Agent入门系列:基于文件系统的Agent上下文工程技术架构
摘要: 本文探讨了利用文件系统管理AI Agent上下文的新方案。传统RAG系统依赖多种数据库,接口复杂调试困难。而文件系统方案仅需操作系统自带功能,通过为每个任务创建专属文件夹存储进度、中间结果和日志,让Agent通过cat、grep等命令直接访问文件。Cornell大学的InfiAgent框架采用"文件系统+分层Agent"架构:L3协调任务拆分,L2执行细分任务,L1处理
目录
前言
目前国内主流的Agent系统上下文管理往往使用RAG系统,用到向量数据库、SQL结构数据库、还有图数据库等,这种涉及很多关于数据库API的调试工作,不同的数据库涉及不同的接口特点,搞得人头大。然而,对于时间性能要求不高的研究型项目,或者个人知识库项目,现在有一种更简洁的技术路线,不用任何数据库,不用任何外挂的API中间件,只要操作系统自带的文件系统就可以搞定所需上下文,而且有研究人员搞到一种方法,可以让Agent的上下文长度接近于无限能力。下面来简单聊聊:
一、先搞懂:Agent为啥需要“上下文管理”?
AI Agent(智能代理)能帮我们做写论文、处理数据这类复杂任务,但任务越长,它要记的“上下文”(比如之前做了啥、中间结果是啥)就越多——太多了会导致Agent卡壳、出错,这就是“长任务崩溃问题”。
而文件系统(像电脑里的文件夹/文件) 是个低成本的解决方案:把Agent的任务进度、中间结果存在文件里,既让Agent能随时“查资料”,又不会让它的“记忆负担”过重。


二、为什么选文件系统管上下文?
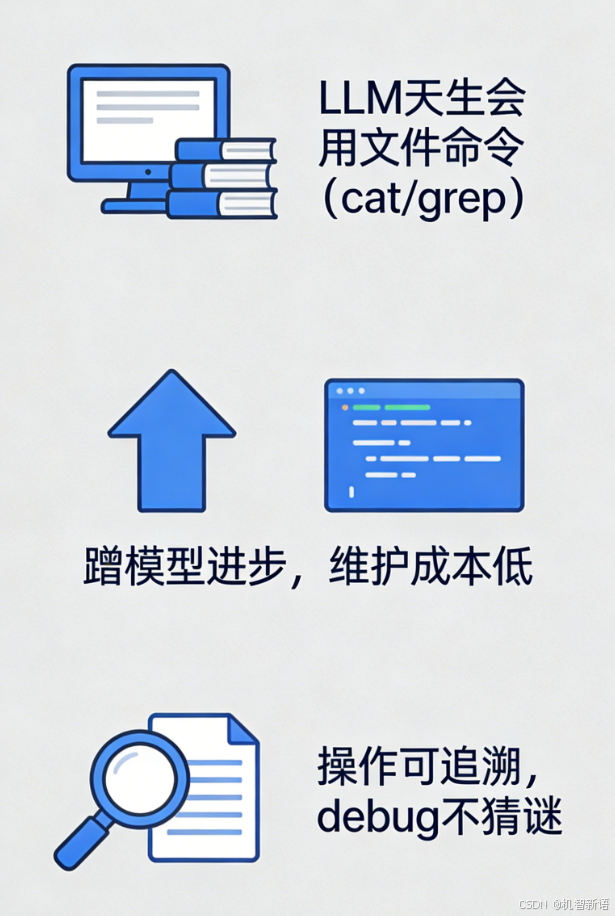
连LLM(大语言模型)都“天生会用”,这是Vercel(一家技术公司)给出的核心理由:

- LLM自带“文件操作技能”
像cat(看文件内容)、grep(搜文件里的内容)这些终端命令,LLM在训练时见过几十亿次,不用额外教——相当于Agent天生会“翻文件夹、查文件”。 - 后续维护更轻松
模型越擅长写代码,Agent的文件操作能力就越强,不用重新设计架构,直接“蹭模型的进步”。 - 出问题能查账,不是黑盒
Agent出bug时,能直接看它读了哪个文件、跑了什么命令,不用猜它“脑子里”在想啥。
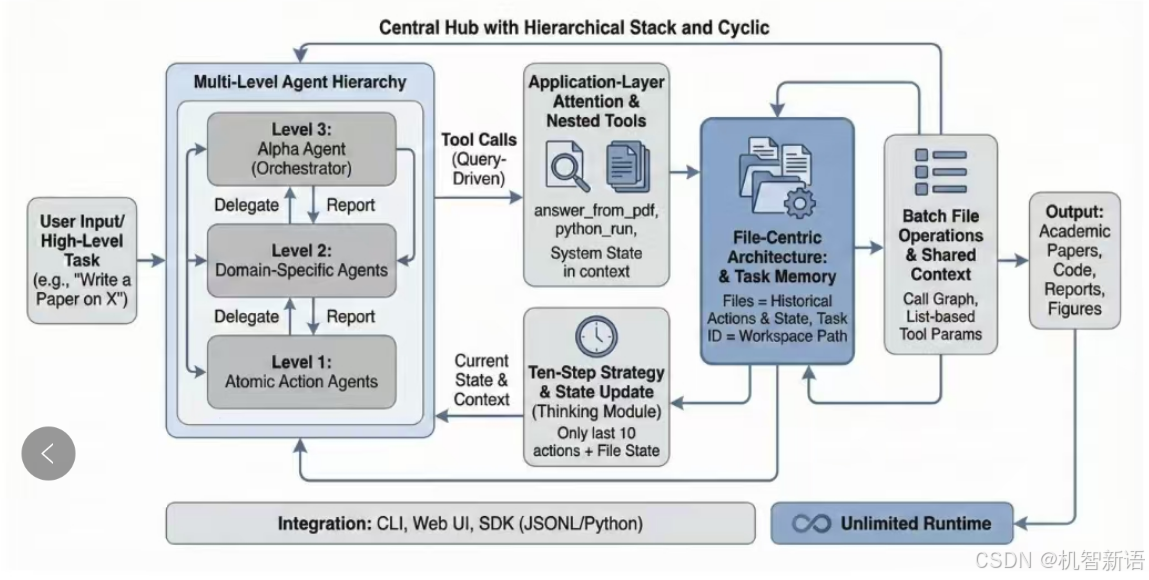
三、具体架构:以InfiAgent为例(适合长任务的框架)
Cornell大学的InfiAgent是“文件系统+分层Agent”的典型案例,
初学者可以这么理解:
1. 核心:文件当“任务笔记本”
给每个任务建一个专属文件夹,里面存:
- 任务计划、中间结果(比如写论文的大纲草稿)
- 工具输出(比如查资料的网页内容)
- 操作日志(比如“刚才用grep搜了文献关键词”)
同时Agent只记最近10个操作(小缓冲区),既保持思路连贯,又不会让“记忆”过载——需要细节时,直接去文件夹里查文件就行。
2. 定期“整理笔记本”:周期性状态整合
任务做久了,文件夹里的内容会变多,Agent会定期把“最近进度”整理到文件里,然后刷新自己的“短期记忆”——相当于你写论文时,定期把草稿存成新文件,不用一直记着所有细节。
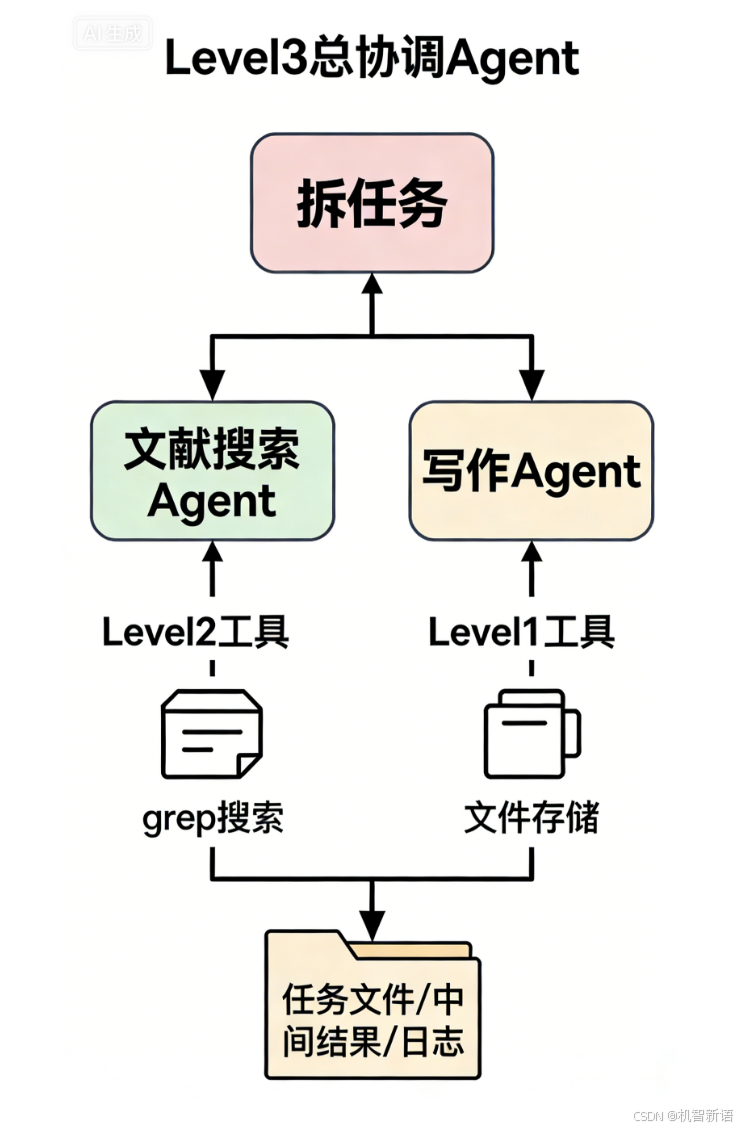
3. 分层干活:不让Agent“一人扛所有”
把Agent分成3层,分工明确:
- Level3(总协调Agent):接用户需求(比如“写一篇AI论文”),拆成小任务(“查文献→写大纲→补内容”)。
- Level2(领域Agent):专做细分活,比如“文献搜索Agent”“论文写作Agent”,负责执行总协调派的任务。
- Level1(工具Agent):专做具体操作,比如“用grep搜文献”“存文件到文件夹”,是干活的“手”。
四、总结:新手怎么入门?
不用搞复杂工具,先从“让Agent用文件存中间结果”开始:比如让Agent写报告时,把大纲存在outline.txt里,查的资料存在refs/文件夹里——既简单,又符合LLM的“使用习惯”。

您觉得以上技术方案如何?是否还有更好的方案,评论区聊聊?
附件:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)