
训练数据极其丰富:全世界开发者每天都在终端里敲这些命令
这意味着:模型不仅会用bash,还更擅长用bash做探索式尝试:试错、对比、迭代,这正是主循环范式最需要的能力。
3 上下文管理
3.1 待办清单是软结构控制
✅ 结构化,但不强制:靠提示就能跑
待办事项(todo)这件事,它并不是通过确定性代码强制执行的,而是写进系统提示,模型就能自觉遵守每次只做一个任务、完成就打勾、遇阻就拆分。
✅ 待办清单带来的四种收益
-
强制规划:不容易迷路
-
崩溃可恢复:知道做到哪一步
-
用户体验:进度可见,避免黑箱跑40分钟
-
可控性:把行为约束显性化,便于评测与复盘
3.2 异步缓冲与上下文压缩
✅ 别把终端输出原样塞回模型
编程代理最常见的变笨时刻:终端输出巨长,日志灌满上下文,模型开始胡言乱语。用异步缓冲(类似I/O与推理解耦)来控制回填内容,只把关键结果喂回模型。
✅ 压缩策略:保头保尾,摘要中段
当上下文接近容量:中间过程丢弃或摘要,保留开头(目标/约束)与结尾(最新状态/错误)。 这是一种非常实用的经验主义:开头决定方向,结尾决定下一步。
3.3 子代理:用隔离换清醒
✅ 把长任务拆到独立上下文里
研究员、文档阅读者、测试执行者、代码审查员……这些子代理的共同点是:
-
它们有自己的上下文窗口
-
主代理只拿回结果摘要/结论
这样主上下文不会被研究细节污染,整体更稳定。
✅ 任务提示可自举:代理给子代理写提示
task工具的描述+提示结构,提示是一长串字符串,由主代理生成。这里的巧妙之处在于:当子任务失败时,主代理可以把失败信息继续注入下一次子任务提示,让系统具备自我修复的迭代空间。这与主循环的精神一致:让模型自己探索、自己纠错。
4 沙箱与安全边界
当代理能抓网页、能访问URL、还能执行命令,互联网上的提示注入就会变成现实风险。处理思路包括:
-
容器化/沙箱化执行环境
-
URL访问限制与阻断策略
-
把高风险操作放到子代理/子沙箱里
-
对批量命令执行做权限管理与前缀规则
核心原则很清晰:把危险能力关进边界清晰的盒子,并且让越危险的操作越难被顺手触发。
个人场景可能会直接开宽权限模式图省事,但企业客户绝不能这么做。这里的现实是:安全设计往往无聊、繁琐,却是能不能上线的生死线。
5 评测与工程权衡
✅ 真正重要的是评测体系
基准测试很不信任:大家都能在某些榜单赢,最后变成宣传。更靠谱的做法是围绕真实场景做评测:
-
端到端测试:给目标,看是否完成
-
时点测试:给半成上下文,看是否会调用正确工具
-
回测(强推):用历史数据重跑,比较版本差异
✅ 智能体气味:表层指标也有用
统计工具调用次数、重试次数、耗时、失败模式分布。它不等于能力本身,但能快速发现退化与异常,是工程上非常便宜的预警系统。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)