Rubric第一讲:评分量表(Rubrics)如何帮助提升大模型可靠性
评分量表是一套结构化指南,用于明确 AI 系统每一次输出的标准具体是什么,怎么样算“好”。得分项列表:例如 “代码是否可编译?”“代码是否包含注释?模型在各得分项上的表现描述:以 “代码可编译性” 为例,既可以用 “是 / 否” 来衡量,也可以采用更细致的分级,如 “是 / 是(但有警告)/ 否”。将表现转化为数值的评分规则:例如 “代码无问题 = 0 分,有警告 = 1 分,不可编译 = 2 分
一、AI 模型的质量取决于数据质量,但如何定义 “优质” 数据?
当前,AI 行业正朝着智能体系统(agentic systems)等更复杂的 AI 应用方向快速发展,但一个关键问题始终没有得到回应:agent进步需要训练数据和评估数据,但我们该如何系统性地衡量这些数据的质量并可持续地优化?
对于投身 AI 领域的企业而言,是时候采用主流 AI 实验室以及一面千识所使用的前沿方法了 —— 结构化评分量表(Structured Evaluation Rubrics)。
二、评估至关重要,但现有方法难以满足生成式应用的实际需求
评估能提供清晰的指标来跟踪 AI 性能、及早发现潜在问题,并确保AI的表现在上线后符合预期。了解Agent当前的问题与局限性对于生产环境的风险管理至关重要。然而,大多数企业仍在依赖过时的评估方法。
随着AI向生成式模型与智能体系统(agentic systems)演进,我们的评估思路也需随之转变。当前的挑战在于,如何构建能够评估开放式、生成式内容的评估框架。对于选择题类任务,MMLU等封闭式Benchmark仍有其价值,但在开放式内容生成的今天,我们需要全新的评估视角。
依赖产品团队的直觉来评估已经难以覆盖生成式模型可能出现的海量case,而用预先定义的理想答案作为对比基准,即 “黄金标准答案” (Golden Answers) ,但预先定义的答案很快会过时,而且在不存在唯一正确答案的场景中,这种方法根本不适用。
要构建能够满足生成式AI独特需求的评估框架,我们必须从根本上改变对 “质量衡量” 本身的认知。在直觉失灵、冗长的 “Golden Answer” 无法覆盖智能体所有交互场景时,评分量表(rubrics)能够从容应对这些挑战。
三、AI评估方法的演进
数十年来,AI评估主要依赖直觉型评估方法,包括:
-
领域专家根据自身对 “理想结果” 的直觉评估 AI 生成的结果
-
给定一个静态benchmark衡量通过率
-
针对有限案例,对比 “黄金数据集”(golden dataset)进行评估
对于答案非黑即白的分类任务,这种方法尚且可行,但将其应用于生成式 AI(GenAI)系统时,却会从根本上失效,比如:
-
评估 AI 生成的深度研究报告
-
评估存在多种有效解法的代码方案
-
评估既需保证事实准确性、又需兼顾创意与细节的聊天场景
在这些场景中,BLEU 分数(一个考核双语能力的benchmark)、精确匹配等传统指标无法捕捉开放式任务中 “质量” 的多维属性,往往会忽略相关性、实用性、以及领域特定需求等关键维度。
随机用几个简单的问题测试新上线的模型,也已经无法反应当今AI处理的任务。今天的agent需要处理日益复杂、长程的开放式任务,例如生成代码、开展深度研究等。在此背景下,行业正从依赖直觉的临时评估方法,转向系统性、有科学依据的评估框架。而曾经只是主流 AI 实验室必备工具的结构化评分量表(rubrics),正迅速成为行业通用标准。
基于评分量表的评估具有以下特点:
-
有建设性,事实性强
-
维度细致而深入,覆盖全面
-
模型自动评估与专家之间一致性高
-
颗粒度足够精细,能为模型的持续改进提供关键反馈
在探讨评分量表对 AI 系统评估的有效性之前,我们首先要明确 “评分量表” 的定义。
四、什么是评分量表?
评分量表是一套结构化指南,用于明确 AI 系统每一次输出的标准具体是什么,怎么样算“好”。
一套评分量表包含以下要素:
-
得分项列表:例如 “代码是否可编译?”“代码是否包含注释?”
-
模型在各得分项上的表现描述:以 “代码可编译性” 为例,既可以用 “是 / 否” 来衡量,也可以采用更细致的分级,如 “是 / 是(但有警告)/ 否”。
-
将表现转化为数值的评分规则:例如 “代码无问题 = 0 分,有警告 = 1 分,不可编译 = 2 分”。
最终的评分量表得分,是由一系列评估指标以及每个指标对应的数值或分值构成的。评分量表本质上是一种将领域专业知识转化成得分项的机制。例如,对于一个生成代码的大语言模型(LLM),需要由熟悉编程的专业人士来确定应纳入哪些得分项,以及每个得分项对应的不同的评分规则。关于评分量表的设计,我们将在后续博客展开更详细的讨论。
评分量表既可用于大语言模型,也可供人类使用。研究人员与项目经理可以向标注员提供评分量表,让所有标注员对数据集的评分体系形成统一认知——这有助于减少偏见,提高标注员之间的一致性。在自动化评估(即 “LLM as judge” 的评估方式)中,评估者会将评分量表纳入提示词(prompt)中。
无论是对人工评估者还是自动化评估者而言,评分量表都能将模糊的预期转化为可重复的分数。评分量表还具有 “双重价值”:在标注阶段,它能确保专家标注员的标注一致性;待模型训练完成后,它又可作为自动化评分的benchmark —— 从而打通了数据标注与评估之间的闭环。
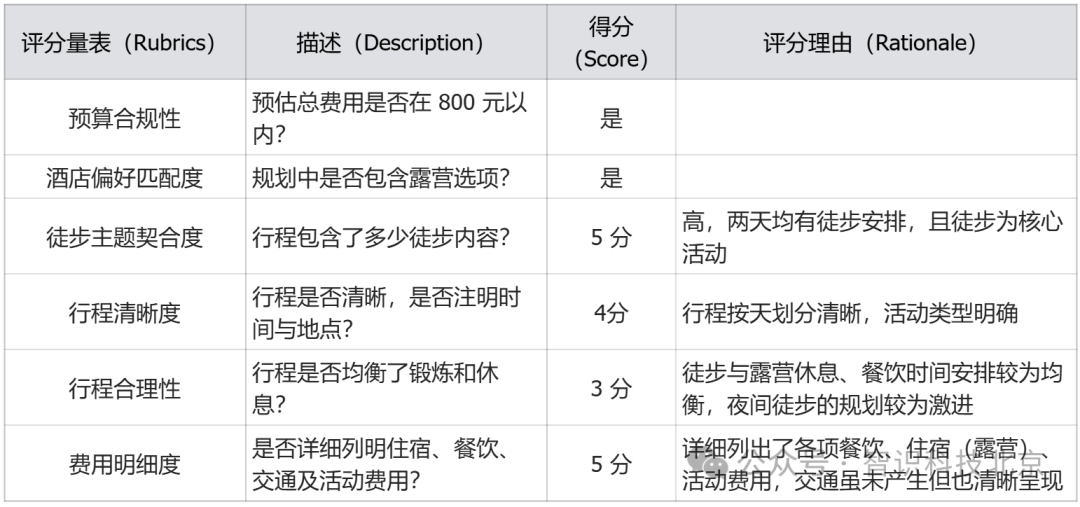
五、示例:周末活动规划智能体的评分量表
提示词(Prompt)
“为一位热爱徒步、偏好露营、总预算不超过 800 元的个人旅行者,规划一次为期两天的周末旅行。需包含建议行程、住宿详情及大致费用”

六、示例:将周末规划评分量表应用于模型生成的响应
提示词(Prompt)
“为一位热爱徒步、偏好露营、总预算不超过 800 元的个人旅行者,规划一次为期两天的周末旅行。需包含建议行程、住宿详情及大致费用”
-
第一天:
-
入门级山林徒步路线探索 - 免费
-
户外简餐套餐(含自热米饭、饮用水、能量棒) - ¥45 元
-
露营地搭建(含营地管理费、公共卫浴使用) - ¥80 元
-
便携卡式炉简易晚餐(含气罐、速食火锅食材) - ¥65 元
-
晚上徒步到山顶看星星 - 免费
-
-
第二天:
-
营地周边晨雾徒步观景 - 免费
-
简易早餐(自煮燕麦片、鸡蛋、热饮) - ¥15 元
-
林间轻徒步拓展路线 - 免费
-
返程前郊外农家简餐(家常菜 + 杂粮饭) - ¥50 元
-
露营装备租赁(1 晚,含双人帐、睡袋、防潮垫,适合单人使用) - ¥280 元
-
-
预估总费用:¥535 元
七、文献综述:行业专家如何看待评分量表(Rubrics)
近期的相关文献普遍认同一个核心观点:应将正确的评估方法视为数据的核心目标,再通过训练流程确保该目标落地。在模型开发周期中,评分量表在两个基础环节中发挥着关键作用:
-
制作高质量训练数据集:确保用于模型训练的数据符合标准
-
实现模型输出评分自动化:确保 AI 系统的输出结果同样符合(与输入数据相同的)标准
以下是在一些行业在构建高质量训练数据中应用评分量表的实例:
-
谷歌(Google)的ML Test Score[1]:将 28 项独立检查转化为可执行的评分卡(scorecard),团队在每次代码提交(pull request)时都会运行该评分卡。实践表明,这种方法不仅使准确率提升了两位数,还能在数据漂移影响生产环境前,及早发现潜在的 “隐性数据漂移”。
-
微软的 RUBICON 框架 [2]:将上述理念延伸至对话式agent领域。该框架利用大语言模型提出大量候选评估指标,再通过筛选优化,最终形成评分量表。与过往经验相比,该评分量表区分优质对话与劣质对话的精度提升了 18%。
-
Databricks[3]:针对RAG(retrieval-augmented generation)场景提出了类似观点。研究表明,向 GPT-4 输入明确的评分量表提示词后,每小时可完成数千对问答的评分,且与专家判断的一致性仍能保持在 80% 以上。
然而,仅仅是提效远远不够,自动化评估还需要通过提升效果才能更多赢得信任。
-
“自动化标注测试”(Alternative Annotator Test)[4]:提出了一个统计框架,用于判断大语言模型何时可替代人工进行打分。该框架仅需少量审核样本,即可量化相关风险。
-
Prometheus 2 框架 [5]:进一步拓展了这一领域的边界,无论是直接评分还是 pairwise 排序(成对比较排序),该框架都能使评估结果与人类及 GPT-4 的偏好保持一致;且无需重新训练完整的奖励模型,就能让算法工程师灵活增减评估指标。
这些研究共同表明,可扩展的模型迭代流程是切实可行的。企业 AI 迭代要实现高效与高质量,需具备以下三个核心特质:
-
可扩展性:将人工精力集中用于处理边缘案例
-
可靠性:评分量表中的问题需足够具体,以便基于提示词进行评分
-
一致性:通过统计保障机制,确保自动化评估的判断与人类专家意见保持一致
在实际应用中,自动化评估通常采用分层策略:
-
第一层:LLM-as-a-judge 进行初步筛选,排查有害内容、格式错误等明显问题
-
第二层:基于评分量表进行二次自动化评分,从事实准确性、连贯性、领域契合度等维度评估通过初步筛选的响应
-
定期人工抽查:对前两层自动化评估进行校准
这种分层结构之所以具备可扩展性,是因为大多数内容无需人工干预,即可通过前两层评估;其可靠性源于评分量表为评估者的判断提供了透明的依据;同时,它还具备灵活性 —— 随着产品目标的变化,团队无需重新定义 “黄金答案”(对于许多开放式任务而言,“黄金答案” 本就不存在),只需编辑或新增打分项即可。
为理解评分量表(rubrics)为何能实现人类专家与大语言模型机评的判断一致性,我们可从 “人类专家依照评分量表进行标注时的心理活动” 入手分析。
八、人工标注心理学
基于评分量表的评估会改变标注员的思考方式。清晰的评分量表能将原本存在于标注者记忆中的评估依据 “外化”,让标注者可一次聚焦一个维度,避免因需同时处理多个维度而导致判断不一致。
相关研究结果也印证了这一点:
-
教育领域研究 [6] 表明,与整体判断相比,使用分析型评分量表能显著提高评分一致性;人工评分者也认为,认知负荷降低是评分一致性提升的主要原因。
-
近期针对 “解释质量” 的基准测试研究 [7](CUBE 论文)在 AI 数据集中也得出了类似结论:一旦标注员采用结构化评分量表,即便在 “推理清晰度”“立场表达” 等主观性较强的任务中,人机一致率也会显著提升。
-
2024 年的一项实验 [8] 更进一步:研究人员让众包工作者与 GPT-4 标注结果配合,发现只有当工作者基于统一评分量表进行标注时,人类与模型的优势才能形成互补,最终准确率才能超越单一来源的判断。
评分一致性需要实证支撑,这也正是 “评分者间一致率”(inter-rater agreement)指标的价值所在。科恩 kappa 系数(Cohen’s Kappa)、弗莱希 kappa 系数(Fleiss’ Kappa)、组内相关系数(intraclass correlation coefficient)等指标,可量化评分者的判断一致性是否高于随机水平 [9]。
评分量表的设计同样关键。大多数评分量表采用 5 分或 7 分李克特量表(Likert scale),但如果缺乏清晰的评分依据,这种量表很容易导致 “趋中偏差”(central tendency)和 “解读偏差”(interpretation bias)。事实上,研究表明,在对话评估任务中,“最优 - 最差评分法”(Best-Worst Scaling)[10] 比传统李克特量表的评分者一致率显著更高;而连续型(滑块式)量表 [11] 相比离散选项,也能进一步提升评分一致性。
评分量表的价值不仅在于提高标注者间的一致性,还能起到护栏(guardrail)的作用,同时缓解标注员的疲劳感:
-
文献 [12] 的作者为 “AI 生成医疗问题长回答的人工评估” 设计了评分量表,其中纳入了可能导致公平性相关风险的多维度偏见指标,从而发现了大语言模型通用有害内容检测工具未能识别的规律。
-
从实践角度来看,Pareto 等人的研究 [13] 表明,结构化打分项与任务轮换相结合,能延缓标注疲劳的出现,确保标注者在长时间工作中仍能保持高质量标注。
用于指导自动化评估的评分量表首先必须能让人工标注者信服并实现一致评分,人工标注才能成为一项可控的实验。
九、结论
综上所述,有充分证据表明,AI 评估应采用分层式、以评分量表为核心的流程,具体步骤如下:
-
制定评分量表,用于识别训练数据与模型输出中的错误规律
-
培训标注员,直至评分者一致率稳定
-
在模型迭代过程中,依靠自动化评估实现快速评分
-
定期开展专家抽检,校准前两层自动化评估的准确性
遵循这些步骤,不仅能构建出适用于实际场景、可提供多维细致指标的评估方法,还能确保该方法具备可靠的可扩展性,满足 AI 系统快速开发对评估效率与规模的需求。
在一面千识研究院,我们不仅致力于研究高质量评估方法,更将其付诸实践。通过我们的 “专家数据即服务”(Expert Data-as-a-Service),我们与前沿模型开发者合作,为大语言模型的训练与评估筛选世界级数据集 —— 这些数据集信号密度高、由专家标注,可精准匹配您在复杂工具agent、复杂推理工作流等领域的应用。
感兴趣的小伙伴可点击链接,了解详情https://talent.meetchances.com/jobs?_fr=csdn

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)